Sistema Operativo - Che cosa fa?
Il compito principale del sistema operativo è quello di offrire servizi agli utenti, ad esempio per gli sviluppatori fornisce un utilizzo più semplice della RAM permettendoci appunto di creare semplicemente delle variabili, oppure fornisce un ambiente grafico per utilizzare le applicazioni non obbligandoci ad utilizzare i terminali con riga di comando.
Per fare questo il sistema operativo deve poter comunicare con l’hardware e gestire le sue risorse come:
- Processore
- RAM
- Dispositivi input / output
Modello di Von Neumann
Questa è la struttura più semplice di un computer monoprocessore, è composto da 3 blocchi principali visti prima e questi devono poter comunicare fra loro, lo fanno tramite il sytem bus. All’intero della CPU sono presenti dei registri molto veloci tra cui:
- PC: Program Counter, contiene l’indirizzo della prossima istruzione da eseguire.
- IR: Instruction Register, contiene l’istruzione da eseguire vera e propria.
- MAR: Memory Address Register, contiene un indirizzo della memoria RAM.
- MBR: Memory Buffer Register, contiene un valore da scrivere sulla RAM.
- ALU (Execution Unit): è la parte che svolge i calcoli logici e aritmetici.
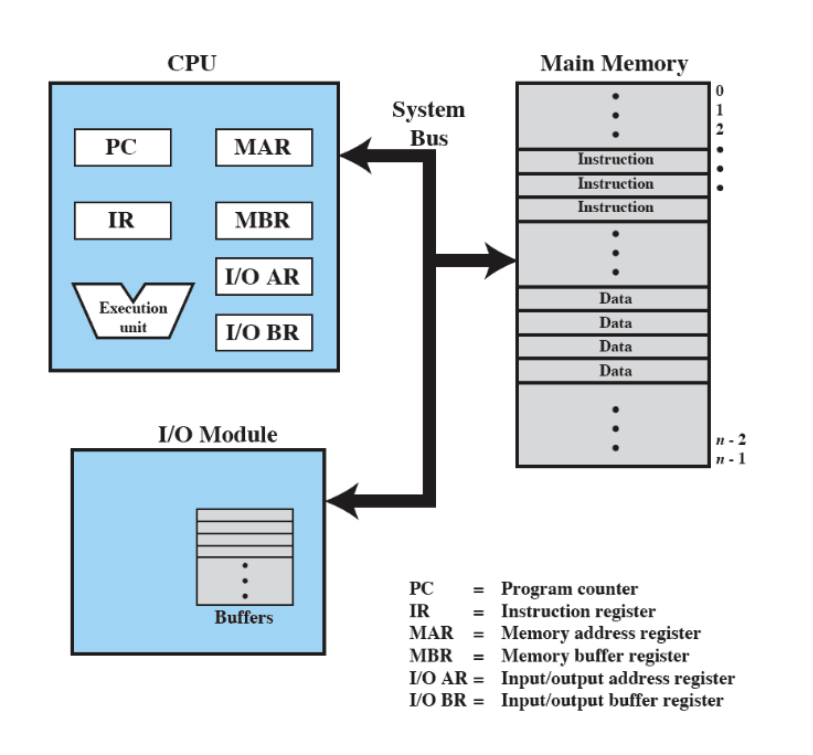
Componenti Principali:
- Processore: Svolge le computazioni.
- Memoria Principale: è volatile ovvero se spegniamo il computer perdiamo tutto il contenuto, viene chiamata memoria reale o primaria.
- Moduli di Input / Output: Periferiche come tastiera e mouse, dischi esterni non volatili, schede di rete ecc…
- Bus di sistema: Serve a far comunicare tra loro le parti interne del computer.
Come visto prima all’interno del processore sono presenti dei registri, delle memorie molto veloci e molto piccole, vediamoli nello specifico:
- Registri visibili all’utente: Sono usati o da chi programma in Assembler o dai Compilatori di linguaggi non interpretati.
- Alcuni sono obbligatori da usare per determinate operazioni su determinati processori mentre altri sono facoltativi e servono a minimizzare gli accessi alla RAM. Quelli non visibili si dividono in:
- Registri di controllo e di stato: Usati dal processore per controllare l’uso del processore stesso, vengono inoltre usati anche da alcune funzioni del Sistema Operativo per controllare l’esecuzione dei programmi.
Fanno parte di questi ad esempio:
- PC
- IR
- PSW (Program Status Word): Contiene le informazioni di stato
- Codici di Condizione (flag): Singoli bit settati dal processore come risultato di operazioni
- Registri interni: Sono usati dal processore tramite microprogrammazione, ovvero in determinate operazioni come il caricamento di un dato in RAM abbiamo bisogno ad esempio di un registro per l’indirizzo dove scrivere e un altro per il dato, questi sono i registri interni e non visibili dall’utente. Vengono anche utilizzati per la comunicazione con la memoria e I/O.
Fanno parte di questi ad esempio:
- MAR e MBR
- I/O Address Register e I/O Buffer Register
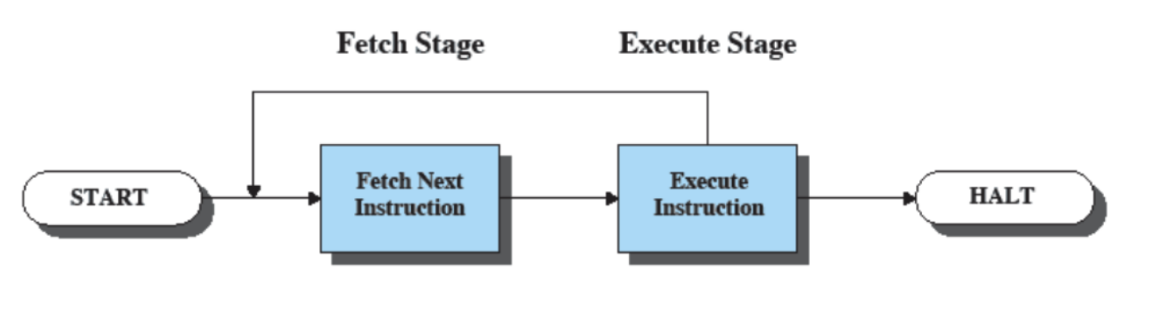
Esecuzione di Istruzioni
L’esecuzione si divide in due passi:
- Fetch: Il processore legge (preleva) le istruzioni dalla memoria RAM, nello specifico legge l’indirizzo di memoria presente nel PC e carica l’istruzione nel IR, quando parte l’esecuzione viene inoltre incrementato il valore del PC.
- Execute: Il processore esegue ogni istruzione prelevata. (presente nel IR).
Categorie di Istruzioni:
- Scambio dati tra processore e memoria. ad es. store word e load word
- Scambio dati tra processore e input / output.
- Manipolazione dati
- Operazioni Aritmetiche
- Di solito solo su valori presenti in registri (MIPS), ma in alcuni processori anche direttamente su RAM.
- Controllo: Modifica del Program Counter tramite salti condizionati o non
- Operazioni Riservate: abilitare o disabilitare alcune impostazioni come interrupt, cache, paginazione e segmentazione.
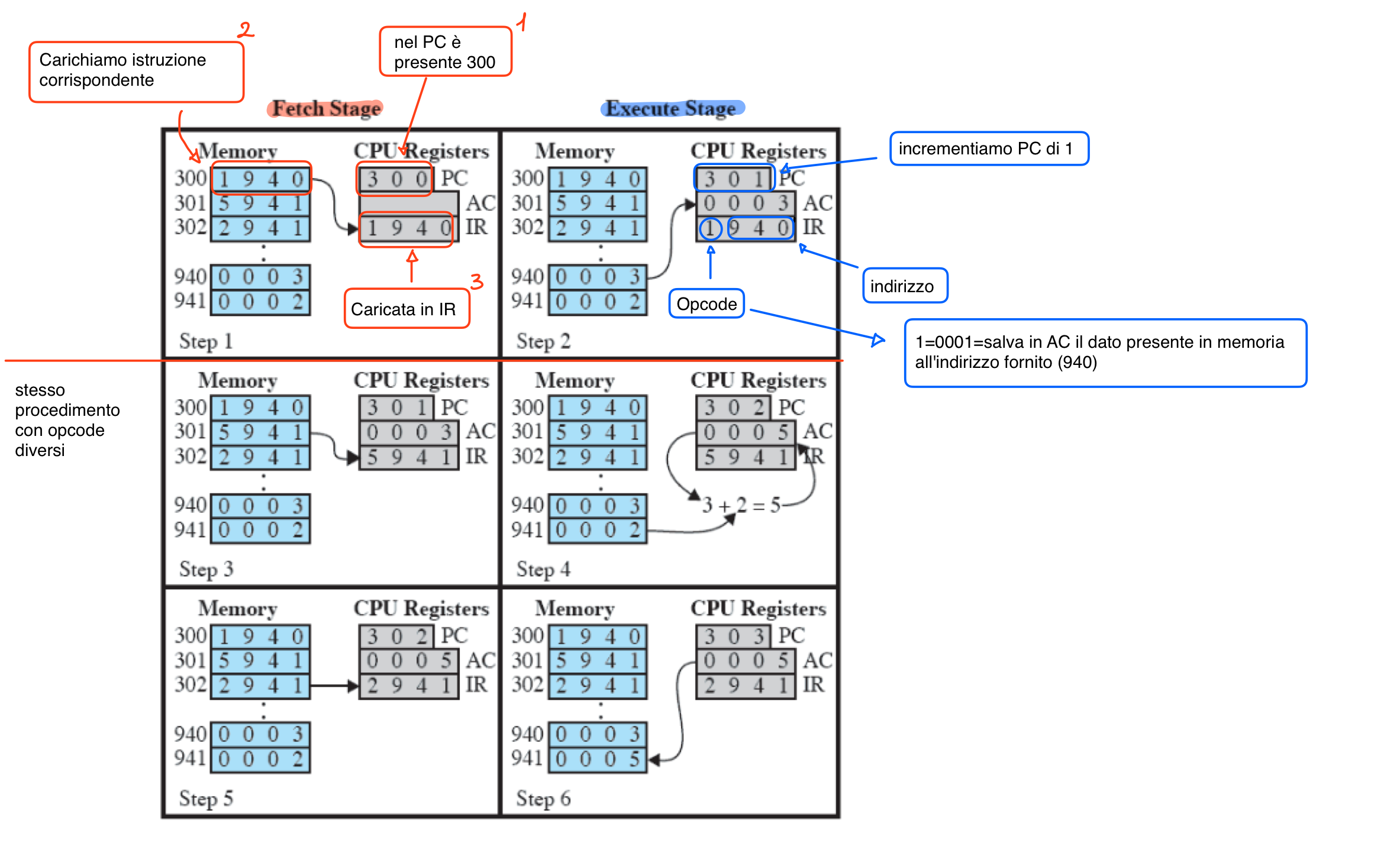
Esempio di una Macchina
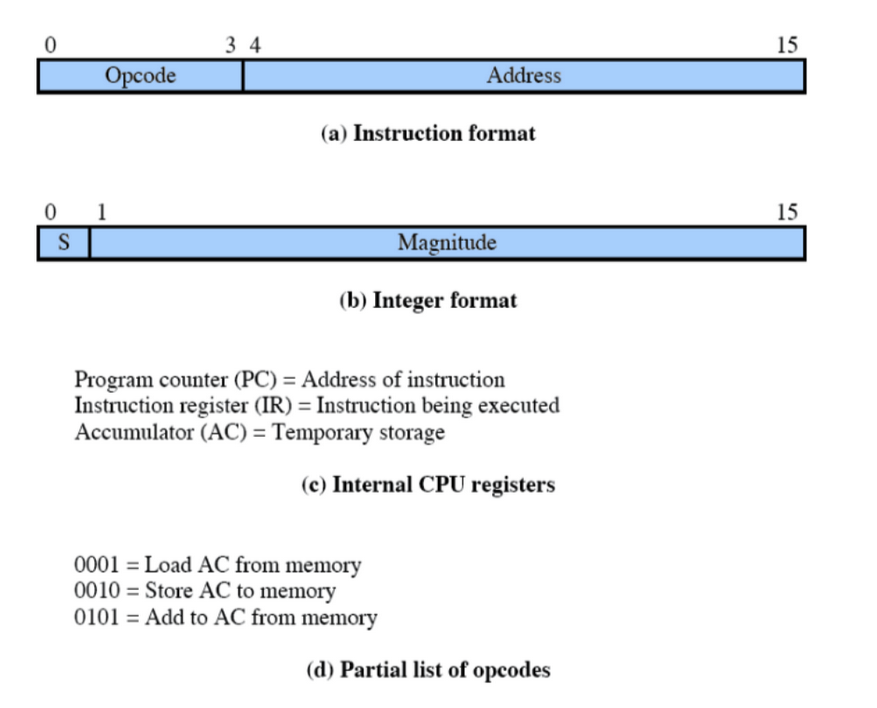
Questo è un esempio di una macchina a 16 bit.
Nel caso di un’istruzione questi 16 bit vengono usati in questo modo:
- I primi 4 indicano il tipo di operazione, Opcode.
- I restanti sono informazioni utili all’istruzione Se memorizziamo un numero:
- Primo bit indica il segno
- I restanti il numero stesso
Questa macchina ha 3 particolari istruzioni:
- 0001 = Salva in AC il dato presente nella memoria all’indirizzo fornito.
- 0010 = Salva in memoria il contenuto di AC, sempre nell’indirizzo fornito.
- 0101 = Aggiungi al valore di AC, il contenuto della memoria presente all’indirizzo fornito.
Interruzioni
Le interruzioni interrompono il normale flusso delle operazioni del processore per eseguire delle particolari operazioni del Sistema Operativo, quindi queste non sono scritte dall’utente.
Le cause di queste interruzioni sono molteplici e a seconda di queste prendono dei nomi diversi, sincrone e asincrone.
Quelle sincrone sono le interruzioni del programma e avvengono immediatamente dopo l’esecuzione di un’istruzione, quelle asincrone invece nella maggior parte dei casi vengono gestite molto dopo l’istruzione che le ha sollevate, e in alcuni casi non vengono nemmeno generate da un’istruzione ma da altri eventi.
Interruzioni Asincrone
- Interruzioni da input / output: Sono generate da un dispositivo I/O e dato che i loro controller sono più lenti del processore, quest’ultimo manda un comando al dispositivo e poi aspetta che questo dispositivo lo interrompa. Queste segnalano il completamente o l’errore di un’operazione I/O. In generale quindi vengono comunque generate in risposta a qualche istruzione.
- Interruzioni di fallimento Hardware: Queste non hanno niente a che vedere con altre istruzioni, infatti potrebbero accadere con: mancanza di potenza oppure errore di parità nella memoria.
- Interruzioni da comunicazione tra CPU: Possono accadere in sistemi con più di una CPU, oppure una CPU con più processori interni.
- Interruzioni da Timer: Vengono generate da un timer interno del processore, una sorta di clock. Sono utilizzate dal sistema operativo per eseguire operazioni ad intervalli regolari. (Ad es. ogni 10 secondi mandami un avviso, ogni 10 secondi viene quindi generato un interrupt).
Interruzioni Sincrone
Sono interruzioni generate dal programma, di solito causate da:
- Overflow.
- Divisione per 0.
- Debugging: servono per permettere allo sviluppatore di eseguire il programma passo dopo passo, ad esempio quando inseriamo dei breakpoint.
- Riferimento ad un indirizzo di memoria non accessibile (fatale), oppure momentaneamente non disponibile (memoria virtuale, gestibile).
- Esecuzione di un’operazione illegale, ad esempio un opcode non esistente.
- Chiamate syscall, queste sono intenzionali.
Quindi quando viene sollevate un’interruzione il sistema operativo crea un handler che esegue delle particolari operazioni sempre presenti nel S.O., nel caso di interruzioni asincrone una volta terminato l’handler si riprende la normale esecuzione del programma dall’istruzione successiva a quella che ha generato l’interruzione, a meno che l’operazione non sia stata completamente abortita.
Con le eccezioni sincrone non è detto accada questo:
- faults: Errore correggibile, viene rieseguita la stessa istruzione.
- aborts: Errore non correggibile, si esegue un software collegato all’interruzione.
- traps e system calls: Si continua dall’istruzione successiva.
Riprendendo quindi il ciclo delle operazioni eseguite dal processore visto prima, possiamo modificarlo in questo modo:
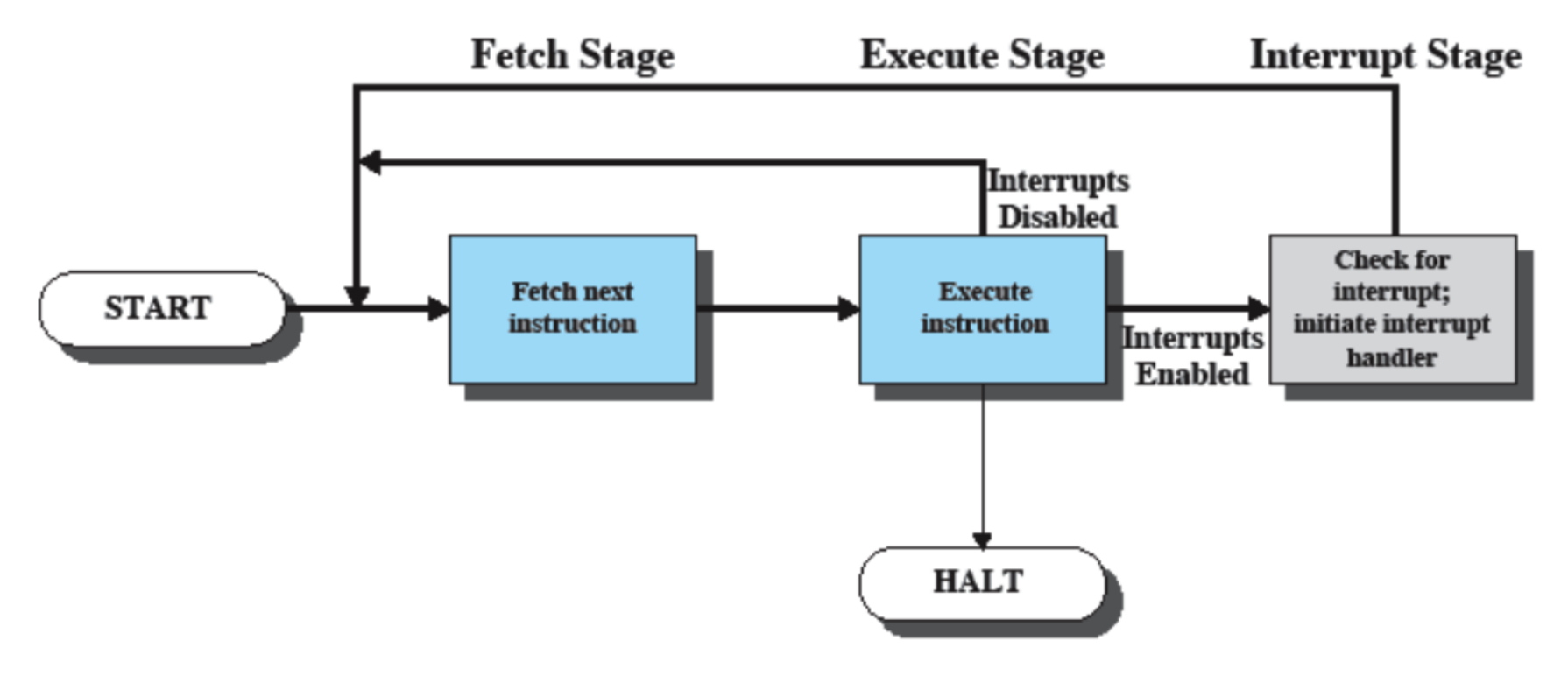
Quindi eseguiamo il fetch normalmente, dopo l’execute però nel caso in cui le interrupt sono abilitate viene anche controllato se l’operazione ne genera uno oppure se ne arriva uno da un’operazione precedente, se è presente viene eseguito l’handler corrispondente.
Interrupt Handler
Come detto prima è una funzione presente nel Sistema Operativo e non prevista nel codice scritto dallo sviluppatore.
Quando viene eseguito l’handler, il Sistema Operativo e l’Hardware collaborano per memorizzare program counter e registro di stato in modo da poterci tornare successivamente, se possibile.
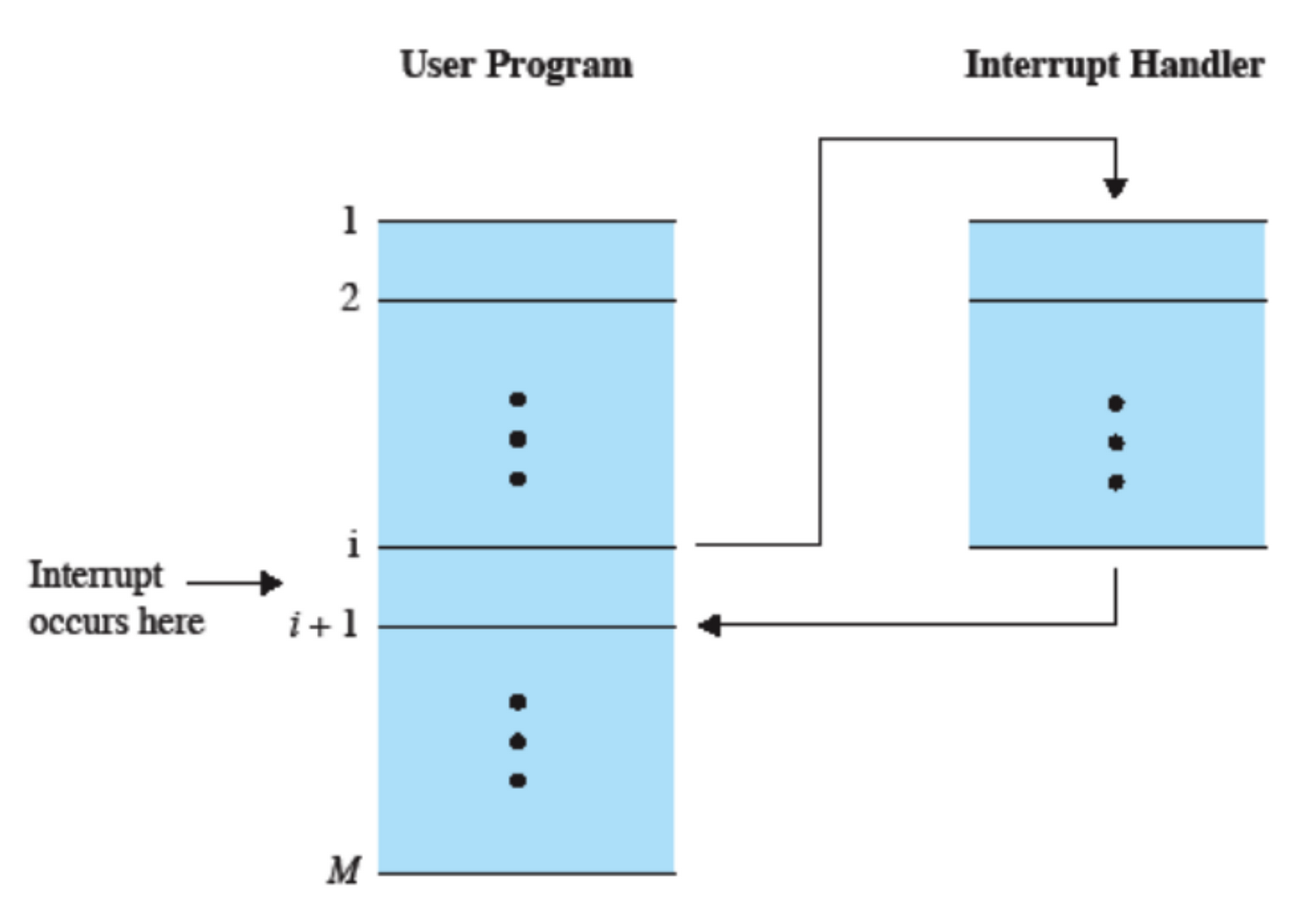
Questo è quello che succede in generale quando viene eseguito un handler.
Nello specifico:
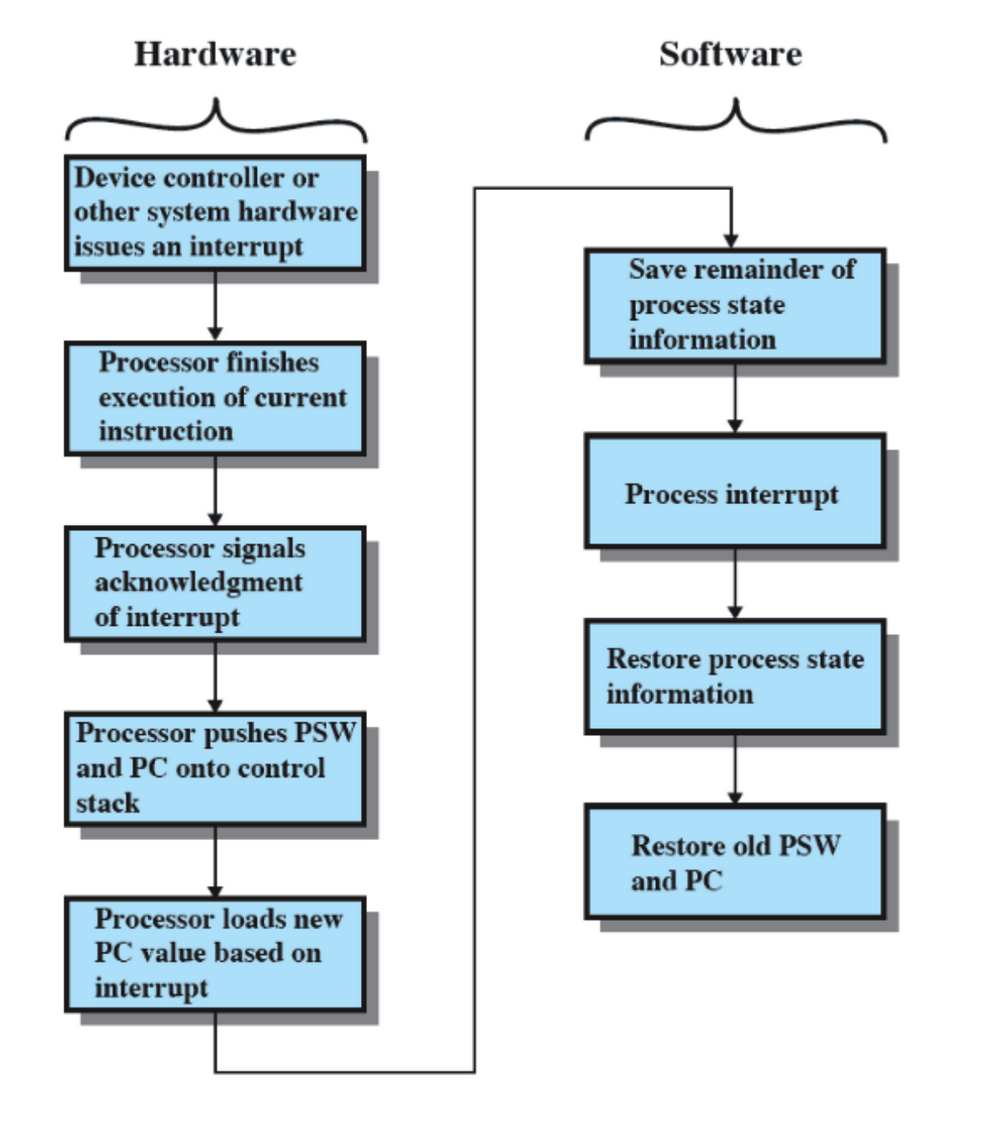
Hardware
- Un dispositivo solleva un’interruzione.
- Il processore finisce l’esecuzione dell’istruzione corrente.
- Segnala che “è a conoscenza” dell’interruzione.
- Salva alcune informazioni, PSW (registri di controllo) e PC, nel Control Stack.
- Carica nel PC il valore per eseguire le istruzione dell’handler.
Software
- Salva tutti i registri della CPU in un opportuno stack.
- Esegue le opportune istruzioni.
- Prende i registri salvati in memoria e li sposta negli opportuni registri di appartenenza.
- Riporta al valore originario anche PSW e PC.
È possibile anche spegnere gli interrupt per togliere la fase di controllo di questi dalla CPU, vengono comunque sollevati e quindi non gestiti.
Ci possono essere anche interrupt annidati, per alcuni interrupt particolari però l’hardware forza il sequenziamento.
I/O con Interrupt
Come visto prima, i controller per i dispositivi I/O sono più lenti del processore e vengono gestiti tramite interrupt.
Prima venivano gestiti in modo sequenziale, quindi quando c’era bisogno di un dispositivo esterno, il processore non svolgeva altre operazioni e aspettava che il dispositivo fosse pronto, con il tempo si è capito che questo metodo portava ad attese inutili.
Come vengono gestiti adesso gli I/O, ovvero con le interruzioni:
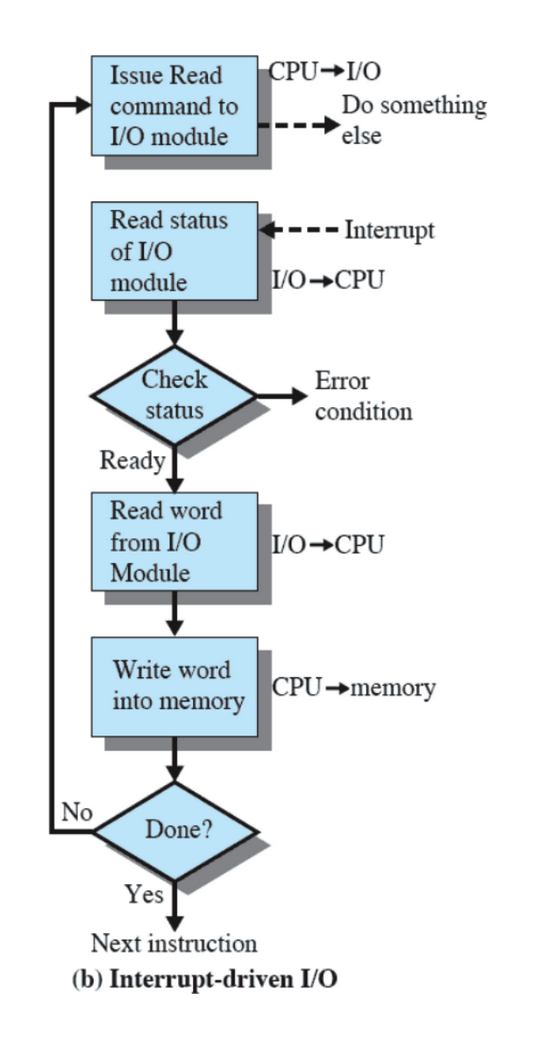
La CPU manda un avviso al dispositivo, mentre il dispositivo si prepara la CPU può fare altro, nel momento in cui il dispositivo è pronto viene mandato un interrupt che fa capire alla CPU che è possibile usare quel dispositivo.
Un passo che rallenta questo metodo è la copia dei dati, infatti il dato preso dal dispositivo prima di andare in memoria deve passare per la CPU.
Infatti in alcuni casi anche questo metodo presenta delle attese:
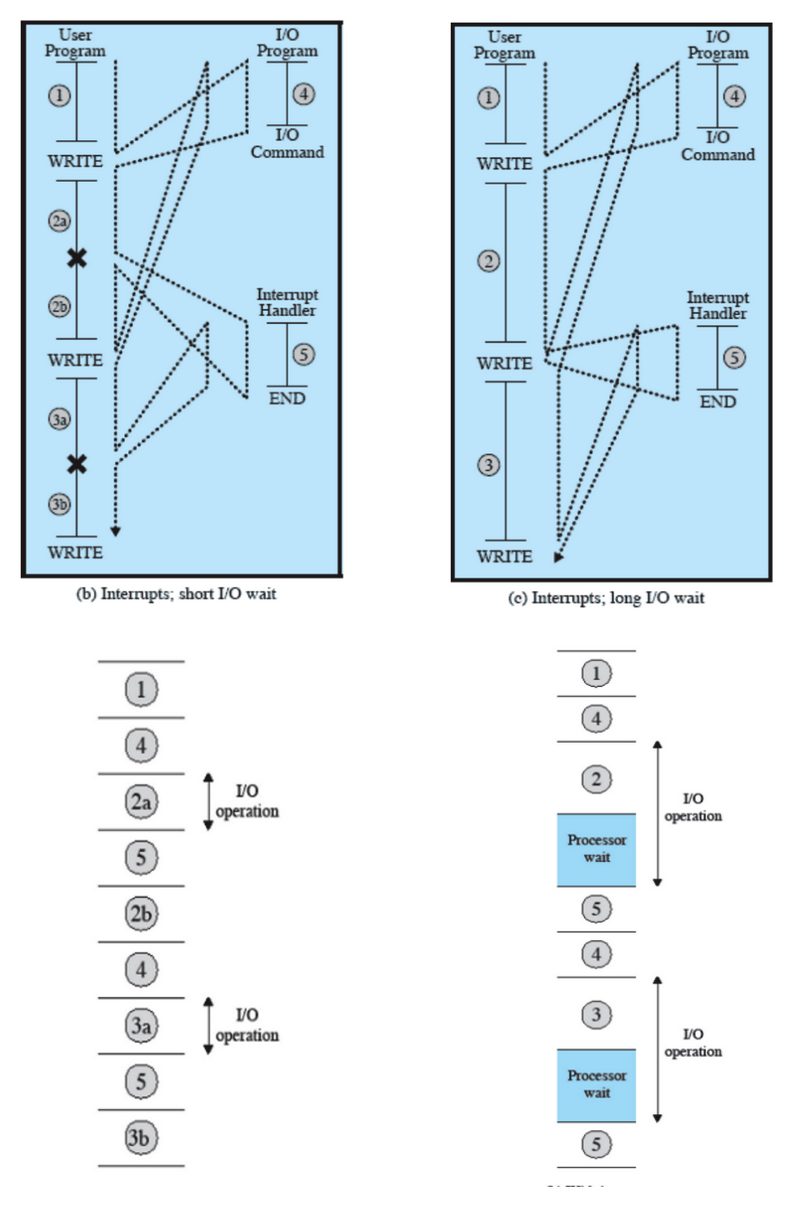
Nel caso di sinistra non ci sono attese dato che tra una scrittura e un’altra il dispositivo è pronto e le completa, nel caso di destra la prima scrittura non è finita e intanto ne viene inviata una seconda, in questo caso il processore deve aspettare che finisca la prima.
Non abbiamo risolto completamente il problema.
Accesso Diretto in Memoria (DMA)
Con questo metodo i dispositivi I/O non hanno più bisogno della CPU come tramite ma possono entrare direttamente in memoria. Quindi utilizziamo comunque gli interrupt ma una volta che questo arriva la CPU non deve gestire nulla perché il trasferimento è già finito.
È molto efficiente ma non risolve comunque completamente il problema.
Multiprogrammazione
Per riempire quelle attese inutili e far svolgere più lavoro possibile nello stesso momento al processore è stato pensato di fargli svolgere più programmi contemporaneamente.
La sequenza con cui questi vengono eseguiti dipende dalla loro priorità e dal fatto che siano in attesa di altre operazioni. In questo modo alla fine della gestione di un’interruzione il programma potrebbe non tornare all’istruzione successiva a dove è stata generata l’interruzione.
Gerarchia della Memoria
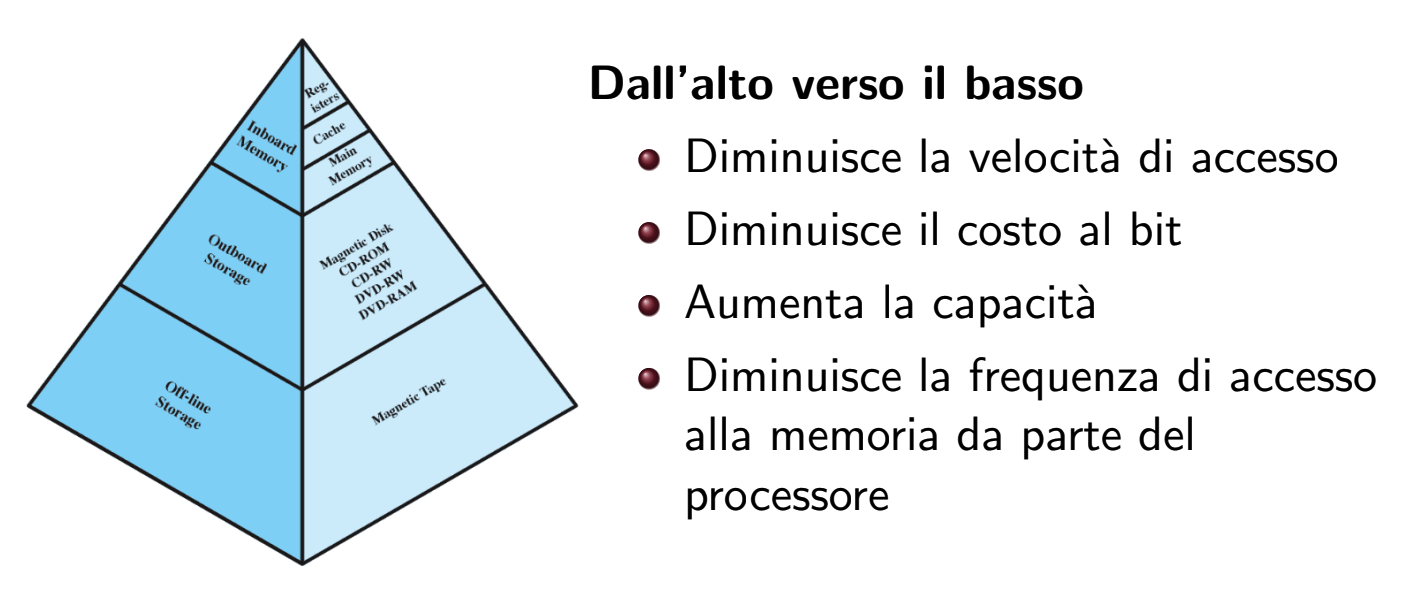
- Inboard Memory: Si trova sui componenti interni del Computer ne fanno parte Registri, Cache e RAM. Tutte queste memorie sono volatili.
- Outboard Memory: Sono ad esempio i dispositivi di memoria esterni.
- Off-line Storage: Dispositivi scollegati dal Computer stesso.
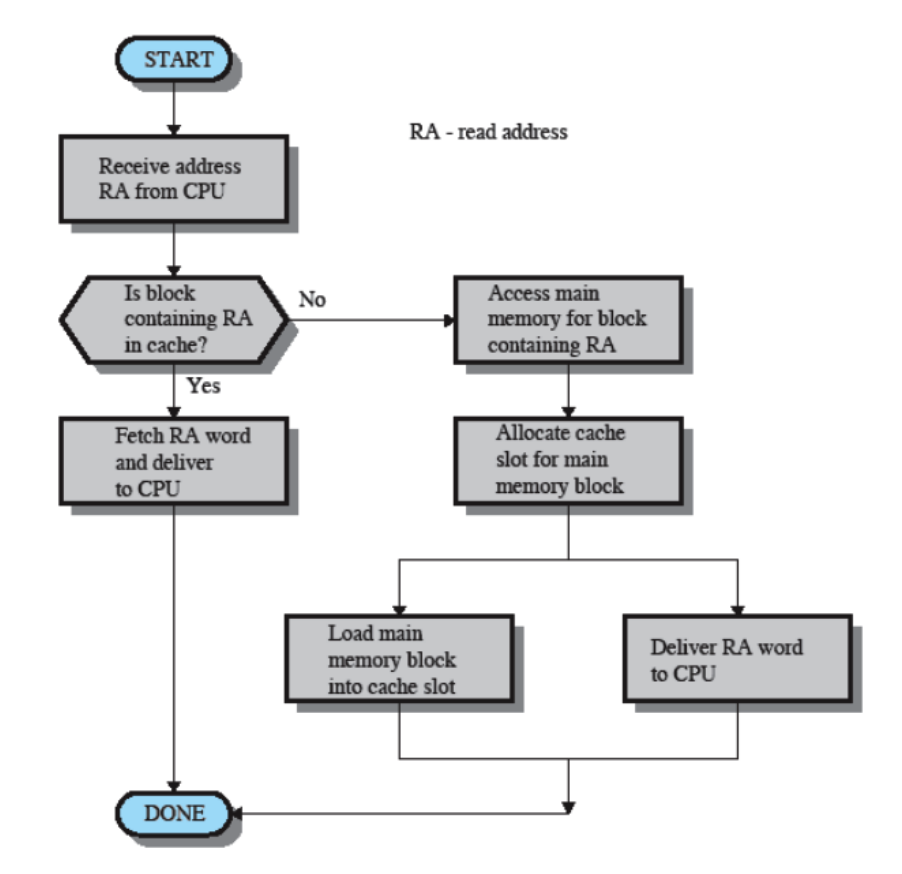
Cache
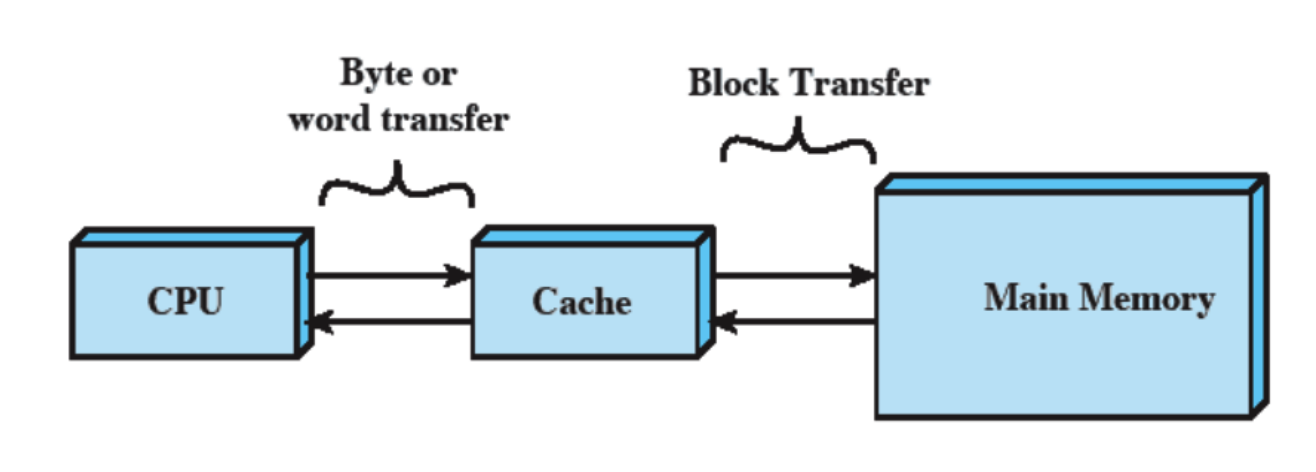
La cache contiene alcune porzioni della RAM, la CPU prima di andare a prendere un dato dalla RAM controlla se è presente nella Cache, se è presente siamo stati fortunati altrimenti lo andiamo a prendere in RAM e scriviamo quella porzione nella Cache, questo perché è molto probabile che questo dato (o uno molto vicino a lui) ci riservirà tra poco (località dei riferimenti).
La Cache è invisibile ai programmatori (anche in assembler) e non la vede quindi nemmeno il compilatore e questo significa che non la vede il Sistema Operativo anche se può decidere di non usarla, inoltre alcune parti del S.O. imitano il funzionamento di questa.
La Cache è quindi gestita completamente dall’Hardware tramite dei circuiti.
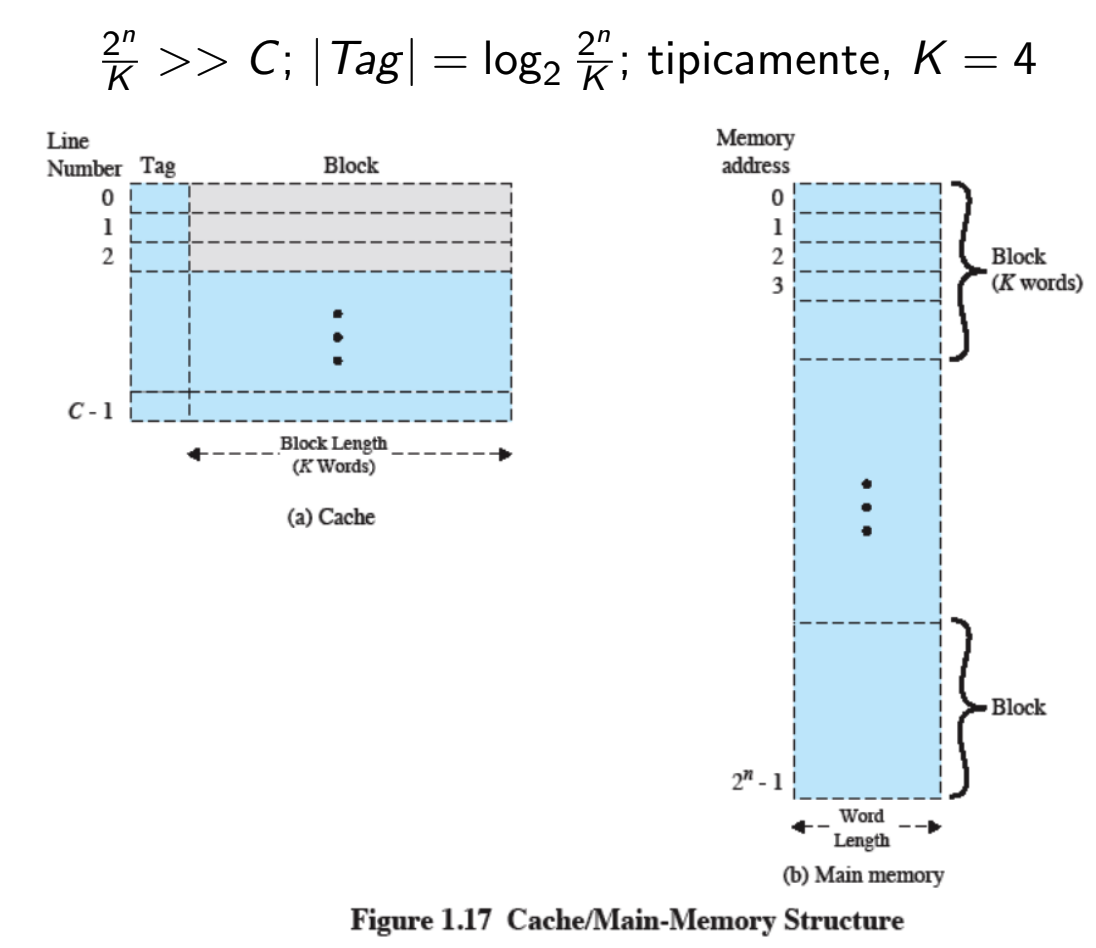
Quindi date locazioni di memoria RAM le dividiamo per ovvero il numero di word in un blocco e otteniamo un numero molto più grande rispetto alla grandezza C della Cache.
Il Tag quindi deve essere grande a sufficienza per coprire tutti i blocchi.
Schema Funzionamento:
- Capacità della Cache: Anche con cache molto piccole diminuiamo di molto gli accessi in RAM.
- Ma c’è da considerare anche la grandezza dei blocchi: Con blocchi molto grandi ho molte possibilità di trovare i dati in cache ma incrementarli troppo è controproducente infatti saranno di più anche i dati da sovrascrivere quando non troviamo qualche dato.
Dobbiamo trovare un giusto equilibrio.
Nozioni sulla Cache
-
Funzione di Mappatura: Determina in che locazione della cache va messo un determinato blocco di memoria.
-
Algoritmo di Rimpiazzamento: Determina in che modo scegliere quale blocco va rimpiazzato in caso serva, tipicamente si usa l’algoritmo LRU (Least Recently Used) che rimpiazza il blocco usato meno recentemente ovvero il più vecchio presente in Cache.
-
Politica di Scrittura: Quando vogliamo scrivere un dato in RAM abbiamo più strade, mettiamo caso che il dato è stato scritto in Cache, adesso lo scriviamo anche in RAM? Se si stiamo utilizzando un Write-Through ovvero ogni modifica che avviene in Cache avviene anche in RAM.
Altrimenti stiamo utilizzando il Write-Back, scriviamo il dato in Cache ma non in RAM perché se successivamente dobbiamo leggerlo lo leggeremo dalla cache e quindi non c’è bisogno di averlo in RAM. Lo scriviamo solo in caso di rimpiazzi su quel blocco, altrimenti perdiamo lo stato aggiornato. In questo modo la memoria potrebbe trovarsi in uno stato “obsoleto” ma è sicuramente più efficiente del Write-Through.
Esempio più complesso

Il processore ha più processori interni, e ogni processore ha diverse cache (L1, L2, L3 ma questa è in comune fra tutti) salendo di numero diventano più grandi e più lente, quindi si controlla in ordine L1 → L2 → L3 → RAM.
- L1: Sono due cache, una per istruzione e un’altra per il resto dei dati.
- L2 e L3: Sono sempre 2 ciascuna ma contengono qualsiasi tipo di dato.
Come detto prima il S.O. può spegnere il caching e inoltre può decidere la politica di scrittura, ad esempio Linux non la spegne mai e utilizza sempre write-back.
Strati e Utenti
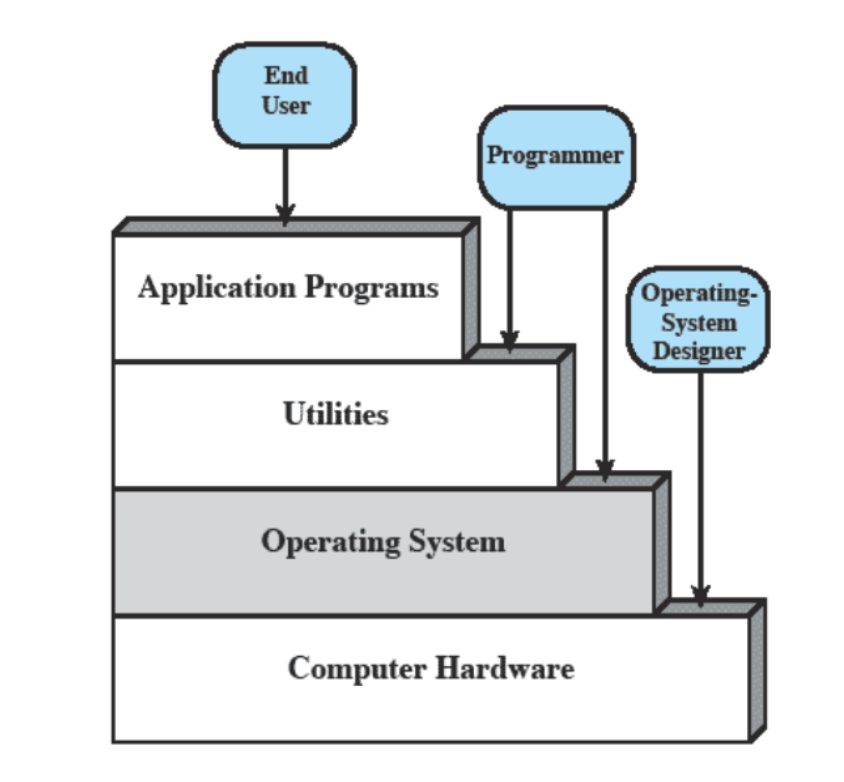
Quindi un utente “non sviluppatore” usa semplicemente le applicazioni, un programmatore si basa principalmente sulle utilities e sul Sistema Operativo mentre chi scrive il S.O. si basa sulle specifiche Hardware.
Nello specifico quali servizi ci offre il S.O.?
- Esecuzione di programmi anche in contemporanea.
- Accesso ai dispositivi I/O.
- Accesso al Sistema Operativo stesso tramite shell.
- Sviluppo di Programmi quindi compilatori, syscalls, debugger ecc…
- Rilevamento e reazione ad errori hardware / software.
- Accounting ovvero una collezione di statistiche di sistema e monitoraggio delle risorse. Viene utilizzato per capire cosa migliorare.
In sostanza quindi il Sistema Operativo è un programma ma che gestisce il funzionamento degli altri programmi, prepara i loro ambienti, li manda in esecuzione, gestisce errori. È un’interfaccia tra hardware e software.
Infatti è un normale programma in esecuzione con il suo ciclo di fetch / execute ma ha privilegi più alti, in alcuni casi può passare questi privilegi ad altri programmi.
Kernel
Una parte del Sistema Operativo in codice macchina è racchiusa tutta insieme in una parte della RAM (solitamente quella iniziale), e serve appunto per eseguirlo. Questa parte si chiama kernel che significa nucleo infatti è la più importante dato che è sempre pronta in RAM.
Evoluzione dei Sistemi Operativi
I S.O. esistevano dagli anni 40 ed erano molto diversi da quelli di adesso, è importante vedere alcune tappe evolutive per capire i moderni sistemi.
Le evoluzione sono dovute principalmente a:
- Aggiornamenti Hardware
- Nuovi servizi
- Correzione di errori
Anni Quaranta
Non c’era nessun Sistema Operativo e per fornire comandi ad un computer si usavano delle speciali console con interruttori, i computer arrivavano a occupare intere stanze.
Il metodo di input venne presto migliorato grazie alle schede perforate:
In ogni caso i sistemi erano interamente sequenziali quindi potevano svolgere un calcolo alla volta e non essendoci un S.O. i programmi utente gestivano da soli gli input e gli output.
Anni Cinquanta / Sessanta
Si mettono insieme più programmi da eseguire (prendono il nome di jobs) e il primo sistema operativo serviva a gestire questi jobs, questo metodo funzionava molto bene in sistemi non interattivi chiamati batch, questi sistemi appunto vogliono solo un dato in input e poi l’utente deve soltanto aspettare la fine dei calcoli.
Questi sistemi mostrarono le prime problematiche:
- Protezione della memoria: ad esempio se un job andava a scrivere nella zona della memoria del controllore dei jobs, questa parte non doveva essere accessibile.
- Timer: Impedisce che un job blocchi l’intero sistema per essere eseguito, infatti alcuni di questi impiegavano anche giorni per essere eseguiti.
- Istruzioni Privilegiate: Ad esempio il sistema di controllo dei jobs doveva essere eseguito con dei privilegi più alti, infatti lui può accedere a quella zona di memoria.
Quindi i job venivano eseguiti in modalità utente (numero limitato di istruzioni) mentre il monitor dei job in modalità sistema (possono essere eseguite più istruzioni e possiamo accedere a zone di memoria protette).
C’era un problema molto importante:
-
Più del 96% del tempo è sprecato ad aspettare i dispositivi I/O

Come possiamo vedere dei 31 microsecondi soltanto 1 è lavoro effettivo della CPU gli altri 30 sono attesa di I/O.
Quindi prima veniva eseguita una programmazione singola ovvero un’operazione per volta con tante attese. Si passa alla multiprogrammazione.
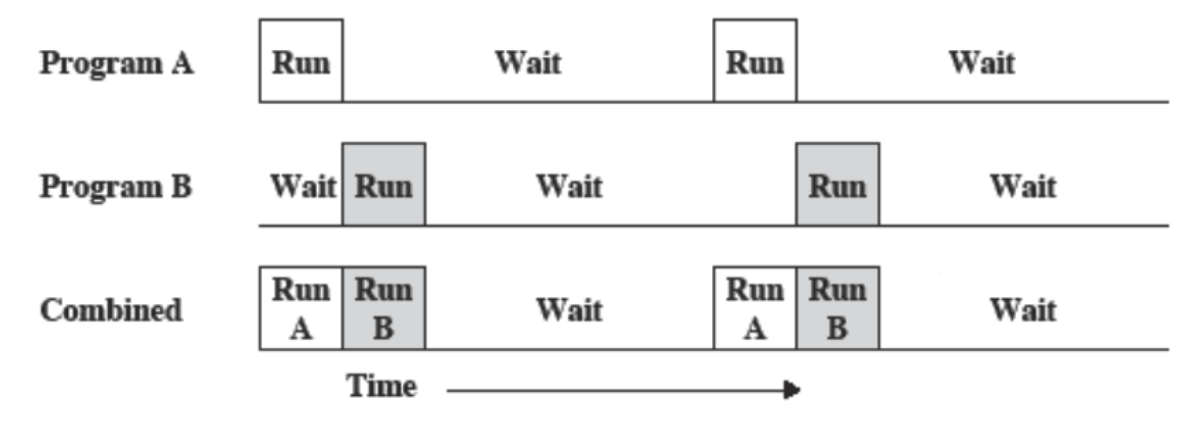
Quindi ci sono più programmi in esecuzione e durante l’attesa di uno ne viene svolto un altro, ci sono comunque attese ma molte di meno.
Esempio
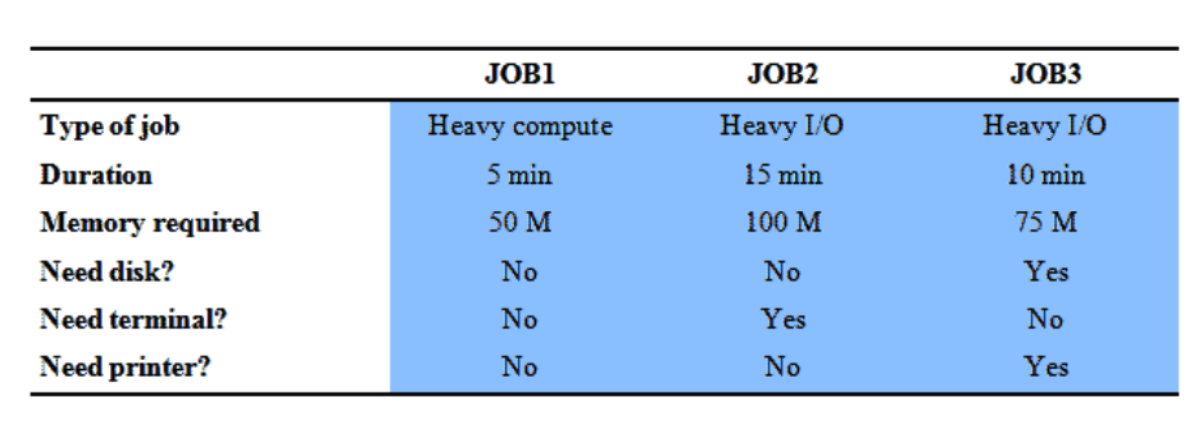
Prendiamo questi 3 jobs, il primo è molto incentrato sulla CPU e dura 5 minuti mentre gli altri due utilizzano molto I/O e durano 15 e 10 minuti, vediamo cosa succede in entrambi i tipi di programmazione:
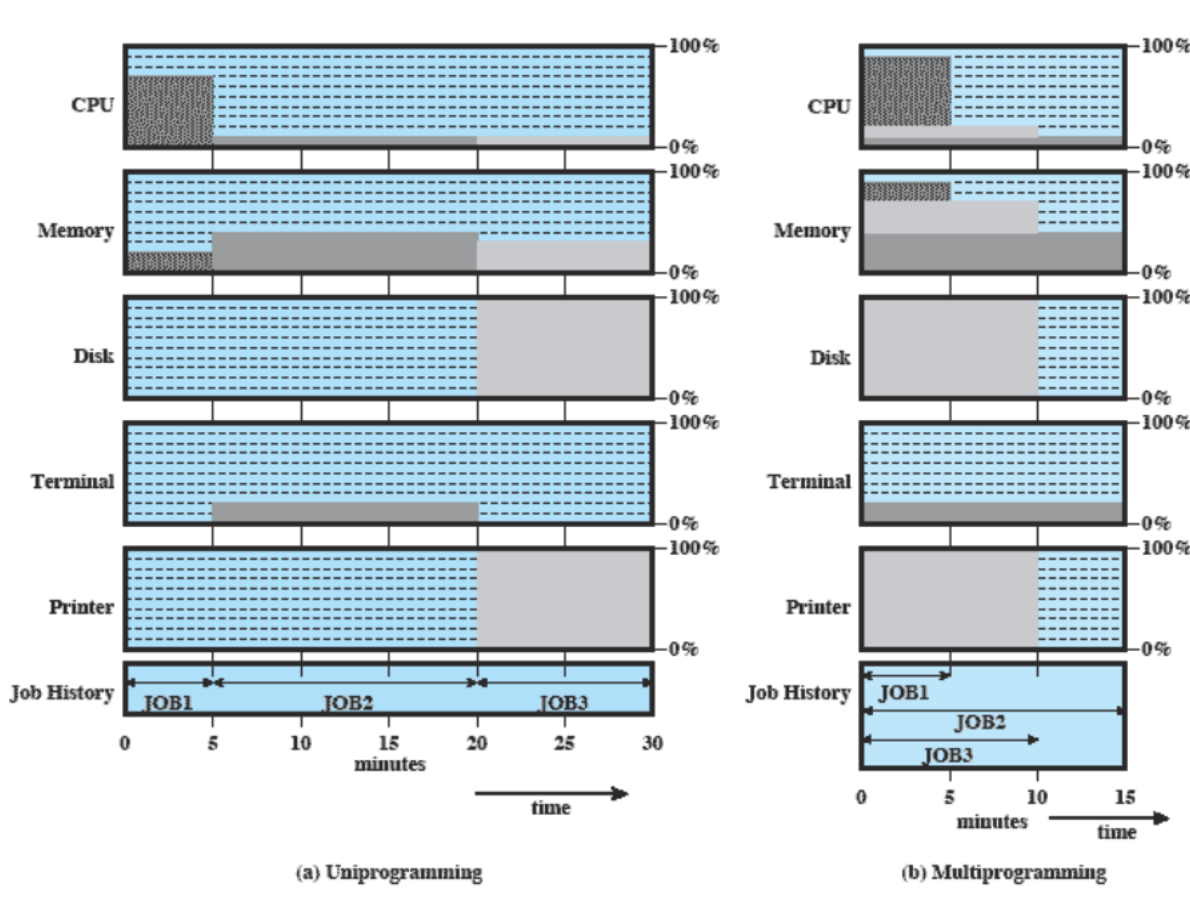
A sinistra abbiamo programmazione singola e quindi impieghiamo 30 minuti (1 job dietro l’altro) e un utilizzo non gestito molto bene delle risorse.
Nella multiprogrammazione invece eseguiamo tutti i job insieme, infatti job1 utilizza soltanto CPU e nessun dispositivo mentre gli altri 2 utilizzano dispositivi diversi e quindi possono essere eseguiti tutti contemporaneamente, ne impieghiamo soltanto 15, ovvero quello con il tempo massimo.
Come statistiche otteniamo:

Throughput: Mean Response Time: Media dei tempi di completamento. Nel caso di uniprogramming dobbiamo considerare che job1 = 5, job2 = job1 + 15 e job3 = job2 + 10, quindi (5 + 20 + 30) / 3
Ovviamente questo è un esempio un po’ estremo.
Sistemi Time Sharing
Dagli anni 70 era necessario gestire più jobs interattivi da parte di più utenti, il tempo del processore veniva gestito fra più utenti (da qui Time Sharing).

Quindi in un sistema Batch vogliamo vedere l’utilizzo della CPU con meno tempi morti possibile mentre nel Time Sharing vogliamo che quando un utente da un comando nel terminale debba attendere il minor tempo possibile per ottenere la risposta.
Nel primo caso veniva utilizzato un Job Control Language mentre nel secondo dei comandi dati da terminale gestiti dal S.O.
Ricapitolando:
- Computazione Seriale (Anni Quaranta)
- Sistema non interattivo / batch (Anni Cinquanta / Sessanta), introdotta la multiprogrammazione
- Time - Sharing (Anni Settanta), job principalmente interattivi
Questa evoluzione porta a degli sviluppi molto interessanti:
- Il concetto di processi
- Gestione della Memoria
- Sicurezza e protezione delle informazioni, dato che molti utenti potevano accedere ai dati.
- Scheduling delle risorse, decidere quale job eseguire in un determinato momento.
- Strutturazione del Sistema, scrivere il codice in moduli ben organizzati.
Dal Job al Processo
Il processo racchiude in un solo concetto job interattivo e non interattivo.
Inoltre incorpora anche un altro tipo di job, quello transazionale real-time, ad esempio un sito per acquistare biglietti deve gestire il caso in cui due persone comprano nello stesso momento lo stesso posto per lo stesso giorno alla stessa ora.
Ogni processo è caratterizzato da:
- Thread di esecuzione ovvero il flusso del processo, ce ne possono essere più di uno.
- Uno stato corrente.
- Un insieme di risorse di sistema associate.
Tutto questo a portato dei problemi per chi scriveva sistemi operativi:
- Errori di sincronizzazione: alcuni interrupt si perdono o vengono ricevuti più volte.
- Violazione della mutua esclusione: Se 2 processi vogliono accedere alla stessa risorsa possono verificarsi problemi.
- Programmi con esecuzione non deterministica: Un programma accede ad una zona di memoria modificata da un altro processo.
- Deadlock (stallo): Più processi attendono l’esecuzione di altri processi in “loop”, ad esempio A sta aspettando B e B sta aspettando A, nessun processo inizia l’esecuzione.
Gestione della Memoria
- I processi andavano isolati, ovvero dovevano accedere a diverse zone di memoria senza andare in conflitto.
- Supporto per la programmazione modulare (stack), è quello che permette a noi programmatori di scrivere delle funzioni all’interno del codice.
- Allocazione e Deallocazione automatica
- Tutto questo viene gestito tramite Paginazione e Memoria Virtuale.
Sicurezza
- Protezione dai DoS (Denial of Service), interruzione del servizio.
- Confidenzialità, gli utenti devono accedere soltanto ai dati per i quali hanno il permesso di lettura / scrittura.
- Integrità: Protezione da modifiche non autorizzate.
- Autenticità: Verificare l’identità degli utenti.
Gestione delle Risorse
Il S.O. in tutto questo deve garantire:
- Equità: dare accesso alle risorse in modo equo.
- Velocità di risposta differenziate: alcuni processi hanno maggiore priorità.
- Efficienza: Massimizzare l’uso delle risorse nel tempo (throughput), minimizzare il tempo di risposta e servire più utenti possibili.
Elementi Principali
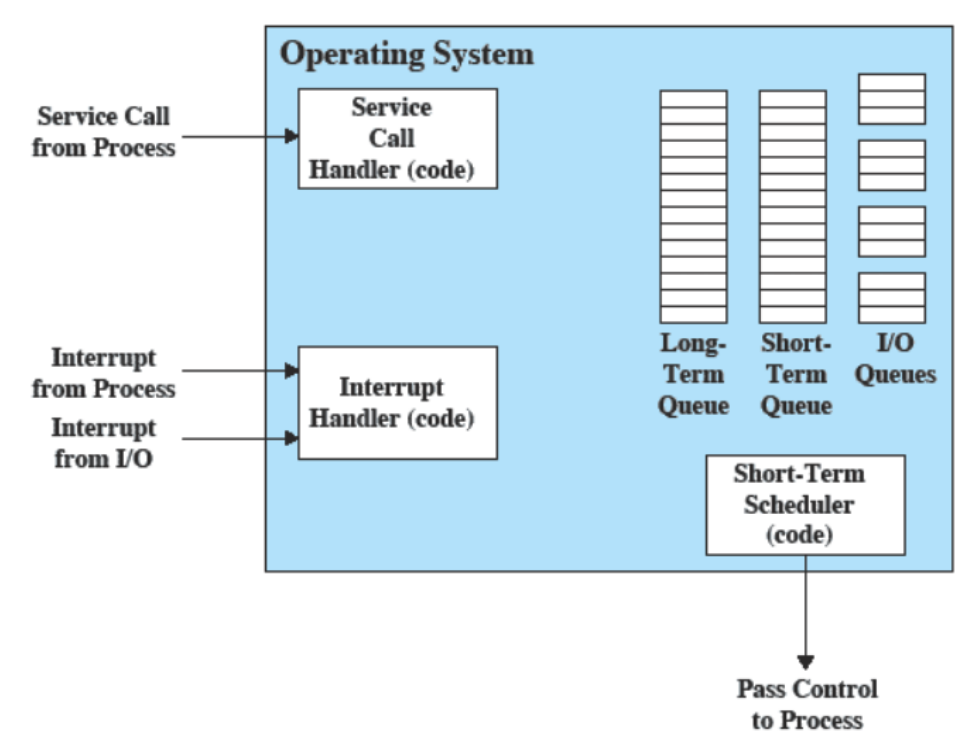
Struttura del Sistema Operativo
Da subito si è capito che non conveniva mettere tutto “a caso”, infatti è stato diviso in una serie di livelli, dove ogni livello effettua un sottoinsieme delle funzioni di sistema.
Ogni livello si basa su quello più sotto, ad esempio il livello 4 può richiedere un’operazione al 5 ma non al 3.
- Livello 1:
- Circuiti elettrici
- Registri, celle di memoria, porte logiche
- Operazioni come reset di un registro o leggere in una locazione di memoria
- Livello 2:
- Insieme delle istruzioni macchina come add, sub, load, store.
- Livello 3:
- Aggiunge il concetto di routine, operazioni di chiamata e ritorno.
- Livello 4:
- Interruzioni.
- Livello 5:
- Processo come programma in esecuzione.
- Sospensione e ripresa di un processo.
- Livello 6:
- Dispositivi di memorizzazione secondaria
- Trasferimento di blocchi di dati
- Livello 7:
- Crea uno spazio logico degli indirizzi per i processi.
- Organizza lo spazio degli indirizzi virtuali in blocchi
- Livello 8:
- Comunicazioni fra processi
- Livello 9:
- Salvataggio di file a lungo termine
- Livello 10:
- Accesso a dispositivi esterni con interfacce standard
- Livello 11:
- Associazione tra identificatori interni ed esterni
- Livello 12:
- Supporto di alto livello per i processi
- Livello 13:
- Interfaccia utente
Architettura UNIX
Kernel Moderno:
Solo per info.
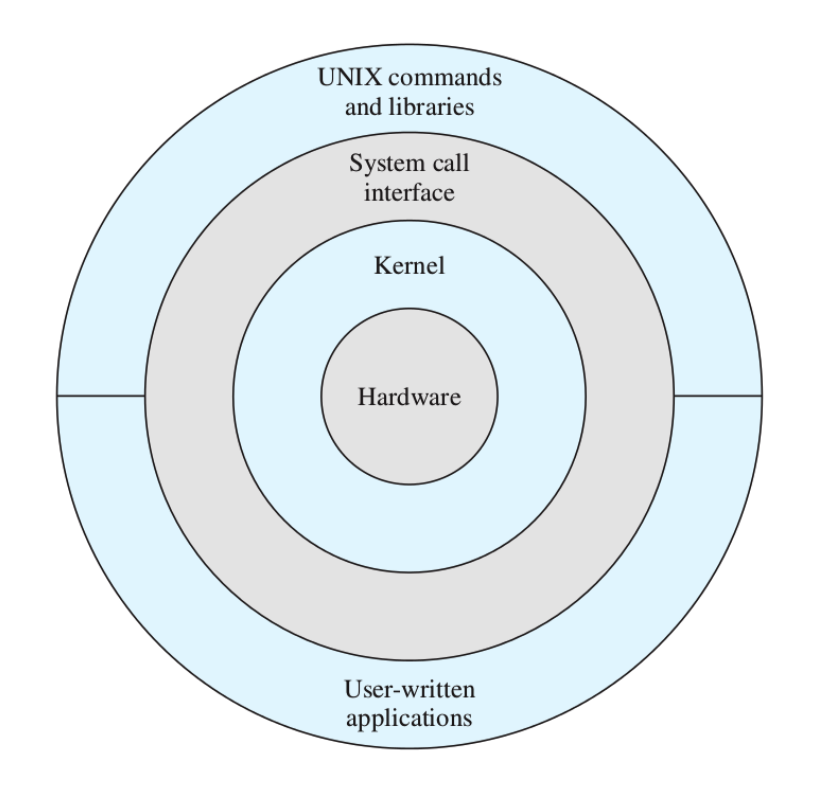
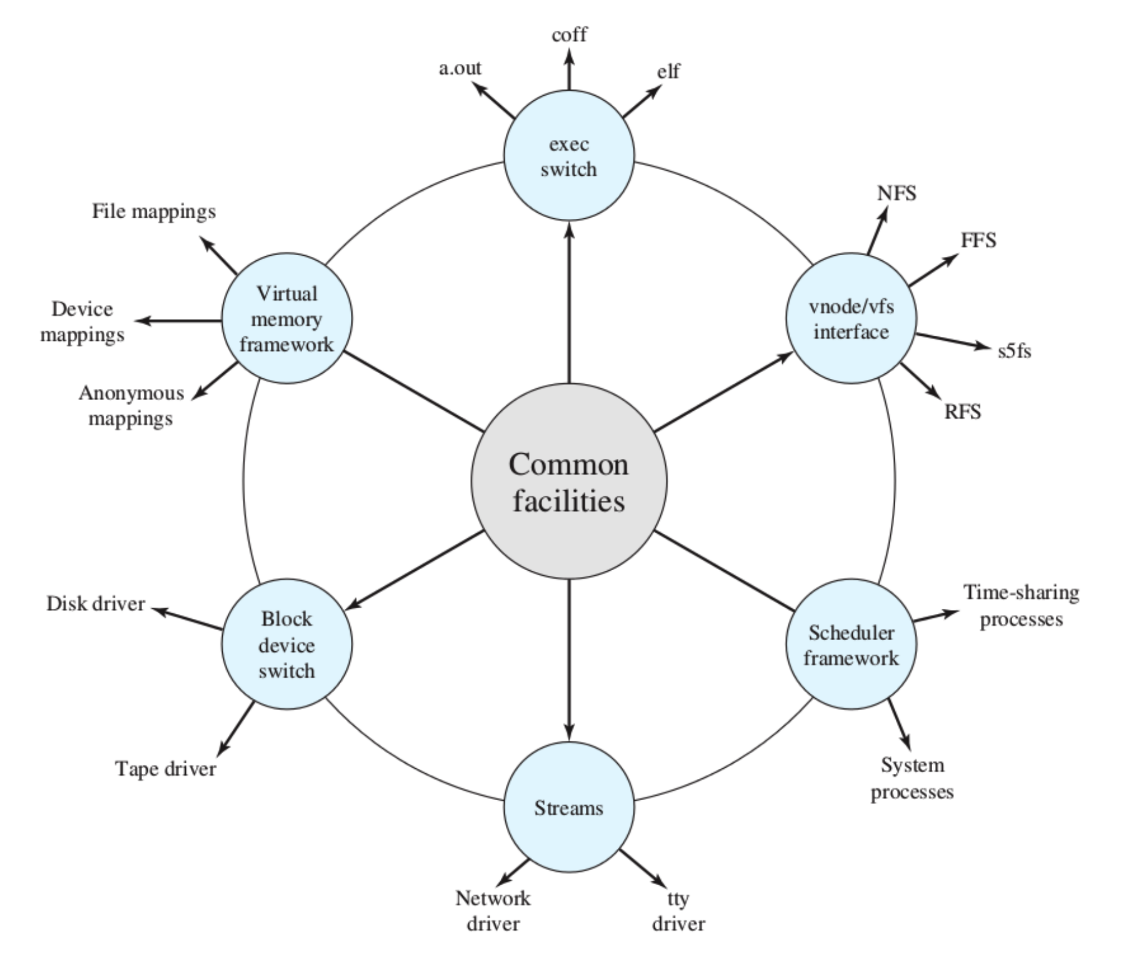
Kernel Moderno di Linux
I moderni kernel sono monolitici o microkernel:
- monolitico: Tutto il sistema operativo viene caricato in RAM all’accensione.
- microkernel: Solo una minima parte del S.O. viene caricato in RAM e il resto solo quando serve.
- Sempre in memoria: scheduler, sincronizazzione.
- Solo a richiesta: gestore memoria, filesystem, driver.
- Il monolitico è più efficiente in velocità ma ovviamente occupa più memoria RAM.
Quasi tutti i sistemi moderni sono a kernel monolitico ad eccezione di MacOS.
Linux invece è principalmente monolitico ma ha dei moduli:
- Alcune parti del sistema operativo possono essere caricate solo quando servono, la differenza è che in Linux cosa serve e cosa no lo decide l’utente e non il S.O.
- Le cose che Linux non carica sono vari filesystem che non gestisce, driver per alcuni dispositivi, funzionalità di rete.
I Processi
Il compito fondamentale del Sistema Operativo è quello di gestire i processi, infatti ogni tipo di computazione può essere vista come processo.
Il Sistema Operativo deve:
- Permettere l’esecuzione di processi multipli in modo alternato, interleaving.
- Assegnare risorse ai processi, come stampante, schermo, schede di rete, e inoltre proteggere da altri processi l’accesso a queste risorse.
- Permettere lo scambio di informazioni tra processi.
- Permettere la sincronizzazione tra processi.
Che cos'è un processo?
In modo semplice è un programma in esecuzione, ovvero quando un utente richiede la computazione svolta da quel programma. Possiamo definirlo anche in altri modi, ad esempio un processo è un’istanza di un programma in esecuzione, e per alcuni programmi possiamo avere anche più istanze, ovvero più processi. Ogni istanza viene assegnata ad un processore per l’esecuzione. Ogni processo è caratterizzato da:
- Codice ovvero una sequenza di istruzioni
- Un insieme di dati
- Un numero di attributi che descrivono lo stato del processo
- Alcuni hanno anche delle risorse associate (stampante, rete, ecc…)
Per adesso quando ci riferiamo ad un “programma in esecuzione” significa che un utente ha richiesto la sua esecuzione e che il programma non è ancora terminato, diciamo per adesso dato che più avanti vedremo altri casi di programmi in esecuzione.
Questo non significa necessariamente che il processo è in esecuzione su un processore, ovvero dal momento in cui inizia fino al momento in cui termina, non è detto che sia sempre in esecuzione e molto spesso non è così; decidere quando mandare in esecuzione un processo sul processore abbiamo visto essere un ruolo fondamentale del Sistema Operativo.
Dietro ad ogni processo c’è un programma:
- Nei moderni S.O. di solito è memorizzato sul disco rigido.
- Solo eseguendo un programma possiamo creare un processo ed eseguendo un programma creiamo almeno un processo.
- Possono far eccezione a queste regole alcuni dei processi creati dal sistema operativo, questi non sono presenti nella memoria di massa ma nel kernel.
Fasi di un Processo
Un processo ha 3 macro-fasi, creazione, esecuzione, terminazione:
- La terminazione può essere prevista
- Un programma svolge dei calcoli e alla fine dell’ultima operazione si termina.
- Un programma viene terminato quando l’utente preme sulla “X” della finestra.
- Se l’utente non lo chiude, potrebbe anche rimanere per sempre in esecuzione.
- Non prevista
- Il processo esegue un’operazione non consentita, viene generata un’eccezione che può portare alla chiusura forzata da parte del sistema operativo.
- Da notare che la terminazione non è detto che sia sempre presente.
Elementi di un Processo
Finché il processo è in esecuzione, ad esso sono associate delle informazioni:
- Identificatore, uno per ogni processo.
- Stato (esecuzione o anche altri).
- Priorità, sarà utile per lo scheduling.
- Hardware Context: È la situazione attuale dei registri della CPU, cioè i loro valori, fra questi è presente ad esempio il Program Counter.
- Puntatori alla memoria RAM usata da questo processo, questa porzione prende il nome di immagine del processo.
- Informazioni sullo stato input / output.
- Informazioni di accounting, chi sta usando il processo.
Ma come sono organizzate queste informazioni?
Per ogni processo c’è un Process Control Block, questo contiene le informazioni viste prime e viene mantenuto nella zona di memoria riservata al kernel, questo significa quindi che nessun processo deve poter accedere a questa zona ma soltanto il Sistema Operativo.
Questo Process Control Block quindi viene creato e gestito dal sistema operativo e permette a quest’ultimo di gestire più processi contemporaneamente, dato che il blocco contiene sufficienti informazioni per bloccare l’esecuzione di un programma e farla riprendere più avanti sempre nello stesso punto in cui era stata fermata.
Trace di un processo
Il comportamento di un processo dipende dalle istruzioni che esegue, questa sequenza di istruzioni è detta trace ovvero traccia del processo.
Dispatcher
Il Dispatcher è un programma presente nel kernel che attraverso dei calcoli che vedremo più avanti decide quando sospendere un processo per mandarne in esecuzione un altro. Questo è presente sempre in memoria anche in sistemi microkernel.
Esecuzione di un Processo
Si considerino 3 processi in esecuzione, quindi sono tutti presenti in memoria, ignoriamo la memoria virtuale:
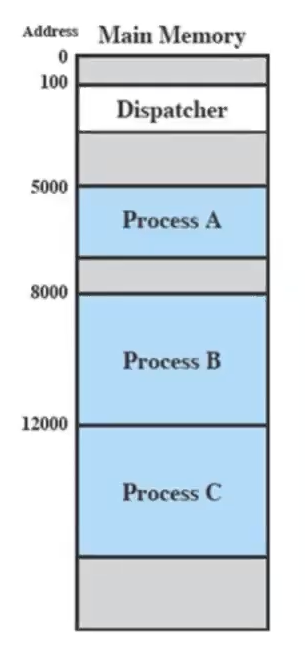
Dal punto di vista di ciascuno dei processi, ognuno viene eseguito senza interruzioni fino al termine:

Adesso supponendo che su questo sistema ci sia soltanto un processo, in realtà i processi non sono stati eseguiti senza interruzioni:
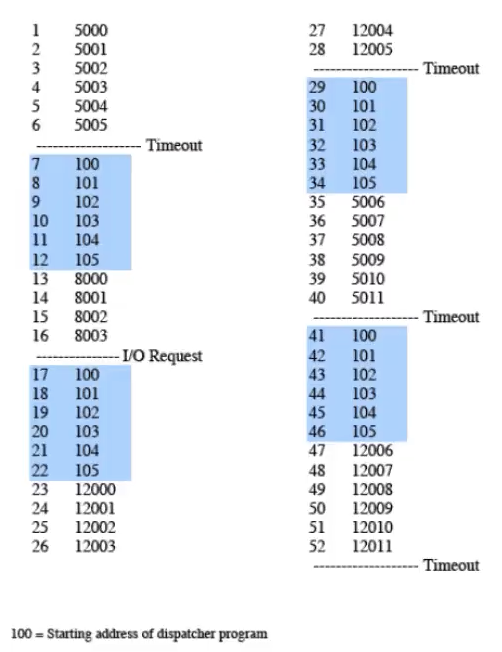
Quindi sono stati eseguiti in ordine: A, Dispatcher, B, Dispatcher, C, Dispatcher, A, Dispatcher, C. Ogni programma è ripartito dall’ultima interruzione.
Il vantaggio è per chi scrive i programmi dato che non devono preoccuparsi di queste interruzioni, infatti per il programma “non esistono”. È ovviamente più difficile costruire un sistema operativo capace di fare ciò.
Modello dei Processi a 2 Stati
Un processo visto in modo molto semplice può trovarsi in due stati:
- In Esecuzione
- Non in Esecuzione (ma comunque “attivo”)
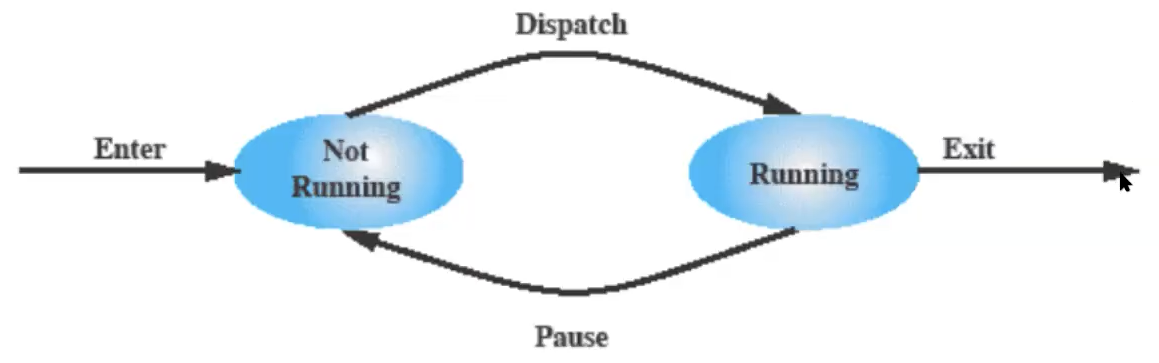
Da notare che un processo appena creato non va subito in esecuzione, deve mandarcelo il Dispatcher.
Se ci fossero soltanto due stati a livello implementativo possiamo vederlo in questo modo:
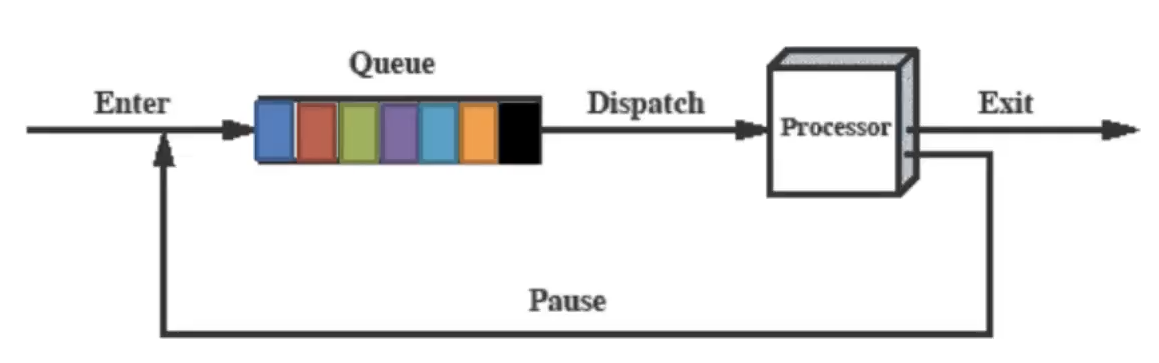
Quindi c’è una coda dei processi non in esecuzione dove il dispatcher prende il processo in cima alla coda e lo mette in esecuzione sul processore e successivamente dalla CPU alla coda, questo ciclo continua finché un processo non finisce (se finisce).
Creazione di Processi
In ogni istante in un sistema operativo c’è sempre almeno 1 processo in esecuzione, infatti come minimo è in esecuzione un gestore dell’interfaccia, che sia grafica o solo testuale.
Se l’utente da un comando, quasi sempre viene creato un nuovo processo, ad esempio clicchiamo con il mouse su un programma oppure tramite un comando.
Process Spawning: Un processo crea un altro processo
Il processo padre è il processo originale ovvero quello che nell’esempio di prima è il gestore dell’interfaccia, mentre il processo figlio è quello nuovo appena creato. Il vecchio processo è comunque in esecuzione e quindi si passa da processi a . Potrebbero anche crearsi più processi figli.
Terminazione di un Processo
Abbiamo visto prima che c’erano più modi di terminazione, nel caso di un normale completamento del processo questo avviene tramite una particolare istruzione macchina che si chiama HALT, questa genera un’interruzione per il S.O.
In linguaggi di programmazione ad alto livello questa viene invocata da system call come exit. Inoltre questa istruzione per terminare il programma di solito viene inserita automaticamente nei compilatori dopo l’ultima istruzione del main del programma.
L’altro caso era una terminazione forzata che chiamiamo uccisioni e possono avvenire:
- Dal S.O. per errori come la terminazione di memoria o altri errori fatali.
- Dall’utente come ad esempio premendo la “X” della finestra.
- Da un altro processo, ad esempio dal terminale uccidiamo un altro processo.
In entrambi i casi sicuramente diminuiamo il numero dei processi, però ci sarà sempre un processo master che non può essere terminato a meno che non si spenga il computer.
Modello dei Processi a 5 Stati
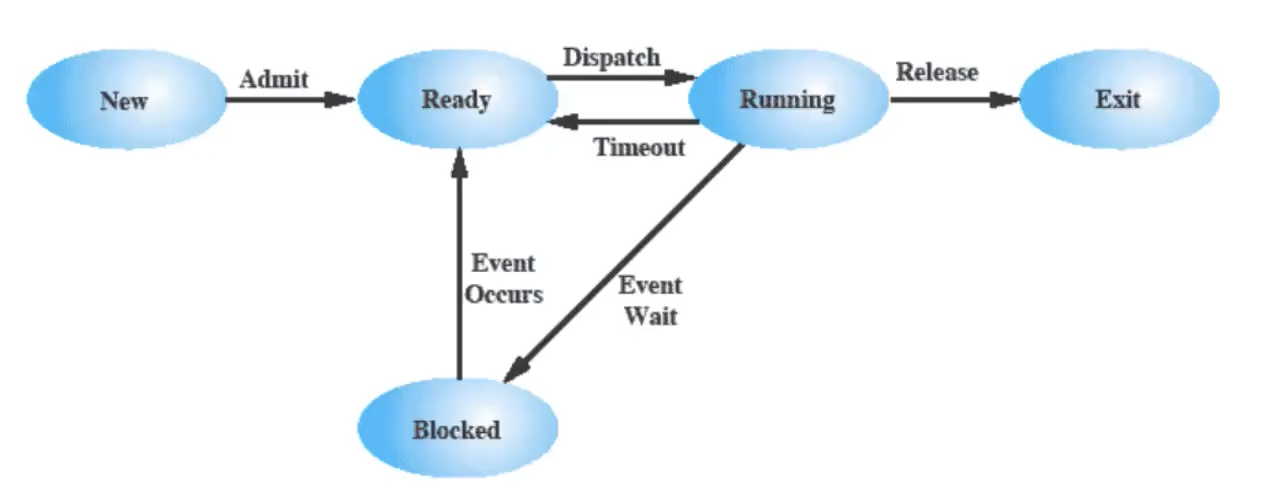
Adesso al posto dello stato not running ne consideriamo altri 2, uno chiamato ready e l’altro blocked, da notare che si potrebbe anche andare da blocked ad exit in alcuni casi di terminazione forzata.
Il funzionamento è molto simile a prima, quindi:
- Appena avviato non va subito in esecuzione ma in Ready.
- Il Dispatcher decide quando mandarlo in Running e anche quando farlo tornare in Ready.
- Come visto prima, se ad esempio un programma deve aspettare un dispositivo I/O allora viene mandato in Blocked cioè in attesa. Dopo che l’attesa è finita il processo torna in Ready.
Per il Dispatcher quindi non avrebbe senso mandare in Running un processo Blocked.
A livello implementativo possiamo vederlo così:
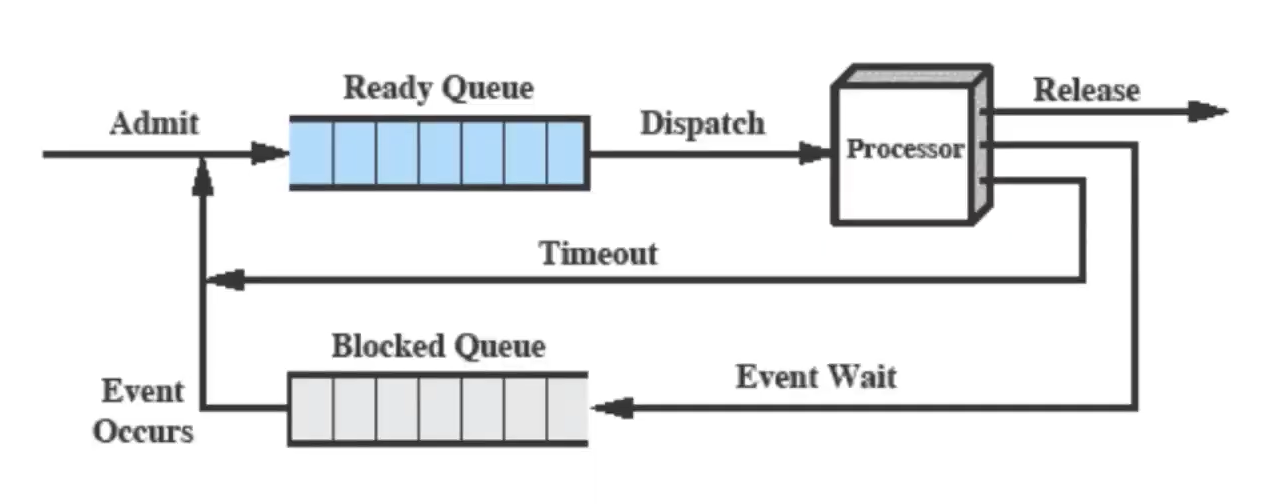
Basta quindi aggiungere una coda per i processi in attesa.
Possiamo migliorare questa implementazione nel seguente modo:
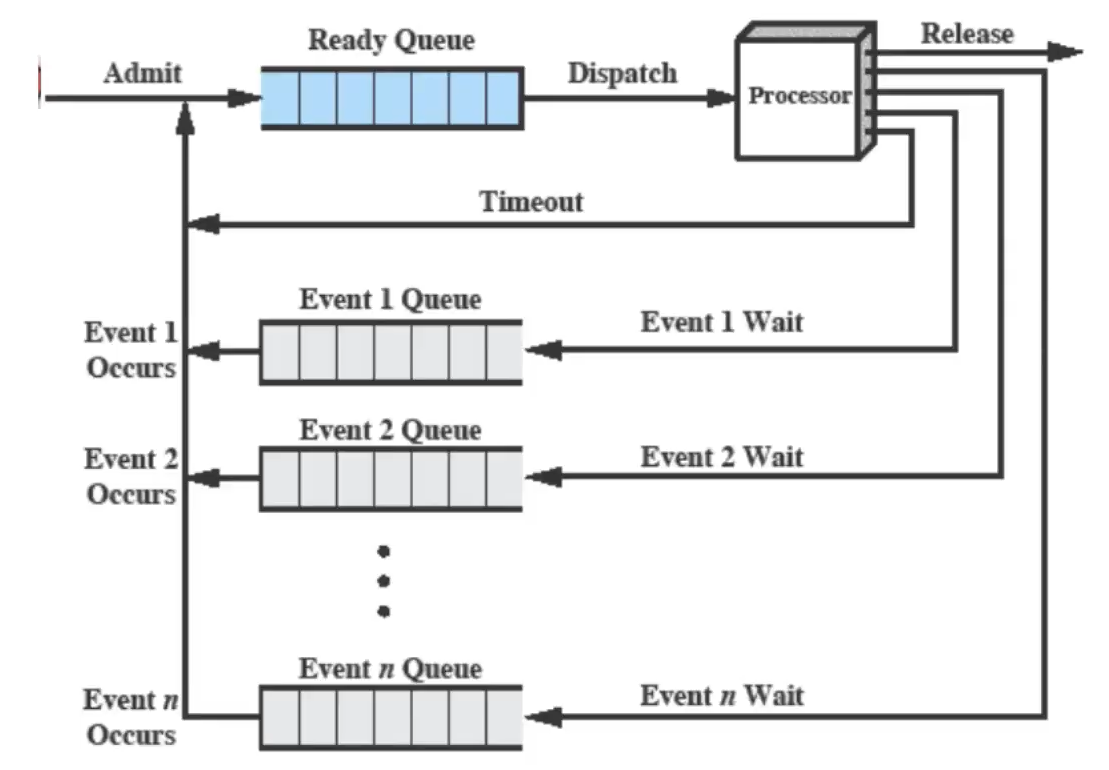
In questo modo abbiamo diverse code per ogni tipo di blocco, quindi ad esempio i processi in attesa della stampante si trovano sulla stessa coda; quelli in attesa di un input dalla tastiera sono sulla stessa coda ecc…
In questo modo quando un blocco termina il Sistema Operativo può prendere il primo processo della coda corrispondente invece di andarlo a cercare in una coda generale come nell’implementazione precedente, questo quindi migliora le prestazioni.
Processi Sospesi
Prima abbiamo detto che tutti i processi si trovano sulla RAM quando sono in esecuzione o bloccati, non sempre è così.
Quando i processi sono in attesa di I/O questi abbiamo visto andare in stato di blocked, questo significa che stanno sprecando memoria RAM dato che non stanno svolgendo operazioni. Lo stato blocked per alcuni processi diventa suspended e quando questo accade il processo viene spostato(“swappato”) dalla RAM al disco rigido.
Vengono introdotti due nuovi stati:
- blocked / suspended ovvero quando viene swappato mentre era bloccato.
- ready / suspended quando invece viene swappato mentre non era bloccato. (anche un processo pronto può venire sospeso per alcune ragioni)
Quindi otteniamo in totale un modello dei processi a 7 stati:
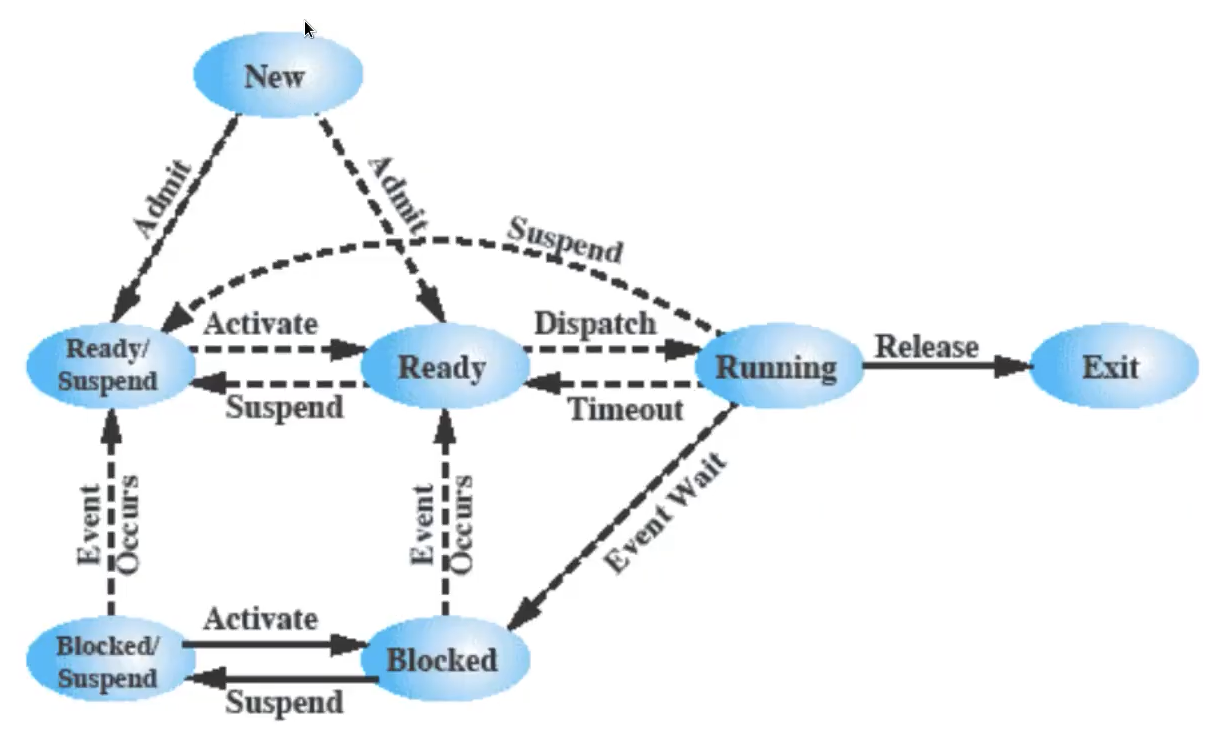
Appena il processo viene creato va fatta subito una scelta da parte del S.O. ovvero se mandare il processo in stato di ready e quindi metterlo in RAM oppure se caricarlo sul disco in stato di ready / suspended, poi come prima il dispatcher decide chi mandare in esecuzione e chi lasciare in ready; se ci sono attese vengono mandate i processi in blocked e questo viene “sbloccato” solo quando l’evento che si sta aspettando accade.
Viene aggiunto che un programma blocked potrebbe essere mandato in blocked / suspended oppure che un programma in esecuzione venga mandato in ready / suspended, inoltre da notare che un programma blocked / suspended può anche andare in ready / suspended e quindi rimanere sul disco.
Da notare anche che da qualsiasi stato si può passare ad Exit, ad esempio se un processo ne uccide un altro.
Motivi per Sospendere un Processo
- Swapping: Il S.O. ha bisogno di memoria per eseguire un programma ready.
- Interno al S.O.: Il S.O. sospetta che il processo stia causando problemi.
- Richiesta utente interattiva: Ad esempio quando eseguiamo debugging, oppure collegato all’uso di risorse.
- Periodicità: Il processo è stato pensato per eseguire poche istruzioni solo qualche volta al giorno (ad esempio monitoraggio per accounting), quindi durante il tempo in cui non esegue nulla non c’è motivo di tenerlo in RAM.
- Richiesta del padre: Il processo padre vuole sospendere l’esecuzione del figlio per esaminarlo o modificarlo oppure per coordinarlo con altri figli.
Processi e Risorse
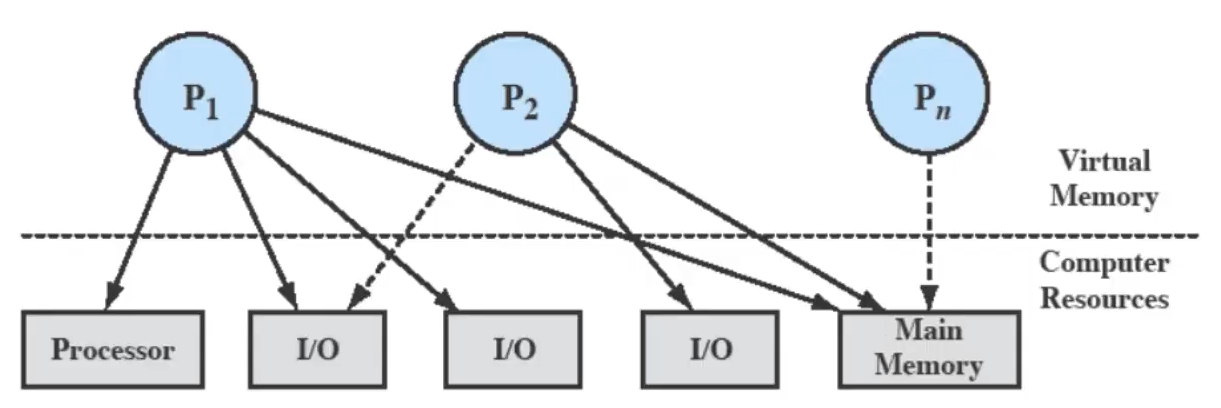
Vediamo che più processi quindi possono richiedere l’utilizzo delle stesse risorse, ad esempio la prima risorsa I/O possiamo dire che è esclusiva ovvero può essere utilizzata da un solo processo alla volta, infatti la sta utilizzando e è in attesa (freccia tratteggiata). Mentre altre risorse possono essere usate contemporaneamente come ad esempio la memoria, ovviamente non le stesse locazioni nello stesso momento ( infatti sta aspettando per delle zone di memoria).
Strutture di Controllo del S.O.
Dato che il Sistema Operativo gestisce l’uso delle risorse di sistema da parte dei processi ma anche le risorse che questi utilizzano deve conoscere lo stato di ogni processo e di ogni risorsa. Per fare questo il S.O. crea una o più tabelle per ogni entità da gestire.
Con un livello di astrazione molto alto possiamo vederlo in questo modo:
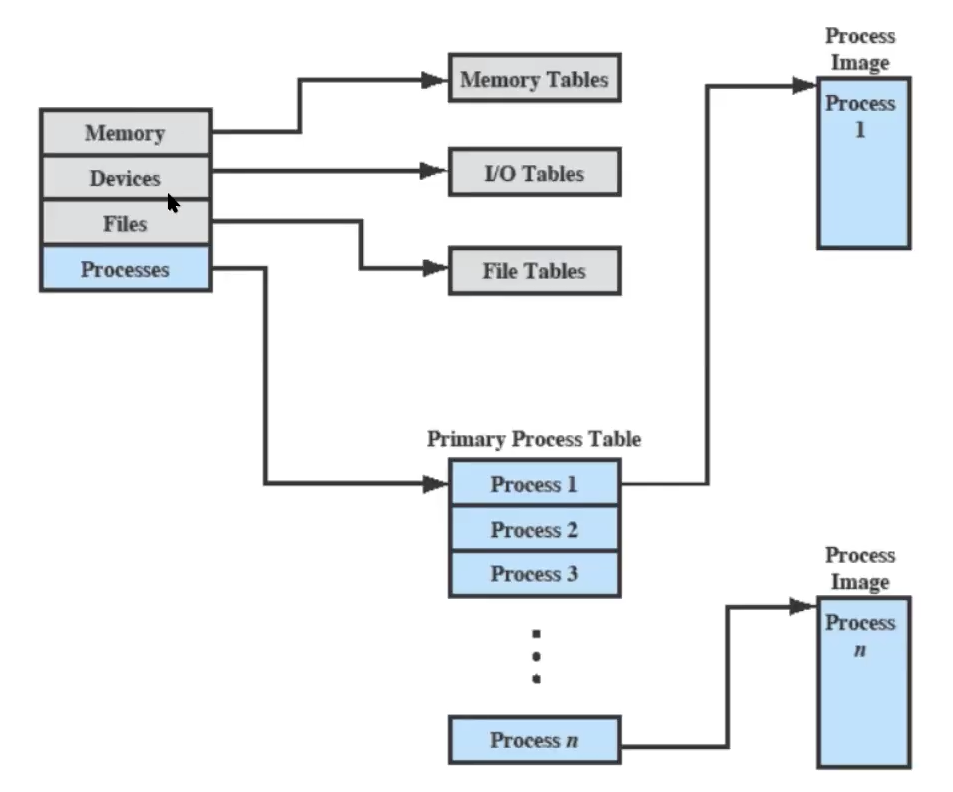
Per ora noi abbiamo visto soltanto i Process Control Block e sono i blocchi che vediamo in Primary Process Table, uno per ogni processo, le process image sempre come visto prima sono le zone di memoria che utilizzano i corrispettivi processi, questa non si trova quindi nel PCB.
Da ricordare inoltre che tutto questo è contenuto nel kernel e quindi non accessibile ai processi.
!!! Tutte le tabelle di seguito verranno approfondite più avanti nel corso !!!
Tabelle di Memoria
Sono usate per la gestione della memoria principale e secondaria, la secondaria serve per la memoria virtuale. Contengono diverse informazioni:
- Allocazione di memoria principale da parte dei processi.
- Allocazione di memoria secondaria da parte dei processi.
- Attributi di protezione per l’accesso a zone di memoria condivisa
- Informazioni per gestire la memoria virtuale
Tabelle per I/O
Sono usate per gestire i dispositivi I/O:
- Sapere se il dispositivo è disponibile
- Stato dell’operazione I/O
- La locazione di memoria principale usata come sorgente o destinazione dell’operazione di trasferimento I/O
Tabelle dei File
Hanno informazioni su:
- Esistenza dei file
- Locazione di memoria secondaria
- Stato correnti
- Altri attributi come nome ecc… Queste sono memorizzate su disco e una parte in RAM.
Tabelle dei Processi
Il SO deve sapere:
- Stato del processo
- Identificatore
- Locazione di memoria
- altre info… Tutte queste informazioni si trovano nel PCB e queste informazioni prendono il nome di attributi del processo.
Si dice process image “quello che vede il programmatore” o anche il processo vero e proprio quindi, come visto anche prima è la zona di memoria RAM utilizzata quindi:
- Programma sorgente
- Dati (variabili)
- Stack delle chiamate Questi 3 visti si trovano in RAM mentre
- Il PCB si trova nel kernel
Da notare che se eseguiamo un’istruzione l’immagine del processo cambia, ad esempio viene modificata una cella di memoria o un registro, l’unica eccezione a questa regola è un jump sulla stessa istruzione, infatti qualsiasi altra istruzione come minimo deve modificare il Program Counter.
Attributi dei Processi
Le informazioni contenute in un PCB possono essere raggruppate in 3 categorie:
- Identificazione
- Stato
- Controllo
Per identificare un processo abbiamo visto che gli viene assegnato un identificativo unico che si chiama PID (Process IDentifier), un numero positivo che gli viene assegnato. Molte tabelle del SO usano i PID per realizzare collegamenti fra le varie tabelle e quella dei processi, ad esempio per tenere conto di quale processo sta utilizzando una determinata risorsa.
Stato del Processo e Stato del Processore
È importante non confondere le due cose, gli stati del processo sono quelli visti prima come ad esempio ready, blocked ecc… mentre lo stato del processore è il contenuto dei suoi registri, le sue informazioni di stato.
Process Control Block
Contiene le informazioni necessarie al SO per controllare e coordinare i vari processi attivi.
- Identificatori
- PID del processo
- PID del processo padre ovvero PPID (Parent PID)
- Identificatore dell’utente che lo ha avviato
- Informazioni sullo stato del Processore, queste informazioni possono essere copiate sul PCB (RAM):
- Registri utente (accessibili dai programmatori)
- Program Counter
- Stack Pointer
- Registri di Stato
- Informazioni di controllo del processo:
- Stato (ready, blocked,…)
- Priorità e altre info per lo scheduling (ultima volta che è stato eseguito ad esempio)
- L’evento da attendere per tornare ready se in attesa.
- Supporto per strutture dati:
- Puntatori ad altri processi
- Questi puntatori possono servire ad esempio a mantenere delle liste puntate di processi, come abbiamo visto per l’attesa delle risorse.
- Comunicazione tra processi
- Flag, segnali e messaggi per supportare la comunicazione.
- Permessi Speciali (a cosa può accedere il processo)
- Gestione della Memoria
- Puntatori ad aree di memoria (NON memoria effettiva) che gestiscono l’utilizzo della memoria virtuale.
- Uso delle risorse
- File aperti
- Uso di altre risorse come il processore o altri componenti
Process Image vista in memoria virtuale ovvero astraendo da come è realmente utilizzata (non sono tutte vicine queste informazioni):
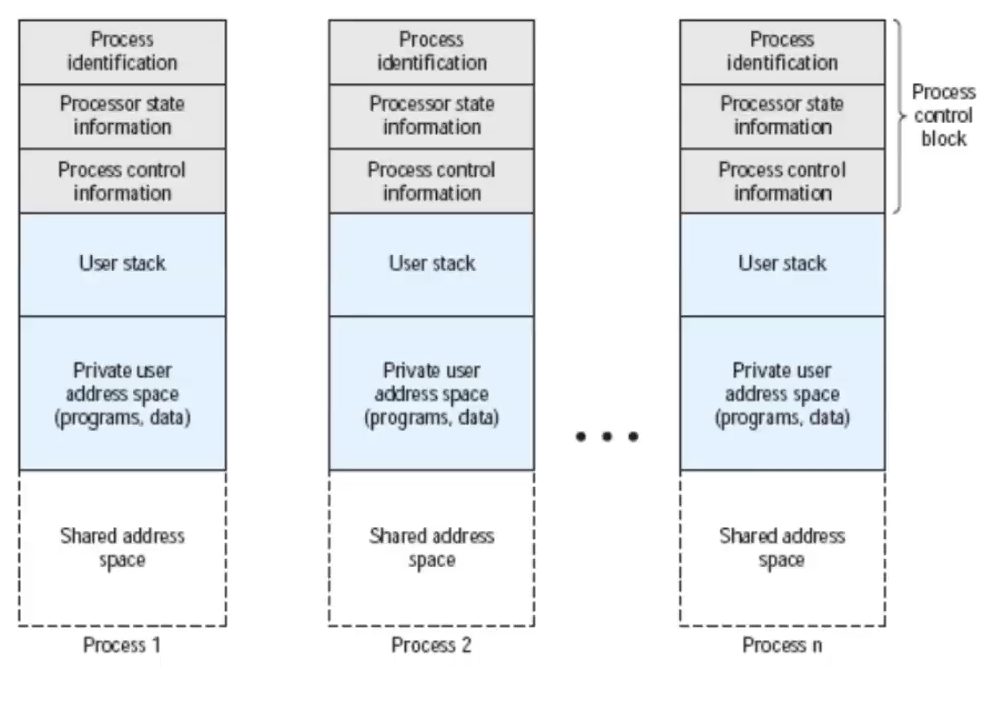
La parte del Process Control Block quindi ricordiamo non essere sotto il controllo del processo ma bensì del Sistema Operativo. Da notare inoltre che l’ultima zona bianca in fondo è condivisa fra tutti i processi, infatti normalmente questo non potrebbe accadere ma se chi ha li ha scritto lo ha previsto allora è possibile.
Il Process Control Block quindi è una parte fondamentale del Sistema Operativo dato che descrive il suo stesso stato e proprio per questo richiede delle protezioni, un blocco non deve essere modificato in modo errato.
Modalità di Esecuzione
Le avevamo accennate all’inizio, abbiamo la kernel mode dove si ha pieno controllo sul sistema, quindi possiamo accedere ovunque; e la user mode dove non possiamo accedere a zone di memoria protette, di solito viene usata per i programmi utente. Questo è anche un modo di protezione da utenti malintenzionati.
Kernel Mode
È stata creata per le operazioni eseguite appunto dal kernel come ad esempio:
- Gestione dei processi tramite PCB
- Creazione e terminazione
- Scheduling e dispatching
- Process Switching (La logica del dispatching)
- Sincronizzazione e comunicazione fra processi
- Gestione della memoria principale
- Allocazione di spazio per i processi
- Gestione della memoria virtuale
- Gestione I/O
- Gestione buffer e cache per I/O
- Assegnazione risorse I/O ai processi
- Funzione di supporto
- Gestione di interrupt ed eccezioni, accounting e monitoraggio
Spesso però i programmi utente hanno bisogno degli I/O, per fare questo i programmi possono passare in modalità kernel per poi tornare in user mode.
Da User Mode a Kernel Mode e ritorno
Un processo inizia sempre dalla User Mode, a seguito di un interrupt si porta a Kernel Mode:
- La prima cosa che fa l’hardware, prima ancora di copiare lo stato del processore, è cambiare la modalità, quindi adesso ci troviamo in modalità sistema.
A questo punto possiamo eseguire gli interrupt handler in modalità kernel, ed è proprio quello che vogliamo dato che questi si trovano nel kernel, che altrimenti sarebbe inaccessibile. L’handler a questo punto una volta terminato, prima di restituire il controllo al processo, lo farà tornare in modalità utente.
Warning
Quando un processo va in modalità kernel può eseguire soltanto istruzioni presenti nel kernel stesso (software di sistema) e non comandi scritti nel suo codice sorgente.
L’interrupt handler può essere eseguito in diversi “modi”, e in tutti questi dobbiamo essere in kernel mode:
- Eseguito per conto dello stesso processo interrotto che lo ha esplicitamente voluto
- System calls oppure in risposta ad una sua richiesta di I/O
- Eseguito per conto dello stesso processo interrotto ma non voluto:
- Errore fatale (abort): Il processo viene terminato
- Errore non fatale (fault): Trasparente rispetto al processo
- Codice eseguito per conto di un altro processo
- È un caso particolare dove ad esempio un processo A ha fatto richiesta di I/O e si trova adesso in stato blocked, se durante l’esecuzione di un altro processo B viene eseguita la richiesta di A allora l’interrupt viene eseguito per conto del processo B ma è in risposta a quello che ha chiesto A. Questo è ormai “accettato” nei moderni sistemi operativi.
Creazione di un Processo
Il Sistema Operativo deve:
- Assegnargli un PID
- Allocargli spazio in RAM
- Inizializzare il suo PCB
- Inserire il processo nella giusta coda, quindi se in ready o suspended.
- Creare o espandere strutture dati come ad esempio quelle per l’accounting
Switching tra Processi
In questa logica di switching possono esserci alcuni problemi, ad esempio:
- Quali fattori determinato uno switch?
- Cosa deve fare il S.O. per tenere aggiornate tutte le strutture relative ai processi? (ad esempio le code ready)
Switch modalità e switch processi
È importante non confondere le due cose, lo switch di modalità lo abbiamo visto prima e serve a permettere l’esecuzione degli handler in modalità sistema. Lo switch tra processi è il meccanismo che decide quale processo mandare in esecuzione e quale in stato di sospensione.
Quando effettuare uno switch
Questo può succedere quando il S.O. prende il controllo togliendolo al processo, questa cosa può accadere per vari motivi:
Passaggi per switching fra processi
Ricordiamo che vanno tutti eseguiti in Kernel Mode
- Salvare il contesto del programma ovvero registri e PC (copiati nel PCB)
- Aggiornare il PCB attualmente in esecuzione
- Spostare il PCB nella coda appropriata
- Scegliere un altro processo da eseguire (potrebbe avvenire anche prima)
- Aggiornare il PCB del nuovo processo
- Aggiorna le strutture dati per la gestione della memoria
- Ripristina il conteso del processo (registri)
Notiamo quindi che escluso il processo 4 i primi 3 sono per un processo A e gli ultimi 3 che fanno le stesse cose ma in ordine inverso sono per il nuovo processo B.
Esecuzione del SO
Il SO è un processo?
Il Sistema Operativo è un insieme di programmi ed è eseguito dal processore come ogni altro programma. Molto spesso lascia che altri programmi vadano in esecuzione per poi riprendere il controllo tramite gli interrupt. È un processo? Possiamo vedere che il comportamento è molto simile ma se si, come viene controllato?
Dipende dal Sistema Operativo
Kernel Separato
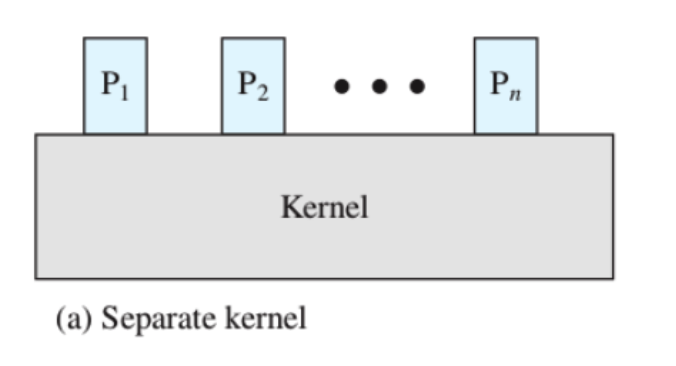
Il Kernel viene eseguito al di fuori dei processi, quindi in questo caso il sistema operativo non è un processo. Questo è eseguito come entità separata con privilegi elevati e zone di memoria riservate.
Kernel all’interno dei processi utente
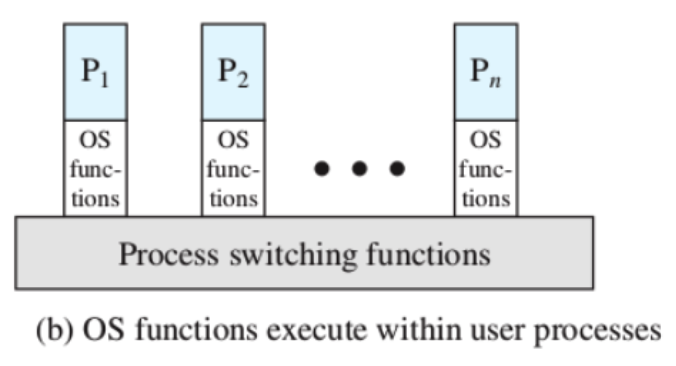
In questo caso il Sistema Operativo viene eseguito nel contesto di un processo utente dopo un interrupt. Come visto prima questo interrupt è una parte del SO che viene eseguita e “delegata” al processo in esecuzione.
Comunque lo stack delle chiamate del processo e quello del SO è separato, questo per questioni di sicurezza.
Inoltre ricordiamo che non è necessario eseguire un process switch ma soltanto un mode switch.
Kernel basato sui Processi
Qui tutto è un processo anche gli interrupt del Sistema Operativo, l’unica cosa che non lo è sono le funzioni che permettono il process switching. In questo caso quindi anche i processi del sistema operativo si trovano all’interno delle varie code.
Linux - Misto tra 2 e 3
Le funzioni del Kernel sono eseguito per lo più tramite interrupt per conto del processo corrente, ci sono però dei processi di sistema chiamati kernel threads che partecipano alla normale competizione del processore senza essere invocati, ci sono già all’accensione.
Di solito sono periodici, quindi ogni “tot tempo” eseguono un’operazione come ad esempio:
- Riorganizzare la RAM liberando spazio
- Gestire dispositivi I/O
- Operazioni di rete
Unix
Usa il modello 2 dove la maggior parte del SO viene eseguito all’interno dei processi utente con le stesse tecniche che abbiamo visto prima.
Transizioni tra Stati dei Processi
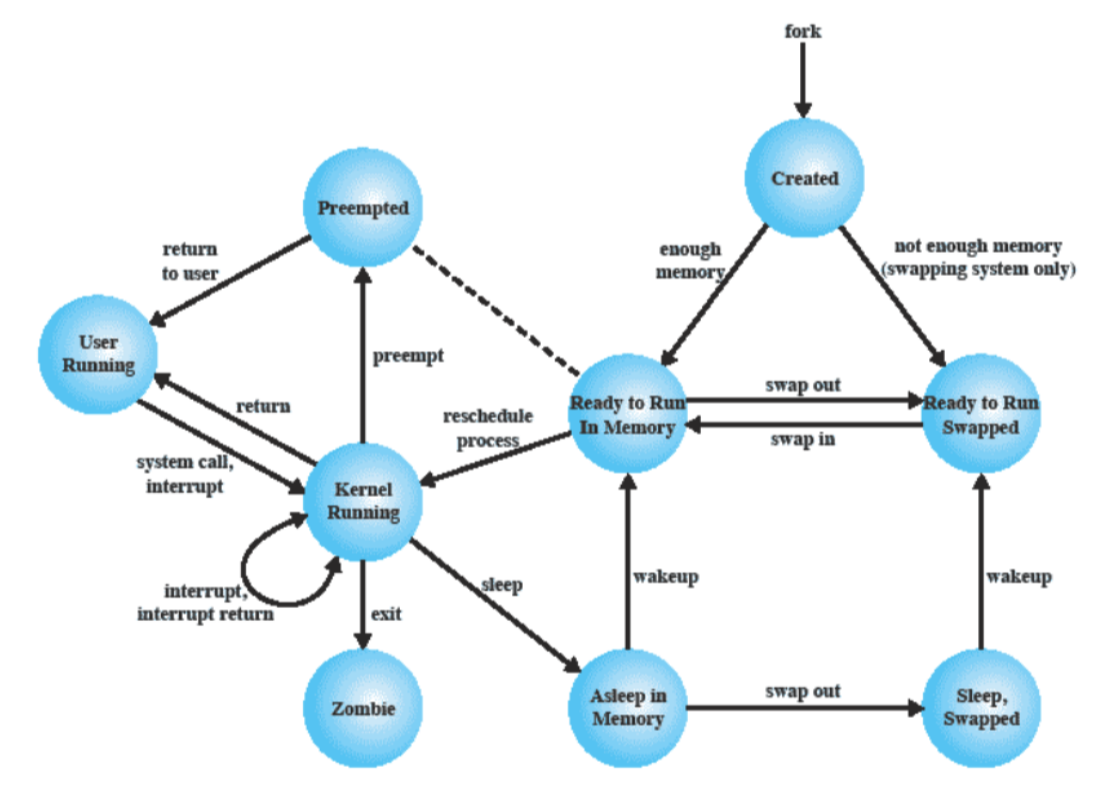
Qua abbiamo più stati ma il funzionamento è simile a quello visto prima. Quando un processo chiama la funzione fork crea un processo figlio, va in ready to run in memory dove è pronto per essere selezionato mentre se si trova in ready to run swapped significa che si trova sul disco. Il running è diviso in kernel running e user running che indicano in che modalità è eseguito un processo, da notare che prima bisogna passare per la kernel running. La preemted indica quando togliamo il processore ad un processo prima che finisca, la asleep in memory indica che non può essere eseguito finché non avviene un altro evento ma si trova comunque in memoria. Sleeping Swapped è come il precedente ma si trova in memoria. Quando un processo finisce va nello stato zombie, più nello specifico quando un processo viene terminato deve mandare al suo padre un codice che indica la sua terminazione, finché non lo fa il processo figlio si trova in questo stato zombie. In questo stato inoltre non esiste più l’immagine del processo ma soltanto il suo PCB.
Il Processo Unix
L’immagine di un processo Unix è divisa in diverse categorie.
Livello Utente
Questi sono visti dai programmatori
- Process Text: Codice Sorgente in linguaggio macchina
- Process Data: Sezione di dati del processo ovvero i collegamenti ai valori delle variabili.
- User Stack: Le chiamate del processo
- Shared Memory: Memoria condivisa con altri processi se presente.
Livello Registro
- Program Counter: Indirizzo della prossima istruzione del process text da eseguire
- Processor status register: Registro di stato del processore, relativo a quando è stato swappato l’ultima volta
- Stack Pointer: Puntatore alla cima dello user stack
- General purpose registers: Registri accessibili al programmatore, relativo a quando è stato swappato l’ultima volta.
Livello Sistema
Gestire un processo a livello di memoria
- Process table entry: Puntatore alla tabella di tutti i processi che individua quello corrente
- U Area: Informazioni per il controllo del processo
- Process Region Table: Definisce il mapping tra indirizzi virtuali ed indirizzi fisici
- Kernel Stack: Lo stack di chiamate separato da quello utente usato per le funzioni di sistema.
Formato del PCB di un processo UNIX:

- Process Size: Indica la dimensione dell’immagine del file e non quella del PCB, quest’ultimo ha grandezza predefinita.
- User Identification: Ad esempio se un processo è in esecuzione utente e va in modalità kernel, l’effective user ID diventa il “sistema operativo” mentre il real user ID rimane l’utente iniziale.
- Event Descriptor: Indica perché il processo è in asleep
- P_Link: Puntatore al prossimo processo in coda (coda ready o altre code).
Creazione di un Processo Unix
- Viene effettuata una chiamata di sistema
fork() - Il SO, in kernel mode:
- Alloca una entry nella tabella dei processi
- Assegna un PID al processo
- Copia l’immagine del padre escludendo la memoria condivisa, una volta fatto questo sia padre che figlio vorranno eseguire la stessa istruzione successiva al fork.
- Incrementa i contatori di ogni file aperto dal padre dato che ora sono anche del figlio
- Assegna al processo lo stato Ready to Run
- La fork ritorna il PID del figlio al padre e 0 al figlio, nello specifico all’interno del codice posso inserire un if sul valore della fork, se è 0 sono nel figlio e posso eseguire le istruzioni che voglio, se non è 0 sono il padre e allora posso continuare con le vecchie istruzioni oppure ad esempio aspettare la terminazione del figlio.
Quindi quando creiamo un processo figlio, inizialmente questo è una copia del padre, si è notato che è la cosa più efficiente dato che è la situazione più comune quella dove un figlio esegue una parte del codice del padre.
Una volta creato, il kernel decide se continuare ad eseguire il padre, eseguire il figlio o un altro processo ancora.
Thread
Per ora abbiamo visto che ci sono più processi che si alternano lo stato di esecuzione sul computer, però non è sempre così, alcune applicazioni sono organizzate in modo parallelo e non perché lo decide il SO ma perché lo ha deciso il programmatore dell’applicazione, ogni esecuzione dell’applicazione si chiama Thread e ad esempio per un’applicazione grafica possiamo avere:
- Un thread per gli input del mouse
- Uno per disegnare su schermo
- Un altro per effettuare i calcoli richiesti
Ricordiamo che di per sé è un processo unico ma ci sono più threads.
Diversi threads di uno stesso processo condividono tutte le risorse del processo tranne lo stack delle chiamate e il processore quindi se non ho abbastanza processori non è detto che tutti i thread vadano in esecuzione. Per le altre risorse invece se un thread ad esempio ha accesso ad un dispositivo I/O allora a questo dispositivo ha accesso l’intero processo.
Il concetto di processo come visto prima ha 2 caratteristiche principale:
- Gestione delle risorse che per quanto riguarda i processi vanno visti come blocco unico
- Scheduling ovvero che i processi possono contenere diverse tracce ovvero diversi threads Nel caso di più threads vanno trattati in maniera diversa.
Diversi casi nei Sistemi Operativi:
A Livello di Gestione:
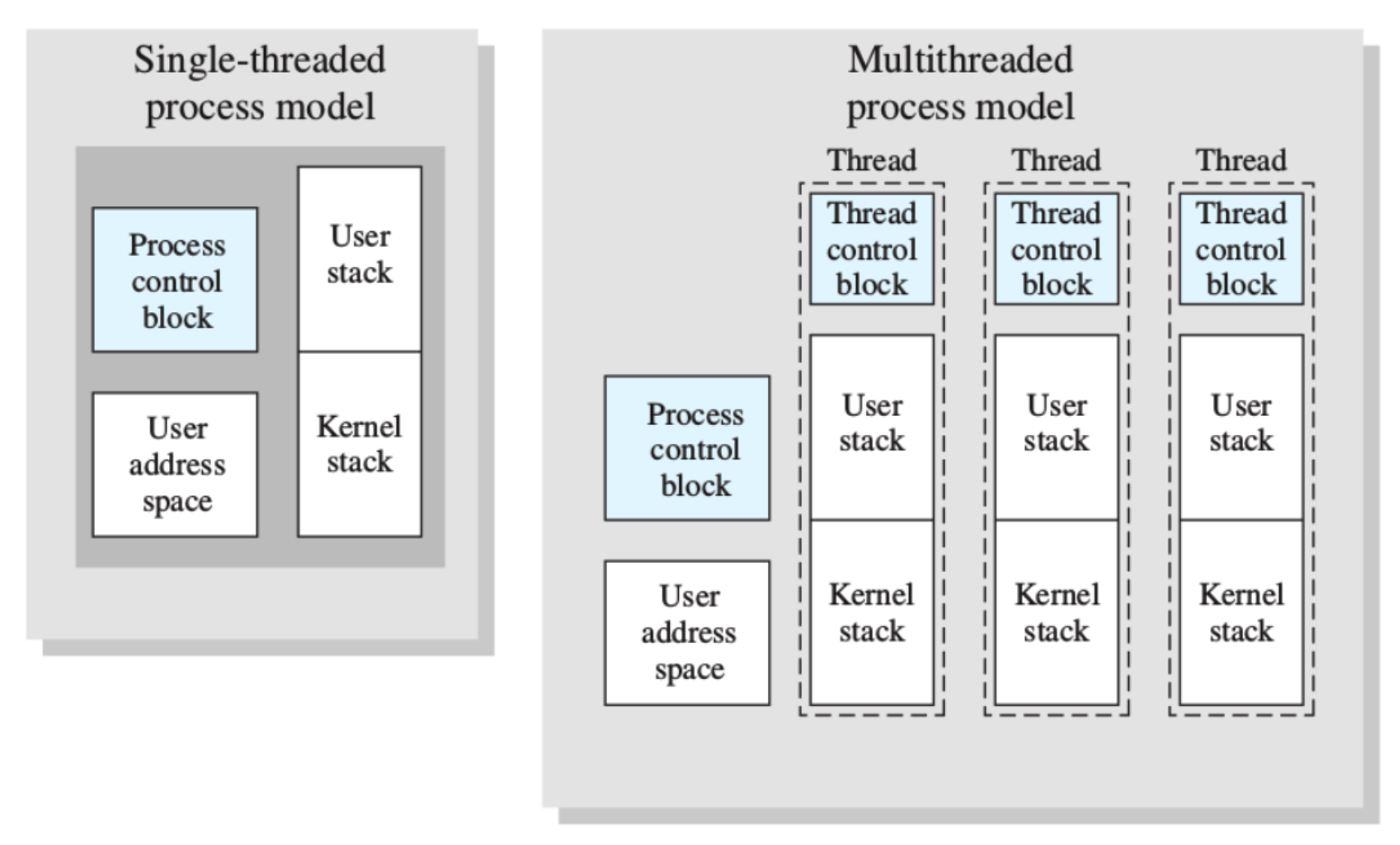
Quindi in un sistema a singolo thread è gestito come abbiamo visto fino ad adesso con un PCB per ogni processo e i 2 stack.
Su un sistema multithread abbiamo un PCB del processo, la User Address Space che è la parte in comune fra tutti i thread, quindi variabili globali ecc.., e per ogni thread la gestione di quel thread quindi un Thread Control Block che serve a gestire lo scheduling fra questi e poi due stack separati per ogni thread, uno utente e uno kernel mode.
Vantaggio dei Thread
Prima abbiamo visto che è possibile creare più processi figli da un padre, a cosa servono quindi i Thread?
Questi sono più efficienti, è inoltre più semplice crearli, terminarli e fare lo switching.
Ogni processo viene creato con un thread al suo interno, dopo il programmatore può creare altri thread con una chiamata di sistema (più leggera del fork dato che ha meno istruzioni da fare, non crea tutti gli spazi necessari per un processo), può bloccare un thread per metterlo in attesa di altre operazioni, quindi c’è anche un unblock, infine con finish si può eliminare un thread.
Ricordiamo che tutte queste operazioni vengono svolte all’interno dello stesso processo e che un processo deve sempre avere almeno un thread.
ULT vs KLT
Differenza nel sistema
Bisogna fare una differenza fra Thread a livello Utente (ULT) e Thread a livello di Sistema (KLT)
Nel primo caso vediamo che se ci sono Thread a livello utente, per il sistema operativo i thread non esistono, ci sono delle librerie a livello utente che gestiscono i thread.
Nel secondo caso, il sistema operativo prevede i thread anche a livello di kernel e quindi li “vede”.
Nel terzo caso vediamo come si potrebbero usare entrambe le cose.
Nella maggior parte dei sistemi operativi moderni si utilizza il secondo metodo, quindi il sistema operativo è a conoscenza dei thread.
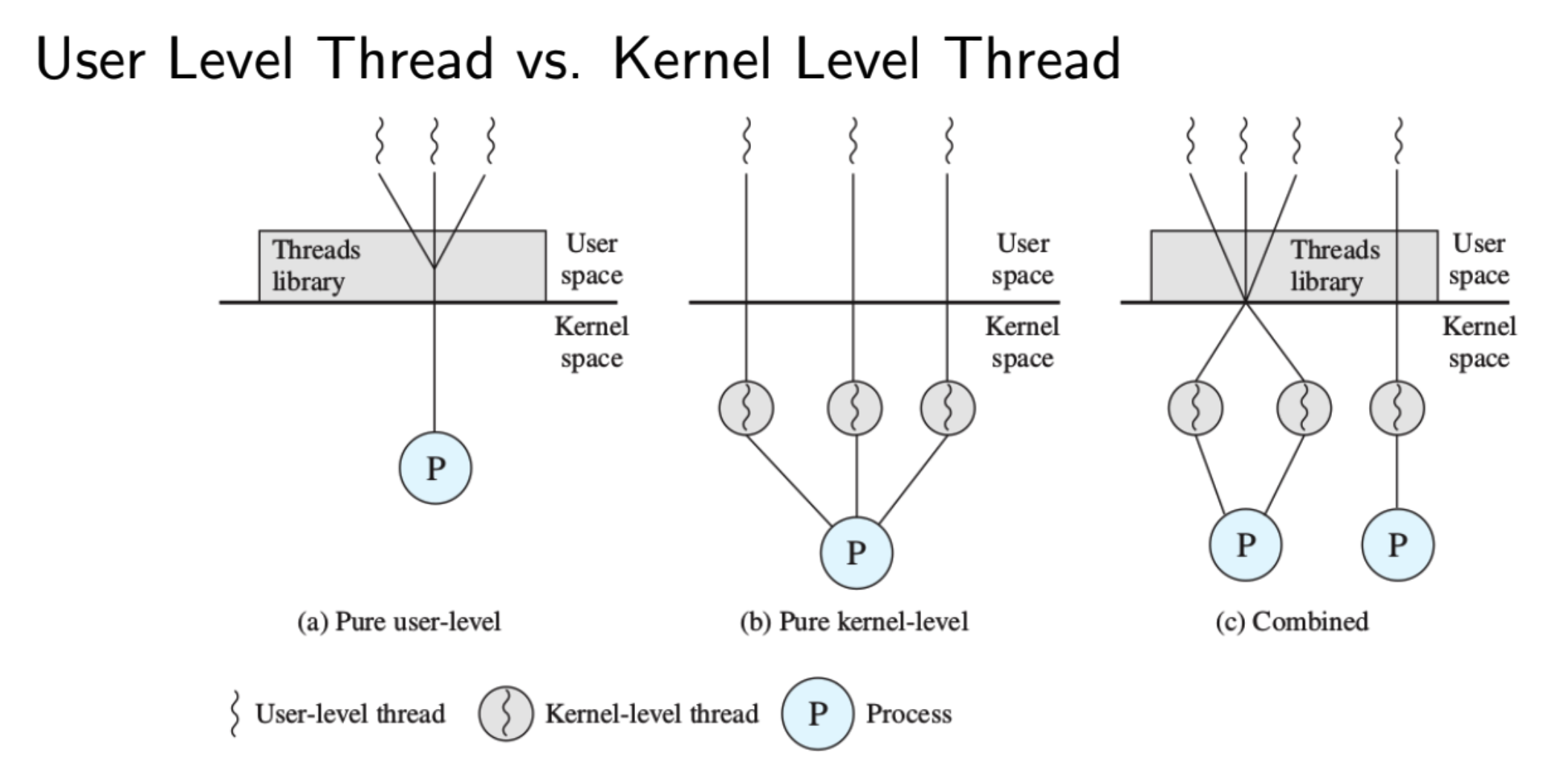
Meglio ULT perché:
- Switch più efficiente dato che per thread dello stesso processo non è richiesto il mode switch.
- Scheduling diverso per ogni applicazione utente
- Permettono di usare i thread anche su sistemi operativi che non li supportano.
Peggio ULT perché:
- Se un thread si blocca, si bloccano tutti quelli di quel processo (a meno che non sia per un block) mentre con i KLT si blocca solo quel thread. Questo avviene perché il Sistema operativo con gli ULT non è a conoscenza dei thread.
- Se ci sono più processori o cores, tutti i thread del processo ne possono usare soltanto uno sempre per lo stesso motivo di prima.
- Se il sistema operativo non ha i KLT non può usarli nemmeno per le operazioni di sistema.
Processi e Thread in Linux
In Linux di base ci sono i Thread che in questo caso prendono il nome di LWP (Litghtweight Process), sono inoltre possibili sia gli ULT che i KLT, i KLT vengono usati dal sistema operativo mentre gli ULT sono scritti dagli utenti che se necessario vengono mappati in KLT con delle librerie (pthreads).
A livello di identificazione c’è da notare che utente e sistema sono termini diversi.
Se usiamo ps -e sul terminale possiamo vedere i processi in esecuzione:
- PID: Questo è unico per tutti i thread di un processo
- TID: Identifica ogni singolo thread
- Il TID non è un semplice numero che va da 1 a con il numero di thread di quel processo, infatti c’è sempre un thread per il quale il TID coincide con il PID
Perché?
- Il PID (come entry del PCB) è unico per ogni thread, questo perché come visto prima per Linux ci sono soltanto thread.
- L’entry del PCB che dà il PID comune a tutti i thread dello stesso processo è il tgid (thread group identifier) e questo coincide con il PID del primo thread creato dal processo.
Esempio
Creiamo un processo che ha quindi un thread, questi hanno lo stesso PID se adesso creiamo un nuovo thread questo avrà un nuovo PID ma il tgid di questo nuovo thread è uguale a quello dei precedenti.
- Una chiamata a
getpid()non restituisce il PID ma il tgid ovvero il PID del processo di cui fa parte - Per processi con un solo thread,
tgid e PIDcoincidono. - C’è un PCB per ogni thread, è quindi diverso dalla foto vista prima, quindi ogni thread control block è all’interno del PCB, questo porta a una ripetizione di informazioni per thread dello stesso processo, ma dato che sono solo puntatori non è così alto lo spazio sprecato.
- Il comando
psvisto prima confonde un po’, il PID che ci mostra è a tutti gli effetti iltgid, il PID vero viene identificato come LWP o SPID o TID.
PCB di LINUX:
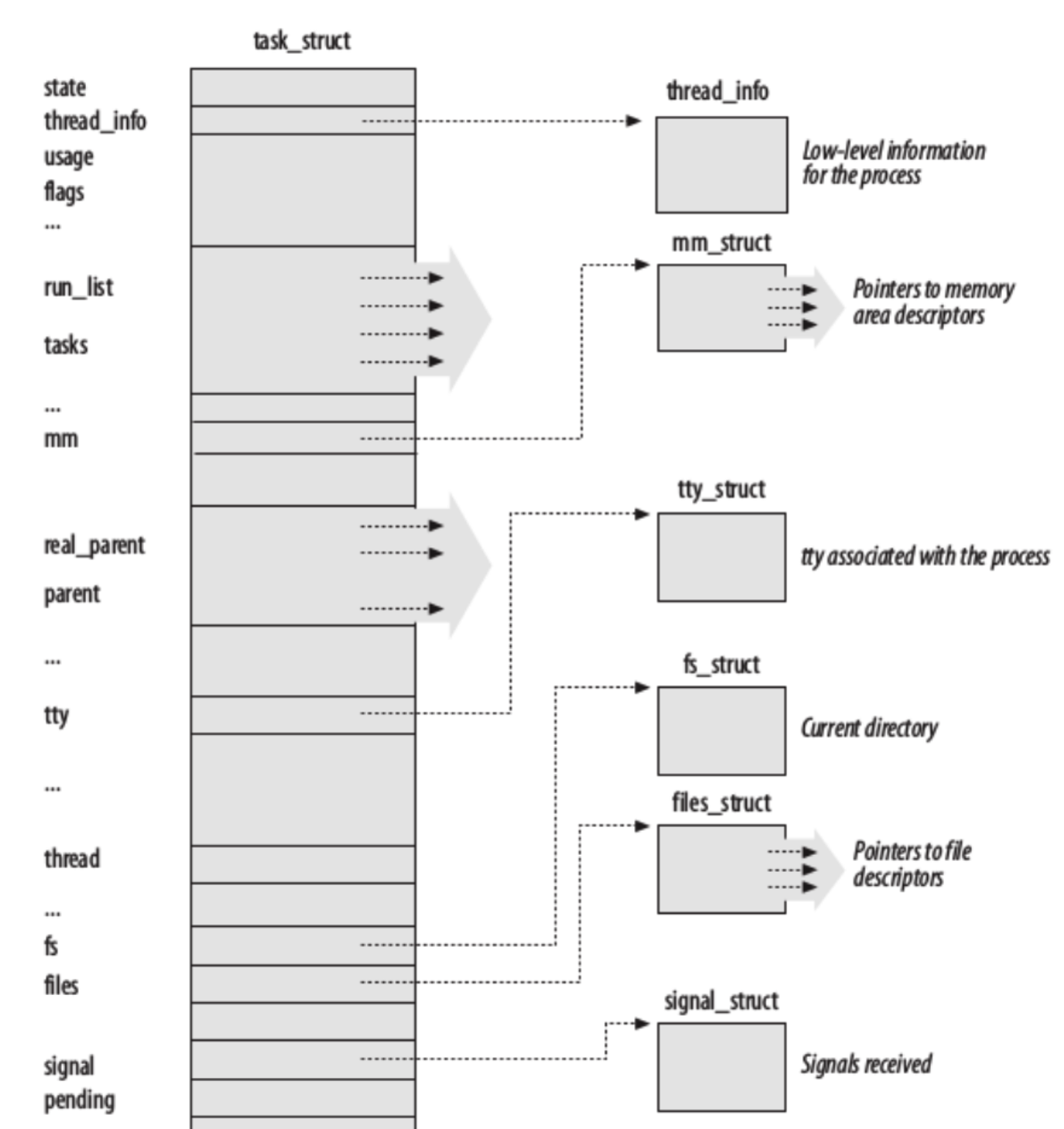
All’interno troviamo il PID, univoco per ogni thread, e il tgid. Le frecce indicano i puntatori.
All’interno notiamo un puntatore ad una struttura thread info, questa è organizzata per contenere anche il kernel stack ovvero lo stack da usare quando il thread passa a modalità sistema.
Nell’immagine non è riportato ma c’è un puntatore thread group (lista concatenata) che ci permette di rintracciare gli altri thread dello stesso processo.
parent e real_parent puntano al padre del processo e inoltre ci sono anche altri puntatori a fratelli e figli.
Processi Parenti:
Stati dei processi Linux
È sostanzialmente il modello a 5 stati, non ci sono processi suspended, o meglio potrebbero esserci ma non per scelta del SO.
Ci sono diversi stati:
TASK_RUNNING: Include sia ready che running, quindi sono tutti “running”.TASK_INTERRUPTIBLE, TASK_UNINTERRUPTIBLE, TASK_STOPPED, TASK_TRACED:Sono tutti blocked la differenza la fa soltanto il motivo per cui lo sono.EXIT_ZOMBIE, EXIT_DEAD: Sono entrambi Exit, zombie ha lo stesso significato di Unix
Segnali ed Interrupt in Linux
È importante non confondere segnali ed interrupt o eccezioni:
- I segnali possono essere inviati da un processo utente ad un altro tramite syscall (di solito con kill che non sempre uccide il processo).
- Quando questo succede il segnale appena ricevuto viene aggiunto al PCB di chi lo riceve (campo signal pending)
Cosa succede poi?
- Quando il processo viene mandato in esecuzione, il kernel per prima cosa controlla se ci sono segnali in attesa.
- Se si, viene chiamato il signal handler eseguito in modalità utente.
- I Signal Handler possono essere anche di sistema, questi sono sovrascritti dagli handler definiti dal programmatore, alcuni handler di sistema non possono essere sovrascritti.
- Anche gli handler di sistema sono eseguiti in modalità utente.
I gestori di interrupt ed eccezioni sono eseguiti invece in modalità kernel.
-
I segnali possono essere anche inviati da un processo che si trova in modalità sistema, spesso però se accade significa che sia dovuto ad un interrupt a monte, esempio:
Eseguiamo un programma C scritto male, che accede ad una zona di memoria senza averla richiesta. Viene generata un’eccezione, successivamente viene eseguito il corrispondente handler in modalità kernel che manda un segnale
SIGSEGVal processo colpevole.La prossima volta che verrà mandato in esecuzione il processo il kernel vedrà dal PCB che c’è un segnale in attesa ed eseguirà l’azione corrispondente, di default è la terminazione del processo ma l’utente può riscriverla, in ogni caso questa azione è eseguita in modalità utente. Ovviamente per la terminazione viene chiamata un’altra syscall che verrà eseguita in modalità kernel.
In breve quindi:
- I Signal Handler sono eseguiti in user mode mentre gli interrupt handler in kernel mode.
- I Signal Handler potrebbero essere riscritti dal programmatore mentre gli interrupt handler no. (Anche 2 signal handler non possono essere riscritti
SIGKILL e SIGSTOP).
Scheduling
Ne abbiamo parlato spesso, è il modo in cui il sistema operativo alloca le risorse tra i vari processi.
Quindi lo scopo è assegnare ad ogni processore i processi da eseguire durante l’esecuzione stessa. Per raggiungere questo scopo nel modo più efficiente possibile vanno ottimizzati alcuni aspetti:
- Tempo di risposta dei processi
- Throughput (massimizzare l’uso delle risorse)
- Efficienza del processore, ovvero minor tempo di idle
- Distribuire il tempo di esecuzione in modo equo
- In alcuni casi però va gestita anche la loro priorità, quindi bisogna essere equi fra quelli che hanno la stessa priorità
- Evitare la starvation dei processi (un processo in starving è un processo in attesa di essere eseguito ma con un scheduling fatto male non viene mai eseguito)
- Overhead basso (per overhead si intende del lavoro aggiuntivo, anche lo scheduler stesso è lavoro aggiuntivo e quindi deve lavorare in modo efficiente e decidere velocemente chi mandare in esecuzione).
Vari tipi di Scheduler
Si differenziano in base a quanto spesso vengono esuguiti
- Long-term Scheduling: viene eseguito molto raramente e decide chi aggiungere ai processi da eseguire
- Medium-term Scheduling: viene eseguito non molto spesso e decide i processi da aggiungere alla memoria principale
- Short-term Scheduling: eseguito molto spesso e decide tra i processi pronti quale mandare in esecuzione
- I/O Scheduling: Decide a quale processo in attesa di I/O assegnare il corrispondente dispotivo
Riprendendo lo schema a 7 stati visto precedentemente, possiamo notare come alcune transizioni tra stati vengono decise dai vari scheduler:
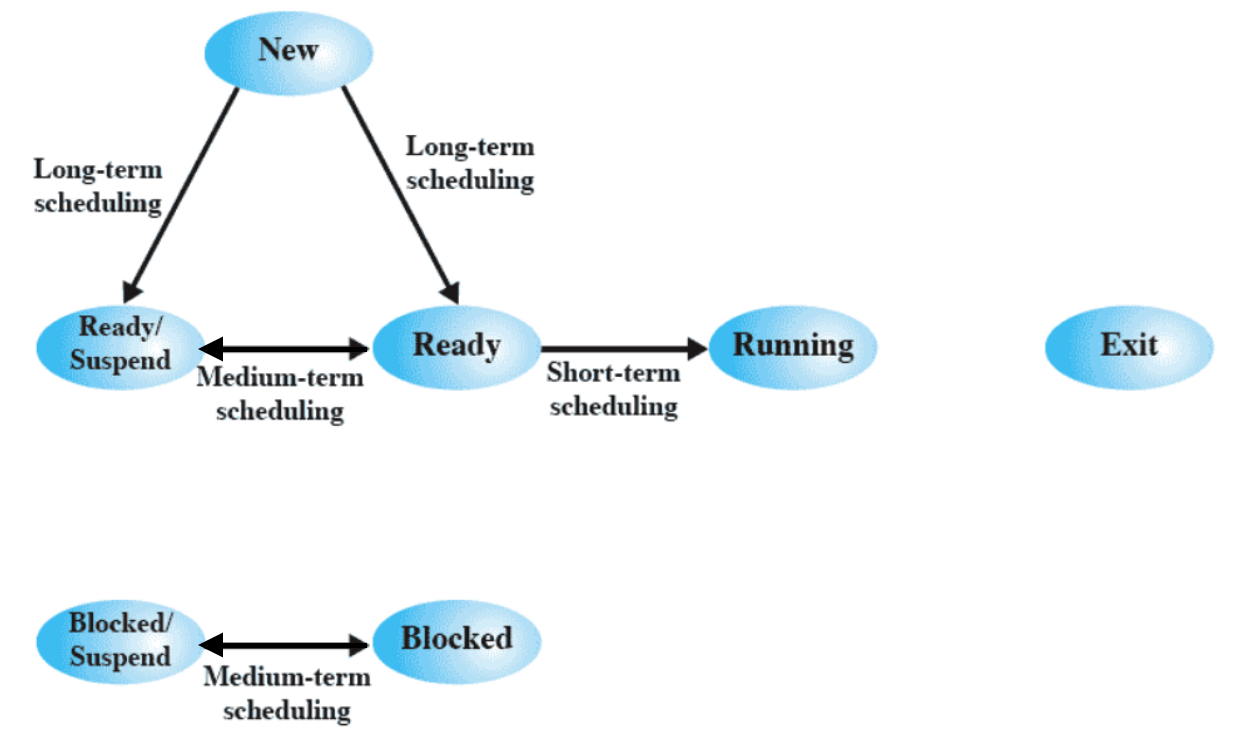
- Long-term: vediamo che decide se un processo appena creato va allocato in RAM oppure sul disco
- Medium-term: Decide se processi sospesi devono andare in ready o blocked
- Short-term: Decide chi mandare in esecuzione tra i processi pronti
Nello specifico, a livello implementativo:
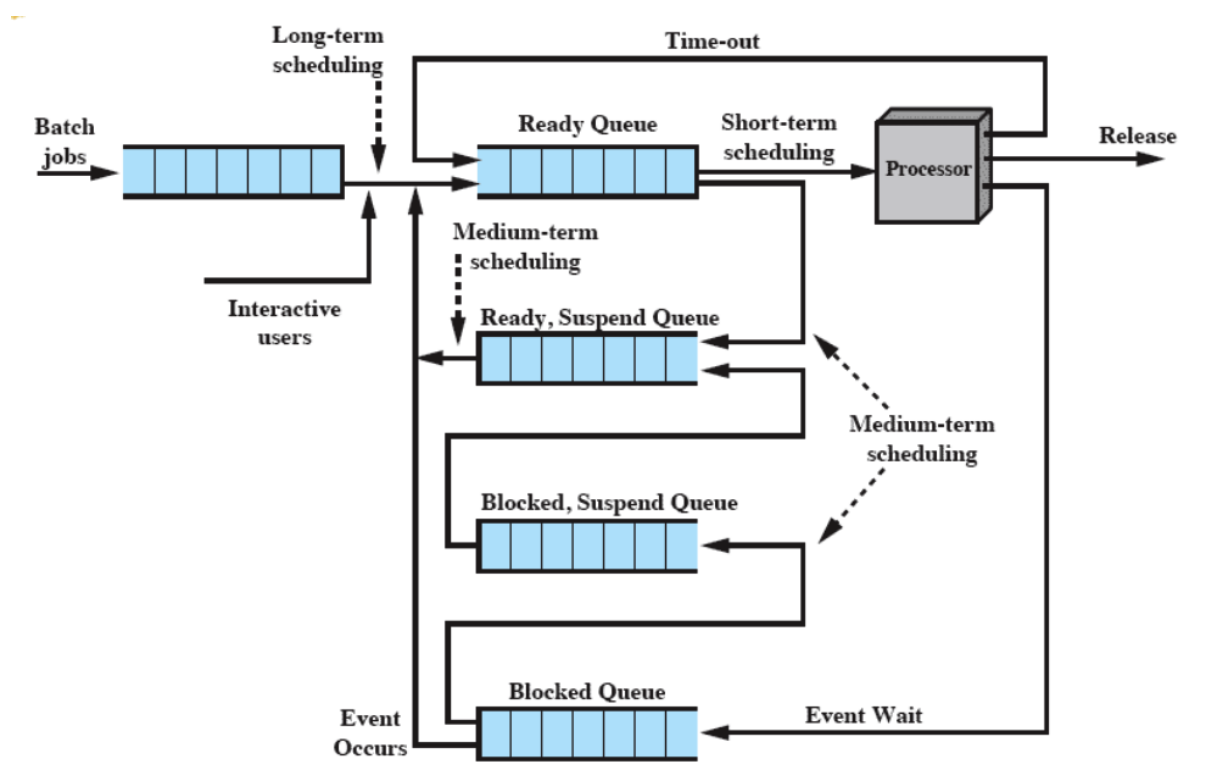
Quindi appena un processo viene creato interviene il long-term scheduling che decide se mandarli su RAM o su disco quindi o su Ready Queue o su Ready, Suspended Queue.
Poi il medium-term scheduling decide se da Ready Queue mandarlo in Ready, Suspende Queue e se da Blocked Queue mandarlo in Blocked, Suspended Queue. O vicerversa.
Lo short-term Scheduling manda i processi dai Ready Queue all’esecuzione sul processore.
Long-Term Scheduling
Decide quali programmi sono ammessi nel sistema per essere eseguiti.
- Spesso è FIFO, ovvero il primo che entra è anche il primo ad essere ammesso. Inoltre tiene anche conto della priorità o di altri fattori come le richieste I/O in sospeso.
- Controlla il grado di multiprogrammazione, quindi ad esempio potrebbe decidere di mettere un programma su disco perché la RAM è piena
- Più processi ci sono, più piccole saranno le percentuali di tempo per cui ogni processo viene eseguito. Va trovato quindi il giusto numero di processi in esecuzione.
Quali sono le tipiche strategie per i Long-Term Scheduler?
- I lavori non interattivi (batch) vengono messi in una coda e lo scheduler li prende man mano che lo ritiene giusto.
- I lavori interattivi vengono ammessi finché non si satura il sistema.
- Se si sa quali processi utilizzando molto I/O (I/O bound) o la CPU (CPU bound) allora si mantiene un giusto equilibrio fra i due.
Inoltre viene chiamato anche in altre occasioni oltre alla creazione di nuovi processi:
- Quando un processo termina
- Quando dei processi sono in idle da troppo tempo
Medium-Term Scheduling
Abbiamo detto che decide se spostare i processi tra running/blocked a suspended, quindi nello specifico se spostare un programma dalla RAM al disco e viceversa.
Anche qui ci basiamo sul grado di multiprogrammazione, se abbiamo troppi programmi magari alcuni verrano spostati su disco, oppure se ci sono pochi verranno presi alcuni dal disco e spostati su RAM.
Lo rivedremo quando faremo la memoria virtuale
Short-Term Scheduling
Viene chiamato anche dispatcher, è quello eseguito più frequentemente e viene invocato in seguito a degli eventi:
- Interruzioni di clock (fanno parte degli interrupt)
- Interruzioni I/O
- Chiamate di sistema
- Segnali
- Altri motivi…
Il suo scopo è quello di ottimizzare l’intero sistema decidendo che programma mandare in esecuzione, ma per valutare una politica di scheduling vanno definiti dei criteri:
Dobbiamo fare una distinzione tra Criteri Utente e Criteri Sistema:
Per utente:
- Tempo di risposta, ovvero quanto tempo passa tra la richiesta e il suo completamento. Per sistema:
- Uso efficiente del processore.
Un’altra distinzione che va fatta è Criteri Prestazionali e Criteri non Prestazionali
Prestazionali:
- Sono correlati alle prestazioni e facili da misurare, sono quantitativi, ad esempio si basano sul tempo di risposta e il throughput Non Prestazionali:
- Sono qualitativi e difficili da misurare come e si basano ad esempio sulla predicibilità e l’equità
Vediamo questi criteri:
-
Criteri Utente Prestazionali
- Turnaround Time (tempo di ritorno)
- Response Time
- Deadline (scadenza)
-
Criteri Utente Non Prestazionali
- Predictability
-
Criteri di Sistema Prestazionali
- Throughput (volume di lavoro nel tempo)
- Processor Utilization
-
Criteri di Sistema non Prestazionali
- Fariness (equità)
- Enforcing Priorities (gestione priorità)
- Balancing Resources (bilanciamento uso risorse)
Turn-Around Time
È il tempo che passa tra la creazione di un processo creato dall’utente e il suo completamento, questo comprende anche i vari tempi di attesa di I/O. È un criterio spesso utilizzato per i processi non interattivi.
Response Time
Questo è più utilizzato per i processi interattivi, è il tempo tra l’invio del programma e il suo completamento.
Lo scheduler ha due obiettivi in questo caso:
- Minimizzare il tempo di risposta
- Massimizzare il numero di utenti con un buon tempo di risposta
Deadline e Predicibilità
Ci sono dei sistemi operativi che ci permettono di dare una deadline ai processi, ovvero possiamo inserire un tempo massimo di esecuzione. Lo scheduler cerca di rispettare questo limite imposto dall’utente e il suo obiettivo è quindi quello di massimizzare il numero di scadenze rispettate.
Per quanto riguarda la predicibilità, l’utente non vuole che ci sia troppa variabilità nei tempi di risposta, ad esempio un programma ci mette 5 secondi e un altro 1, oppure se lanciamo più volte lo stesso programma ci aspettiamo sempre il solito tempo di esecuzione. Ovviamente con alcune eccezioni particolari come ad esempio RAM satura.
Throughput
È il numero di processi che il sistema riesce a completare in un certo tempo, lo scheduler ovviamente vuole massimizzare questo valore. Ci dà una misura su quanto lavoro viene effettuato e ovviamente dipende anche dai tempi di esecuzioni dei processi
Utilizzo del Processore
È la percentuale di tempo in cui il processore viene utilizzato, lo scheduler deve fare in modo che il processore sia in idle il minor tempo possibile, quindi deve fare in modo che ci siano processi ready.
Questo è molto utile su sistemi condivisi tra più utenti.
Bilanciamento Risorse
Lo scheduler deve fare in modo che le risorse vengano usate il più possibile, quindi ad esempio favorire i processi che useranno per meno tempo una risorsa che in quel momento è poco utilizzata.
Fairness e priorità
Se non ci sono specifiche sulla priorità allora tutti i processi devono essere trattati allo stesso modo, se c’è vanno favoriti quelli con priorità più alta, ogni priorità avrà una coda.
Non deve verificarsi starvation ovvero come detto prima, processi che aspettano la loro esecuzione senza mai andarci.
Priorità e Starvation
Da notare che la priorità può causare la starvation, infatti un processo a bassa priorità potrebbe soffrire di starvation a causa di un processo a priorità più alta, come soluzione possiamo fare in modo che man mano che “l’età” del processo aumenta, aumenta anche la sua priorità. Oppure anche in base a quante volte è andato in esecuzione.
Algoritmi di Scheduling
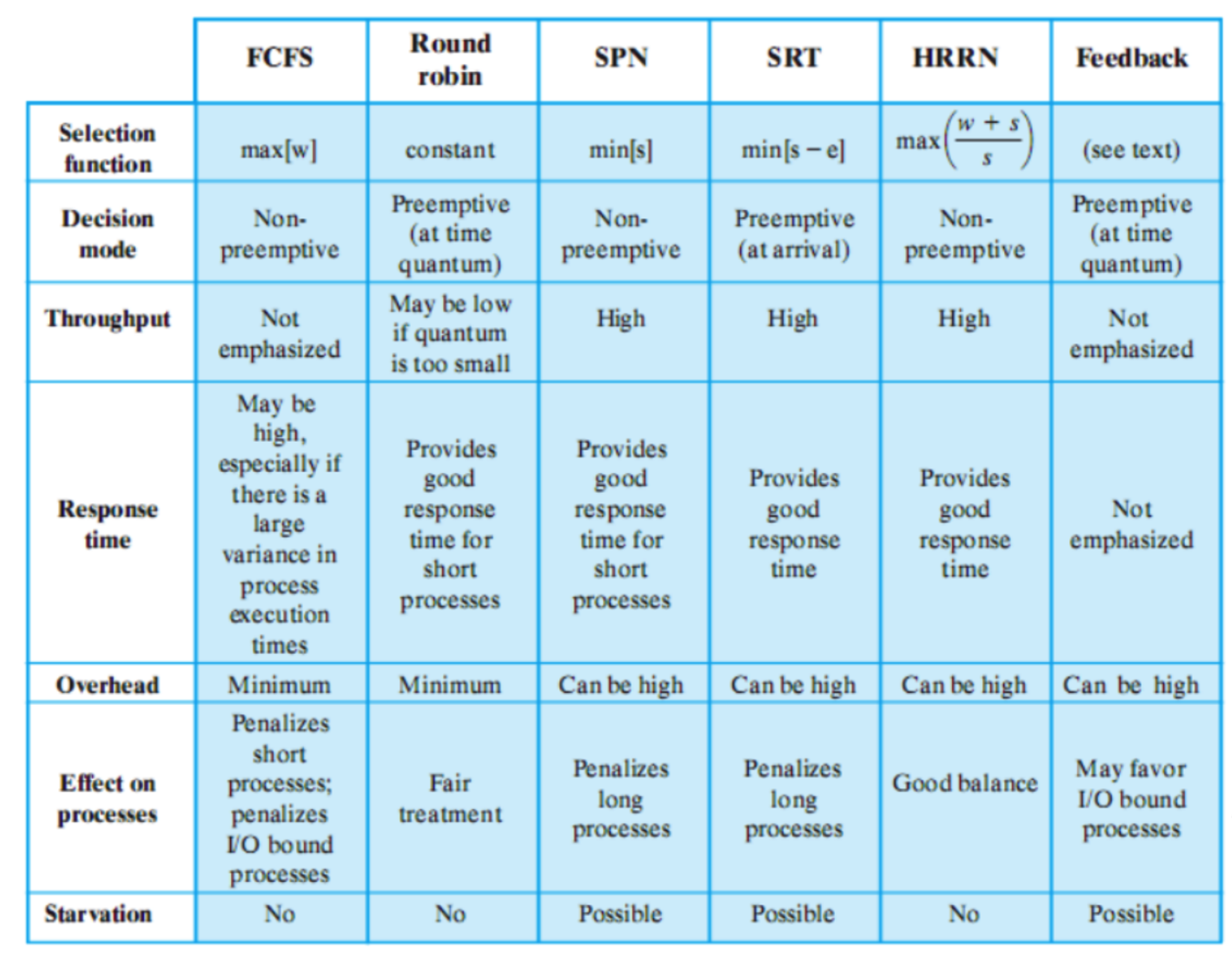
Le colonne ci indicano i vari algoritmi, le prime due righe ci spiegano come vengono effetuate quelle decisioni mentre per le altre abbiamo delle descrizioni
Funzione di Selezione
È quella che sceglie il processo da mandare in esecuzione, si basa sulle caratteristiche dell’esecuzione, ecco alcuni paramentri:
- : Tempo trascorso in attesa
- : Tempo trascorso in esecuzione
- : Tempo totale richiesto
Quindi appena un processo nasce avremo mentre per o viene effettuata una stima o viene fornita una deadline.
Modalità di Decisione
Specifica quando viene invocata la funzione di selezione, abbiamo due modalità:
- Non-Preemptive: Se un processo è in esecuzione allora arriva o a fine terminazione o ad una richiesta bloccante
- Preemptive: Il sistema operativo può interrompere un processo in esecuzione e mandarlo in stato di ready. Questo blocco può avvenire o per l’arrivo di nuovi processi o per un interrupt:
- Interrupt I/O: Un processo blocked diventa ready
- Clock Interrupt: Avviene in modo periodico per evitare che un processo monopolizzi il sistema
Esempi
FCFS: First Come First Served
Tutti i processi vengono aggiunti alla coda dei processi ready e quando un processo smette di essere eseguito si passa a quello che ha aspettato di più in coda. È non-preemptive quindi si passa ad un altro solo se termina o per interrupt.
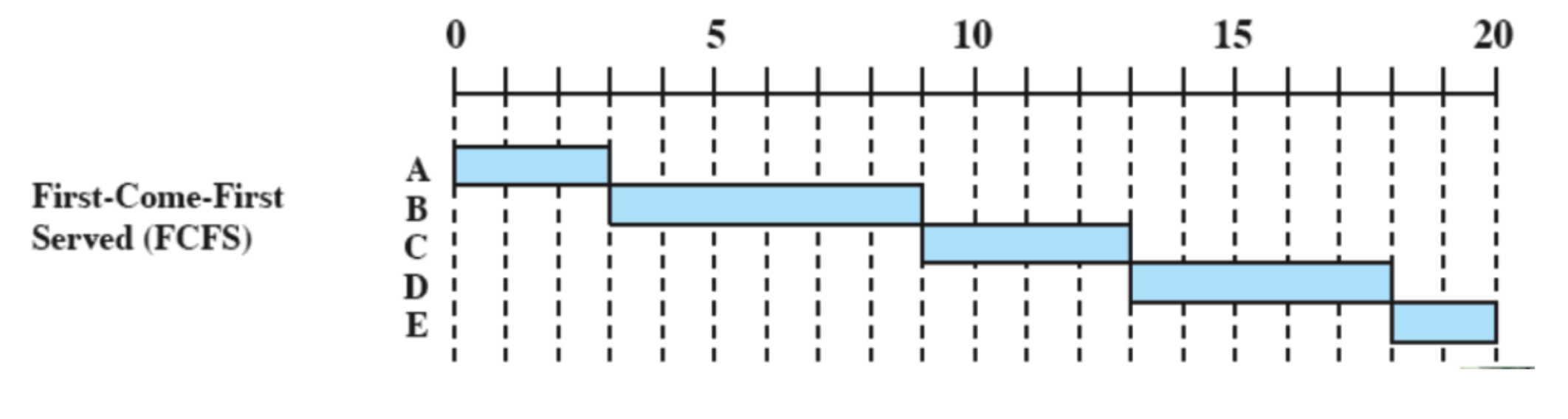
Quali sono i principali problemi?
- Un processo con poco tempo di esecuzione potrebbe dover attendere molto tempo prima di andare in esecuzione, in questo esempio
- Favorisce i processi CPU-Bound infatti dopo che uno di questi prende la CPU non la libera finché non viene interrotto o termina.
Round-Robin
Usa la preemption basandosi su un clock, spesso viene anche chiamato time slicing perché ogni processo ha una “fetta” di tempo prestabilita.
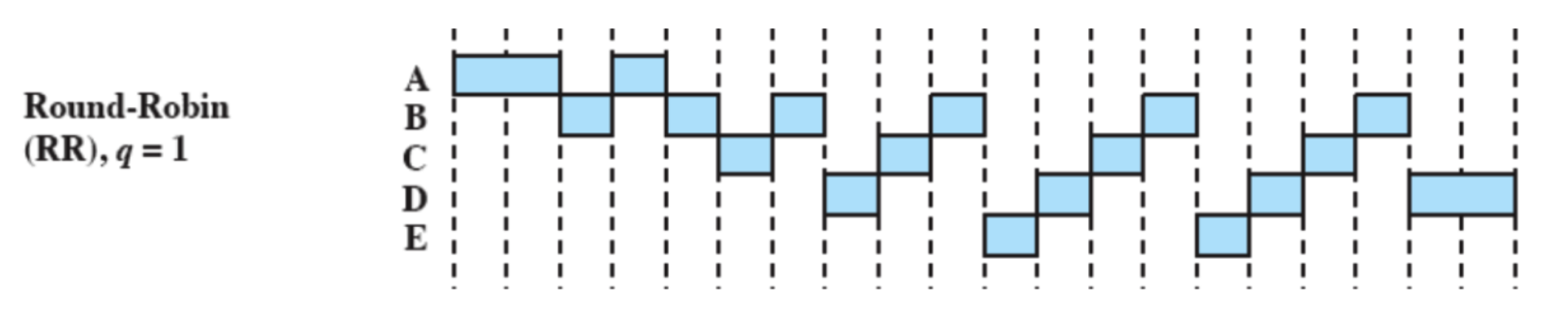
Inizialmente c’è solo quindi dopo una “fetta” interviene lo scheduler ma sceglie comunque . Successivamente invece notiamo che viene sempre scelto un processo diverso tranne alla fine quando accade la stessa situazione iniziale ma con .
Notiamo che il problema di prima con che è molto corto non si presenta, infatti viene eseguito non molto lontano dalla sua richiesta.
Le interruzioni di clock vengono generate a intervalli periodici e quando ne arriva una il processo in esecuzione viene messo in stato di ready e viene selezionato il nuovo processo da eseguire. Ovviamente se prima del clock arriva un interrupt I/O allora questo viene messo nella coda blocked.
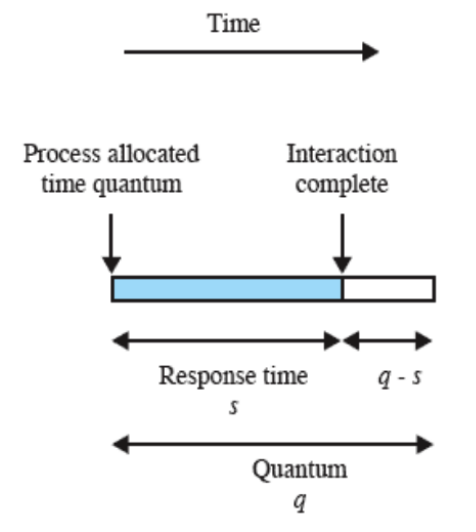
Questa “fetta di tempo” che diamo ad ogni processo, quanto deve essere lunga?
In generale deve essere poco più grande del tempo di interazione di un processo. Quindi ad esempio:
Dove Quantum q indica la “fetta di tempo”. Se invece prendiamo dei valori non corretti accade questo:
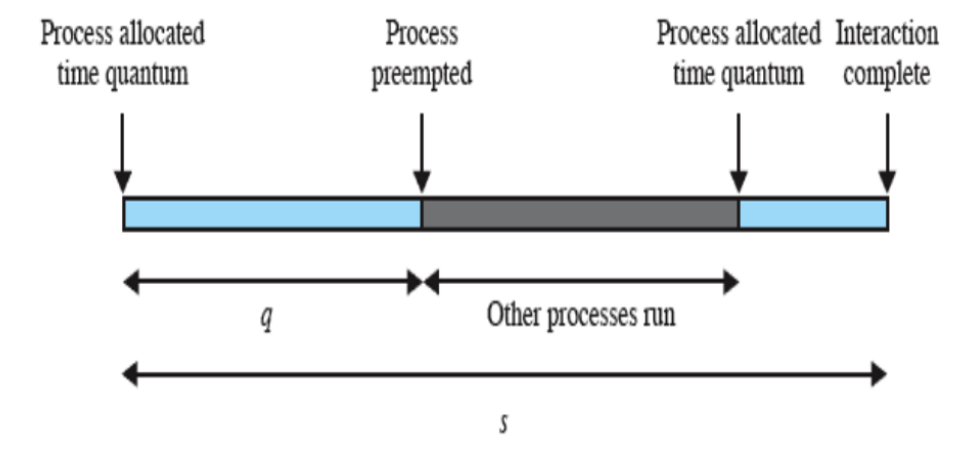
Non avremo uno scheduler molto ottimale, infatti interromperà i processi prima della loro terminazione.
Scelta del "Quanto di Tempo"
In generale deve essere poco più lungo del tempo medio di interazione per un processo, ma non troppo lungo perché potrebbe durare più del tipico processo e in quel caso il Round-Robin degenera in un FCFS.
Come abbiamo visto prima il FCFS favorisce i processi CPU-Bound ovvero con poche richieste bloccanti, questo accade anche con il Round-Robin, infatti se un processo fa poche richieste I/O significa che questo userà al massimo il suo quanto di tempo.
Questo però significa che i processi I/O Bound sono poco favoriti e inefficienti.
Una soluzione proposta è il Round-Robin virtuale:
- Se un processo fa una richiesta bloccante durante il suo tempo, il processo non va in coda di ready ma in un’altra che ha priorità su quella ready.
A livello implementativo abbiamo:
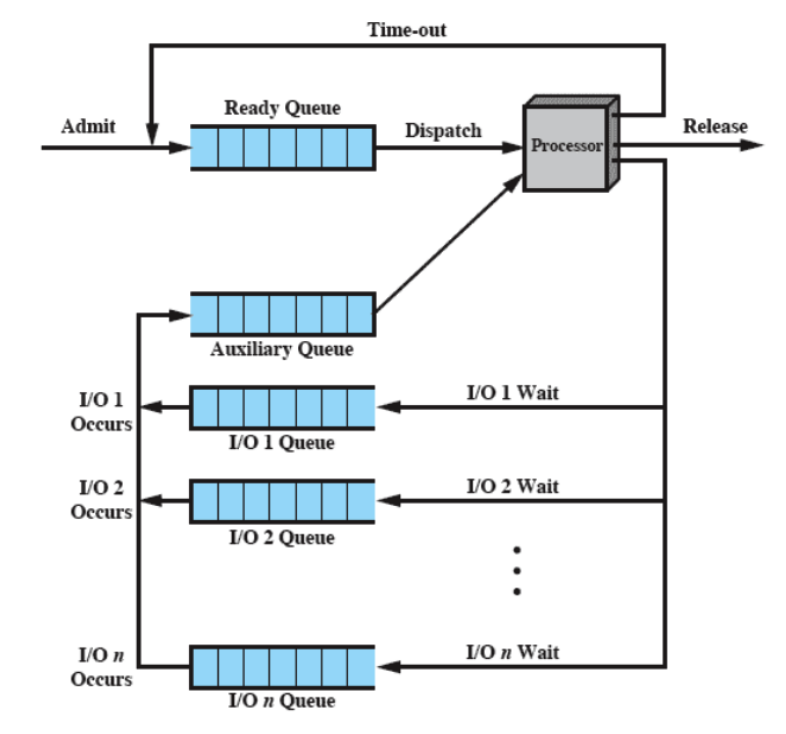
In questo modo quindi evitiamo di favorire i processi CPU-Bound e garantire più equità.
Da notare però che i processi che vengono mandati in esecuzione da questa coda ausiliaria non hanno a disposizione un intera fetta di tempo ma soltanto quello che gli rimaneva quando hanno effettuato la richiesta.
Ad esempio: Il processo ha 5 ms di tempo e a 3ms fa una richiesta I/O quindi va nella coda ausiliaria, quando viene rimandato in esecuzione avrà a disposizione soltanto 5-3 ms quindi 2ms.
SPN: Shortest Process Next
Come suggerisce il nome, il prossimo processo da mandare in esecuzione è quello più breve, per fare questo, quando un processo nasce deve dire quanto tempo impiegherà a terminare. È consigliato quindi per processi batch.
Grazie a questo scheduler i processi corti verranno eseguiti prima di quelli più lunghi, inoltre è non-preemptive quindi una volta iniziato un processo questo o termina o fa una qualche richiesta bloccante.
Quindi prendendo l’esempio di prima, i processi verranno eseguiti nel seguente modo:

Quali sono i problemi di questo tipo di scheduler?
- Prima abbiamo visto un criterio utente non prestazionale, la predicibilità, ovvero che il tempo di risposta medio di un processo sia sempre lo stesso. Con questo tipo di scheduling riduciamo la predicibilità dei processi lunghi, infatti se ci sono molti processi corti questi avranno la precedenza. Per questo motivo potrebbe anche verificarsi starvation sui processi lunghi.
- Se un processo fornisce un tempo di esecuzione inesatto, il sistema operativo può abortire il processo.
Se il processo, quando nasce, non fornisce un tempo di esecuzione possiamo comunque effettuare una stima? Si con il seguente metodo, usiamo il passato per predire il futuro :
Ma per eseguire questo metodo il dispatcher deve mantenere tutti i valori dei tempi di risposta di ciascun processo e questo potrebbe occupare molta memoria. Possiamo però calcolare questa media in un altro modo:
Quindi si deve ricordare soltanto l’ultimo tempo e l’ultima stima per ciascun programma.
Adesso se in questa formula chiamiamo possiamo scrivere:
Se la scomponiamo, otteniamo:
Questo si chiama Exponential Averaging e serve a far pesare di più le istanze più recenti.
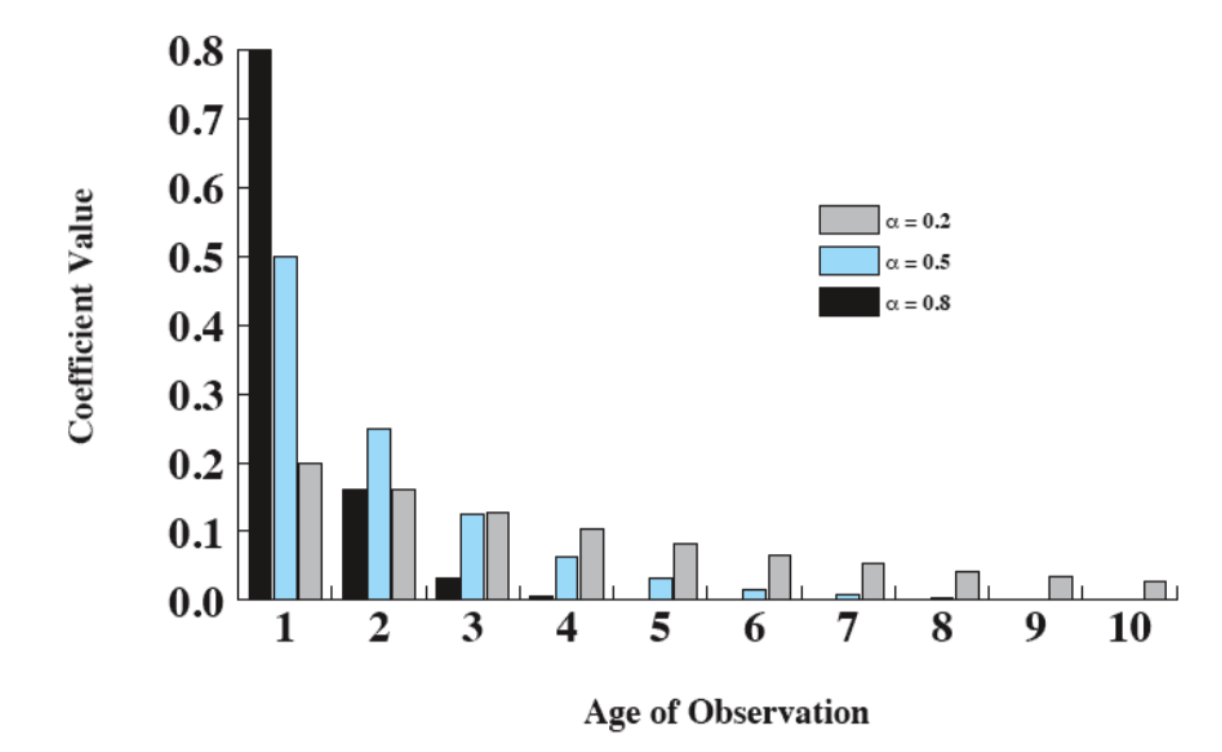
Notiamo quindi che i valori passati, soprattutto con grandi vengono dimenticati più velocemente.
Vediamo le differenze:
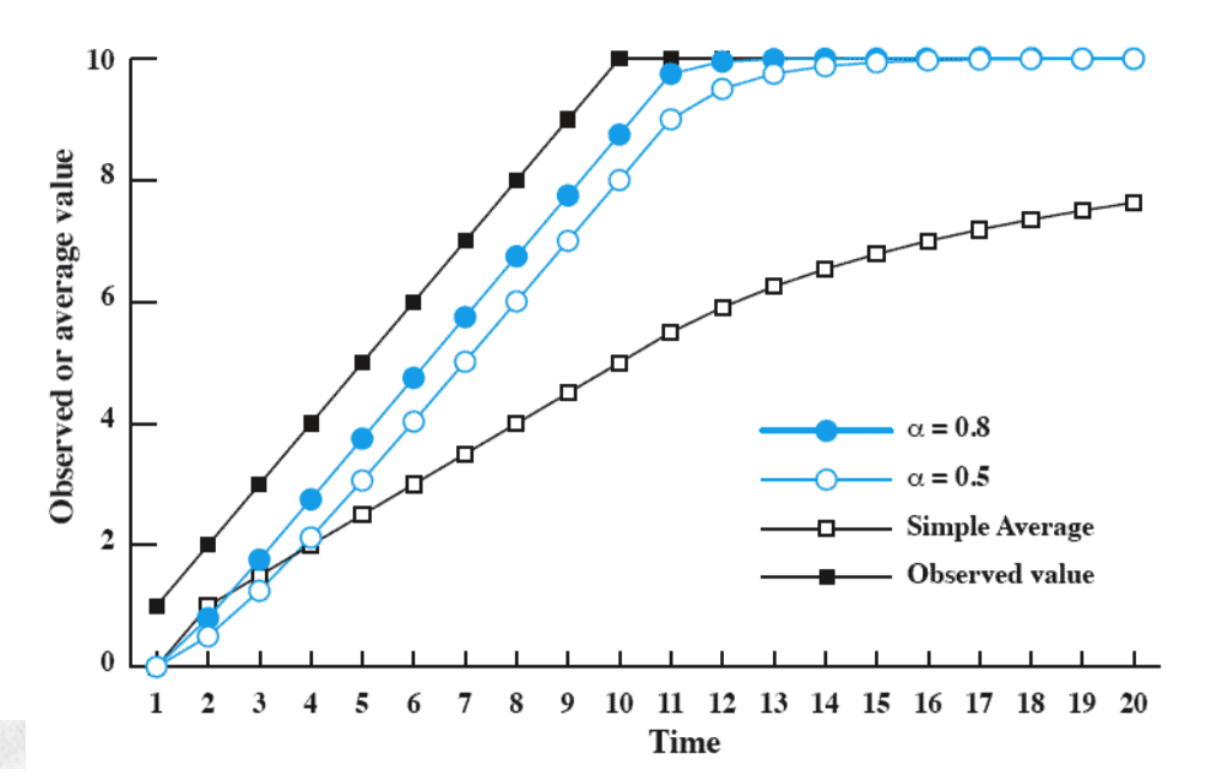
In nero abbiamo i tempi di esecuzione del processo, vediamo quindi che i primi 10 avvii hanno un tempo che cresce e poi si stabilizza.
Se effettuiamo una semplice media (quadrati neri vuoti) notiamo che la predizione è molto lontana dai veri valori.
Se invece utilizziamo degli fissi vediamo che i valori sono molto vicini.
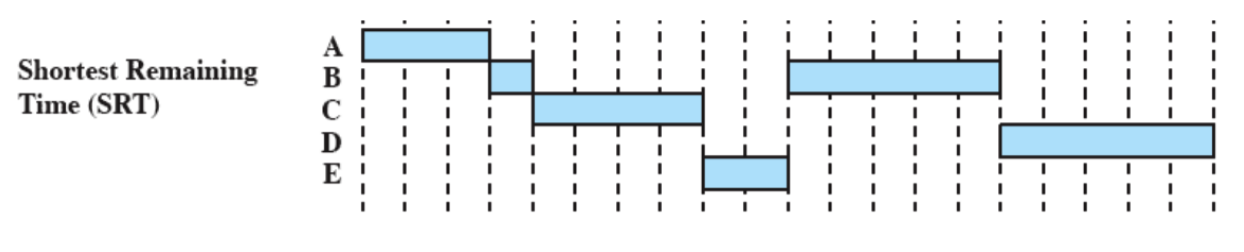
SRT: Shortest Remaining Time
Funziona come l’SPN ma è preemptive, a differenza di altri però non ha una time quantum ma si basa sul fatto che arrivi un nuovo processo, quindi quando ne arriva un altro si fa un controllo.
Viene effettuata una stima sul tempo rimanente di esecuzione e prende quello con il tempo più breve.
HRRN: Highest Response Ratio Next
Anche questo algoritmo necessita di conoscere il tempo di risposta di un processo, in questo caso non abbiamo starvation.
In questo algoritmo si sceglie il processo che ha come valore più alto:

In generale quindi non guarda soltanto quanto ci metterà il processo ma anche quanto ha aspettato.
Scheduling Tradizionale in UNIX
In UNIX abbiamo diversi algoritmi di scheduling usati insieme, nello specifico combina la priorità con il Round Robin:
- Un processo resta in esecuzione per al massimo un secondo a meno che non termini o si blocchi.
- Ci sono diverse code per ogni priorità e per ogni coda si fa un Round-Robin
- Ogni secondo vengono ricalcolate le priorità, quindi più uno resta in esecuzione più la sua priorità viene abbassata.
- Le priorità iniziale vengono stabilite in base al tipo di processo:
- Swapper (alta), gestisce la memoria virtuale
- Controllo dispositivi I/O a blocchi (dischi)
- Gestione file
- Controllo dispositivi I/O a caratteri (tastiera)
- Processi Utente (bassa)
Formula di Scheduling (ricalcolo delle probabilità)
Che utilizziamo nella formula:
Abbiamo:
- indica il numero del processo
- indica quanto il processo ha usato il processore nell’intervallo , usa exponentiale averaging, questo viene incrementato di ogni di secondo
- indica la categoria del processo vista prima
- , un processo può indicare questo valore per “autodeclassarsi” e dare spazio ad altri processi, quindi se ne dichiara uno maggiore di 0 questo andrà ad alzare il valore della priorità dato che vanno da 0 a 4 dove 0 è il più alto. Di solito è utilizzato in processi di sistema dove il S.O. sa che può toglierli precedenza se serve
Esempio
Hanno tutti lo stesso livello di e di quindi:
- Arriva per primo e viene mandato in esecuzione, mentre gli altri non sono in esecuzione il loro valore di non viene incrementato di mentre si.
- Arriva l’interrupt dopo un secondo quindi il suo valore diventa e nella priorità viene ridiviso per 2 e sommato a quindi di priorità.
- Viene quindi scelto dato che è arrivato prima di e ha priorità più bassa di .
- Vengono effettuati gli stessi passaggi di prima…
Architetture Multiprocessore
Cosa succede quando abbiamo computer multiprocessore? Vediamo i diversi tipi di macchina:
- Cluster: Ogni processore ha la sua RAM e una rete locale.
- Processori Specializzati: Ad esempio ogni I/O ha un suo processore
- Multiprocessore e/o multicore: Condividono la RAM e c’è un solo sistema operativo che controlla tutto. Vedremo nello specifico questo tipo di macchine.
Prima avevamo dei processi ready e dovevamo decidere quale mandare in esecuzione, adesso dobbiamo anche decidere su quale processore. Vediamo come assegnare i processori.
Assegnamento Statico
- Quando un processo viene creato gli viene assegnato un processore e per tutta la sua durata andrà sempre in esecuzione su di lui.
- Possiamo utilizzare uno scheduler per ogni processore
- Come vantaggio abbiamo che è semplice da realizzare e poco overhead (lavoro aggiuntivo)
- Come svantaggio abbiamo che qualche processore può rimanere in idle, causato appunto dal fatto che scegliamo sempre lo stesso processore per ogni processo.
Assegnamento Dinamico
- Nel corso della sua esistenza un processo può essere spostato su un altro processore
- È più complesso da realizzare
Questo metodo può andare bene sui processi utente, ma per quelli del sistema operativo?
Questi potrebbero essere eseguiti sullo stesso processore in modo da essere realizzabile più facilmente, però potrebbe causare bottleneck dato che ha più carico rispetto agli altri e inoltre se quel processore va in errore o smette di funzionare, si blocca tutto il sistema operativo.
È più ragionevole quindi eseguire il sistema operativo su più processori anche se causa un maggiore overhead dato dal fatto che il S.O. viaggia in continuazione.
Scheduling in Linux
Linux vuole velocità di esecuzione in modo semplice a livello implementativo e per questo non utilizza long-term o medium-term scheduling.
C’è una via di mezzo di long-term:
- Quando un processo viene creato questo viene aggiunto alla coda appropriata e se non viene creato è perché la memoria è satura.
In Linux come code abbiamo le runqueues e le wait queues che corrispondono rispettivamente alla coda dei ready e a quella dei suspended. Infatti nelle wait vengono messi i processi quando effettuano una richiesta che implica un’attesa, mentre le run queues sono quelle da cui il dispatcher prende i processi da eseguire.
Da notare che in architetture multiprocessori, ogni processore avrà la sua runqueues ma le wait sono in comune fra tutti.
Come quello di UNIX è preemptive quindi a “quanto di tempo” e con priorità dinamica:
- Questa decresce man mano che un processo viene eseguito
- Cresce man mano che non viene eseguito
Implementa delle correzioni per avere:
- Operazione in quasi e quindi costante
- Servire in modo appropriato i processi real-time
Come?
Riceve un interrupt hardware ogni 1ms:
- Se più lungo ci sono problemi per i real-time
- Se più corto arrivano troppi interrupt e si passa troppo tempo in Kernel Mode
Il quanto di tempo per ciascun processo è un multiplo di 1ms.
Per capire questo multiplo dobbiamo vedere i vari tipi di processi:
- Interattivi:
- Quando si agisce sul programma bisogna dargli la CPU entro 150ms
- Altrimenti per l’utente sembrerà che il programma non sia reattivo
- Batch:
- Sono penalizzati dallo scheduler, infatti l’utente non dovendo usare il programma attivamente non ricerca reattività
- Real Time:
- I 2 tipi precedenti vengono individuati da Linux in modo autonomo tramite dei suoi metodi, per questo tipo di processi invece deve essere presente la system call
sched_setschedulernel codice sorgente. - Normalmente sono utilizzati solo dai KLT (Kernel Level Thread) di sistema.
- I 2 tipi precedenti vengono individuati da Linux in modo autonomo tramite dei suoi metodi, per questo tipo di processi invece deve essere presente la system call
Tutti possono essere CPU - I/O Bound
Per quanto riguarda lo scheduling quindi ci sono 3 classi:
- SCHED_FIFO e SCHED_RR per i processi real time
- SCHED_OTHER per tutti gli altri
Prima si eseguono i processi con scheduler SCHED_FIFO e SCHED_RR poi andiamo a vedere gli altri:
- Le prime due classi abbiamo un livello di priorità da 1 a 99 mentre per la terza da 100 a 139.
- Ci sono quindi 140 runqueues, 140 per ogni processore. In alcuni casi è presente anche una con priorità 0 per casi particolari.
- Si passa dal livello al livello solo se o non ci sono processi in o nessun processo in è in stato di RUNNING.
La preemption è dovuta a 2 casi:
- Si esaurisce il “quanto di tempo” per il processo
- Un altro processo passa da uno stato blocked a RUNNING
Nel secondo caso, molto spesso il processo che ha cambiato stato verrà eseguito dal processore (ad esempio è stato mandato un comando da tastiera e quindi entro 150ms il sistema operativo deve dargli il processore). Ad esempio se abbiamo un editor di testo un compilatore verrà data precedenza all’editor di testo.
Regole Generali
La classe SCHED_FIFO non viene bloccato da interrupt, un processo viene rimesso in coda solo se si blocca per qualche richiesta o viene mandato in RUNNING un processo prioritario altrimenti non viene fermato.
Gli altri processi funzionano normalmente a “quanti di tempo” compresa la classe SCHED_RR, quindi questi vengono rimessi in coda anche quando finiscono il loro tempo.
I processi real-time non cambiano mai priorità mentre gli SCHED_OTHER si, ovvero man mano che vanno in esecuzione la loro priorità decresce.
In sistemi multi CPU c’è un sistema periodico che ridistribuisce il carico se necessario, anche se l’assegnamento è statico.
Gestione della Memoria
Per evitare problemi nella scrittura di programmi, è il sistema operativo a gestire la memoria, questo dà un’illusione ai vari processi facendogli credere che hanno a disposizione l’intera memoria.
Per fare questo il sistema operativo “appoggia” alcuni processi sul disco, questo ovviamente rallenta le operazioni e quindi il sistema operativo devi pianificarlo in modo efficiente e fare in modo di avere più processi possibili in RAM.
Come realizziamo questo?
- Rilocazione: Deve esserci un “aiuto” da parte dell’hardware quindi s.o. e hardware devono collaborare (devono esserci istruzioni macchina utili)
- Protezione
- Condivisione
- Organizzazione Logica
- Organizzazione Fisica
Rilocazione
Il programmatore non sa e non deve sapere in quale zona della memoria il programma che sta scrivendo verrà caricato, potrebbe anche andare sul disco e poi tornare in RAM in una posizione diversa a prima.
I riferimenti in memoria delle istruzioni macchina non sono i veri indirizzi in RAM, c’è un’operazione che prende quell’indirizzo e lo traduce in un vero indirizzo in RAM. Questa operazione può essere fatta o in preprocessing ad esempio a compilazione o a run-time, se siamo in questo caso c’è bisogno di supporto hardware.
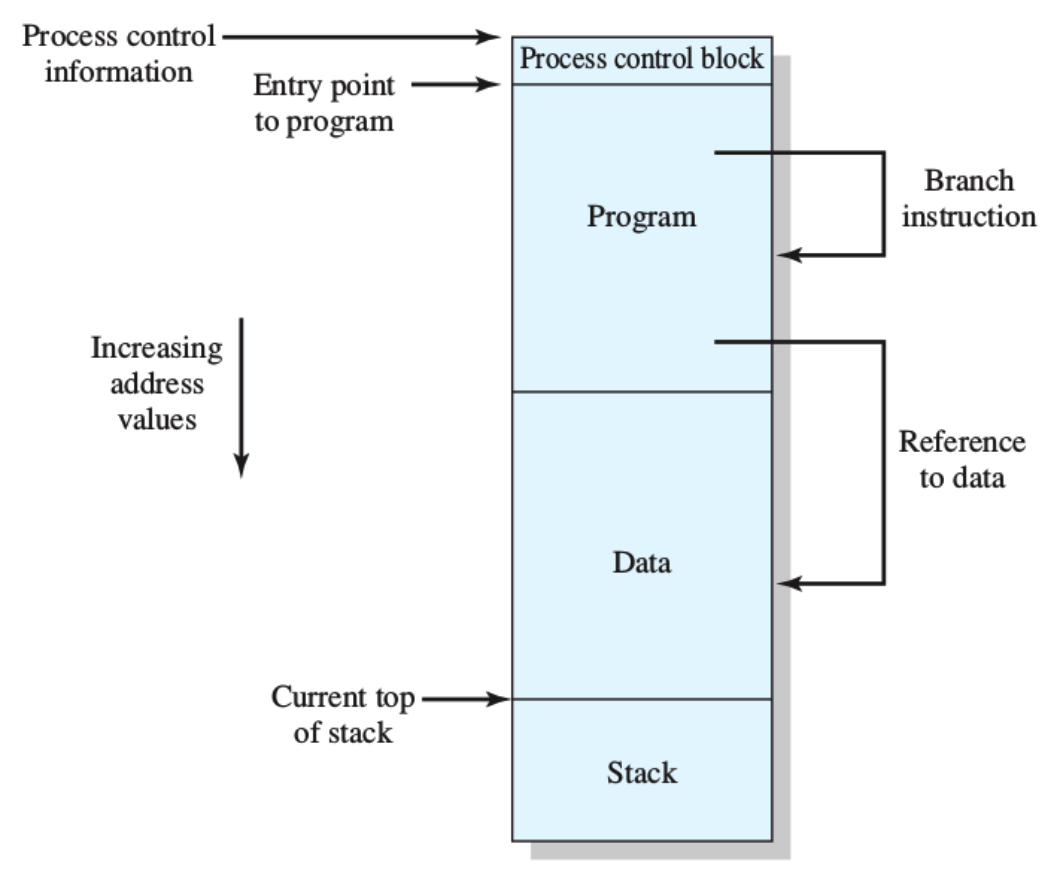
Gli indirizzi che abbiamo nel programma sono o indirizzi di salto ad altre istruzioni o riferimenti a dati. Tutti questi indirizzi vanno ricalcolati per garantire la rilocazione.
Come funziona?
Il programma è scritto in moduli e può utilizzare anche librerie statiche presenti nel sistema operativo. Ogni modulo viene compilato separatamente generando un file oggetto ciascuno e tutti vengono collegati da un linker per creare un programma eseguibile chiamato load-module (può essere caricato in RAM).
Il Loader prende un file su disco e lo carica in RAM, potrebbe esserci bisogno di librerie dinamiche che vengono chiamate a tempo di esecuzione.
Ogni modulo è formato da un blocchetto che ha codice sorgente e dati condivisi, non essendo in esecuzione non ha lo stack. Notiamo che all’inizio abbiamo indirizzi simbolici e quando diventa eseguibile abbiamo più possibilità:
- Diventano indirizzi assoluti (b) e non funziona bene in sistemi operativi moderni, dobbiamo sapere da dove parte il programma.
- Diventano indirizzi relativi (c), ogni processo inizia, secondo lui, da 0.
- Indirizzi relativi e rilocazione (d), ogni processo inizia da un indirizzo e i suoi indirizzi diventano il valore specificato.
Gli indirizzi li denominiamo:
- Logici: Il riferimento in memoria è indipendente dall’attuale posizionamento del programma in memoria, si trovano nelle istruzioni ma hanno bisogno di “traduzione”
- Relativi: Il riferimento è espresso come uno spiazzamento rispetto ad un punto fisso, sono un caso particolare degli indirizzi logici.
- Fisici o Assoluti: Riferimento effettivo ad un indirizzo in memoria, non ha bisogno di traduzione.
Le soluzioni più recenti fanno in modo che gli indirizzi assoluti vengano calcolati soltanto nel momento in cui si fa riferimento alla memoria ma serve hardware dedicato.
Esempio
Il Sistema Operativo da un valore al Base Register che è da dove inizia il processo, poi ad ogni indirizzo del codice aggiunge questo valore, quindi se inizia da 1500 e c’è un jump 400, questo diventerà un jump 400+1500.
Per fare questo e permettere anche i cambi di locazione, il sistema operativo deve sempre mantenere aggiornato il valore all’interno del Base Register.
I valori di Base e Bounds Register (indirizzo fine processo) si trovano all’interno del PCB del processo e i loro valori vengono impostati durante il process switch, va sempre mantenuto il valore iniziale corretto del processo in esecuzione.
Protezione
I processi non devono poter accedere a locazioni di memoria di altri processi a meno che non siano autorizzati. A causa della rilocazione non sappiamo in che zona di memoria si troverà il processo al momento di esecuzione e quindi anche qui abbiamo bisogno di un supporto hardware
Condivisione
Contrario della Protezione, alcuni processi devono poter comunicare fra loro quindi hanno delle zone di memoria condivise con gli altri processi.
In alcuni casi questo è previsto dallo sviluppatore del programma mentre in altri è il sistema operativo a decidere questo, ad esempio quando eseguiamo lo stesso programma più volte e quindi hanno lo stesso codice sorgente, conviene quindi mettere in memoria il codice una sola volta e far accedere tutte le istanze a quel blocco.
Organizzazione Logica
A livello hardware la memoria è organizzata in modo lineare però a livello software, nei programmi, ci accediamo tramite variabili, inoltre i programmi possono essere scritti in vari moduli con diversi permessi. Il sistema operativo deve fare “da ponte” tra come è organizzata la memoria nell’hardware a come la vogliamo vedere ad alto livello.
Organizzazione Fisica
Si occupa del flusso di dati tra RAM e Memoria Secondaria (Hard Disk ecc…).
Non se ne può occupare il programmatore, infatti la memoria potrebbe non essere sempre sufficiente a contenere il programma e c’era bisogno dell’overlaying, ovvero il programmatore doveva dividere il codice in moduli e fare in modo che venissero posizionati nella stessa zona di memoria in tempi diversi, era molto difficile da programmare.
Adesso se ne occupa il Sistema Operativo, quindi possiamo richiedere tutte le risorse che vogliamo anche non sapendo quanta memoria avremo a disposizione. Come lo fa?
Vedremo diversi tipi di strategie utilizzate per gestire la memoria, fino alla memoria virtuale che è quella usata oggi.
Il problema di cui ci occupiamo adesso è quindi di avere un numero di processi e di volerli posizionare tutti in memoria, ma questa non può contenerli tutti.
Partizionamento
Era uno dei primi metodi, esistono diversi tipi:
- Partizionamento fisso
- Partizionamento dinamico
- Paginazione semplice
- Segmentazione Semplice
- Paginazione con memoria virtuale
- Segmentazione con memoria virtuale
Partizionamento Fisso
Possiamo dividerlo in altre due categorie, ma vediamo come funziona.
Le partizioni vengono create all’accensione del PC e rimangono uguali fino al suo spegnimento.
Abbiamo tutte partizioni di uguale lunghezza, se un processo ha una dimensione minore o uguale alla misura allora può essere caricato in una partizione libera, quando un processo viene sospeso, si libera la partizione da lui occupata e viene portato sul disco.
Se un processo era troppo grande, il programmatore doveva usare l’overlaying visto prima.
Questo era già un problema di questa tecnica, inoltre c’è un uso inefficiente della memoria, se un programma usava ad esempio anche solo 5kb gli veniva comunque data una partizione di dimensione fissa, ad esempio 8mb. Questo problema si chiama Frammentazione Interna
Partizionamento Fisso Variabile
Non risolve i problemi ma li diminuisce.
Appena accendiamo il PC vengono create le partizioni, fino al suo spegnimento rimangono uguali, in questo caso però le partizioni hanno dimensioni diverse.
Possiamo quindi inserire programmi più piccoli in partizioni più piccole, riducendo la frammentazione interna e inoltre avendo partizioni più grandi, alcuni programmi non richiederanno overlaying.
Abbiamo bisogno però di un algoritmo per decidere su quale partizione mettere un processo
Nel caso di partizioni di uguale lunghezza non ne abbiamo bisogno. Nel caso di diverse lunghezza dobbiamo:
- Trovare la partizione più piccola che lo contiene
- Creare una coda per ogni partizione, oppure una per tutte
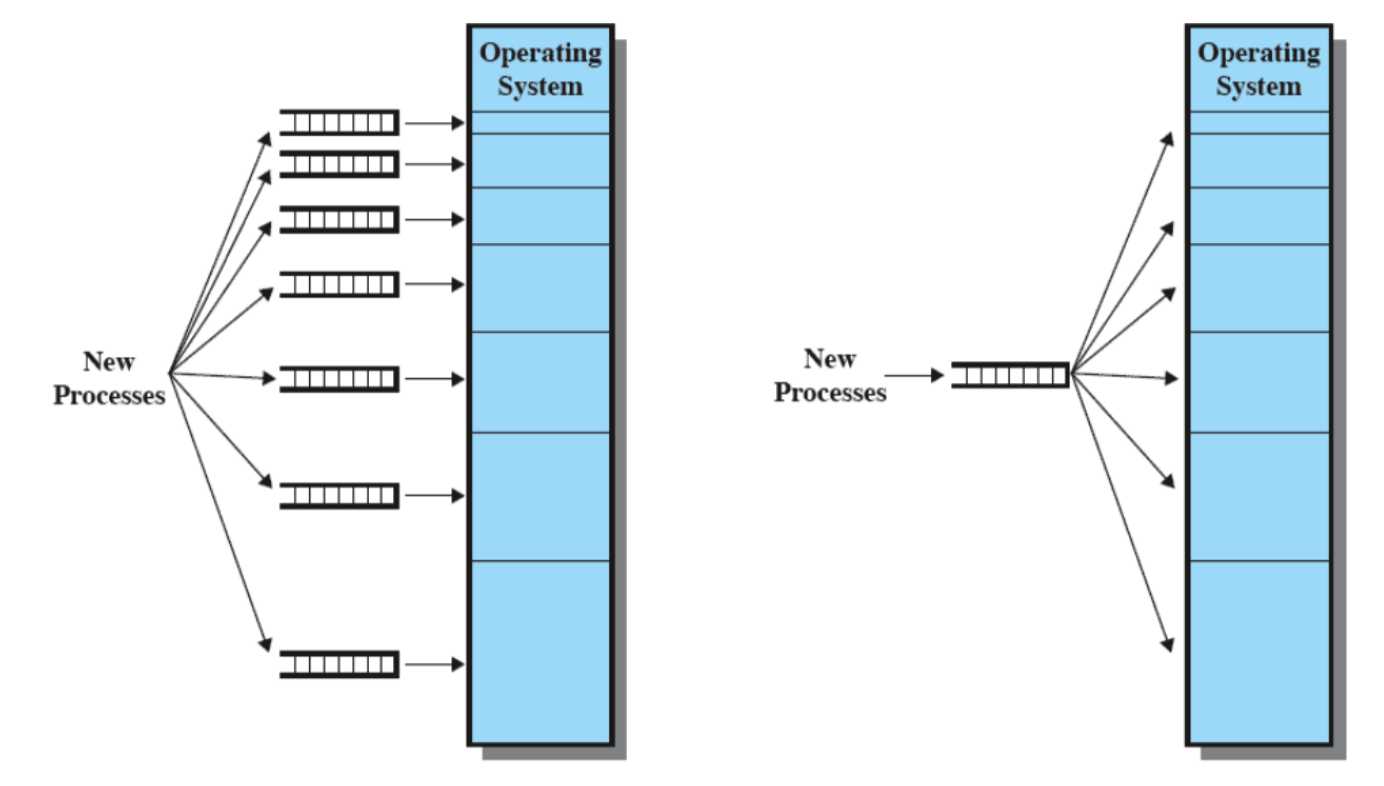
Quindi quali sono i problemi principali che persistono?
- Numero massimo di processi in memoria, ovvero il numero di partizioni deciso all’inizio
- Se ci sono molti processi piccoli, usiamo la memoria in modo inefficiente
Partizionamento Dinamico
Qui le partizioni variano in misura e in quantità e per ciascun processo viene allocata esattamente la quantità di memoria che gli serve.
Vediamo un esempio
Questo è come si presenta la memoria inizialmente, quindi troviamo soltanto la partizione del sistema operativo.
Arrivano in ordine i 3 processi e gli vengono allocate delle partizioni uguali allo spazio di cui hanno bisogno.
Arriva un processo P4 che ha bisogno di 8MB, non sono disponibili, il sistema operativo decide di spostare P2 sul disco e dare spazio a P4.
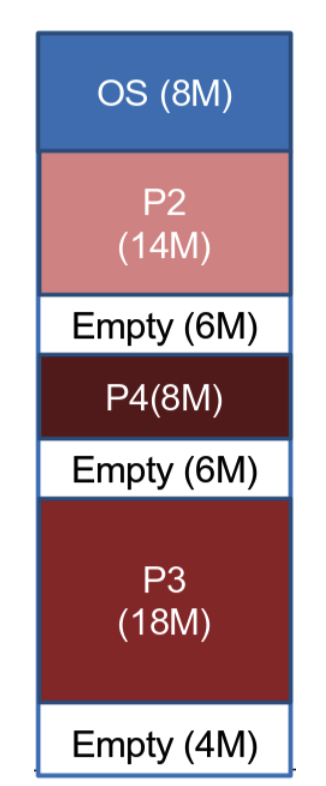
È tornato P2 e il S.O. ha deciso di rimuovere P1 per dargli spazio in memoria.
Un problema che abbiamo adesso è che abbiamo si 16MB di memoria liberi ma non sono “successivi” quindi se arriva ad esempio un processo da 8MB non può essere allocato in memoria. Questo si chiama Frammentazione Esterna.
Possiamo risolvere questo problema con la compattazione, ovvero ad un certo punto il S.O. quando vede che la memoria è troppo frammentata interviene riorganizzando la memoria, questo però porta a molto overhead.
Un altro problema, sempre prendendo l’esempio di prima, è che se arriva un processo più piccolo, ad esempio 3MB, dobbiamo decidere dove metterlo, in quale blocco conviene di più? Si potrebbe pensare di inserirlo in quello più piccolo che lo contiene in modo da sprecare meno memoria ma in realtà questo porta ai risultati peggiori (algoritmo best-fit), questo perché lascia dei frammenti molto piccoli costringendo a fare spesso compattazione.
Un algoritmo migliore è il first-fit ovvero scorre la memoria dall’inizio e lo inserisce nel primo blocco adatto, è molto veloce e tende a riempire solo la prima parte della memoria. In generale era il migliore.
Un’altra alternativa è il next-fit, funziona come il first-fit ma tramite un puntatore si ricorda dove aveva concluso la ricerca e al successo riparte da li, questo per risolvere il problema di riempire soltanto la prima parte di memoria.
Buddy System (Sistema del Compagno)
È una via di mezzo tra partizionamento fisso e dinamico, le partizioni si creano man mano che vengono aggiunti processi però è fisso perché non possiamo creare tutte le partizioni possibili.
Abbiamo a disposizione per lo user space ed la dimensione di un processo da mettere in RAM, il sistema inizia a dividere per 2 lo spazio fino a trovare un tale che , in questo modo abbiamo due partizioni adatte a contenere il processo e ne usiamo una. Quando un processo finisce, se il buddy è libero si può fare una fusione, il buddy è il suo compagno.
Esempio
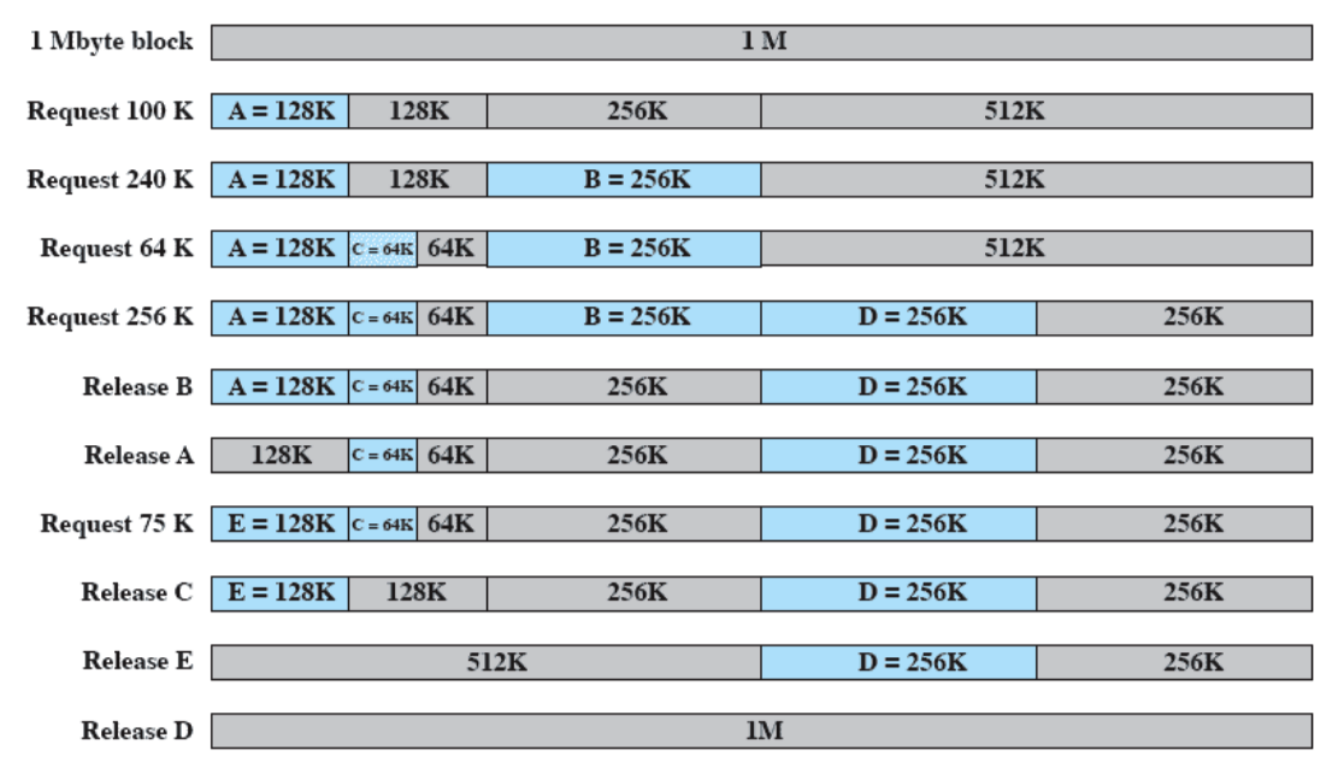
Questo sistema si presta per essere rappresentato da un albero binario:
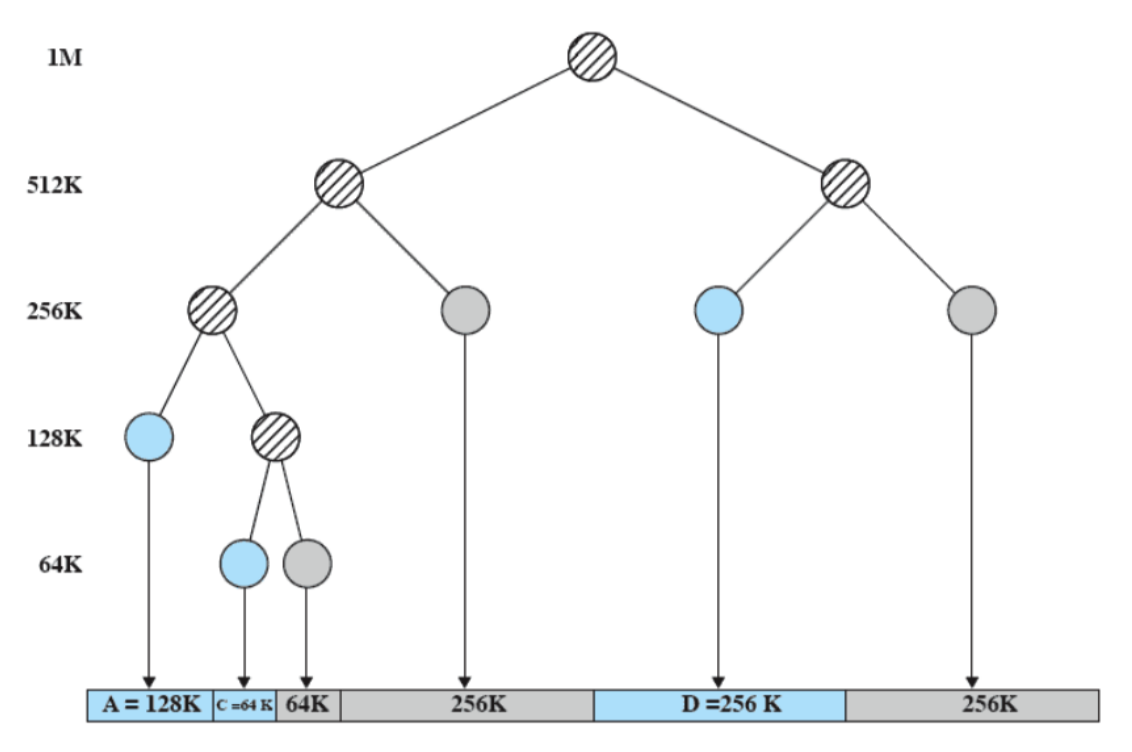
Paginazione (Semplice)
La paginazione semplice non viene usata ma è importante per capire come funziona la memoria virtuale.
La memoria viene partizionata in pezzi di grandezza uguale e piccola, stesso trattamento avviene per i processi, i pezzi di processi sono chiamati pagine, mentre i pezzi di memoria frame.
Ogni pagina, per essere utilizzata deve essere allocata in un frame:
- Pagine contigue possono essere messe in frame distanti
- Una pagina quindi può andare in un qualsiasi frame
- Pagina e frame hanno la stessa dimensione
Per fare questo, i sistemi operativi devono avere una tabella delle pagine per ogni processo, questa ci dice ogni pagina in che frame si trova, aggiunge ovviamente dell’overhead.
Da notare inoltre che va corretta la rilocazione, non possiamo più sommare l’inizio del processo con l’indirizzo, dobbiamo fare in modo che l’hardware possa accedere alla tabella delle pagine, quindi con un process switch va ricaricata la tabella delle pagine del processo.
Esempio

Arrivano 3 processi:
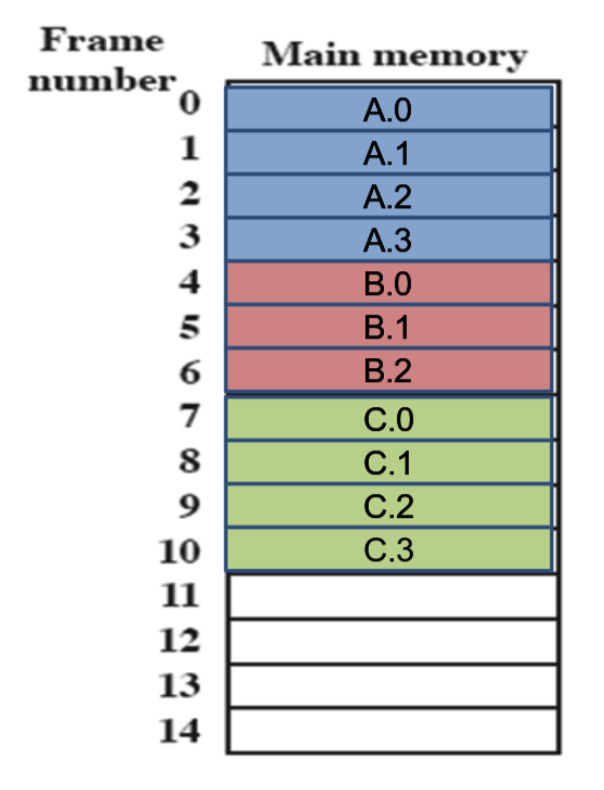
Adesso si libera B:
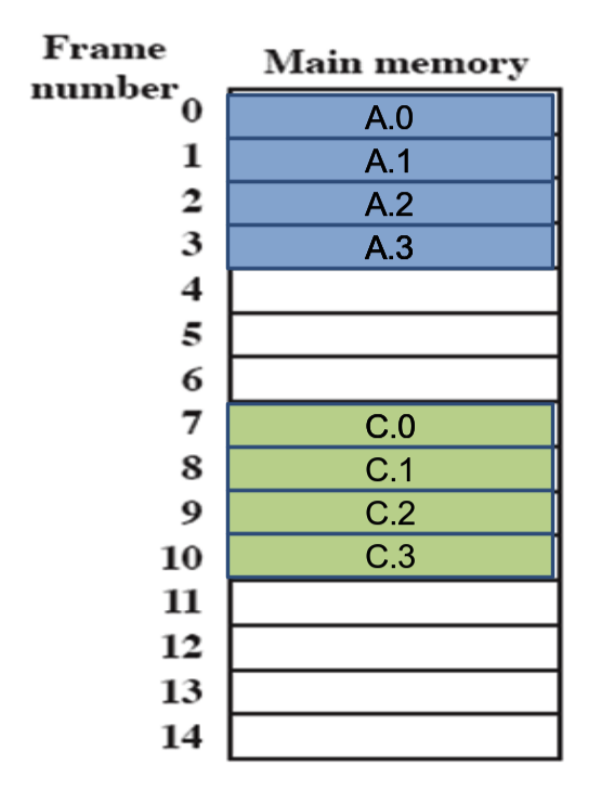
Adesso cosa succede se arriva un processo da 5?
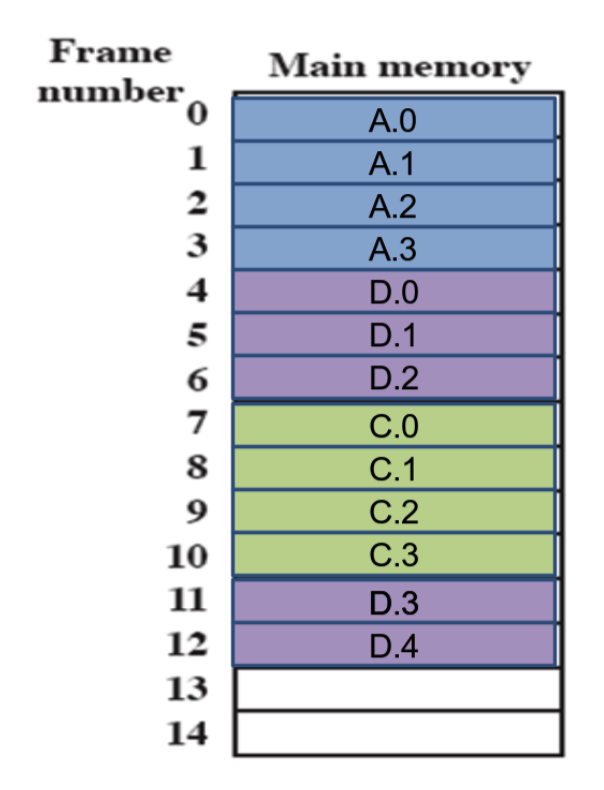
Questo è tutto gestito dal sistema operativo, con l’aiuto dell’hardware.
Segmentazione (Semplice)
Un programma viene diviso in segmenti, cosa cambia dalle pagine?
- I segmenti hanno lunghezza variabile e un limite massimo alla loro dimensione
- Un indirizzo di memoria è un numero di segmento e un offset al suo interno
È simile al partizionamento dinamico ma:
- Il programmatore deve gestire esplicitamente la segmentazione, deve dire quanti segmenti ci sono e la loro dimensione, a posizionarli in RAM ci pensa il S.O.
Ovviamente, come le pagine, deve esserci una tabella dei segmenti
Vediamo come funzionano i salti
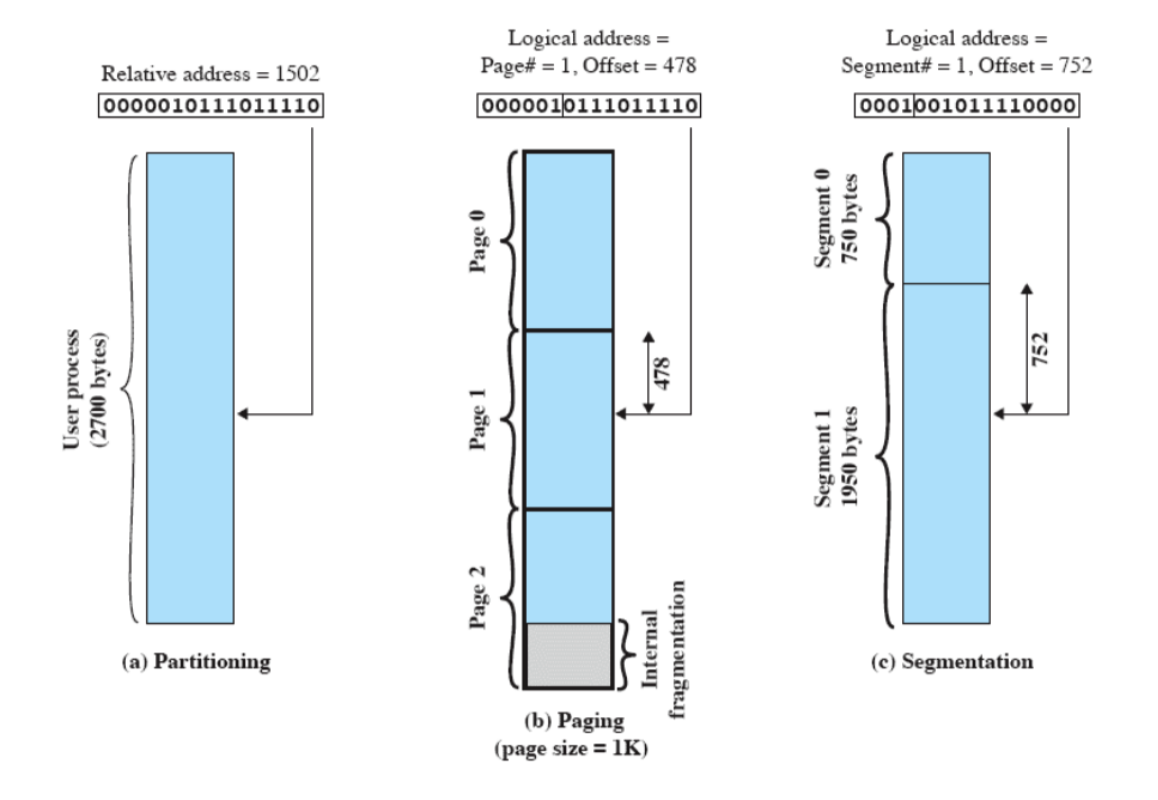
- Nel primo caso molto semplicemente dobbiamo solo sapere dove comincia il processo, e sommare il suo indirizzo iniziale a quello dell’istruzione.
- Nella paginazione dobbiamo prima di tutto capire in che pagina si trova l’indirizzo poi grazie alla tabella vediamo in che punto della memoria si trova quella pagina e adesso abbiamo un certo offset che ci indica l’inizio di quella pagina. A questo punto effettuiamo normalmente la somma con l’indirizzo del codice.
- Nella segmentazione funziona allo stesso modo ma dobbiamo tenere conto del fatto che i segmenti possono avere dimensioni diverse.
Esempio Paginazione
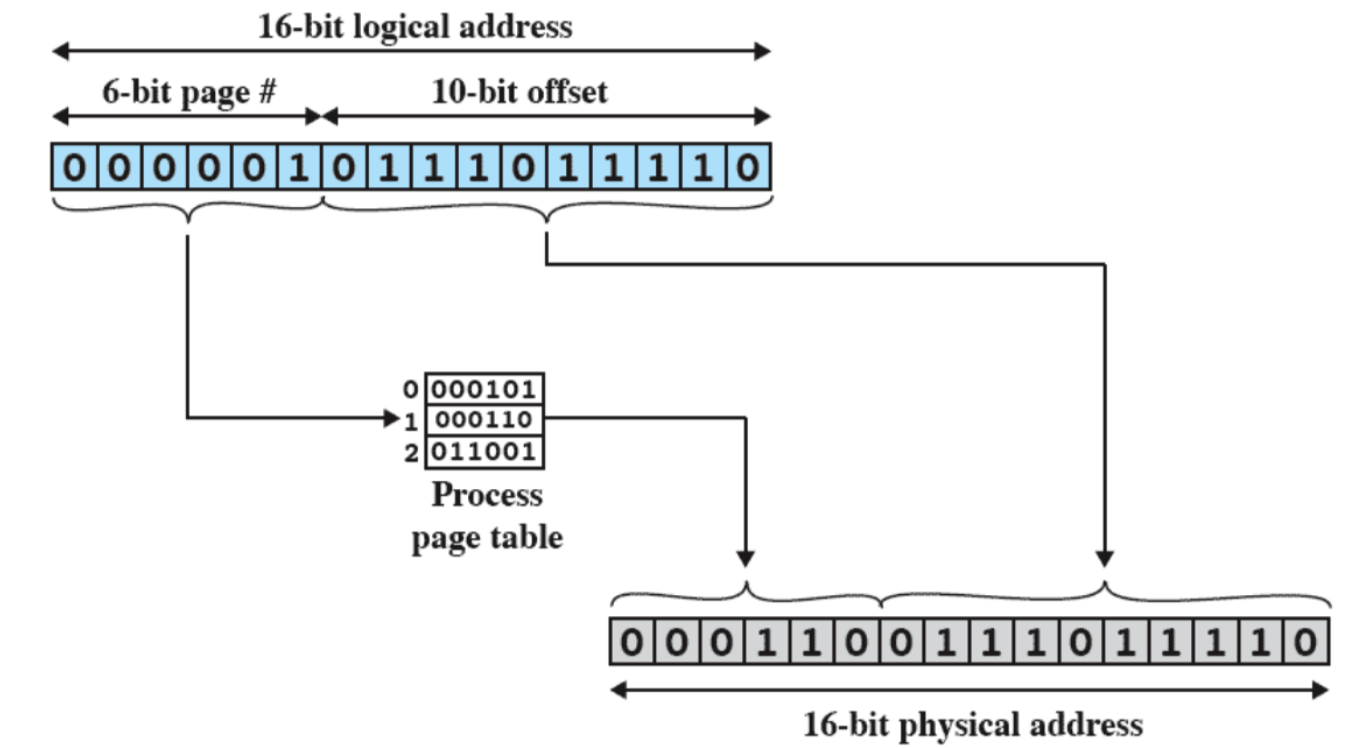
Abbiamo un indirizzo logico, ovvero che deve essere tradotto in indirizzo fisico della RAM. Come lo facciamo?
Le dimensioni delle pagine sono scelte sempre come potenza di 2, quindi , nell’esempio abbiamo .
Quindi per ogni indirizzo, per trovare la pagina mi basta fare che in binario corrisponde a togliere i 10 bit meno significativi, i bit rimanenti mi indicano la pagina che dovrò prendere dalla tabella delle pagine e sostituire il suo indirizzo nell’indirizzo fisico.
Per l’offset non devo fare nulla, lo copio così come è.
Quindi l’indirizzo della pagina ci fa muovere fra queste, mentre l’offset ci fa muovere all’interno della pagina.
Esempio più numerico
Consideriamo l’esempio di prima:
E quindi avremo come tabella delle pagine:
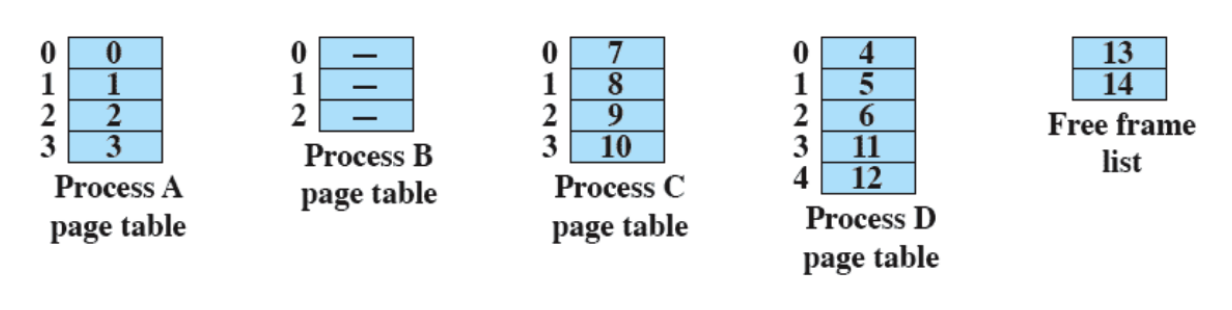
Supponiamo adesso di avere pagine da 100 bytes e quindi una RAM totale di 1500 bytes (15 frame).
I processi occupano rispettivamente 400,300,400,500 bytes e nelle loro istruzioni, gli indirizzi in RAM sono relativi all’inizio, quindi D ad esempio avrà indirizzi da 0 a 499.
Adesso mettiamo caso che in D ci sia l’istruzione j 343. Ovviamente 343 non è l’indirizzo fisico in RAM, calcoliamolo:
Prima di tutto dobbiamo capire in che pagina ci troviamo quindi facciamo e otteniamo 3 quindi guardando la tabella delle pagine di D, notiamo che la pagina 3 si trova al frame 11, poi per muoverci all’interno del frame facciamo e otteniamo 43.
Quindi l’indirizzo finale è dato da . Ovvero numero di frame per la loro grandezza, e ci posizioniamo sul giusto frame, sommiamo l’offset.
Esempio Segmentazione
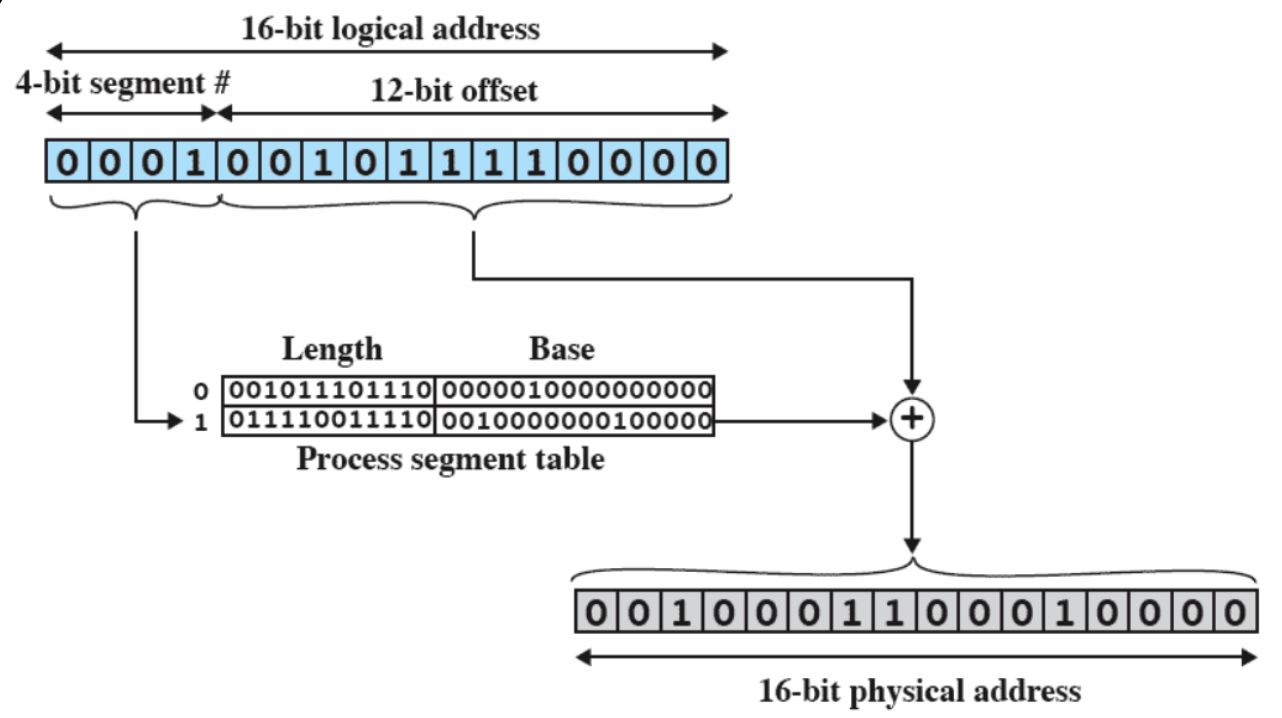
In questo caso si presuppone che i segmenti non possano essere più grandi di bytes, facciamo ragionamenti simili a prima ma al posto della tabella delle pagine abbiamo quella dei segmenti che deve indicarci sia da dove parte il segmento ma anche quanto è lungo, dato che possono avere dimensioni diverse.
Quindi prendo da dove inizia il segmento, ci sommo l’offset e trovo l’indirizzo fisico.
Gestione della Memoria: Concetti Fondamentali
Per ora abbiamo visto che i riferimenti alla memoria sono logici e vanno convertiti in indirizzi fisici a tempo di esecuzione, questo perché un processo potrebbe essere spostato durante la sua esecuzione, inoltre i processi sono spezzati in più parti non necessariamente contigue.
Se queste condizioni sono vere, non occorre che tutte le pagine o segmenti del processo siano in memoria principale, l’importante è che ci sia l’istruzione successiva da eseguire. Si passa dalla paginazione semplice a quella con memoria virtuale.
Il S.O. porta in memoria solo alcuni pezzi del programma, questo viene chiamato resident set, quando il programma richiede qualcosa che non si trova in questo set (page fault) viene generato un interrupt I/O che mette il processo in modalità blocked.
Il pezzo di processo viene portato in RAM, ma finché questo non accade ci sono altri processi che vanno in esecuzione, nel momento in cui è tutto pronto ci sarà un interrupt che lo manderà in ready e il processo dovrà rieseguire la stessa istruzione che aveva causato il page fault, infatti adesso non lo causerà.
Grazie a questo possiamo avere molti più processi in RAM, quindi il processore passa poco tempo in idle e inoltre un processo potrebbe richiedere più dell’intera memoria principale.
Memoria Virtuale: Terminologia
Con memoria virtuale intendiamo uno schema di allocazione in cui la memoria secondaria può essere usata come se fosse principale.
- Gli indirizzi dei programmi sono logici mentre quelli usati dal sistema sono fisici
- C’è bisogno di una traduzione dai logici a fisici
- La dimensione di questa memoria è limitata oltre che dalla sua grandezza anche dallo schema di indirizzamento
- La dimensione della RAM invece non influisce sulla dimensione della virtuale.
Definizioni:
- Indirizzo Virtuale: Sono come gli indirizzi logici, fanno in modo che si possa accedere a locazioni della memoria virtuale come se fossero locazioni della principale.
- Spazio indirizzi virtuali: La quantità di memoria virtuale assegnata ad un processo
- Spazio degli indirizzi Quantità di memoria assegnata ad un processo
- Indirizzo Reale: Indirizzo di una locazione di memoria principale, sarebbe l’indirizzo fisico.
Quindi:
- Memoria Reale: Indichiamo la RAM
- Memoria Virtuale: Quella su disco, ci permette di avere multiprogrammazione elevata liberando il programmatore dai vincoli della principale
Vediamo però alcuni effetti collaterali.
Trashing
Il Sistema Operativo impiega troppo tempo a swappare pezzi di processi da RAM a disco o viceversa, accade ad esempio quando ci sono troppi page fault.
Per evitarlo il S.O. cerca di indovinare quali pezzi di processo saranno richiesti nella prossima istruzione, questo tentativo si basa sulla storia recente. Come si fa?
I riferimenti che un processo fa tendono ad essere vicini, quindi solo pochi pezzi di processo saranno necessari di volta in volta, è possibile quindi prevedere quali pezzi di processo saranno necessari in futuro. Funziona simile alla cache quindi.
Memoria Virtuale: Supporto Richiesto
Vediamo come si realizza.
Paginazione e Segmentazione devono essere supportati dall’hardware altrimenti il S.O. avrebbe troppo lavoro, come ad esempio la traduzione degli indirizzi.
Il S.O. deve essere in grado di muovere pagine / segmenti dalla RAM alla memoria secondaria.
Paginazione per la Memoria Virtuale
Ogni processo ha una sua tabella delle pagine, ogni entry di questa tabella contiene:
- Un bit di presenza che indica se quella pagina è in RAM o se bisogna prenderla su disco
- Un bit che indica se la pagina è stata usata in lettura o anche scrittura
- Altri bit di controllo
- Il numero di frame in memoria principale
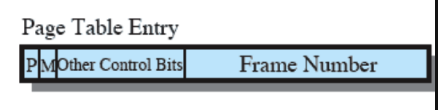
Come funziona la traduzione adesso?
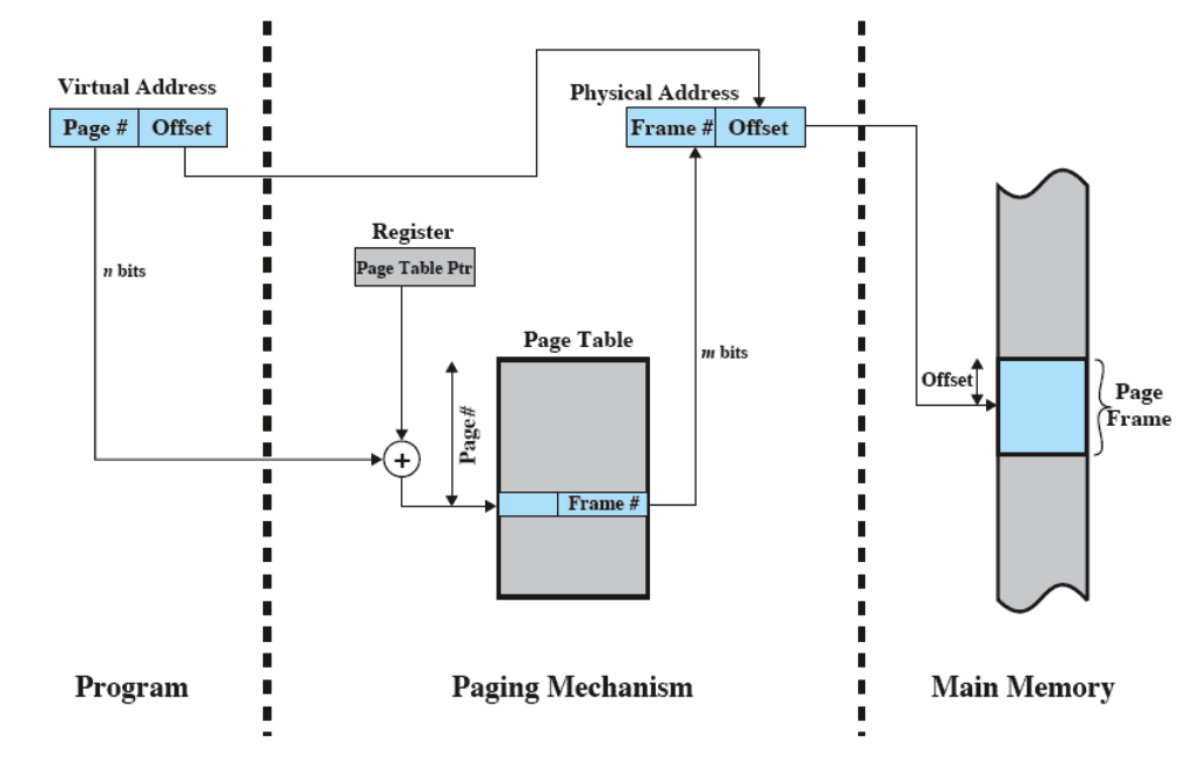
In un registro Page Tabe Ptr è contenuto il riferimento all’inizio della tabella delle pagine, tramite l’indirizzo virtuale accediamo alla pagina corrispondente, lo facciamo andando come prima cosa all’indirizzo puntato dal registro (inizio della tabella) e poi sommiamo il numero di pagina dell’indirizzo moltiplicato per la grandezza di ogni entry della tabella.
Adesso dalla tabella otteniamo il frame della RAM con il quale sostituiamo il numero di pagina dell’indirizzo virtuale ottenendo un indirizzo fisico.
Quindi ad ogni process switch il sistema operativo deve occuparsi di aggiornare il valore presente nel registro che contiene l’inizio della tabella delle pagine.
Questa struttura porta però a molto overhead, le tabelle potrebbero contenere molti elementi. Quando un processo è in esecuzione, è assicurato che almeno una parte della sua tabella delle pagine sia in memoria principale, vediamo qualche conto:
Abbiamo 8Gb di spazio virtuale e 1kb per ogni pagina, quindi in totale possiamo avere di entry per ogni tabella, questo significa che per ogni processo abbiamo entries (divisione ma in binario), necessari a indicizzare tutti i frames della RAM. (8 giga è mentre 1kb è )
Quanto spazio occupa una entry? Ha 1 byte per i bit di controllo + quindi ad esempio con 4GB di RAM abbiamo indirizzi da massimo 32 bit, ne togliamo 10 per le pagine da 1kB ci rimangono 22 bit per il Frame Number della entry, quindi in totale abbiamo 3 bytes per il frame number più un byte per i bit di controllo.
Se abbiamo entries allora dobbiamo fare di overhead per ogni processo
Ad esempio con una RAM da 1Gb, bastano 20 processi a occupare più di metà RAM in overhead.
Come risolviamo questo problema?
Tabella delle pagine a 2 livelli
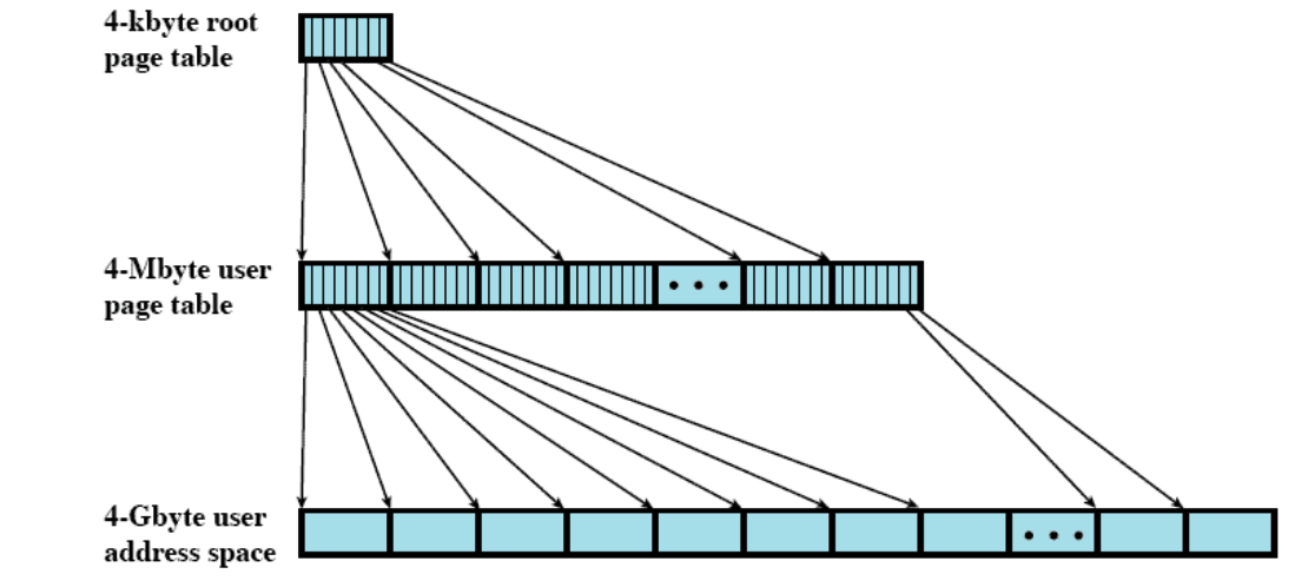
In questo caso abbiamo una tabella che invece di puntare direttamente a zone di RAM punta ad un’altra tabella che poi punta allo spazio utente.
Come funziona adesso la traduzione?
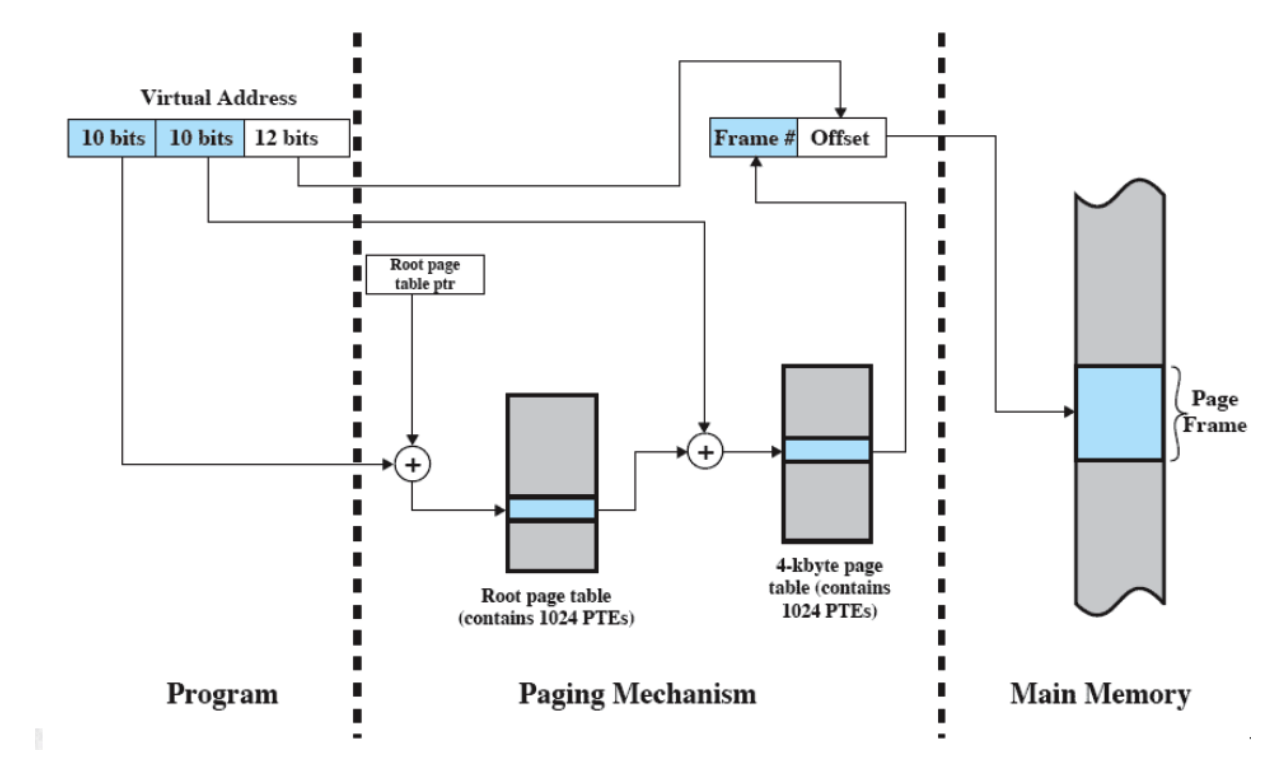
Adesso l’indirizzo va spezzato in 3, in generale in n.livelli + 1.
L’hardware deve consultare due tabelle adesso ma il funzionamento è uguale a quello visto prima.
Vediamo perché conviene facendo dei conti.
Abbiamo 8GB di spazio virtuale e quindi 33 bits di indirizzo, supponiamo di utilizzare 10 bit per l’offset quindi come prima abbiamo pagine da 1kB, i restanti 23 li dividiamo in 15+8, i 15 bit li usiamo per il primo livello e gli 8 per il secondo. Per rendere più efficiente il tutto una tabella di secondo livello deve essere grande quanto una pagina.
Ogni processo ha quindi un overhead di infatti deve contenere tutte le entries di entrambe le tabelle e in più un ulteriore overhead di solo per il primo livello.
Adesso è sufficiente caricare in RAM il primo livello che è molto poco e una tabella del secondo e quindi per ogni processo di overhead che è circa , con una RAM da 1GB servono circa 1000 processi per occupare metà RAM.
Da rivedere =(
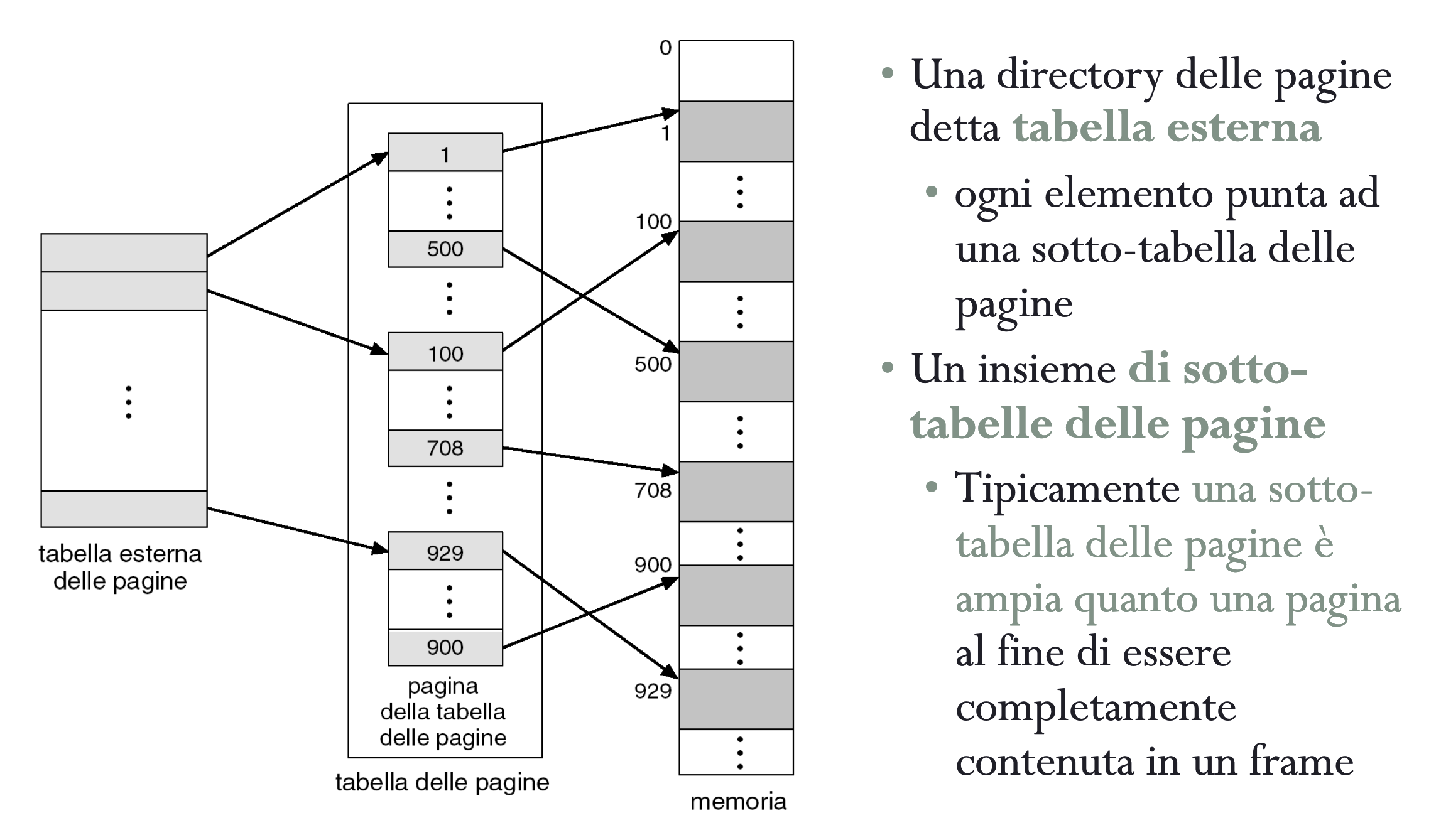
Slide dove si vede meglio graficamente, noi carichiamo il primo livello ovvero la tabella a sinistra dove ogni pagina è una tabella di secondo livello. A noi ci basta caricare in RAM il primo livello e poi vedere quale sottotabella caricare.
Infatti dividiamo l’indirizzo in indirizzo di primo livello e di secondo.
Translation Lookaside Buffer
Tradotto possiamo vederlo come: Memoria temporanea per la traduzione futura.
Ogni riferimento alla memoria virtuale può generare due accessi alla memoria, uno per la tabella delle pagine e uno per prendere il dato vero e proprio. Per risolvere questo si usa una cache per gli elementi della tabella delle pagine, questo contiene indirizzi di frame. Questo è il TLB.
Dato un indirizzo virtuale il processore non va subito a fare la traduzione ma prima consulta il TLB, se la pagina è presente allora si prende il frame number e ricava l’indirizzo reale. Altrimenti prende la tabella delle pagine del processo ed effettua i normali calcoli, se la pagina si trova in memoria ok altrimenti si gestisce il page fault e successivamente si aggiorna il TLB, funziona quindi molto simile alla cache.
Schema Funzionamento
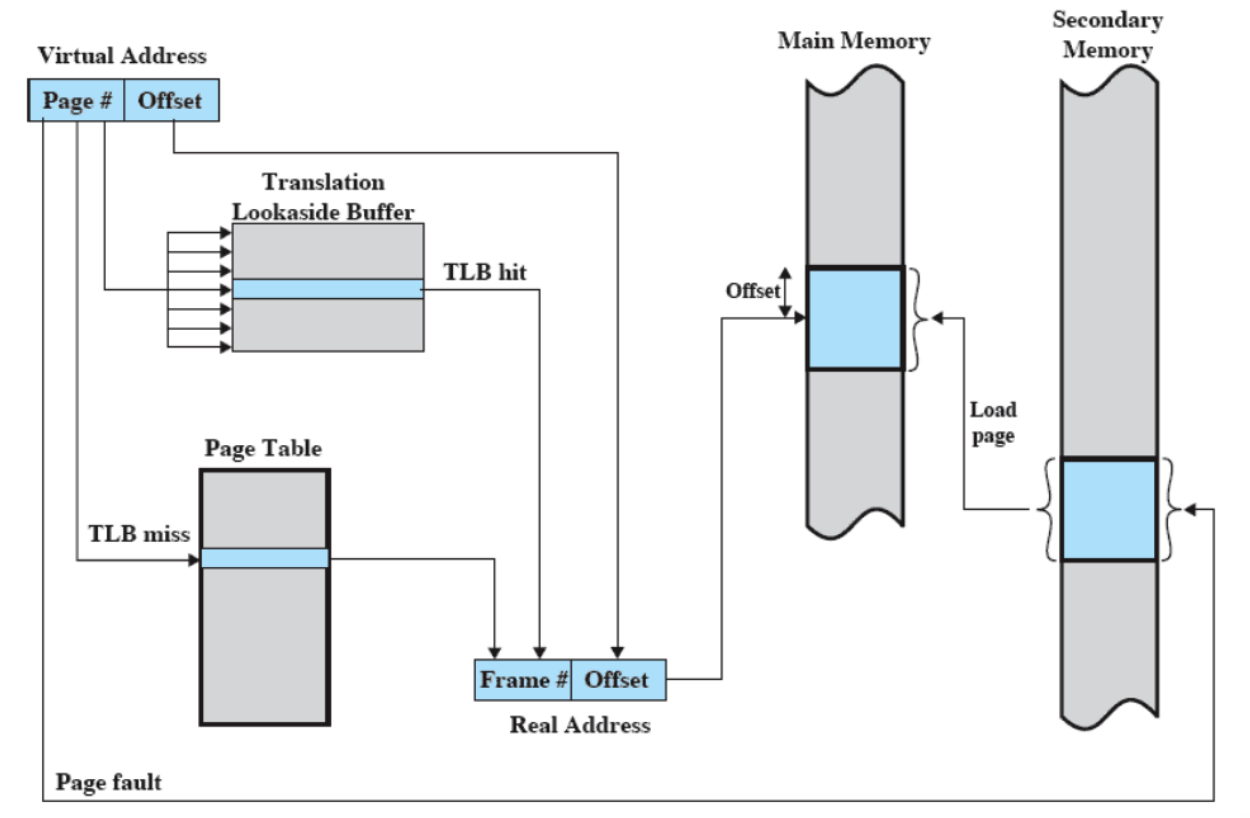
Schema Logico
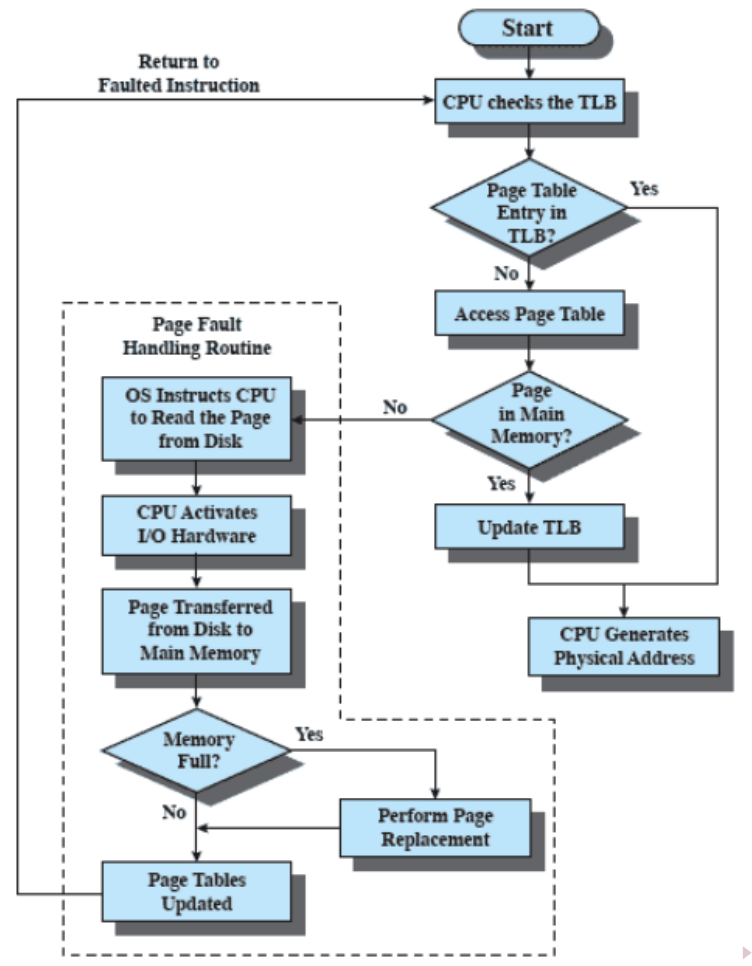
Il TLB deve poter essere resettato dal S.O., infatti ogni processo ha il proprio TLB, quindi ad ogni process switch dobbiamo cambiare TLB.
Da notare che nel TLB non sono presenti ovviamente tutte le pagine ma solo alcune e quindi non possiamo accedere direttamente ad un indirizzo ma dobbiamo cercare la pagina in ogni entry del TLB, potrebbe essere molto lento. Grazie all’hardware possiamo fare questa cosa in modo parallelo e controllarle tutte nello stesso momento.
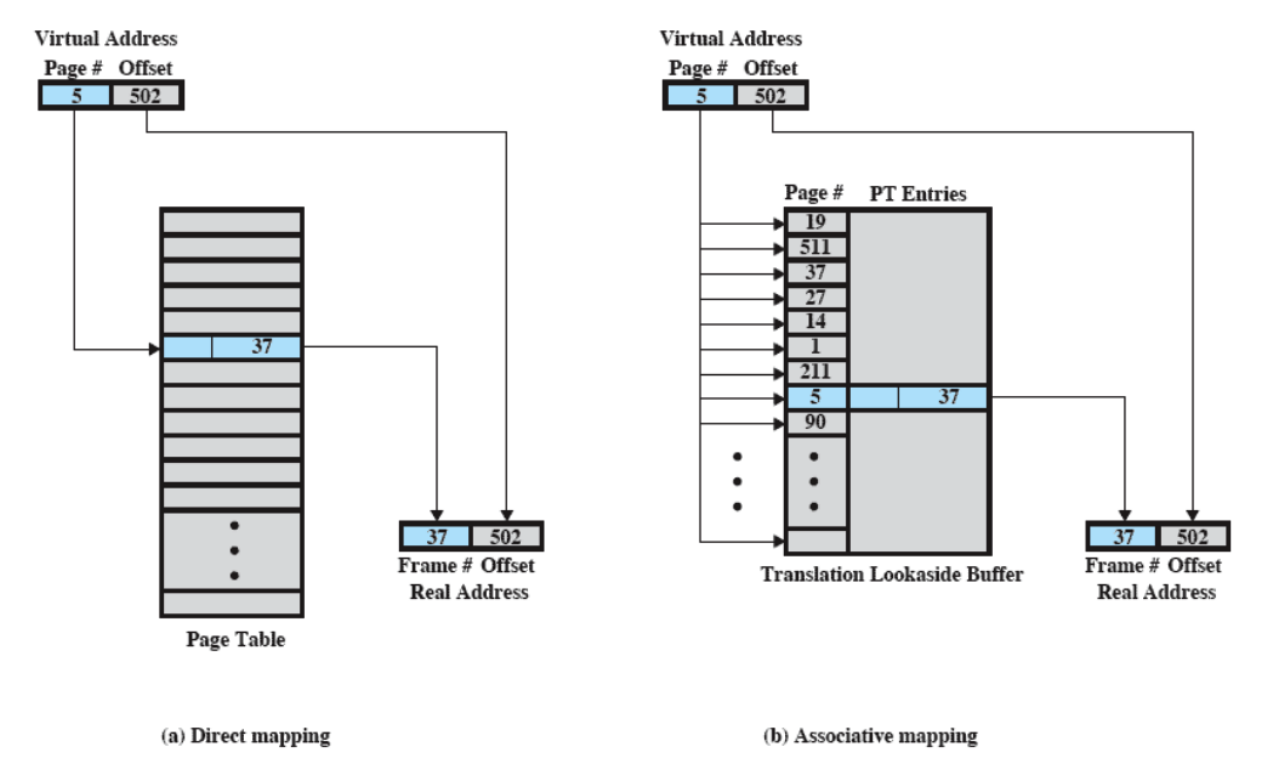
A sinistra quindi possiamo utilizzare il numero come indirizzo per accedervi direttamente mentre a destra dobbiamo controllarli tutti.
Un altro problema è che bisogna fare in modo che il TLB contenga solo pagine che si trovano in RAM, non devono verificarsi page fault dopo un TLB hit altrimenti sarebbe impossibile accorgersene. Quindi se il S.O. swappa una pagina deve informare anche il TLB.
Quindi mettendo insieme tutto quello che abbiamo visto:
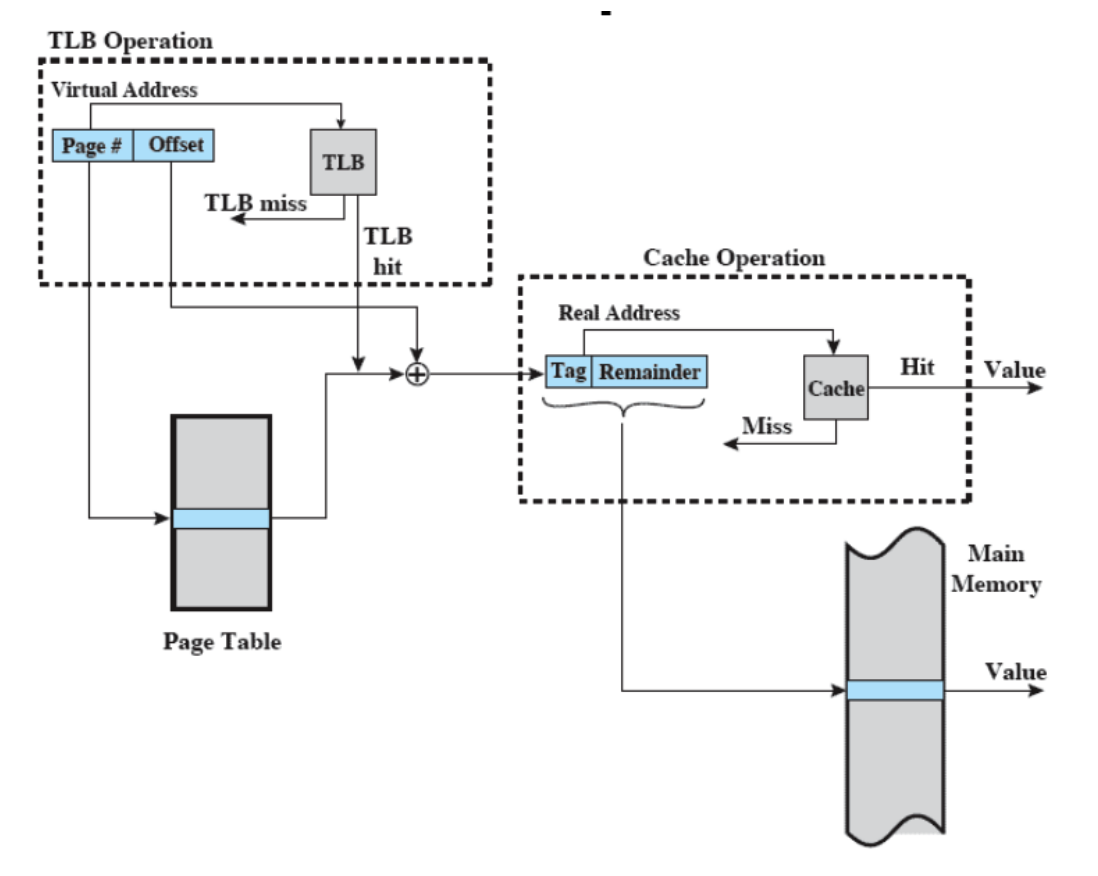
Il blocco del TLB si occupa di trasformare un indirizzo logico in uno fisico e una volta fatto questo si va a controllare nella cache se questo è presente altrimenti si accede veramente alla RAM.
Dimensione delle Pagine
Più piccola è una pagina minore è la frammentazione all’interno delle pagine ma è anche maggiore il numero di pagine per un processo e questo porta ad una tabella delle pagine più grande per ogni processo. Quindi la maggior parte delle tabelle finisce in memoria secondaria e questa è ottimizzata per trasferire grossi blocchi di dati quindi è comodo avere pagine ragionevolmente grandi.
Più piccola è una pagina maggiore sarà il numero di pagine in RAM, e in tutte queste i riferimenti saranno vicini e quindi pochi page fault, questo non accade con pagine più grandi.
Dobbiamo quindi realizzare pagine alla giusta dimensione, quale?
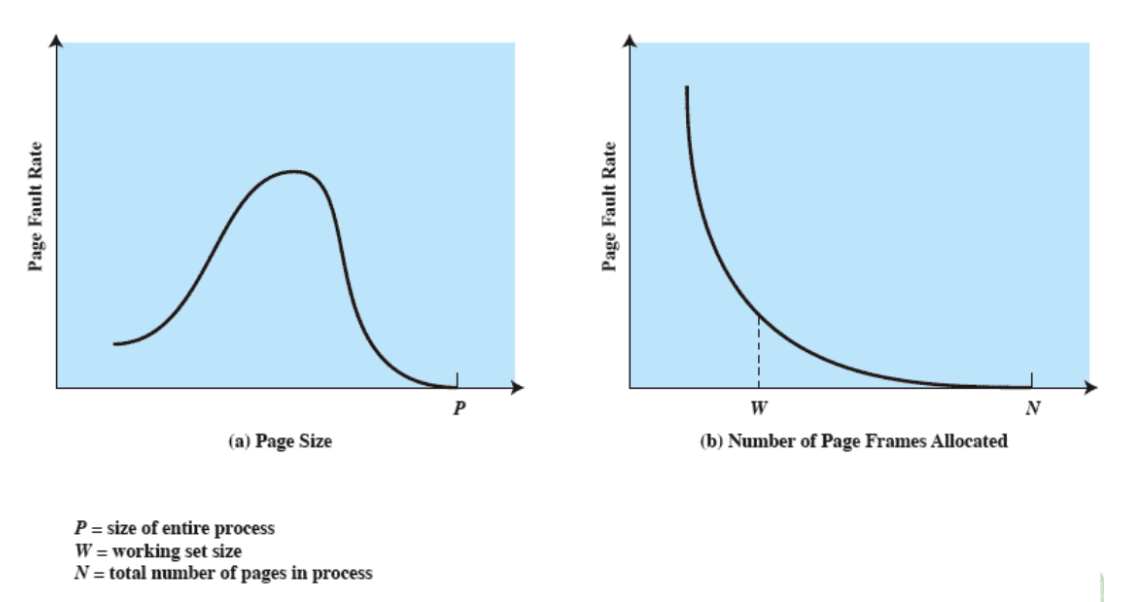
Sull’asse X abbiamo il numero di Byte per ogni pagina fino ad arrivare a pagine della stessa dimensione del processo. Sulla Y invece abbiamo il numero di page fault. Il grafico a destra non ci interessa per ora.
Notiamo che quindi con pagine grandi abbiamo pochi fault ma ovviamente meno multiprogrammazione dato che possiamo caricare meno processi in RAM. Con pagine piccole abbiamo comunque pochi fault ma dobbiamo stare attenti a non avere troppo overhead.
Segmentazione
Permette al programmatore di vedere la memoria come un insieme di segmenti di indirizzi, semplifica la gestione di strutture che crescono nel tempo come lo stack. Inoltre permette di creare ad esempio dei segmenti per i dati condivisi ed altri per i dati da non condividere con altri processi.
In modo simile alla paginazione ogni processo ha una tabella dei segmenti e ogni entry di questa tabella ha:
- L’indirizzo in RAM di partenza del processo
- La lunghezza del segmento
- Un bit per indicare se il segmento è presente in RAM o no
- Altri bit di controllo
Traduzione
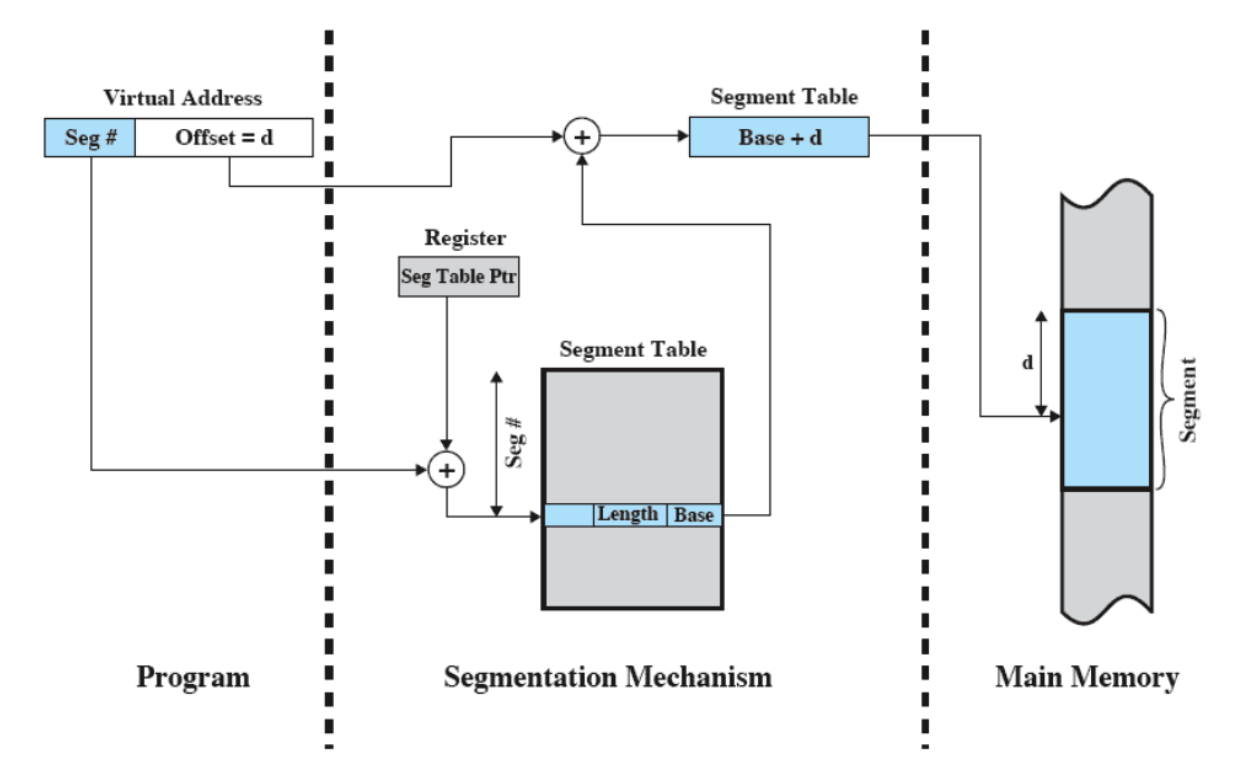
Quindi facciamo all’interno della tabella in modo analogo alla paginazione effettuiamo una moltiplicazione con quanti segmenti abbiamo e ci sommiamo l’inizio della tabella presente nel registro. Una volta ottenuto il valore Base lo sommiamo all’offset per accedere al segmento della memoria, dobbiamo controllare di non superare la Length del segmento.
Paginazione e Segmentazione
La paginazione è invisibile al programmatore mentre la segmentazione no, ovviamente se programma in assembler. Di base si uniscono queste tecniche, i segmenti possono essere molto grandi e quindi li dividiamo in pagine.
Quindi abbiamo:
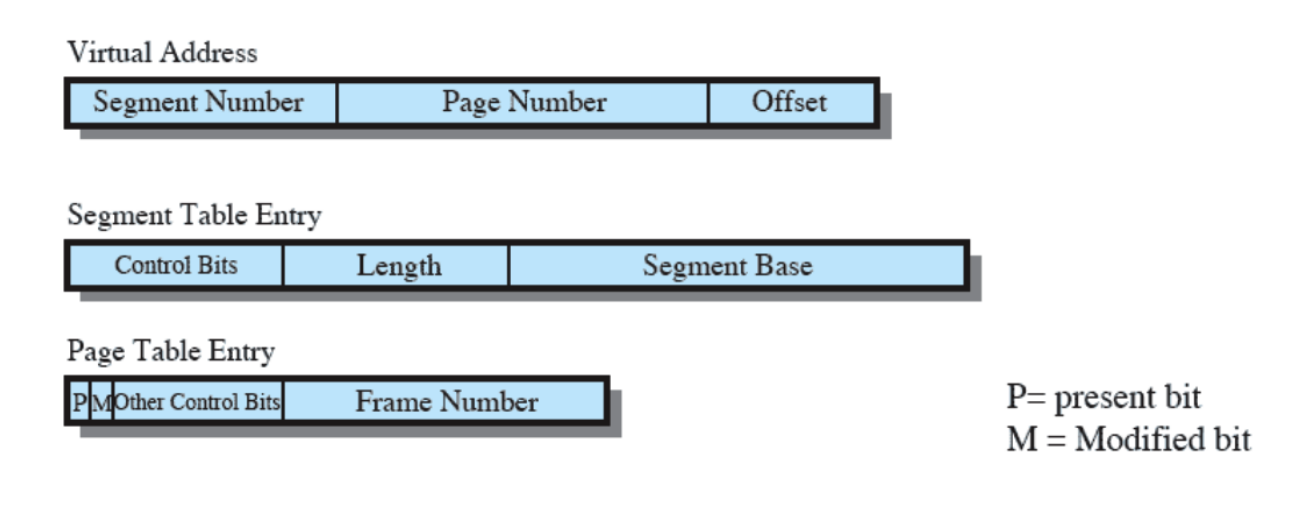
Ogni indirizzo virtuale ha un riferimento al segmento e uno alla pagina e quindi ha una tabella dei segmenti con i vari entry e una tabella delle pagine con i suoi entry, come funziona la traduzione?
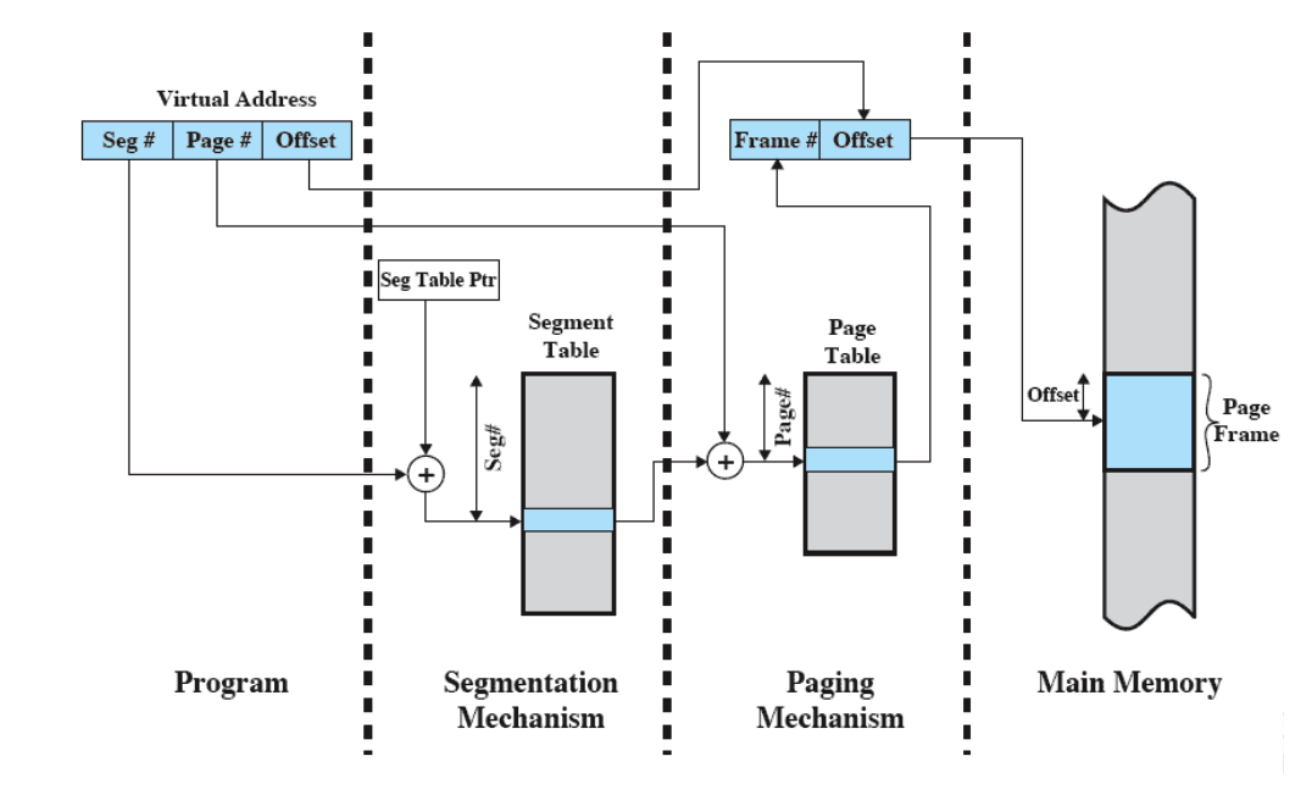
Quindi prima vediamo di quale segmento abbiamo bisogno, poi dato che il segmento è paginato vediamo con la tabella delle pagine dove si trova e infine otteniamo l’indirizzo fisico.
Quindi nella tabella dei segmenti una volta trovato l’entry corretto abbiamo l’inizio della tabella delle pagine corrispondente
Decisioni nel S.O.
Come decidiamo quindi se usare o no la memoria virtuale, se usare segmentazione, paginazione o entrambe? Che algoritmi usare per i vari aspetti della gestione della memoria?
Ci sono alcuni aspetti da considerare:
- Politica di prelievo (fetch)
- Politica di posizionamento (placement policy)
- Politica di sostituzione (replacement policy)
- Altro:
- Gestione resident set
- Politica di pulitura
- Controllo del carico
- Tutto questo minimizzando page fault
Fetch Policy
Decide quando una pagina data va portata in memoria principale, ci sono due modi principali:
- Paginazione su richiesta (demand paging) - Quella vista fino ad ora
- Prepaginazione (prepaging)
Il prepaging cerca di anticipare il processo, porta quindi in memoria più pagine di quelle richieste, ovviamente vicine a quella richiesta. Questo è anche efficiente per quanto riguarda il disco.
Placement Policy
Decide dove mettere una pagina in memoria principale quando c’è almeno un frame libero, tipicamente il primo frame libero è quello dove viene messa la pagina.
Replacement Policy
Se tutti i frame sono occupati, quale pagina tolgo dalla RAM?
Va fatto in modo da minimizzare la probabilità che la pagina appena sostituita venga subito richiesta dopo, si usa sempre il principio di località, quindi ci si basa sulle richieste fatte prima.
Da notare che alcuni frame potrebbero essere bloccati, Frame Locking, questi non possono essere sostituiti, di solito sono del sistema operativo.
Gestione Resident Set
Il resident set è la parte del processo presente in RAM, la gestione di questo racchiude due problemi:
- Decidere per ogni processo quanti frame allocare - Resident set management
- Quando si rimpiazza un frame, scegliamo fra i frame del processo corrente o anche di altri processi? Replacement Scope
Ci sono 2 tecniche per ogni problema
Resident set management:
- Allocazione Fissa: Il numero di frame è deciso al tempo di creazione del processo
- Allocazione Dinamica: Il numero di frame varia durante la vita del processo
Riprendendo il grafico di prima
A Destra abbiamo, sulla Y i page fault mentre sulla X il numero di frame allocati, l’ottimo è la W ovvero più o meno la metà tra pochi frame e molti.
Replacement Scope:
- Politica locale: Rimpiazzo soltanto i frame dello stesso processo
- Politica globale: Posso scegliere altri processi (non del S.O.)
In tutto abbiamo 3 strategie, infatti se scegliamo l’allocazione fissa non possiamo utilizzare la politica globale perché a quel punto stiamo togliendo dei frame ad un processo e aggiungendone altri ad un altro, e quindi è stata cambiata l’allocazione fissa fatta all’inizio.
Politica di Pulitura
Se modifichiamo un frame va riportata la modifica anche sulla pagina corrispondente, quindi abbiamo gli stessi problemi della cache, quando facciamo questa modifica? Quando facciamo la modifica o quando il frame viene sostituito?
Solitamente si fa una via di mezzo con il page buffering che vedremo più avanti. L’idea è accumulare delle richieste di modifica e poi farle tutte insieme.
Controllo del Carico (Medium-Term Scheduler)
Dobbiamo cercare di mantenere più alta possibile la multiprogrammazione, ovvero quanti processi riusciamo a tenere in RAM, questo significa che hanno un residente set più grande di 0, ma non troppo alta altrimenti avremo i resident set troppo piccoli e quindi tanti page fault.
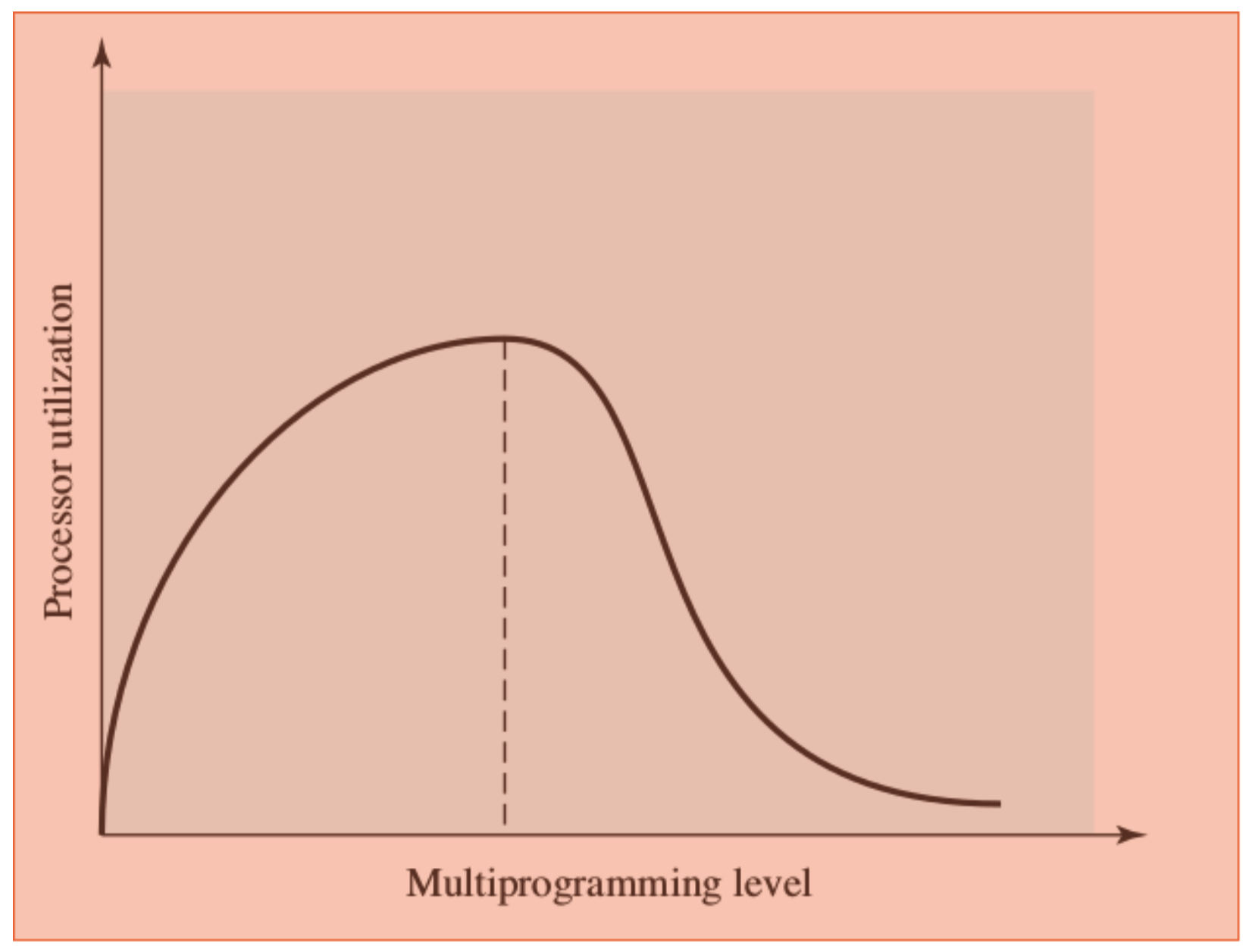
Per farlo:
- Si cerca di aumentare e diminuire il numero di processi attivi, se devo portare dei processi in RAM mi devo assicurare che saranno pronti. Al contrario se devo portarli su disco il sistema operativo deve sapere che questi si bloccheranno tra poco.
Servono quindi delle politiche di monitoraggio per capire come si “muoveranno” i processi, questo si fa con un processo del sistema operativo che vede lo stato di multiprogrammazione e decide se bisogna cambiare qualcosa, ovvero se portare da suspended a ready o viceversa.
Per esempio si misura il tempo medio fra due page fault e si confronta con il tempo medio di gestione di un fault, se questi due valori sono molto vicini probabilmente avremo trashing. Infatti per ogni page fault ne arriverà subito un altro.
Questo processo di monitoraggio viene invocato ogni tot page fault e fa parte dell’algoritmo di rimpiazzamento.
Come scegliamo un processo da sospendere?
Supponiamo che il processo di monitoraggio decida di diminuire il numero di processo in RAM, come scegliamo il processo?
- Processo con minore priorità
- Chi ha causato ultimo page fault
- Ultimo processo attivato
- Processo con working set più piccolo (numero di frame allocati in memoria)
- Processo con immagine più grande (più grande numero di pagine)
- Processo con il più alto tempo rimanente di esecuzione
Algoritmo di Sostituzione
In questo momento siamo con tutti i frame della RAM occupati, quali algoritmi di sostituzione possiamo utilizzare?
- LRU: Least Recently Used, quindi uguale alla cache, sostituiamo la pagina utilizzata meno di recente, ma per la RAM non funziona benissimo.
- FIFO: Sostituzione a coda, First in First out
- Clock: Sostituzione a orologio, quella su cui si basano molti SO
Non c’è una politica migliore fra tutte, possiamo provarle un po’ tutte e confrontarle con la sostituzione ottima ovvero un caso di cui conosciamo il “futuro” e sappiamo quindi quali sono le migliori pagine da sostituire.
Esempi Successivi
Vedremo gli esempi di applicazione di questi algoritmi con le stesse richieste di pagine in memoria, ovvero abbiamo 3 frame disponibili e vengono richieste nel seguente ordine le pagine:
- Sostituzione Ottimale (ricordiamo non implementabile)
Sappiamo cosa chiederemo più avanti quindi sappiamo quale pagina sostituire:
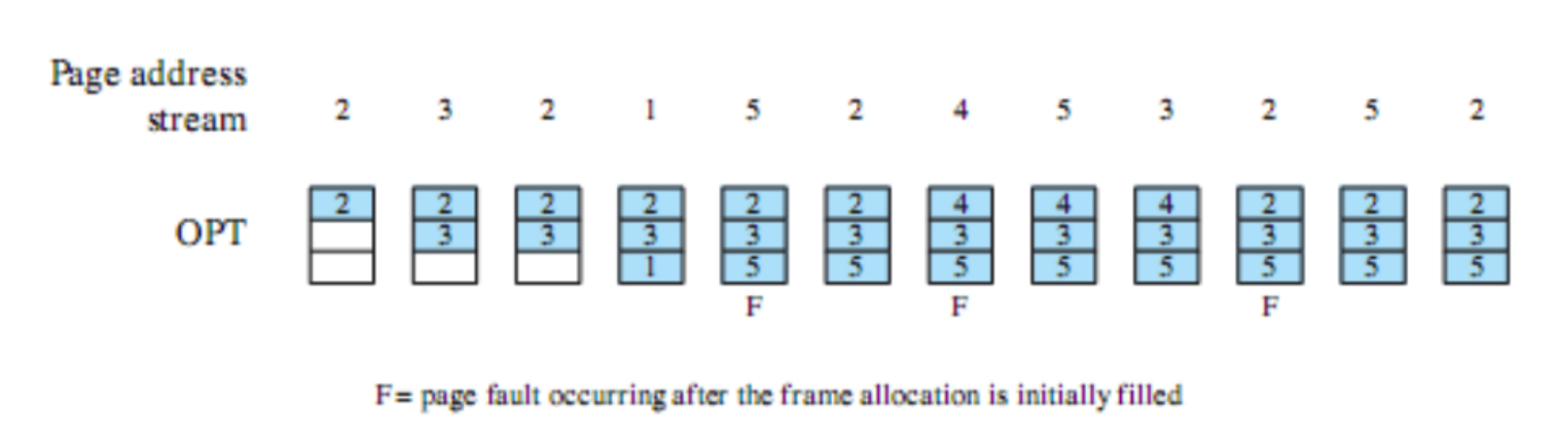
Mettiamo le pagine nel primo frame che troviamo, abbiamo 3 page faults.
Analizziamo da quando la memoria è piena:
- Sostituiamo 1 perché sappiamo che non la chiederemo più
- Quando chiediamo 4 sostituiamo 2 perché è quello che verrà chiamato più avanti
- Quando richiamiamo il 2 sostituiamo il 4 perché sappiamo che non lo chiameremo più
Quindi l’algoritmo migliore fra quelli che vedremo avanti sarà quello che si avvicina di più a 3, ovviamente ne avrà sicuramente di più.
- LRU - Sostituiamo la pagina a cui non si è fatto riferimento per il tempo più lungo.
Questo ha problemi dato che occorre etichettare ogni frame con il tempo dell’ultimo accesso, nella cache è più semplice dato che è implementato hardware. Fare questo su memorie molto più grandi come la RAM (rispetto alla cache) diventa molto costoso.
Vediamo comunque come si comporterebbe:
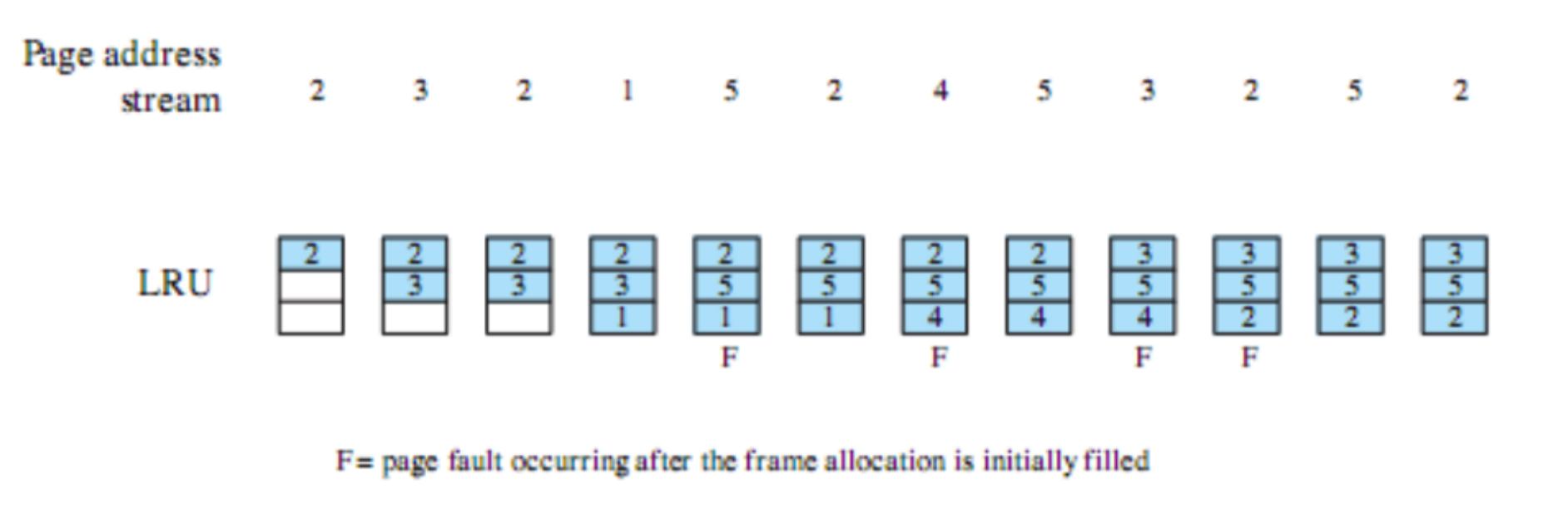
Da quando la memoria è piena:
- Sostituiamo il 3 dato che è il più lontano ad essere stato chiamato.
- Sostituiamo 1 poi 2 e 4 sempre per lo stesso motivo.
Notiamo che ad esempio all’inizio non viene sostituito 1 perché si pensa che verrà richiamato, ovviamente non è così, ma non possiamo conoscere il futuro come prima.
Abbiamo 4 page faults che è comunque molto vicino alla ottimale.
- FIFO
Usiamo un approccio diverso, non ci interessa di abbassare il numero di page fault, vogliamo avere meno overhead possibile.
Trattiamo i frame come fossero una coda circolare, facciamo un round robin su questa coda, rimpiazziamo le pagine che sono state in memoria per più tempo. Ha un’implementazione molto semplice ma non è spesso ottimale.
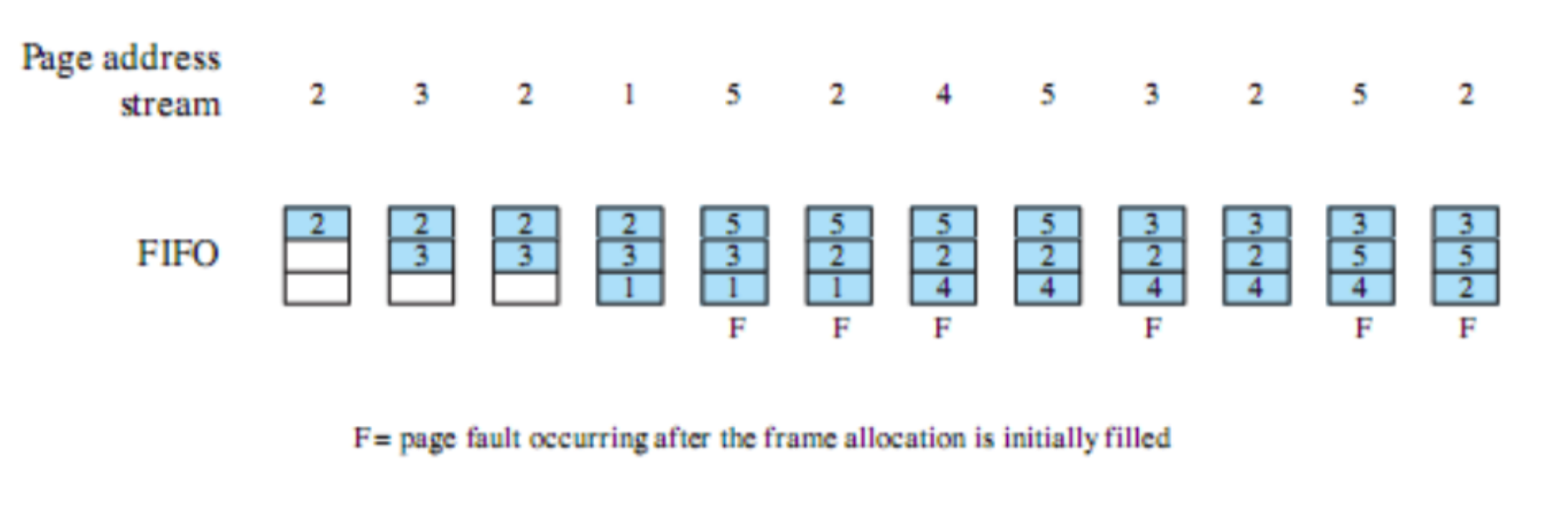
Dobbiamo immaginare un puntatore che all’inizio si trova sul primo frame e va avanti al successivo ad ogni fault.
Otteniamo 6 page faults, si allontana di più dall’ottimale rispetto alla LRU.
- Orologio
Comprende entrambe le tecniche viste prima, c’è un use bit per ogni frame che indica se la pagina di quel frame è stata riferita, il bit è a 1 se la pagina è stata riferita di recente.
Quando occorre sostituire una pagina facciamo FIFO ma cerchiamo il primo frame che ha il bit a 0, se troviamo una pagina a 1 la impostiamo a 0 e andiamo avanti.
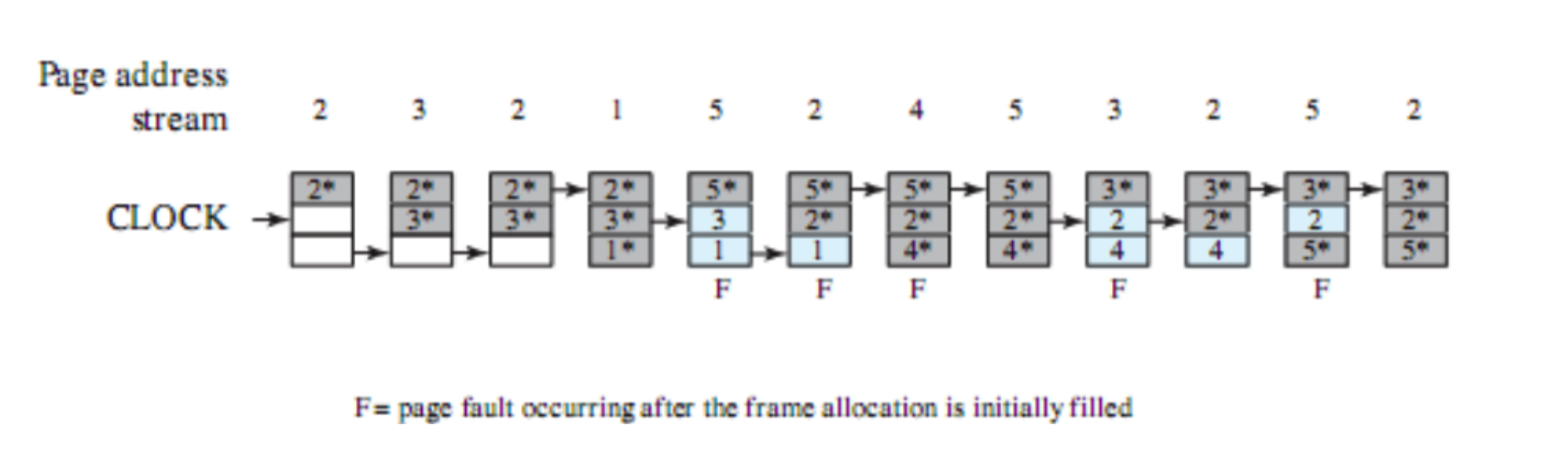
Quando abbiamo un * significa che lo use bit è a 1, la freccia indica il puntatore FIFO.
Quando abbiamo la memoria piena cosa succede?
Abbiamo iterato su tutta la memoria e abbiamo portato tutti i bit a 0 dato che non ne avevamo nemmeno uno, quando riniziamo troviamo il 2 con bit a 0 e quindi lo sostituiamo con la pagina 5 a bit 1. Procediamo avanti con lo stesso ragionamento.
Come risultato abbiamo 5 page faults, si accorge che la pagina 2 e 5 sono molto richieste.
- Confronto Finale
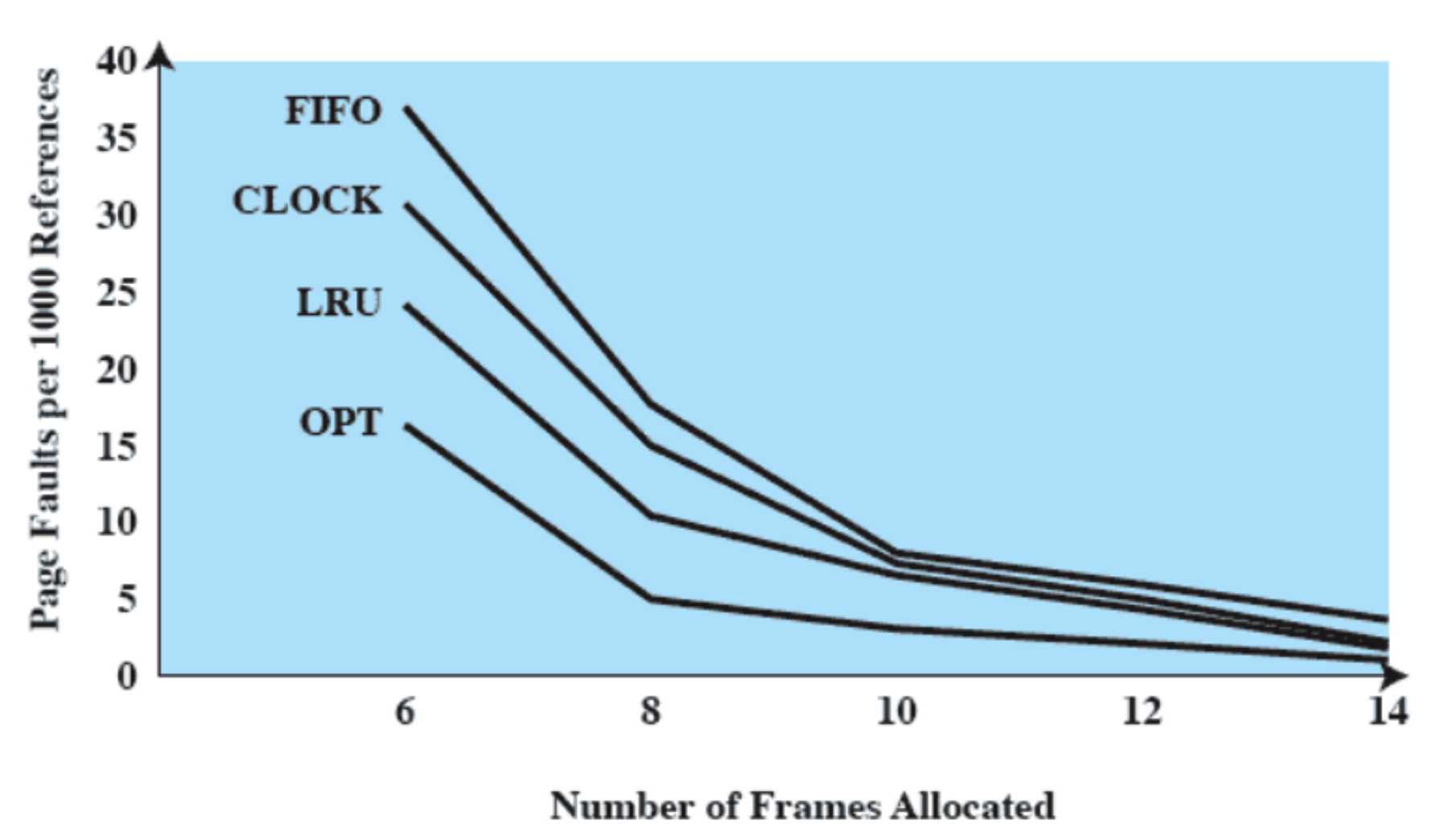
Vediamo quindi che il clock riesce a stare vicino all’LRU quando abbiamo molti frame, inoltre abbiamo meno overhead.
Buffering delle Pagine
È un’altra tecnica utilizzata simile alla cache ma per le pagine, non hardware. È una modifica del FIFO ma usata anche con LRU e/o clock, serve ad avvicinare il FIFO al clock.
Diamo meno memoria al processo e questa memoria guadagnata la usiamo come cache, se vogliamo rimpiazzare una pagina non la mettiamo subito su disco prima la passiamo nella cache.
Quindi rimaniamo con due frame e abbiamo una cache da una pagina e supponiamo siano tutti accessi in lettura:
Stiamo utilizzando FIFO, quindi al primo caso invece di portare 2 sul disco lo portiamo sulla cache, succesivamente dobbiamo sostituire 3 e quindi lo mettiamo nella cache e portiamo il 2 sul disco. Se una pagina in cache viene referenziata ci potremmo accedere più velocemente. Ovviamente sarebbe ottimale avere più di una pagina in cache.
Gestione della Memoria in Linux
Fa una distinzione tra richiesta di memoria da parte del Kernel e da parte dell’utente. Per richieste del Kernel fa pochi controlli, “si fida di se stesso”, per i processi utente fa controlli di protezione e di rispetto dei limiti altrimenti partono dei segnali.
È completamente diversa la gestione della memoria, il Kernel può usare sia la parte a lui riservata che quella riservata all’utente facendo delle richieste.
-
Se la richiesta è di pochi bytes fa in modo di avere alcune pagine già pronte da cui prendere i pochi bytes richieste. Questo si chiama slab allocator
-
Se la richiesta è grande, fino a 4MB, fa in modo di allocare più pagine contigue in frame contigui, questo fa in modo che il DMA (Gli I/O accedono direttamente alla memoria), che ignora la paginazione, vada dritto in RAM.
-
Usa il buddy system
-
Gestione Memoria Utente
-
Fetch Policy: Paging on demand, le pagine vengono caricate quando richieste
-
Placement Policy: Primo frame libero
-
Replacement Policy: più avanti
-
Gestione resident set: Politica dinamica con replacement scope globale (sostituisce anche pagine di altri processi ma anche la cache del disco in questo caso), anche qui usa buddy system per richieste grandi
-
Politica di pulitura: Ritardata il più possibile
-
Controllo del carico: Assente
Replacement Policy:
Usa l’algoritmo dell’orologio “corretto” ma il kernel più recente usa un LRU “corretto”.
Il precedente algoritmo dell’orologio era molto efficace ma poco efficiente ovvero con molto overhead soprattutto con memorie molto grandi.
Questo nuovo algoritmo ha due bit PG_referenced e PG_active, sulla base di active il kernel mantiene due liste di pagine, attive e non attive.
C’è un thread del kernel chiamato kswapd in esecuzione periodica che scorre le pagine inattive:
PG_referencedviene settato ogni volta che la pagina viene richiesta- Poi possono accadere due casi: arriva prima
kswapdo arriva un altro riferimento a quella pagina. - Nel secondo caso la pagina diventa attiva, è stata chiamata due volte in poco tempo.
- Se invece arriva prima
kswapdilPG_referencedviene reimpostato a 0
Solo le pagine inattive possono essere rimpiazzate, per fare questo si usa una LRU con contatore a 8 bit.
Schema Grafico:
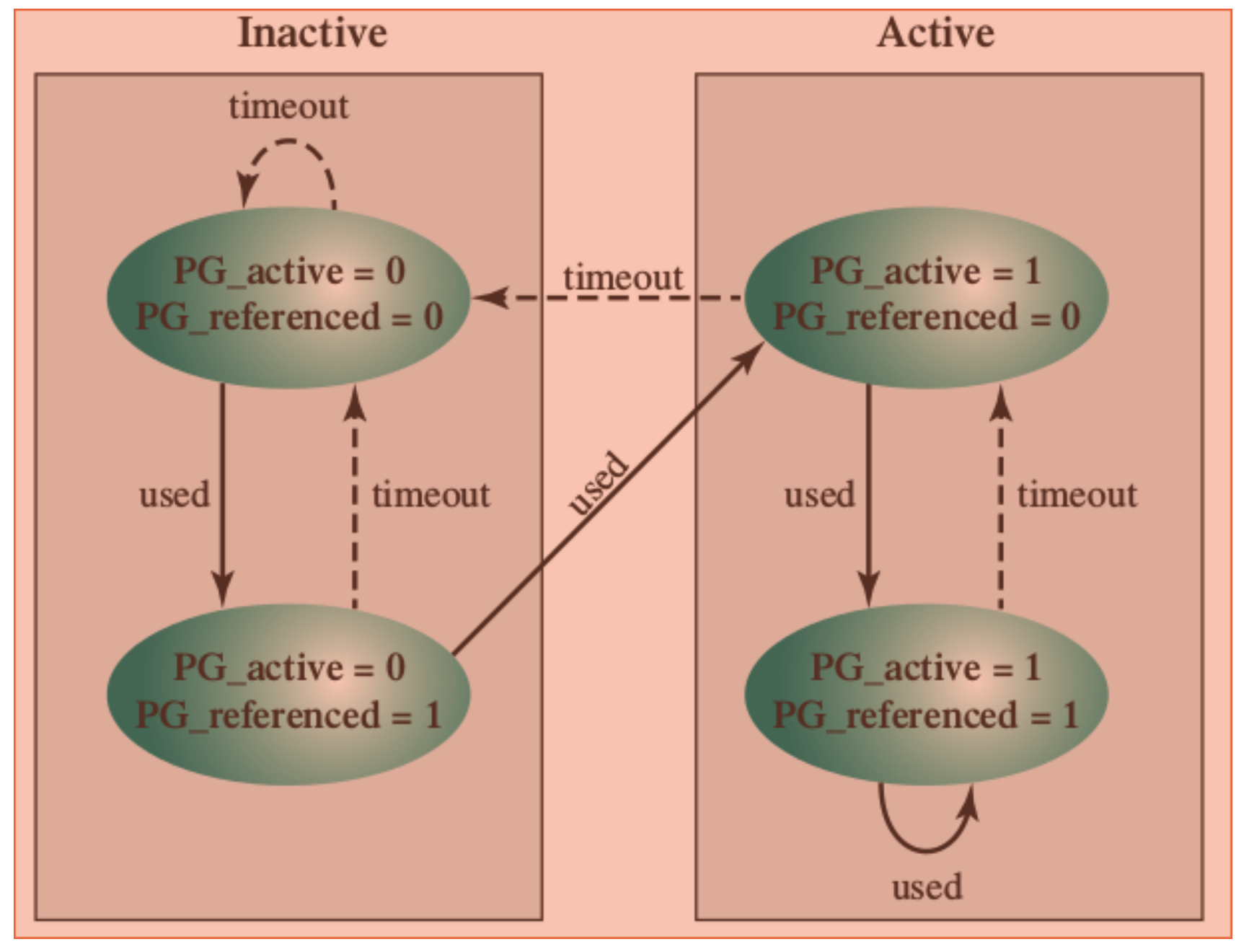
Con timeout intendiamo il tempo con cui arriva kswapd.