Il problema principale della gestione Input Output è che ci sono tantissimi dispositivi e tutti molto diversi fra loro, inoltre c’è anche una grande varietà di applicazioni che utilizzano questi dispositivi.
Scrivere un S.O. in grado di gestirli tutti è quindi molto difficile.
Possiamo dividere i dispositivi in 3 categorie:
- Leggibili dall’utente
- Leggibili dalla macchina
- Dispositivi di comunicazione
Dispositivi Leggibili dall’Utente
Sono i dispositivi utilizzati per la comunicazione con l’utente, come:
- Stampanti
- Terminali Hardware: Monitor, Tastiera, Mouse. Da non confondere con i terminali software dove eseguiamo comandi
In generale tutto quello che usa l’utente per dare informazioni al computer
Dispositivi Leggibili dalla Macchina
Dispositivi per la comunicazione leggibili in modo elettronico quindi ad esempio:
- Dischi
- Chiavette USB
- Sensori
- ecc…
Dispositivi di Comunicazione
Utilizzati per la comunicazione con altri dispositivi:
- Modem
- Schede Wi-Fi
- Schede Ethernet
Funzionamento dei Dispositivi I/O
Si chiamano così perché appunto servono a scambiare informazioni con un elaboratore.
Un dispositivo di input è fatto in modo per essere interrogato sul valore di una grandezza al suo interno, ad esempio:
- Il mouse può essere interrogato sul suo ultimo spostamento effettuato
- La tastiera viene interrogata sul codice Unicode dei tasti premuti
- Il disco vi dice i valori dei bit in una certa posizione
Un processo che effettua una syscall read su un dispositivo vuole conoscere questo dato per poi eseguire delle azioni.
Un Dispositivo di Output prevede di cambiare il valore di una certa grandezza fisica al suo interno. Ad esempio:
- Un monitor prevede di cambiare il valore RGB dei suoi pixel
- Una stampante il file da stampare
- Un disco il valore dei bit da sovrascrivere in una certa posizione
Un processo che effettua una syscall write vuole cambiare qualche valore all’interno del dispositivo.
Il sistema operativo deve quindi offrire due syscall: read,write e tra i loro argomenti ci sarà l’identificativo del dispositivo interessato, su Linux c’è il file descriptor.
Se avviene una syscall, entra in gioco il kernel che comanda l’inizializzazione del trasferimento di informazioni in lettura o scrittura a seconda del caso, mette il processo in blocked e passa ad altro. A questo punto al resto ci pensa il dispositivo I/O.
La parte del kernel che gestisce un particolare dispositivo I/O si chiama driver, questo quindi fornisce gli opportuni comandi al S.O. per controllare il dispositivo, spesso sono istruzioni macchina.
Il trasferimento dei dati spesso si fa con il DMA.
A trasferimento completato arriva l’interrupt e il processo torna ready:
- L’operazione di trasferimento potrebbe fallire, ad esempio un disco difettoso
- Potrebbe essere necessario fare ulteriori trasferimenti
Differenze tra Dispositivi I/O
Prima abbiamo detto che esistono tanti dispositivi di I/O, tutti diversi fra loro, vediamo quali sono i fattori che contribuiscono a questi cambiamenti:
- Data rate: Frequenza di accettazione / emissione di dati
- Applicazione: Il modo in cui vengono usati
- Difficoltà nel controllo
- Unità di trasferimento dati (caratteri oppure blocchi di dati)
- Rappresentazione dei dati
- Condizioni di errore
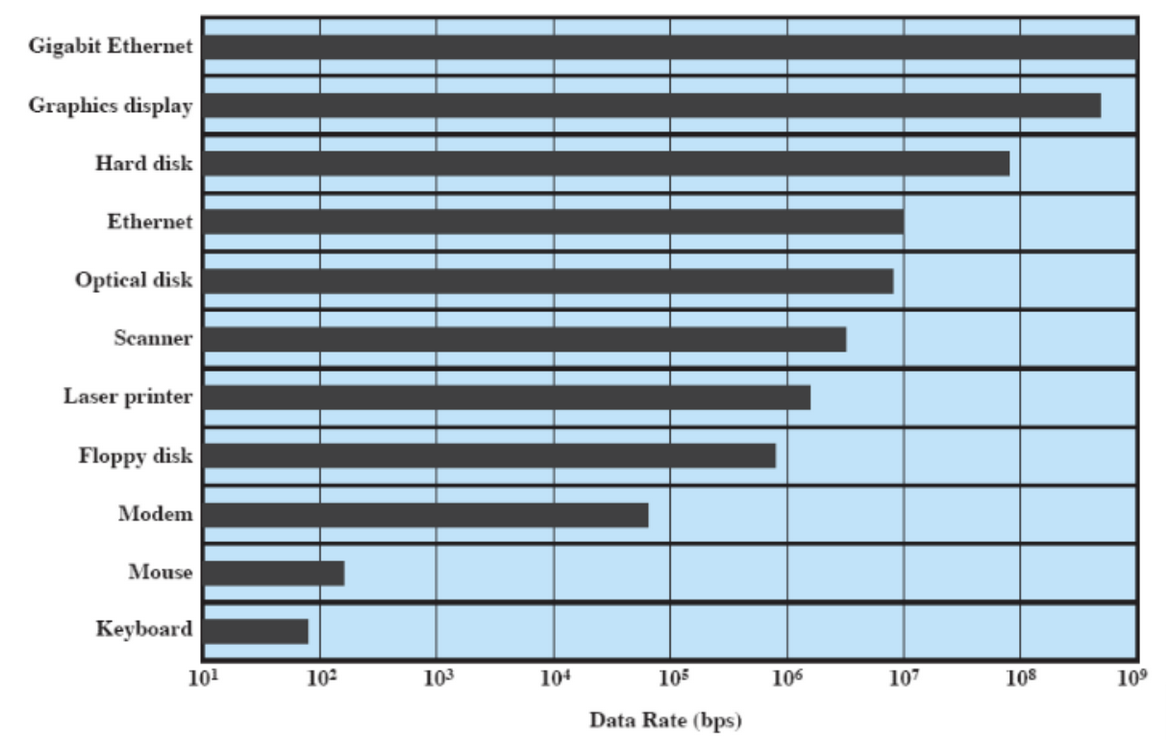
Data Rate
È la velocità di trasferimento dei dati, ci sono dispositivi molto lenti e altri molto veloci
Applicazioni
È il modo in cui vengono usati, ad esempio i dischi sono usati per memorizzare files e richiedono un software per la gestione di quest’ultimi. Ma possono anche essere utilizzati per la memoria virtuale.
Oppure un terminale come tastiera e mouse usato da un amministratore dovrebbe avere priorità più alta.
Complessità del Controllo
- Tastiera e Mouse richiedono un controllo molto semplice.
- Una stampante è più complessa dato che deve muovere molti macchinari per la stampa.
- Il Disco è una delle cose più complesse da controllare.
Tutto questo non si fa solo software ma anche con hardware dedicato.
Unità di Trasferimento Dati
I dati possono essere trasferiti:
- In blocchi di byte di lunghezza fissa, usato ad esempio per memorie secondarie come dischi, chiavi USB ecc…
- Flusso di byte (stream) o equivalentemente di caratteri, usato da qualsiasi cosa non sia memoria secondaria, quindi terminali hardware, dispositivi di comunicazione di rete ecc…
Rappresentazione dei Dati
I dati sono rappresentati secondo codifiche diverse in dispositivi diversi, ad esempio tastiere possono usare ASCII o UNICODE o avere controlli di parità diversi.
Condizioni d’Errore
La natura degli errori varia da dispositivo a dispositivo:
- Possono notificare gli errori in modo diverso
- Conseguenze degli errori, possiamo avere errori fatali o altri ignorabili
- Gestione degli errori
Ad esempio se abbiamo dei pixel rotti su un monitor non funzioneranno quelli e basta, ma se invece su un disco abbiamo degli errori potrebbe non avviarsi nemmeno il sistema operativo.
Tecniche per effettuare I/O
In generale abbiamo diverse modalità di fare I/O:

DMA
- Il processo delega le operazioni di I/O al modulo DMA.
- Il modulo trasferisce i dati direttamente da o verso la memoria principale
- Quando l’operazione è terminata, il modulo genera l’interrupt per il processore
Modulo DMA:
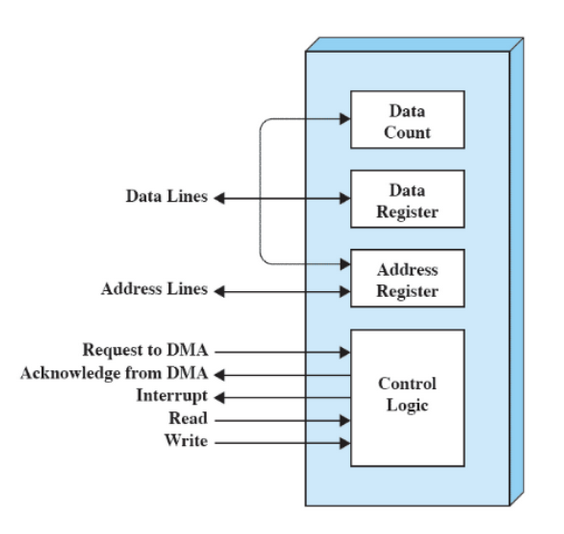
- Data Register: Contiene i dati da trasferire
- Control Logic: Decide cosa deve fare, contiene quindi informazioni sull’operazione da eseguire.
Le frecce che vanno verso l’esterno sono informazioni che il DMA da al S.O., le frecce verso di lui invece sono informazioni che riceve.
Evoluzione della Funzione di I/O
Inizialmente il processore controllava il dispositivo esterno.
Successivamente è stato aggiunto un modulo di I/O direttamente sul dispositivo, abbiamo ottenuto il I/O programmato, senza interrupt ma il processore non si deve occupare di alcune cose del dispositivo.
Vengono introdotti gli interrupt, migliorano l’efficienza dato che il processore non deve aspettare che il dispositivo finisca.
Viene introdotto il DMA, i dati viaggiano direttamente tra dispositivo e memoria senza usare il processore, quest’ultimo agisce solo all’inizio e alla fine dell’operazione.
Viene migliorato il DMA, il modulo I/O diventa un processore separato chiamato I/O Channel, successivamente gli viene data anche una RAM dedicata. Quindi molti dispositivi di ultima generazione sono dei “mini computer” a tutti gli effetti.
Come otteniamo l’efficienza?
La maggior parte dei dispositivi sono molto lenti rispetto alla RAM, come abbiamo visto dobbiamo sfruttare al meglio la multiprogrammazione per mettere in attesa programmi mentre altri sono in esecuzione.
L’I/O potrebbe comunque non riuscire a stare al passo della CPU, avremo quindi pochissimi processi ready.
È necessario quindi cercare soluzioni software dedicate a livello di S.O., come visto prima in particolare per il disco.
Generalità
Un altro obiettivo è quello di gestire i dispositivi in modo uniforme, nascondere la maggior parte dei dettagli dei dispositivi nelle operazioni a basso livello.
Quindi non è bene avere diverse syscall read per ogni dispositivo, è meglio averne una con parametri diversi.
Dobbiamo offrire diverse operazioni: read, write, lock, unlock, open, close.
Ad esempio leggere da tastiera o dal mouse è molto diverso ma il S.O. deve farle sembrare cose simili.
Come otteniamo questi obiettivi?
Progettazione Gerarchica
Ogni livello si basa su quello che fa il sottostante ed offre servizi al sovrastante. Ogni livello contiene funzionalità simili per complessità, tempi e astrazione. Inoltre modificare un livello non dovrebbe causare effetti sugli altri.
Per l’I/O ci sono 3 macrotipi di progettazioni maggiormente usate.
Dispositivo Locale
Usato per dispositivi locali, ad esempio stampante, monitor e tastiera.
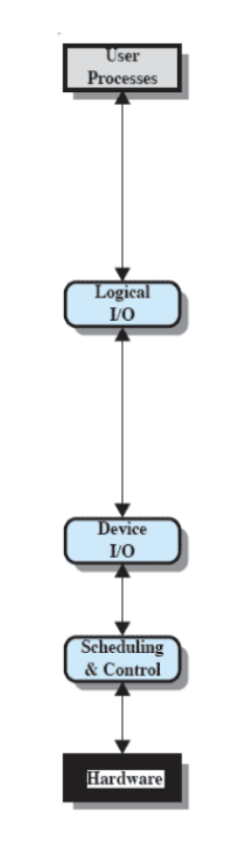
A livello più in alto abbiamo il processo utente che ha richiesto un’informazione da un dispositivo. In fondo abbiamo l’hardware che fornisce istruzioni macchina e in mezzo abbiamo cosa deve fare il S.O.
- logical I/O: Da un’interfaccia logica al programma, l’utente quindi può chiedere di fare queste istruzioni. Lui le trasforma e le passa a
- Driver I/O: Trasforma le richieste logiche in comandi I/O.
- Scheduling and Control: Invia le vere e proprie richieste in linguaggio macchina
Dispositivo di Comunicazione
È praticamente identico, al posto di Logical I/O abbiamo Communication Architecture, questo perché possiamo avere diverse architetture di comunicazione, ad esempio TCP/IP.
File System
Ci concentreremo di più su questo. Si usa per i dischi come SSD, HDD, CD, DVD ecc…
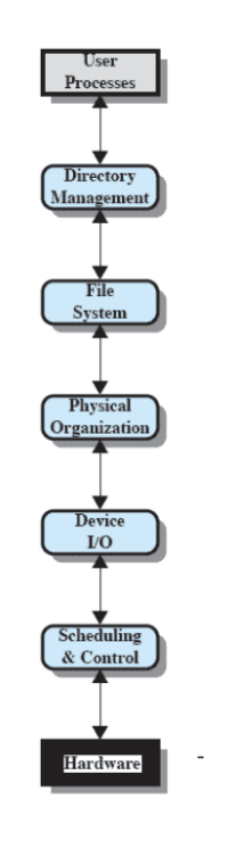
Anche qui partiamo da processo utente e arriviamo all’hardware.
- Directory Management: Definisce le operazioni sui file come crearli, cancellarli ecc…
- File System: È la struttura logica dell’operazione quindi come dobbiamo aprirli, scriverli ecc…
- Organizzazione Fisica: Si occupa di allocare e deallocare spazio sul disco
Tecniche Input Output
Buffering dell’I/O
Nell’attesa del completamento di un’operazione di I/O, alcune pagine devono rimanere in memoria principale per evitare un deadlock. Infatti:
Se un processo richiede un I/O su una sua zona di memoria, ma poi questo viene sospeso e sostituito da un altro processo, la richiesta per essere completata ha bisogno del processo in memoria, ma il processo per tornare in memoria ha bisogno del completamento della richiesta. Siamo in deadlock.
Una soluzione a questo problema è il buffering, ovvero effettuare trasferimenti di input in anticipo e di output in ritardo rispetto alle richieste. E quindi non eseguirle on-demand.
Quindi cosa succede?
-
Senza buffer il SO accede al dispositivo nel momento in cui ne ha bisogno:
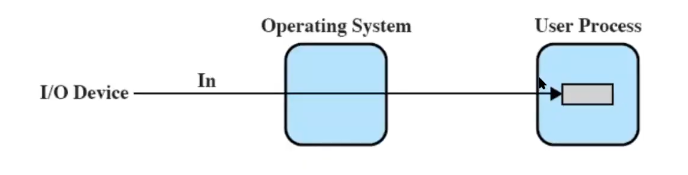
E questo comporta i problemi visti prima.
-
Utilizzando il buffering, il SO crea un buffer in memoria principale per una specifica richiesta I/O
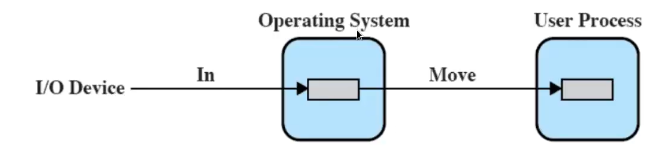
Quindi il sistema operativo fa la lettura e la mette nel buffer, poi in un secondo momento fornisce l’informazione al processo utente. Quindi dobbiamo fare un trasferimento da RAM a RAM e non da I/O a RAM.
Buffer Singolo Orientato a Blocchi
I trasferimenti di input vengono effettuati al buffer nella memoria del sistema e non in quella utente, il blocco viene mandato in quella utente soltanto quando necessario.
Questo comporta un input anticipato e di solito quando viene letto un blocco dal buffer vengono presi anche quelli vicino, dato che per il principio di località c’é una buona probabilità che questi servano. L’output viene invece posticipato.
Buffer Singolo Orientato agli Stream
Qui invece di avere i blocchi, si usa il buffer per intere linee di input o output
Buffer Doppio
Usare lo stesso buffer per tutti i dispositivi significa che prima o poi lo riempiremo e avremo di nuovo un collo di bottiglia ma invece che sui dispositivi, lo avremo all’interno del SO.
Per risolvere questo problema possiamo usare più di un buffer, ogni dispositivo controlla un puntatore che gli dice su quale buffer scrivere, poi il puntatore si porta al successivo, in questo modo mentre usiamo un buffer magari se ne libera un altro.
Buffer: Pro e Contro
Il buffer riesce a mantenere il processore non in idle anche con tanto richieste I/O, ma se c’è molta domanda i buffer si riempiranno comunque. Inoltre é utile quando ci sono molti dispositivi I/O diversi da gestire.
Un Contro é quello dell’overhead a causa della copia intermedia in kernel memory:
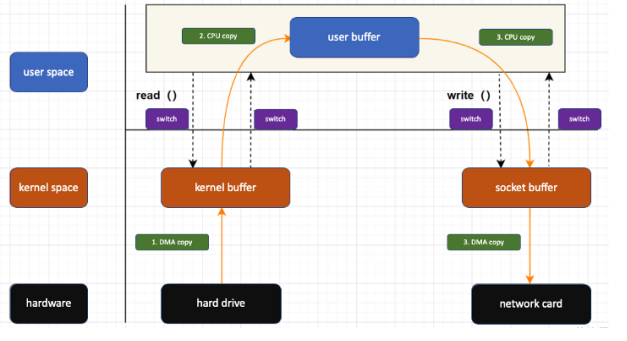
risolvibile con Buffer: Zero Copy:
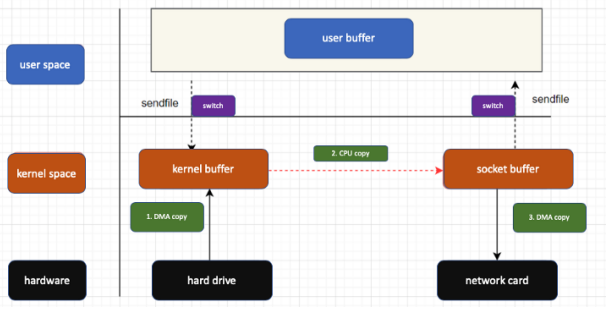
In questo modo evita copie inutili intermedia facendo trasferimenti da un kernel buffer ad un altro.
Scheduling del Disco
Le tecniche che vedremo valgono per gli HDD e non per gli SSD
HDD
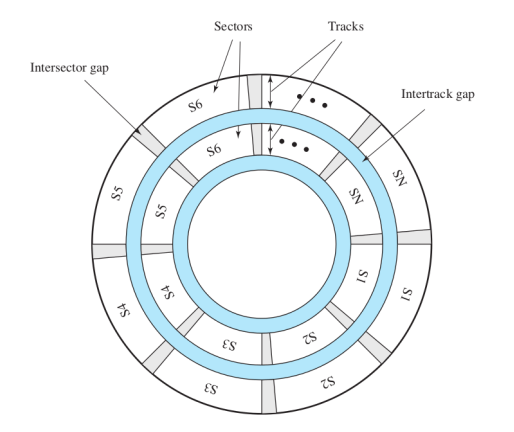
- Traccia: un percorso intero circolare
- Settore: una parte della traccia
Ovviamente avvicinandoci al centro queste diventano sempre più piccoli. Ci sono anche delle zone di “marcazione” che non contengono dati ma servono a delimitare le zone.
I dati si trovano quindi sulle tracce e sui settori, per leggere e scrivere quindi devo sapere su quale traccia e su quale settore di questa traccia si trovano i dati.
Per selezionare una traccia bisogna:
- Spostare una testina se il disco ha testine mobili (ci focalizziamo su queste)
- Selezionare una testina se il disco ha testine fisse
Per selezionare un settore:
- Dobbiamo aspettare che il disco ruoti in modo da avere la testina su quel settore
Ovviamente i dati possono trovarsi su più settori o addirittura più tracce. Tipicamente un settore misura 512 byte.
Un’operazione sul disco dipende da molti dettagli:
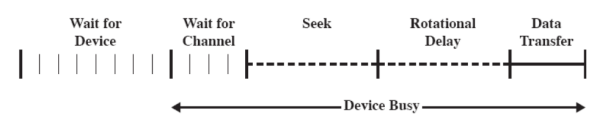
- Il SO chiede al disco se é libero per essere utilizzato.
- Se i dischi hanno più canali (più dischi) aspettare anche che il canale sia libero.
- Adesso che siamo nel disco interessato dobbiamo muovere la testina sulla traccia (seek).
- Aspettare il tempo di rotazione per il settore (Rotational Delay)
- Trasferimento dati, qui il disco continua a girare ma la testina legge o scrive dati.
Prestazioni del Disco
Abbiamo il tempo di accesso che é dato dalla somma di:
- Seek Time ovvero il tempo di posizionamento della testina sulla traccia
- Rotational Delay ovvero il tempo necessario affinché l’inizio del settore raggiunga la testina.
- Tempo di trasferimento, il tempo richiesto per trasferire i dati che scorrono sotto la testina.
Abbiamo inoltre anche i tempi di:
- Wait for device: Il tempo di attesa che il dispositivo sia assegnato alla richiesta
- Wait for channel: Attesa che il sottodispositivo sia assegnato alla richiesta (ad esempio se ci sono più dischi sullo stesso canale di comunicazione)
Politiche di Scheduling per il Disco
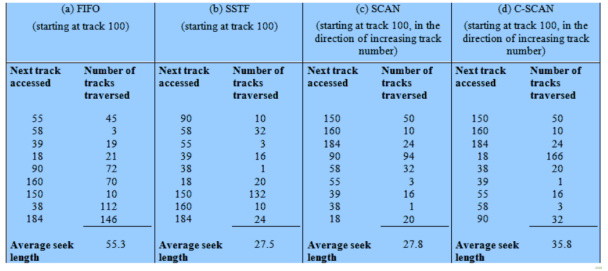
Su dischi a testine mobili sono stati pensati algoritmi per rendere efficienti le operazioni di scrittura e lettura. Le confronteremo tutte su un caso:
La testina si trova sulla traccia 100 e ci sono 200 tracce. Vengono richieste in ordine le tracce: 55, 58, 39, 18, 90, 160, 150, 38, 184.
Considereremo solo il seek time che é il parametro più importante per le prestazioni.
Li confrontiamo con il random, ovvero lo scheduling peggiore.
FIFO
Serviamo le richieste in modo sequenziale:
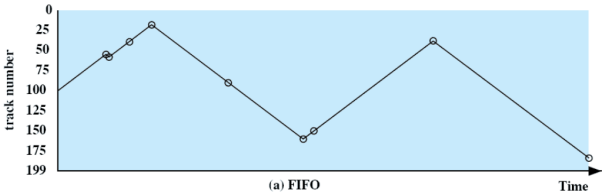
Questo é equo per i processi ma se ci sono molti processi le prestazioni sono simili allo scheduling random.
Priorità
In questo caso l’obiettivo non é ottimizzare il disco, ma rispettare le priorità dei processi. Vogliamo soddisfare prima i processi con alta priorità.
In questo modo i processi più lunghi potrebbero dover aspettare troppo e non va bene per i DBMS.
Non possiamo fare un grafico dato che non abbiamo i livelli di priorità delle richieste.
LIFO
Ottimo per DBMS con transazioni ovvero una sequenza di operazioni che non può essere interrotta. Il dispositivo viene affidato all’utente più recente a costo di “rallentare” altri utenti.
È possibile la starvation dato che potremmo dare la priorità a pochi utenti e non tutti. Questo si fa perché se un utente accede ad un file chiederà sequenzialmente altri dati di quel file ed é quindi più efficiente far finire lui prima.
Anche qui non possiamo fare un grafico dato che non sappiamo che utente ha fatto la richiesta.
Minimo Tempo di Servizio
In questo caso supponiamo di conoscere la posizione della testina e invece di andare nell’ordine delle richieste, scegliamo di volta in volta quella più vicina.
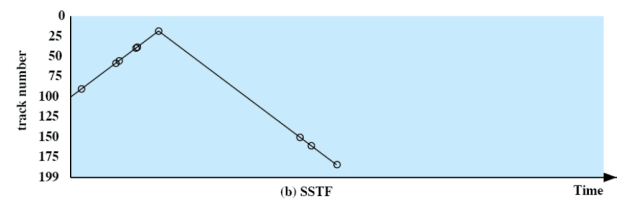
Notiamo che la testina si é mossa molto meno rispetto al FIFO.
È possibile che ci sia la starvation delle richieste, infatti mettiamo caso di aver servito la 90 e nel mentre arrivano altre richieste molto vicine a 90, potremmo rallentare molto alte richieste come ad esempio la 55.
SCAN
Si scelgono le richieste in modo che seguano sempre lo stesso movimento della testina:
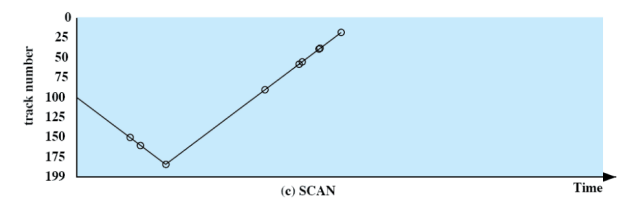
Quindi ci muoviamo verso l’alto da 100 e una volta raggiunta la più alta si torna indietro.
In questo modo evitiamo la starvation vista prima ma favoriamo le richieste ai bordi dato che vengono attrevarsati due volte in poco tempo. Questo viene risolto dal C-SCAN.
Inoltre favorisce le richieste appena arrivate, infatti se ben piazzate possono precedere richieste che sono li da molto tempo. Questo viene risolto dal N-step-SCAN.
C-SCAN
Funziona come lo SCAN ma si eseguono richieste solo in un “verso”:
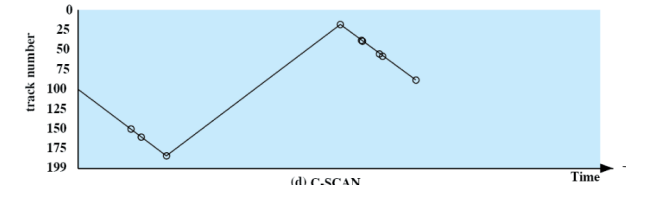
In questo caso le eseguiamo soltanto salendo. Infatti durante la discesa non vengono eseguite richieste.
FSCAN
Implementa due code, quando SCAN inizia tutte le richieste sono nella coda F e un’altra coda R é vuota. Mentre SCAN serve la coda F ogni richiesta viene aggiunta in R, in questo modo una volta finita F lo SCAN inizia a servire R.
In questo modo ogni nuova richiesta deve aspettare la conclusione delle precedenti e quindi quelle vecchie non vengono rimpiazzate dalle nuove come nello SCAN.
N-step-SCAN
È la generalizzazione del FSCAN ma con un numero di code. Se é molto alto abbiamo le prestazioni simili allo SCAN ma con fairness (equità). Invece se N=1 si usa il FIFO per ottenere equità.
Confronto Prestazionale

Cenni sugli SSD
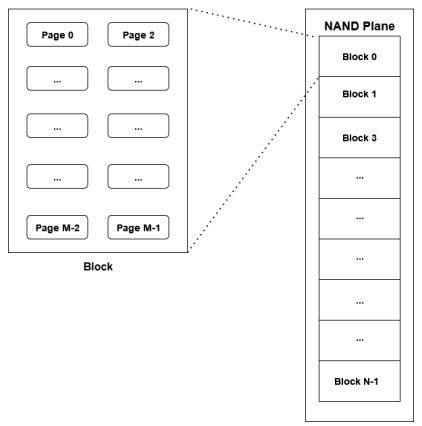
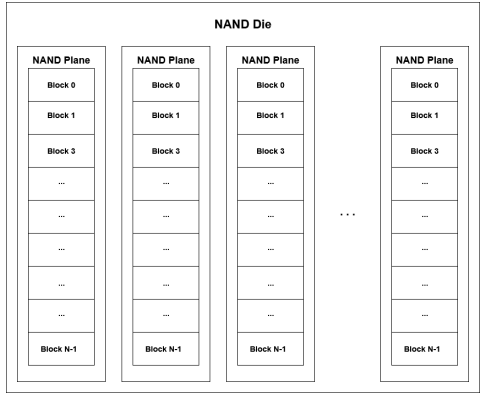
Come sono costruiti?
- Sono costituiti da flash chips (stack) di die, il controller dell’SSD gestisce questi stack
- Ogni die ha un numero di plaes
- Le planes sono divese in blocks
- Ogni block é composto da pages
- Ogni pagina é composta da cells, quest’ultime possono immagazzinare un solo bit (due se multi-level)
Graficamente:
Per quanto riguarda le operazioni:
- Sia in lettura che in scrittura l’unità di accesso minima é la pagina, però in scrittura una pagina può essere scritta solo se vuota e quindi non é possibili la sovrascrittura.
Sovrascrivere una pagina implica l’azzeramento dell’intero blocco che la contiene infatti si fa una copia del blocco, si azzera l’originale, si scrive la nuova pagina e si ricopiano le altre dalla copia effettuata prima.
Gli SSD sono estremamente veloci dato che non c’è tempo di seek infatti non dobbiamo preoccuparci di dove si trovano i dati, consentono accesso parallelo ai diversi flash chips ed esistono algoritmi e file system progettati per massimizzare le performance degli SSD. Ad esempio il F2FS.
Cache del Disco
Oltre al buffer abbiamo anche la cache del disco, é un altro buffer presente in memoria principale pensato per alcuni settori del disco. L’obiettivo é il solito delle cache, quindi se dobbiamo cercare qualcosa in un disco prima controlliamo se si trova in cache per risparmiare tempo, se il dato non c’è lo prendiamo dal disco e lo copiamo in cache.
Da non confondere con una cache del disco presente all’interno del disco, questa non ci interessa dato che invisibile al sistema operativo.
Quindi il solito problema é quello di capire cosa cancellare quando questa si riempie, abbiamo diversi algoritmi.
LRU (Meno di recente)
Se occorre rimpiazzare qualcosa si prende quello che si trova nella cache da più tempo.
La cache viene puntata da uno stack di puntatori, quello riferito più di frequente si trova in cima allo stack, quindi quando utilizziamo un dato dobbiamo portare il suo puntatore in cima. Se vogliamo quindi quello meno usato andiamo a prendere quello in fondo.
Non é un vero stack dato che non facciamo solo push, pop ma dobbiamo prendere anche il dato che si trova in fondo.
LFU (Usato meno di frequente)
Ci basiamo sulla frequenza degli accessi, serve un contatore per ogni settore che viene incrementato di 1 ad ogni riferimento. Per rimpiazzare scegliamo quello con il contatore al valore più basso.
Sembra avere più senso dell’LRU dato che meno viene usato un settore meno servirà tuttavia se usato come scritto prima potrebbero esserci effetti collaterali:
- Un settore viene acceduto molte volte di fila per la località dei dati ma una volta presi tutti non ci serve più, ormai però abbiamo accumulato molti accessi e quindi ha un valore alto nel contatore e non verrà sostituito.
Sostituzione basata su Frequenza
Cerchiamo di fare una via di mezzo fra i due.
Abbiamo uno stack di puntatori come LRU ma é spezzato in 2, una parte nuova e una vecchia.
Quando viene fatto un riferimento ad un settore questo viene portato in cima e poi abbiamo due casi:
- Se ci troviamo nella parte nuova il suo contatore non viene incrementato
- Se ci troviamo nella parte vecchia si
Se il settore non era presente in cache, viene portato all’inizio e il contatore impostato ad 1.
Quando dobbiamo effettuare un rimpiazzo prendiamo quello con il contatore minimo soltanto nella parte vecchia
Vogliamo evitare il problema visto prima del settore acceduto molte volte e poi “inutile”. Infatti in questo modo se accediamo molte volte, il settore finirà nella parte nuova ma il suo contatore non viene incrementato.
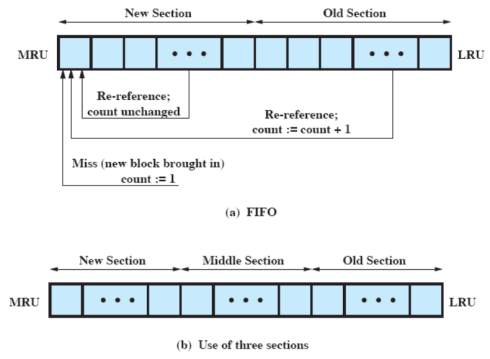
Abbiamo comunque un problema: se non si verifica presto un riferimento ad un blocco appena inserito questo potrebbe venir sostituito non appena scorre nella parte vecchia. Per risolvere questo problema facciamo 3 segmenti, come nella foto sopra.
A questo punto abbiamo 3 zone:
- Nuovo: Qui i contatori non vengono incrementati, non effettuiamo rimpiazzi qua dentro
- Medio: I contatori vengono incrementati ma non possiamo comunque fare rimpiazzi
- Vecchio: Contatori incrementati e rimpiazzi possibili
RAID
Redundant array of independent disks
Abbiamo a disposizioni più dischi fisici e possiamo trattarli separatamente:
- In Windows li mostra esplicitamente come dischi diversi
- Linux potrebbe dire che alcune directory sono in un disco e altre su un altro disco.
- Specifichiamo queste “regole” e poi non ci pensiamo più
Oppure un’altra strada è quella di considerarli come un unico disco, per fare questo in Linux abbiamo: Linux LVM (Logical Volume Manager).
Alcuni files e directory stanno in un disco e altri su un altro e questo viene deciso dal sistema operativo in particolare l’LVM appunto che é un modulo del kernel da aggiungere.
In questo modo l’utente non si preoccupa di dove salvare i file ed evitiamo di far crescere una directory fino a riempire il disco. Di questo problema se ne occupa l’LVM.
L’LVM va bene se si hanno pochi dischi e non ci interessa la ridondanza, ovvero memorizzare un dato su diversi dispositivi, in questo modo se uno si rompe abbiamo un “backup”. Ovviamente se abbiamo ridondanza dobbiamo fare in modo che i dati siano coerenti ovvero sempre uguali.
Per fare questo si usa il RAID, che non si occupa solo di ridondanza ma anche di velocizzare operazioni.
Esistono device composti da più dischi fisici e gestiti da un RAID direttamente dal dispositivo (hardware) e in questo il SO non se ne preoccupa, deve solo fare read e write. In altri casi è il SO a fare questa gestione.
Gerarchia Dischi RAID
RAID0
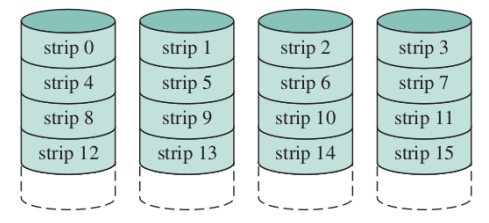
Non ha ridondanza, i dischi sono divisi in strip che contengono un numero di settori e un insieme di strip (una riga), si chiama stripe, ad esempio nella foto sopra una stripe sono gli strip 0,1,2,3 oppure 4,5,6,7.
Il vantaggio di questo RAID è solo la parallelizzazione, se io ho un file diviso su più strip posso accedervi in modo parallelo dato che sono su dischi diversi.
Come spazio totale abbiamo la somma degli spazi dei dischi.
RAID1
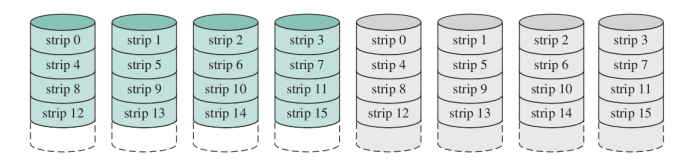
Fisicamente abbiamo dischi ma la capacità di memorizzazione è quella di dischi. Essenzialmente duplichiamo ogni dato su un altro disco.
Se si rompe uno di questi possiamo recuperare i dati, se si rompono 2 dipende da quali si sono rotti, infatti se si rompe un disco e la sua copia quei dati sono persi.
RAID2
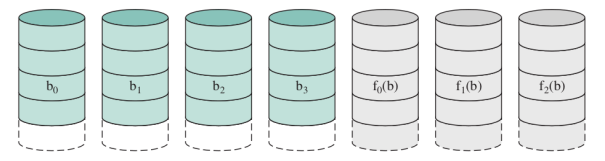
Con questo RAID vogliamo proteggerci non dai fallimenti di un intero disco ma magari solo di qualche bit.
Invece di duplicare esattamente un disco si usano dei codici particolari, di solito sono delle funzioni che prese in input delle sequenze di bit ne restituiscono un’altra con meno bit di solito in scala logaritmica.
Per esempio il codice di Hamming può correggere errori su singoli bit e rilevare errori su 2 bit.
Non si hanno più di dischi di overhead, ma tanti quanti servono a memorizzare il codice di Hamming che è proporzionale al logaritmo della capacità dei dischi.
Non viene utilizzato
RAID3
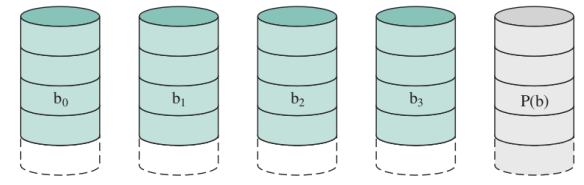
Anche questo non viene utilizzato ma serve a riprodurre quelli di livello superiore.
Abbiamo un solo disco di overhead che memorizza per ogni bit, la parità dei bit che hanno la stessa posizione, ad esempio se nei 4 dischi abbiamo nella stessa posizione tre ‘1’, allora nel disco di overhead avremo ‘1’, dato che il numero di ‘1’ è dispari, se avessimo avuto un numero pari allora avremmo trovato ‘0’.
Quando fallisce un solo disco é possibile recuperare i dati, ovviamente non deve fallire quello di overhead.
RAID4
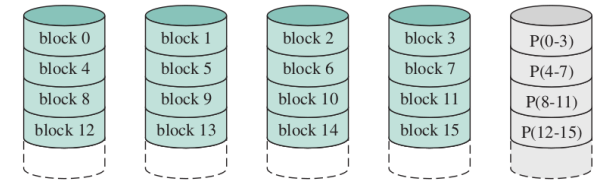
Funziona come il RAID3, ma nel 3 la parità era sui bit, qui la abbiamo sui blocchi, offre miglior parallelismo ma è complicato gestire piccole scritture.
RAID5
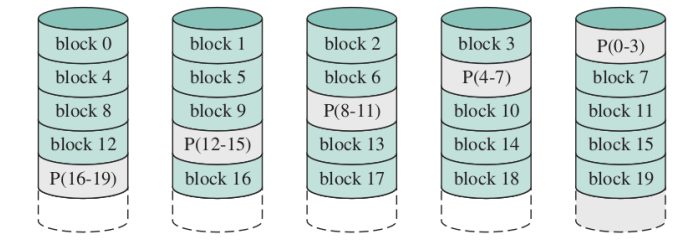
Risolve il problema del fallimento del disco di parità, qui infatti le informazioni di parità sono distribuite sui dischi stessi, nel RAID4 infatti ogni scrittura aveva effetto sul disco di parità qui invece non ne abbiamo uno privilegiato.
RAID6
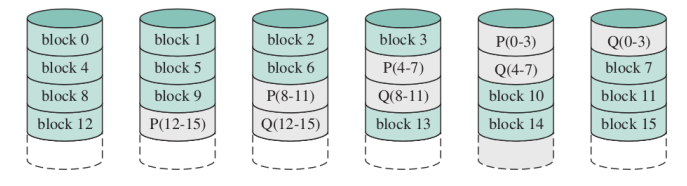
Qui abbiamo 2 dischi di overhead ma non designati infatti le informazioni sono sparse sui dischi.
Questo permette di recuperare le informazioni anche con il fallimento di due dischi.
Per le operazioni di scrittura abbiamo una penalità del 30% in più rispetto al RAID5 mentre invece si equivalgono per quanto riguarda la lettura.
Riepilogo
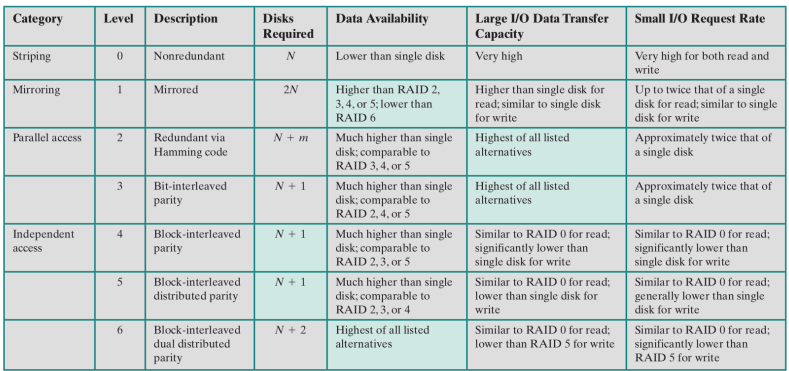
- Parallel access: se eseguiamo un’operazione sul RAID tutti i dischi effettuano in sincrono quell’operazione
- Indipendent: un’operazione sul RAID é un’operazione su un sottoinsieme dei suoi dischi, questo permette il completamento in parallelo di richieste distinte.
- Data availability: possibilità di recupero in caso di fallimento
- Small I/O request rate: velocità nel rispondere a piccole richieste di I/O, nella tabella viene indicato per ogni RAID in quali operazioni é migliore.
I/O in Linux
In Linux la page cache (cache del disco nel sistema) è unica per tutti i trasferimenti tra disco e memoria (anche virtuale).
Questo porta a 2 vantaggi:
- Scritture condensate
- Sfruttando la località dei riferimenti, si risparmiano accessi a disco
Quando si scrive su disco?
- È rimasta poca memoria e i processi ne stanno chiedendo altra
Non abbiamo una politica separata di replacement, è la stessa usata per il rimpiazzo delle pagine