È un modo di organizzare la memoria, si basa su file e directory, le directory possono contenere sia file che altre directory, entrambi si basano sugli INODE che vedremo più avanti o Inode.
Le directory hanno una struttura gerarchica ad albero, i file invece sono delle sequenze di bit e sono ASCII o binari, dobbiamo quindi conoscere come sono organizzati questi bit per poterli leggere. Esistono anche file speciali o non regolari come ad esempio i link.
Linux ha un solo filesystem principale e la radice delle directory è / che si chiama root.
All’interno di una directory troviamo dei file speciali che vediamo indicati come:
.: Indica la cartella corrente..: Indica la cartella precedente
Se ad esempio ci troviamo nella root allora entrambi indicheranno la root.
Ogni file o directory è raggiungibile dalla directory principale root mediante:
- path assoluto: Inizia dalla root ed è una sequenza di cartelle separate da
/.
Di solito il percorso fino alla cartella utente viene sostituito da ~, quindi ad esempio:
/home/utente1/dir1/dir2/file.pdf
Lo troveremo scritto come:
~/dir1/dir2/file.pdf
Conoscere la directory corrente (cwd)
Per conoscere in che directory ci troviamo (cwd) possiamo usare il comando
pwd. Per cambiare la cwd possiamo usare il comandocd [path]dove path può anche essere un percorso relativo. Nel path possiamo usare ad esempio..per tornare nella directory precedente.Se non inseriamo un percorso torniamo alla directory home dell’utente loggato.
Per creare una directory usiamo il comando mkdir seguito dal percorso della directory:
mkdir [OPTION] DIRECTORY
Se vogliamo creare un intero path e creare anche le cartelle che mancano usiamo l’opzione -p
Per creare i file invece possiamo usare touch nomefile, il vero utilizzo del comando touch è quello di modificare gli attributi temporali del file come data creazione, ultimo accesso in lettura ecc… però il comando se viene eseguito su un file che non esiste lo crea.
Path relativo vs assoluto
Un path assoluto inizia dalla root directory mentre quello relativo dalla cwd, current working directory.
Un path assoluto quindi è valido qualunque sia la cwd, mentre uno relativo se cambiamo cwd potrebbe non essere più valido.
In una directory troviamo anche dei file nascosti come ad esempio:
.bash_history: Contiene i precedenti comandi usati nella shell.bashrc: Contiene la configurazione della shell
Usiamo ls -a / --all per visualizzare anche i file nascosti
Se vogliamo visualizzare ad albero tutte le directory ed i file che contengono possiamo usare l’opzione -R per il comando ls oppure installare una utility esterna chiamata Tree.
Mounting
In Linux a differenza di altri OS siamo in grado di gestire diversi filesystem e proprio per questo i dispositivi esterni che colleghiamo non vanno a creare delle nuove unità ma semplicemente una nuova directory all’interno del preesistente albero delle directory.
Tutti i dispositivi che colleghiamo sono accessibili tramite la cartella /dev e tramite il comando mount possiamo collegarli in una directory, di solito /mnt/nomedispositivo, la cartella all’interno di /mnt deve già esistere.
La sintassi è - mount /dev/disco /mnt/directory, come opzione possiamo indicare anche il filesystem del disco oppure Linux potrebbe identificarlo da solo.
In generale una qualsiasi directory può diventare il punto di mount per un altro filesystem se e solo se la directory root di diventa accessibile da .
- Se è vuota, dopo il mount conterrà
- Se non è vuota i suoi dati non andranno persi ma torneranno accessibili dopo l’unmount di .
Il comando mount se usato da solo ci mostra i filesystem montati nel sistema.
Partizioni
Un singolo disco può essere diviso in una o più partizioni ad esempio una partizione può contenere il sistema operativo mentre una partizione contiene i dati degli utenti, quindi ad esempio la partizione verrà montata su / mentre la partizione su /home.
Questo può tornare utile ad esempio nel caso in cui volessimo cambiare sistema operativo o reinstallarlo, infatti possiamo reinstallarlo in e rimontare in /home. Questo meccanismo possiamo usarlo in generale per passare i nostri dati da una distribuzione ad un’altra.
Tipi di Filesystem
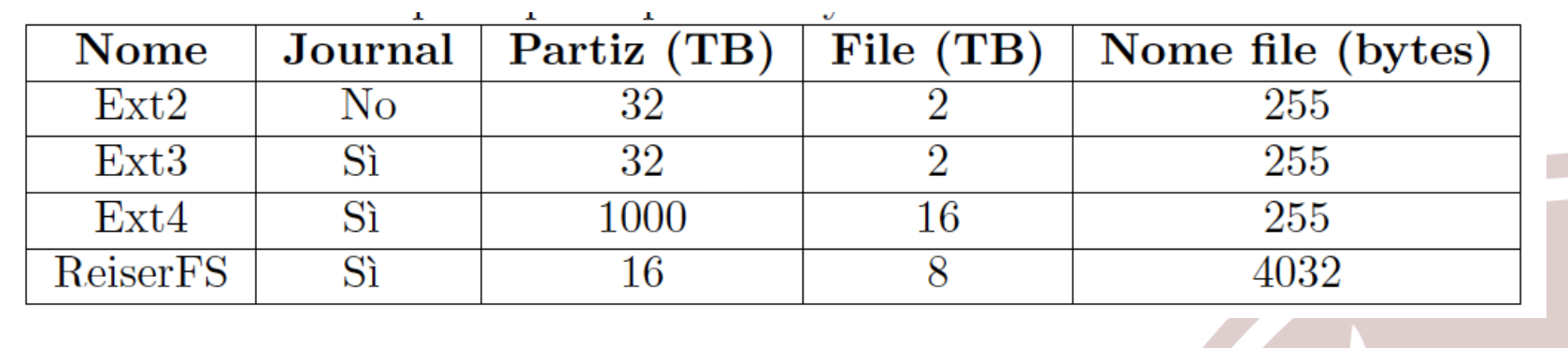
Per l’utente finale il filesystem può indicare:
- La dimensione massima delle partizioni
- La dimensione massima dei file presenti su disco
- Lunghezza massima dei nomi dei file
- Se c’è journaling o no
Per un programmatore invece indica il tipo di codifica dei dati.
Quindi le procedure da seguire sono:
- Scelta del FS
- Formattazione del disco in base al FS scelto
- Montare la partizione specificando il tipo di FS
I principali FS di Windows sono:
- NTFS, MSDOS, FAT32, FAT64 - FAT e NTFS possono essere montati anche su Linux
Diversi modi per visualizzare i file system montati:
mountcat /etc/mtabcat /etc/fstab- Questo visualizza i dischi da montare al boot del sistema

File passwd e group
Questi due file si trovano rispettivamente:
/etc/passwd- Contiene tutti gli utenti/etc/group- Contiene tutti i gruppi
Questi file hanno una struttura definita con la quale i programmatori possono “interfacciarsi” ad esempio come fa il comando adduser.
Entrambi i file sono organizzati per righe, una riga è una sequenza di caratteri che termina con un carattere speciale chiamato line feed o LF ed è il valore 0x0A, ogni riga contiene dei campi separati da :.
Il file passwd ha la seguente struttura:
username:password:uid:gid:gecos:homedir:shelldove al posto della password avremo unaxper indicare che questa è cifrata.
Il file group invece:
groupname:password:groupID:listautentiDove gli utenti nella lista sono separati da,. Anche qui troveremo una password cifrata e quindi indicata da unax.
I File
Ogni file del filesystem viene identificato da una struttura dati inode ed univocamente identificato da un inode number, quando cancelliamo un file andiamo a rendere nuovamente disponibile il suo inode number per un altro file quando sarà necessario.
Un file ha diversi attributi:
- Tipo - regular, block, fifo
- User ID - ID dell’utente proprietario
- Group ID - ID del gruppo a cui è associato il file
- Mode - Permessi di accesso al file da parte di utenti e gruppi
- Size - Dimensione in byte del file
- Timestamps
- mtime - indica l’ultima volta che il file è stato modificato
- ctime - indica l’ultima volta che è stato modificato un attributo del file
- atime - indica l’ultima volta che è stato letto qualcosa dal file
- Link count - Numero di hard link che puntano a quel file
- Data Pointers - Puntatore alla lista di blocchi che compongono il file, se si tratta di una directory allora il contenuto su disco è costituito da una tabella di 2 colonne dove vengono associati
nome file / directory - inode number
Ad esempio un filesystem ext2, è organizzato su disco nel seguente modo:
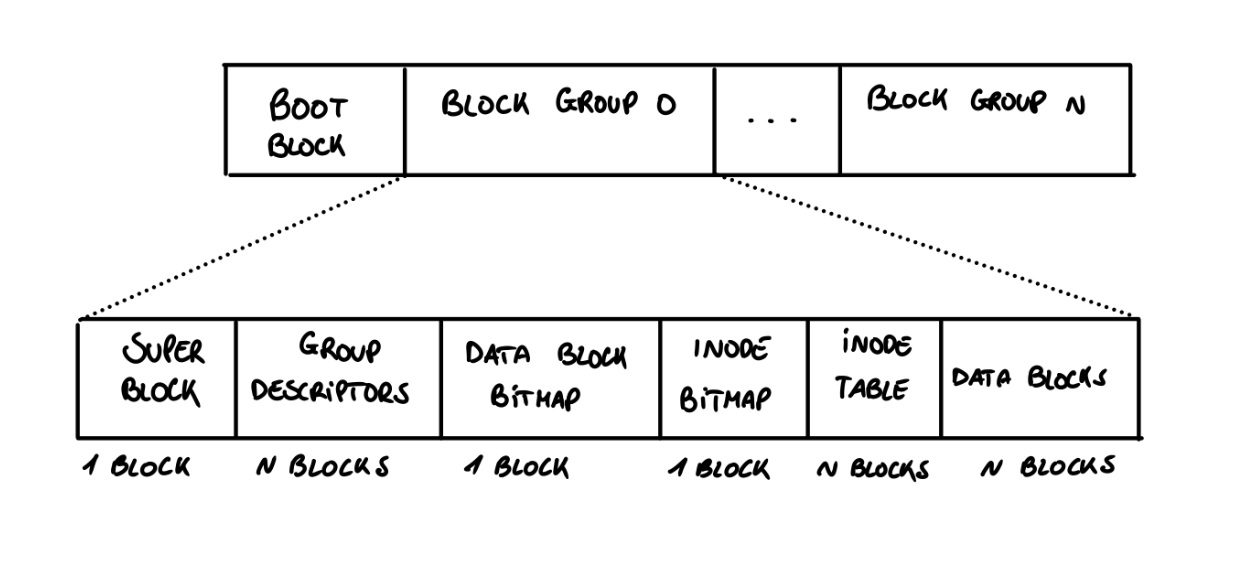
I primi 1024 bytes del disco sono riservati per la partizione di boot e non vengono usati quindi dal filesystem, il resto è separato in diversi blocchi, come è composto ogni blocco?
- SuperBlock - Contiene informazioni come il numero totale di blocchi su disco, le dimensioni di questi, numero di blocchi liberi ecc…
- GroupDescriptors - Descrive ogni blocco presente su disco, quindi ad esempio associa le bitmap ai blocchi e inode
- Data block bitmap / inode - Queste sono delle sequenze di bit, ciascuno rappresenta uno specifico blocco o inode. Se il bit vale 0 allora il blocco o inode è libero altrimenti è occupato. La grandezza di una bitmap deve entrare in un blocco
- Inode table - È una sequenza di blocchi che contengono degli inode, questa contiene tutto quello che il sistema operativo deve conoscere di un file quindi tipo, permessi, nome ecc… ma soprattutto dove si trovano i suoi data blocks. Su questa tabella vengono quindi eseguiti molto spesso degli accessi e va minimizzato questo tempo.
- Data Blocks - I blocchi veri e propri dei file.
Quindi a livello di associazione fra bitmap e blocchi avremo questa situazione:
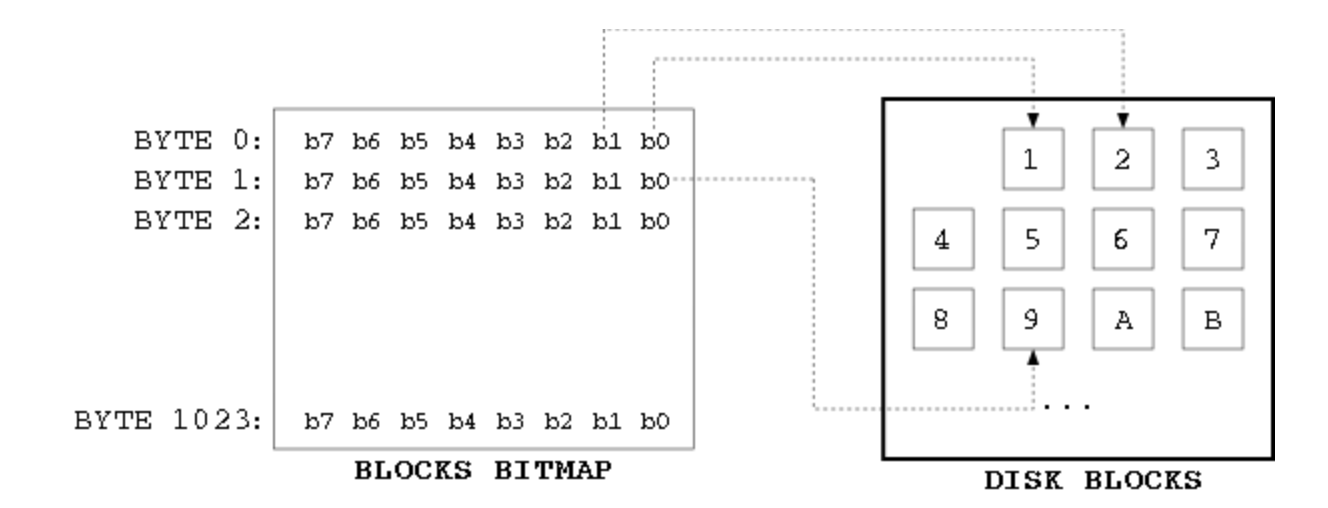
In un blocco entra tutta la bitmap e ogni bit indica la disponibilità di un blocco sul disco.
Per accedere ad un file quindi dobbiamo andare a leggere gli inode delle directory sul percorso, ad esempio:
- Cerchiamo
/home/ealtieri/hello.txt
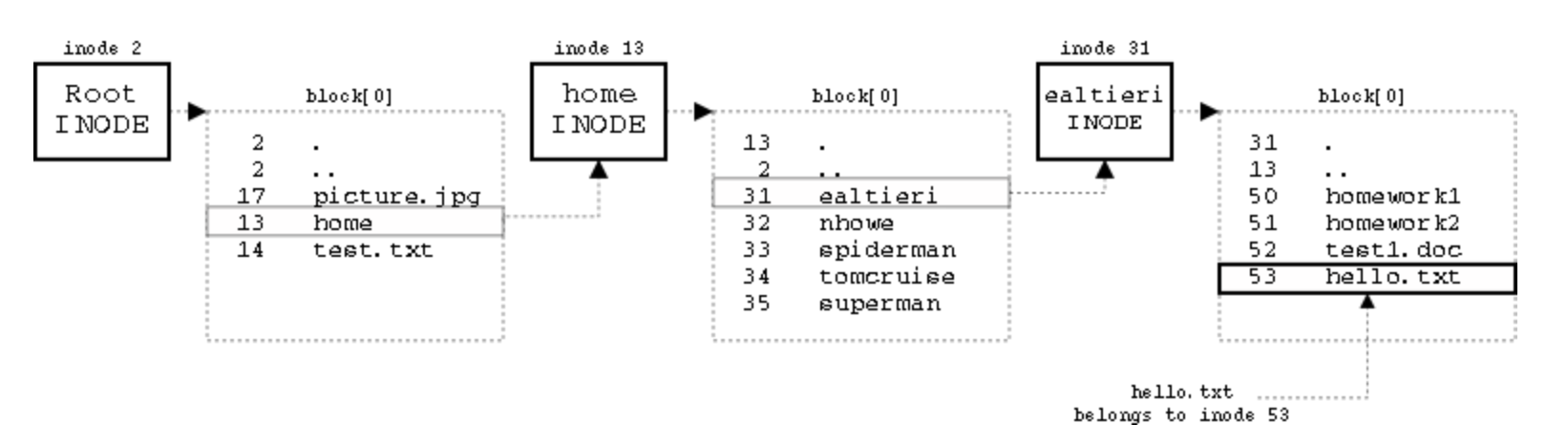
- Root si trova in inode 2 che ci porta al blocco 0
- home si trova all’inode 13 che si trova al blocco 0
- ealtieri si trova all’inode 31 sempre al blocco 0
- troviamo il file hello.txt che è collegato all’inode 53
Gli inode quindi mantengono “le informazioni” del file ovvero dove si trova mentre i blocchi contengono i dati veri e propri.
Come visualizziamo le informazioni contenute nell’inode di un file?
Usiamo ls con diverse opzioni:
-imostra l’inode number-lmostra altre informazioni come ad esempio i permessi degli utenti su quel file
Sintassi: ls [-i] [-l] nomefile
La dimensione che ci viene mostrato è lo spazio effettivamente utilizzato sul disco mentre per le cartelle ci viene mostrata la dimensione del file speciale che le “descrive” ovvero quello che contiene la tabella di coppie nome_file - inode_number.
Otteniamo un output simile:
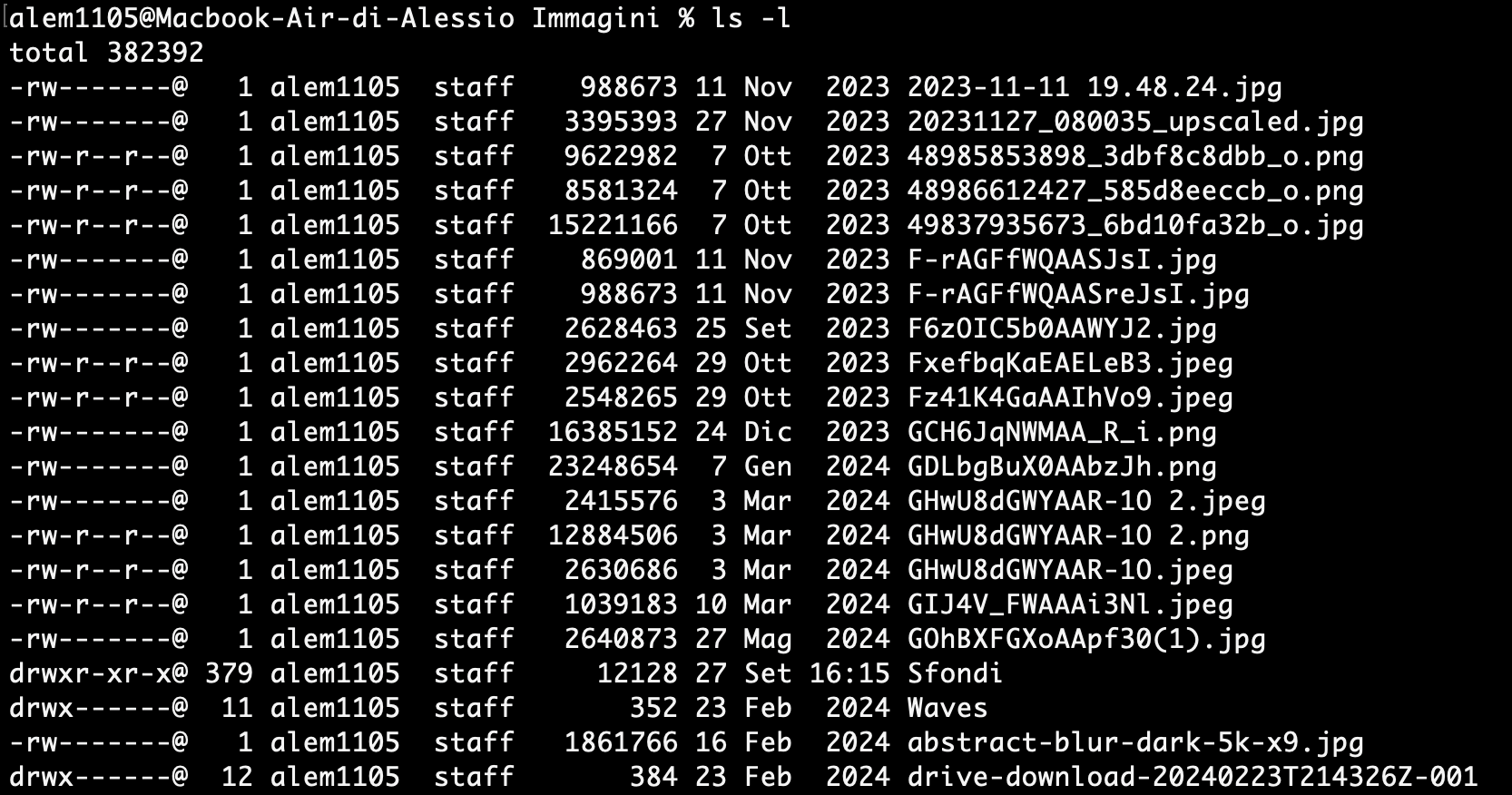
Un altro valore che possiamo osservare è il numero presente dopo i permessi, questo ci indica per le directory quanti file contengono, infatti per i file questo vale 1.
Il numero totale 382392 in alto invece indica la dimensione della directory in blocchi su disco, solo quella directory senza comprendere tutto il sottoalbero. Quindi essenzialmente considera soltanto le dimensioni di file e file speciali delle directory presenti al suo interno.
Altre opzioni che possiamo utilizzare sono:
-nper visualizzare gli ID degli utenti e gruppi e non il loro nome esteso- Per vedere i timestamp dobbiamo usare
-lma anche:-cper ctime-uper atime- niente per mtime
Un altro comando per ricavare informazioni dai file è stat filename, possiamo usarlo con:
stat -c %B filenameper ricavare la dimensione del blocco su disco che coincide con la dimensione di un settore di disco
Permessi di Accesso ai File
Possiamo definire i permessi per diversi utenti:
- Proprietario
- Gruppo del proprietario
- Resto degli utenti
I permessi sono indicati da una terna, ovvero quella vista sopra e per ciascun valore della terna ci sono altri tre valori ovvero r,w,e che indicano rispettivamente se quell’utente / gruppo può leggere, scrivere o eseguire il file.
Quindi una possibile terna è:
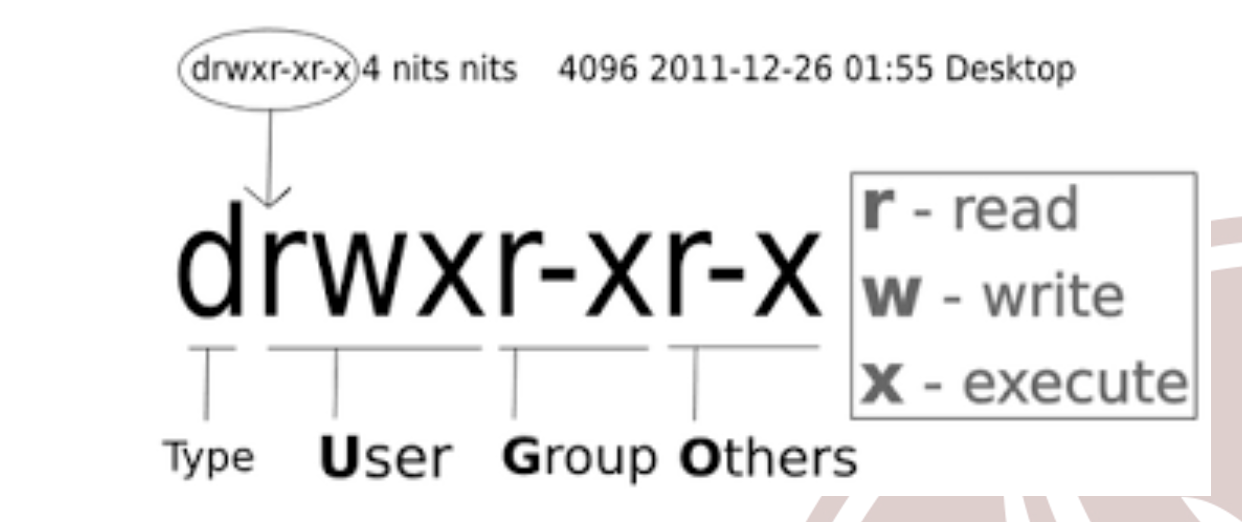
In generale:

Permessi di Accesso a Directory

Permessi Speciali
Questo tipo di permessi può essere applicato sia a file che directory, troviamo:
- sticky bit
t - setuid bit
s - setgid bit
s
Sticky bit - È inutile sui file, se invece è applicato su una directory corregge il comportamento di w+x in modo da non permettere la cancellazione di file anche senza permessi sul file stesso.
Siano:
- D una directory
- U e U’ due utenti diversi
- D appartiene a U
- D non appartiene a U’ ne al gruppo di U’
- f un file in D
Se U’ cerca di cancellare f allora:
- Senza sticky bit su D, sarà sufficiente avere i diritti di scrittura su D anche se non si hanno i permessi di scrittura su f.
- Con lo sticky bit sono necessari anche i permessi di scrittura su f per cancellare f.
setuid bit - Si usa solo per i file eseguibili, quando un file viene eseguito questo agisce avendo i permessi del suo proprietario e non dell’esecutore quindi se il proprietario è root il programma viene eseguito con privilegi di root indipendentemente dall’esecutore.
Un esempio è il comando passwd che permette a tutti gli utenti di essere eseguito soltanto sulla loro password, il comando infatti appartiene a root e lui può eseguirlo su tutti gli utenti.
setgid bit - Analogo al setuid ma per i gruppi, questo però può essere applicato anche alle directory. Quando creiamo un file di base gli viene assegnato come gruppo il nostro gruppo, se invece applichiamo il setgid ad una directory ovvero le assegnamo un gruppo, allora tutti i file creati al suo interno avranno come gruppo non quello del proprietario del file ma quello della directory.
Visualizzare gli attributi
Possiamo farlo con ls o stat
I permessi speciali vengono visualizzati al posto del bit di esecuzione:
- il
setuidnella terna user - il
setgidnella terna group - lo
stickynella terna other
Siccome sostituiamo il bit della x, se questo permesse c’era allora la so la tsaranno minuscoli altrimenti saranno maiuscoli.
Cambiare i Permessi di un File
Usiamo il comando chmod che ha una sintassi:
chmod mode[, mode...] filename
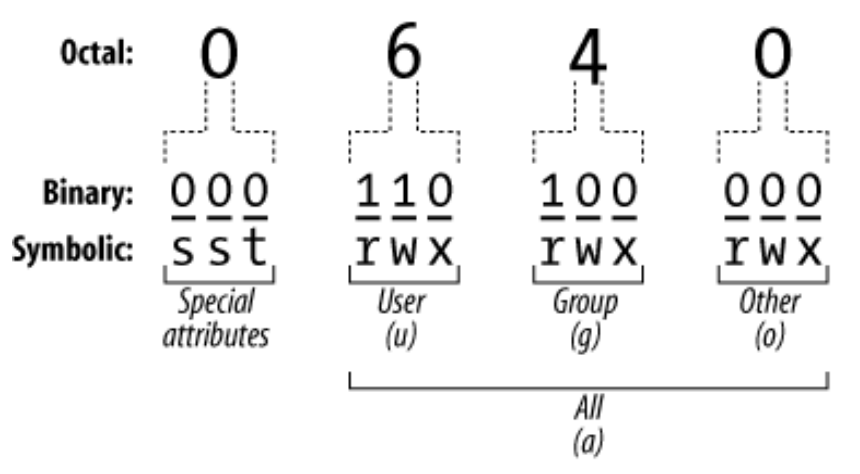
Usiamo il formato ottale (Casalicchio’s favorite):
- 4 numeri tra 0 e 7 come la tabella vista prima
- il primo numero indica setuid(4), setgid(2) e sticky(1)
- gli altri sono per utente, gruppo e other
- Si possono fornire 3 numeri se si assume setuid, setgid e sticky settati
Quindi dobbiamo effettuare somme in binario per decidere i permessi, quelli speciali infatti valgono appunto 4,2,1 e se vogliamo impostare ad esempio setuid e setgid scriveremo come primo numero 6.
Se vogliamo impostare tutti i permessi per il proprietario avremo come secondo numero 111 ovvero 7 oppure se vogliamo impostare soltanto lettura ed esecuzione 101 ovvero 5.
Possiamo usare la modalità simbolica:
- Usa la sintassi
chmod [ugoa][+-=][perms...] - Dove perms è zero o una o più lettere
rwxXstper i permessi oppure una lettera dei gruppi.
Esempi
- Per settare
rws r-S -w-usiamochmod 6742 filename - Per settare
rwx r-- -wTusiamochmod 1742 filename
Con la versione simbolica:
- Per settare
rws r-S -w-dobbiamo eseguirechmod g+rwsx filenamechmod u+rs filenamechmod o+w filename
Ovviamente vanno tolti eventuali permessi aggiuntivi con -
- Per settare
rwx r-- -wTeseguiamo:chmod g+rwx filenamechmod u+r filenamechmod o+wt filename
Possiamo impostarli tutti insieme con = ad esempio u=rwx imposta tutti i permessi all’utente.
Cambiare owner e gruppo di un file
Possiamo usare rispettivamente i comandi:
chown [-R] proprietario {file}chgrp [-R] gruppo {file}
Con l’opzione -R lo facciamo in modo ricorsivo sulle sottocartelle.
Questi comandi possono essere utilizzati solo da root.
Altri Comandi

Alcuni comandi:
-
umasksetta la maschera dei file a mode, ovvero imposta i diritti di accesso che avranno i file alla loro creazione. Da notare che la umask non funziona per quanto riguarda i permessi di esecuzione sui file ma per le directory si. -
ln- un link è un nuovo file che punta al file destinazione, questo collegamento è soltanto un puntatore. Con i soft link creiamo un nuovo file con un inode diverso, gli hard link invece non hanno il concetto di puntatore e puntato ma abbiamo direttamente lo stesso inode, cancellare il file quindi non è permesso se ci sono hard link collegati.
Con rm non rimuoviamo completamente un dato dal disco ma rimuoviamo il suo inode, per pulire completamente un’area di memoria possiamo usare il comando dd e scrivere quella zona ad esempio con tutti 0.
touchmodifica i timestamp di un file e se non esiste lo crea, può essere usato anche su directorydufa il conto di tutte le dimensioni dei file e directory dati come argomentodfmostra la dimensione e l’uso attuale del filesystemddServe per creare file in modo più elaborato ovvero gestendo in modo specifico i blocchi. Possiamo usarlo infatti per copiare anche dei file speciali che non sono copiabili concp. Può tornare utile anche nel caso visto sopra per cancellare completamente una zona di memoria.mkfsserve a creare un filesystem su un device, esegua una formattazione dato che prepara quella memoria a memorizzare i dati in un certo modo. Possiamo poi montarli conmount.