Visione d’Insieme
I File
I file sono l’elemento principale per la maggior parte delle applicazioni, molto spesso l’input di un’applicazione è un file o anche l’output.
I file a differenza della RAM “sopravvivono” ad un processo.
Il file system è quindi una parte del SO che più interessa all’utente e delle proprietà che deve gestire il SO sono:
- Esistenza a lungo termine dei file
- Diversi processi utilizzano gli stessi file
- Strutturabilità ovvero un sistema di organizzazione per aiutare l’utente a trovare i file
Gestione dei File
I file vengono gestiti da un insieme di programmi e librerie del kernel e questi vengono chiamati File Management System e sono eseguiti a livello kernel.
Le librerie vengono invocate come system call sempre in kernel mode.
Questi hanno a che fare con la memoria secondaria e in Linux anche con la RAM, possiamo gestirla come fosse un file.
Forniscono astrazione attraverso delle operazioni.
Per ogni file vengono mantenuti dei metadati come il proprietario, la dimensione, la creazione ecc…
Operazioni sui File
- Creazione
- Cancellazione
- Apertura
- Lettura, solo su file aperti
- Scrittura, solo su file aperti
- Chiusura
Terminologia
- Campo (field)
- Record
- File
- Databse
Campi e Record
I campi sono i dati di base e contengono valori singoli, sono caratterizzati da una lunghezza e un tipo di dato, un esempio di campo é un carattere ASCII.
Un insieme di Campi è un record, ad esempio Impiegato è caratterizzato da nome, cognome, matricola, stipendio.
File e Database
I file sono visti come insieme di record, questi hanno un nome e possono implementare meccanismi di controllo dell’accesso, decidere quindi chi può accedere a cosa. Nei moderni SO ogni record è un solo campo con un byte.
I database sono collezioni di file, esistono dei DBMS che sono dei processi che gestiscono database.
Sistemi per la gestione dei File
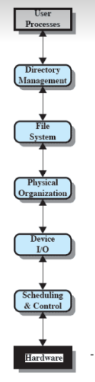
Adesso ci occuperemo di Directory Management, File System, Physical Organization.
I File Management Systems sollevano i programmatori dal dover scrivere codice per gestire i file e forniscono servizi agli utente per l’uso di file.
Obiettivi per un File Management System:
- Rispondere alla necessità degli utenti riguardo alla gestione dei dati
- Garantire che i dati non si corrompano
- Ottimizzare le prestazioni
- Fornire supporto per diversi tipi di memoria secondaria come USB, CD, DVD…
- Minimizzare i dati persi o distrutti
- Fornire interfacce standard per processi utente
- Fornire supporto per I/O effettuato da più utenti in contemporanea
Requisiti per i File Management System:
- Ogni utente deve essere in grado di creare, cancellare e modificare un file
- Ogni utente deve poter accedere in modo controllato ai file di un altro utente
- Ogni utente deve poter leggere e modificare i permessi di accesso ai propri file
- Ogni utente deve poter ristrutturare i propri file in modo attinente al problema affrontato (nei moderni SO hanno rimosso l’organizzazione in campi record ecc… e i file sono soltanto una sequenza di byte, e sta a chi progetta l’applicazione decidere come interpretare i byte)
- Ogni utente deve poter muovere i dati da un file ad un altro
- Ogni utente deve poter mantenere una copia di backup dei propri file
- Ogni utente deve poter accedere ai propri file tramite nomi simbolici (scelti da lui)
Ma vediamo come é organizzato il codice, riprendiamo la foto di prima:
- Directory Management: Sono tutte le operazioni utente che hanno a che fare con i file come crearli, cancellarli ecc… In questa fase si passa da nomi di file a identificatori.
- File System: Struttura logica delle operazioni (apri, chiudi, leggi, scrivi …)
- Organizzazione fisica: Dagli identificatori dei file si passa agli indirizzi fisici sul disco. Decide dove mettere i file e come posizionarli.
- Scheduling & Control: Qui avvengono i vari SCAN
Le Directory
Le directory sono anche loro dei file, anche se speciali, queste contengono altri file e le loro informazioni come attributi (metadati), proprietario e soprattutto la loro posizione. Forniscono inoltre il mapping tra nome del file e file vero e proprio.
I file system permettono in genere diverse operazioni sulle directory:
- Ricerca
- Creazione File
- Cancellazione File
- Lista del contenuto
- Modifica della directory
Le directory devono mantenere, per ogni file:
- Delle informazioni di base
- Nome del file, che in ogni directory deve essere unico
- Tipo del file (anche se alcuni SO non lo fanno)
- Organizzazione del file (non viene più usato ma serviva a capire come interpretare un file, come erano organizzati i suoi record e campi)
- Informazioni sull’indirizzo
- Volume: Indica il dispositivo sui cui é memorizzato il file
- Indirizzo di partenza: da quale traccia o settore inizia il file
- Dimensione attuale in word, byte o blocchi
- Dimensione allocata: la dimensione massima del file
- Controllo di Accesso
- Proprietario, chi può concedere o negare permessi ad altri utenti e modificare tali impostazioni
- Informazioni sull’accesso: ad esempio nome utente e password degli utenti autorizzati
- Azioni permesse: Per controllare lettura, scrittura, esecuzione o altro tramite rete
- Informazioni sull’uso
- Data di creazione e identità del creatore
- Ultimo accesso in lettura e scrittura
- Identità ultimo lettore o scrittore
- Data ultimo backup
- Uso attuale
Il metodo usato per memorizzare le informazioni sopra varia da sistema a sistema.
Inizialmente si faceva una sola directory con una lista di tutti i file sul dispositivo ma ovviamente portava a diversi problemi, ad esempio non si poteva dare lo stesso nome a due file e poi con il crescere dei file non aiutava l’organizzazione.
Si è passati a uno schema a due livelli dove c’è una directory per ogni utente che contiene una lista dei file di quell’utente. Inoltre tutte le directory degli utenti erano contenute in una directory master.
Schema Gerarchico ad Albero
Infine si è arrivati allo schema usato ancora oggi ovvero uno schema gerarchico ad albero per le directory. Qui una directory master contiene le directory utente che a loro volta possono contenere sia file che altre directory. Esistono anche sottodirectory di sistema.
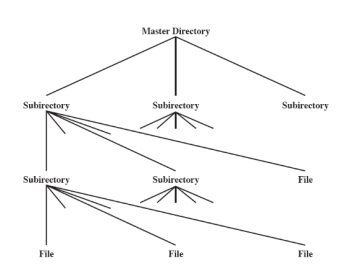
Gli utente devono potersi riferire ad un file usando solo il suo nome, questo deve essere unico. La struttura ad albero permette agli utenti di trovare un file seguendo un percorso nell’albero (directory path), i nomi duplicati sono possibili solo se con percorsi diversi.
Directory di Lavoro
Dare ogni volta il percorso intero di un file potrebbe risultare lento e noioso, per questo agli utenti viene solitamente associata una directory di lavoro, tutti i nomi dei file sono forniti relativamente a questa directory. Ovviamente è sempre possibile fornire l’intero percorso
Gestione della Memoria Secondaria
Il SO è responsabile dell’assegnamento di blocchi a file, significa che deve soddisfare l’utente sulle operazioni dei file, avendo a disposizione il disco.
Per fare questo ci sono due problemi principali:
- Decidere dove posizionare le strutture richieste
- Mantenere traccia di dove è stato deciso mettere le informazioni di un file
Ovviamente per fare questo è necessario tenere traccia anche dello spazio libero ovvero quello allocabile.
I file si allocano in “blocchi” e l’unità minima è il settore del disco, di solito un blocco è una sequenza contigua di settori del disco. Quindi ad esempio se dobbiamo salvare un file anche di un solo carattere, il SO allocherà comunque un intero blocco.
Ci sono vari problemi da affrontare.
Allocazione di Spazio per i File
Dobbiamo decidere:
- Se fare preallocazione oppure allocazione dinamica
- Blocchi di dimensione fissa o dinamica, di solito quando si parla di blocchi siamo in dimensioni fisse, se parliamo di porzioni in dinamica.
- Metodo di allocazione: Contiguo, concatenato o indicizzato
- Gestione della file allocation table: una tabella che mantiene delle informazioni per ogni file come ad esempio dove si trova sul disco e quali porzioni lo compongono.
Preallocazione vs Allocazione Dinamica
La preallocazione è molto semplice, stiamo creando un file e allora allochiamo sul disco la dimensione massima che quel file può richiedere. Nei file system che usano questa allocazione al momento di creazione di un file dobbiamo dichiarare anche la sua grandezza massima.
Ovviamente in alcune situazioni si può stimare facilmente la dimensione massima del file mentre in altre no. Quindi in alcuni caso la preallocazione porta a spreco di spazio anche se a un risparmio di computazione.
Per questo la preferita è la allocazione dinamica, la dimensione viene aggiustata in base alle syscall append, truncate.
Dimensione delle Porzioni
Quanto facciamo grandi le porzioni?
Abbiamo due possibilità:
- Allocare subito una porzione larga a sufficienza per l’intero file, questo è molto efficiente per il processo dato che le porzioni sono contigue e l’accesso sequenziale è più veloce.
- Allocare un blocco alla volta, è molto efficiente per il SO che deve gestire molte richieste.
Per fare al meglio, si cerca un insieme di queste due tecniche:
- Per le prestazioni di accesso al file sono ottime porzioni contigue
- Porzioni piccole portano a grandi tabelle di allocazione e quindi molto overhead dato che nella tabella abbiamo molte “indicazioni” per raggiungere tutte le porzioni di ogni file. Ma portano anche a maggior riutilizzo dei blocchi
- Vogliamo evitare grandi porzioni fisse che causano frammentazione interna, ovvero spreco di spazio
- La frammentazione esterna è sempre possibile infatti i file possono venire cancellati. Per frammentazione esterna intendiamo quando rimangono degli “spazi” non allocati molto piccoli non contigui sparsi per la memoria e che quindi non possono essere allocati da altri file, risultando quindi inutili. Essenzialmente, nel complesso magari abbiamo spazio per un nuovo file, ma gli “spazi” di memoria liberi non sono grandi abbastanza o non contigui da contenerlo.
Arriviamo quindi a 2 possibilità, valide per entrambi i tipi di allocazione:
- Porzioni grandi e di dimensione variabile, in questo modo ogni allocazione è contigua e le tabella delle allocazioni non è molto grande ma diventa complicata la gestione dello spazio libero, avremo bisogno di algoritmi ad hoc
- Porzioni fisse e piccole, tipicamente 1 blocco per 1 porzione, molto meno contiguo dell’altra opzione e per lo spazio libero ci basta guardare una tabella di bit.
Ad esempio con la preallocazione conviene utilizzare le porzioni grandi con dimensione variabile, in questo modo nella tabella ci basta salvare per ogni indirizzo il suo inizio e la lunghezza. Anche qui come nella RAM ci sono diversi modi per scegliere dove salvare i file ma é comunque inefficiente per quanto riguarda lo spazio libero dato che avremo bisogno di fare compattazione (problema della frammentazione). Compattare il disco é più costoso che compattare la RAM dato che il disco è un dispositivo I/O.
Come Allocare spazio per i File
Si utilizzano principalmente 3 metodi:
- Contiguo
- Concatenato
- Indicizzato
In ogni caso serve una tabella di allocazione dei file.
Per ciascuno dei metodi ci sono delle “regole”:
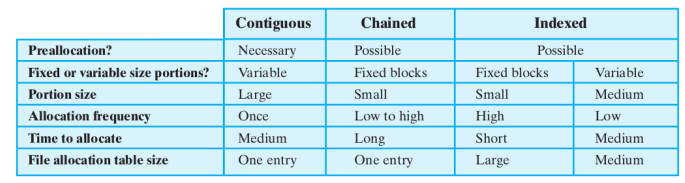
Allocazione Contigua
Se abbiamo un file e sappiamo quanto è grande allochiamo subito tutta la memoria necessaria in modo contiguo. Se non sappiamo quanto diventerà grande il file non possiamo quindi applicarla, perderemo contiguità.
In questo modo per ogni file sarà necessaria una sola entry nella tabella di allocazione che indica la partenza e la lunghezza del file.
Ci sarà frammentazione esterna al momento di cancellazione dei file con quindi necessità di compattazione.
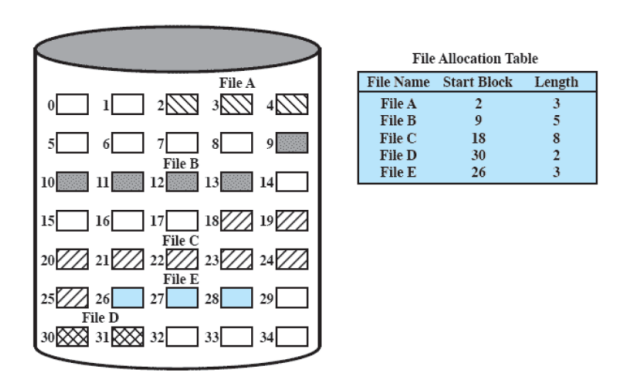
Quindi ad esempio se volessimo salvare un file da 8 blocchi anche se abbiamo a disposizione lo spazio necessario non potremmo farlo dato che non abbiamo 8 sezioni contigue, dovremmo eseguire una compattazione che ancora al giorno d’oggi è molto onerosa per il disco.
Se però eseguiamo compattazione otteniamo:
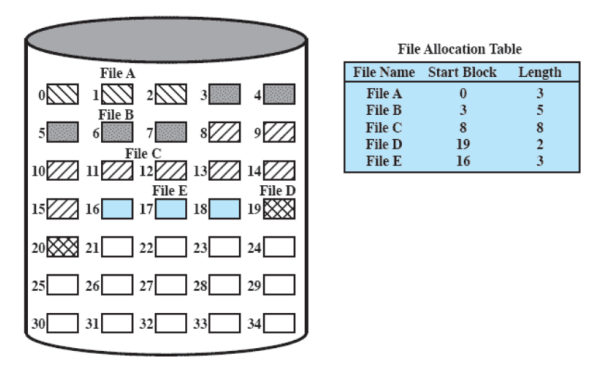
Da notare che è cambiata anche la tabella ovviamente.
Allocazione Concatenata
Allochiamo un blocco alla volta, non è necessaria preallocazione.
Ogni blocco, nella parte finale ha un puntatore al prossimo blocco, anche qui nella tabella abbiamo bisogno di una sola entry dato che i puntatori sono sparsi fra i blocchi.
La frammentazione interna è trascurabile mentre quella esterna non c’è dato che non vogliamo contiguità.
È buona se vogliamo accedere ad un file sequenzialmente ma se invece ci serve un certo blocco dobbiamo scorrerli tutti fino ad arrivare a quello desiderato.
Al posto della compattazione si esegue il consolidamento ovvero mettere i blocchi di un file contigui e migliorare l’accesso non sequenziale, quindi non serve a guadagnare spazio ma solo a migliorare le prestazione.
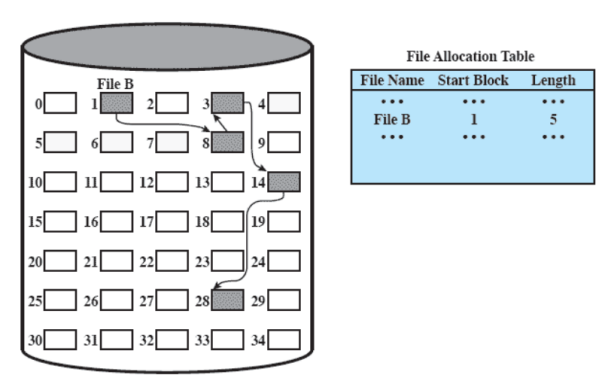
Se eseguiamo un consolidamento:
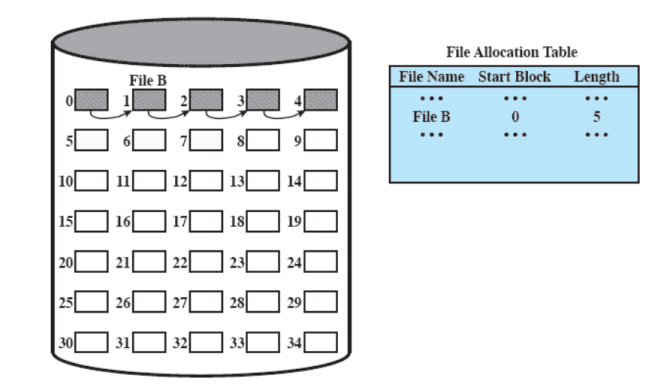
Allocazione Indicizzata
Questa è quella più utilizzata, anche se al giorno d’oggi con delle modifiche, è infatti una via di mezzo fra i due metodi precedenti ma risolve i loro problemi.
Qui la tabella contiene una sola entry per file con l’indirizzo di un blocco, ma questo blocco in realtà ha una entry per ogni porzione allocata al file, quindi abbiamo blocchi con indirizzi e blocchi con informazioni. È presente quindi un bit che indica che cosa contiene il blocco e se il file è troppo grande si fanno più livelli.
Vediamo un esempio:
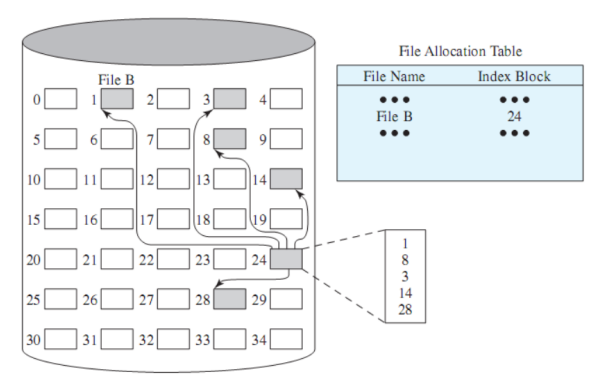
Quindi la tabella ci dice che il file B ha come blocco indice il blocco 24, dentro a questo blocco non troviamo i dati del file ma gli indirizzi dei blocchi che contengono il file, in questo caso, in ordine: 1,8,3,14,28.
Questo esempio è se utilizziamo delle porzioni a lunghezza fissa, se le abbiamo variabili:
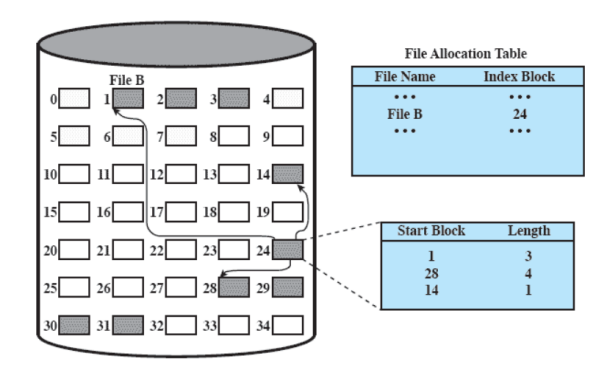
In questo caso il blocco degli indici oltre agli indirizzi deve contenere anche la lunghezza dei blocchi con le informazioni.
L’allocazione qui può essere:
- Blocchi di lunghezza fissa: niente frammentazione esterna
- Blocchi di lunghezza variabile: rischiamo frammentazione esterna ma migliore località A volte occorre il consolidamento:
- Blocchi di lunghezza fissa: migliora la località
- Blocchi di lunghezza variabile: riduce la dimensione dell’indice, prendiamo l’ultimo esempio, se il file B fosse tutto contiguo il suo blocco avrebbe una sola entry e non 3.
Gestione dello Spazio Libero
Adesso vediamo come gestire lo spazio libero invece di quello occupato dai file, infatti anche questo è altrettanto importante dato che per salvare i file devo sapere dove ho dello spazio libero.
Ci serve una tabella di allocazione di disco oltre a quella di allocazione dei file e ogni volta che si alloca o cancella un file dobbiamo aggiornare questa tabella.
Abbiamo comunque diversi modi per farlo
Tabelle di bit
Un vettore dove ogni bit é riferito ad un blocco su disco, se 0 il blocco é libero altrimenti é occupato, questo va bene per tutti gli schemi visti finora e minimizza lo spazio richiesto nella tabella di allocazione del disco.
Il problema é che se il disco é quasi pieno devo scorrere tutti i bit alla ricerca di uno 0, questo é risolvibile con delle tabelle riassuntive di porzioni della tabella di bit, ad esempio che indicano il numero di blocchi liberi in totale e quello di blocchi liberi contigui.
Porzioni libere concatenate
Questo metodo non ha praticamente overhead di spazio, infatti mi basta sapere dove sta la prima porzione libera e poi con dei puntatori vado a prendere le successive, un po’ come avevamo visto nell’allocazione concatenata.
Quindi avere zone libere contigue mi fa risparmiare spazio nella tabella dato che posso indicare l’inizio e la lunghezza.
Anche questa va bene per tutti gli schemi visti ma ci sono dei problemi:
- Se c’è frammentazione le porzioni sono tutte da un blocco e la lista diventa lunga dato che non posso indicare una lunghezza e l’inizio, ma ogni volta un nuovo inizio per ogni porzione.
- È lungo cancellare file molto frammentati
Indicizzazione
Tratta lo spazio libero come un file e quindi usa un indice come si farebbe per un file, l’indice gestisce le porzioni come se fossero di lunghezza variabile e quindi abbiamo un’entry per ogni porzione libera nel disco.
Questo offre molta efficienza a tutti i metodi di allocazione visti finora.
Lista dei Blocchi liberi
Ogni blocco ha un numero sequenziale e questi numeri vengono salvati in una zona di memoria.
Per i file noi carichiamo in RAM la tabella solo quando ne abbiamo bisogno, per quanto riguarda lo spazio libero invece dobbiamo sempre avere a disposizione informazioni su di esso. Con questo metodo riusciamo a farlo portando in RAM una parte di questa lista di numeri associati ai blocchi, possiamo infatti organizzarla come una pila e tenere la parte alta in RAM e poi utilizzare pop per allocare spazio, push per deallocare spazio. Quando la parte in RAM finisce si prende una nuova parte dal disco.
Ovviamente possiamo gestirla anche in altri modi come ad esempio una coda.
Volumi
I volumi sono un disco “logico” infatti possono essere una partizione del disco oppure anche più dischi messi insieme e visti come un solo volume (LVM).
I volumi sono quindi un insieme di settori della memoria secondaria che possono essere usati dal SO o dalle applicazioni, questi settori non devono essere necessariamente contigui ma appariranno come tali al SO e alle applicazioni.
Un volume potrebbe anche essere il risultato dell’unione di volumi più piccoli
Dati e Metadati: Consistenza
I dati sono il contenuto del file mentre i metadati sono delle informazioni aggiuntive sul file.
Ad esempio, lista blocchi liberi, lista blocchi all’interno del file, data ultima modifica, creatore ecc…
I dati sono su disco dato che devono persistere, ma per efficienza sono anche su RAM ma mantenere i metadati consistenti fra RAM e disco è inefficiente quindi si fa solo di tanto in tanto ad esempio quando il disco è poco usato o si sono accumulati molti aggiornamenti.
I SO moderni utilizzano il journaling, ovvero scrivere questi aggiornamenti da fare in una zona del disco dedicata chiamata log, quando appunto si può fare questo aggiornamento si fanno tutti quelli accumulati nel log, inoltre anche se il sistema crasha ci basta leggere il log.
E se c’è un evento imprevisto?
- Il computer viene spento all’improvviso
- Il disco viene rimosso senza dare un comando
Potrebbero esserci delle informazioni non aggiornate.
Ci basta scrivere un bit all’inizio del disco che ci dice se il sistema é stato spento correttamente.
Al reboot se il bit è 0 occorre eseguire un programma di ripristino del disco, cosa fa?
- Blocco in uso ma non appartenente a nessun file? Viene dichiarato libero
- Blocco libero ma appartenente ad un file? Lo si dichiara appartenente a quel file
- Se c’è journaling è più semplice dato che ci basta consultare il log
Journaling
Come detto prima è una zona dedicata del disco in cui scrivere le operazioni da fare prima di eseguirle effettivamente nel file system.
Se al reboot il bit di shutdown è 0:
- Confronta il journal allo stato corrente del file system
- Corregge inconsistenze nel file system basandosi sulle operazioni presenti nel journal:
- Se la scrittura è completa, in caso di crash durante la scrittura nel file system è possibile recuperare l’errore
- Se c’è un crash durante la scrittura nel journal, il file system rimane integro
Ci sono diversi tipi di journaling:
- Fisico
- Logico
Journaling Fisico
Copia nel journal tutti i blocchi che dovranno essere poi scritti nel file system, inclusi i metadati. Se avviene un crash durante la scrittura nel file system è sufficiente copiare il contenuto dal journal al file system al reboot successivo
Journal Logico
Copia nel journal soltanto i metadati delle operazioni effettuate e se c’è un crash si copiano i metadati dal journal al file system ma può causare corruzione dei dati infatti il contenuto del file è perso dato che non è stato salvato nel journal
Alternative al Journaling
-
Sofr Updates File System
Riordina scritture su file system in modo da non avere mai inconsistenze, ovvero permette solo determinati tipi di inconsistenze che non causano perdita di dati.
-
Log-Structured File Systems
L’intero file system è strutturato come un buffer circolare detto log e sia dati che metadati sono scritti in modo sequenziale sempre alla fine del log, possono esserci quindi diverse versioni dello stesso file corrispondenti a diversi istanti di tempo.
-
Copy-on-Write File Systems
Evitano sovrascritture dei contenuti dei file e scrivono i nuovi contenuti in blocchi vuoti aggiornando poi i metadati per puntare ai nuovi contenuti.
Gestione dei File in UNIX
In UNIX esistono 6 tipi di file:
- Normale
- Directory
- Speciale (Mappano i dispositivi I/O su nomi di file, ad esempio i dischi collegati)
- Named Pipe (Fanno comunicare tra loro i processi)
- Hard Link (Collegamenti, nomi di file alternativi)
- Link Simbolico (Contiene il nome del file cui si riferisce)
Inode
È una struttura dati che contiene le informazioni essenziali per un file.
Di solito per ogni inode c’è un file ma tramite gli Hard Link si può fare in modo che lo stesso inode si riferisca più file.
Tutti gli inode sono conservati sul disco e alcuni di questi sono anche in RAM ovvero quelli che si riferiscono a file aperti.
Ogni inode ha un numero associato tramite il quale possiamo accedere all’inode.
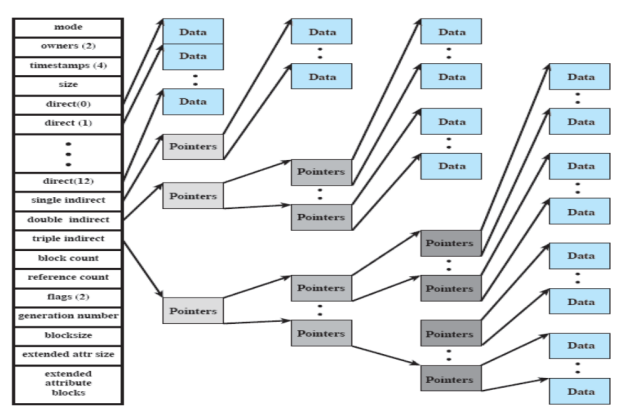
Alcune delle informazioni presenti negli inode:
- Quando il file è stato acceduto in lettura / scrittura per l’ultima volta
- Identificatori dell’utente proprietario
- Tempo di creazione e ultimo accesso
- Flag utente e kernel
- Dimensione totale del file
- Numero dei blocchi, dimensione dei blocchi e puntatori ai blocchi
- Se si riferisce ad una directory allora anche il numero di file
Per quanto riguarda la dimensione del file
Se andiamo a vedere la dimensione di un file avremo: dimensione file e dimensione su disco, questo perché la dimensione del file è quella vera mentre quella su disco è quella allocata tramite la dimensione dei blocchi e quindi superiore a quella effettiva in alcuni casi.

Qual é l’idea dietro gli inode per quanto riguarda l’allocazione di File?
- Se il file è piccolo i dati vengono raggiunti tramite i puntatori che nella foto sono chiamati direct, nell’esempio abbiamo 13 puntatori e quindi basterebbero se il file fosse grande . Se questi non bastano ci sono puntatori a più livelli: singoli, doppi, tripli.
- Singoli: → Blocco di Puntatori → Blocco
- Doppi: → Blocco di Puntatori → Blocco di Puntatori → Blocco
- Tripli: → Blocco di Puntatori → Blocco di Puntatori → Blocco di Puntatori → Blocco
Inoltre i blocchi non devono essere contrassegnati se sono per puntatori o dati, questo perché partendo dall’inode sappiamo quanti livelli dobbiamo passare.
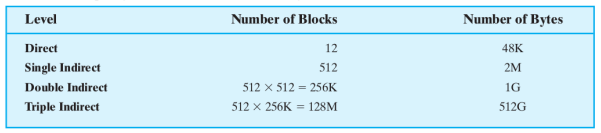
A destra sono indicate le dimensioni massime per un singolo file che possiamo coprire con i vari livelli di puntatori.
Questo perché se ad esempio abbiamo blocchi da 4KB e un puntatore occupa 4 byte con i puntatori singoli avremo il primo puntatore che punta ad un blocco di puntatori e dentro a questo blocco di puntatori possiamo immagazzinare puntatori ovvero blocchi di dati.
Con i puntatori doppi abbiamo il puntatore che punta ad un blocco di puntatori e questi puntatori a loro volta puntano ad altri blocchi di puntatori, quindi seguendo lo stesso esempio di prima abbiamo blocchi di dati.
Infine per il terzo livello sempre seguendo lo stesso esempio blocchi di dati.
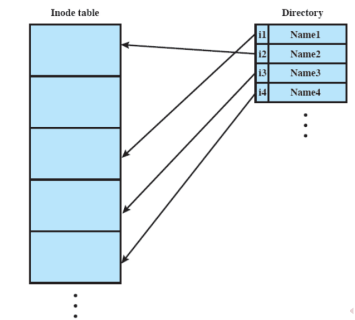
Inode e Directory
Le directory sono dei file speciali che contengono una lista di coppie formate da (nome di file, puntatore ad inode corrispondente) e alcuni di questi file potrebbero essere a loro volta delle directory formando così una gerarchia:
Accesso ai File
Come visto prima, per accedere ad un file dobbiamo essere un utente abilitato.
Per ogni file esiste una terna di permessi: lettura, scrittura ed esecuzione. Quando qualcuno vuole svolgere un’operazione su un file Linux confronta i permessi con l’utente che ha richiesto l’operazione.
Ci sono 3 distinzioni: Proprietario, gruppi dove si trova il proprietario e tutti gli altri.
Quindi:
- Prima si controlla se l’utente coincide con il proprietario
- Se questo non accade si cerca se hanno un gruppo in comune
- Altrimenti si applica la regola per gli altri
Esempio
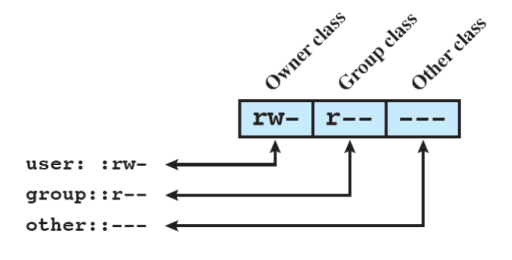
In questo esempio:
- Proprietario ha scrittura e lettura
- Gruppo del proprietario ha solo lettura
- Gli altri nessuna
Gestione File Condivisi
Come si gestiscono i file che devono essere condivisi su più directory? Dato che fare una copia del file è costoso ed inutile ci sono diverse soluzioni:
- Symbolik Links
Esiste un solo descrittore del file originale, ad esempio un inode e i symlink contengono il cammino completo sul file system verso quel file. Da notare che possono esistere symlink a file non più esistenti.
- Hard links
Puntatore diretto al descrittore del file originale, ovvero l’inode, il file condiviso non può essere cancellato finché esistono link remoti ad esso. L’inode contiene un contatore dei file che lo referenziano.
Gestione dei File su Windows
Windows ha 2 file system principali:
- FAT: vecchio file system presente sulle versioni MS-DOS
- NTFS: nuovo file system, usa un’allocazione con bitmap con blocchi (cluster) di dimensione fissa.
FAT
FAT sta per File Allocation Table, è infatti una tabella ordinata di puntatori ma è molto limitato e andava bene per i vecchi dischi, tuttavia viene ancora usato per le chiavette USB.
In questa tabella sono presenti dei record che possono essere da 12, 16 o 32 bit, da qui i nomi FAT-12, FAT-16 e FAT-32. Abbiamo tanti record quanti i cluster del disco.
I cluster hanno dimensione da 2 a 32KB ed è scelta dall’utente in fase di formattazione, da qui nascono i primi problemi infatti se abbiamo ad esempio un disco da 32MB e scegliamo 32KB come dimensione dei cluster allora la nostra tabella è lunga 1000 e se questi record sono da 32bit avremo 4KB di tabella.
È quindi poco scalabile, se ad esempio abbiamo puntatori da 32 bit con un disco da 100GB e cluster da 2KB allora la FAT ha 50M di righe quindi per la FAT.
Come funziona?
Il volume viene diviso in varie regioni:

-
Regione Boot Sector: Contiene informazioni necessarie per l’accesso al volume ovvero la tipologia e il puntatore alle altre sezioni del volume e il bootloader del sistema operativo
-
Regione FAT: È la tabella dei puntatori vista prima, mappa quindi il contenuto della regione dati indicando a quali file o directory i cluster appartengono. Sono presenti due copie di questa regione per coprire i casi in cui una sia corrotta.
-
La root directory è una directory table che contiene tutti i file entry per la directory root del sistema, in FAT12 e FAT16 ha una dimensione fissa e limitata di 256 entries. In FAT32 è inclusa nella regione dati insieme a file e directory normali e non ha limitazioni sulla dimensione.
-
Regione Dati: È la regione del volume in cui sono effettivamente contenuti i dati dei file e directory, le directory seguono la struttura FAT e i file sono semplicemente dei dati contenuti nei cluster.
Per quanto riguarda le directory, queste contengono un elenco di entries da 32 byte, ogni entry contiene le informazioni per un file: nome, attributi, timestamp, …, e ovviamente l’indirizzo del primo cluster nella tabella FAT, se é presente un’altra directory allora avrà le stesse informazioni per i suoi file ottenendo quindi una struttura gerarchica.
Data la tabella FAT, il puntatore i-esimo:
- Se è zero indica che l’i-esimo cluster del disco è libero
- Se non è zero e non è un valore speciale, indica il cluster dove troviamo il prossimo pezzo del file. Quindi se ad esempio alla riga 10 troviamo scritto 5 significa che il cluster 10 ha dei pezzi di file e al blocco 5 troviamo i prossimi.
- Se sono presenti tutti 1 allora siamo in un valore speciale, questo indica che è l’ultimo blocco del file.
Esempio
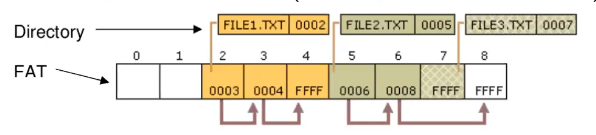
Quindi nella directory leggo che il file 1 inizia al blocco 2, quindi vado nella FAT alla riga 2, questo significa che appunto nella riga 2 trovo la successiva riga da esplorare e nel blocco 2 i pezzi di file successivi. Continuando quindi nella 2 ci spostiamo alla riga 3 e quindi al blocco 3 e poi alla riga 4 e blocco 4, qui troviamo il valore speciale 1111 e quindi capiamo che ci troviamo nell’ultimo blocco.
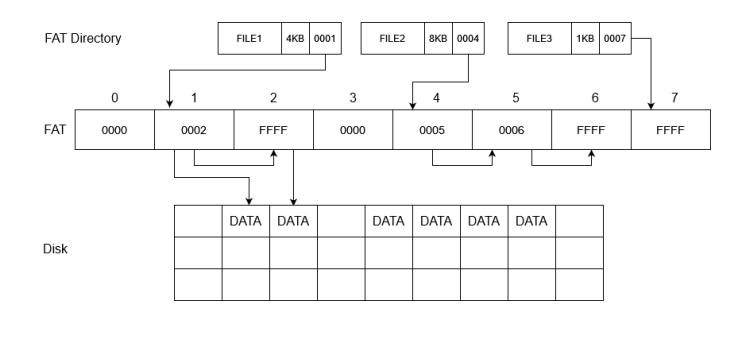
Anche qui il file1 inizia alla riga 1, quindi accediamo al cluster 1 per i dati e nella riga 1 troviamo scritto 2, quindi accediamo al cluster 2 per i dati e nella riga 2 troviamo scritto FFFF quindi era l’ultimo blocco.
Limitazioni FAT
- Supporta file di massimo 4GB, infatti nelle directory le entries hanno a disposizione solamente 32bit nel campo della dimensione del file.
- Non implementa il Journaling
- Non consente meccanismi di controllo degli accessi ai file o directory
- Le partizioni possono essere grandi al massimo 2TB ( settori da 512B)
NTFS
Questo è il file system utilizzato anche nelle recenti versioni di Windows:
- Per i nomi di file utilizza UNICODE e ha un limite massimo di 255 caratteri
- I file sono definiti come un insieme di attributi e questi attributi sono rappresentati come un byte stream
- Supporta Hard e Soft Link
- Implementa il Journaling
Vediamo la composizione del volume:

-
Boot Sector: Valgono le stesse regole del FAT ma alcuni campi si trovano in posizioni diverse
-
Master File Table (MFT): È la principale struttura dati del file system ed è unica per ciascun volume a differenza del FAT.
Questa è implementata come un file, è una sequenza di record da 1 a 4KB e ogni record descrive un file.
Ogni record contiene una lista di attributi sottoforma di coppie (attributo, valore):
- Attributo è un intero che indica appunto il tipo di attributo
- Valore è definito come una sequenza di byte
- Il contenuto di un file è anch’esso un attributo
Se il valore dell’attributo è piccolo allora può essere incluso direttamente nel record e viene chiamato attributo residente altrimenti è un puntatore ad un record remoto e quindi viene chiamato attributo non residente.
I primi 27 record sono riservata per metadati del filesystem: 0) Descrive l’MFT stesso, in particolari tutti i file nel volume
- Contiene una copia dei primi record dell’MFT in modo non residente (Chiamata MFT Mirror)
- Informazioni di journaling (solo metadata)
- Informazioni sul volume come ID, Label, versione FS ecc…
- Tabella degli attributi usati nell’MFT (definisce gli interi da usare per ogni attributo)
- Definisce la lista dei blocchi liberi usando una bitmap
Dal record 28 in poi ci sono i descrittori dei file normali.
L’ NTFS cerca sempre di assegnare ad un file delle sequenze contigue di blocchi, oppure se il file è piccolo lo salva direttamente nella MFT. Per i file grandi quindi il valore dell’attributo indica la sequenza ordinata dei blocchi sul disco dove risiede il file.
Per ogni file esiste un record nell’MFT, se il file ha delle zone vuote queste non occupano spazio fisico sul disco ma l’MFT se le “ricorda” impostando i bit a 0, in questo modo non sprechiamo spazio, inoltre il sistema ha una lista che contiene tutte queste aree vuote.
Questo è utile, ad esempio se creiamo un file da 1GB ma con 100MB effettivi utilizzati allora quei 900MB non verranno scritti a 0 sul disco fisico ma soltanto nell’MFT, per il sistema operativo il file sembrerà comunque lungo 1GB, riservando quindi spazio per quel file.
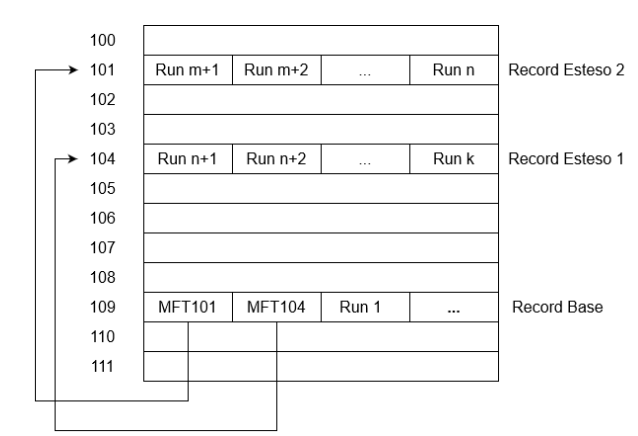
Esempio Record
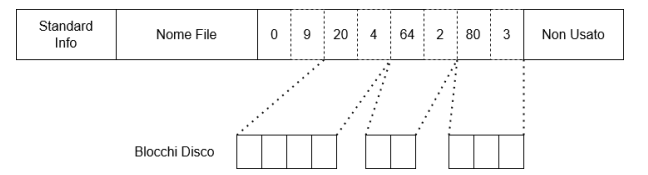
Quindi il primo indica da dove partire e il secondo numero quanti blocchi contigui. Questo consente di descrivere file di dimensione potenzialmente illimitata, dipende tutto dalla contiguità dei blocchi:
-
Se abbiamo blocchi da 1KB, 1 file da 20GB descritto in 20 sequenze (zone contigue) da 1 milione di blocchi sappiamo che ogni sequenza ha bisogno di una coppia di valori e nel nostro caso gli attributi sono da 64bit = 8byte quindi per ogni coppia byte.
Inoltre a fine sequenza ce ne sta un’altra vuota che ci segnala la fine del file quindi in tutto 21 coppie da 16 byte =
Quindi per descrivere un file da 20GB diviso in 20 sequenze contigue sono necessari 336 byte.
-
Prendiamo come altro esempio un file da 64KB diviso in 64 sequenze da 1 blocco.
Seguendo i ragionamenti di prima abbiamo 65 coppie da 16 byte e quindi 1040 byte, quindi per descrivere un file da 64KB frammentato in 64 blocchi singoli abbiamo bisogno di 1040byte
Quindi notiamo che quando i blocchi sono contigui il file può essere descritto con poche coppie se invece è frammentato ne servono di più aumentando anche lo spazio necessario per descrivere il file.
Per file più grandi o molto frammentati possono essere necessari più record e qui NTFS usa una tecnica simile agli INODE di Linux:
- Il record base è un puntatore a record secondari e eventuale spazio rimanente nel record base contiene le prime sequenze del file
Esempio
Unix File System
È diviso nelle seguenti regioni:

-
La regione Boot Block è simile al blocco di boot per FAT, contiene quindi informazioni e dati necessari per il bootstrap
-
Regione superblock: Contiene informazioni sui metadati del filesystem come le dimensioni delle partizioni, dimensione dei blocchi e puntatore alla lista dei blocchi liberi.
Di questa ci sono copie ridondanti in caso di corruzione, queste sono salvate in gruppi di blocchi sparsi nel file system, la prima copia però è sempre in una parte prefissata per facilitare la recovery.
-
Regione Lista degli I-node (i-list): è una tabella numerata di descrittori dei file ovvero gli inode. È presente un inode per ogni file salvato nel sistema e ciascun inode nella lista punta ai blocchi dei file nella sezione dati del volume.
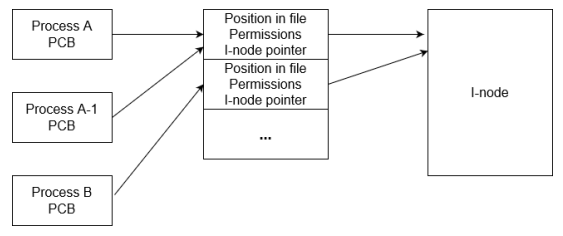
Il kernel Unix usa due strutture di controllo separate per gestire file aperti e descrittori i-node:
- Per file attualmente in uso c’è il puntatore al suo descrittore salvato nel Process Control Block
- Una tabella globale di descrittori di file aperti mantenuta in una apposita struttura dati
Linux?
Linux supporta nativamente ext2/ext3/ext4, le differenze sono:
- ext2: direttamente dai file system Unix originari
- ext3: ext2 ma con journaling
- ext4: ext3 in grado di memorizzare singoli file più grandi di 2TB e file system più grandi di 16TB.
Ha pieno supporto per gli inode che sono memorizzati nella parte iniziale del file system e permette inoltre di leggere e scrivere altri file system come quelli di Windows, ma:
- Con FAT non è possibile memorizzare gli inode sul dispositivo
- vengono creati on-the-fly su una cache quando vengono aperti i file