Controllo della Concorrenza
Sappiamo che in un computer i processi vengono eseguiti in modo interleaved ovvero vengono alternati fra di loro ma la CPU può eseguirne soltanto uno alla volta.
La CPU può quindi eseguire alcune istruzioni di un programma, sospenderlo ed eseguire istruzioni di un altro e poi tornare al primo programma. Questo permette un utilizzo efficiente della CPU.
In un DBMS la principale risorsa alla quale accediamo in modo concorrente è appunto la base di dati, questo tipo di accesso può causare problemi quando effettuiamo delle scritture e va quindi controllato.
Transazione
Definizione
È l’esecuzione di una parte di un programma e rappresenta un’unità logica di accesso o modifica alla base di dati. Possiamo vederla quindi come una vera e propria operazione sulla base di dati.
Le transazioni devono rispettare delle proprietà che si indicano con la sigla ACID, dall’inglese Atomicity, Consistency, Isolation, Durability (Atomicità, Consistenza, Isolamento, Durabilità):
- Atomicità: Quando eseguiamo una transazione questa deve essere eseguita per intero, se viene interrotta per qualche motivo allora dobbiamo annullare ogni operazione fatta da questa. Se altre transazioni hanno usato le modifiche fatte da una transazione annullata allora dobbiamo annullare anche quest’ultima.
- Consistenza: Quando eseguiamo una transazione, le modifiche che apporta alla base di dati non devono violare i vincoli di integrità.
- Isolamento: Ogni transazione deve essere eseguita in modo isolato e indipendente dalle altre, l’eventuale fallimento di una non deve interferire con le altre. L’esito di un insieme di transazioni quindi non deve dipendere dall’ordine in cui le eseguo, ovviamente posso ottenere risultati diversi ma l’importante è che non falliscano presa una loro permutazione qualsiasi.
- Durabilità: Prende anche il nome di persistenza, si riferisce al fatto che una transazione dopo aver scritto i suoi risultati sulla base, questi non devono essere persi, per assicurarsi questo vengono scritti anche dei log su tutte le operazioni eseguite sul BD.
Schedule
Uno schedule è un ordinamento di un insieme T di transazioni, questo conserva l’ordine che le operazioni hanno all’intero delle singole transazioni.
Se l’operazione O1 precede l’operazione O2 in una transazione allora sarà così in ogni schedule dove compare questa transazione, ovviamente fra loro due potrebbero comparire operazioni di altre transazioni.
Schedule Seriale
È uno schedule che si ottiene permutando le transazioni in T, questo corrisponde ad una esecuzione sequenziale delle transazioni queste non vengono quindi interrotte e vengono eseguite una per volta per intero.
Vedremo più avanti che uno schedule accettabile è equivalente ad uno schedule seriale.
Problemi dell’Esecuzione Concorrente
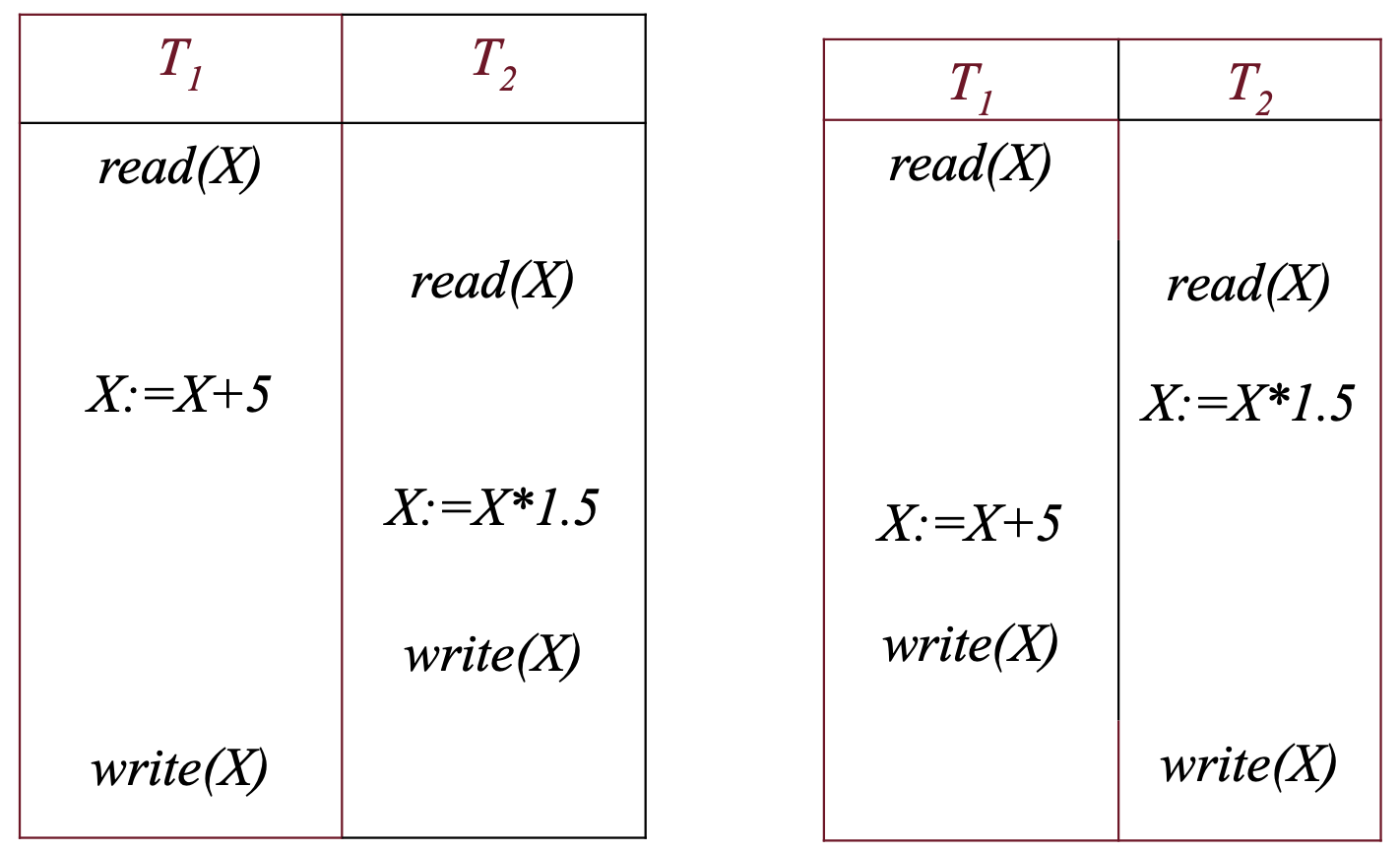
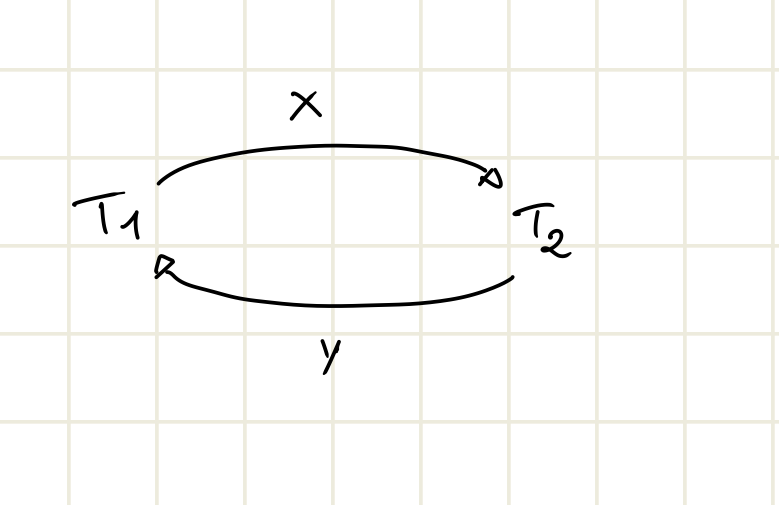
Consideriamo ad esempio le due transazioni:


E vediamo un possibile schedule di queste due:

Questo è un caso di lost o ghost update ovvero un aggiornamento perso. Infatti se il valore di X iniziale è X0, al termine dell’esecuzione invece di essere X0-N+M sarà X0+M questo perché T2 legge il valore di X iniziale invece di quello modificato da T1.
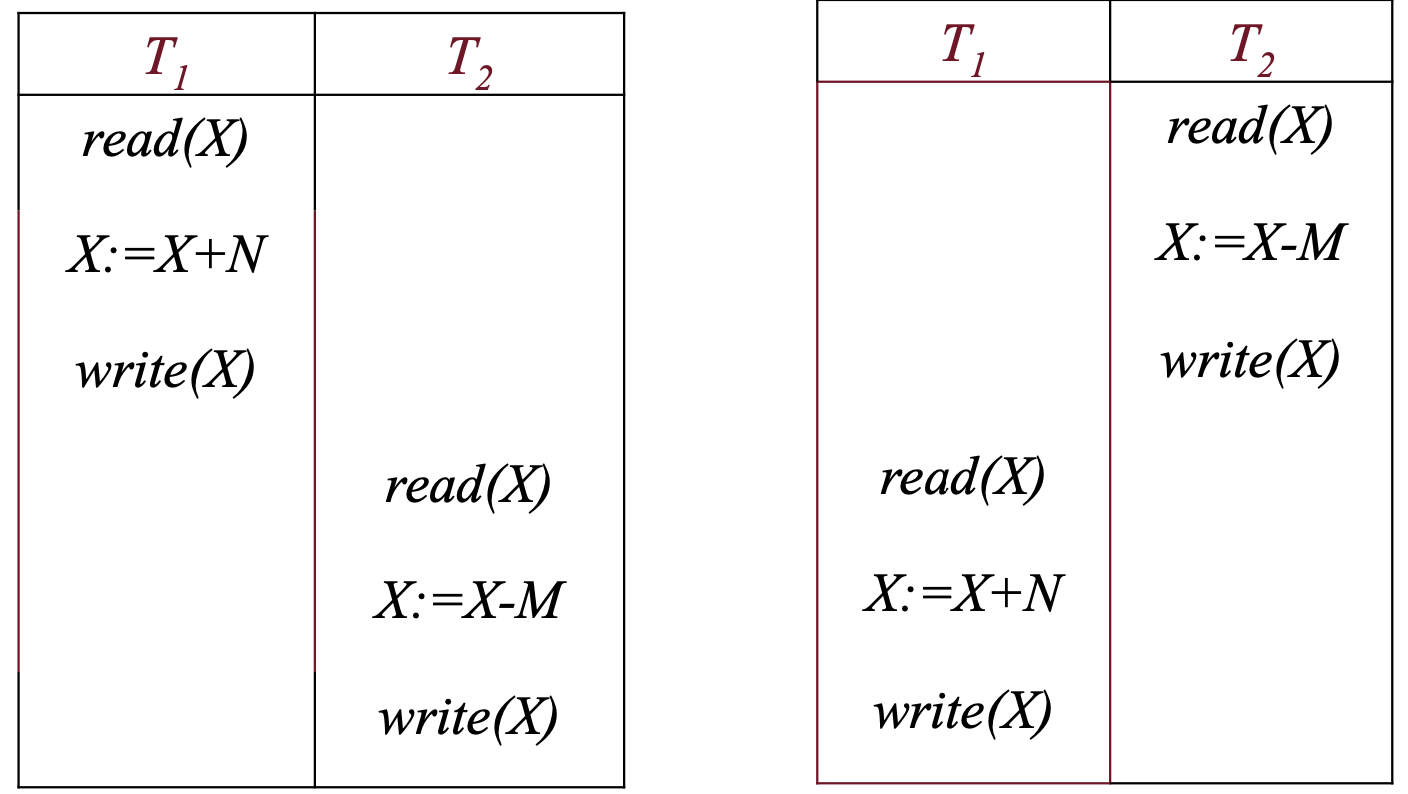
Altro esempio di schedule:

Questo è un caso di dato sporco infatti il valore letto da T2 è un valore, anche se aggiornato correttamente, di un’operazione che non si è conclusa e quindi non più valido.
Altro esempio di schedule:

In questo caso l’errore prende il nome di aggregato non corretto e si verifica quando una parte dei dati che abbiamo utilizzato non è corretta. Infatti nell’esempio abbiamo il valore di X aggiornato correttamente ma non quello di Y.
Quando definiamo uno schedule errato?
Definiamo uno schedule errato quando i valori prodotti non sono quelli che si avrebbero se le due transazioni fossero eseguite in modo sequenziale. Per questo i precedenti sono errati.
Serializzabilità
Tutti gli scheduli seriali sono corretti, gli schedule non seriali invece sono corretti se serializzabili ovvero equivalenti ad uno schedule seriale. Che significa equivalente nel contesto degli schedule?
Una prima ipotesi potrebbe essere: Due schedule si dicono equivalente se presi gli stessi input producono gli stessi risultati. Ma non basta.
Infatti vediamo ad esempio questi due schedule:
Questi producono lo stesso risultato solo se il valore iniziale di X è 10, negli altri casi no.
Equivalenza di schedule
Due schedule si dicono equivalenti se producono valori uguali, ma due valori si dicono uguali solo se prodotti dalla stessa sequenza di operazioni.
Esempio
Questi non sono equivalenti perché X non è prodotto dalla stessa sequenza di operazioni ma sono comunque corretti dato che sono seriali.
Testare la serializzabilità
Testare la serializzabilità di uno schedule è molto difficile:
- È difficile stabilire quando uno schedule comincia o finisce
- È impossibile determinare in anticipo in che ordine verranno eseguite le operazioni dato che questo dipende dal carico del sistema, l’ordine in cui queste vengono inviate e la loro priorità
- Se eseguiamo uno schedule e poi testando la serializzabilità notiamo che non è serializzabile allora dovremmo annullare i suoi effetti
Quindi il metodo che si usa non è testare la serializzabilità ma usare metodi che la garantiscono per gli schedule, eliminando così la necessità di doverli testare ogni volta. Facciamo questo imponendo dei protocolli alle transazioni oppure usando i timestamp delle transazioni ovvero degli identificatori generati dal sistema usati per ordinarle e garantire la serializzabilità.
Item
Entrambi i metodi visti sopra fanno uso del concetto di item ovvero un’unità della base di dati della quale controlliamo l’accesso.
Le dimensioni degli item devono essere definite in base all’uso che viene fatto della base di dati e in modo da garantire che una transazione acceda in media a pochi item. Le dimensioni di un item usate dal sistema sono dette la sua granularità.
La granularità va dal singolo campo ad un’intera tabella o oltre, una grande granularità ci permette una gestione efficiente della concorrenza mentre una piccola ci permette di eseguire più transazioni in modo concorrente ma allo stesso tempo sovraccarica il sistema.
Il meccanismo di Lock
Questo si realizza tramite una variabile associata ad ogni item che ne descrive lo stato rispetto alle operazioni che possono essere eseguite su di lui, la variabile assume due valori nel caso di lock binario:
- Locked: L’item è in uso da una transazione e non può essere utilizzato da altre
- Unlocked: È possibile utilizzare l’item per svolgere operazioni su di esso.
Quando una transazione vuole utilizzare un item quindi, controlla se questo è unlock e se si, tramite un’operazione di locking lo porta in stato di locked in modo da poterlo utilizzare per le sue operazioni, una volta finito lo rilascia tramite un’operazione di unlocking permettendo quindi ad altre transazioni di utilizzarlo.
Il lock agisce quindi da primitiva di sincronizzazione.
Schedule Legale
Uno schedule è detto legale se una transazione, ogni volta che deve leggere o scrivere un item effettua un locking e poi rilascia ogni lock fatto. (Notiamo quindi che il lock risolve il problema di lost update)
Il lock binario, visto prima, assume i due valori visti prima e fa uso di due operazioni:
- lock(X) per richiedere l’accesso ad un item X
- unlock(X) per rilasciare l’item X
L’insieme degli item letti e scritti da una transazione coincidono.
Osservazione
Come detto prima, questo è il metodo più semplice di implementare il lock ma ne esistono anche altri come il lock a tre valori che tramite un altro stato permette la lettura sullo stesso item in modo simultaneo da più transazioni aumentando quindi il livello di concorrenza.

Equivalenza
Vedremo che il concetto di equivalenza degli schedule cambia in base al protocollo di locking adottato. Noi vedremo in base al lock binario.
Per prima cosa utilizziamo un modello delle transazioni che considera soltanto le operazioni rilevanti ovvero gli accessi che nel nostro caso sono soltanto le operazioni di lock e unlock.
Quindi per noi una transazione diventa una sequenza di operazioni di lock e unlock e ogni lock(X) implica la lettura di X mentre un unlock(X) implica la scrittura di X.
Per verificare l’equivalenza andiamo ad associare ad ogni unlock una funzione, diversa dagli altri unlock, che prende come input tutti gli item letti dalla transazione prima di quell’unlock. Quindi ad esempio:
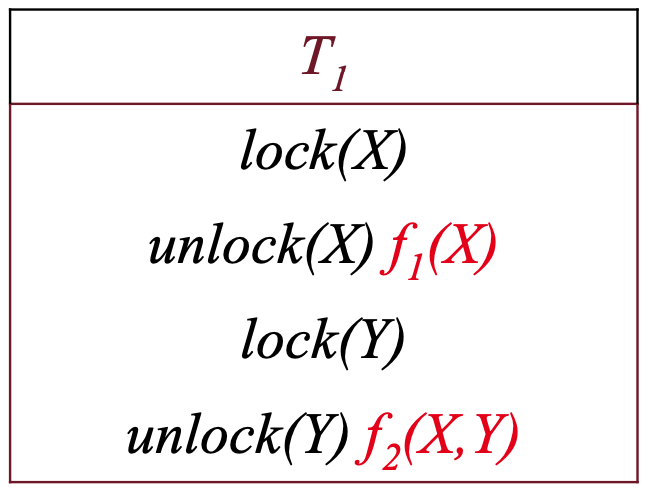
E diciamo che due schedule sono equivalenti quando le formule finali per ciascun item sono uguali. Inoltre uno schedule è serializzabile se è equivalente ad uno schedule seriale.
Esempio
Consideriamo le due transazioni:

E lo schedule:
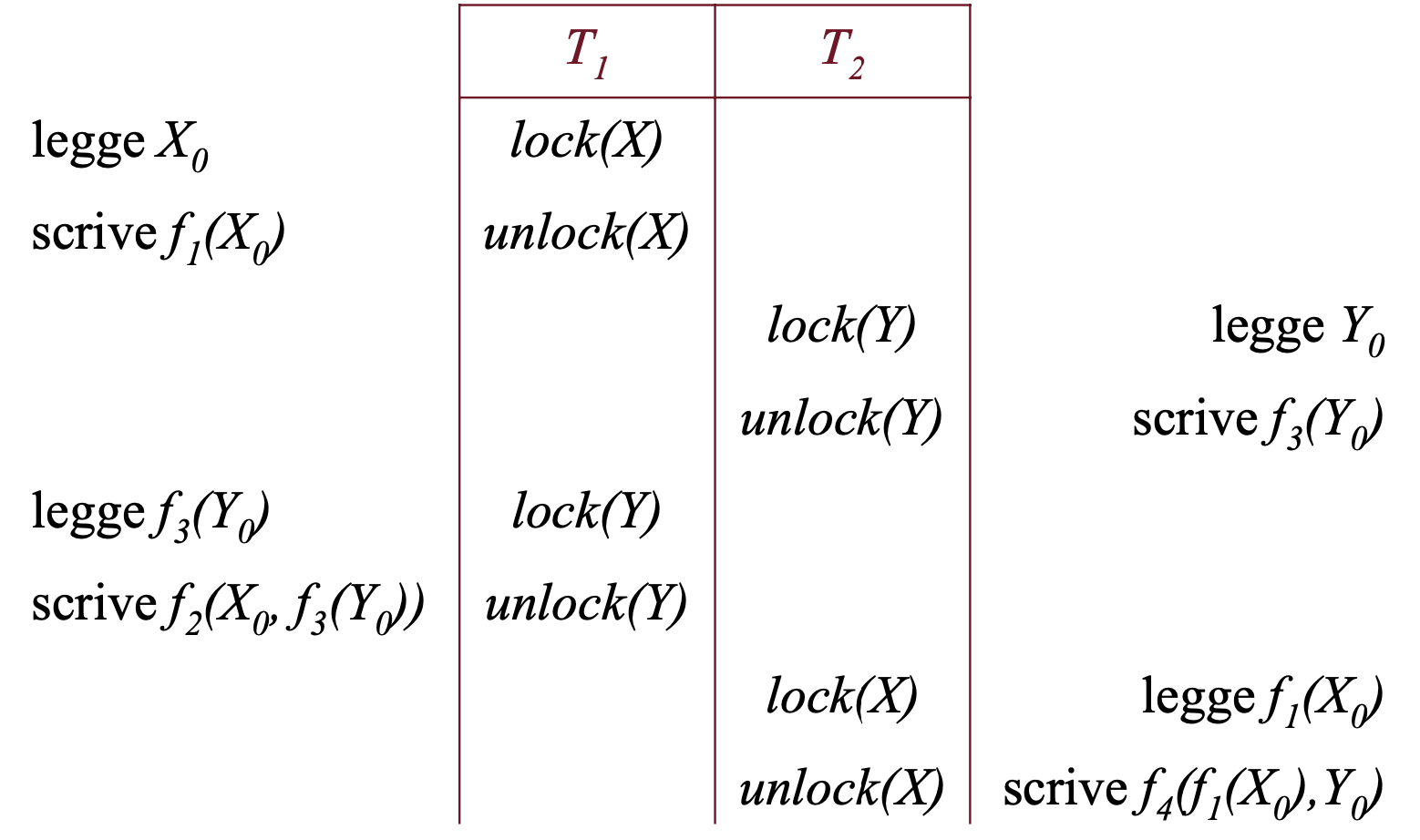
Otteniamo come valore finale di X: , Y per ora non ci interessa.
In questo caso abbiamo due possibili schedule seriali quindi dobbiamo confrontare il valore finale di X con entrambi:
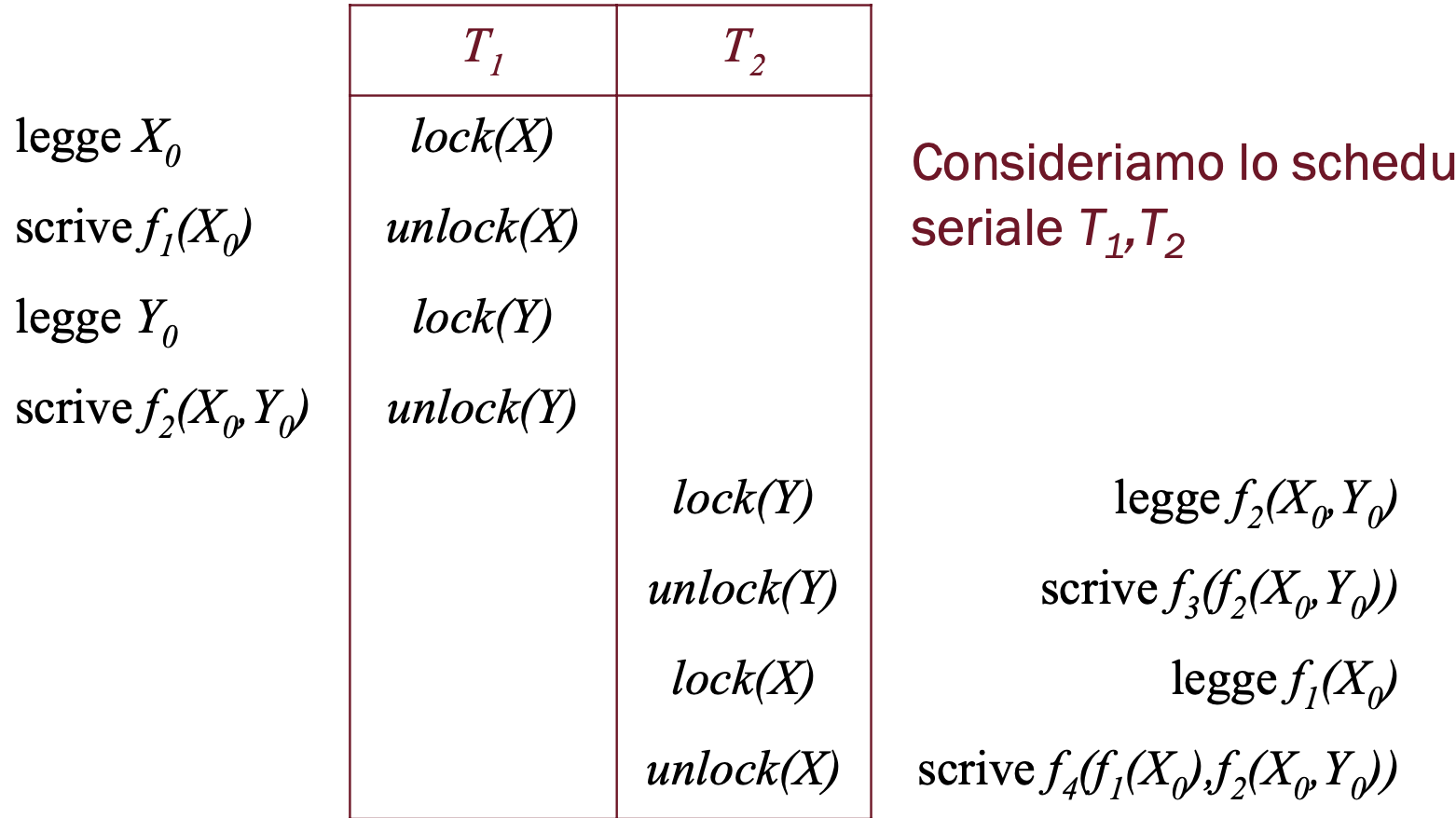
In questo caso abbiamo come valore finale di X: che è diverso dallo schedule iniziale, proviamo a controllare l’altro schedule seriale:
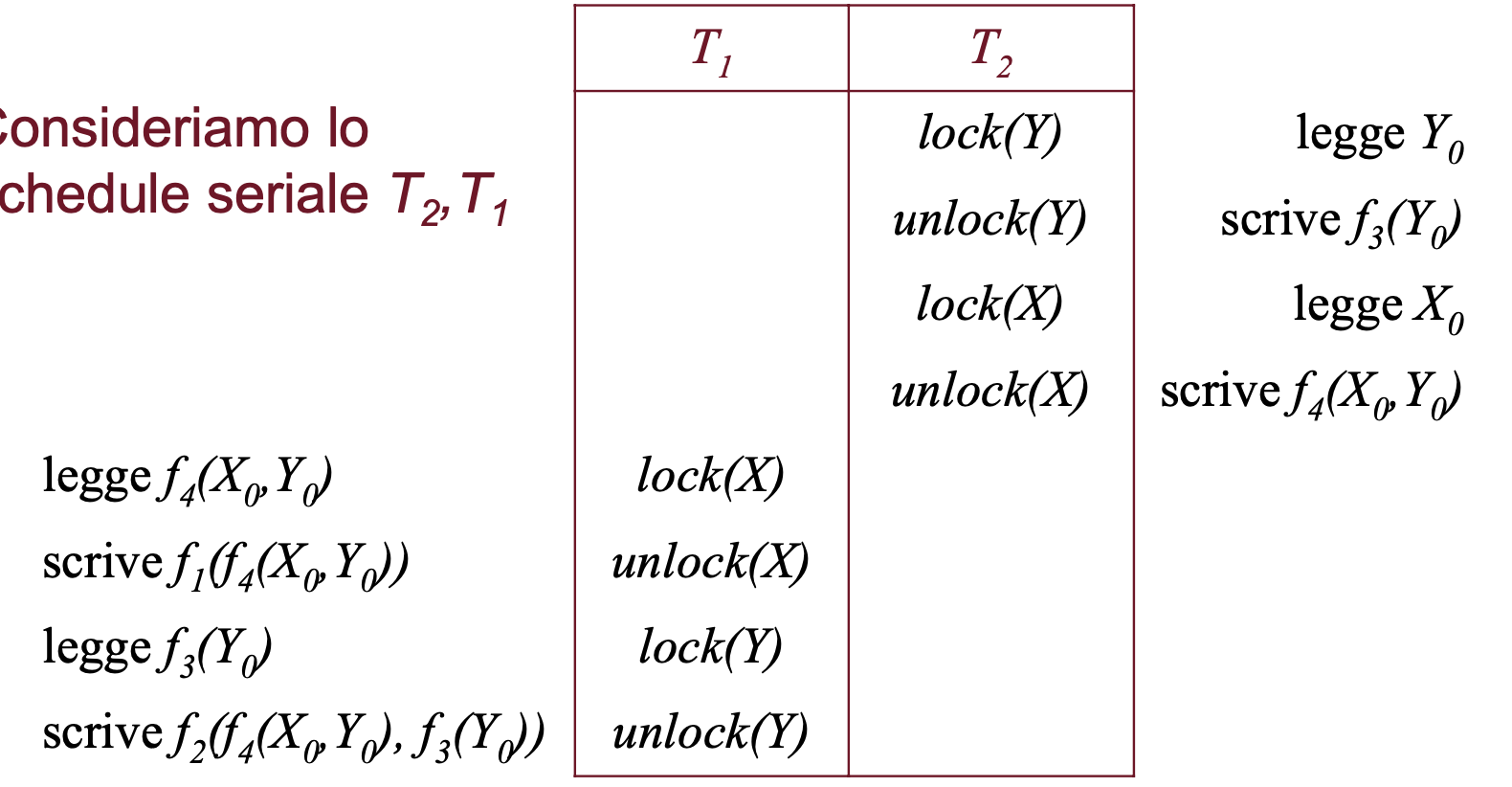
Questo scrive come valore finale di X: .
Quindi lo schedule preso inizialmente non è serializzabile dato che non è equivalente ad uno schedule seriale. Inoltre come detto nella definizione vanno controllati i valori di tutti gli item ma se già ne abbiamo uno sbagliato è inutile andare a controllare gli altri.
Quindi:
- Per verificare che uno schedule è serializzabile controlliamo tutti gli item
- Per verificare che non lo è ci possiamo fermare anche al primo item errato
Schedule Serializzabile
Uno schedule è serializzabile se esiste uno schedule seriale tale che per ogni item, l’ordine in cui le varie transazioni fanno un lock su quell’item coincide con quello dello schedule seriale.
Algoritmo 1 - Testare Serializzabilità
Dato uno schedule S creiamo un grafo diretto G, grafo di serializzazione dove:
- I nodi sono le transazioni
- Gli archi vanno da una transazione ad una transazione e hanno etichetta X se in S la transazione si esegue un unlock(X) e esegue il successivo lock(X)
Attenzione! Non un lock(X) successivo qualsiasi, ma il successivo ovvero il primo lock(X) immediatamente dopo a quel unlock.
Esempio Grafo
Esempi:
Prendiamo lo schedule:
Che avrà come grafo:
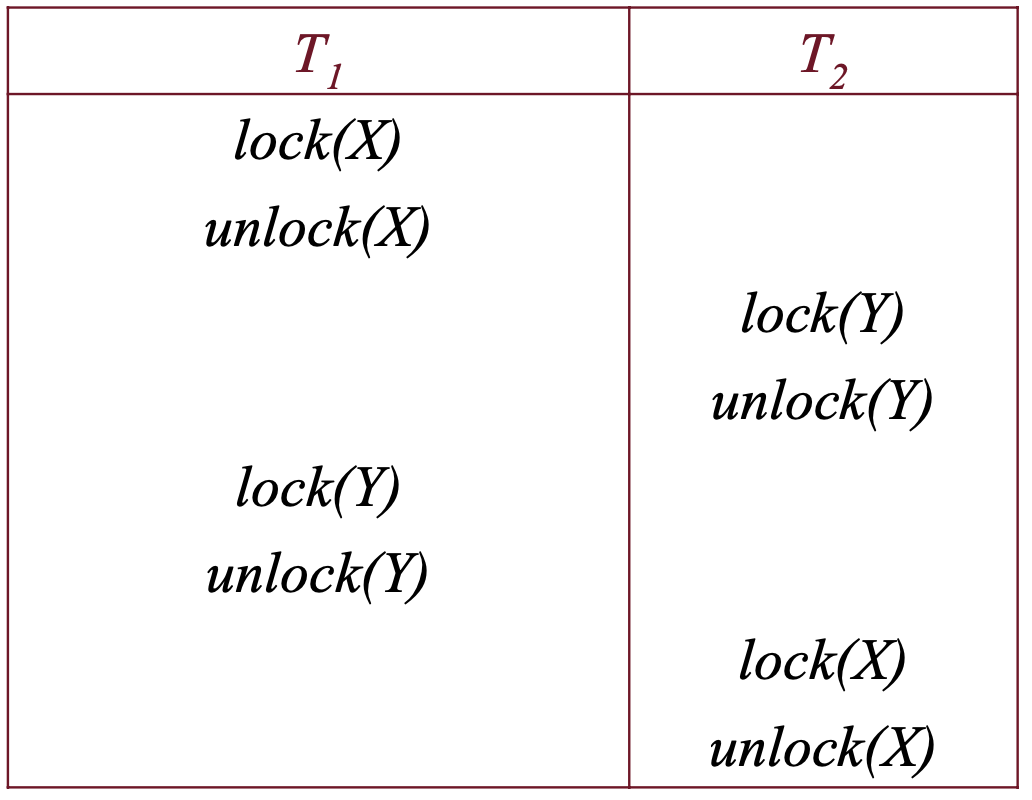
Il passo successivo è quello di osservare il grafo e notare se sono presenti dei cicli, se G ha un ciclo allora lo schedule non è serializzabile altrimenti applicando a G l’ordinamento topologico si ottiene uno schedule seriale equivalente ad .
Ordinamento Topologico
Preso il grafo eliminiamo in modo ricorsivo i nodi che non hanno archi entranti, ogni possibile ordinamento topologico è uno schedule seriale equivalente a S.
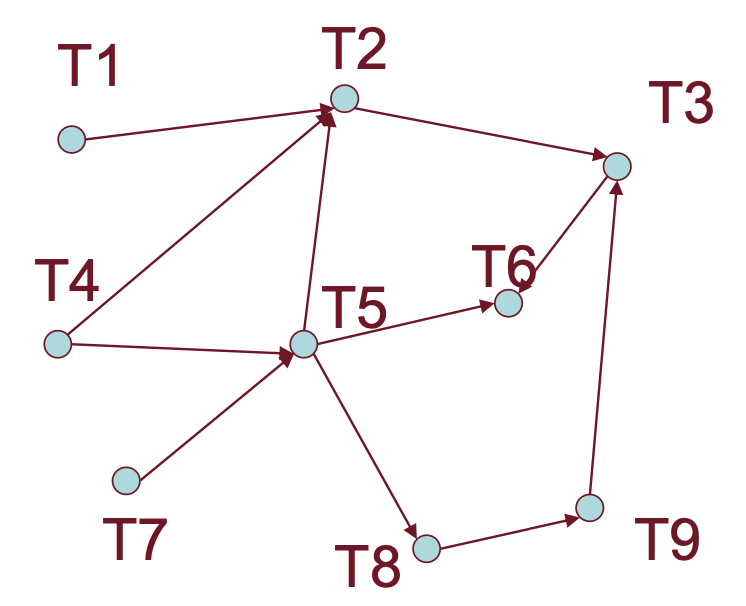
Un possibile schedule seriale equivalente è quindi: T4 T7 T5 T1 T8 T9 T2 T3 T6.
Teorema (Correttezza algoritmo grafo serializzazione)
Uno schedule S è serializzabile se e solo se il suo grafo di serializzazione è aciclico.
Inoltre da notare che se applichiamo l’ordinamento topologico su dei grafi con dei cicli, questo prima o poi si bloccherà.
Protocollo di Locking a due Fasi
Una transazione si dice a due fasi se:
- Prima effettua tutte le operazioni di lock (fase di locking)
- Poi tutte le operazioni di unlock (fase di unlocking)
Quindi una volta effettuato un unlock non è più possibile effettuare altri lock, per nessuna variabile.
Inoltre da non confondere il protocollo a due fasi con il lock a due valori, il fatto di essere a due fasi è solo una caratteristica aggiuntiva, ci possono essere infatti anche transazioni a due fasi e 3 valori di lock.
Teorema sul lock a due fasi
Sia T un insieme di transazioni, se ogni transazione in T è a due fasi allora ogni schedule di T è serializzabile.
Dimostrazione Teorema per Assurdo
Dato che facciamo una dimostrazione per assurdo, abbiamo ogni transazione in S a due fasi ma nel nostro grafo vogliamo anche un ciclo:
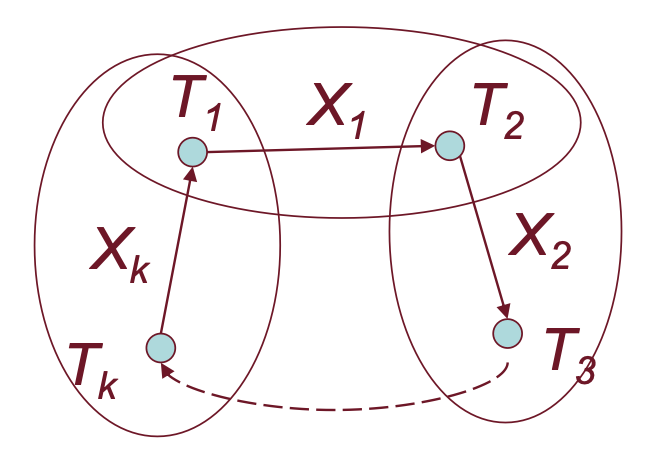
E nel nostro schedule S avremo:
- T1 unlock(X1)
- …
- T2 lock(X1)
- …
- T2 unlock(X2)
- …
- T3 lock(X3)
- …
- …
- Tk unlock(Xk)
- …
- T1 lock(Xk)
Notiamo che per creare il ciclo abbiamo bisogno di T1 che esegue un lock su Xk ma questo non è possibile dato che è a due fasi e quindi dopo avere effettuato all’inizio un unlock su X1 non può più effettuare altri lock. Abbiamo ottenuto una contraddizione e quindi dimostrato il teorema.
Ovviamente questa contraddizione può crearsi ovunque ma noi per comodità lo abbiamo mostrato all’inizio.
Nota
Da notare che se abbiamo uno schedule con tutte transazioni non a due fasi non è detto che non sia serializzabile, ma se ne abbiamo anche solo una a due fasi esisterà sempre uno schedule non serializzabile.
Deadlock e Livelock
Un deadlock si verifica quando ogni transazione in un insieme T è in attesa di ottenere un lock su un item sul quale un’altra transazione nello stesso insieme mantiene un lock quindi questa rimane bloccata non rilasciando i lock e bloccando anche eventuali transazioni non dell’insieme.
Essenzialmente accade una situazione del tipo:
- A ha un lock e sta aspettando un unlock di B
- Anche B sta aspettando un unlock di C
- Ma C sta aspettando un unlock di A Quindi è tutto bloccato.
Quando si verificano queste situazioni, vanno risolte.
Possiamo verificare il sussistere di una situazione di stallo si mantiene il grafo di attesa, dove:
- I nodi sono le transazioni
- Gli archi vanno da una transazione T1 ad una T2 se la T1 è in attesa di ottenere un lock su un item sul quale T2 mantiene un lock
Se nel grafo c’è un ciclo si verificherà una situazione di stallo che coinvolge le transazioni nel ciclo.
Per risolvere il sussistere di un deadlock dobbiamo necessariamente effettuare il rollback di una transazione coinvolta e farla ripartire. Per rollback intendiamo:
- Abortire la transazione
- Annullare i suoi effetti sulla base di dati, ripristinando quindi i valori dei dati precedenti all’inizio della transazione
- Tutti i lock mantenuti dalla transazione vengono rilasciati
Ovviamente oltre a risolvere le situazioni di stallo si possono anche prevenire.
Ad esempio: Si ordinano gli item e si impone alle transazioni di richiedere i lock necessari seguendo tale ordine. In questo modo non possiamo avere cicli nel grafo, infatti:
Supponiamo per assurdo che le transazioni richiedono gli item seguendo un ordine fissato e che nel grafo ci sia un ciclo.
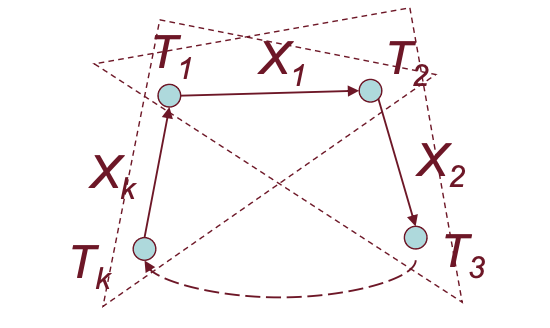
Osservando il grafo notiamo che e da questo segue che ma poi otteniamo che è una contraddizione dato che doveva essere la prima nell’ordine prefissato.
Un livelock invece si verifica quando una transazione aspetta indefinitamente che gli venga concesso un lock su un certo item, questo può non arrivare perché arrivano sempre altre transazioni prima di lei.
Per risolvere il livelock possiamo usare una strategia first came-first served oppure eseguendo le transazioni in base alla loro priorità e aumentando la priorità di una transazione in base al tempo in cui rimane in attesa.
Abort di una Transazione
Ci sono diversi casi in cui eseguiamo l’abort di una transazione:
- La transazione esegue un’operazione non corretta, ad esempio una divisione per 0
- Lo scheduler rileva un deadlock
- Lo scheduler fa abortire la transazione per garantire la serializzabilità (timestamp)
- Si verifica un malfunzionamento hardware o software
Punto di Commit
Il punto di commit di una transazione è il punto in cui la transazione:
- Ha ottenuto tutti i lock necessari
- Ha effettuato tutti i calcoli necessari
Una volta raggiunto questo punto la transazione non può più essere abortita per i motivi 1 e 3 visti sopra.
Dati Sporchi
Sono dei dati scritti da una transazione sulla base di dati prima che abbia raggiunto il suo punto di commit.
Rollback a Cascata
Quando una transazione T viene abortita abbiamo visto che devono essere annullati anche i suoi effetti prodotti sulla base di dati ma non solo di T, anche di tutte le transazioni che hanno letto i dati sporchi.
Problemi Concorrenza e Soluzioni
Abbiamo quindi visto che:
- L’aggiornamento perso viene risolto dal lock binario
- I dati sporchi vengono risolti dal protocollo a 2 fasi stretto, che vedremo tra poco
- L’aggregato non corretto viene risolto dal protocollo a 2 fasi.
Per risolvere il problema dei dati sporchi le transazioni devono obbedire a regole più restrittive di quelle del locking a due fasi.
Protocollo a due Fasi Stretto
Una transazione si dice che soddisfa il protocollo di locking a due fasti stretto se:
- Non scrive sulla base di dati prima del punto di commit.
- Non rilascia un lock finché non ha finito di scrivere tutti gli item sulla base.
Classificazione dei Protocolli
Possiamo classificarli in due categorie:
- Conservativi: Cercano di evitare le situazioni di stallo
- Aggressivi: Cercano di eseguire le transazioni nel modo più veloce possibile anche causando situazioni di stallo per poi risolverle.
Protocolli Conservativi
Una transazione T richiede tutti i lock che servono all’inizio e li ottiene se e solo se tutti i lock sono disponibili, se non lo sono allora la transazione viene messa in una coda di attesa.
In questo modo evitiamo il deadlock ma non il livelock, infatti una transazione rischia di non partire mai.
Applichiamo quindi questo tipo di protocolli quando abbiamo un alto rischio di deadlock.
Se vogliamo però evitare anche il livelock:
- Come prima la transazione deve richiedere tutti i lock e li riceve se tutti disponibili ma anche se nessuna transazione che la precede nella coda è in attesa di un lock richiesto da lei.
Quindi in conclusione:
- Vantaggi
- Si evita il verificarsi di deadlock e livelock
- Svantaggi
- L’esecuzione di una transazione può essere ritardata
- Una transazione è costretta a chiedere un lock su ogni item che potrebbe servirgli anche se poi non lo usa effettivamente
Protocolli Aggressivi
In questo tipo di protocolli, una transazione deve richiedere un lock su un item subito prima di leggerlo o scriverlo, in questo modo sono possibili i deadlock.
Quindi, quando scegliere un protocollo aggressivo o uno conservativo? Possiamo distinguere i casi in base alla probabilità che due transazioni richiedano un lock su uno stesso item, se questa è:
- Alta: Conviene utilizzare i conservativi in quanto evitiamo il sovraccarico di sistema per gestire il deadlock (ovvero eseguire parzialmente delle transazioni che verranno abortite e riavviate)
- Bassa: Conviene utilizzare gli aggressivi in quanto evitiamo il sovraccarico della gestione dei lock (decidere se garantire un lock, mantenere le code ecc…)
Conclusione
Solo se tutte le transazioni sono a due fasi abbiamo la certezza che ogni schedule è serializzabile.
Tutti i protocolli di lock a due fasi risolvono l’aggregato non corretto.
Time-Stamp
Il timestamp è un valore sequenziale e crescente che identifica una transazione. È assegnato alla transazione quando questa viene creata e può assumere diversi valori come ad esempio un contatore o anche l’ora di creazione.
Questo significa che più il valore del timestamp è alto e meno è il tempo che la transazione si trova nel sistema. Quindi se una transazione T1 ha timestamp minore di T2, se fossero eseguite in modo sequenziale T1 verrebbe eseguita prima di T2.
Serializzabilità
Uno schedule è serializzabile se è equivalente allo schedule seriale dove le transazioni compaiono ordinate in base ai loro timestamp.
Quindi possiamo anche dire che è serializzabile se per ciascun item acceduto da più transazioni, l’ordine in cui queste accedono è lo stesso ordine imposto dai timestamp
Esempio
Prediamo le due transazioni

Queste hanno come timestamp T1 = 110 e T2 = 100 quindi significa che T2 è arrivata prima di T1. Uno schedule serializzabile deve quindi essere equivalente allo schedule seriale T2 T1.
Prendiamo lo schedule:

Questo non è serializzabile dato che T1 ha letto il valore di X prima della modifica di T2.
Altro esempio
Abbiamo le transazioni
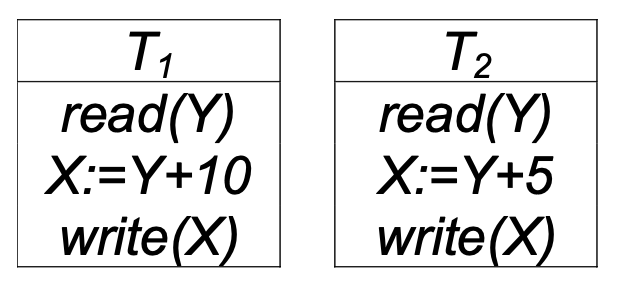
Con timestamp T1 = 110 e T2 = 100 quindi come prima lo schedule è serializzabile se equivalente allo schedule seriale T2 T1.
Prendiamo quindi lo schedule:
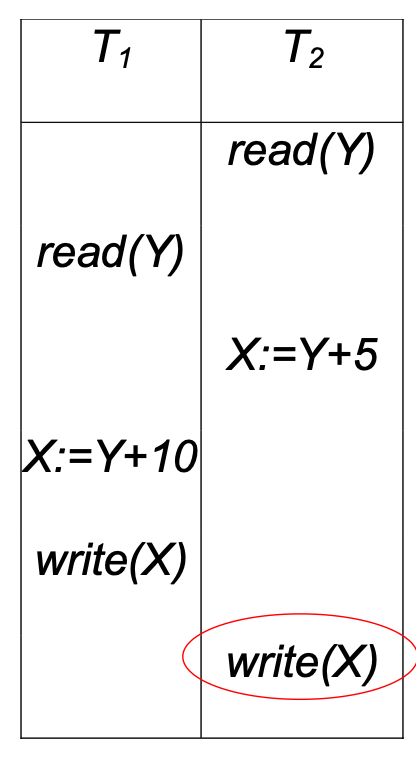
Osserviamo però anche lo schedule seriale T2 T1:

Notiamo che il dato finale di X viene scritto da T1 e non si basa sul valore attuale di X ma su quello di Y che è lo stesso per entrambe le transazioni.
Quindi lo schedule preso come esempio è ancora serializzabile se non effettuiamo l’ultima write di T2, in questo modo rispettiamo lo schedule seriale.
Diversi Timestamp
Associamo ad ogni item due timestamp:
- read timestamp di un item X che indichiamo con read_TS(X) ed è il più grande fra tutti i timestamp di transazioni che hanno letto X con successo.
- write timestamp di un item X che indichiamo con write_TS(X) ed è il più grande fra tutti i timestamp di transazioni che hanno scritto X con successo.
Come li utilizziamo?
- Ogni volta che una transazione T cerca di eseguire un read(X) o un write(X) confrontiamo il timestamp della transazione con il read e write timestamp dell’item per assicurarci che non ci siano violazioni nell’ordine stabilito dai timestamp.
Nello specifico:
-
T vuole eseguire una write(X):
- Se read_TS(X) > TS(T) allora T viene rolled back, significa che qualcuno di più recente ha già letto il dato e quindi la scrittura andrebbe a causargli danni
- Se write_TS(X) > TS(T) allora l’operazione di scrittura non viene effettuata, infatti è inutile andare a scrivere dato che il dato è stato modificato più recentemente. Più avanti vedremo in modo dettagliato.
- Se nessuna delle condizioni è soddisfatta allora eseguiamo il write e impostiamo il write timestamp dell’item uguale a quello della transazione.
-
T vuole eseguire una read(X):
- Se write_TS(X) > TS(T) allora T viene rolled back, questo significa che qualcuno arrivato dopo T ha già scritto il dato e quindi T “ha fatto tardi”
- Se write_TS(X) ⇐ TS(T) allora la read è eseguita e se read_TS(X) < TS(T) allora impostiamo il read timestamp dell’item uguale a quello della transazione. Infatti significa che stiamo seguendo il giusto ordine delle operazioni
Esempio 1
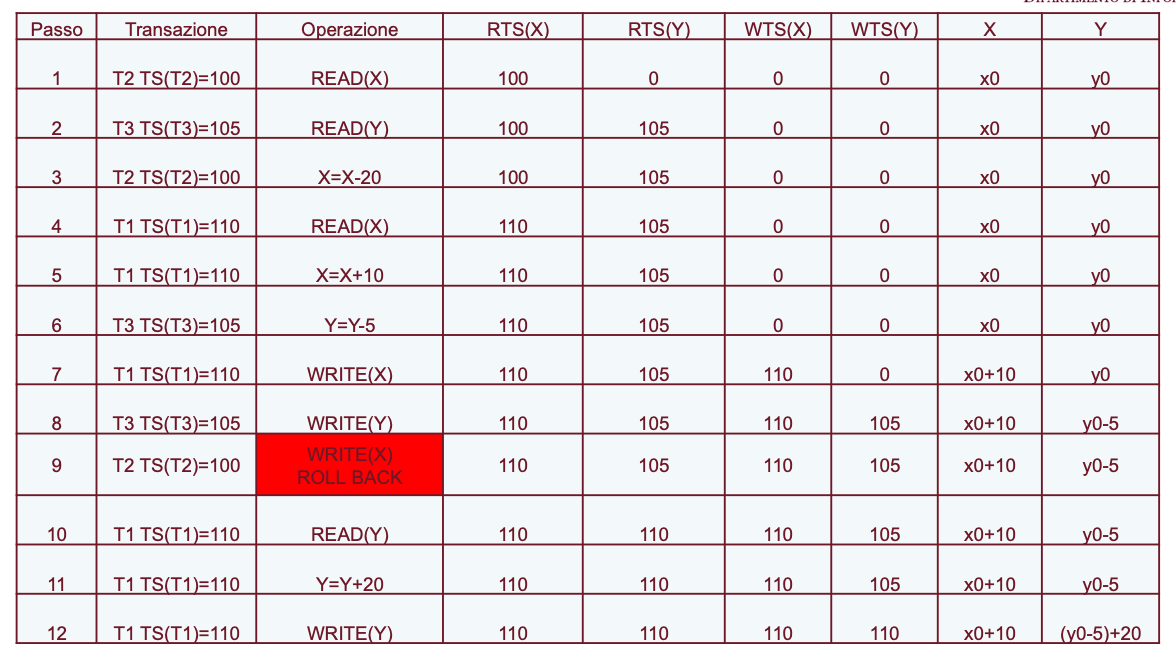
Al passo 9 dobbiamo abortire l’operazione perché T2 ha timestamp 100 e vuole eseguire un write(X) ma notiamo che il Read timestamp di X è più grande quindi qualcuno arrivato dopo ha già letto il dato e T2 andrebbe a causare incongruenze.
Esempio 2
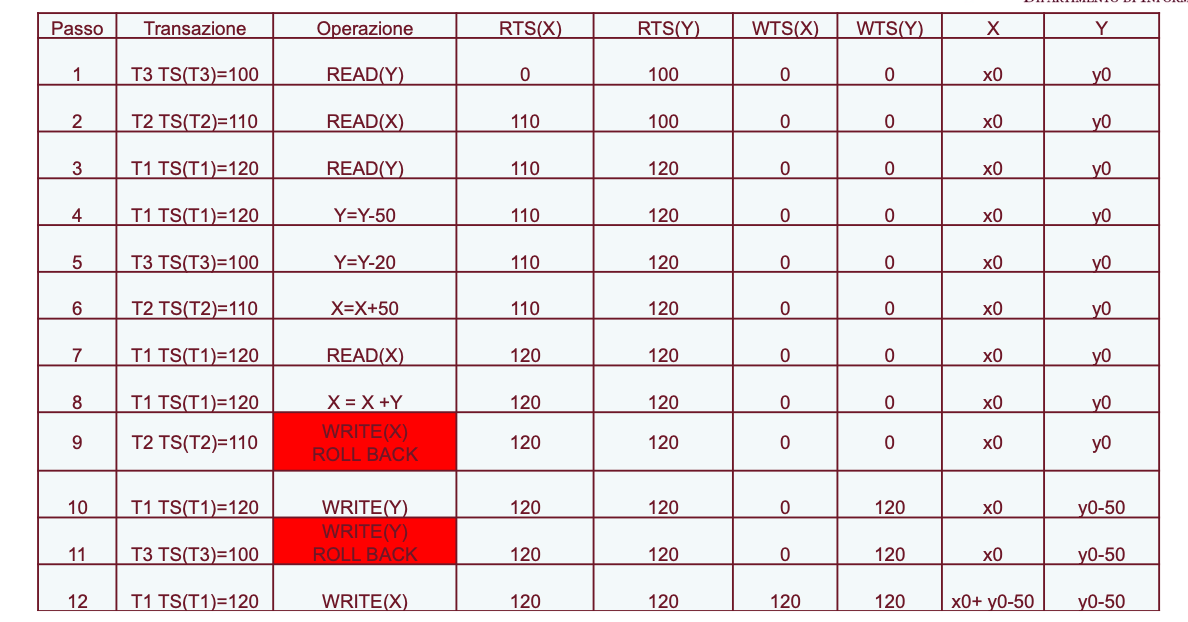
Al passo 9 T2 vuole eseguire un write(X), lei ha timestamp 110 ma il read time stamp di X è più grande e quindi dobbiamo eseguire un rollback.
Al passo 11 accade la stessa cosa.
Osservazioni
In entrambi i casi, lo schedule delle transazioni superstiti è equivalente allo schedule seriale delle transazioni eseguite nell’ordine di arrivo.
Quello che provoca il rollback di una transazione che vuole leggere è che una più giovane ha già scritto i dati.
Quello che provoca il rollback di una transazione che vuole scrivere è che una più giovane ha già letto i dati.
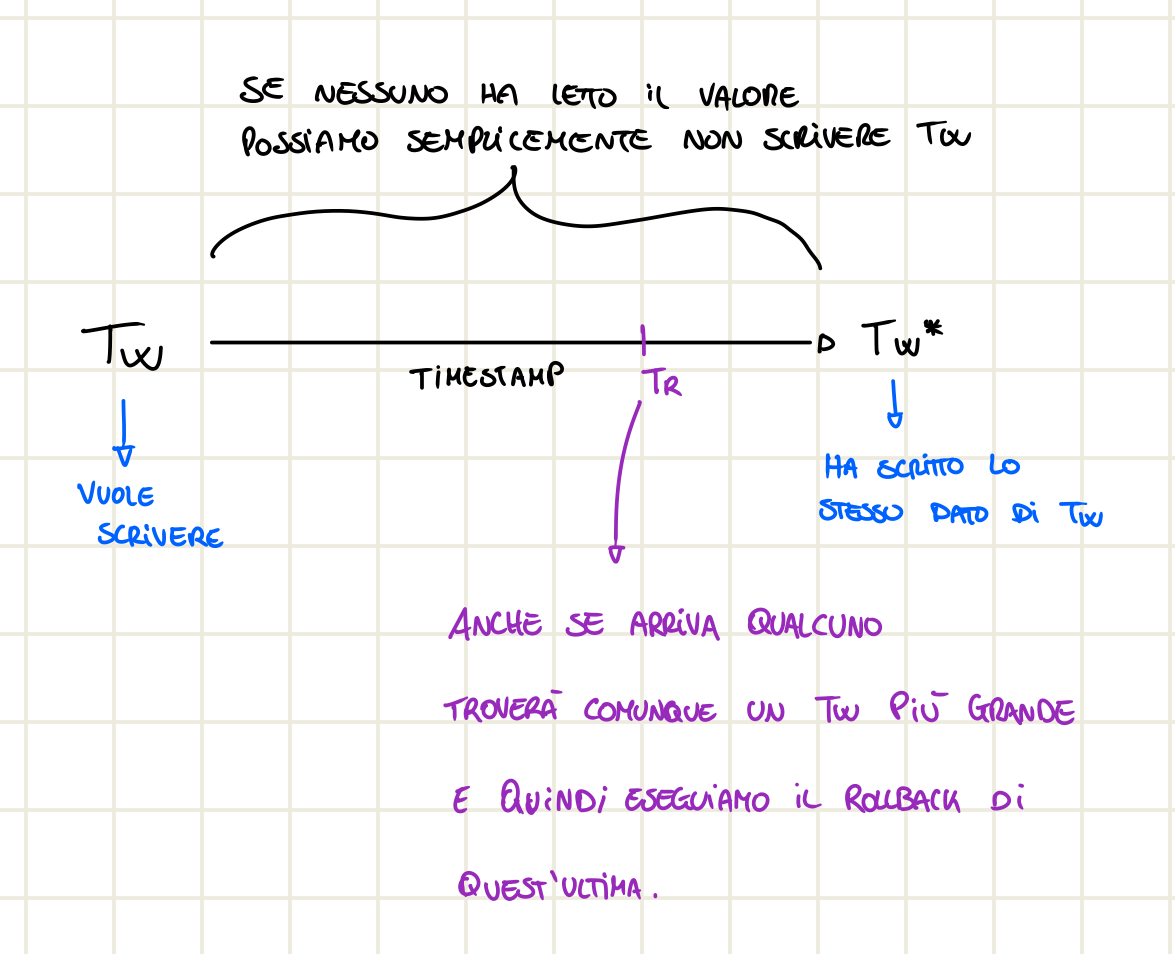
Da notare che se una transazione vuole scrivere e non c’è stata nessuna transazione più giovane che ha già letto ma una più giovane li ha già scritti allora non è necessario il rollback ma ci basta non effettuare la scrittura della più vecchia.
Perché è importante salvare il timestamp più alto e non quello dell’ultima transazione ad aver usato l’item?

Adesso supponiamo di scrivere su X il timestamp dell’ultima transazione, secondo l’algoritmo di scrittura T2 potrebbe scrivere su X ma è sbagliato dato che T3 che è più giovane ha già letto il dato e quindi T2 andrebbe a modificargli i dati essendo lei più vecchia. Non abbiamo rispettato l’ordine dei timestamp ovvero T1 T2 T3.
Perché possiamo annullare semplicemente la write in quel caso? Anche se spiegato prima: