Istruzioni, Assemblatore e Compilatore
Per comunicare con un computer abbiamo bisogno di inviare dei segnali elettrici, questo corrisponde all’azione di far passare corrente in un componente oppure no. In questo modo diventa molto semplice usare il sistema numerico binario per rappresentare con 1 il passaggio di corrente e con il 0 il non passaggio.
A seconda della progettazione della sua progettazione ogni componente reagisce in base alle sequenze di 0 ed 1 che riceve, queste sequenze prendono il nome di istruzioni e possono essere interpretate come comandi o come dei veri e propri numeri.
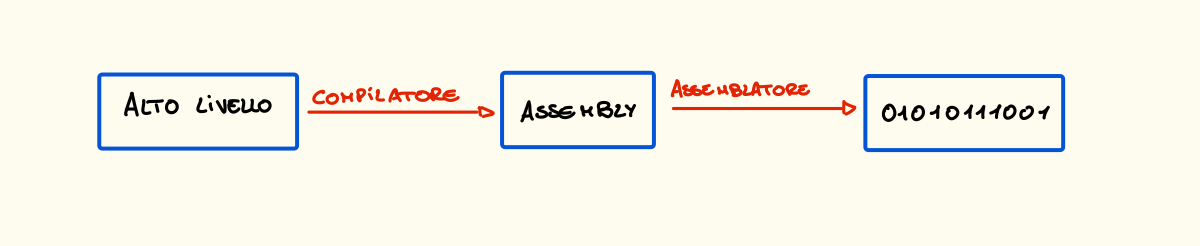
Inizialmente si comunicava con i computer inserendo manualmente ogni sequenza di numeri binari (bit) ma successivamente vennero creati gli assemblatori ovvero dei programmi in grado di convertire delle notazioni più vicini al nostro linguaggio in effettive istruzioni. Questo linguaggio viene detto Linguaggio Assembler.
Del codice scritto in assembly risulta comunque difficile da interpretare velocemente e per questo nacquero linguaggio sempre più vicini al nostro chiamati linguaggi ad alto livello, questi vengono interpretati da un compilatore che traduce questo codice in linguaggio assembly che a sua volta viene convertito in linguaggio macchina (bit di 0 e 1) da un assemblatore.
Architettura di Von Neumann, CPU e Memorie
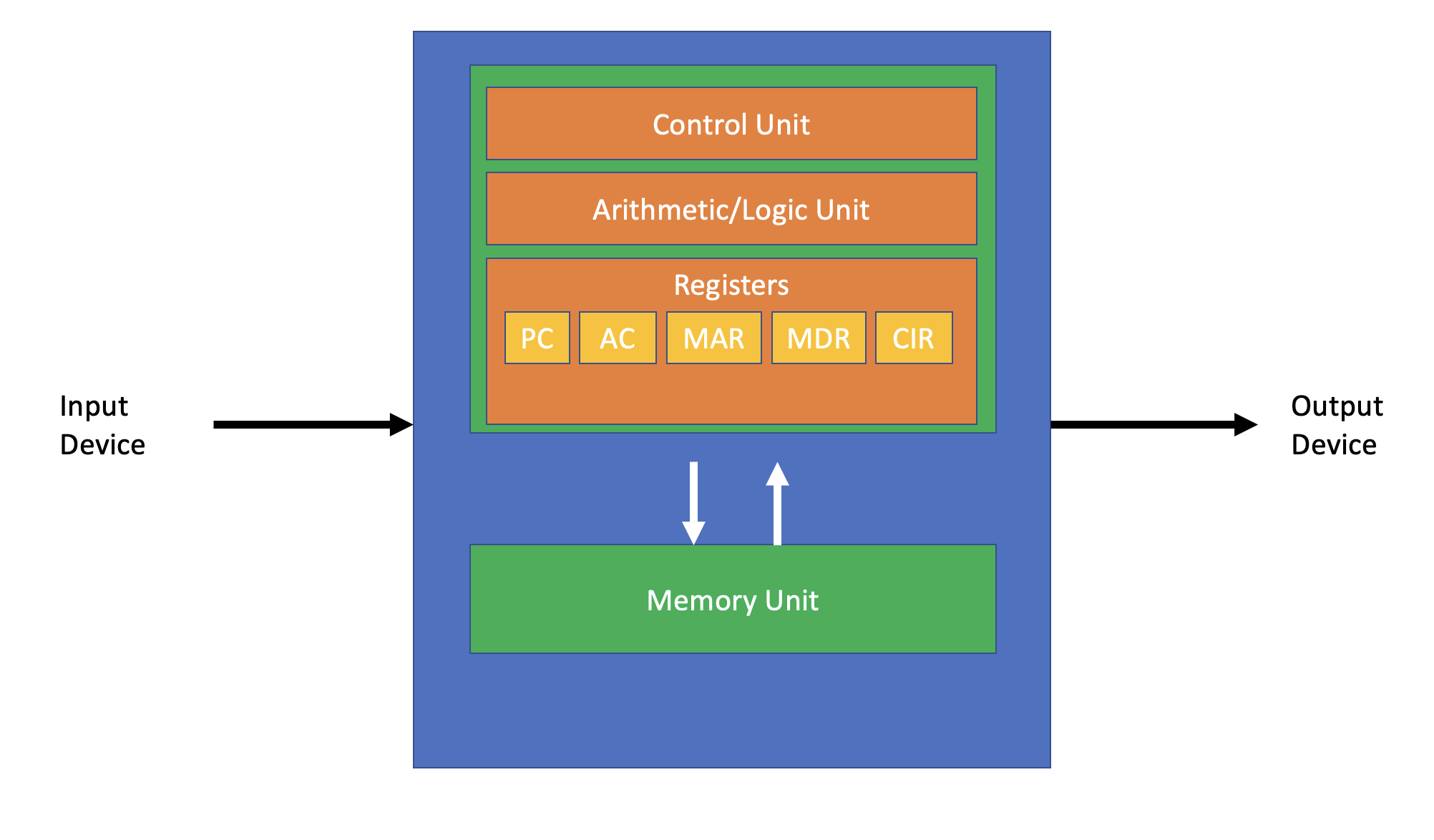
L’esempio più semplice di architettura di un computer è l’architettura di Von Neumann secondo la quale un computer è costituito da 4 elementi:
- Central Processing Unit (CPU): Esegue tutte le istruzioni che compongono un processo, ovvero un programma caricato in memoria. Questa a sua volta si divide in 3 elementi: - Control Unit (CU): Coordina le operazioni - Arithmetic Logic Unit (ALU): Svolge operazioni logiche e matematiche - Registri: Piccole memorie interne per dati temporanei
- Memoria: Serve a memorizzare istruzioni e dati
- Input / Output: Comunicare con l’esterno
- Bus di sistema: Un canale che mette in comunicazione tutti i componenti, questo si divide in 3 sottocanali ognuno con funzioni specifiche: - Control Bus: Coordinazione fra i componenti - Addres Bus: Indirizzi delle istruzioni da eseguire - Data Bus: Scambio di dati
I primi modelli di computer erano in grado di eseguire soltanto un processo alla volta, adesso abbiamo dei sistemi di parallelismo che ci permettono di gestire più processi in contemporanea. Questo metodo prende il nome di scheduling e consiste nel sospendere temporaneamente l’esecuzione di un processo ed eseguire le istruzioni di un secondo processo, grazie alla rapidità della CPU ci sembrerà di star eseguendo più programmi nello stesso momento. Infatti per ogni istruzione il processore deve svolgere 3 fasi:
- Fetch: Lettura dell’istruzione successiva
- Decode: Decodifica dell’operazione da compiere
- Execute: Esecuzione
L’architettura di Von Neumann prevede che un programma prima di venire eseguito venga caricato in memoria e quando questo succede il programma prende il nome di processo.
L’architettura MIPS 2000
Possiamo individuare due tipologie principali di architetture di calcolatori:
Architettura CISC:
- Complex Instruction Set Computer
- Istruzioni di dimensione variabile, per effettuare il fetch della prossima istruzione dobbiamo prima decodificarla
- Operazioni effettuate in memoria, necessitiamo di molti accessi a quest’ultima
- Pochi registri interni
- Modi di indirizzamento più complessi che rischiano di creare conflitti tra le istruzioni
Architettura RISC:
- Reduced Instruction Set Computer
- Istruzioni di dimensione fissa
- Operazioni svolte dalla ALU e solo tra registri
- Molti registri interni
- Modi di indirizzamento più semplici dato che le istruzioni hanno lunghezza fissa
Le architetture di tipo CISC sono più complesse ma ottimali per scopi specifici mentre le RISC sono più semplici ma per scopi generici. L’architettura MIPS rientra nelle RISC
- Word con dimensione fissa da 32 bit
- Spazio di indirizzamento di word
- Memoria indicizzata al byte (8 bit) quindi dato un indirizzo di memoria per accedere al successivo dovremo andare al
- I numeri vengono salvati in Complemento a 2 su 32 bit
- Dotata di 3 microprocessori:
- CPU principale dotata di ALU e 32 registri, svolge le istruzioni
- Coprocessore 0 gestione delle “trap” (eccezioni…)
- Coprocessore 1 esegue i calcoli in virgola mobile
- 32 registri:

Linguaggio Assembly MIPS
Le istruzioni che possiamo dare alla CPU nell’architettura MIPS hanno una struttura molto semplice ovvero:
<operazione> <destinazione>, <sorgenti>, <argomenti>
Un esempio pratico che possiamo fare è l’operazione di somma fra due registri:
add $s0, $t0, $t1Questa istruzione non fa altro che leggere i valori nei registri t0, sommarli e scrivere il risultato nel registro $s0.
Struttura
È importante ricordare che questa struttura è una generalizzazione e non viene rispettata da tutte le istruzioni.
Infatti anche se le istruzioni hanno strutture diverse per noi umani quando vengono lette ed interpretate dall’assemblatore queste vengono convertite in word da lunghezza fissa di 32 bit (linguaggio macchina). La disposizione di questi 32 bit determina quindi il tipo di istruzione e tutto quello che deve fare il calcolatore, abbiamo 3 tipologie di istruzioni:
Istruzioni R-Type (tipo registro)
Questa tipologia di istruzioni accede a valori presenti nei registri e NON ha bisogno quindi di accedere alla memoria, viene utilizzata per svolgere operazioni logiche ed aritmetiche
.jpg)
- Opcode (OP): Indica la categoria dell’istruzione
- First Register (RS): Indica il primo registro sorgente
- Second Register (RT): Indica il secondo registro sorgente
- Destination Register (RD): Indica il registro dove verrà scritto il risultato
- Shift Amount (SHAMT): Indica la quantità di bit da shiftare
- Function Code (FUNCT): Possiamo vederlo come un’estensione dell’opcode infatti questo ci indica l’operazione specifica da eseguire all’interno della categoria indicata dall’opcode
Istruzioni I-Type (tipo immediato)
Questa struttura viene utilizzata per le operazioni di load e store ma anche per effettuare salti condizionati

- Opcode (OP): Viene indicata l’operazione di tipo immediato da svolgere
- First Register (RS): Indica il registro sorgente
- Destination Register (RT): Indica il registro dove verrà scritto il risultato dell’operazione
- Immediate: Viene indicato il valore costante da utilizzare nell’operazione (ad esempio una somma).
Istruzioni J-Type (tipo jump)
Questa struttura viene utilizzata per effettuare salti non condizionati

- Opcode (OP): Viene indicata l’operazione di salto non condizionato
- Address: Contiene l’indirizzo dove effettuare il jump, è importante ricordare che siccome la memoria è indicizzata al byte e non seguendo le word, quindi se voglio andare avanti di un’istruzione devo andare avanti di 32 bit (4 byte). Quindi ad esempio se accedo all’indirizzo 2500, in realtà sto entrando all’indirizzo 10.000 (2500 * 4).
Differenza dei salti
- Salti Condizionati: vengono effettuati solo se si verificano determinate condizioni
- Salti non Condizionati: l’istruzione viene eseguita indipendentemente da altri fattori
Organizzazione della memoria
La memoria nell’architettura MIPS 2000 è indicizzata al byte e come abbiamo già visto ogni word è composta da 4 byte. Per avere in testa un’idea più chiara di come è fatta la memoria possiamo vederla come una tabella composta da 4 colonne dove ciascuna di queste indica un byte e righe dove ogni riga indica una word. Ad ogni byte è associato un indirizzo che per comodità è rappresentato da 8 cifre esadecimali, infatti ogni cifra esadecimale è formata da 4 bit quindi 8 * 4 = 32 bit
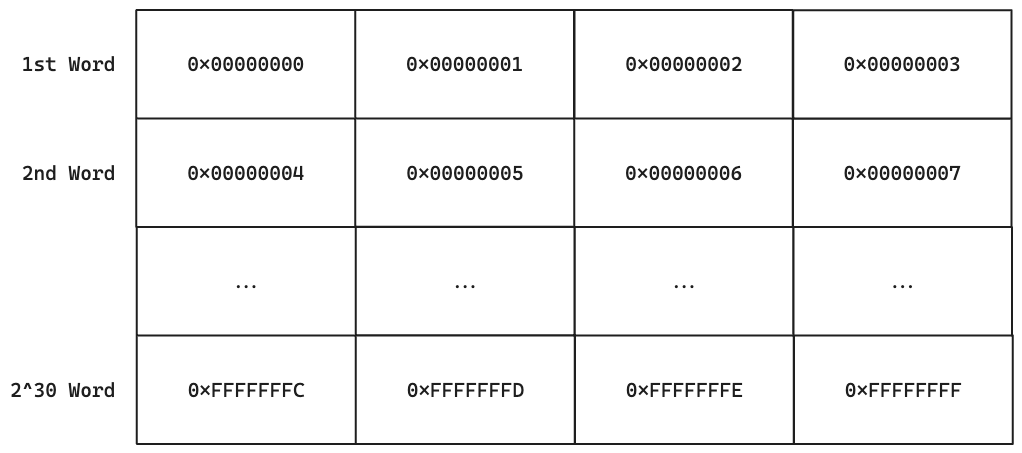
Quindi possiamo dire che il k-esimo byte si troverà all’indirizzo dato che contiamo anche lo 0 mentre la j-esima word si trova all’indirizzo .
In linguaggio assembly per leggere il contenuto di una word presente in memoria si utilizza questa istruzione:
<offset>($indirizzo)Dove al posto di $indirizzo dobbiamo inserire un registro che contiene l’indirizzo di memoria da cui andremo a estrarre la word mentre al posto di offset inseriamo il numero di byte successivi a partire dall’indirizzo specificato.
Esempio: Vogliamo accedere alla word presente all’indirizzo 3996 e anche alla sua successiva:
li $t0, 3996
lw $t1, 0($t0)
lw $t1, 4($to)- li (load immediate): Abbiamo caricate nel registro $t0 il valore 3996
- lw (load word): Abbiamo caricato l’intera word presente all’indirizzo presente in t1. Nella riga successiva sempre con la stessa istruzione abbiamo caricato la word successiva all’indirizzo 3996 ovvero la 4000.
Parti della memoria
Adesso che sappiamo come è organizzata la memoria possiamo vedere le sue parti principali
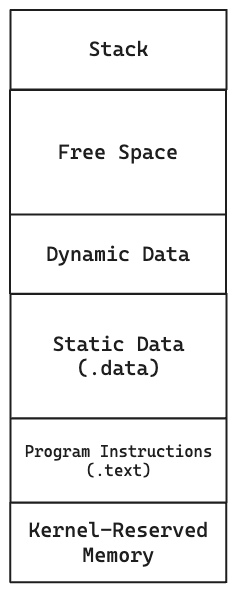
- Stack: Viene utilizzata per gestire le funzioni ovvero le sue variabili locali ma anche chiamate ricorsive, non ha dimensione fissa e può espandersi anche nel free space, per operare al suo interno utilizziamo il registro $sp stack pointer.
- Dynamic Data (Heap): Contiene i dati dinamici che vengono creati durante l’esecuzione dei programmi, anche questa si può espandere nel free space.
- Static Data: Contiene tutti i dati statici dichiarati all’avvio del programma ovvero nella sezione .data che vedremo in seguito, per gestire gli indirizzi in questa zona viene utilizzato il registro $gp global pointer.
- Program Instructions: Contiene le istruzioni del programma presenti nella sezione .text, all’interno di questa sezione opera il Program Counter ovvero il registro che contiene la posizione dell’istruzione successiva da eseguire.
- Kernel Reserved: Sezione di memoria riservata al kernel del sistema operativo alla quale noi programmatori non possiamo accedere, nel caso questo avvenisse si verificherebbe un’eccezione.
Direttive Principali ed Esempi di Codice
Prima di iniziare a scrivere codice assembly è importante saper riconoscere quelle che sono le direttive, queste non sono vere e proprie istruzioni ma delle notazioni che verranno convertite dall’assemblatore in istruzioni più complesse.
Le principali sono queste:

Vediamo un esempio di codice molto banale per introdurre anche il concetto di label e poi andiamo a vedere un codice più articolato.
.text
main:
li $t0, 5 # Carichiamo 5 in $to
li $t1, 0x10 # Carichiamo il valore esadecimale 0x10 in $t1
add $s0, $t0, $t1 # Scriviamo in $s0 il valore $t0 + $t1Quindi nel registro $s0 abbiamo scritto il valore 21 ovvero 5 + 16 (10 esadecimale). La label è la scritta main: presente prima del codice, questa funziona come da segnalibro per l’assemblatore e possono essere inserite sia per indicare istruzioni o dati statici.
.data
vettore: 10, 2, 0x12
stringa: "Ciao sono Alessio"
vettore_float: 10.3, 3.14
.text
main:
la $s0, vettore # Carico indirizzo del vettore in $s0
lw $s1, 0($s0) # 10 -> $s1
lw $s2, 4($s0) # 2 -> $s2
lw $s3, 8($s0) # 0x12 -> $s3
add $t0, $s1, $s2 # $s1 + $s2 -> $t0
sub $t0, $t0, $s3 # $t0 - $s3 -> $t0Endianess
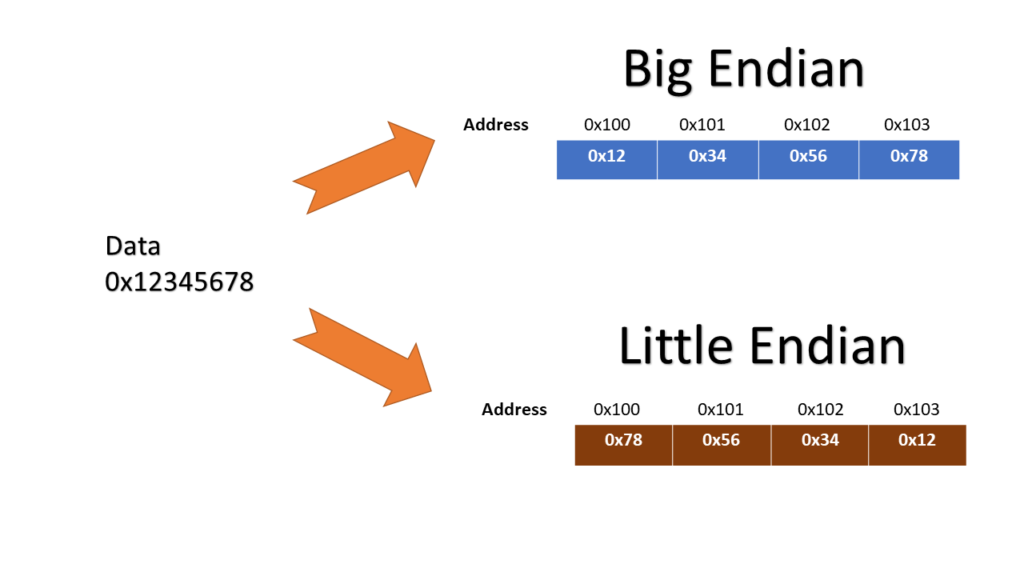
I processori possono salvare e interpretare i byte nella memoria in diversi modi, due di questi formati sono:
- Big Endian: Il byte più significativo viene salvato all’indirizzo più basso, quindi prima, mentre i byte meno significativi negli indirizzi successivi
- Little Endian: Il byte più significativo viene salvato all’indirizzo più alto, quindi dopo, mentre i byte meno significativi vengono salvati negli indirizzi precedenti
Nel simulatore MARS utilizziamo la notazione little endian infatti se andiamo a vedere la rappresentazione ASCII delle stringhe che salviamo risulteranno invertite ogni 4 caratteri (byte)

Salti Condizionati e Salti Assoluti
Con un’operazione di salto andiamo a modificare il registro del Program Counter ovvero l’indirizzo dell’istruzione successiva da eseguire.
- Salti Assoluti: L’operazione di salto viene eseguita non appena viene raggiunta.
.text
main:
li $t0, 0
loop:
addi $t0, $t0, 1
j loop // Salto all'etichetta 'loop'In questo caso abbiamo creato un loop infinito, infatti non raggiungeremo mai la fine del programma.
- Salti Condizionati:
Hanno lo stesso funzionamento dei jump, ovvero vanno a modificare l’indirizzo presente nel program counter ma lo fanno soltanto se rispettiamo una determinata condizione, possiamo creare più condizioni:
- Branch on Equal: Il salto viene effettuato se e solo se il valore contenuto nel primo registro è uguale al secondo.
beq $s1, $s2, label- Branch on Not Equal: Il salto viene effettuato se e solo il valore contenuto nel primo registro non è uguale al valore contenuto nel secondo registro.
bne $s1, $s2, label- Branch on Less Than or Equal Zero: Il salto viene effettuato se e solo se il valore contenuto nel primo registro è minore o uguale a zero.
blez $s1, label- Branch on Greater Than or Equal Zero: Il salto viene effettuato se e solo il valore contenuto nel primo registro è maggiore o uguale a zero.
bgez $s1, label- Branch on Less Than Zero: Il salto viene effettuato se e solo se il valore contenuto nel primo registro è minore di zero.
bltz $s1, label- Branch on Greater Than Zero: Il salto viene effettuato se e solo se il valore contenuto nel primo registro è maggiore di zero.
bgtz $s1, labelEsempio di codice che cerca il valore massimo in un array di 4 valori
.data
values: 10, 13, 99, 9
maxValue = 0
.text
main:
lw $s0, values
lw $s1, values+4
lw $s2, values+8
lw $s3, value+12
CopyA: move $t0, $s0
CheckB: slt $t1, $t0, $s1
beq $t1, $zero, CheckC
move $t0, $s1
CheckC: slt $t1, $t0, $s2
beq $t1, $zero, CheckD
move $t0, $s2
CheckD: slt $t1, $t0, $s3
beq $t1, $zero, End
move $t0, $s3
End: sw $t0, maxValueIn questa versione del codice non abbiamo utilizzato i salti per creare dei cicli infatti il programma è molto ridondante, possiamo creare una versione migliorata salvando in un registro l’indirizzo di memoria del vettore e ciclando su tutti i valori.
.data
values = 10, 13, 99, 1000
maxValue = 0
.text
main:
la $s0, values
li $s1, 3
lw $s2, 0($s0)
CheckNext:
subi $s1, $s1, 1
addi $s0, $s0, 4
lw $t0, 0($s0)
slt $t1, $s2, $t0
beq $t1, $zero, CheckEnd
move $s2, $t0
CheckEnd:
bne $s1, $zero, CheckNext
sw $s2, maxValueVettori e Matrici
Abbiamo già introdotto il concetto di vettore ovvero una collezione di elementi posti in sequenza nella memoria, tutti della stessa dimensione. Questo concetto è molto importante per la gestione della memoria, consideriamo adesso questi vettori:
vet1: .word 100, 55, 4
vet2: .half 100, 55, 4
vet3: .byte 100, 55, 4Questi 3 vettori differiscono nella lunghezza dei loro elementi, infatti il primo è composto da word da 4 byte, il secondo da half word da 2 byte e il terzo da byte. Possiamo rappresentarli nella memoria in questo modo:
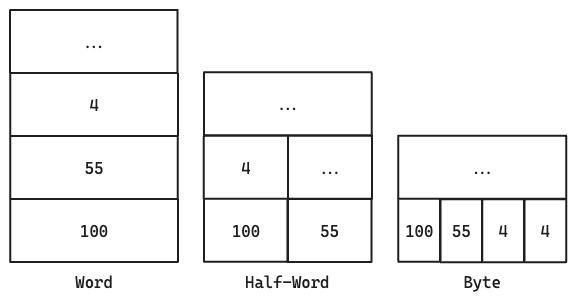
Questa differenza ovviamente implica anche un codice assembly diverso, infatti nel primo vettore ci sposteremo di 4 in 4, nel secondo di 2 in 2 mentre per l’ultimo di byte in byte.
.text
main:
li $s0, vet1
li $s1, vet1 + 4
li $s0, vet2
li $s1, vet2 + 2
li $s0, vet3
li $s0, vet3 + 1Notiamo quindi che è possibile utilizzare diversi formati per rappresentare i nostri dati e svolgere le stesse funzioni ma usando una quantità molto inferiore di memoria
Stringhe di caratteri
Possiamo estendere il concetto di vettore alle stringhe di caratteri, infatti i caratteri alfanumerici vengono codificati in un valore binario di 8 bit utilizzando la codifica ASCII, quindi ogni carattere corrisponde ad un byte. Quindi possiamo dire che una stringa di testo non è altro che un vettore di caratteri dove ogni carattere corrisponde al suo valore intero nella codifica ASCII.
Fine Stringa
Ogni carattere occupa un byte in memoria e a fine di ogni stringa viene inserito un carattere speciale che fa capire al compilatore la fine della stringa, ‘\0’ ovvero il Null Byte
Per accedere agli elementi di un vettore ci sono due modi:
-
Accesso tramite puntatore: L’indirizzo di memoria viene caricato in un registro che prende appunto il nome di puntatore. Per raggiungere il k-esimo valore il nostro puntatore dovrà valere: indirizzo_vettore + k * dim_elementi(es. 4-2-1 ecc..)
Esempio:
.data
vector: 10, 123, 33
.text
main:
la $s0, vector # Carico in $s0 l'indirizzo del vettore
li $t0, 2 # Carico in $t0 il valore 2, indice dell'elemento
sll $t1, $t0, 2 # Carico in $t1 il valore $t0 * 4 (shifto di 2)
add $s0, $s0, $t1 # Sommo $s0 e $t1 (sposto il puntatore)- Accesso traite indice: Nel caso in cui il vettore è stato creato in modo statico quindi nella direttiva .data possiamo accedervi usando direttamente un valore e non un puntatore
.data
vector: 10, 123, 33
.text
main:
li $t0, 2 # Carico 2 in $t0
sll $t1, $t0, 2 # Moltiplico per 4 e carico in $t1
lw $s0, vector($t1) # Leggo l'indirzzo vettore+$t1Matrici - vettori di vettori
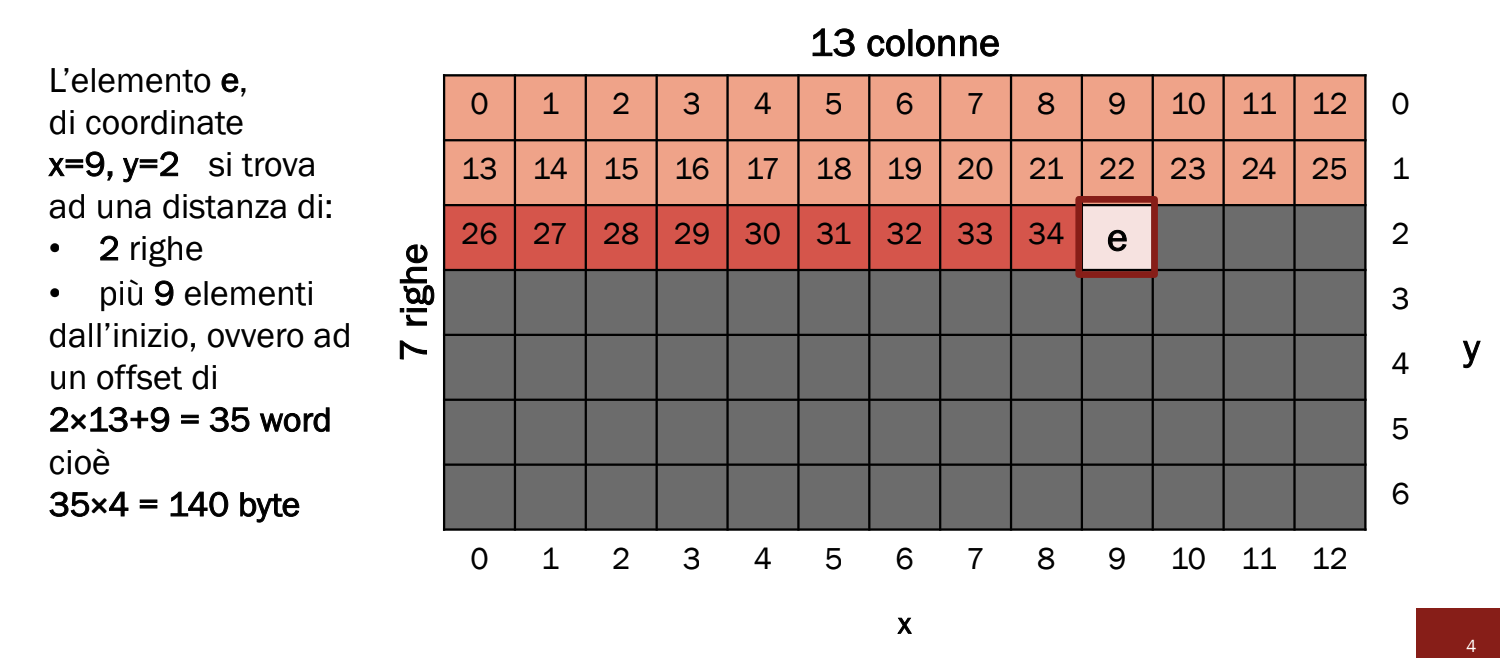
Una matrice non è altro che un vettore di M elementi dove ogni elemento è un vettore di N elementi, otteniamo quindi questi dati:
- Numero totale di elementi =
- Dimensione Totale in byte =
- In memoria verrà salvata come una serie di M serie tutte da N elementi, ovvero un’unica serie di M * N elementi cosecutivi.
Dato che in assembly non abbiamo un tipo per definire le matrici spetta a noi programmatori decretare le sue dimensioni, infatti una serie di 36 elementi può essere interpretata come:
Accedere ad elementi specifici:
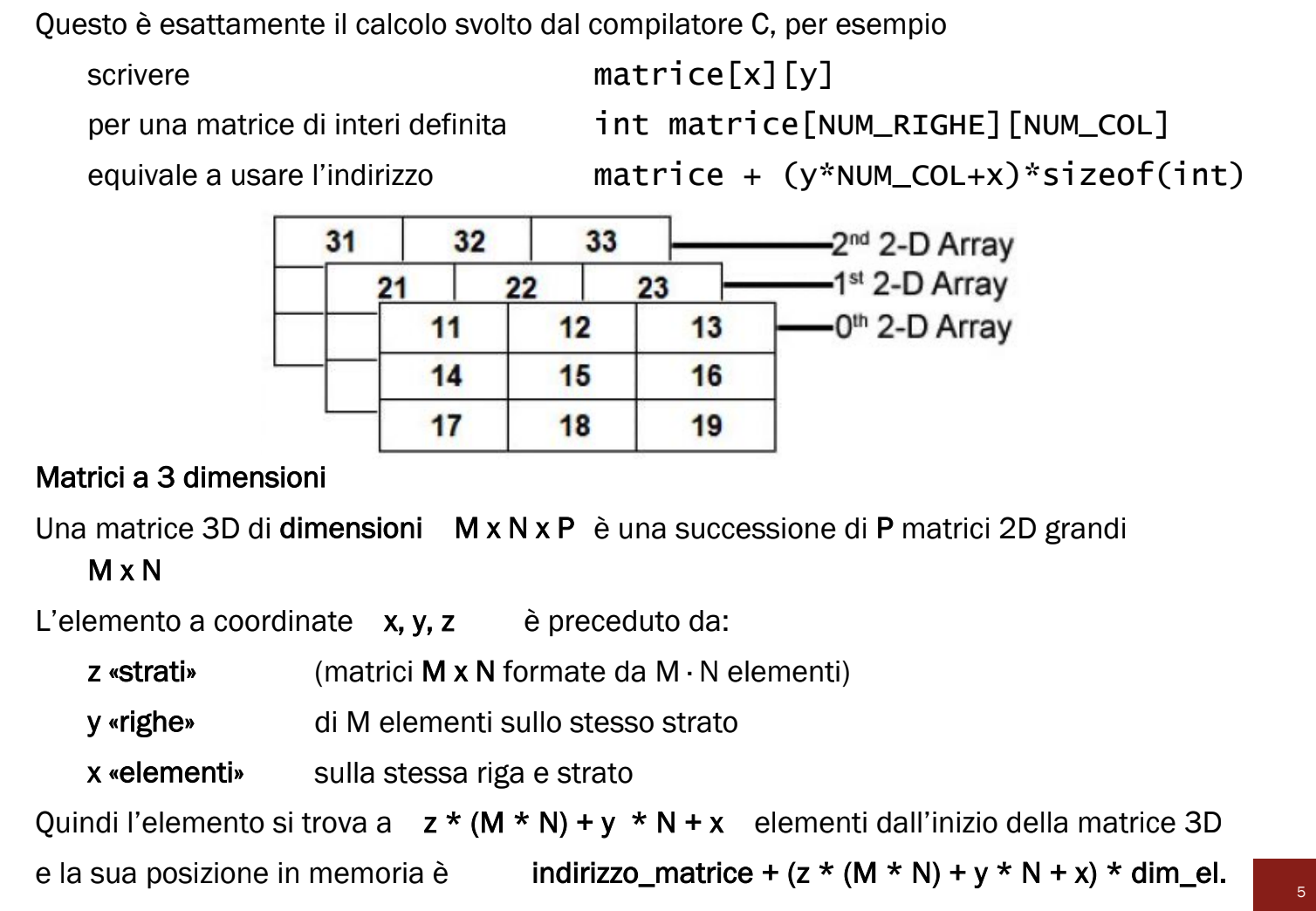
Matrici 3D
System Calls (syscalls)
Con il termine syscall indichiamo una chiamata al sistema ovvero un set di servizi messi a disposizione dal Kernel del Sistema Operativo. Ogni S.O. gestisce le chiamate in modo diverso ma generalmente un sistema MIPS segue questo formato:
- Input:
- Registro $v0: Dove inseriamo il codice della syscall che vogliamo chiamare
- Registri a1, f0: Vengono inseriti eventuali parametri aggiuntivi
- Output:
- Registri f0: Vengono restituiti eventuali valori della syscall
Quella spesso più utilizzata è la syscall per mandare in stampa valori sul terminale
.data
stringa: .asciiz "Hello, World!"
.text
main:
la $a0, stringa # Carichiamo in $a0 l'indirzzo della stringa
li $v0, 4 # Carichiamo il valore per la stampa
syscall # Chiamiamo la syscall4 infatti è il valore da caricare nel registro a0 dobbiamo caricare l’indirzzo della stringa. Ci sono molti valori per syscall, questi sono solo alcuni:
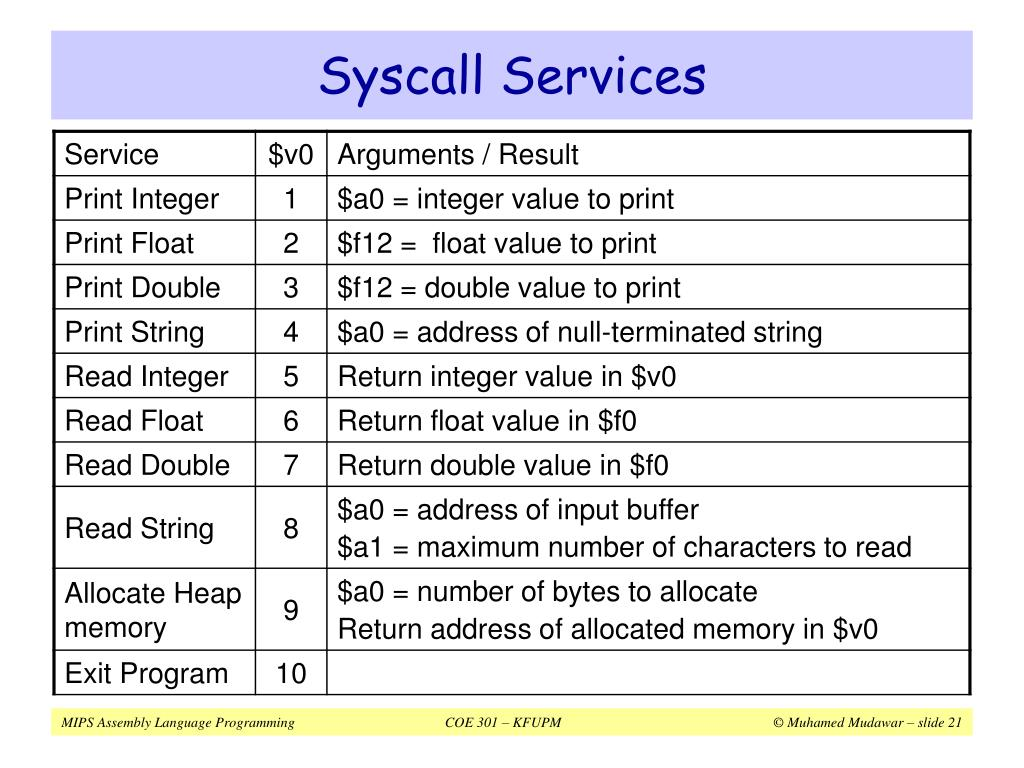
Pseudoistruzioni
Le pseudoistruzioni possiamo vederle come un insieme di istruzioni, queste infatti sono utilizzabili nel linguaggio MIPS ma non sono implementate a livello hardware, vengono quindi tradotte dall’assemblatore in una sequenza di istruzioni implementate nella CPU.
Funzioni e Procedure
Una funzione è un segmento di codice che riceve degli argomenti e restituisce un valore di ritorno, sono utili per rendere il codice riutilizzabile e modulare. Le funzioni hanno una loro struttura in assembly:
- Hanno un indirizzo di partenza
- Leggono dei registri scelti come argomenti della funzione
- Svolge le operazioni
- Carica i risultati in dei registri scelti come output
- Quando termina ritorna all’istruzione da cui è stata chiamata, riprendendo quindi l’esecuzione del codice principale
Per chiamare una funzione utilizziamo l’istruzione jal <label> (Jump and Link) che prima di effettuare il salto alla label salva nel registro $ra l’indirizzo di memoria dell’istruzione successiva (PC + 4). Una volta che la funzione termina possiamo ritornare al codice principale con l’istruzione jr <registro> (Jump to Register) sul registro $ra.
Convenzioni
- Registri di Input ($a0, $a1, $a2, $a3)
- Registri di output ($v0, $v1)
- Registri temporanei ($t0, $t1, …) sono i registri che possono cambiare tra una chiamata e un’altra
- Registri salvati ($s0, $s1, …) non cambiano tra una chiamata e un’altra
Esempio di codice
.text
main:
li $a0, 5 // Carico il primo argomento
li $a1, 7 // Carico il secondo argomento
jal somma_con_quadrato // Eseguo la funzione
move $a0, $v0 // sposto in a0 il risultato della somma
jal stampa_intero // Eseguo la funzione
li $v0, 10 // Syscall per terminare
syscall
somma_con_quadrato:
mult $t0, $a1, $a1
add $v0, $a0, $t0
jr $ra
stampa_intero:
li $v0, 1
syscall
jr $raQuesto tipo di implementazione però può presentare dei problemi dato che le funzioni potrebbero utilizzare dei registri usati anche dal codice principale, dovremmo quindi salvare in altri registri lo stato precedente del programma prima di chiamare la funzione. Oppure possiamo utilizzare lo stack di memoria
Stack di Memoria
Quindi prima di chiamare una funzione è buona norma preservare lo stato in cui si trova il programma, ovvero i valori contenuti nei registri, per poi ripristinarlo una volta eseguita quest’ultima. In questo modo possiamo anche chiamare più funzioni all’interno di una funzione tramite la conservazione dell’indirizzo contenuto in $ra, quest’ultimo infatti verrebbe sovrascritto dalla seconda funzione che chiamiamo e così non avremmo più modo di tornare al codice principale.
Seguiamo quindi uno schema simile:
- Salviamo lo stato dei registri precedente della prima funzione
- Salviamo lo stato dei registri precedente della seconda funzione
- …
- Ripristiniamo lo stato dei registri precedente alla seconda funzione
- Salviamo lo stato dei registri precedente della seconda funzione
- Ripristiniamo lo stato dei registri precedente alla prima funzione
Questo comportamento è quello di una pila o Stack al quale viene aggiunto un elemento in cima e viene rimosso un elemento sempre dalla cima, Push e Pop
Per realizzare questo utilizziamo una zona della memoria apposita chiamata stack di memoria che cresce verso il basso tenendo traccia dell’ultimo elemento preservato nella funzione tramite il registro $sp (Stack Pointer)
Apertura e Chiusura dello Stack
Supponiamo quindi di dover salvare il contenuto del registro $t0 nello stack in modo da poterne modificare il valore all’interno di un’altra funzione per poi ripristinarlo una volta conclusa.
Siccome lo stack di memoria cresce verso il basso e il registro $sp punta all’ultimo elemento salvato nello stack, dobbiamo sottrarre a $sp la dimensione in byte dell’elemento che si vuole salvare per poi andarlo a salvare in memoria nell’indirizzo puntato da $sp (apertura dello stack). Una volta terminate le operazioni della funzione, possiamo eseguire le operazioni inverse ripristinando lo stato dei registri (chiusura dello stack).
subi $sp, $sp, 4 // Apertura dello stack per salvare una word
sw $t0, 0($sp) // Salvo $t0 all'indirizzo puntato da $sp
// Operazioni della funzione
lw $t0, 0($sp) // Carico il valore precedente di $t0
addi $sp, $sp, 4 // Chiusura dello stack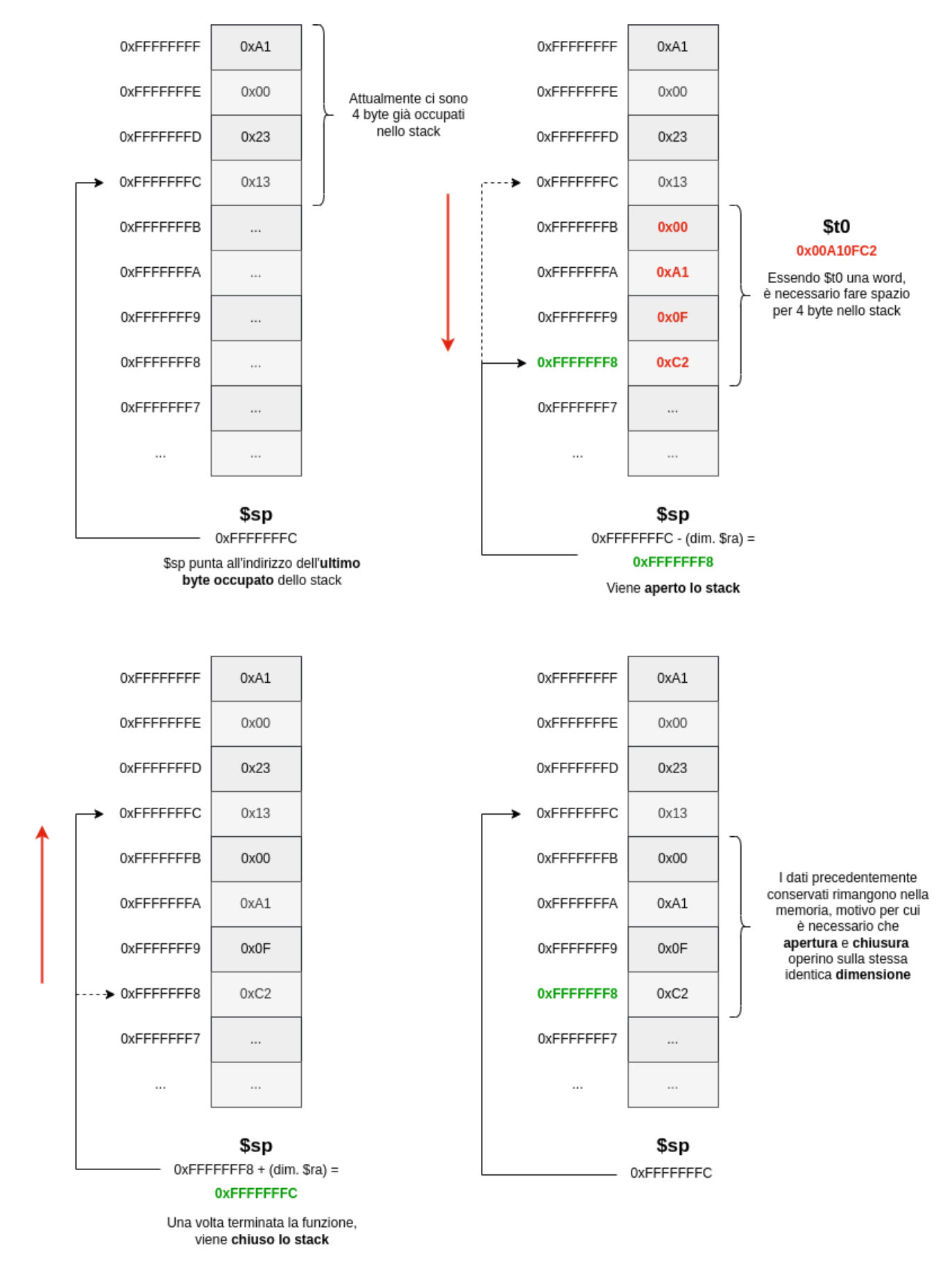
Tutto quello che viene salvato nello stack prende il nome di Stack Frame ed è composto da:
- Argomenti della funzione
- Indirizzo di ritorno
- Frame pointer, indirizzo da cui parte lo stack frame ma spesso non è necessario, è contenuto in $fp
- Registri utilizzati all’interno della funzione
- Variabili locali create nella funzione in modo che vengano eliminate una volta che questa si chiude
Riscriviamo quindi il programma di prima ma preservando lo stato del programma nello stack:
.text
main:
li $a0, 5
li $a1, 7
jal somma_con_quadrato
move $a0, $v0
jal stampa_intero
li $v0, 10
syscall
somma_con_quadrato:
// Apertura Stack
subi $sp, $sp, 8
sw $ra, 0($sp)
sw $t0, 4($sp)
mult $t0, $a1, $a1
add $v0, $a0, $t0
// Chiusura Stack
lw $t0, 4($sp)
lw $ra, 0($sp)
addi $sp, $sp, 8
jr $ra
stampa_intero:
// Apertura stack
subi $sp, $sp, 8
sw $ra, 0($sp)
sw $v0, 4($sp)
li $v0, 1
syscall
// Chiusura dello stack
lw $v0, 4($sp)
lw $ra, 0($sp)
addi $sp, $sp, 8
jr $raCi basta quindi sottrarre la quantità di byte che ci servono a memorizzare tutti i registri che andremo a modificare, salvare i registri in memoria e poi una volta svolta le operazioni della funzione eseguiamo le operazioni inverse ai salvataggi.
Funzioni Ricorsive
Come in altri linguaggi anche in assembly è possibile scrivere delle funzioni che chiamano se stesse che spesso rendono la soluzione di un problema più semplice da scrivere. L’implementazione è molto simile a quella di linguaggi di alto livello, abbiamo quindi bisogno di almeno un caso base e di un problema più complesso che manda la funzione in ricorsione
Esempio con Fibonacci
.text
main:
li $a0, 3 // Argomenti della funzione
jal Fibonacci
move $a0, $v0 // Stampa risultato
li $v0, 1
syscall
li $v0, 10 // Fine programma
syscall
Fibonacci:
beq $a0, 0, BaseCase_0 // Se $a0 == 0
beq $a0, 1, BaseCase_1 // Se $a0 == 1
j RecursiveStep // Se $a0 > 1
BaseCase_0:
li $v0, 0
jr $ra // Ritorno al chiamante
BaseCase_1:
li $v0, 1
jr $ra
RecursiveStep:
// Apertura Stack
subi $sp, $sp, 12
sw $ra, 0($sp)
sw $a0, 4($sp)
sw $v1, 8($sp)
subi $a0, $a0, 1
jal Fibonacci
move $v1, $v0 // $v1 = fib($a0 - 1)
subi $a0, $a0, 1
jal Fibonacci // $v0 = fib($a0 - 2)
add $v0, $v1, $v0 // $v0 = $v0 + $v1
// Chiusura dello stack
lw $v1, 8($sp)
lw $a0, 4($sp)
lw $ra, 0($sp)
addi $sp, $sp, 12
jr $raLa logica del programma è quindi se sto in un caso base metto in $v0 0 o 1 altrimenti vado in ricorsione sul numero presente in $a0 -1 e -2 sommando poi i risultati ottenuti. Il risultato finale sarà salvato su $v0