La CPU
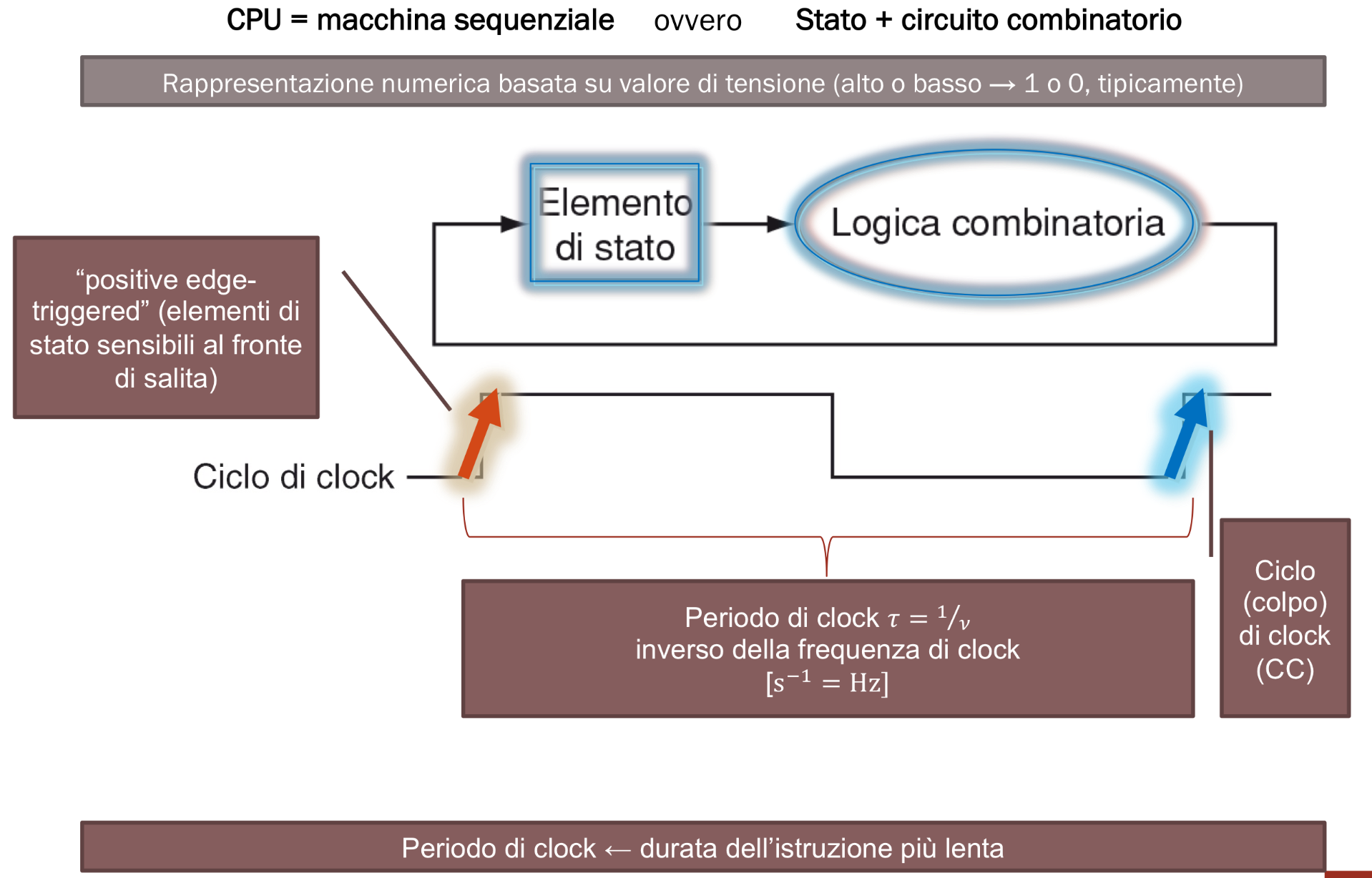
La CPU è una macchina sequenziale questo significa che è formata da uno stato che la descrive e una logica combinatoria che cambia lo stato. La CPU cambia il suo stato grazie ad un clock, questa infatti è sensibile ai fronti di salita, viene quindi chiamata positive edge-triggered, ad ogni colpo di clock viene quindi eseguita un’istruzione. Dato che le istruzioni nel circuito, ovvero i segnali, si propagano parallelamente, il tempo di esecuzione delle istruzioni è dato dall’istruzione più lenta e come periodo di clock dobbiamo quindi scegliere un tempo maggiore a quest’ultima oppure rischiamo di ottenere dei risultati sbagliati.
Overclock
Quando effettuiamo overclock di una CPU spesso può capitare che il sistema non sia stabile proprio perché la CPU prende i risultati delle istruzioni quando queste non sono ancora finite. Succede appunto quando la frequenza di clock è più veloce del tempo di esecuzione delle istruzioni.
Progettare la CPU MIPS
Dobbiamo stabilire le proprietà della nostra CPU:
- Definire come viene elaborata un’istruzione
- Scegliere quali istruzioni realizzare
- Quali unità funzionali ci servono
- Collegare queste unità
- Costruire la CU (Control Unit) ovvero il componente che controlla il funzionamento della CPU (La CU deve saper leggere le istruzioni sottoforma di sequenze da 32 bit)
- Calcolare il massimo tempo di esecuzione delle istruzioni (ci fornisce il periodo di clock)
Fasi di esecuzione di un’istruzione:
- Fetch: Carichiamo i 32 bit dell’istruzione dalla memoria alla CU
- Decodifica: Decodifica i 32 bit dell’istruzione e leggi gli argomenti dai registri
- Esecuzione: Svolta dall’ALU
- Memoria: Lettura / Scrittura in Ram / Registri
- Write Back: Scrittura dei risultati nei registri se necessaria
Altre Operazioni necessarie:
- Aggiornare il Program Counter
Istruzioni da Realizzare
| Categoria Istruzioni | Esempio | Tipo |
|---|---|---|
| Accesso alla memoria | lw, sw | I |
| Salti Condizionati | beq | I |
| Operazioni aritmetico-logiche | add, sub, sll, slt | R |
| Salti non Condizionati | j, jal | J |
| Operazioni non costanti | li, addi, subi | I |
Formato delle istruzioni in memoria:

Unità Funzionali Necessarie
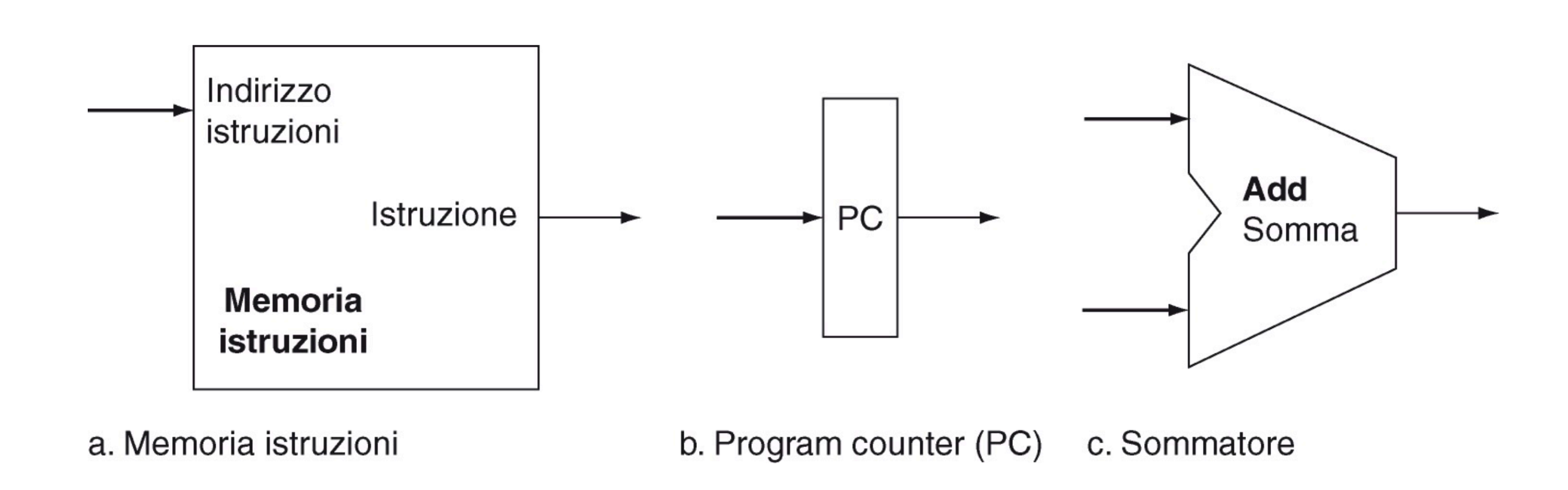
- Pogram Counter: Contiene l’indirizzo dell’istruzione da eseguire
- Memoria Istruzioni: Contiene le istruzioni
- Adder: Calcola il PC e la destinazione dei salti
- Registri: Contengono gli argomenti delle istruzioni
- ALU: Svolge le operazioni aritmetico-logiche
- Memoria dati: Da cui leggere / scrivere dati (op. load / store)
Quando un’unità può ricevere dati da più sorgenti è necessario utilizzare un MUX per selezionare la sorgente desiderata.
Memoria Istruzioni, PC e Sommatore
Memoria istruzioni:
- Input: Indirizzo a 32 bit
- Output: Istruzione da 32 bit situato all’indirizzo in input Program Counter:
- Registro che contiene l’indirizzo dell’istruzione corrente Sommatore:
- Calcola il nuovo PC e la destinazione dei salti
- Riceve due valori da 32 bit e ne restituisce la somma
Ad esempio per aumentare il PC alla prossima istruzione:
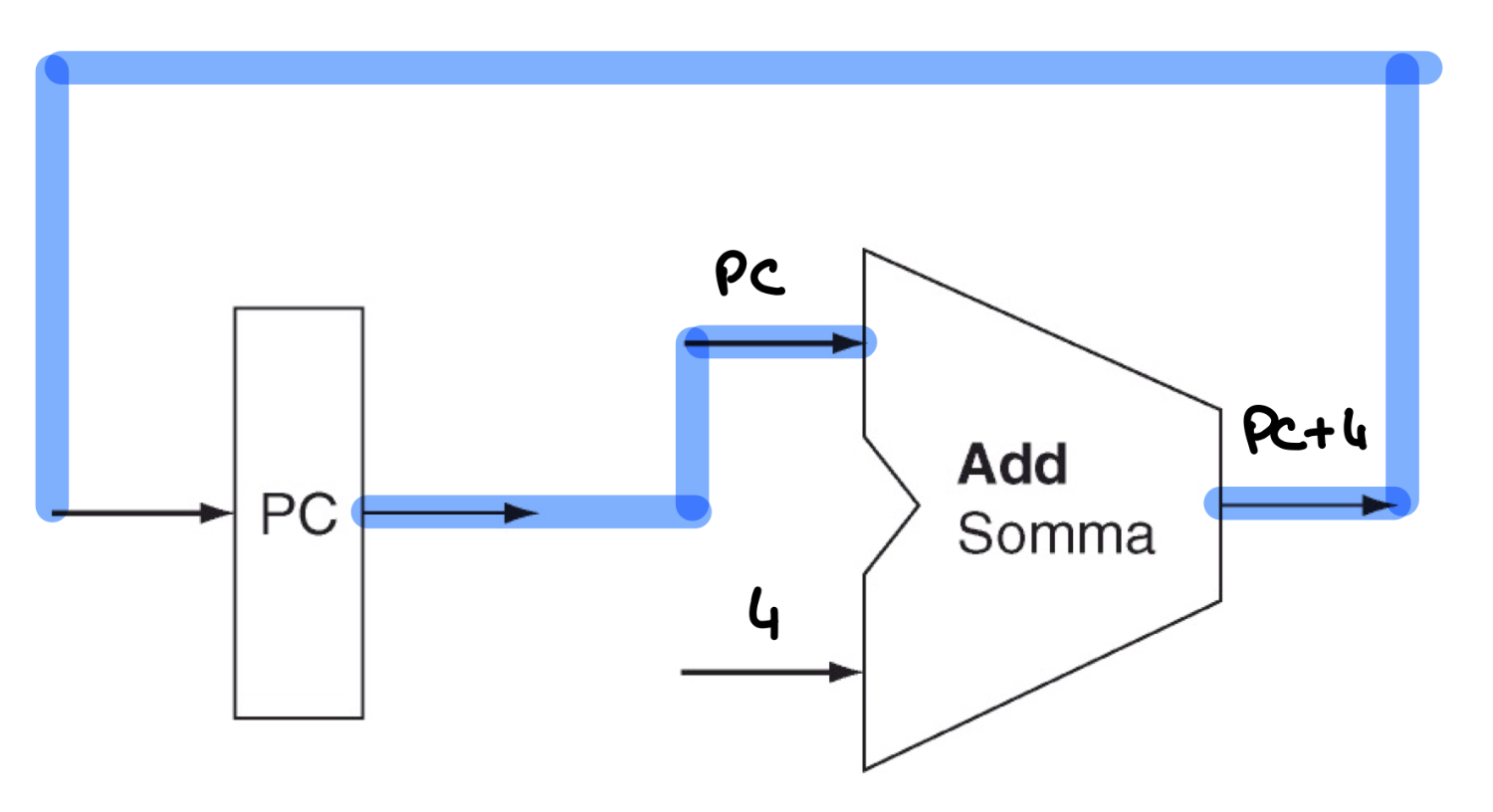
Nota: il 4 andrà inserito in 32 bit
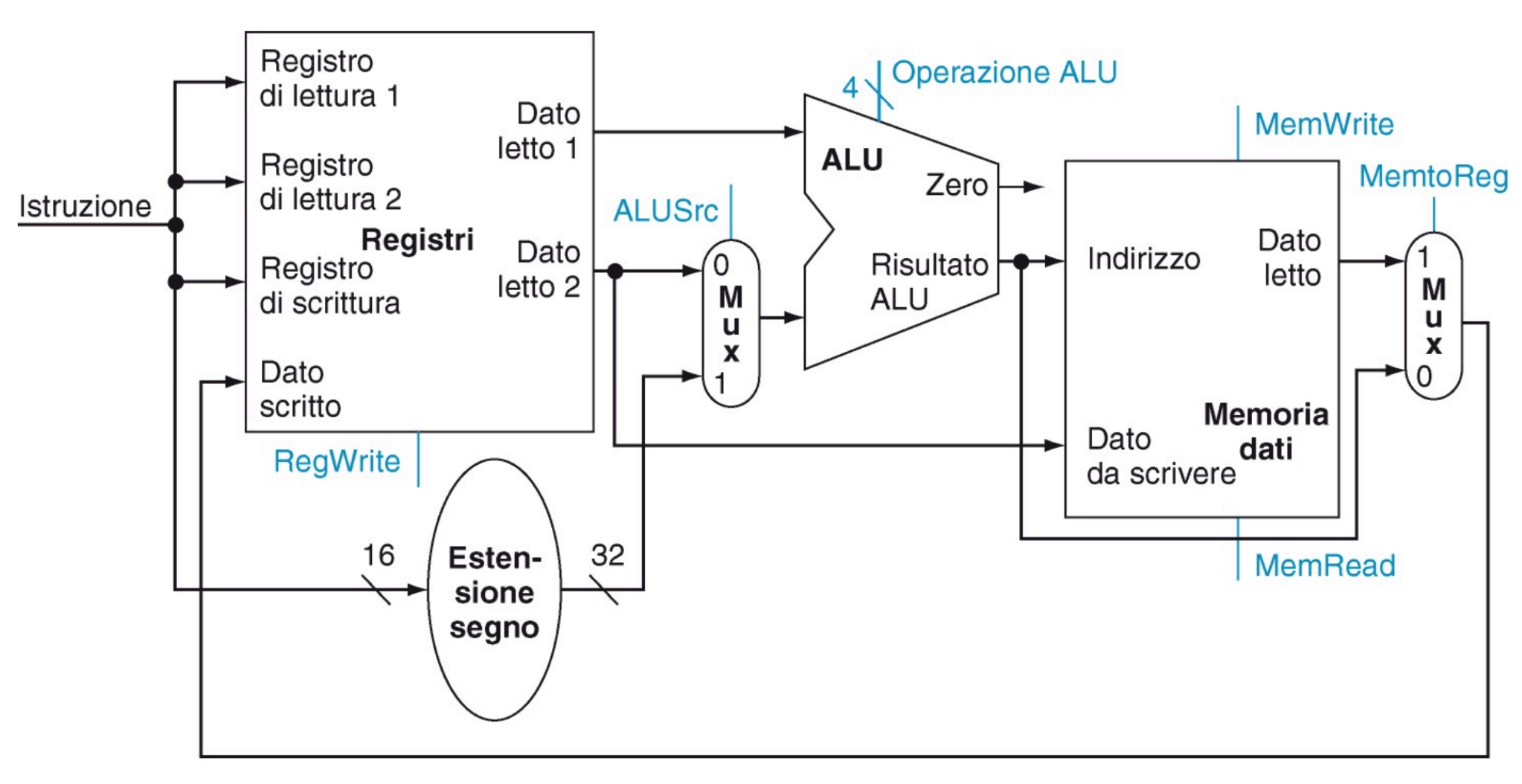
Registri e ALU
Blocco dei registri:
- Contiene 32 registri a 32 bit indirizzabili con 5 bit
- Può memorizzare un dato in un registro e contemporaneamente fornirlo in uscita
- 3 porte a 5 bit per indicare 2 registri dai quali leggere e uno su cui scrivere
- 3 porte dati a 32 bit:
- Una in ingresso per il valore da memorizzare
- 2 in uscita per i valori letti dai registri in input
- Il segnale RegWrite abilita se impostato ad 1 la scrittura nel registro di scrittura
ALU:
- Riceve due valori a 32 bit e svolge l’operazione indicata nel segnale Operazione ALU da 4 bit
- Oltre al risultato da 32 bit produce anche un segnale Zero da un bit che viene impostato ad 1 se il risultato dell’operazione vale 0, altrimenti viene impostato a 0.
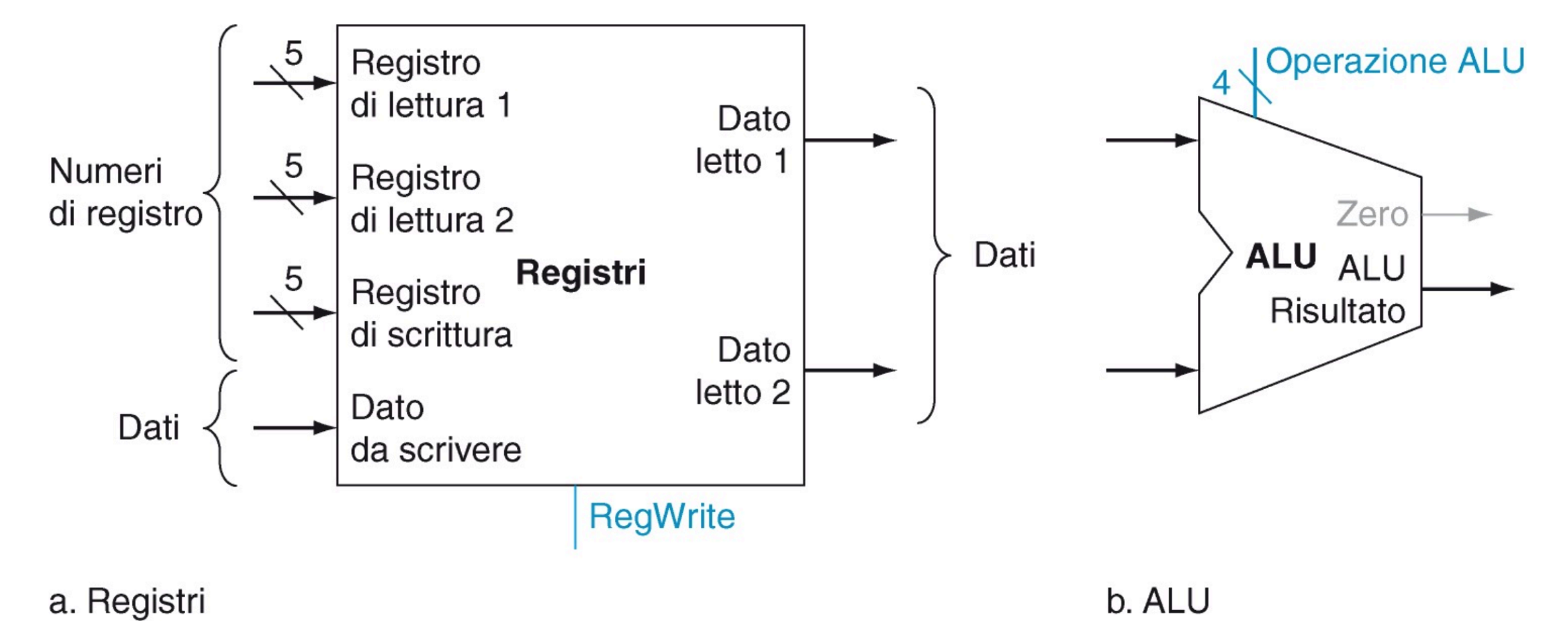
Abbiamo bisogno di sommatore e ALU dato che il PC va aggioranto durante l’esecuzione di altre istruzioni
Memoria Dati, unità di estensione del segno
Unità di memoria:
- Riceve un indirizzo da 32 bit che indica quale word della memoria va letta / scritta
- Riceve il segnale MemRead che abilita la lettura (istruzione lw)
- Riceve un dato da 32 bit che va salvato in quell’indirizzo (istruzione sw)
- Riceve il segnale MemWrite che abilita la scrittura del dato all’indirizzo
- Fornisce una porta in uscita a 32 bit per il dato letto, accade quando MemRead = 1
NOTA: i segnali MemRead e MemWrite sono univoci, non possono essere abilitati entrambi nello stesso momento.
Unità estensione segno:
- Trasforma un intero relativo, CA2 da 16 bit a 32 bit, quindi copia il bit del segno nei 16 bit più significativi della parola
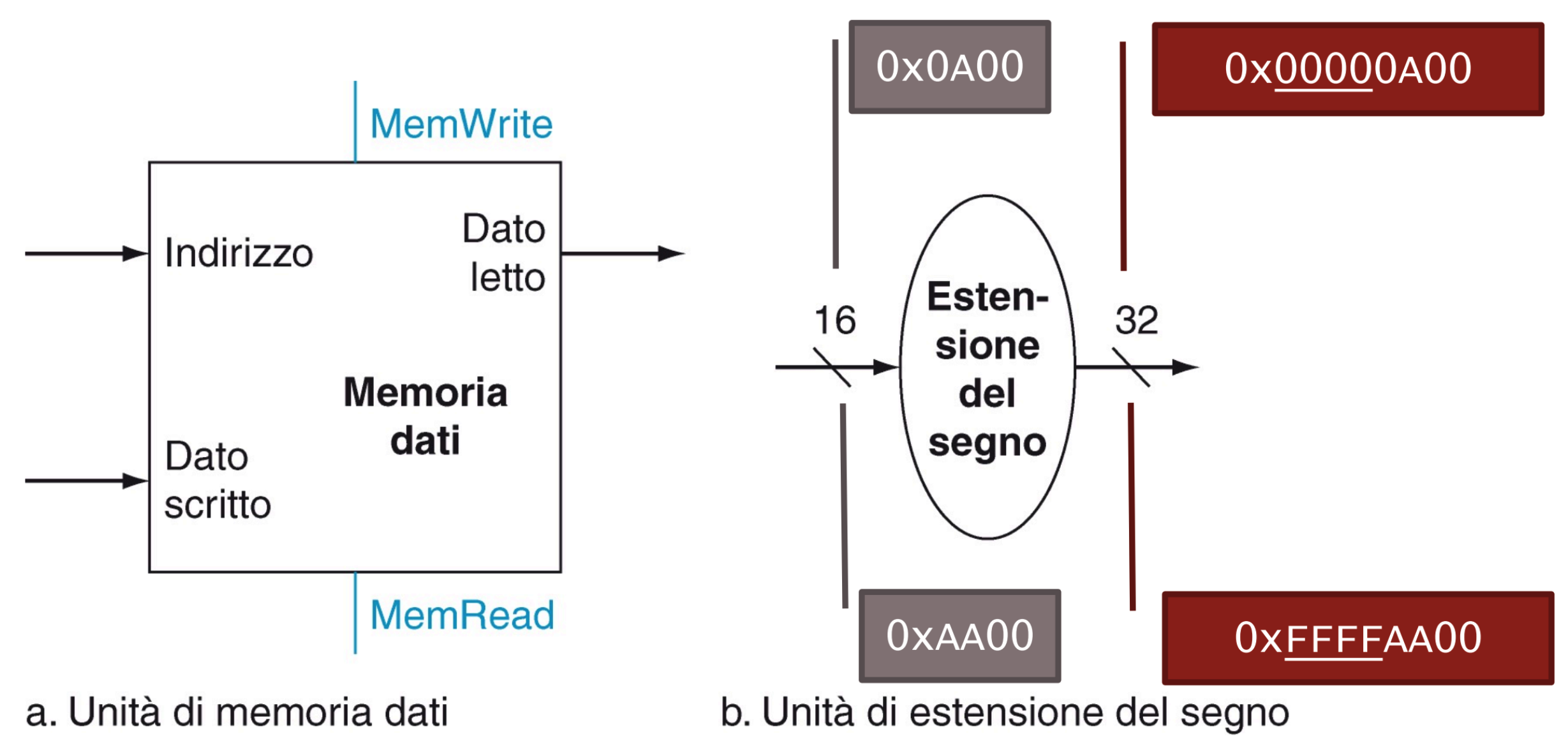
L’intero relativo positivo è stato esteso con tanti 0 mentre l’intero relativo negativo è stato esteso con tante F
Fetch di un’istruzione e aggiornamento PC
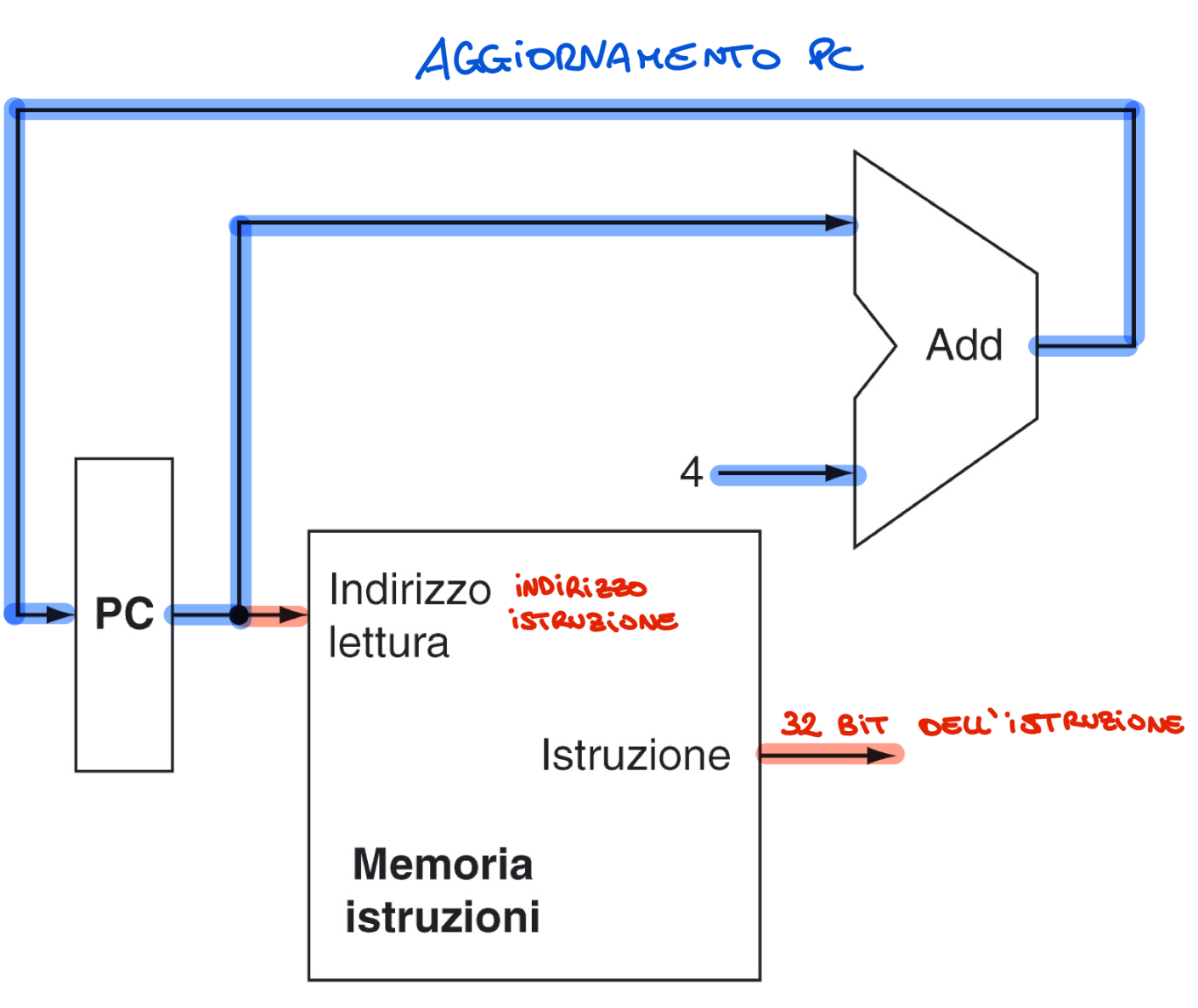
Quindi estraiamo i 32 bit che rappresentano l’istruzione dalla mememoria, incrementiamo il PC e lo rimandiamo in input al PC.
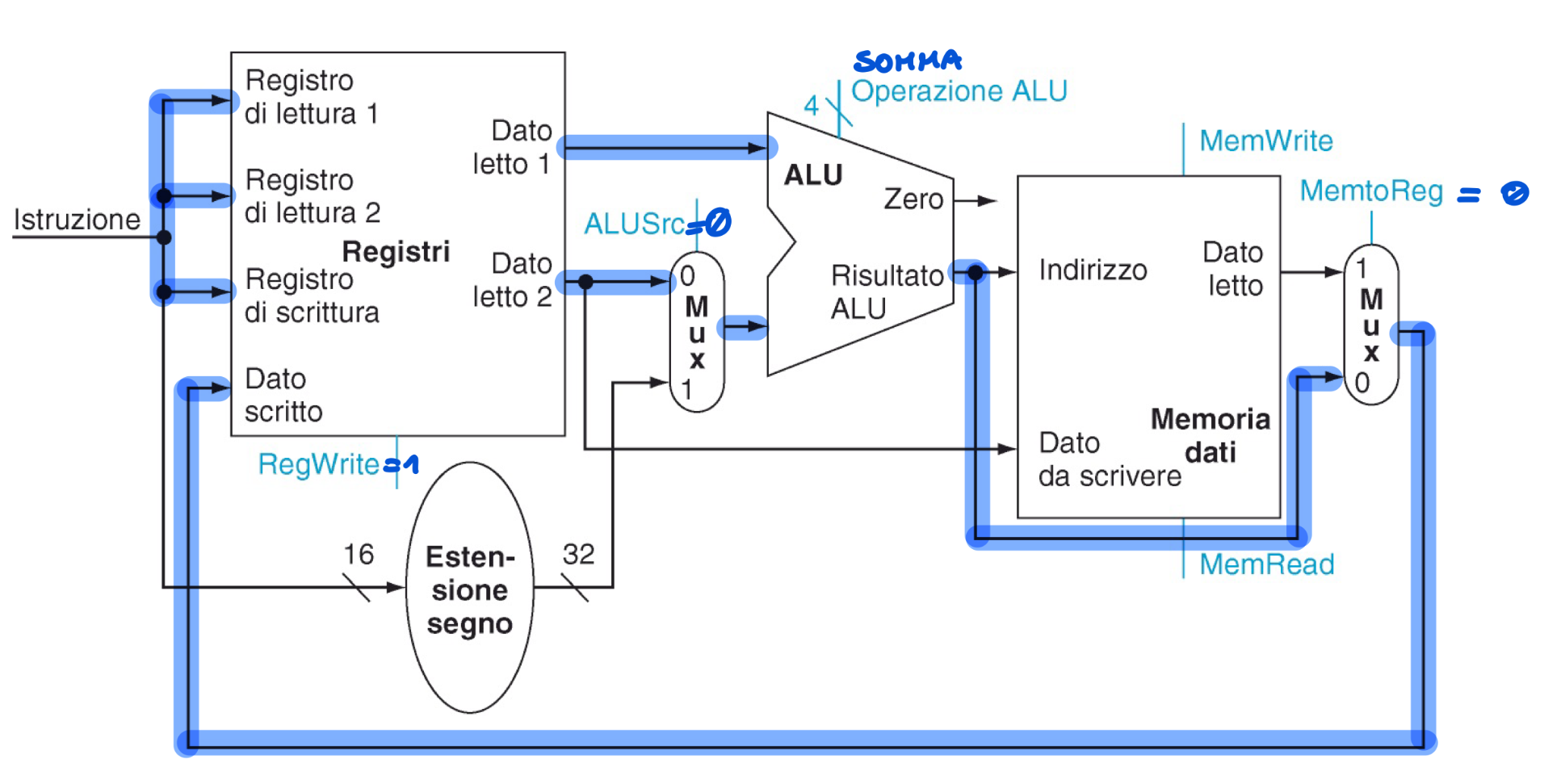
Operazioni ALU e accesso alla Memoria
Le istruzioni di tipo I e R sono molto simili, infatti il secondo argomento dell’istruzione è un registro o un campo immediato. Utilizziamo un segnale ALUSrc che seleziona la porta di un MUX per far entrare un campo immediato o un registro. Il risultato dell’ALU o della lw viene selezionato dal segnale MemtoReg che comanda un altro MUX
Nello specifico:
Linee utilizzate per l’istruzione add s1, $s2
Linee utilizzate per l’istruzione lw s0, 4(\s1)
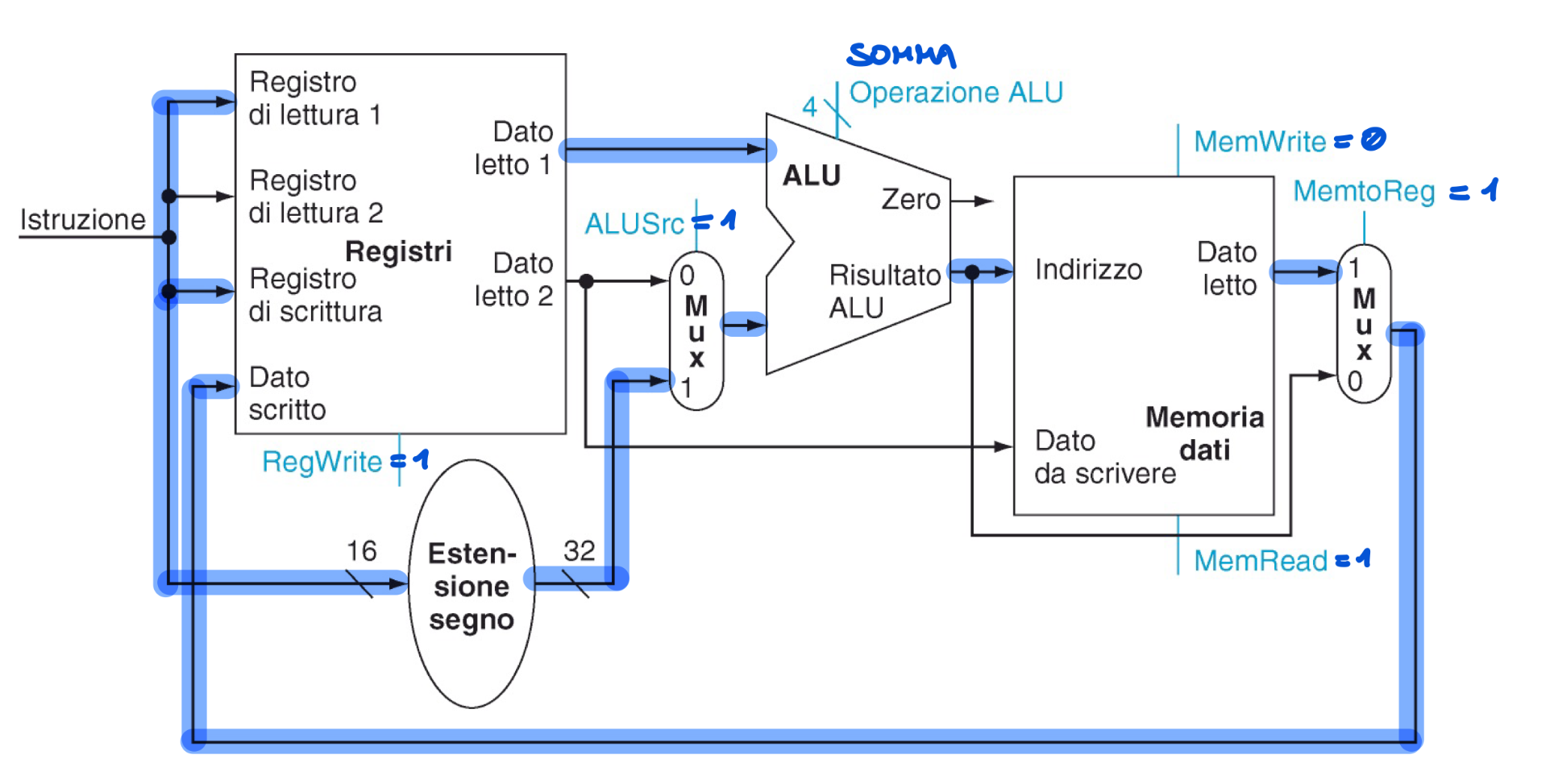
Linee utilizzate per l’istruzione sw s0, 4(\s1)
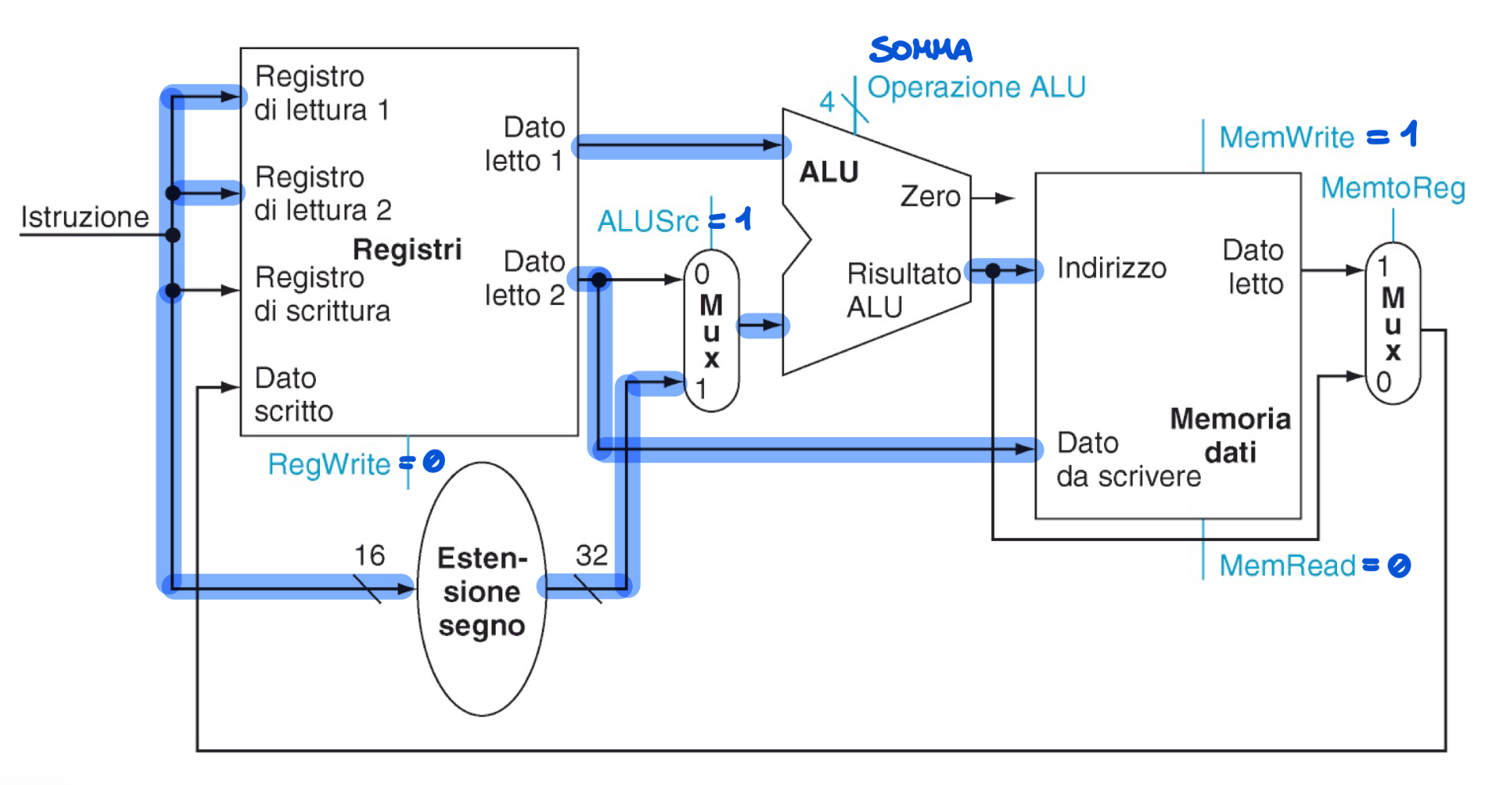
Salti Condizionati
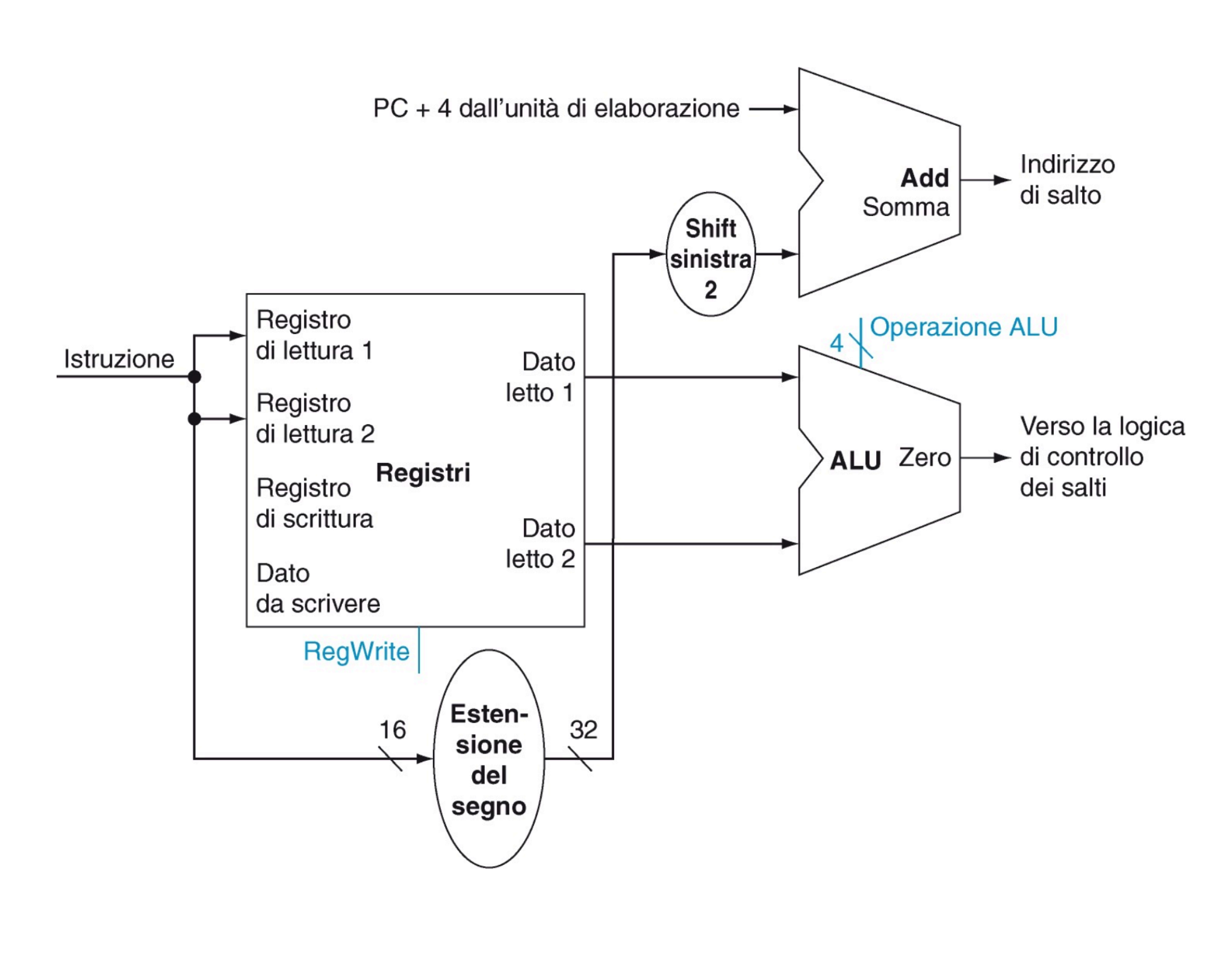
- La ALU viene utilizzata come comparatore (sottrazione) se il segnale zero vale 1 allora dobbiamo effettuare il salto
- La destinazione dei salti sarà un numero relativo all’istruzione seguente estesa nel segno, moltiplicata per 4 e sommata a PC + 4
- Il nuovo valore del PC può quindi provenire da PC + 4 o dall’uscita dell’adder ovvero dopo un salto Abbiamo bisogno di un MUX di selezione
Linee utilizzate per l’istruzione beq 0, \1, label
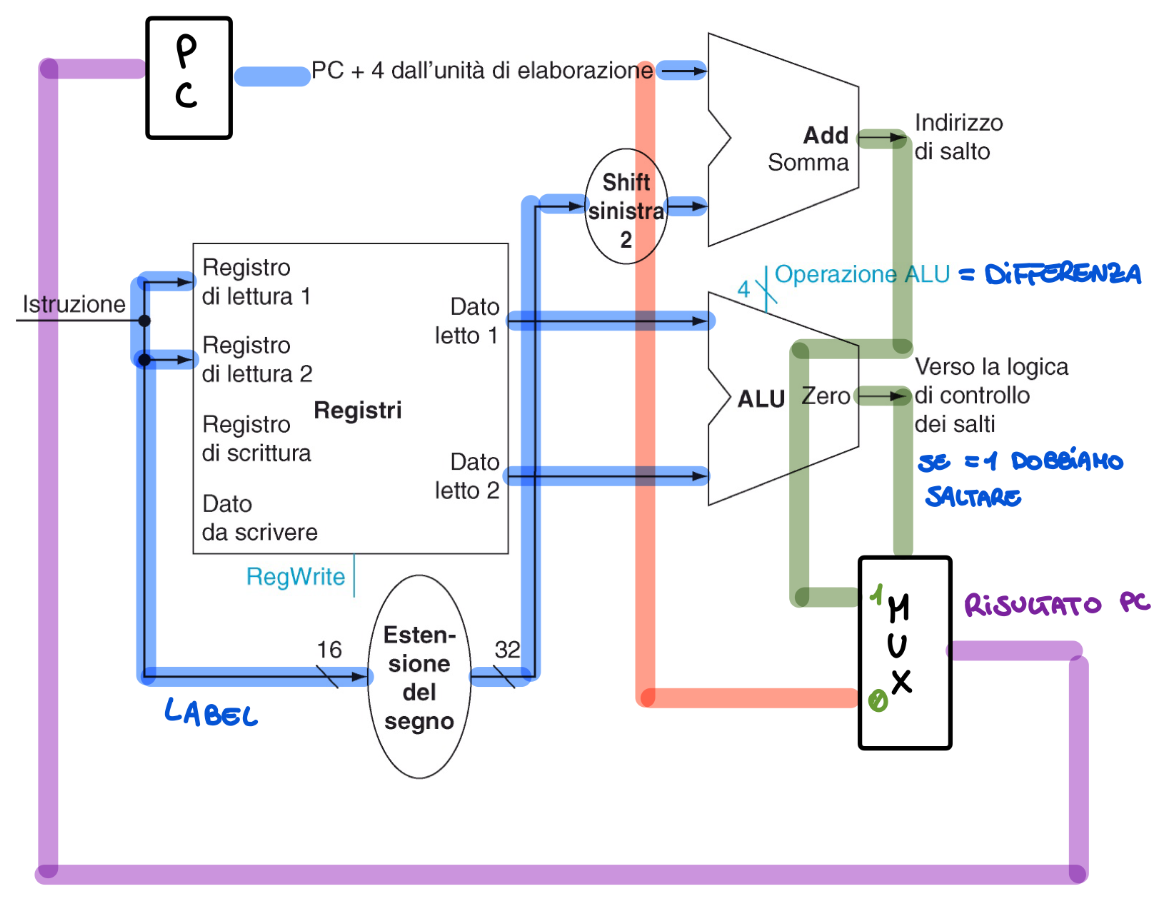
Quindi se nell’ALU otteniamo come risultato 0 nel segnale 0 andiamo semplicemente avanti all’istruzione PC + 4 mentre se vale 1 dobbiamo saltare al valore della label che seguendo le regole dette prima deve essere estesa nel segno fino a 32 bit, shiftata di 2 a sinistra ovvero moltiplicata per 4 e sommata all’indirizzo della nostra istruzione successiva quindi PC + 4, quindi tramite un MUX scegliamo il valore corretto e riportiamo il risultato all’interno del PC.
Mettendo insieme tutti i componenti otteniamo:
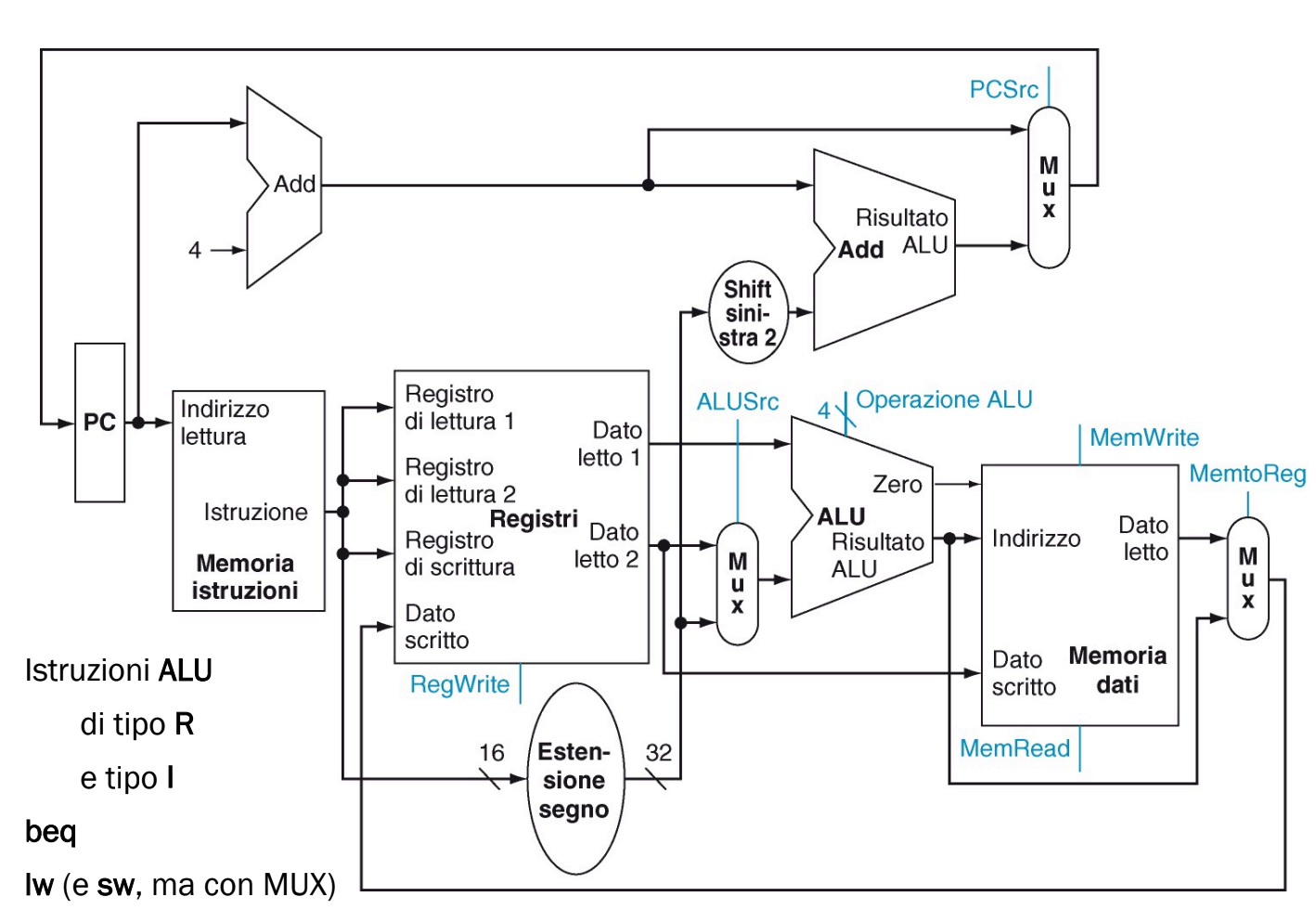
Linee attraversate per l’istruzione lw $s0, 0x00000004($29)
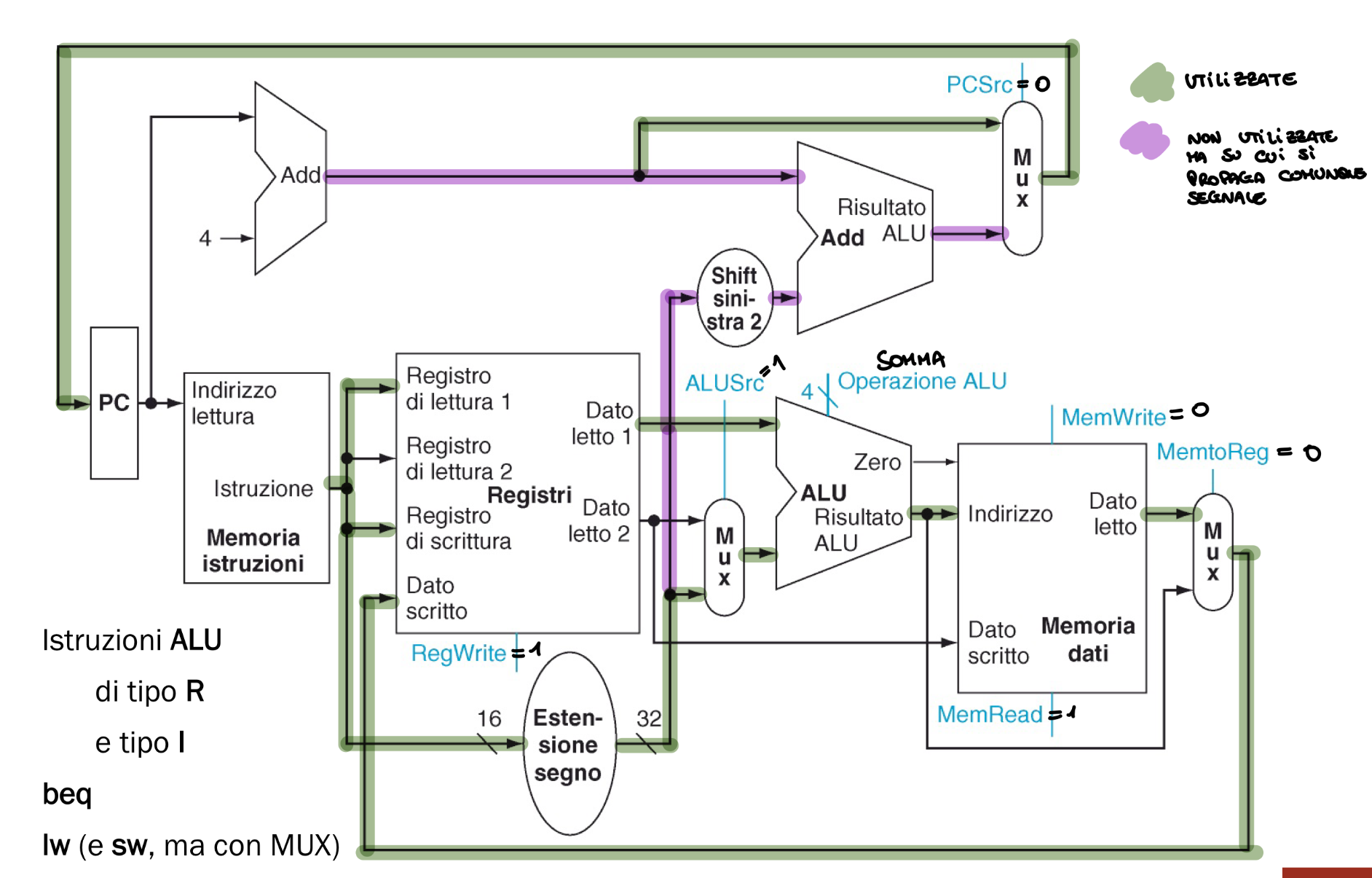
Adesso possiamo anche aggiungere i segnali di controllo gestiti dalla CU e la logica di salto
- Salto: Viene effettuato se nella porta AND passa sia il valore Zero della ALU quindi se il confronto ha avuto successo e se il segnale di controllo per il Jump vale 1, quindi se c’è un salto o no.
- I segnali di controllo fanno parte dei 32 bit dell’istruzione.
Segnali di controllo della ALU
| ALU control lines | Function |
|---|---|
| 0000 | AND |
| 0001 | OR |
| 0010 | add |
| 0110 | subtract |
| 0111 | set on less than |
| 1100 | NOR |
Formato delle Istruzioni e bit di controllo ALU
La logica di controllo per la ALU è implementata a cascata, questo comporta più livelli di decodifica e una circuteria più semplice. Quindi prima si prendono i 3 codici di selezione per ALUOp e poi a seconda dei casi viene considerato il campo funct nell’istruzione
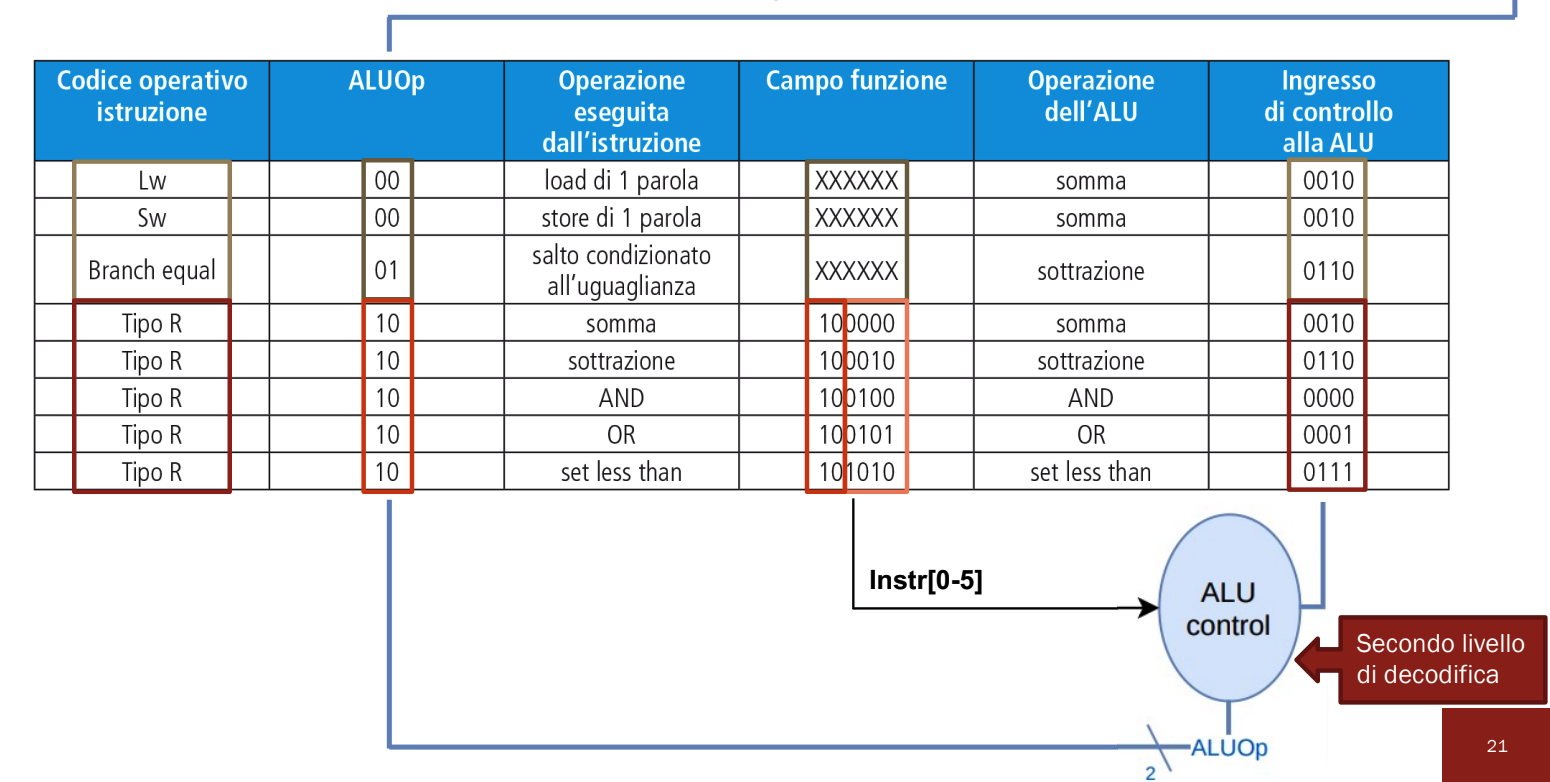
Il primo livello avviene nella CU che manda i primi due bit e abbiamo più casi:
- 00: Dobbiamo effettuare una somma, i successivi 4 bit saranno 0010 (lw, sw)
- 01: Dobbiamo effettuare una sottrazione, successivi 4 saranno 0110 (Salti Condizionati)
- Quindi per questi due casi sappiamo già che 4 bit successivi inserire, non abbiamo più “opzioni”
- 10: Dobbiamo generare i successivi 4 bit basandoci sui bit presenti in funct seguendo la tabella sopra
Più nello specifico guardo i bit in questo modo:
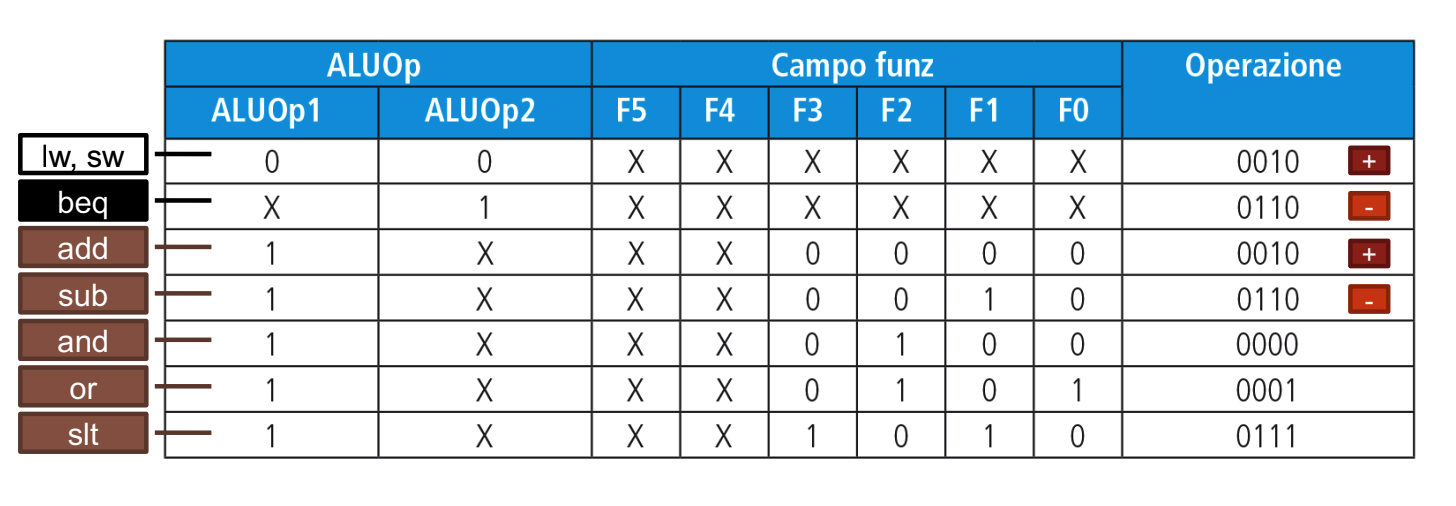
Dove la X indica i bit che non mi interessa guardare.
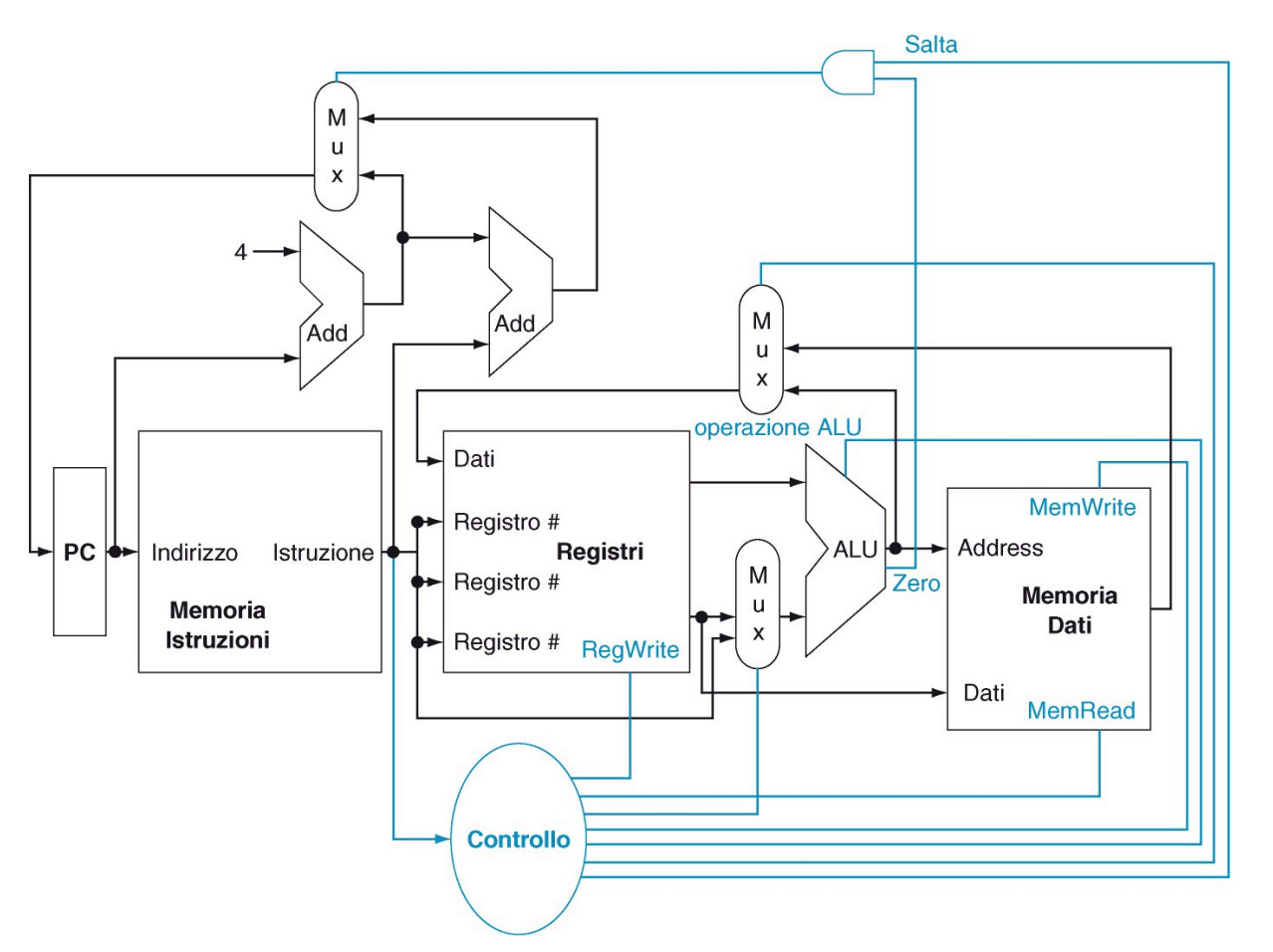
Datapath Completo
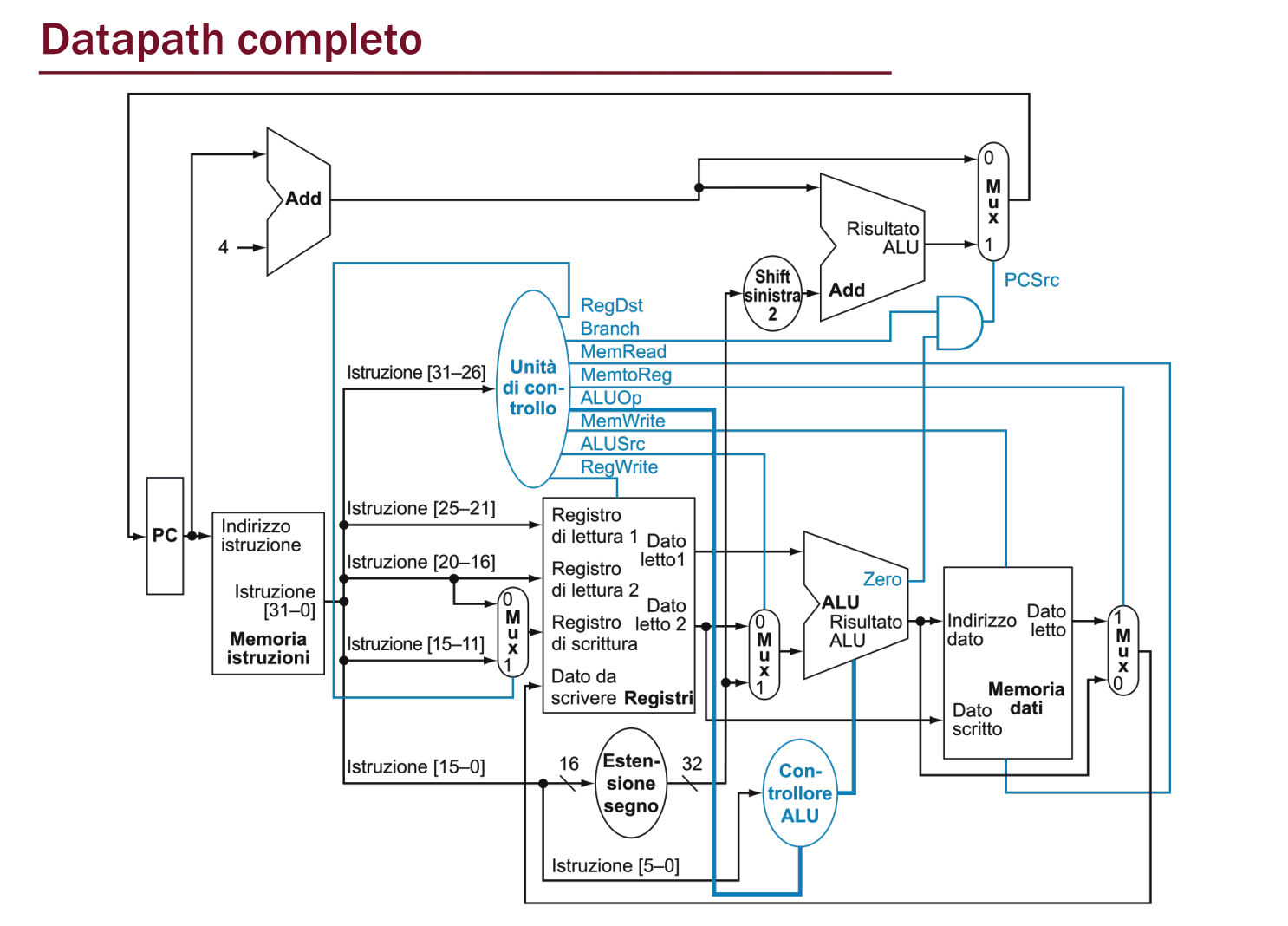
Segnali di Controllo nello specifico

Segnali della ALU (2)
Come abbiamo visto prima la ALU deve eseguire 3 tipi di comportamento:
- Se l’istruzione è di tipo R esegue l’operazione indicata in funct
- Se l’istruzione è lw, sw effettua una somma
- Se l’istruzione è un salto effettua una differenza E per codificare 3 comportamenti bastano 2 segnali dalla CU: ALUOp = 1 e ALUOp = 0

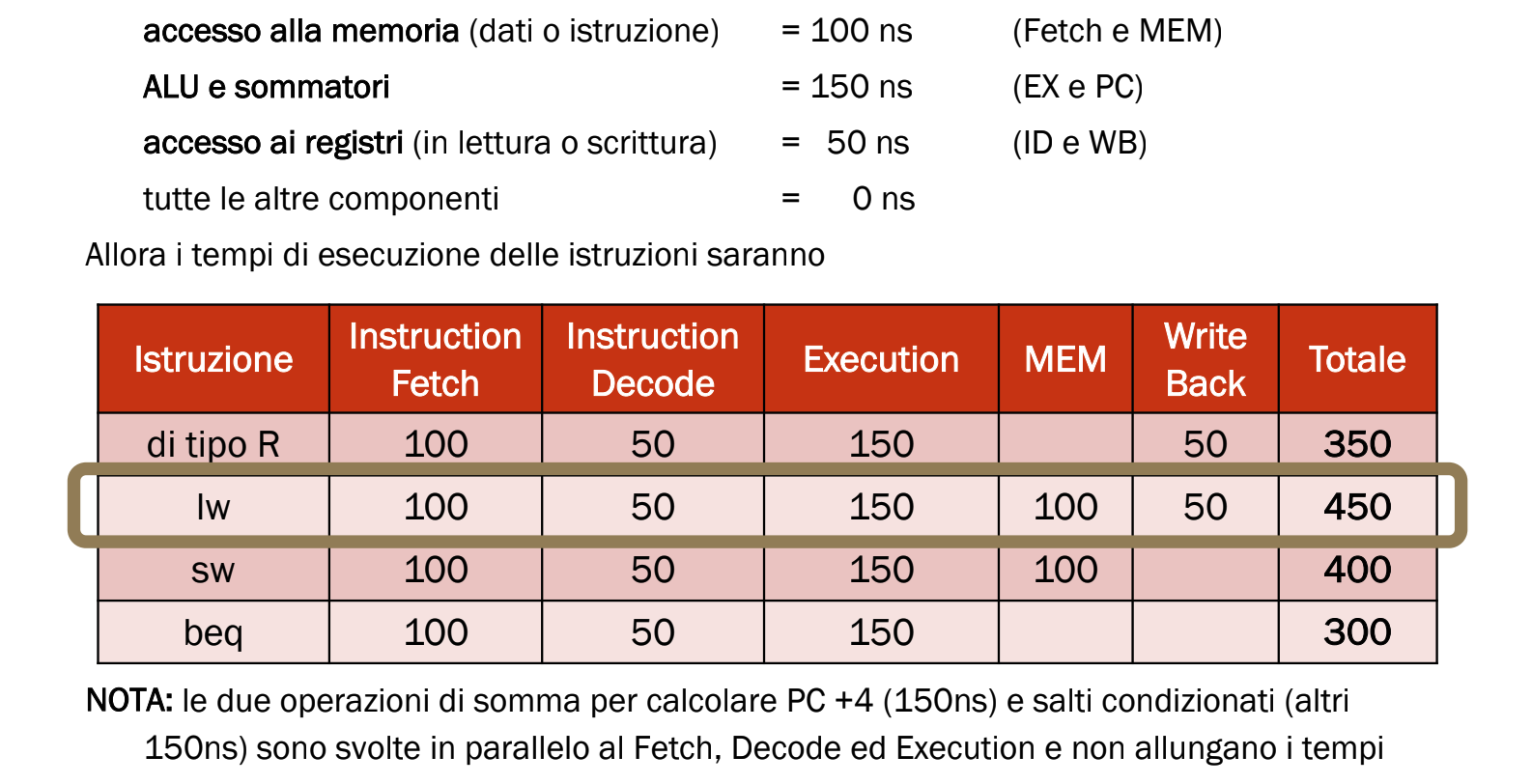
Tempi di Esecuzione
Se conosciamo i tempi di esecuzione di ogni componente allora possiamo calcolare il tempo necessario a svolgere ogni istruzione. È importante ricordare che il segnale si propaga in tutto il circuito in parallelo.
Esempio con tempi stabiliti
Aggiungere nuove istruzioni
Con delle piccole modifiche ai componenti già presenti possiamo aggiungere facilmente delle nuove istruzioni. Per ogni istruzione dobbiamo quindi:
- La sua codifica in bit
- Cosa fa
- Se abbiamo bisogno di nuovi componenti
- Dove passeranno le informazioni
- La tabella di verità dei segnali di controllo
- Calcolare se il tempo necessario è superiore alle altre istruzioni e quindi se abbiamo bisogno di prolungare il tempo totale.
Aggiungiamo l’istruzione di J
Come codifica scegliamo di dedicare i primi 6 bit alla tipologia di istruzione e i restanti 26 all’indirizzo di destinazione del salto, quindi:
- È un indirizzo assoluto
- Indica l’istruzione di destinazione e va quindi moltiplicato per 4 (shift di 2, andiamo a 28 bit)
- I restanti 4 bit li prendiamo dal PC + 4 tramite un OR
Come unità aggiuntive abbiamo bisogno di uno shift left* di 2 bit con un input da 26 e un MUX per scegliere il nuovo PC. Per i segnali di controllo impostiamo un segnale Jump a 1 e a 0 i RegWrite e MemWrite per evitare modifiche a registri e memoria. Per quanto riguarda il tempo, dobbiamo considerare il Fetch e in parallelo il tempo di calcolo del PC + 4, quindi prendiamo il massimo dei due tempi
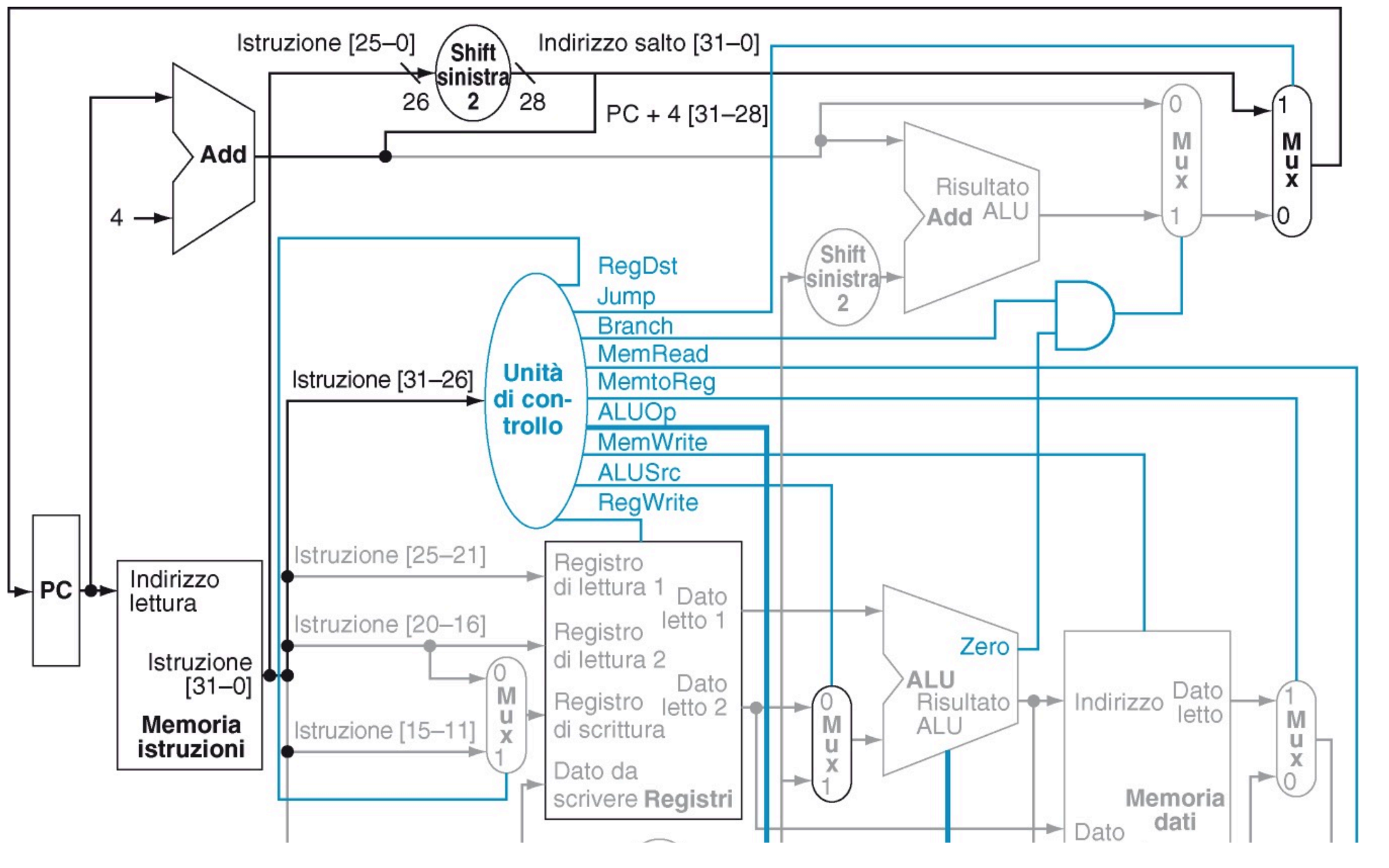
Con il collegamento dei due cavi stiamo effettuando l’OR. Con il secondo MUX quindi non prendiamo il valore in uscita da PC + 4 ma scegliamo il nostro calcolo appena effettuato.
Architettura Completa Modificata:
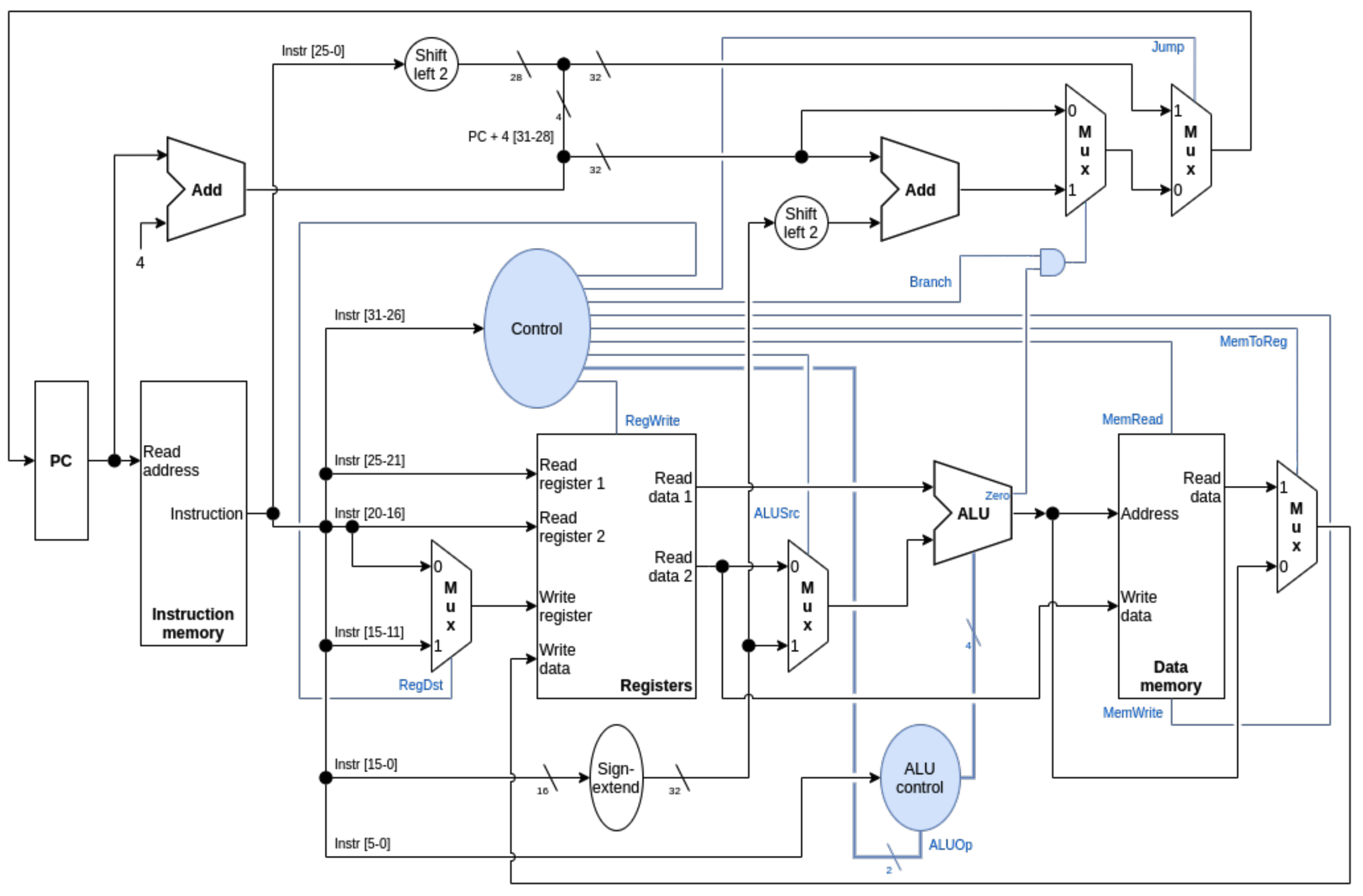
Istruzione JAL
La codifichiamo sempre come un’istruzione di tipo J e per il calcolo dell’indirizzo svolge le stesse operazioni del salto normale ma il risultato viene scritto nel registro $ra insieme ad un + 4.
Abbiamo bisogno degli stessi componenti del Jump ma più MUX per selezionare il valore PC +4 e altri per selezionare il numero del registro $ra
Abbiamo bisogno di un segnale Link per attivare i nuovi MUX
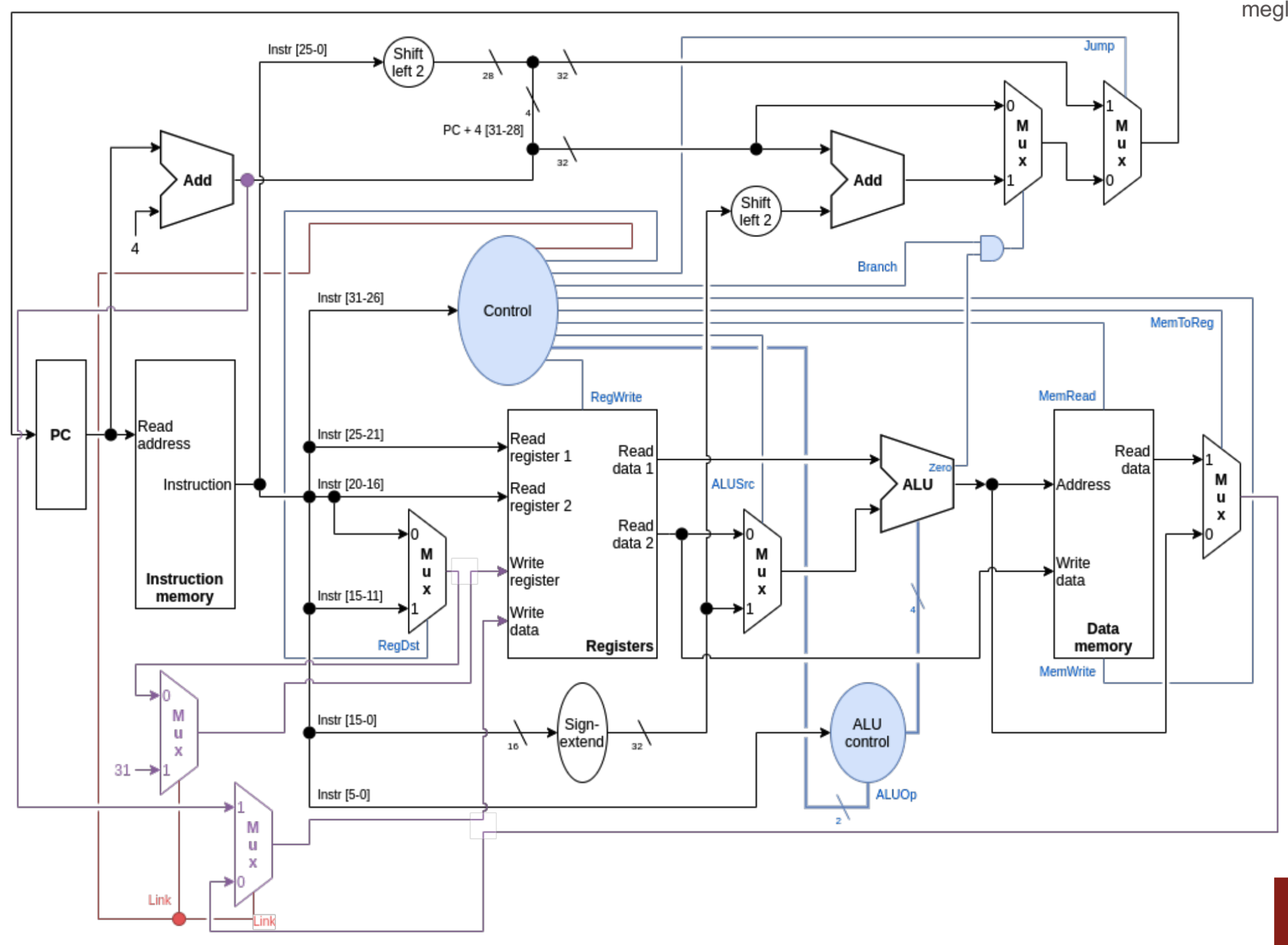
Quindi con il segnale link mandiamo nel registro di scrittura il valore 31 che equivale al registro $ra e scriviamo nel registro il valore di PC + 4 poi effettuiamo il Jump al valore calcolato con i 26 bit dell’istruzione, come abbiamo fatto anche prima per il jump normale.
Istruzione addi / la
Deve scrivere in un registro la somma data dai valori presenti in un registro e da una costante, abbiamo già tutti i componenti necessari ovvero l’estensione del segno della costante, un MUX per scegliere la costante come secondo addendo e un ALU. Non abbiamo bisogno di circuteria aggiuntiva
Istruzione jr
Trasferisce nel PC il contenuto del registro rs Abbiamo bisogno soltanto di un MUX in più per scegliere il PC dall’uscita del blocco registri e quindi anche di un segnali di controllo che chiamiamo JumpToReg che abilita il MUX per inserire in PC il valore del registro
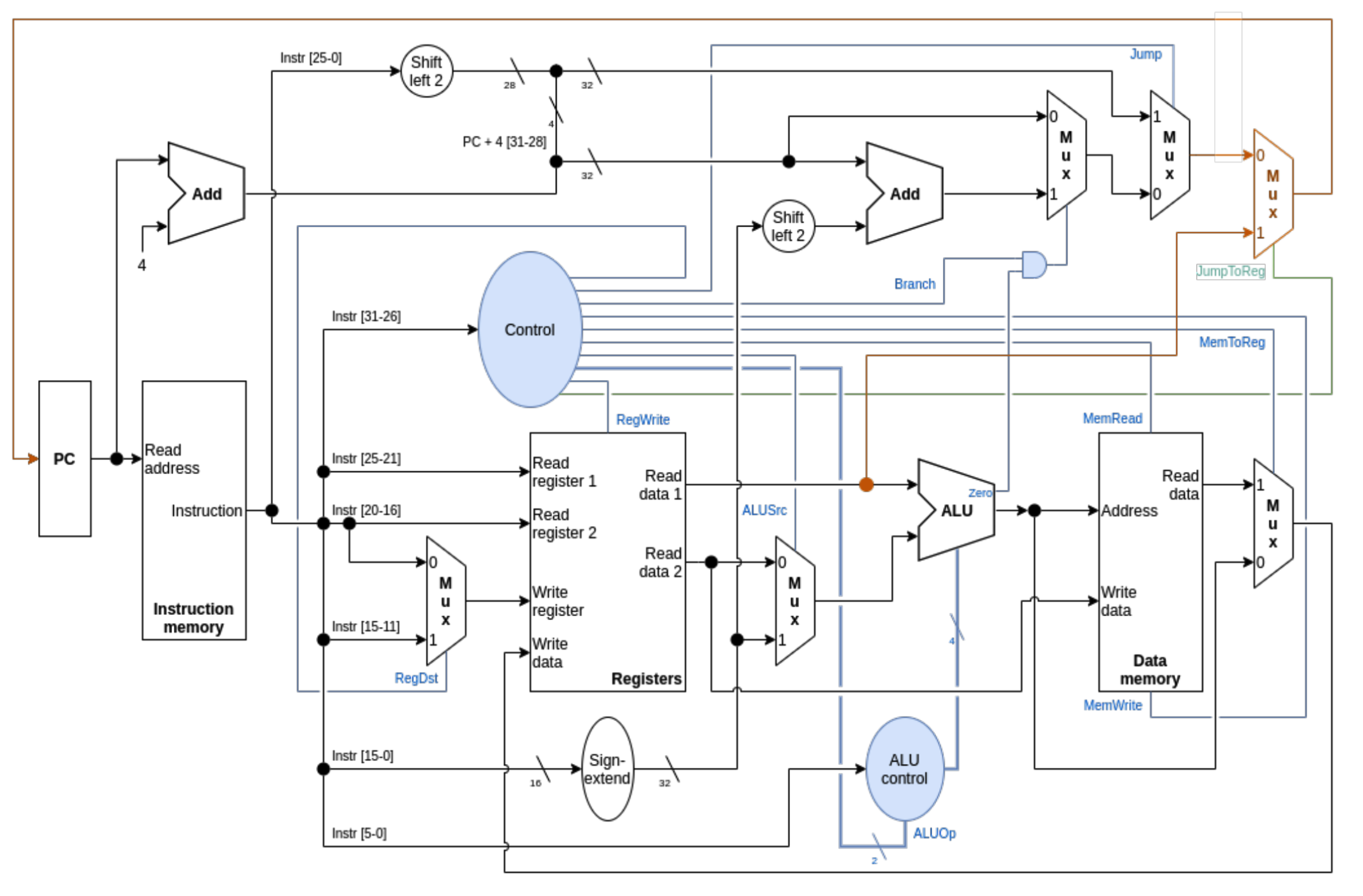
Quindi grazie al MUX saltiamo ogni calcolo effettuato precedentemente per saltare direttamente al valore presente nel registro dell’istruzione, se il segnale è impostato 1 ovviamente
Control Unit malfunzionante
Ricordiamo prima di tutto i casi dei vari segnali di controllo:
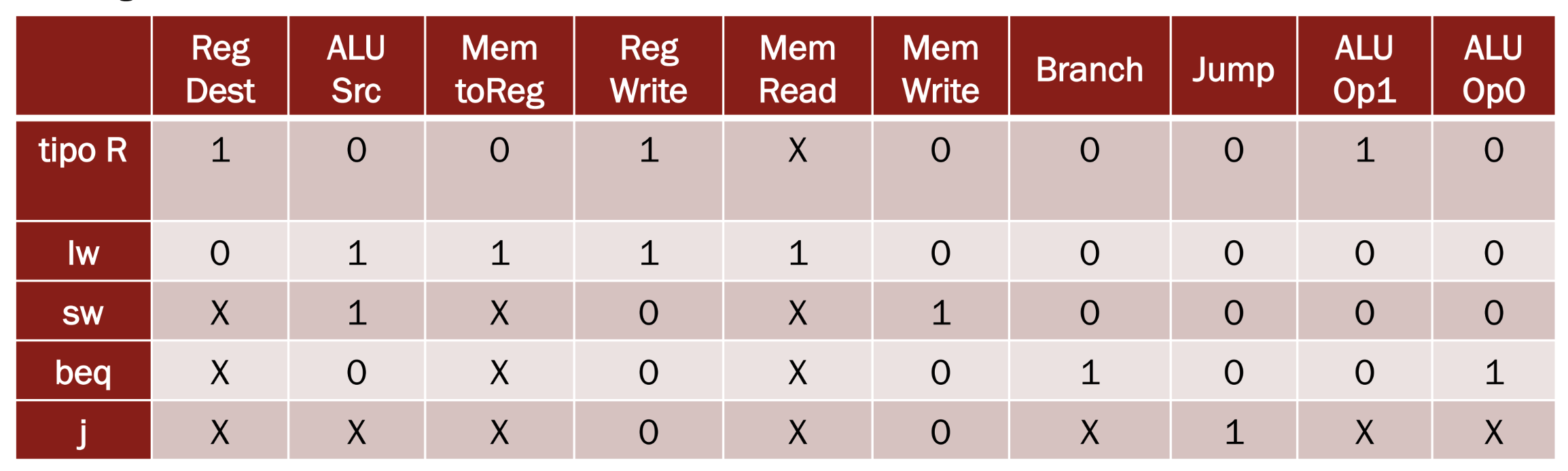
Quando la CU genera segnali errati dobbiamo individuare quale combinazione di segnali viene generata e quali istruzioni vengono influenzate, una volta individuate possiamo scrivere un programma MIPS che stabilisce se il malfunzionamento è presente o no.
Esempio 1 RegWrite impostato da Branch
Abbiamo il dubbio che il segnale RegWrite venga determinato insieme al segnale Branch, impostiamo due ipotesi:
- MemToReg = 1 solo per l’istruzione lw altrimenti vale 0 e non X
- RegDest = 1 solo per le istruzioni di tipo R altrimenti vale 0 e non X
Dobbiamo quindi individuare le istruzioni affette da questo problema e scrivere un programma che inserisca in un registro il valore 1 se funziona correttamente, 0 altrimenti
Vediamo quindi come risulta la tavola di verità
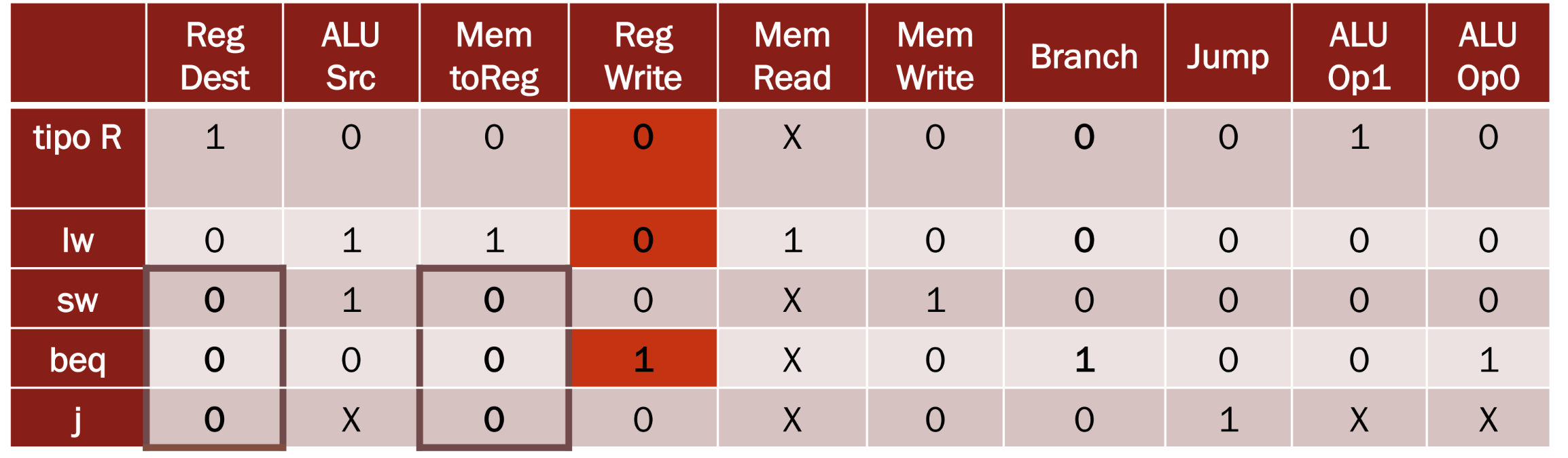
Quindi notiamo che:
- Le istruzioni di tipo R e lw lasceranno i registri di destinazioni invariati, quindi non funzioneranno
- L’istruzione di salto beq andrà a modificare involontariamente il valore dei registri dato che assumendo MemToReg = 0 andiamo a scrivere nei registri il valore del risultato dell’ALU, appunto perchè RegWrite è impostato a 1 involontariamente
Una soluzione molto banale per scrivere il programma MIPS è quella di avere in memoria il valore 1 e provare a caricarlo con una lw che dovrebbe essere non funzionante e quindi lasciare il registro invariato
Possiamo anche usare una somma sul registro dato che non dovrebbe funzionare
L’importante è cercare di cambiare il valore di un registro usando le istruzioni che dovrebbero essere malfunzionanti
Esempio 2 MemWrite opposto a RegWrite
In questo caso pensiamo che il problema sia che il controllo MemWrite è attivo se e solo se non è attivo il segnale RegWrite
Assumiamo che:
- MemToReg = 1 solo per la lw
- RegDest = 1 solo per le istruzioni di tipo R
Guardando la tavola di verità notiamo che abbiamo modificato valori soltanto nelle istruzioni beq e j che adesso scriveranno in memoria involontariamente mentre le altre istruzioni restano invariate.
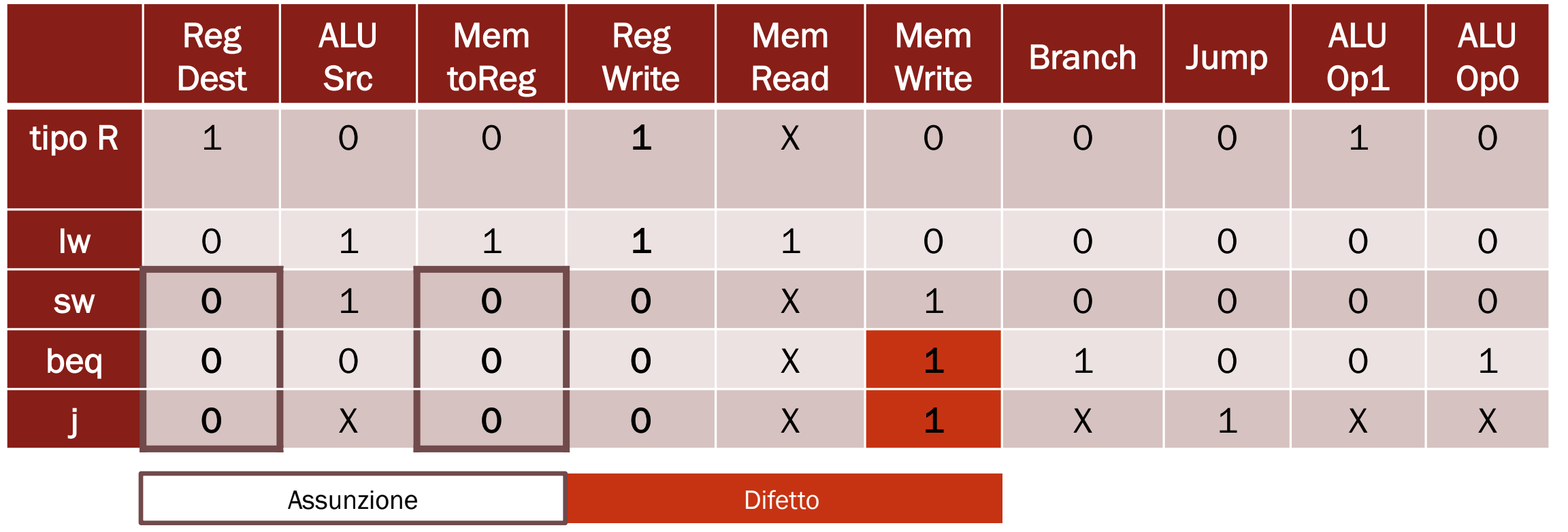
Quindi per trovare il malfunzionamento dobbiamo modificare un registro utilizzando i salti.
Utilizziamo l’istruzione beq, questa istruzione se malfunzionante scriverà all’indirizzo di memoria calcolato dalla ALU, quindi la differenza tra i due registri sorgente, il valore presente nel secondo registro sorgente dato che MemWrite = 1.
move $s0, $zero
sw $s0, 0
li $s1, 1
beq $s1, $s1, On
On:
lw $s0, 0Cosa fa:
- Impostiamo $s0 = 0
- Scriviamo il valore 0 all’indirizzo di memoria 0
- Impostiamo $s1 = 1
- Facciamo un salto “inutile” ma se l’istruzione è malfunzionante avrà salvato all’indirizzo di memoria 0, cioè la differenza tra $s1 e $s1, il valore contenuto nel secondo registro sorgente $s1 che contiene 1
- Quindi con l’ultima istruzione carichiamo nel registro il valore presente all’indirizzo di memoria 0 che se rimasto invariato a 0 indica il corretto funzionamento della CU, se cambiato in 1 indica la presenza di errori.
Pipeline e Parallelismo
Fino ad adesso abbiamo diviso l’esecuzione di un’istruzione in 3 fasi: Fetch, Decode e Execute, possiamo però individuare altre due fasi all’interno della Execute, ovvero quella di accesso alla memoria (Memory Access) e la scrittura del risultato dell’ALU o del dato letto in memoria all’interno del registro di destinazione (Write Back).
Adesso quindi dividiamo le istruzioni in queste 5 fasi che avvengono ciascuna una singola volta all’interno di un ciclo di clock ed è anche necessario che ciascuna di queste venga eseguita una alla volta.
Possiamo quindi rendere più efficiente l’architettura MIPS scomponendo un’istruzione in una sorta di catena di montaggio (Pipeline) dove ogni fase svolge il suo compito e passa il risultato alla fase successiva procedendo però ad iniziare anche l’elaborazione dell’istruzione successiva.
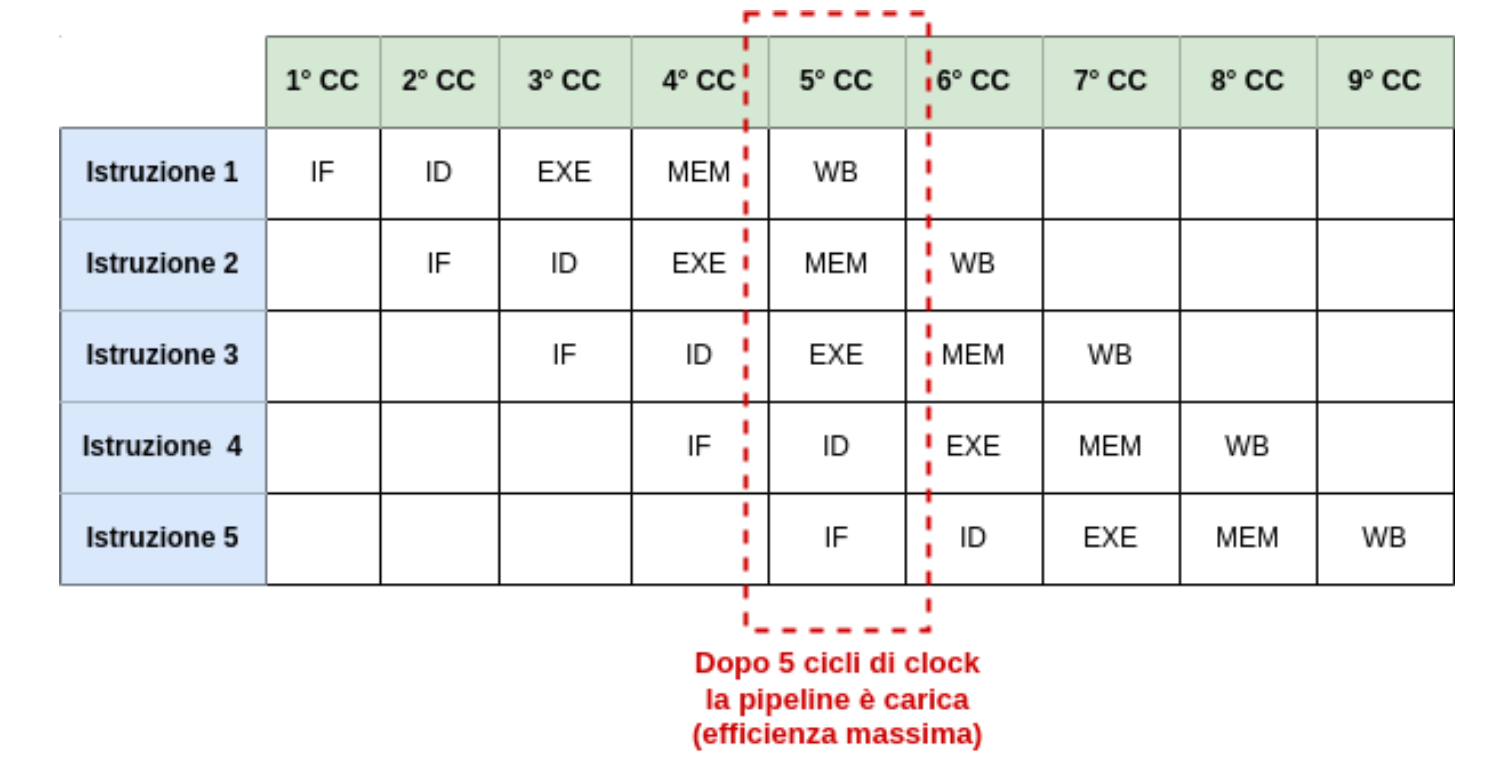
Quindi a 5 istruzioni eseguite contemporaneamente avremo riempito la nostra Pipeline dato che ogni fase deve essere eseguita esclusivamente quindi una fase diversa per volta. Questo ci permette di ridurre il periodo di clock dalla durata dell’istruzione più lenta alla durata della fase più lenta.
Infatti nel caso in cui ogni fase impieghi lo stesso tempo avremo quintuplicato la velocità
Facciamo un esempio
Impostiamo i seguenti valori come tempi delle 5 fasi:
- Instruction Fetch: 200ps
- Instruction Decode: 100ps
- Instruction Execute: 200ps
- Memory Access: 200ps
- Write Back: 100ps
Prendiamo come esempio l’istruzione di load word che richiede tutte e 5 le fasi, quindi avremmo bisogno di un periodo di clock di 800ps, ovvero la somma di tutte le fasi.
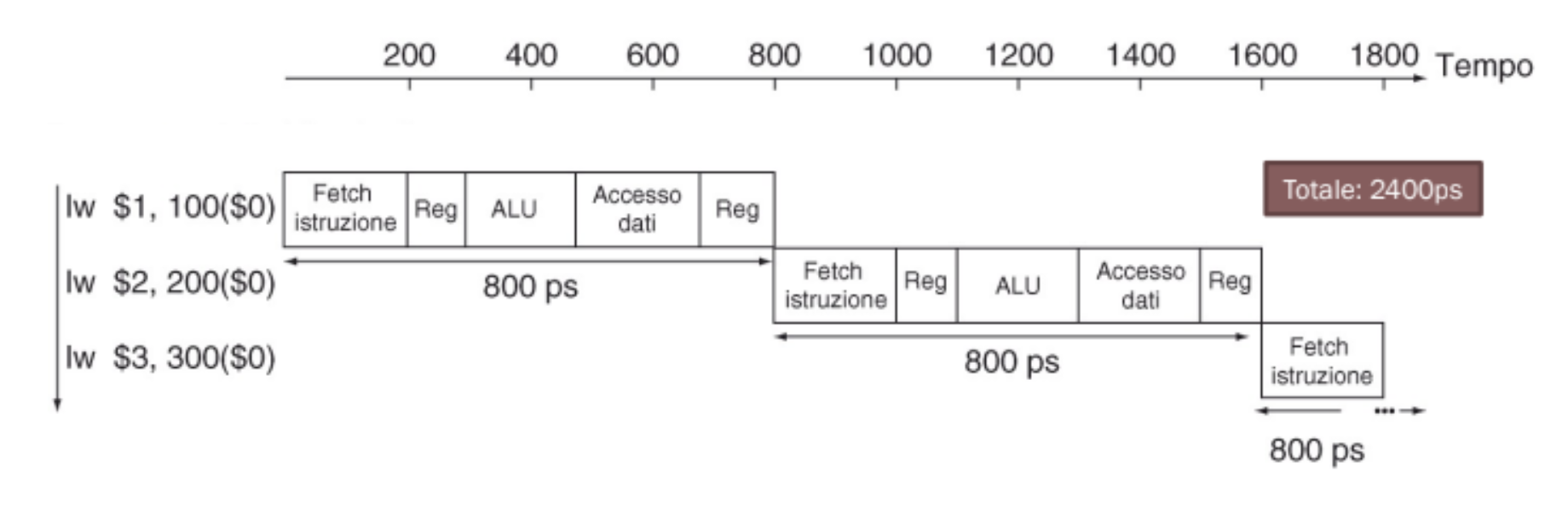
Possiamo invece utilizzare la pipeline per diminuire il tempo di clock a 200ps ovvero il tempo necessario a completare la fase più lenta.
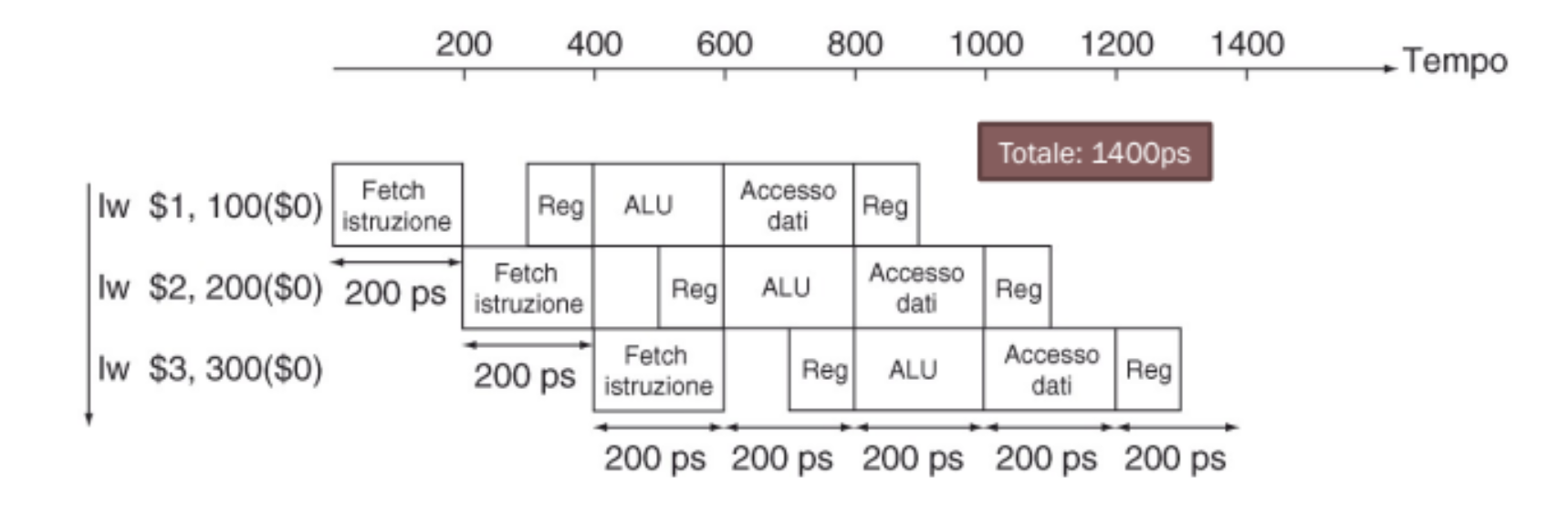
In questo modo notiamo anche come abbiamo diminuito di 1000ps il tempo totale di esecuzione
Come facciamo però a introdurre la pipeline nell’architettura?
Modifiche all’Architettura
Per rendere l’esecuzione di ogni fase indipendente da un’altra dobbiamo inserire dei banchi di registri tra di esse che si occuperanno di memorizzare temporaneamente tutti i dati e segnali di controllo processati da ogni fase durante l’ultimo ciclo di clock.
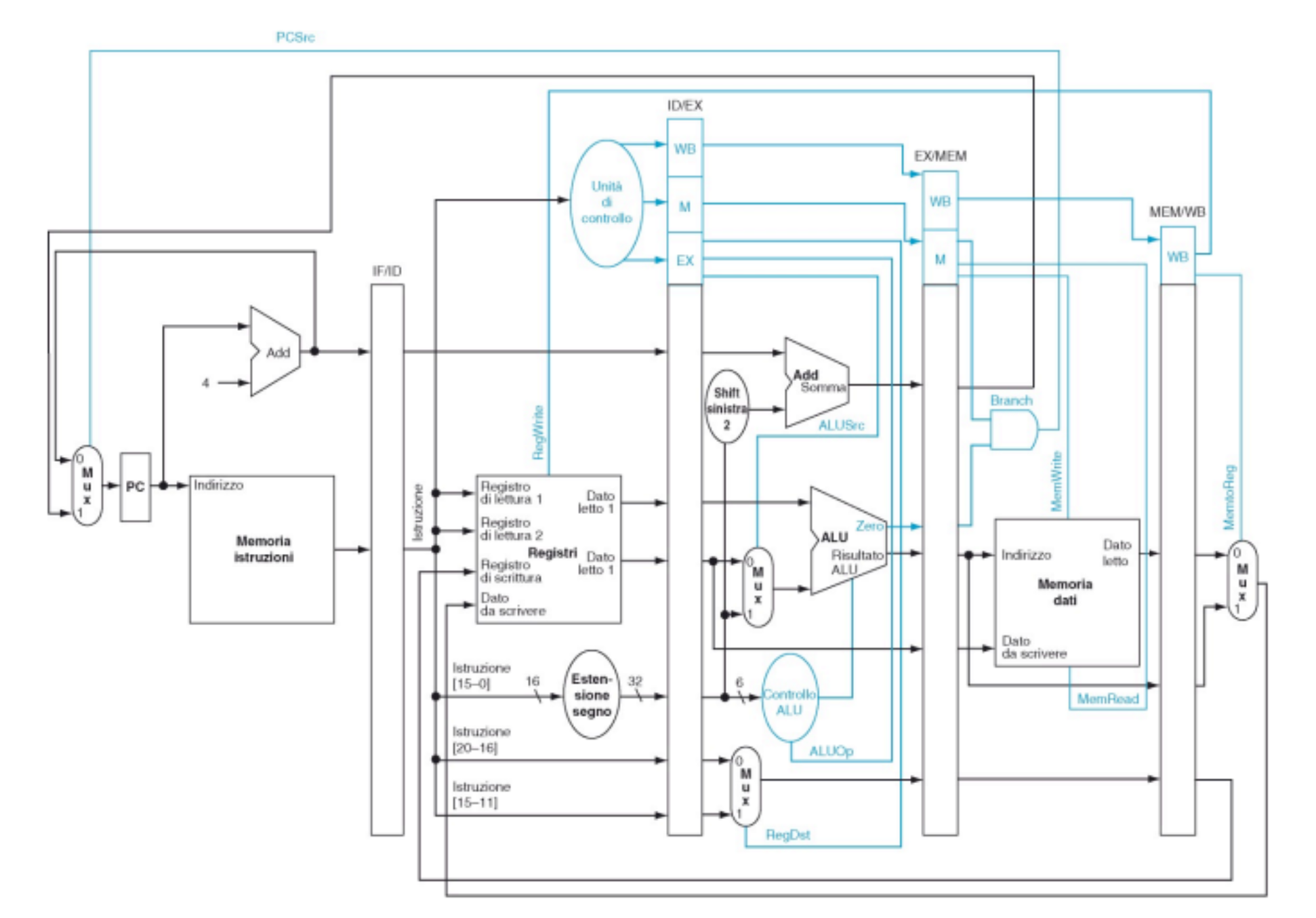
Questi sono i 4 banchi di registri aggiunti tra una fase e un’altra:
- IF / ID
- ID / EXE
- EX / MEM
- MEM / WB
Nei banchi sono contenuti i registri e i dati utilizzati per tale istruzione mentre nei “blocchetti” blu indicati sopra sono contenuti i segnali di controllo dell’istruzione necessari allo svolgimento di quella fase.
Lettura e Scrittura dal Register File
Dato che sia la fase di Decode e WriteBack lavorano sul Register File ed entrambe impiegano un tempo inferiore e uguale possiamo eseguire entrambe le fasi nello stesso ciclo di clock. Infatti se le altre fasi impiegano 200ps e queste soltanto 100ps possiamo eseguire ad esempio la scrittura durante il Rising Edge del Clock e la lettura sul Register File durante il Falling Edge
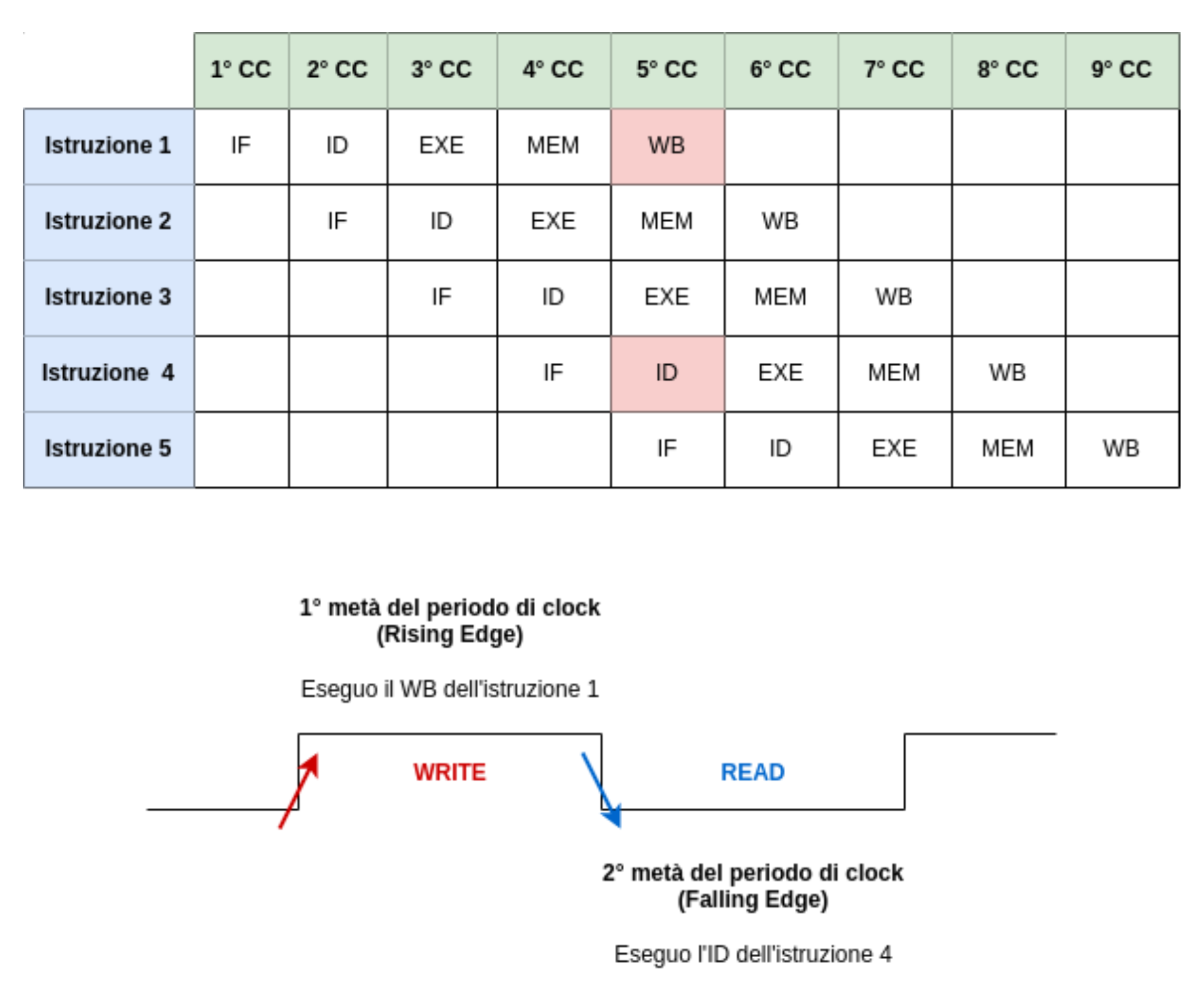
Criticità nell’esecuzione
Questa nuova architettura può comportare alcune criticità. Immaginiamo il caso in cui l’istruzione 1 modifichi il valore di un registro e l’istruzione 2 legga il valore di questo registro, quindi per via della suddivisione in fasi durante il decode dell’istruzione 2 non è ancora stata eseguita la fase di WriteBack della prima istruzione e quindi il registro non è ancora stato modificato.
Abbiamo 3 diversi dipi di criticità (hazard):
- Structural Hazard: Risorse hardware insufficienti
- Data Hazard: Il dato richiesto non è ancora stato aggiornato
- Control Hazard: L’esecuzione di un salto modifica il flusso delle istruzioni
Data Hazard e Forwarding
Prendendo il caso di prima possiamo analizzare il caso di queste due istruzioni:
addi $s0, $s1, 5
sub $s2, $s0, $t0Guardiamo cosa succede sulla pipeline:
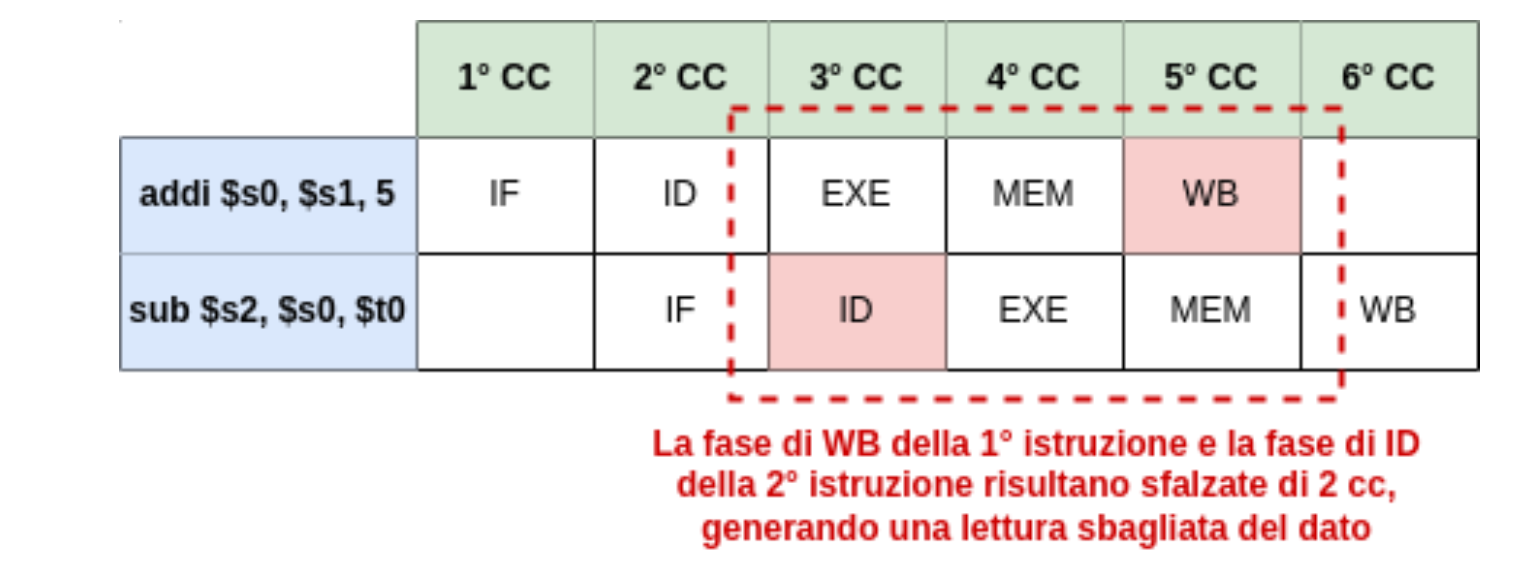
Quindi la seconda istruzione leggerà il dato nel registro $s0 quando ancora la prima istruzione non ha aggiornato il registro. Per risolvere questo problema dobbiamo quindi allineare le fasi di WriteBack e Instruction Decode inserendo degli “stalli”.
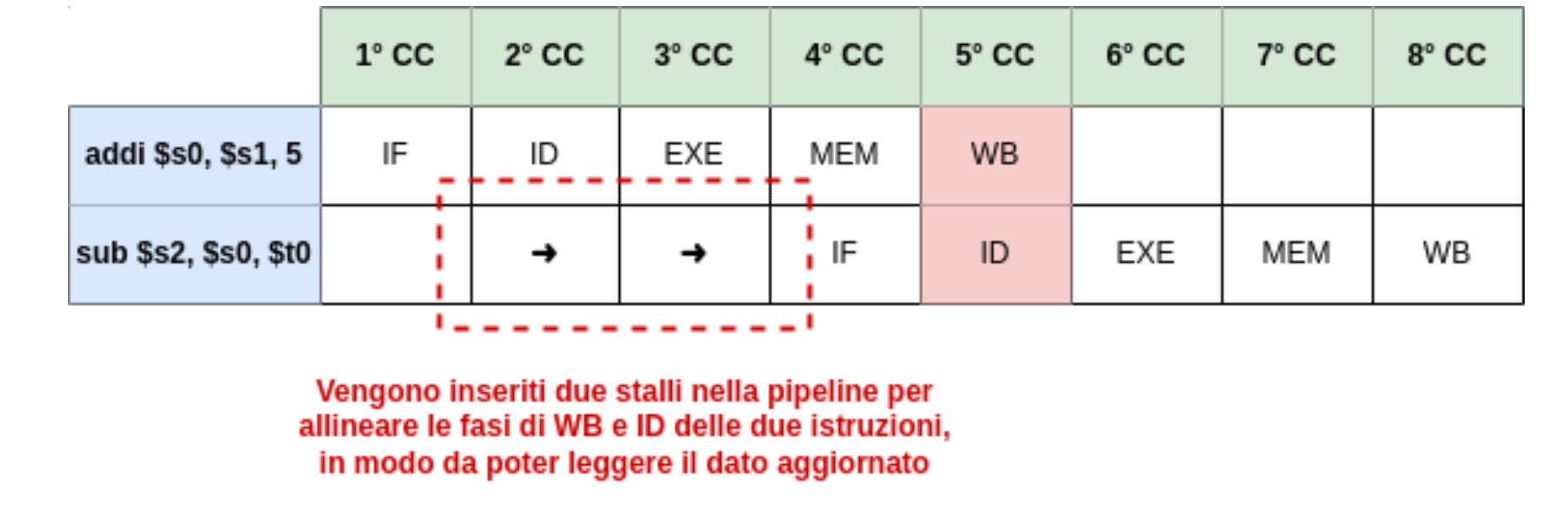
Possiamo creare questa sovrapposizione perché come abbiamo visto la scrittura nei registri avviene durante la prima metà del clock mentre la lettura durante la seconda.
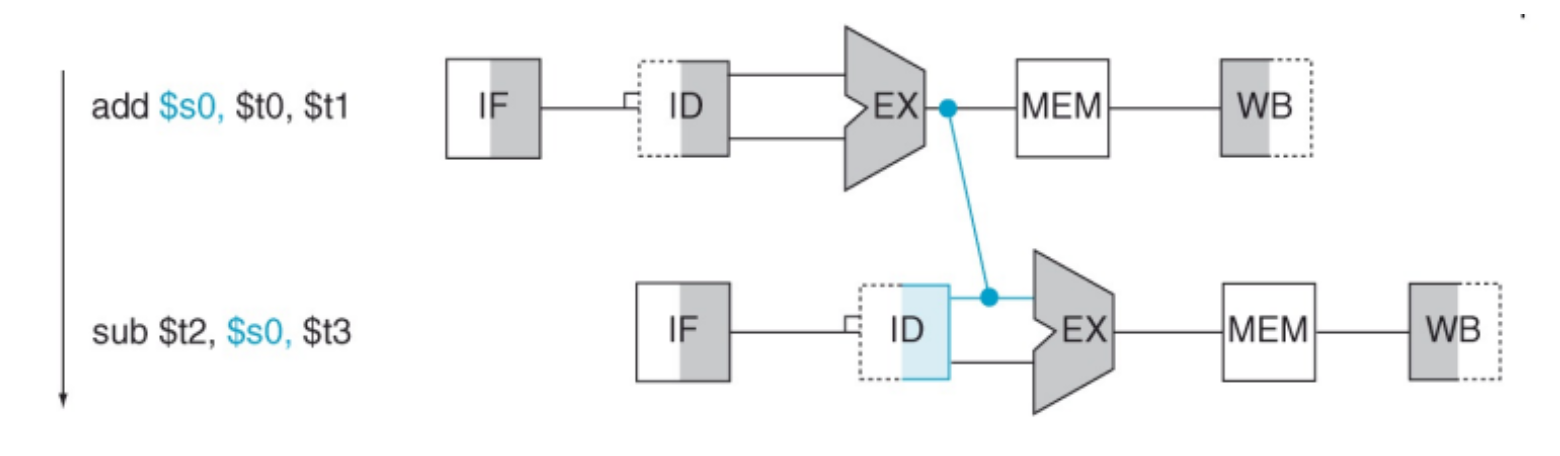
Però possiamo osservare che il valore giusto lo abbiamo dopo la fase di EXE della prima istruzione, potremmo quindi usare una “scorciatoia” che sovrascrive il dato errato senza aspettare la fase di Write Back. Questo ci da la possibilità di non dover inserire gli stalli, e questa tecnica prende il nome di forwarding (o Bypassing).
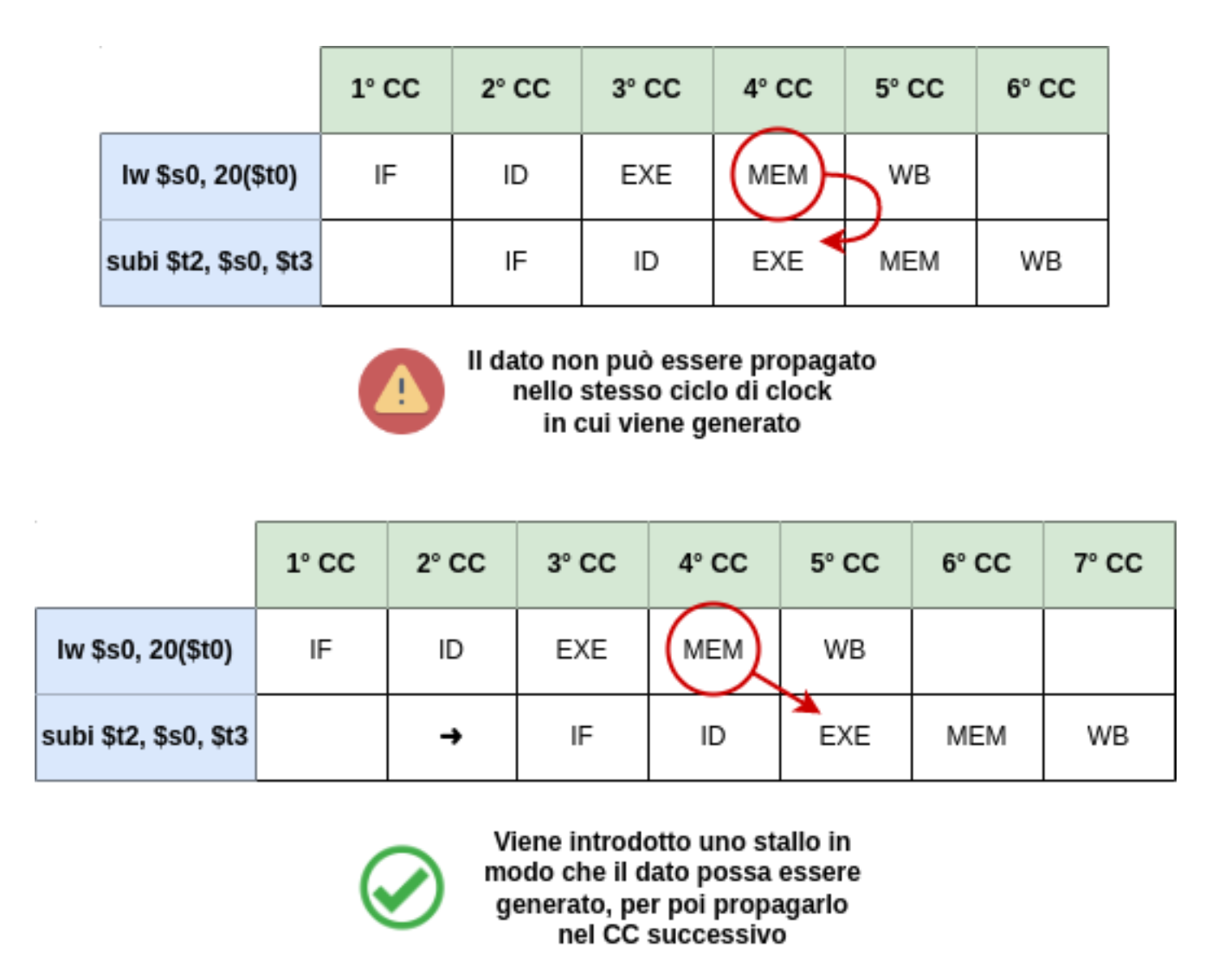
Alcune volte però è comunque necessario aggiungere degli stalli, vediamo il caso delle istruzioni:
lw $s0, 20($t1)
sub $t2, $s0, $t3In questo caso il valore richiesto in $s0 viene generato durante la fase MEM per via della lw, si creerebbe la situazione dove il dato viene generato nello stesso momento in cui è richiesto dall’istruzione successiva, possiamo utilizzare il forwarding soltanto se inseriamo uno stallo per non effettuare le fasi nello stesso momento.
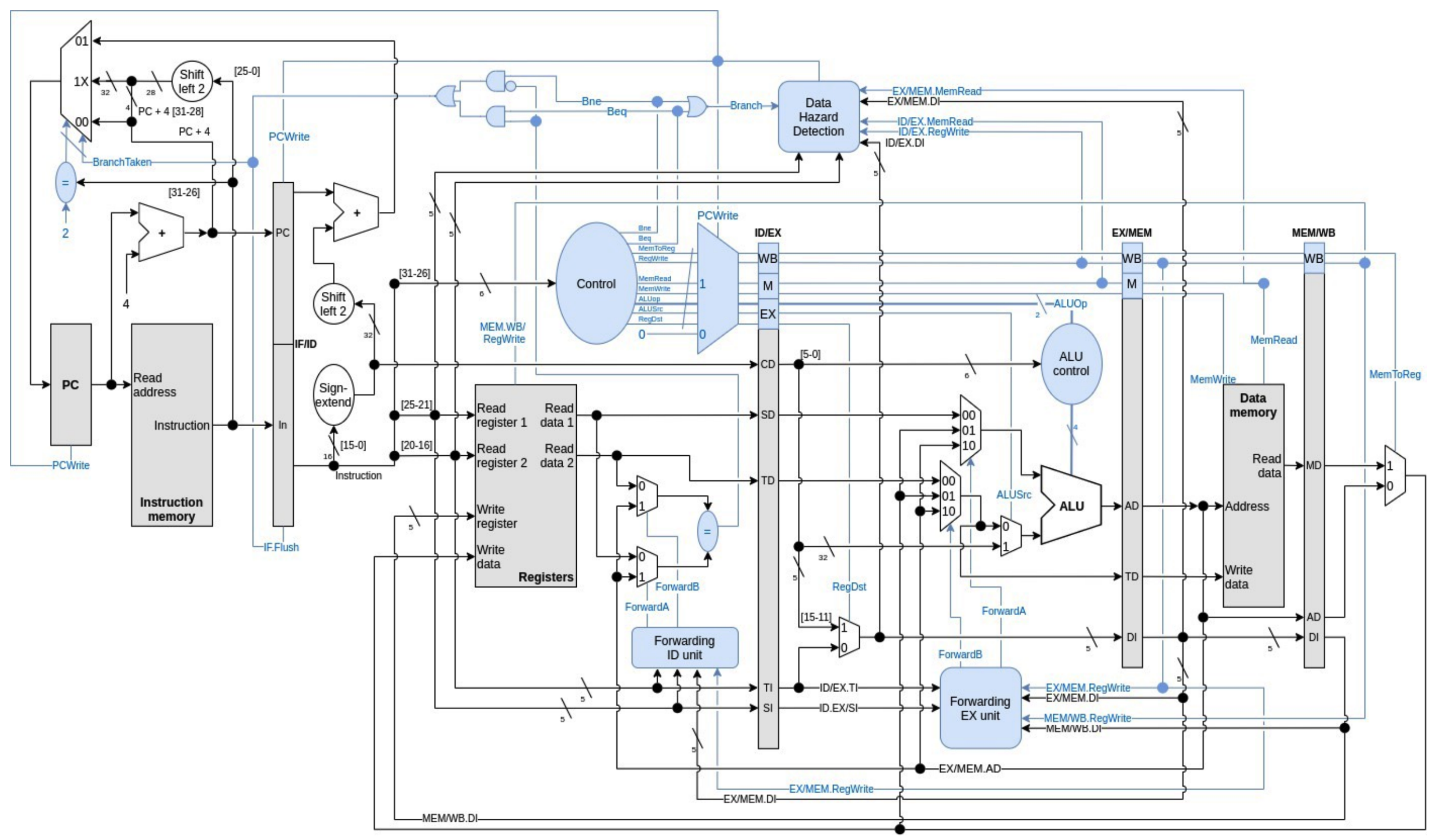
Per realizzare il forwarding dobbiamo inserire un nuova unità di controllo che sceglierà da quale fase prendere il dato invece di aspettare la lettura dai registri, i controlli che farà sono i seguenti:
L’unità attiverà un forwarding per la fase EXE solo se si ha RegWrite == 1, EX / MEM.rd != 0 e MemRead == 0 e poi:
- ID / EX.rs == EX / MEM.rd oppure ID / EX.rt == EX / MEM.rd attiverà un forwarding sull’istruzione precedente
- ID / EX.rs == MEM / WB.rd oppure ID / EX.rt == MEM / WB.rd attiverà un forwarding sulla seconda istruzione precedente
Con queste condizioni andiamo a controllare se l’istruzione presente nei banchi EXE / MEM scrive un dato su un registro e poi controlliamo se un registro sorgente dell’istruzione successiva contenuta in ID / EXE è uguale al registro destinazione dell’istruzione precedente caricata nei banchi EXE / MEM. Ragionamento analogo per il forwarding su due istruzioni indietro nei banchi EXE / MEM
Perché controlliamo
rd != 0?Più avanti sarà necessario utilizzare delle istruzioni particolari chiamate nop in cui si “scrive” sul registro $s0, queste svolgono la seguente istruzione:
sll $zero, $zero, 0
Modifiche all’architettura Dobbiamo quindi sostituire il valore letto dal blocco registri con quello prodotto dall’istruzione precendente in fase di EXE o nel caso di due istruzioni precedenti in fase di MEM.
Per implementare queste modifiche a livello hardware è necessario aggiungere due MUX uno a testa sugli ingressi dell’ALU che selezionino tre casi:
- Nessun Forwarding: Il valore proviene dal banco ID / EXE
- Forwarding dall’istruzione precedente: Il valore proviene dal banco EXE / MEM
- Forwarding dalla seconda istruzione precedente: Il valore proviene dal banco MEM / WB E questi MUX verranno controllati da una nuova unità funzionale chiamata Unità di Propagazione, nello specifico funzionerà nel seguente modo:
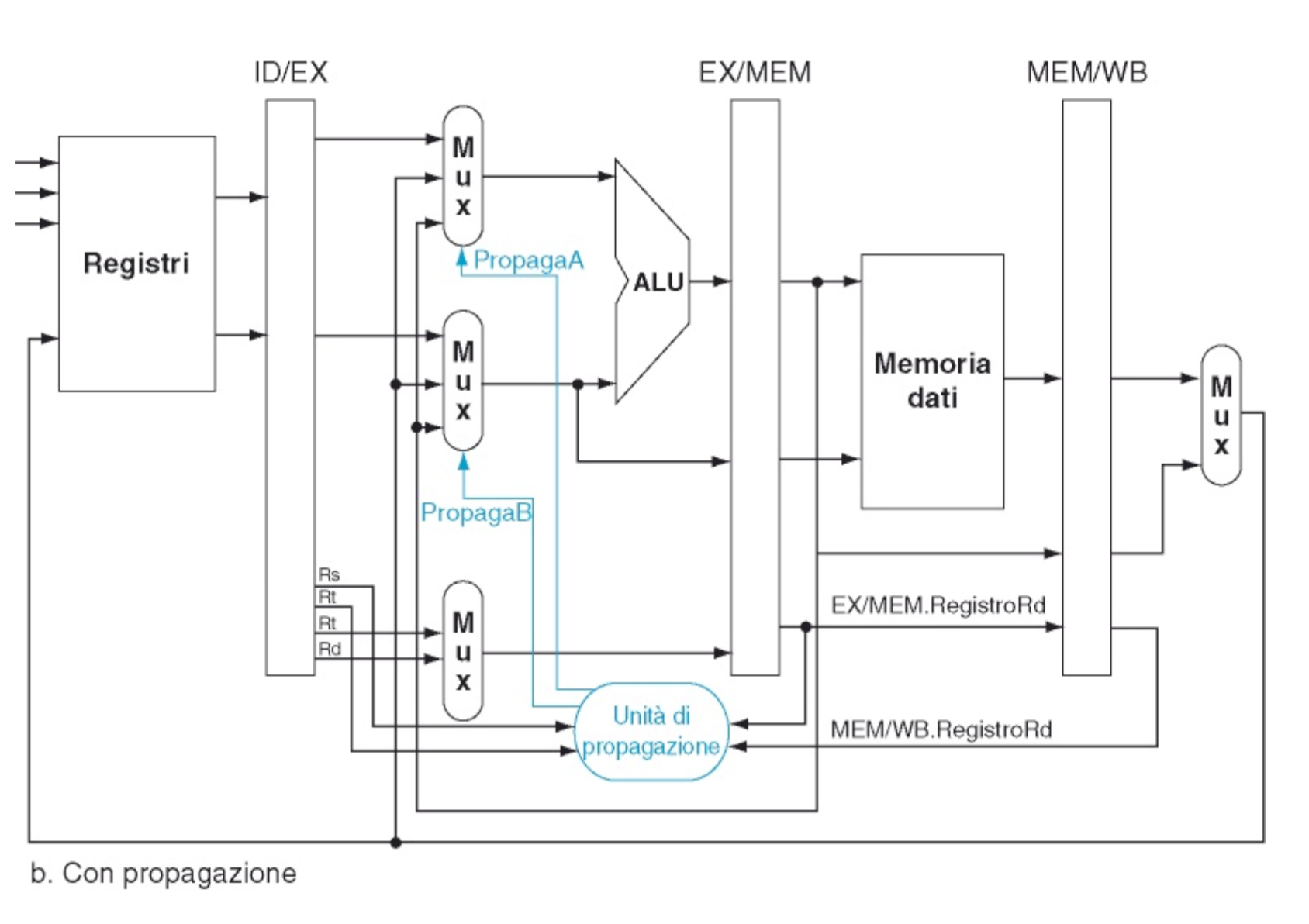
Quindi l’unità di propagazione controlla i registri rs / rt della fase ID / EX con il registro rd della fase EX / MEM, se questi sono uguali genera dei segnali di controllo, PropagaA o PropagaB, i segnali funzionano nel seguente modo:
| Controllo Multiplexer | Sorgente | Funzionamento |
|---|---|---|
| PropagaA = 00 | ID / EXE | Il primo operando della ALU (rs) proviene dal banco dei registi (no forwarding) |
| PropagaA = 10 | EX / MEM | Il primo operando della ALU (rs) viene preso dal risultato della ALU nel ciclo di clock precedente cioè nella fase EX / MEM |
| PropagaA = 01 | MEM / WB | Il primo operando della ALU (rs) viene preso dalla memoria o dalla ALU di due cicli precedenti ovvero dalla fase MEM / WB |
| PropagaB = 00 | ID / EXE | Il secondo operando della ALU (rt) proviene dal banco dei registri (no forwarding) |
| PropagaB = 10 | EX / MEM | Il secondo operando della ALU (rt) viene preso dal risultato della ALU del clock precedente dalla fase EX / MEM |
| PropagaB = 01 | MEM / WB | Il secondo operando della ALU proviene dalla fase MEM / WB di due clock precedenti, dalla memoria o dalla ALU |
Altri tipi di forwarding
È possibile realizzare altri tipi di forwarding:
- Nella fase ID, ma è necessario soltanto se l’istruzione
beqviene anticipata in ID, lo vedremo più avanti- Nella fase MEM, necessario se un’istruzione di load word è seguita da un’istruzione di store word, infatti se sw è preceduta da un’istruzione di tipo R avviene il forwarding in EXE appena visto
Realizzare il forwarding in MEM (lw / sw)
Come detto prima il forwarding in fase di MEM è necessario quando abbiamo una dopo l’altra le istruzioni lw e sw, queste vengono usate in questo ordine quando abbiamo bisogno di spostare un valore da una locazione della memoria in un’altra. Cosa succede nella pipeline durante l’esecuzione?
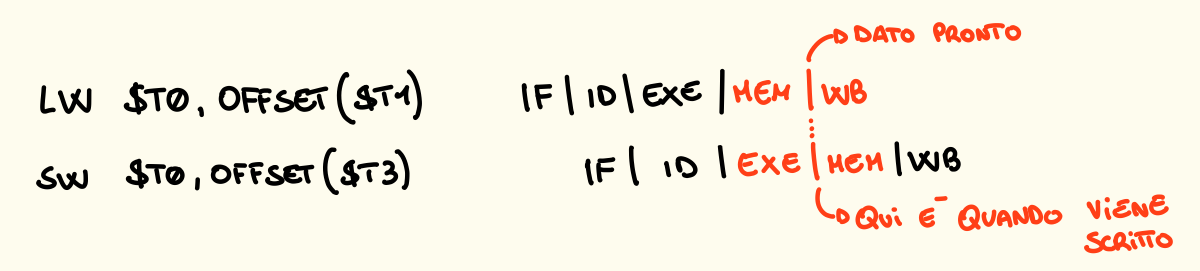
È necessario quindi aggiungere un MUX sull’ingresso del dato da scrivere in memoria, un ingresso prederà il valore normalmente dal banco della pipeline EX / MEM mentre un altro lo prenderà dal banco della fase MEM / WB dell’istruzione precedente.
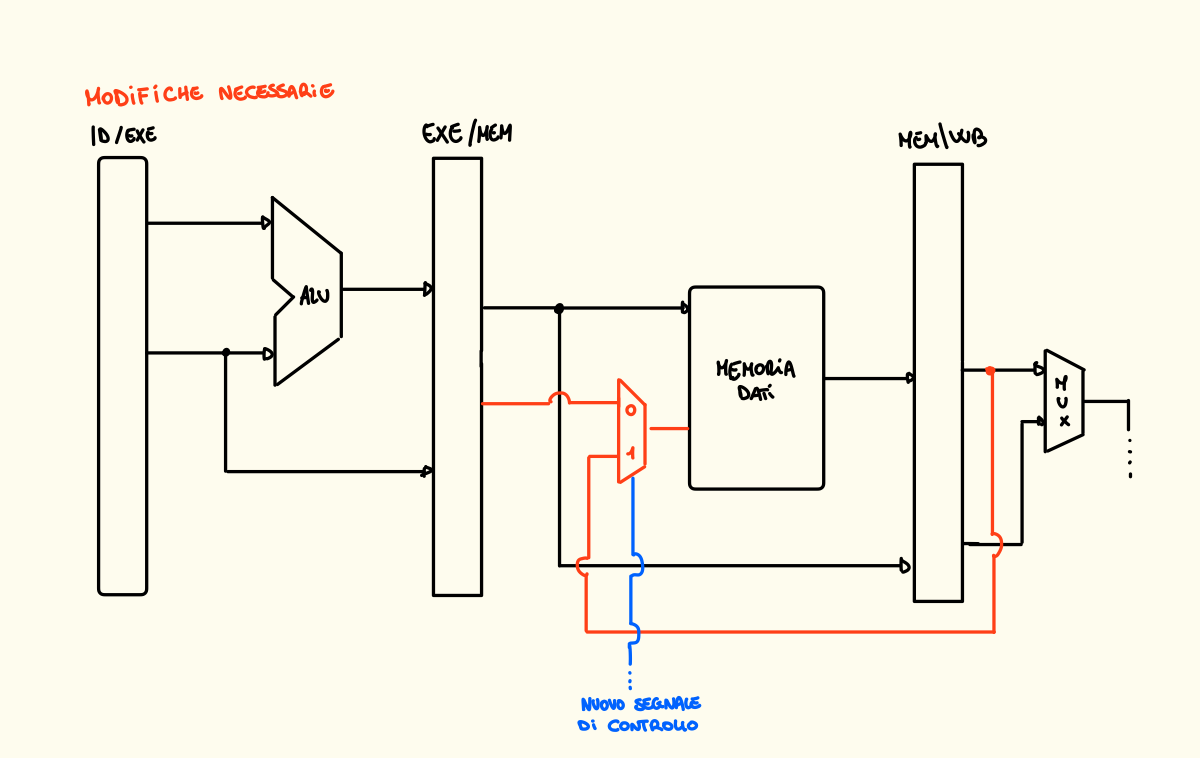
Come rileviamo il forwarding e quindi generiamo un segnale di controllo? Dobbiamo controllare se:
- MEM / WB.MemToReg == 1 && MEM / WB.RegWrite == 1 per capire se nell’istruzione striamo prendendo un dato dalla memoria per scriverlo in un registro
- EX / MEM.MemWrite == 1 per capire se nella nuova istruzione andiamo a scrivere nella memoria
- MEM / WB.Rt == EX / MEM.Rt per controllare se i due registri che contengono l’indirizzo di memoria sono lo stesso registro.
Stallo dell’istruzione
In alcuni casi per realizzare il forwarding è necessario inserire comunque uno stallo per attendere che il dato sia pronto nella fase che ci interessa.

Abbiamo realizzato il forwarding ma abbiamo comunque avuto bisogno di inserire due stalli.
Come riconosciamo dove dobbiamo inserire uno stallo? Dobbiamo esaminare le due istruzioni:
- La seconda istruzione ha bisogno del dato in fase di EXE ma la prima lo produrrà soltanto nella fase di MEM dato che è una load word, quindi:
ID / EX.MemRead == 1 && (IF / ID.rs == ID / EX.rt || IF / ID.rt == ID / EX.rt)Se dobbiamo scrivere in memoria e i registri sorgente delle due istruzioni sono uguali. - Un altro caso è quando la seconda lo richiede in ID e la prima lo produce dopo EXE (avviene nei beq anticipati):
ID / EX.RegWrite == 1 && (IF / ID.rt == ID / EX.rd || IF / ID.rs == ID / EX.rd) && op == beqQuindi se l’istruzione precedente scrive su un registro e i registri sorgente della successiva sono uguali al destinazione della precedente e l’istruzione è un salto.
Come fermiamo l'istruzione con lo stallo? (Fase ID)
Dobbiamo annullare l’istruzione che deve attendere e per fare questo dobbiamo azzerare i segnali di controllo MemWrite e RegWrite ovvero il banco IF / ID.istruzione e poi dobbiamo rileggere l’istruzione in modo da eseguirla al colpo di clock successivo e per fare questo dobbiamo impedire che il PC si aggiorni.
Esempio di inserimento stalli e forwarding
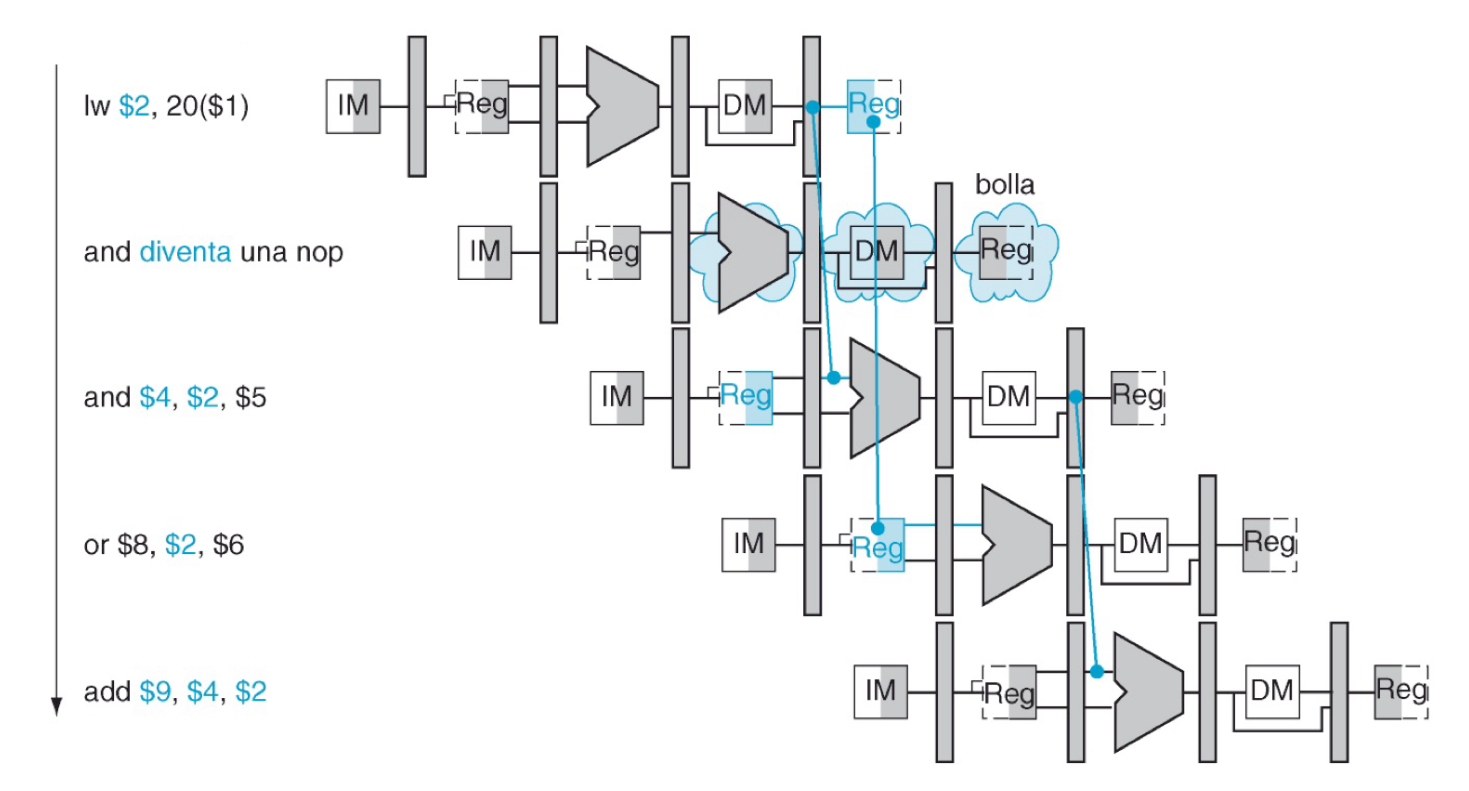
In questo caso l’istruzione AND aveva bisogno del dato in ID / EXE ma questo era pronto in fase MEM / WB della precedente e quindi non era possibile fare forwarding, annullando l’operazione inserendo uno stallo invece è stato possibile propagare il dato necessario.
Architettura Modificata
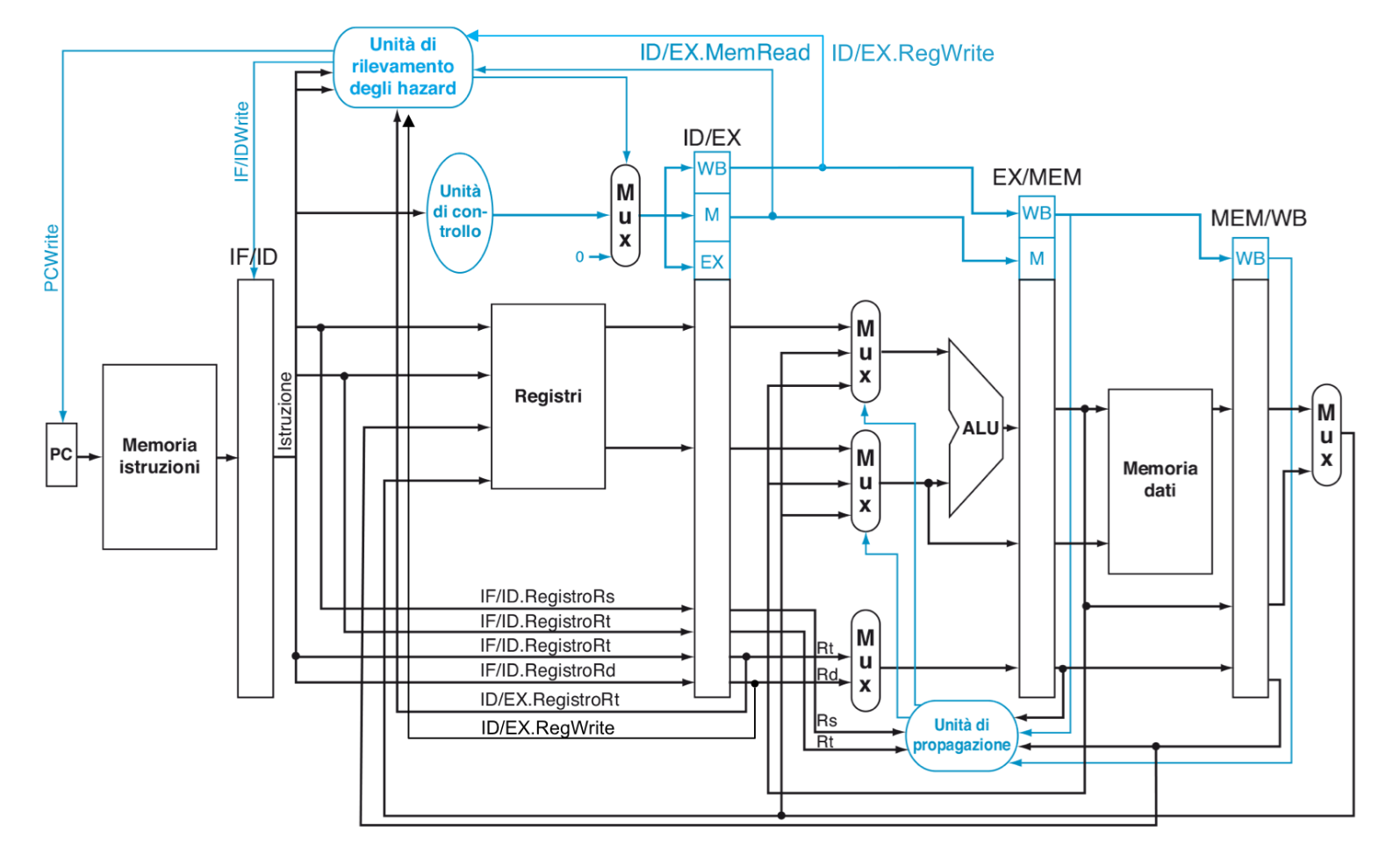
Il segnale PCWrite serve a non far aggiornare il PC nel caso in cui inseriamo uno stallo
Anticipare i Jump e Control Hazard
Ogni operazione viene riconosciuta dalla CPU durante la fase di ID e nello stesso momento viene caricata un’altra, quindi quando eseguiamo un jump abbiamo bisogno sicuramente di uno stallo per eliminare dalla pipeline le operazioni già caricate (Control Hazard).
j destinazione # IF ID EX MM WB
etichetta:
addi $s1, $s1, 42 # IF ID EX MM WB va annullata
destinazione:
sub $s1, $s1, $s2 # IF ID EX MM WBPer eliminare un’istruzione con lo stallo dobbiamo azzerare i segnali di controllo MemWrite e RegWrite e il banco IF / ID, aggiorniamo infine il PC affinché possa leggere la giusta istruzione al prossimo clock.
Anticipare il Jump alla fase IF
Dobbiamo anticipare il riconoscimento dell’istruzione fatto dalla CU in fase di ID, per fare questo usiamo un comparatore con il valore OpCode della J ovvero 000010. Poi dobbiamo anche spostare l’aggiornamento del PC alla fase IF e per fare questo eseguiamo lo shift logico a sinistra di 2 dei 26 bit meno significativi dell’istruzione e aggiungiamo i 4 bit più significativi del PC + 4. Adesso quindi la Jump non introduce più stalli dato che la riconosciamo in fase IF.
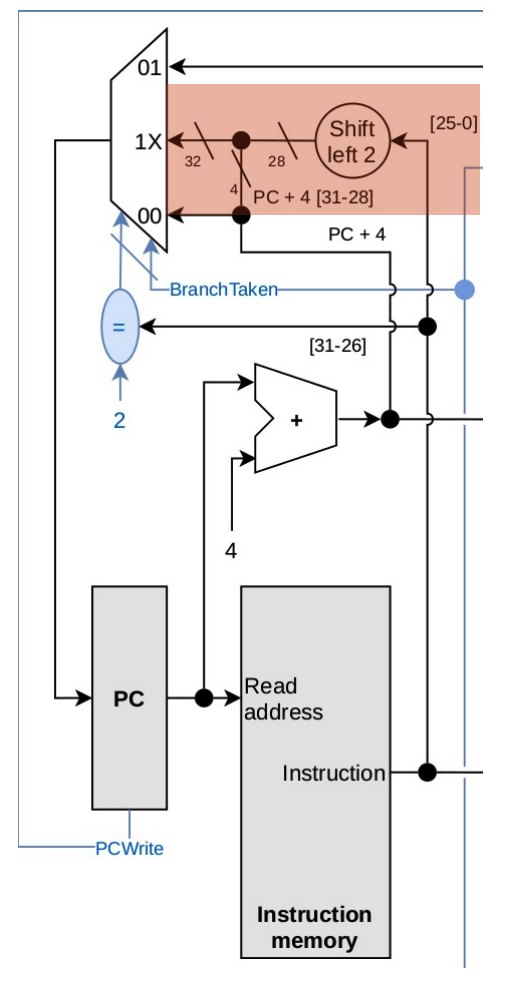
Control Hazards (beq)
L’istruzione beq di norma usa la ALU per eseguire i confronti quindi:
- Il salto avviene dopo la fase di EXE e quindi nella MEM e quindi abbiamo caricato in pipeline 2 istruzioni che in caso di salto vanno annullate.
- Ha bisogno degli elementi da confrontare in fase di EXE quindi non ha bisogno di stalli a meno che non sia preceduta da una lw che carica i dati in fase di MEM.
Come annullare le istruzioni?
IF / ID.Istruzioneviene azzerata facendo unaNOP (No Operation), 0x00…0. Una No Operation corrisponde a 32 bit di 0 che come istruzione èsll $0, $0, 0ID / EXE.MemWrite,ID / EXE.RegWriteeMemReadvengono azzerate per non leggere o scrivere sui registri o nella memoria.
Per anticipare la decisione di salto quindi alla fase ID per i branch occorre non utilizzare la ALU:
- Usiamo un comparatore tra i due argomenti del blocco registri
- Spostiamo la logica del salto ed il calcolo dell’indirizzo alla fase ID
- Inseriamo un’unità di forwarding apposita
In questo modo quando con un branch saltiamo dobbiamo inserire un solo stallo e non più due, dato che riconosciamo il salto in ID e non in EXE.
Attenzione Anticipando i controlli del salto alla fase ID avremo bisogno di questi dati da comparare nella fase ID e non più nella fase EXE. Quindi ad esempio se un branch è seguito da una lw dovremo inserire due stalli per aspettare che il dato sia pronto in fase di ID. Oppure se seguito da una tipo R dovremo inserire uno stallo per aspettare il dato.
Architettura CPU
Predire i Salti
L’idea principale è quella di inserire una o due istruzioni che verrano eseguite indipendentemente dal salto per evitare di inserire stalli dopo il branch, infatti se l’istruzione dopo la beq viene sempre eseguita anche quando il salto viene fatto, si elimina lo stallo eseguendo l’istruzione al posto dello stallo.
Impatto della beq: Se il salto viene eseguito dopo i calcoli della ALU e quindi in fase EXE dobbiamo inserire:
- 2 stalli se il salto viene eseguito
- 1 stallo prima se la beq è preceduta da lw
Se la beq è anticipata nella fase ID:
- 1 stallo se il salto viene eseguito
- 2 stalli prima se preceduta da lw o R.
L’impatto dipende anche da come è scritto il codice infatti se il test viene fatto all’inizio la beq eseguirà un solo salto inserendo quindi una sola volta gli stalli necessari, se invece il controllo viene eseguito alla fine le beq eseguirà molti salti per ripetere il corpo e quindi dovrà inserire molti più stalli.
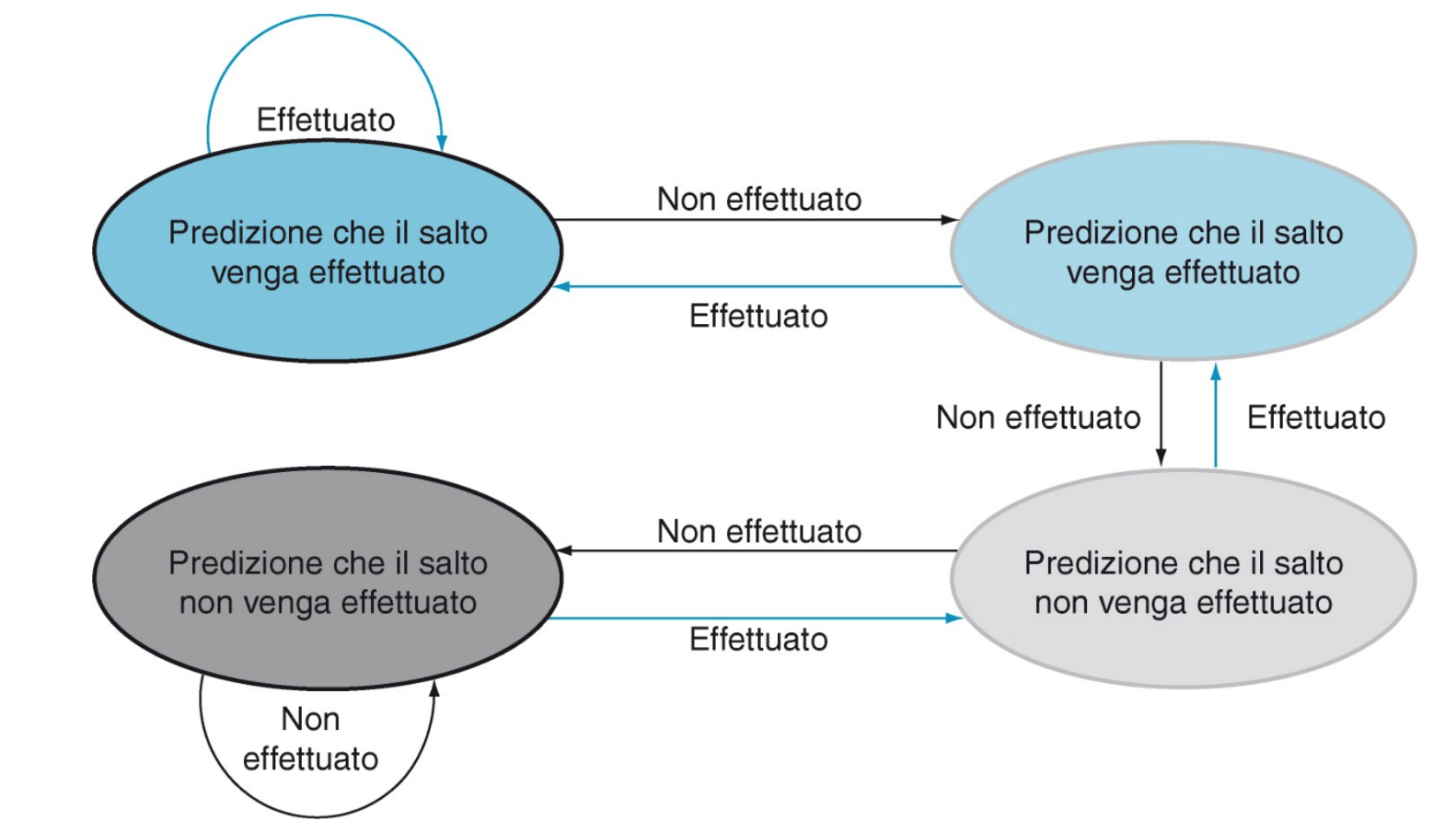
Infatti la CPU per come l’abbiamo vista fino ad ora prevede che il salto non viene effettuato, possiamo prevedere il salto e caricare quindi le giuste istruzioni?
Ad ogni istruzione di alto possiamo associare dei bit che contano quanti salti abbiamo effettuato e decidere quindi se è più probabile che avvenga o meno.
Con 2 bit possiamo realizzare una macchina a stati finiti:
- Necessita di due previsioni sbagliate per cambiare lo stato della previsione
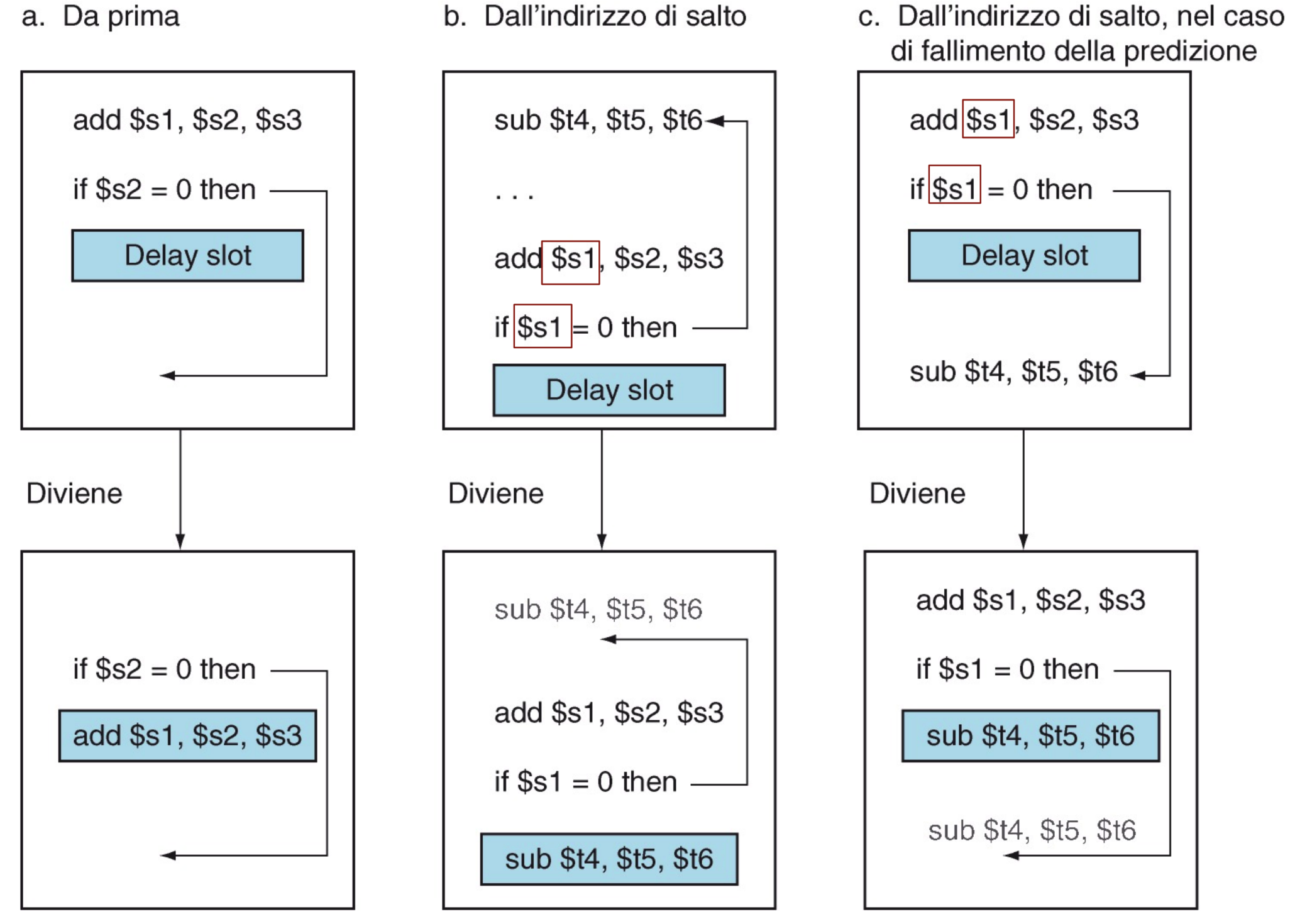
Ritardare il salto
Per recuperare il tempo perso nello stallo possiamo ritardare il salto.
- Eseguiamo in ogni caso l’istruzione che segue la beq (delay slot).
In questo delay slot possiamo inserire una delle istruzioni che vanno sempre eseguite, ci sono più casi:
-
Un’istruzione precedente alla beq e che non abbia dipendenze con essa (anche indirette)
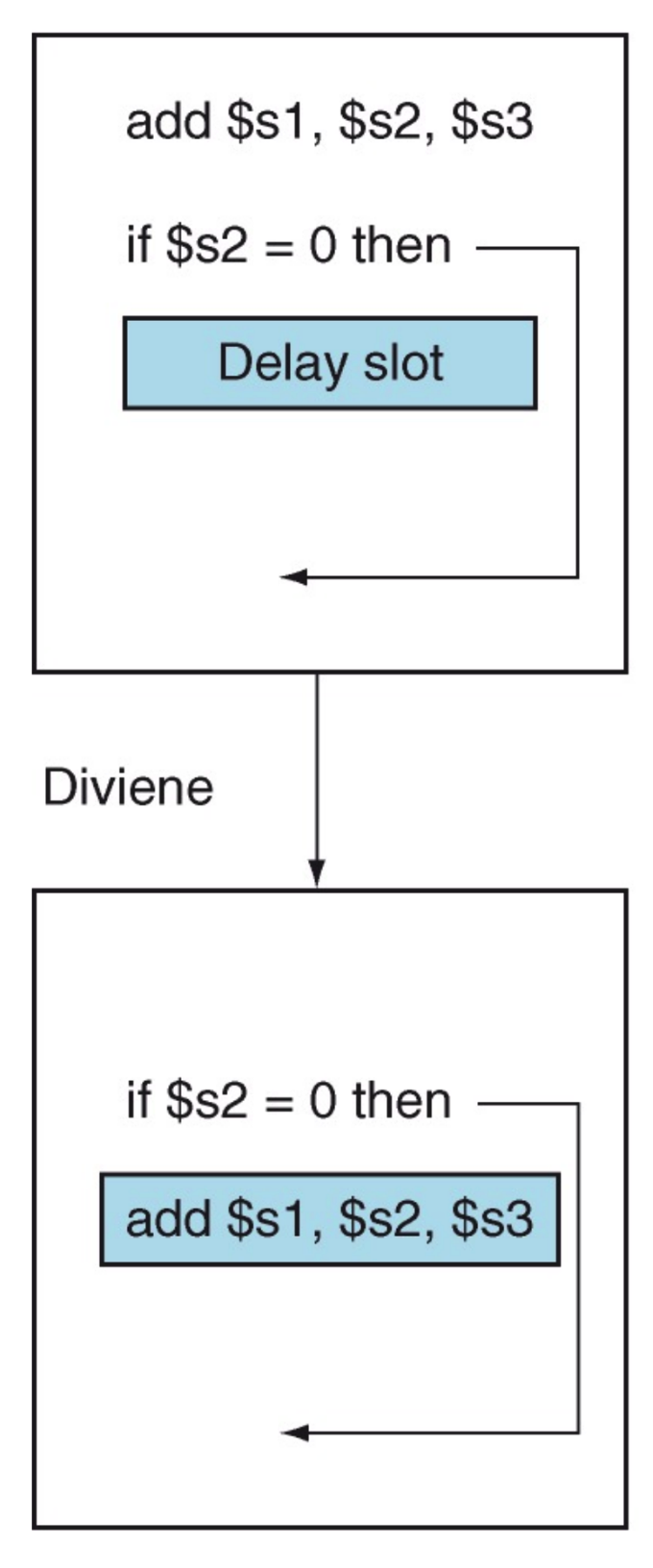
Se non abbiamo istruzioni precedenti senza dipendenze:
-
L’istruzione alla destinazione del salto, ma non è sempre possibile.
-
L’istruzione dobbiamo copiarla e non spostarla questo perché potrebbe far parte di altri flussi
-
Se il salto non viene effettuato l’istruzione che abbiamo inserito e che viene quindi sempre eseguita non deve creare problemi all’istruzione successiva
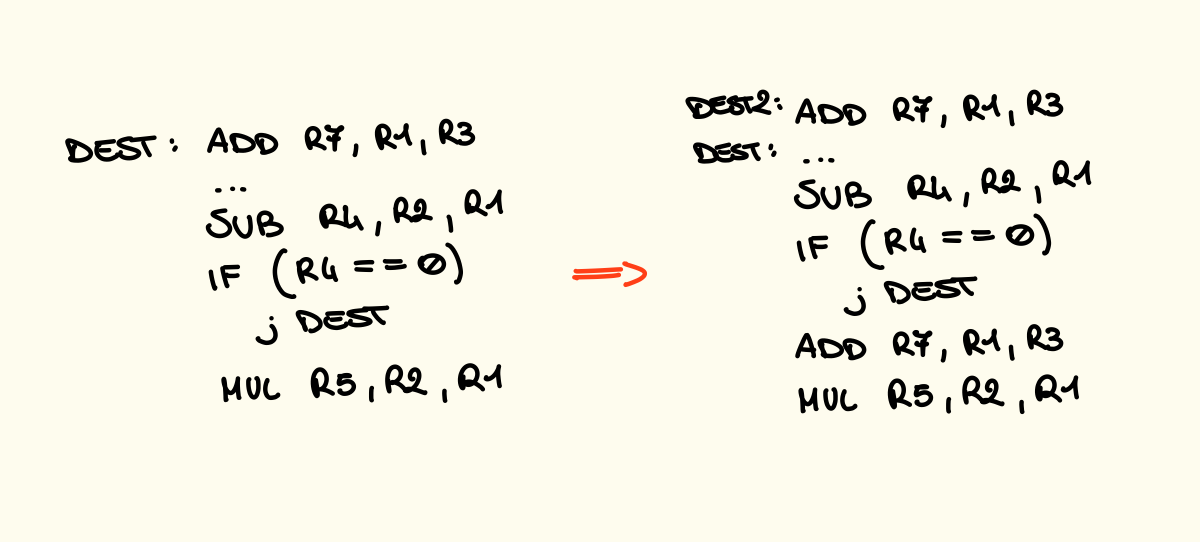
Le istruzioni che prima puntavano a dest adesso dovranno puntare a dest2. Questa tecnica ha senso se la probabilità che il branch venga effettuato è alta, ad esempio quando il branch è la condizione di uscita:
-
-
Se non abbiamo alternative inseriamo una NOP
Non ho ben capito a che serve dato che così ripeto più volte la stessa istruzione inutile, tanto vale che metto lo stallo (?) 🥹
Cache
Grazie alla pipeline siamo riusciti a velocizzare notevolmente l’esecuzione delle istruzioni della CPU, l’ultimo “rallentamento” che possiamo incontrare è quello della memoria questa infatti è circa 10 o anche 100 volte più lenta del processore. La soluzione più banale sembra quella di inserire una memoria più veloce delle stesse dimensioni della RAM ma questo sarebbe molto dispendioso, quindi dato che possiamo inserire una memoria estremamente veloce ma anche molto piccola cerchiamo di sfruttarla al massimo con questi due prinicipi:
- Principio di località temporale: Un programma tende ad accedere allo stesso elemento in momenti temporali molto vicini fra loro.
- Principio di località spaziale: Un programma tende ad accedere ad elementi in memoria successivi fra loro. Quindi per sfruttare questi due principi inseriamo una memoria piccola (cache) tra la CPU e la memoria in cui conserviamo i dati più utilizzati e anche quelli vicini ad essi.
Letture in diverse Memorie:
Quando la CPU richiede un indirizzo della memoria possono verificarsi due situazioni:
- HIT: Il blocco corrispondente all’indirizzo è presente nella cache e viene caricato da quest’ultima
- MISS: Il blocco non è presente nella cache, viene quindi caricato dalla memoria e copiato anche nella cache.
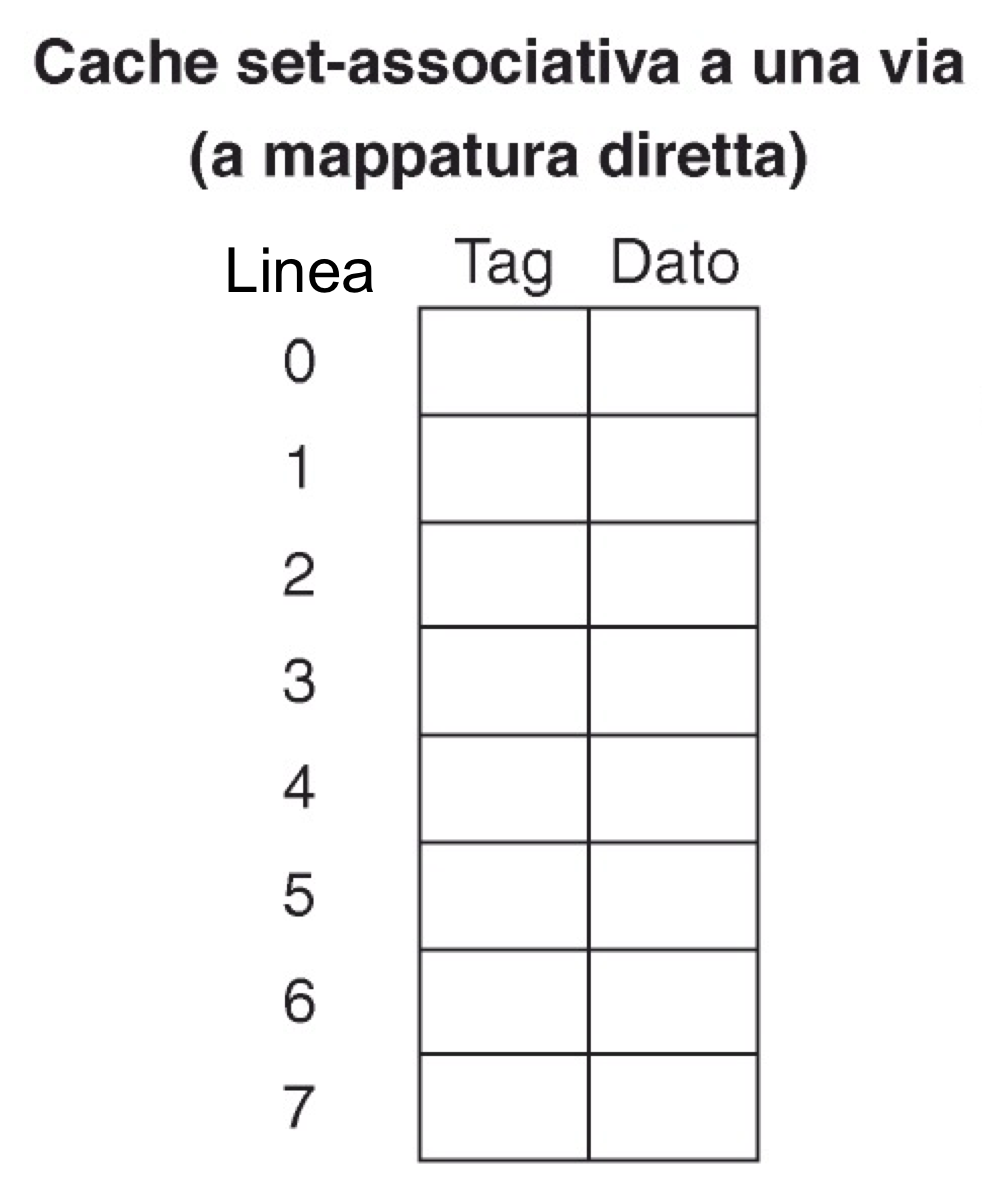
Cache Direct-Mapped
Dato che la cache deve contenere soltanto i dati più richiesti e con poco spazio a disposizione dobbiamo memorizzare più blocchi di memoria nello stesso spazio, questi quindi dovranno sovrascriversi a vicenda. La nostra cache è organizzata nel seguente modo:
- Ha N linee che indicano gli spazi occupabili dai blocchi di memoria Ogni linea ha:
- Un bit di validità che indica se i dati contenuti in quella linea sono validi o meno, quindi se il bit vale 0 la linea è considerata vuota.
- Campo Tag che ci permette di identificare il blocco di memoria memorizzato nella linea
- Il blocco di memoria vero e proprio memorizzato all’interno della linea
| Linea | V. Bit | Tag | Blocco |
|---|---|---|---|
| 0 | 0 | // | // |
| 1 | 1 | 4 | 101010101… |
| 2 | 0 | // | // |
| 3 | 1 | 2 | 10110110… |
Adesso dobbiamo trovare un modo che a partire dall’indirizzo di memoria richiesto ci permetta di capire in quale linea della cache potrebbe essere salvato il dato.
- La nostra cache ha linee e ognuna di queste ha un indice associato, per poter selezionare tutti gli indici abbiamo quindi bisogno di bit.
- Scomponiamo la memoria in word e ogni word corrisponde a 4 byte (32 bit), ogni blocco deve quindi contenere bit.
- Ci serve un valore che chiameremo offset word che ci indica quale word contenuta nel blocco corrisponde a quella richiesta dalla CPU. Questo valore avrà quindi una dimensione di bit in modo tale da poter selezionare tutte le possibili word del blocco.
- Abbiamo bisogno anche di un altro valore che chiameremo offset di byte che seleziona fra i 4 byte della word quello corrispondente al byte richiesto dall’indirizzo di memoria. Quindi dato che ogni word è formata da 4 byte per per selezionarli ci bastano 2 bit.
Prendiamo quindi un indirizzo di memoria, scomponiamolo e costruiamo la nostra cache:
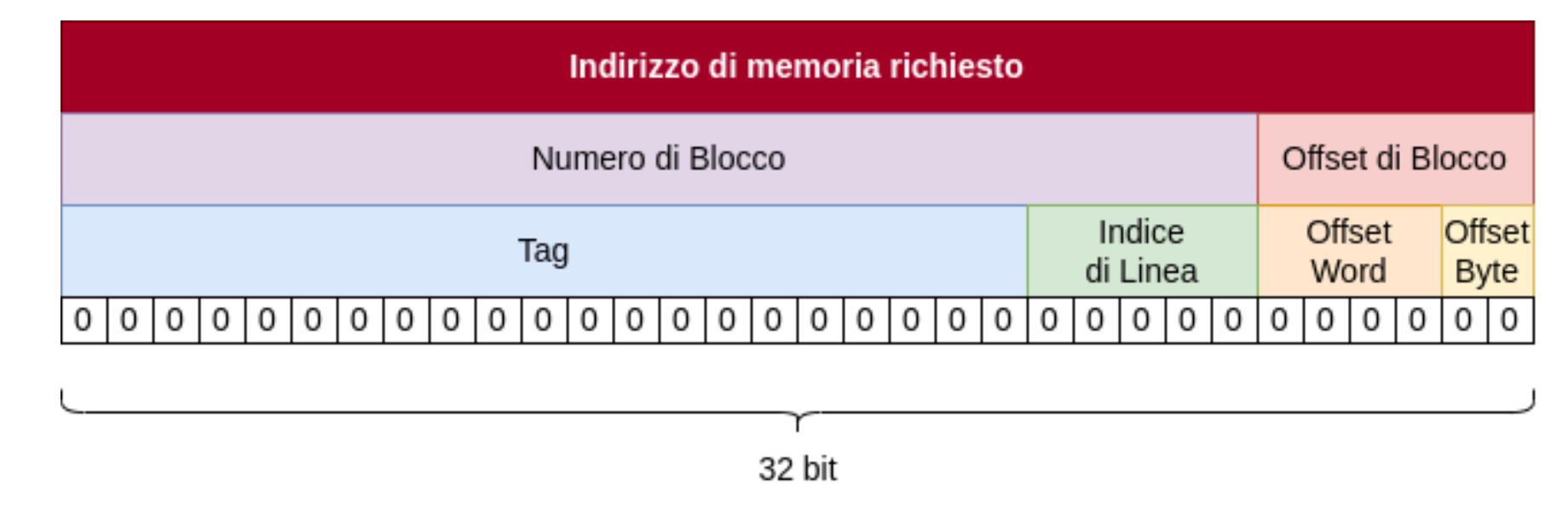
- 5 bit per l’indice della linea: linee = linee.
- L’offset delle word è composto da 4 bit quindi ogni blocco è composto da word = word, quindi ha una grandezza di 512 bit, .
- Il tag, ovvero il dato che indica in che blocco ci troviamo è formato da (offset di byte) e quindi in questo caso è formato da bit.
- Una linea deve contenere: 1 bit di veridicità, il tag che indica il blocco e il blocco vero e proprio quindi: bit.
- La dimensione totale della cache è quindi: bit byte quindi circa 2.1KB.
In breve:
- Cache con linee
- Blocchi di dimensione word da 4 byte quindi ogni blocco da: byte
- 1 bit di validità
- Campo TAG: bit
- Dimensione totale della cache: bit.
Determinare un HIT o un MISS
Adesso che abbiamo una struttura per i nostri dati possiamo realizzare la cache.
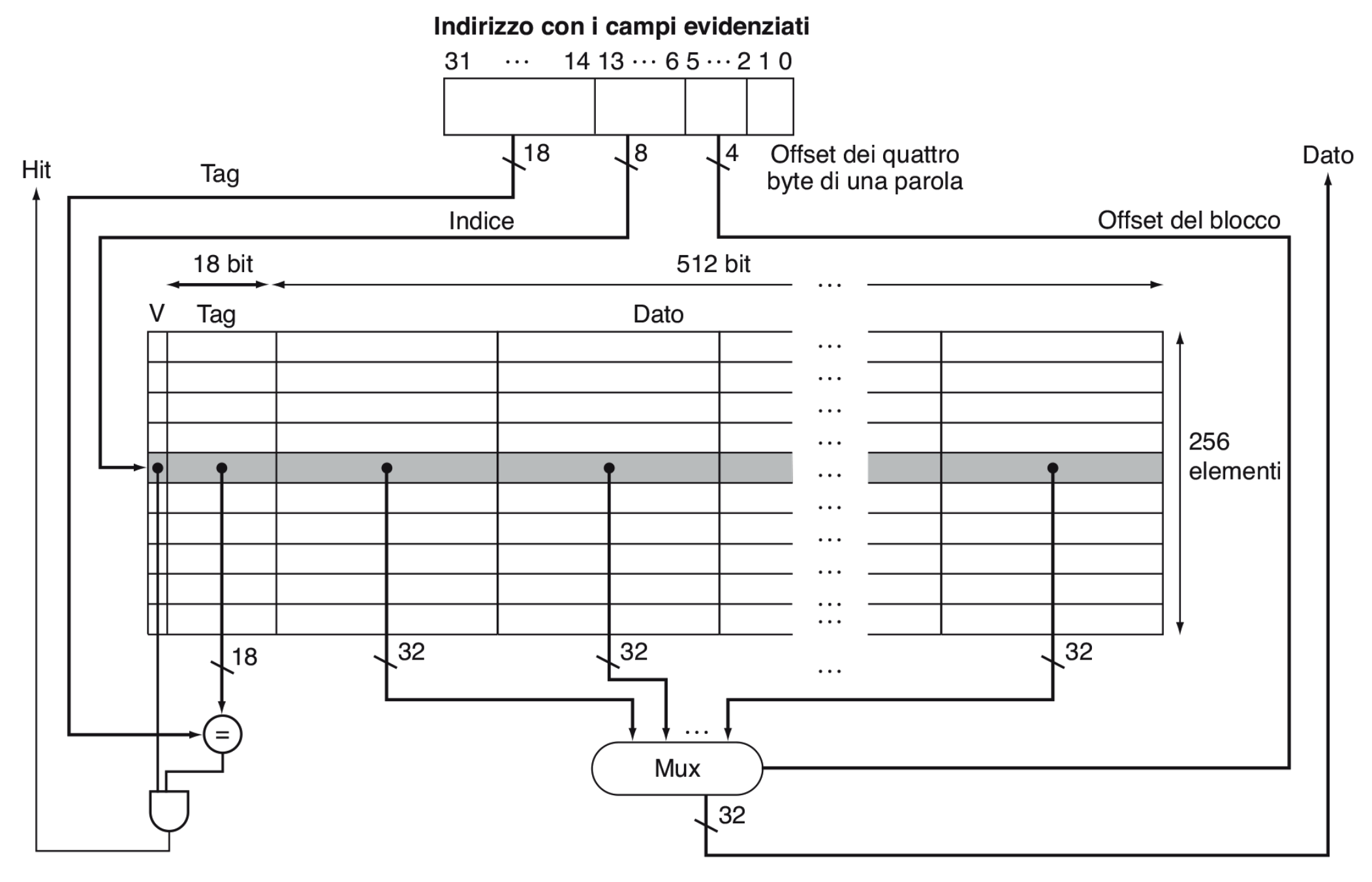
- Prendiamo gli 8 bit dell’indice e ci posizioniamo sulla linea corrispondente.
- Controlliamo se i 18 bit del tag sono uguali al tag contenuto nella linea e se il bit di validità è impostato a 1, in questo caso si verifica un HIT, altrimenti un MISS.
- Nei restanti bit della linea è presente il blocco di memoria che navighiamo tramite un MUX che ha come linea di controllo i 4 bit dell’offset word.
Altri tipi di Mapping
Fino ad ora abbiamo visto la memoria cache con direct-mapping dove ogni linea contiene un blocco di memoria:
Pro:
- Hardware semplice ma costoso
- È molto semplice determinare in quale linea è salvato il dato:
#linea = #blocco % N
Contro:
- Blocchi diversi sono mappati sulla stessa linea e vanno quindi sovrascritti, se questo accade molto spesso si verificano molti MISS (trashing).
Vediamo adesso altre tipologie di mapping:
- Fully Associative mapping Un blocco può essere posto in una linea qualsiasi, come pro abbiamo la massima flessibilità ma come contro un hardware molto complesso e costoso. Questo perché sappiamo dove si trova il blocco all’interno del set e dobbiamo quindi andarlo a cercare.
- Set-Associative mapping
Le linee sono organizzate in S set dove ogni blocco è disposto in una qualsiasi delle vie del set fissato.
- Per determinare il set:
#set = #blocco % SLe vie sono date dal numero di linee di ogni set.
- Per determinare il set:
Vediamo vari esempi di cache a 8 blocchi organizzati in diversi mapping.



- Esempio Inserimento
Proviamo ad inserire i blocchi di memoria con TAG = 0, 1, 2, 3, 4, 8 nelle memoria a 2 e 4 vie e vediamo cosa succede, ricordiamo che per calcolare il set di inserimento dobbiamo effettuare #blocco % S
- Due Vie
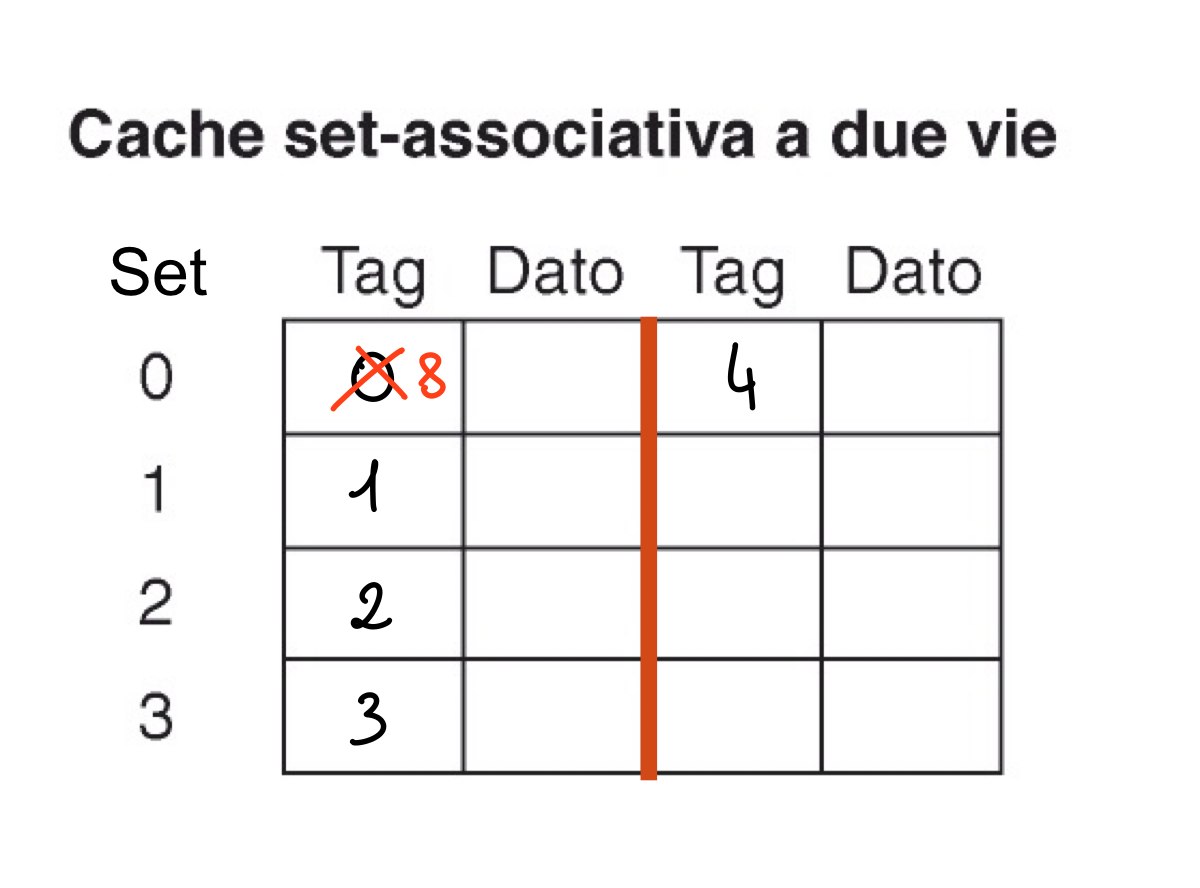
In questo caso inseriamo i blocchi 0, 1, 2, 3 poi il blocco 4 deve andare nel set 0 che contiene in una via il blocco 0 ma ha un’altra via libera quindi possiamo inserirlo mentre il blocco 8 che va sempre nel set 0 trova entrambe le vie occupate quindi dovremo sovrascrivere o la prima o la seconda. Per scegliere cosa sovrascrivere vedremo più avanti le politiche di rimpiazzo, per ora prendiamo la prima via.
- Quattro Vie
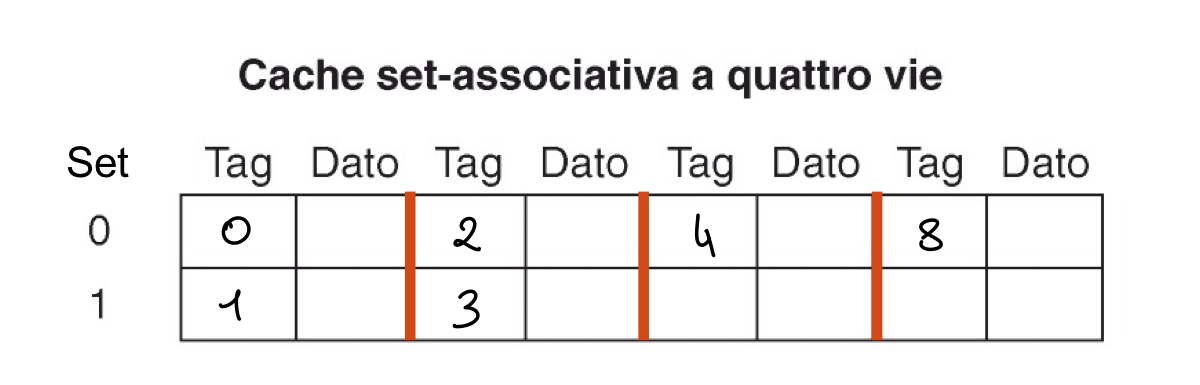
In questo caso invece inseriamo tutti i dati senza sovrascrivere nulla.
Il numero delle vie ci indica quindi quanto è associativa la nostra cache, più vie abbiamo più la nostra cache è associativa e diventa quindi anche più veloce ma anche più costosa.
Le cache si indicano con n.set * n.vie, quindi con 8 blocchi possiamo ottenere:
- 8x1 direct mapping (8 set 1 via)
- 4x2 set associative (4 set 2 vie)
- 2x4 set associative (2 set 4 vie)
- 1x8 full associative (1 set 8 vie)
A livello di circuito come implementiamo questa tipologia di cache? Abbiamo bisogno di un comparatore per ciascuna via e se uno di questi manda come segnale 1 (true) ci troviamo in una situazione di HIT, come capiamo quale comparatore? Utilizziamo un MUX con il numero di ingressi e il numero di linee di controllo pari al numero di vie.
Esempio di Cache associativa a 4 vie con blocchi da 1 word
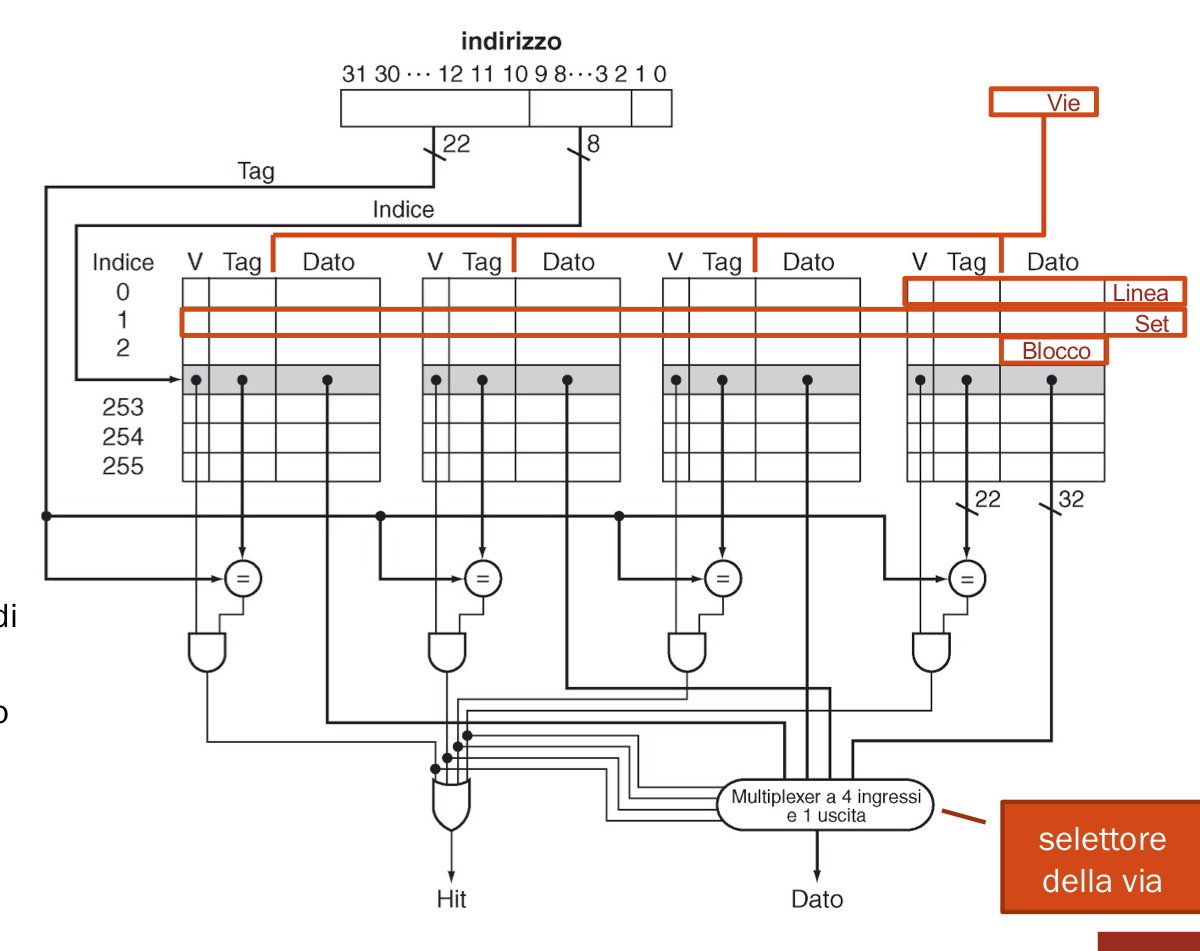
Grandezza della cache
Per ogni via possiamo identificare una tabella, ogni tabella contiene quindi S set con blocchi da N word. Per ogni linea della tabella abbiamo:
- 1 bit di validità (se servono anche i bit used / dirty che vedremo successivamente)
- i bit del tag: 32 bit - bit di offset - bit dell’indice di set
- bit del blocco: N(numero word) x 32.
Dimensione della cache:
I bit necessari per l’offset di blocco e di word sono mentre per l’indice di set abbiamo bisogno di bit.
Esempio: costruiamo una cache a 4 vie, con 8 set e blocchi da 4 word.
- Dimensione del blocco: 4(numero di word) x 32 = 128 bit
- bit di offset: bit
- bit del tag: 32 - 7 = 25 bit
Dimensione della cache: bit
Politiche di Rimpiazzo
Ci indicano in che modo sovrascrivere un dato quando non abbiamo spazio per inserirlo in cache.
- LRU (Least Recently Used): Sostituire il blocco più vecchio
- Si associa il bit used a ciascuna linea
- Ad ogni accesso si pone used = 1
- Dopo un intervallo di tempo si azzera, quindi le linee con used = 1 sono le più recenti
- Può risultare costoso mantenere questa informazione
- LFU (Least Frequently Used): Sostituire il blocco meno usato
- Si associa un contatore a ciascuna linea e si aggiorna ad ogni accesso
- Hardware più complesso
- Random: Sostituiamo un blocco a caso
Tipi di MISS
Un accesso alla cache può causare un MISS per tre motivi:
- Cold Start: Quel dato non era mai stato richiesto prima. Questo tipo di MISS è influenzato dalla dimensione del blocco, infatti blocchi più grandi contengono più dati e quindi il numero di cold start diminuisce
- Conflict: Abbiamo ancora spazio libero in cache ma per via del grado di associatività dobbiamo sovrascrivere un blocco. In una cache full associative se il dato viene richiesto in meno di altri blocchi avremmo avuto un HIT. Questo MISS è influenzato quindi dal grado di associatività, infatti più vie abbiamo meno conflitti ci saranno
- Capacity: Il blocco viene sovrascritto perché non abbiamo spazi liberi nella cache in cui scriverlo. Questo miss è influenzato dalla capacità della cache, maggiore è il numero di set maggiore sarà il numero di richieste gestibili
Il Cold Start ha la precedenza sulla tipologia di MISS, ad esempio se sovrascriviamo un blocco per qualsiasi motivo (conflict o capacity) ma il dato che stiamo scrivendo non lo abbiamo mai richiesto prima allora ci troviamo in un cold start.
Politiche di Scrittura
Se un dato presente nella cache viene aggiornato, come aggiorniamo la RAM?
- Write Through: Ad ogni modifica viene aggiornato il blocco anche nella memoria RAM
- PRO: Anche con delle cache multiple il dato rimane coerente in tutte le memorie
- CONTRO: Si perde molto tempo a scrivere nello stesso blocco più volte
- Write Back: Il blocco viene aggiornato solo quando viene sostituito ovvero quando non è più presente in cache.
- Pro: La scrittura del blocco avviene più raramente e quindi abbiamo una cache più veloce
- Contro: Il dato non è sempre coerente fra tutte le memoria causando complicazioni in sistemi multiprocessore o multicache.
Idea per Ottimizzazione: Possiamo utilizzare un bit Dirty che ci indica se un dato è modificato o no per evitare di scrivere sulla RAM i blocchi non modificati.
Cache Multilivello

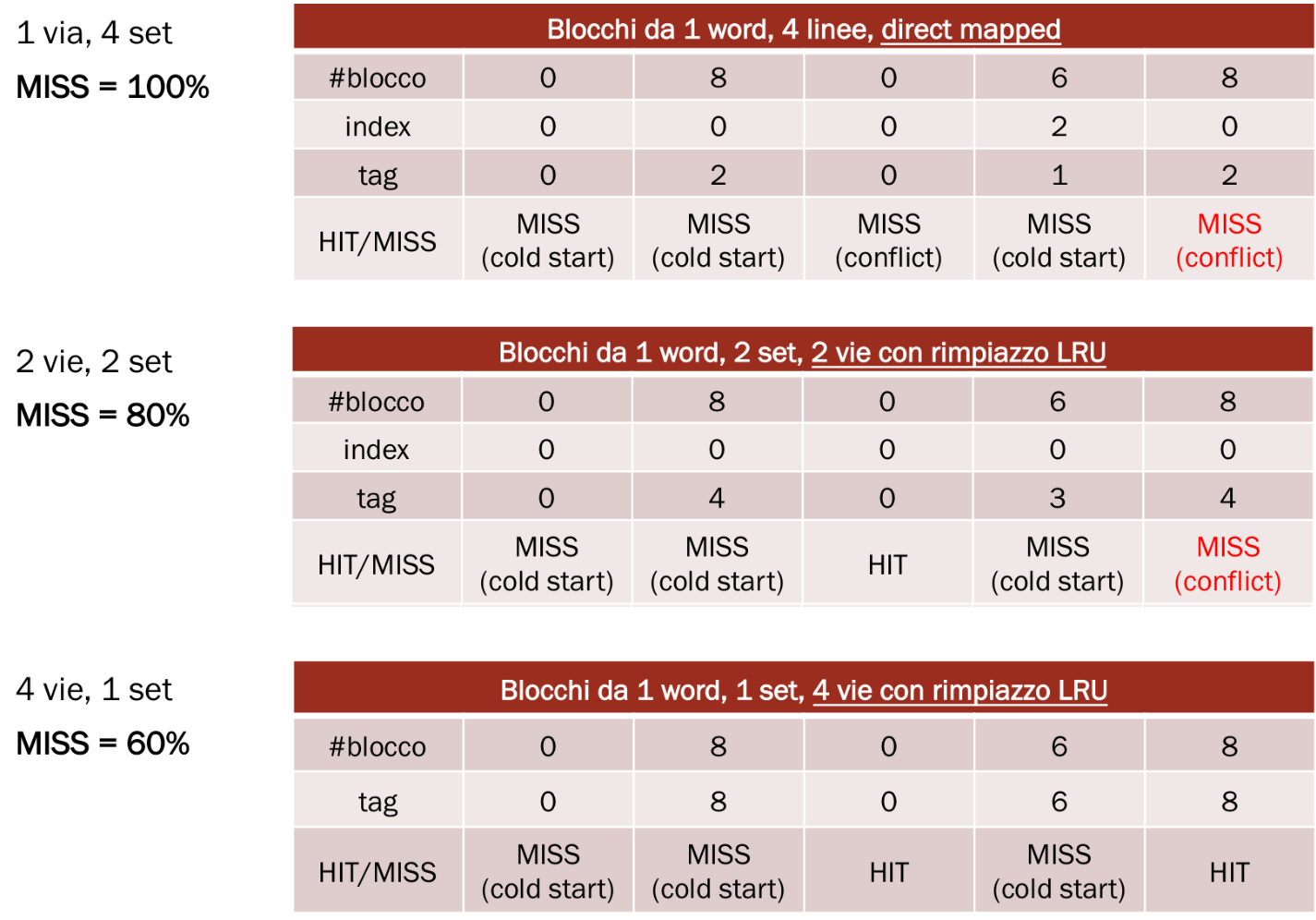
Infatti prendiamo come esempio la seguente sequenza di accessi in memoria: 0, 8, 0, 6, 8. Guardiamo cosa succede con diversi tipi di mapping con politica di rimpiazzo LRU.
Possiamo strutturare le nostre memoria in questo modo:
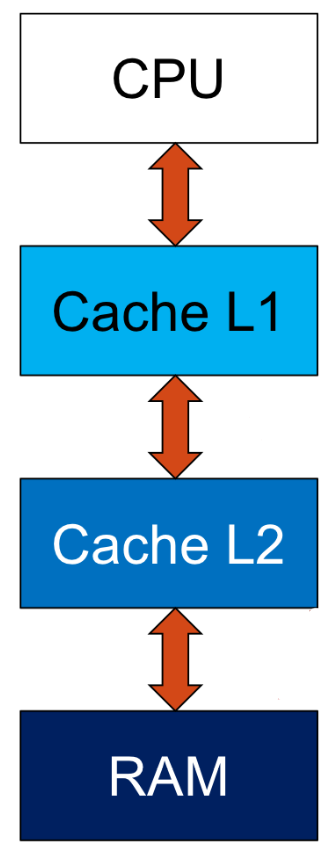
In questo modo abbiamo che:
- Ogni HIT fornisce i dati al livello superiore
- Se si verifica un MISS andiamo a chiedere i dati al livello inferiore
- L’accesso impiega il tempo del livello dove si verifica l’HIT
Esempio di Calcolo dei tempi
- HIT su L1:
- HIT su L2:
- Accesso a RAM: (si verifica dopo un MISS su L2)
- Clock della CPU da (2 Cicli di Clock per ns) e 3 CPI (cicli di clock per istruzione).
- Percentuale di MISS su L1 = 15% e quindi percentuale di HIT = 85%
- Percentuale di MISS su L2 = 20% e quindi HIT = 80%
Tempo medio di accesso in memoria:
Considerando i 2 cicli di clock per ogni ns abbiamo cicli di clock per accesso.
Guardando nello specifico i calcoli abbiamo eseguito:
%HIT L1 * TempoL1 + %MISS L1 x %HIT L2 * TempoL2 + %MISS L1 * %MISS L2 * TempoRAM.
In questo modo per ogni livello consideriamo anche la percentuale di Miss del livello superiore, la RAM non ha percentuale di HIT dato che è sempre HIT.
Esercizio calcolo cache e HITT / MISS
Per calcolare velocemente gli HIT e MISS senza costruire la tabella, se ci troviamo in un rimpiazzo LRU, ci basta controllare per ogni blocco i passaggi precedenti di miss effettuati sulla stessa linea entro il range delle vie. Ad esempio in questo caso abbiamo 4 vie quindi per determinare un HIT controlliamo i 4 passaggi precedenti sulla stessa linea del blocco e controlliamo se è presente il blocco con lo stesso tag nei soli miss.
Cache Multiple per Processori Multipli
In un sistema multiprocessore si usano più cache in parallelo e siccome diversi processi potrebbero dover modificare o accedere agli stessi dati è necessario mantenere la coerenza di questi fra i vari processori.
Idee: Collegare tra loro le cache in modo che ognuna sappia che cosa stanno facendo le altre e permettere il passaggio delle informazioni tra le cache.
Quando più processori accedono contemporaneamente agli stessi dati lo stesso blocco è presente in due copie diverse in due cache separate.
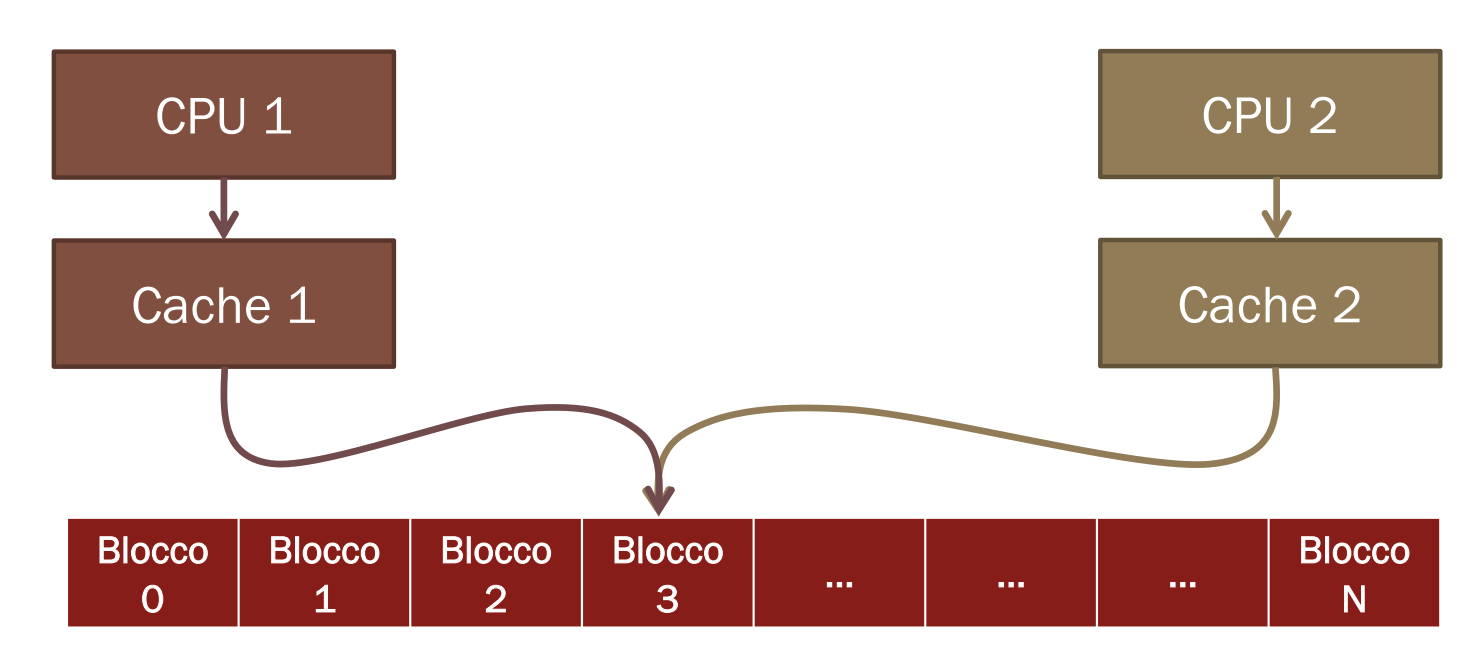
Un sistema però ha dei dati coerenti se la lettura di un dato restituisce il suo valore più recente.
- Coerenza: Indica quale valore deve essere restituito dalla lettura di un dato
- Consistenza: Dopo aver effettuato una scrittura ci indica dopo quanto tempo il dato sarà disponibile. Una scrittura non è considerata completa finché tutti i processori non ne vedono l’effetto, inoltre i processori non devono cambiare l’ordine delle scritture, ma se necessario quello delle letture.
Esempi: Se P1 legge da X dopo aver scritto X e senza che altri utilizzino X, leggeremo lo stesso valore. Se P2 legge da X dopo che P1 ha scritto in X ed è passato abbastanza tempo, leggeremo il valore scritto da P1. Ma se ad esempio abbiamo due CPU, entrambe leggono un dato e quindi lo aggiungono alle loro cache, poi una di queste scrive un dato nella stessa locazione, questa CPU aggiornerà il dato sia nella cache che nella memoria ma non nella cache dell’altra CPU dove rimarrà la sua vecchia versione.
Garantire la Coerenza
In un’architettura multiprocessore dove vogliamo garantire coerenza nella cache dobbiamo avere:
- Migrazione dei dati Se un dato viene trasferito in una cache locale questo deve poter essere usato in modo trasparente
- Replicazione dei dati Quando un dato condiviso viene letto da più processori deve essere replicato nelle corrispondenti cache.
Come supporto per la coerenza utilizziamo un protocollo hardware che traccia lo stato di condivisione dei blocchi fra tutte le cache.
Protocollo di Snooping
Questo protocollo prevede che:
- Ogni cache che contiene un blocco di memoria, contiene anche lo stato di condivisione nelle altre cache.
- Collegare le cache con un bus per permettere di controllare (snooping) le altre e aggiornare lo stato di condivisione del blocco.
- Dobbiamo trasmettere le MISS e le scritture da una cache a tutte le altre, questo serve a far migrare un blocco o per invalidarlo se obsoleto.

Quindi le CPU leggono in X e dopo i MISS aggiornano le loro cache, dopo che la CPU A scrive in X, il blocco X è invalidato e quindi va aggiornato anche nelle altre cache oltre che nella memoria.
Il controllore di una cache
Per progettare questo controllore possiamo utilizzare un Automa a Stati Finiti.
Quindi per ogni automa dobbiamo definire:
- Stati
- Input / output
- Transizioni di stati
- Codifica di stati / input / output
In questo caso specifico andiamo a definire 4 stati:
- Idle: Quando siamo in attesa della richiesta
- Confronto dei tag: Cerchiamo nei blocchi della cache il tag
- Allocazione: Leggiamo il blocco dalla memoria
- Write - Back: Scrittura del blocco sulla memoria
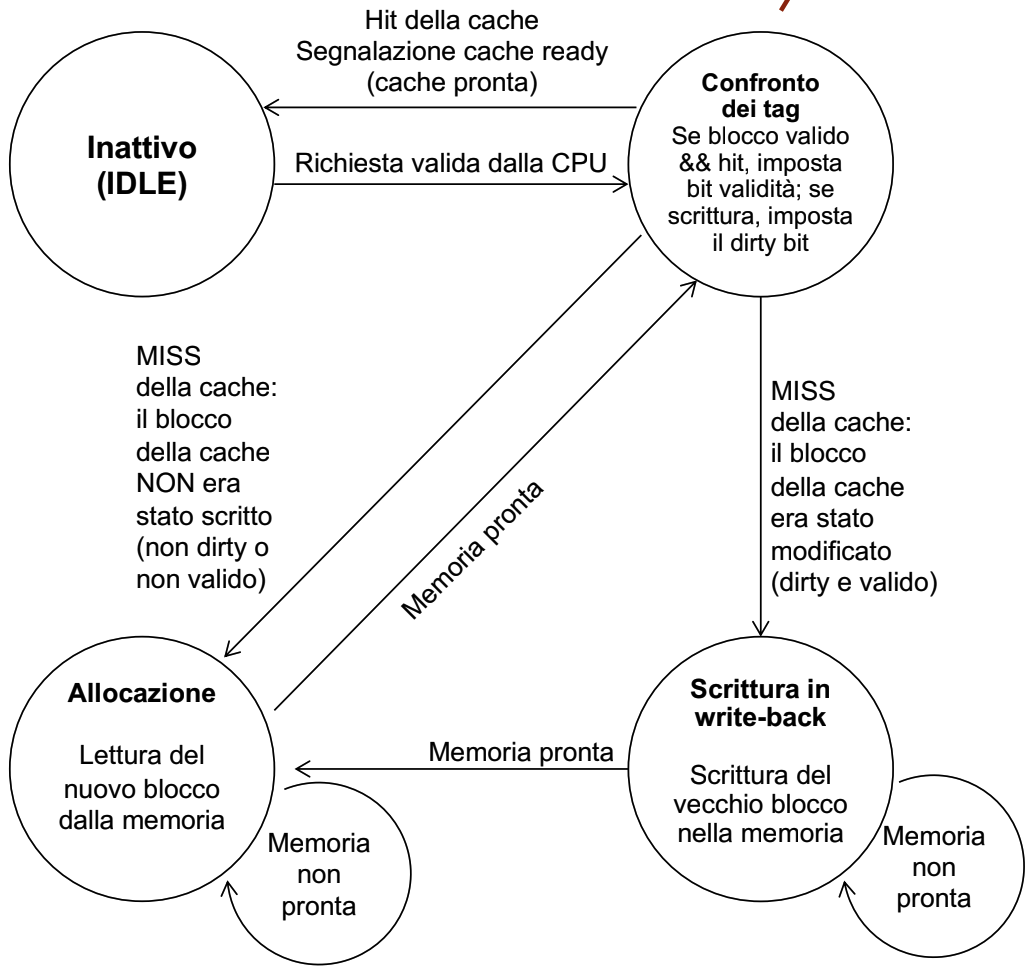
Quindi durante la fase di idle possiamo l’input che ci fa cambiare stato è una richiesta valida della CPU che ci porta a confrontare i tag della cache. Se il blocco è valido ed è un HIT torniamo nella fase di idle altrimenti possono verificarsi due tipi di MISS, se il blocco non era stato scritto andiamo in allocazione per leggere il nuovo blocco da inserire nella cache oppure il blocco era stato modificato e quindi dobbiamo scriverlo in memoria. Quando la memoria è pronta nel primo caso torniamo al confronto dei tag mentre nel secondo rileggiamo il blocco e quindi andiamo in allocazione.