Indirizzamento IPv4
Un indirizzo IP è composto da 32 bit ovvero 4 byte, ciascuno di essi è rappresentato in notazione decimale, quindi nel range 0-255. Ogni interfaccia di un host e router di Internet hanno un indirizzo IP globale univoco.
Per interfaccia non intendiamo un host o un dispositivo, ma il confine tra il dispositivo e l’esterno, questo significa che ad esempio un singolo dispositivo può avere più indirizzi se ha più interfacce. Ad esempio se un PC si collega tramite cavo ethernet ad una rete e tramite WiFi sempre alla stessa rete avrà due indirizzi IP diversi, uno sull’interfaccia via cavo e uno su quella wireless.
Spazio degli Indirizzi
Essendo formati da 32 bit significa che possiamo avere indirizzi, più di 4 miliardi.
Possiamo indicarli in binario, in notazione decimale separando ogni byte con un punto oppure in esadecimale ovvero come si fa nella programmazione di rete.
Gerarchia degli Indirizzi
Gli indirizzi vanno divisi in:
- Prefisso: si scelgono bit da sinistra che individuano la rete
- Suffisso: i restanti bit individuano l’interfaccia all’interno della rete
Il prefisso può avere una lunghezza fissa o variabile.
Indirizzamento a lunghezza fissa (con classi)
Ci sono 3 lunghezze di prefisso che identificano le varie classi
- Classe A - Prefisso da 8 bit e il primo byte va da 0 a 127
- Classe B - Prefisso da 16 bit e il primo byte va da 128 a 191
- Classe C - Prefisso da 24 bit e il primo byte va da 192 a 223
- Classe D - Non ci sono prefissi e suffissi ma sono degli indirizzi speciali di multicast ovvero per inviare messaggi a tutta la rete. Il primo byte va da 224 a 239

Un vantaggio di questo metodo è che una volta preso l’indirizzo si risale facilmente alla classe e alla lunghezza del prefisso.
Il contro però è che ad esempio la classe A può essere assegnata soltanto a 128 organizzazioni al mondo (reti) che avranno ciascuna 16.777.216 nodi. Molti di questi nodi sono sprecati e inoltre non bastano gli indirizzi per 128 organizzazioni.
La classe B ha gli stessi problemi della A mentre la classe C può gestire molte organizzazioni ma per ciascuna di esse rende disponibili soltanto 256 nodi.
Questo metodo infatti non viene più utilizzato ma si usa un indirizzamento senza classi.
Indirizzamento senza classi
Con questo metodo si utilizzano blocchi di lunghezza variabile che non appartengono a nessuna classe, così facendo però prendendo un indirizzo da solo non riusciamo a risalire alla lunghezza del suo prefisso e per questo la indichiamo alla fine con uno slash.
Questa notazione che indica indirizzo e lunghezza prefisso si chiama CIDR (Classless InterDomain Routing).
Esempio
200.23.16.0/23 →
Se è la lunghezza del prefisso allora possiamo ricavare varie informazioni:
- Il numero di indirizzi nel blocco (rete) è dato da
- Per trovare il primo indirizzo si impostano a 0 tutti i bit del suffisso
- Per trovare l’ultimo si impostano a 1 tutti i bit del suffisso
Maschera e Indirizzo di Rete
La maschera dell’indirizzo è un numero da 32 bit dove i primi bit (del prefisso) a sinistra sono impostati a 1 mentre i restanti a 0, grazie alla maschera si ottiene l’indirizzo di rete usato nell’instradamento dei datagrammi verso la destinazione.
Infatti tramite la maschera, usando delle operazioni, possiamo ricavare immediatamente le seguenti informazioni di un blocco:
- Numero degli indirizzi del blocco
- Primo indirizzo del blocco
- Ultimo indirizzo del blocco
Esempio
Una maschera da /24 bit è 255.255.255.0 e indica appunto che i primi 24 bit sono per la rete.
Con l’operazione NOT otteniamo 0.0.0.255 che in binario è 0000000.00000000.00000000.11111111 e aggiungendo uno otteniamo 256 ovvero gli indirizzi disponibili in quella sottorete.
Indirizzi IP Speciali
- L’indirizzo 0.0.0.0 è utilizzato dagli host al momento del boot
- Gli indirizzi che hanno lo 0 come numero di rete si riferiscono alla rete corrente
- L’indirizzo composto da tutti 1 permette la trasmissione broadcast sulla rete locale
- Gli indirizzi con un numero di rete specifico e tutti 1 su quello host permette di mandare messaggi broadcast ad una rete specifica
- Gli indirizzi nella forma
127.xx.yy.zzsono riservati al loopback ovvero i pacchetti vengono inviati e ricevuti dalla stessa macchina, sono usati per testare applicazioni
Distribuzione degli indirizzi in una rete LAN
Un amministratore di rete, per ottenere un blocco di indirizzi liberi da usare in una rete deve contattare il suo ISP. In questo modo otterrà un blocco di indirizzi contigui con un prefisso comune nella forma a.b.c.d/x dove x indicano le sottoreti e 32-x indica il numero di dispositivi per l’organizzazione (all’interno di una sottorete)
Ma l’ISP da dove ottiene il blocco di indirizzi? C’è un organizzazione che gestisce questo aspetto e anche i server DNS root chiamata ICANN (Internet Corporation for Assigned Names and Numbers).
Una volta ottenuto un blocco di indirizzi come li assegnamo ai dispositivi in una rete?
- Assegnazione manuale - la eseguiamo una volta per dispositivo e avremo sempre lo stesso indirizzo nella rete
- DHCP (Dynamic Host Configuration Protocol) - Quando l’host si connette alla rete gli viene assegnato un indirizzo in automatico. È comunque configurabile in modo da avere gli stessi indirizzi per gli stessi dispositivi.
Il DHCP ci permette di ottenere in modo dinamico gli indirizzi e quindi anche il loro riutilizzo, ad esempio io mi collego ed ottengo l’indirizzo x e quando mi scollego questo torna libero e può essere usato da altri.
DHCP fornisce anche altre informazioni agli host ovvero:
- Indirizzo IP
- Maschera di Rete
- Indirizzo del router
- Indirizzo DNS
Anche il DHCP si basa sul paradigma client - server:
- Client ottiene le informazioni dalla rete
- Ogni sottorete dispone di un server DHCP, se questo non è presente è il router ad agire da server.
Quando un dispositivo si collega:
- Invia un messaggio broadcast
DHCP discover - Il server DHCP risponde con
DHCP offer - L’host richiede l’indirizzo IP con
DHCP request - Il server DHCP invia l’indirizzo
DHCP ack
Come sono formati i messaggi DHCP?

Da notare che nel pacchetto non è previsto un campo per il tipo di messaggio, quindi per indicare il tipo viene usato un magic cookie nel campo opzioni pari a 99.130.83.99
E la prima comunicazione avviene in questo modo:
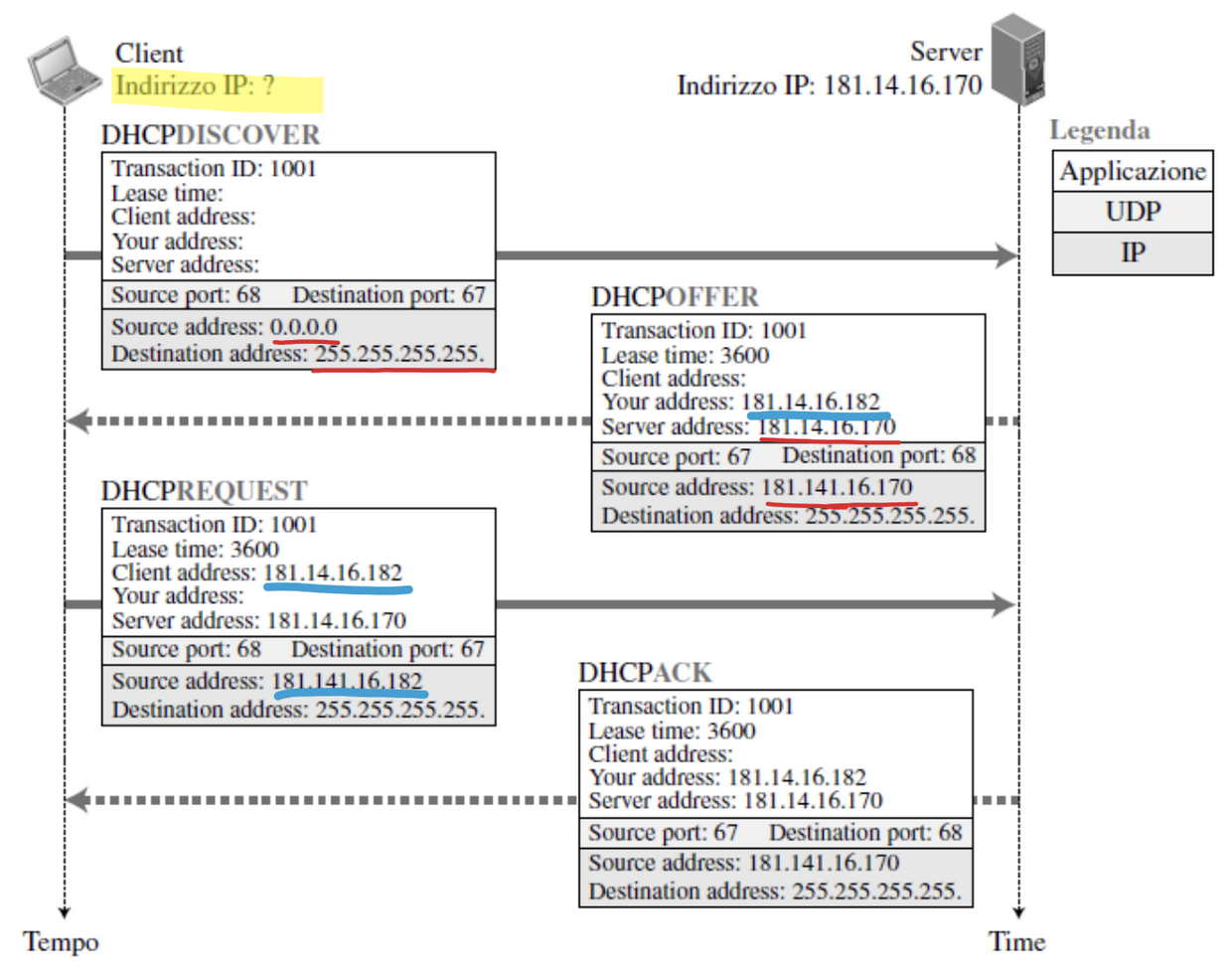
- Notiamo che l’host quando manda il primo messaggio di broadcast ha come indirizzo 0.0.0.0 dato che non ne ha ancora uno assegnato
Per gestire queste richieste il DHCP usa delle well-known port ovvero 68 in ascolto sul client e 67 in ascolto sul server. Questo perché siccome il client non ha ancora un indirizzo anche il server invia la risposta in broadcast che verrà presa da tutti i client in ascolto sulla porta 68. La porta infatti non è l’unica cosa che distingue il client ma si usa anche l’indirizzo MAC, altrimenti nel caso di client che si collegano nello stesso momento si potrebbero creare conflitti ovvero due host interpretano lo stesso messaggio di risposta del server come destinato a loro.
Il DHCP fornisce si tutte le altre informazioni come DNS e altro ma in realtà fornisce soltanto l’indirizzo IP e un pathname in DHCPACK che punta ad un file con queste informazioni, l’host successivamente ottiene il file tramite FTP.
NAT
Prima abbiamo visto il concetto di sottorete ovvero una rete isolata dove i terminali sono collegati all’interfaccia di un host o router.
All’interno della stessa sottorete i terminali devono avere tutti lo stesso prefisso ad esempio nella sottorete 223.1.1.0/24tutti i terminali devono iniziare con 223.1.1.xxx
Quindi dato un indirizzo IP e la sua maschera di rete come capiamo a che blocco appartiene?
- Il prefisso ha lunghezza variabile
- Se multiplo di 8 allora gli indirizzi degli host vanno da 0 a 255
- Se non è multiplo di 8 allora va vista la rappresentazione binaria dell’ultimo byte, se ad esempio inizia con 10xxxxxx ovvero vale 1 il bit alla posizione 7 significa che gli indirizzi degli host vanno da 128 a 191 cioè 10111111
Questa notazione CIDR ha reso più flessibile l’assegnazione di blocchi alle aziende ad esempio ma ha anche creato un problema, se in futuro si ha bisogno di più indirizzi e il blocco successivo è occupato come si fa? Ma soprattutto con tutti i dispositivi di oggi, gli indirizzi IP disponibili non basterebbero più.
Indirizzi Privati
All’interno delle sottoreti si usano degli indirizzi privati divisi in varie classi:
- da 10.0.0.0 a 10.255.255.255 con maschera da 8 bit 10.0.0.0/8
- da 172.16.0.0 a 172.31.255.255 con maschera da 12 bit 172.16.0.0/12
- da 192.168.0.0 a 182.168.255.255 con maschera da 16 bit 192.168.0.0/16
In questo modo tutti i dispositivi interni hanno un indirizzo privato e quando si comunica con l’esterno si usa un solo indirizzo pubblico effettuando una traduzione tramite il NAT (network address translation). Tramite questo metodo è possibile assegnare gli stessi indirizzi privati all’interno di sottoreti diverse.
Quindi l’unico dispositivo esposto all’esterno raggiungibile è il router.
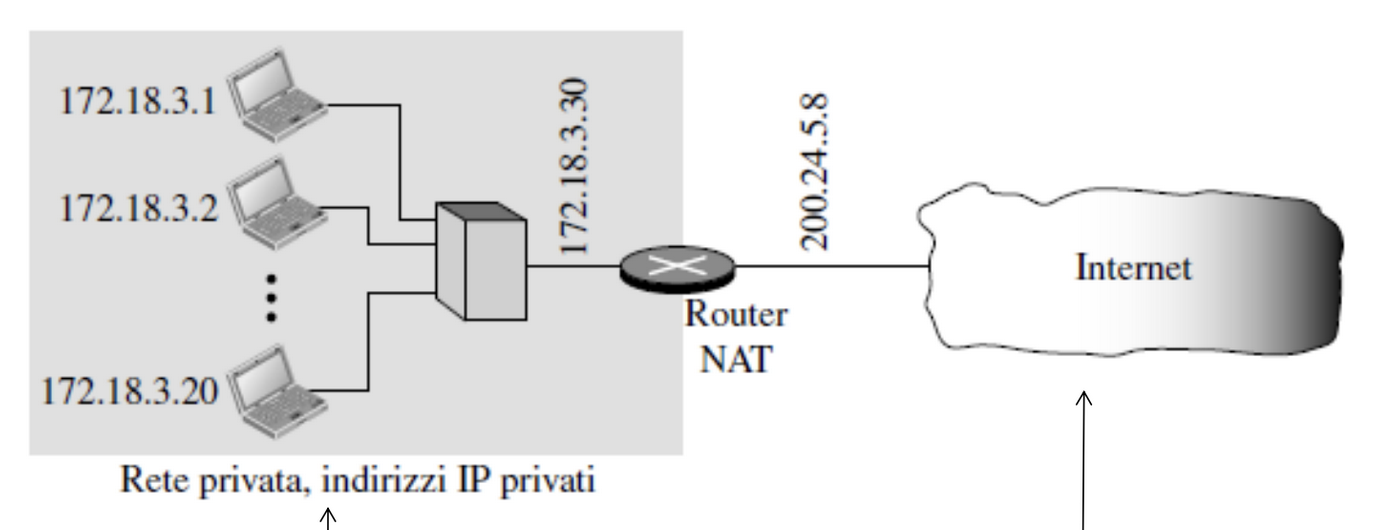
I router che abilitano il NAT quindi permettono di:
- Nascondere i dettagli della rete interna all’esterno
- Non è necessario allocare un blocco tramite l’ISP dato che l’ISP deve fornirci un solo indirizzo pubblico per il router
- È possibile cambiare l’indirizzo privato di una rete senza dover informare l’Internet
- È possibile cambiare ISP senza cambiare gli indirizzi della rete privata
Come viene implementata la traduzione?
Quando un router con NAT riceve il datagramma genera per esso un nuovo numero di porta d’origine e sostituisce l’indirizzo IP origine (dell’host) con il proprio indirizzo IP (router) sul lato WAN e il numero di porta origine iniziale con il numero nuovo scelto prima.
Esempio
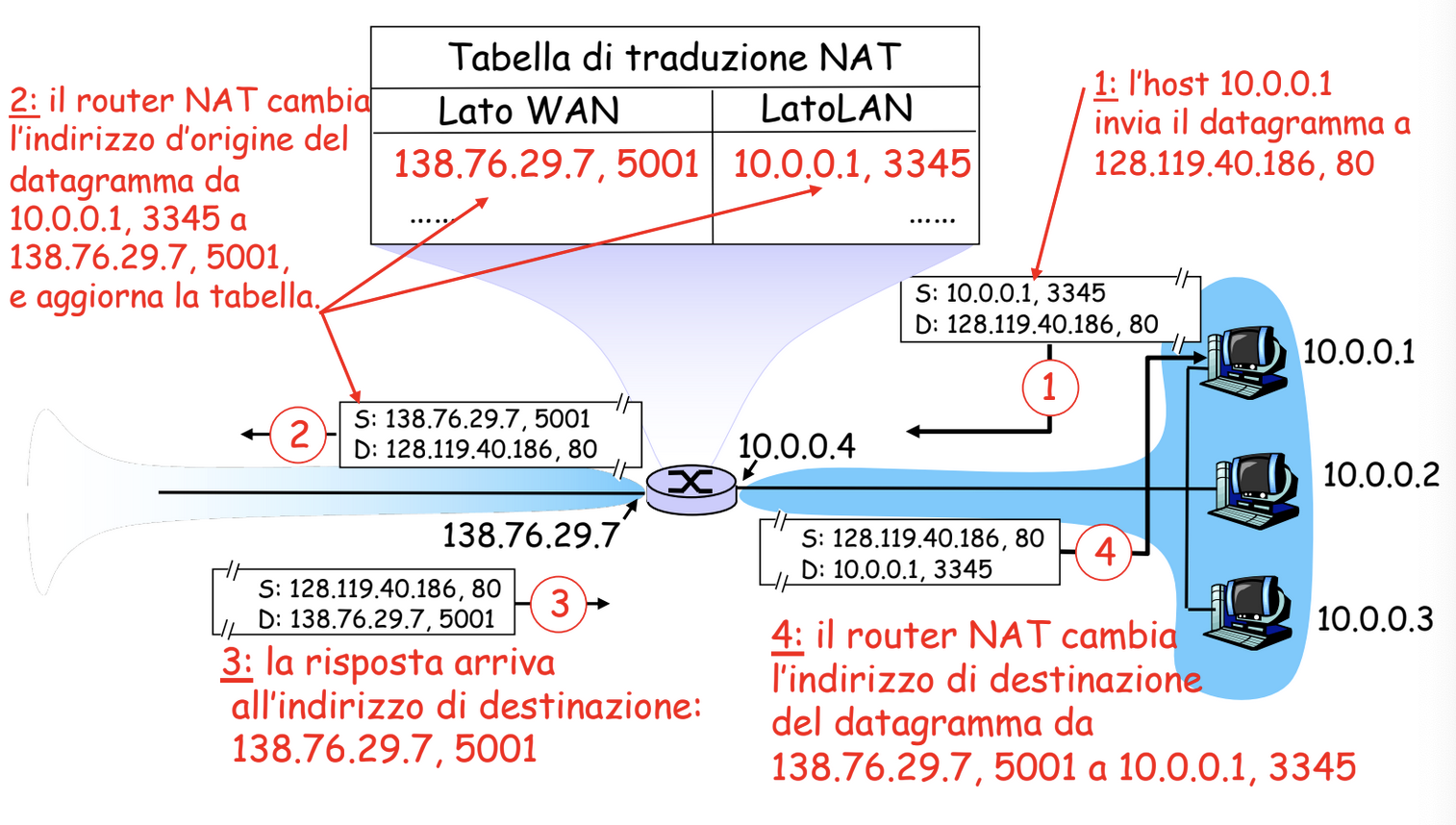
Dato che il numero di porta è lungo 16 bit il protocollo NAT può supportare più di 60.000 connessioni simultanee con un solo indirizzo IP.
Il NAT è stato un protocollo contestato:
- I router dovrebbero elaborare i pacchetti solo fino al livello 3
- Il numero di porta viene usato per identificare degli host e non dei processi
- Viola il cosiddetto argomento punto - punto ovvero gli host dovrebbero comunicare fra di loro e per risolvere la scarsità di indirizzi andrebbe usato IPv6
- Il NAT crea problemi con le app P2P in cui ogni peer dovrebbe essere in grado di avviare una connessione TCP con qualsiasi altro peer. A meno che il NAT non sia specificamente configurato per quella specifica applicazione P2P.
Nemico numero 1 giocatori BO2 zombie
🤓 Non consentendo connessione P2P vanno aperte manualmente le porte sul router per ogni servizio che vogliamo usare oppure utilizzare UPnP che permette ad un servizio di aprire in automatico delle porte sul router (anche se non molto sicuro)

Forwarding datagrammi IP
Inoltrare significa collocare il datagramma sul giusto percorso che lo porterà a destinazione o comunque procedere verso essa.
Quando un host deve inviare un datagramma all’esterno lo invia al router della rete locale il quale accede alla tabella di routing per trovare il successivo hop a cui inviarlo, l’inoltro richiede una riga nella tabella per ogni blocco di rete.
Esempio
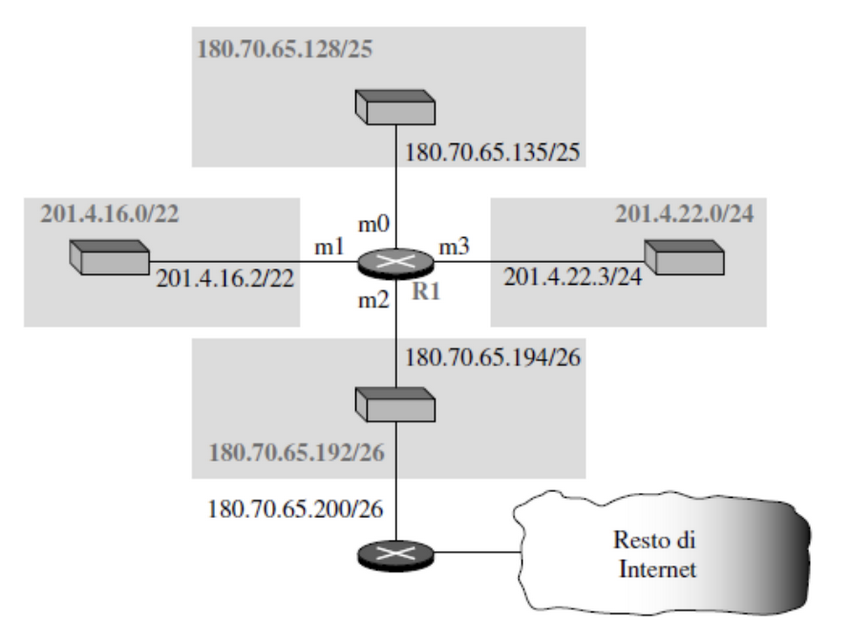
Il router R1 avrà una tabella, ad esempio:
| Indirizzo di Rete | Hop successivo | Interfaccia |
|---|---|---|
| 180.70.65.192/26 | - | m2 |
| 180.70.65.128/25 | - | m0 |
| 201.4.22.0/24 | - | m3 |
| 201.4.16.0/22 | - | m1 |
| default | 180.70.65.200 | m2 |
| Possiamo trovare la tabella rappresentata anche con numeri in binario dove vengono rappresentati soltanto i bit della sottorete ovvero il prefisso: |
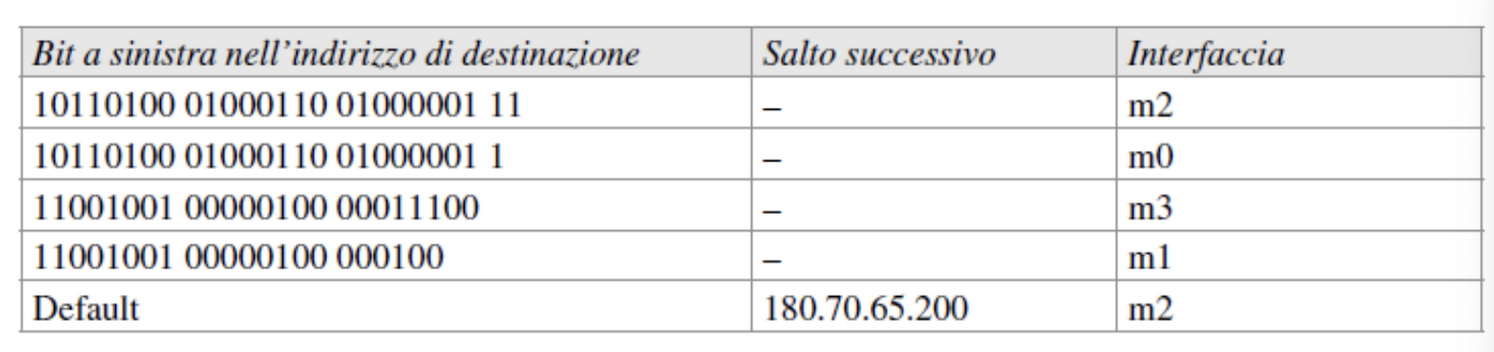
Infatti se dividiamo in ottetti otteniamo (primo valore):
- 10110100 → 180
- 01000110 → 70
- 01000001 → 65
- 11000000 → 192
All’interno della tabella sono presenti indirizzi di rete, ma un datagramma contiene l’indirizzo IP dell’host di destinazione e non sa qual è la lunghezza del prefisso di rete, come si esegue l’instradamento?
Confrontiamo bit a bit e vediamo quanti più bit combaciano con quelli presenti nel datagramma, ad esempio se combaciano i primi 26 lo mandiamo nell’interfaccia m2, se combaciano i primi 25 nella m0 e così via. Ovviamente si parte da più cifre per essere più precisi.
Esempio
Arriva al router un datagramma con destinazione 180.70.65.140, in decimale vediamo che va instradato nell’interfaccia m0, in binario abbiamo:
- Destinazione: 10110100010001100100000110001100
- La prima maschera non combacia:
Verrà testata anche la seconda e combacierà
Aggregazione degli indirizzi
Inserire nella tabella una riga per ogni blocco può portare ad avere tabelle molto lunghe che portano anche a tempi di ricerca molto lunghi, per risolvere il problema si usa l’aggregazione degli indirizzi.
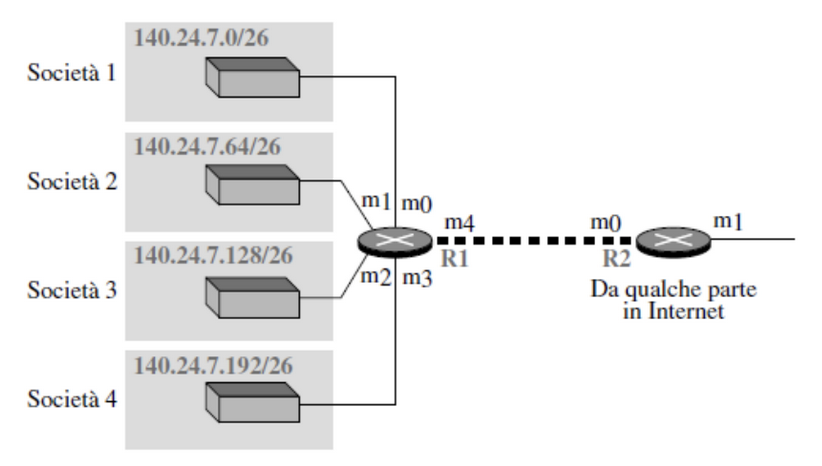
Notiamo che le 4 società hanno 4 blocchi di indirizzi contigui, le raggruppiamo quindi in un router che le gestisce ovvero R1 e all’interno di R2 eseguiamo una mappatura su una maschera che le contiene tutta con interfaccia di uscita sul router R1.
In questo modo abbiamo meno entry sul tabella di R2 e soltanto 4 in quella di R1.
Quindi in R2 avremo soltanto la seguente riga:
- Indirizzo: 140.24.7.0/24
- Next Hop: Indirizzo R1
- interfaccia: m0
È importante ricordare che:
- Per eseguire l’aggregazione le reti devono essere contigue
- Devono avere tutte lo stesso next-hop
- Il prefisso aggregato deve contenere soltanto tutte le reti originale
ICMP
Troviamo questo protocollo sempre al livello di rete e serve a notificare gli errori da parte dei router agli host.
Infatti nell’IPv4 ci sono diversi problemi non gestiti:
- Se un router deve scartare un pacchetto perché non sa dove instradarlo cosa si fa?
- Se un datagramma ha il campo TTL pari a 0?
- Se un host non riceve tutti i frammenti di datagramma entro un limite di tempo?
Grazie a ICMP il router che riscontra l’errore può inviare i dettagli di questo all’host mittente sperando che le informazioni che invia siano sufficienti a risolvere il problema per l’invio successivo.
In realtà ICMP è considerato parte di IP dato che lo usa per inviare i suoi messaggi anche se agisce a livello di rete sopra all’IP.
I messaggi che invia hanno un campo tipo e un campo codice, contengono l’intestazione e i primi 8 byte del datagramma IP che ha causato l’errore.

Da qui in poi scritto un po’ di corsa, non so quanto sia giusto ma mi sembrava un po’ inutile (toccava andare in mensa 🤓)
Ad esempio il comando ping si basa sui messaggi di richiesta e di risposta echo di ICMP, infatti in alcuni dispositivi non è possibile mandare messaggi di ping.
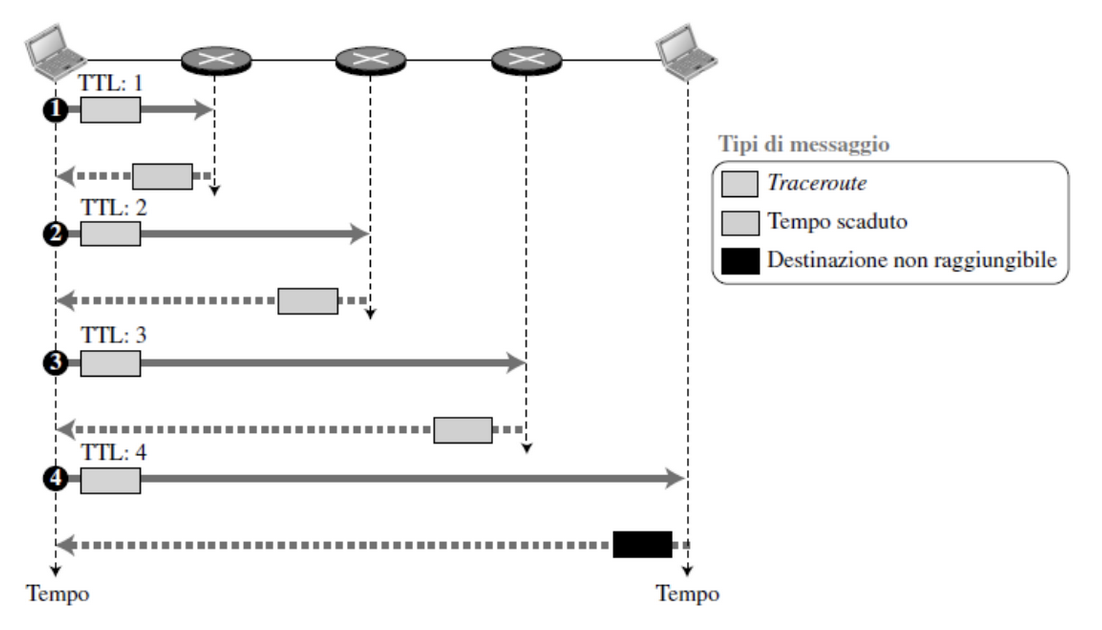
Anche tracerout sfrutta questo protocollo.
Invia datagrammi IP contenenti segmenti UDP a delle porte inutilizzate, il primo avrà TTL 1 il secondo 2 ecc…
Dato che il numero di porta è improbabile il mittente avvia un timer per ogni datagramma.
Per via di come sono stati impostati i TTL, l’n-esimo router scarterà l’n-esimo datagramma e invia all’origine un messaggio di allerta ICMP (tipo 11 codice 0) che include nome e indirizzo del router.
Quando arriva il messaggio ICMP il mittente riesce a calcolare l’RTT.
Traceroute esegue questo per 3 volte.
Non c’è una struttura client server ma solo client e messaggi ICMP, i messaggi vengono infatti inviati da router intermedi per via del timer scaduto e la porta irraggiungibile dal mittente.