funny memino
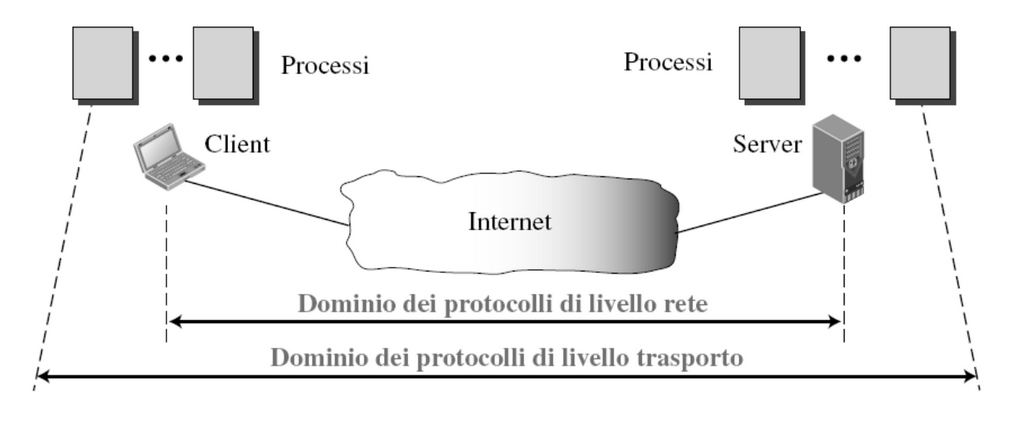
A livello di trasporto abbiamo una connessione logica ovvero gli host eseguono i processi come se fossero direttamente connessi. I protocolli di trasporto vengono eseguiti nei sistemi terminali e funzionano con un meccanismo di incapsulamento quando si invia un messaggio e decapsulamento quando si riceve.
A livello di rete abbiamo una comunicazione tra host basata sui servizi del livello di collegamento mentre a livello di trasporto una comunicazione tra processi basata sui servizi del livello di rete.
Esempio
1 persona di un condominio invia una lettera a 1 persona di un altro condominio consegnandola/ricevendola a/da un portiere.
Possiamo individuare le seguenti figure:
- Processi = persone
- Messaggi delle applicazioni = lettere nelle buste
- host = condomini
- protocollo di trasporto = portieri dei condomini
- protocollo del livello di rete = servizio postale
Quindi notiamo che i protocolli di trasporto (portieri) lavorano a livello locale e non sono coinvolti al di fuori.
Indirizzamento
I nuovi sistemi operativi sono multiutente e multiprocesso questo significa che sia a livello client che server avremo diversi processi attivi. Per stabilire una comunicazione tra due processi sarà quindi necessario individuare:
- Host locale
- Host remoto
- Processo locale
- Processo remoto
L’host verrà identificato tramite un indirizzo IP mentre il processo tramite un numero di porta.
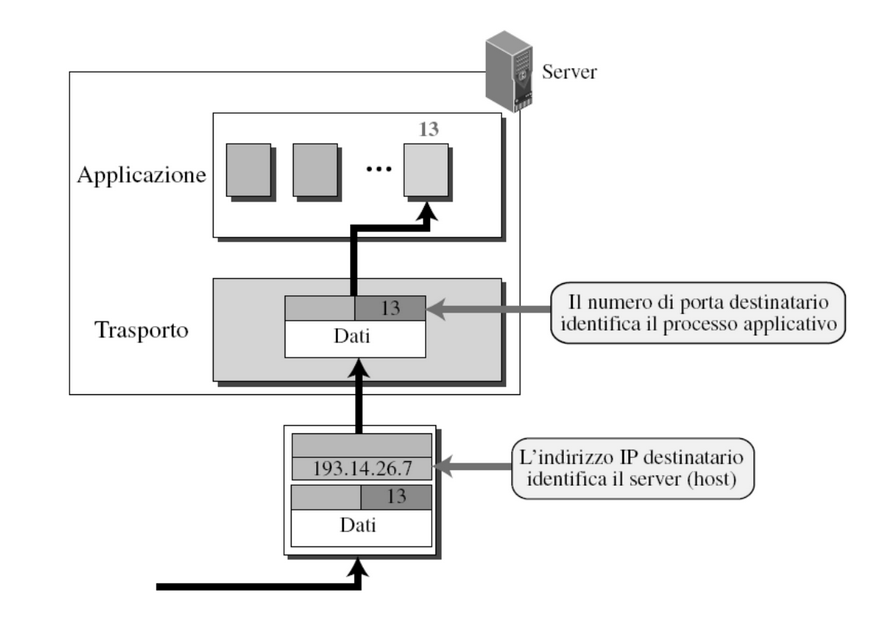
La combinazione di indirizzo IP + porta prende il nome di socket address.
Incapsulamento / Decapsulamento
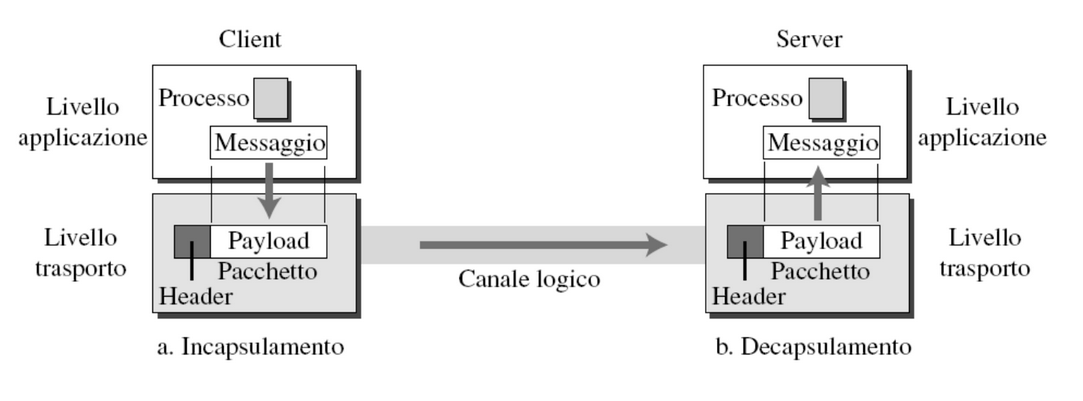
Prima di venire spediti vengono incapsulati ovvero viene aggiunto un header che verrà poi riconosciuto quando arriva a destinazione.
Questi pacchetti si chiamano:
- segmenti se usiamo TCP
- datagrammi utente se usiamo UDP
Questo processo prende anche il nome di Multiplexing / Demultiplexing
Multiplexing - Demultiplexing
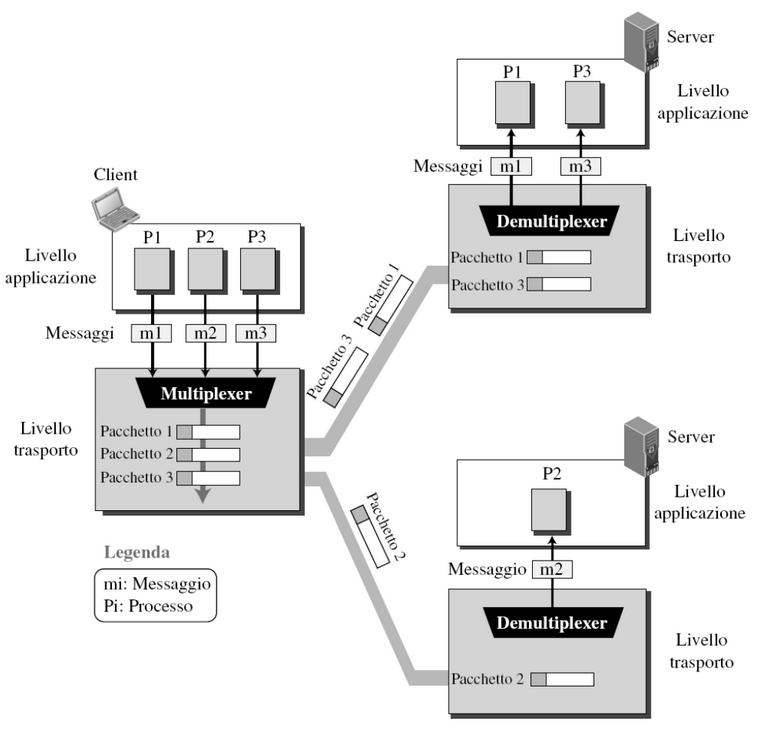
Multiplexing
Il multiplexing a livello mittente raccoglie i dati da vari socket e li incapsula con l’intestazione corrispondente che verrà poi usata per il demultiplexing.
Ad esempio se in un host abbiamo due processi uno FTP e uno HTTP l’host dovrà raccogliere i dati da questi socket e passarli al livello di rete
Demultiplexing
Deve consegnare i segmenti ricevuti al socket proprietario, come li riconosce? Grazie agli header di intestazione di ogni messaggio.
Come funziona nello specifico il demultiplexing?
- L’host riceve i datagrammi IP, ognuno di questi ha un indirizzo IP di origine e di destinazione
- Ogni datagramma trasporta un segmento a livello di trasporto
- Ogni segmento ha un numero di porta per origine e uno per destinazione
I pacchetti UDP e TCP sono strutturati nel seguente modo:
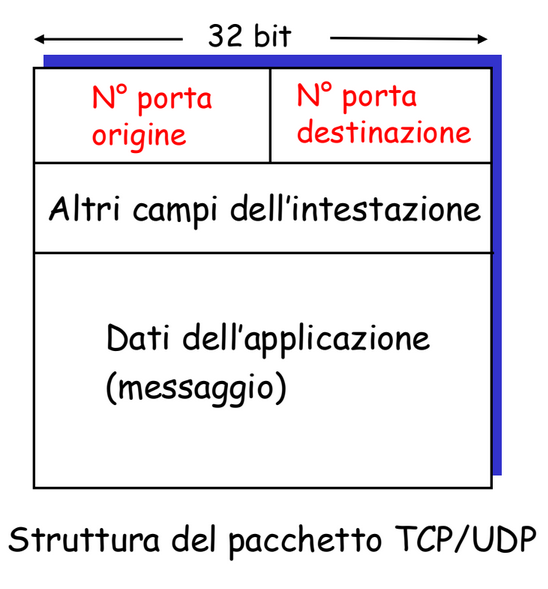
I campi per la porta occupano 16 bit e possono assumere valori da 0 a 65535 dove i primi 1023 sono usati per servizi specifici, vengono chiamati well known-port number.
Quindi in generale quello che succede è questo:
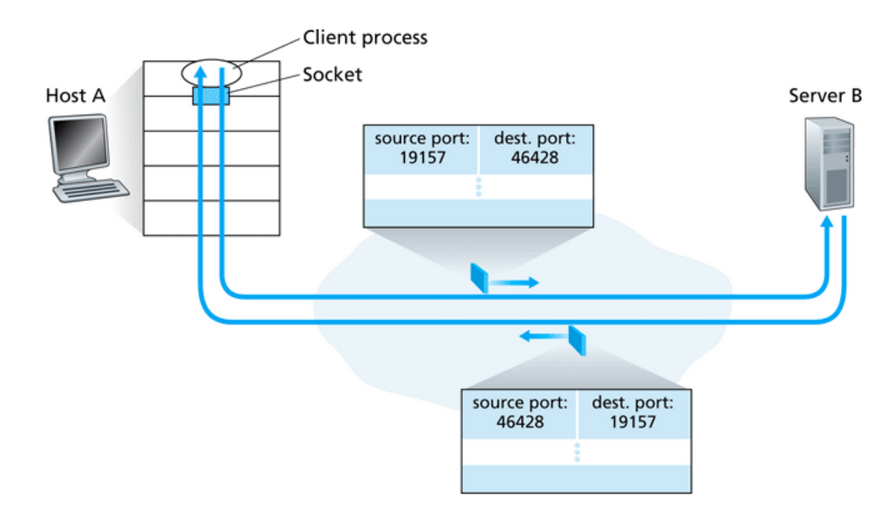
Socket
Come detto prima i socket permettono la comunicazione fra processi, questi però appaiono si come terminali o file ma in realtà non sono entità fisiche, sono delle astrazioni, una struttura dati creata dal programma applicativo.
Comunicare tra un processo client e uno server significa comunicare tra due socket.
Sono composti da:
- 32 bit di indirizzo IP
- 16 bit numero di porta
Individuare i socket address
L’interazione tra client e server è bidirezionale, ci serve quindi una coppia di indirizzi socket uno locale e uno remoto ovvero mittente e destinatario. Questi due indirizzi si scambiano di posto a seconda del ruolo ovvero il mittente in una direzione è il destinatario nell’altra.
Come vengono individuati questi indirizzi?
Lato Client
Il client ha bisogno di socket address locale (client) e remoto (server)
- Socket address locale: Viene fornito dal sistema operativo questo infatti conosce l’indirizzo IP del computer sul quale il client è in esecuzione e anche il numero di porta assegnato.
- Socket address remoto: Il numero di porta varia in base all’applicazione che stiamo usando, l’indirizzo viene fornito dal DNS oppure il socket intero è conosciuto dal programmatore se ad esempio sta testando un’applicazione
Lato Server
Anche il server ovviamente ha bisogno di socket address locale (server) e remoto (client)
- Socket address locale: Fornito dal sistema operativo, conosce l’indirizzo IP del computer e il numero di porta è noto al server perché assegnato dal progettista.
- Socket address remoto: è il socket address locale del client che si connette, questo viene trovato dal server all’interno del pacchetto di richiesta.
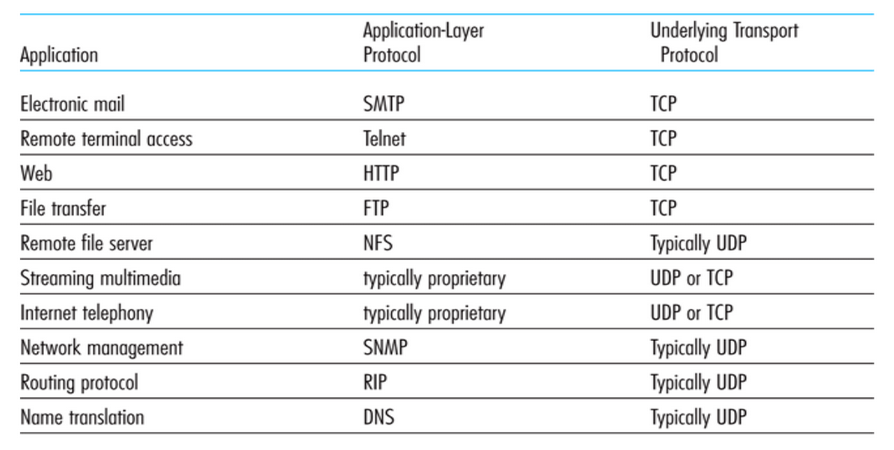
Servizi di Trasporto
Usiamo 2 servizi:
- TCP: Affidabile ma più lento
- UDP: Non affidabile ma più veloce
TCP
Si dice orientato alla connessione ovvero che è richiesto un setup fra i processi client e server.
Funziona come un tubo dove il trasmettitore spinge i bit da una estremità e il ricevitore li prende dall’altra, viene quindi mantenuto l’ordine di trasmissione.
Il TCP offre:
- Trasporto Affidabile
- Controllo di flusso: il mittente evita il sovraccarico del destinatario
- Controllo della congestione: se la rete è sovraccaricata si riduce l’invio di dati
Non offre:
- sistemi di sicurezza dei dati
- temporizzazione
- garanzia su ampiezza di banda minima
UDP
Funziona senza connessione ovvero non è richiesto alcun setup fra processi client e server.
Abbiamo un trasferimento inaffidabile infatti i dati potrebbero non arrivare nello stesso ordine in cui li inviamo.
Inoltre non offre alcuni servizi del TCP il controllo del flusso o della congestione.
Per cosa viene usato quindi UDP? Principalmente per dati che appunto non richiedono affidabilità come ad esempio streaming video o telefonia internet come Skype.
Vediamolo più nel dettaglio
UDP - User Datagram Protocol
È un protocollo di trasporto inaffidabile e privo di connessione, ci offre i seguenti servizi:
- Comunicazione tramite socket
- Multiplexing e demultiplexing dei pacchetti
- Incapsulamento e decapsulamento
Non fornisce controllo errori (è ammesso solo checksum), flusso o congestione.
Il mittente invia i pacchetti uno dopo l’altro e non si preoccupa dell’effettivo arrivo al destinatario:
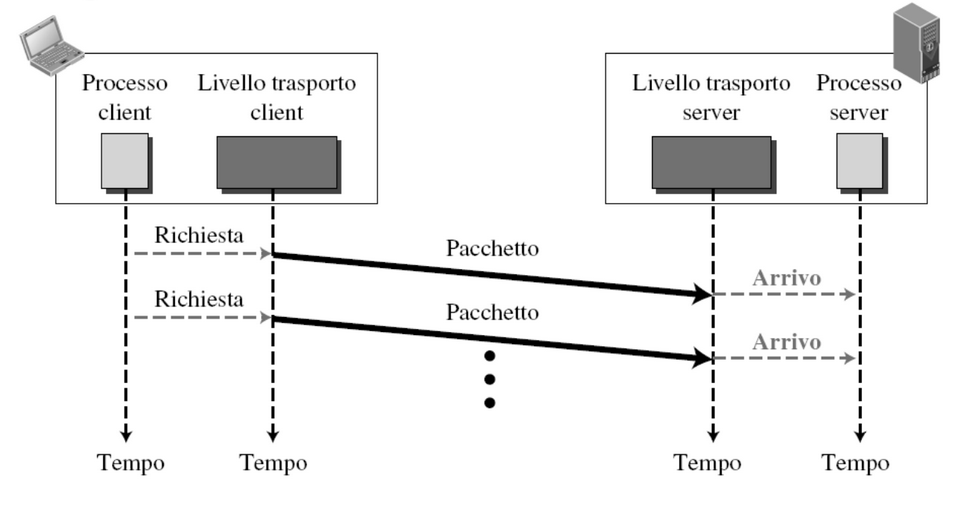
Inoltre dato che ogni pacchetto è indipendente dagli altri e non c’è coordinazione tra livello di trasporto mittente e destinatario si verificano anche situazioni simili:
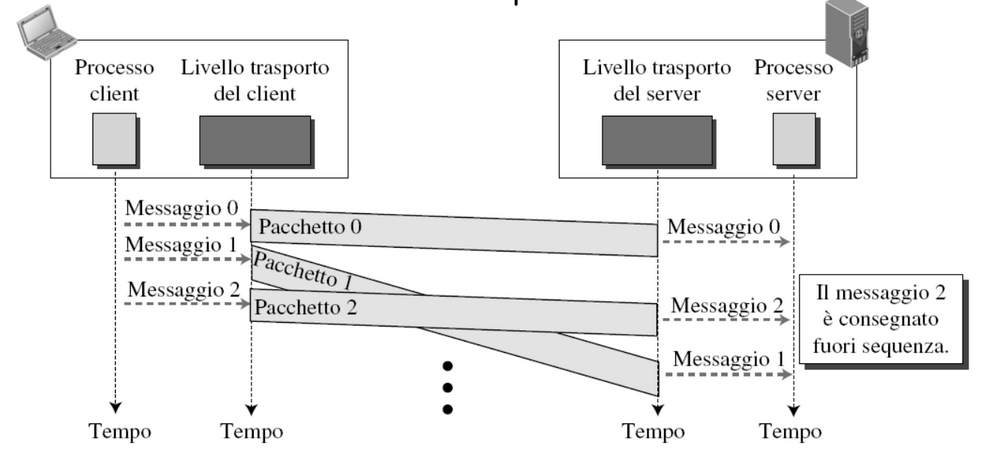
Ovvero dove i pacchetti arrivano in un ordine diverso da quello in cui sono stati spediti.
Rappresentazione tramite FSM
Possiamo rappresentare il comportamento di un protocollo di trasporto come un automa a stati finiti, questo rimane in uno stato finché un evento non lo modifica.
La rappresentazione per UDP è molto semplice:
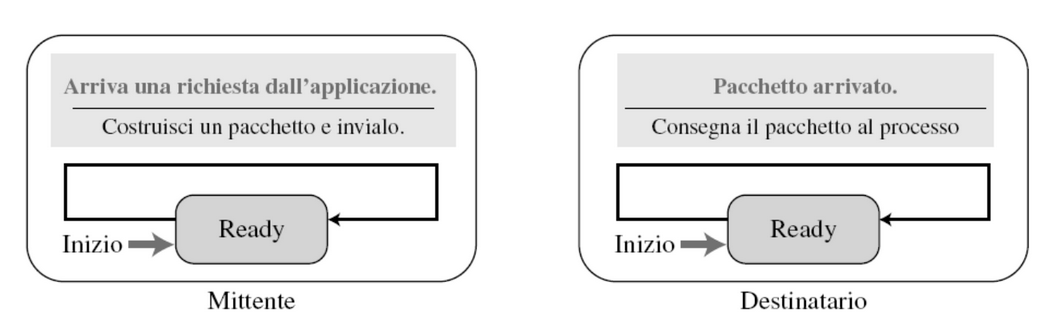
Abbiamo soltanto lo stato ready e quando arriva un pacchetto o quando dobbiamo spedirlo uno effettua l’azione e una volta terminata ritorna nello stato ready.
Datagrammi UDP
Dato che non c’è flusso di dati, i processi devono inviare richieste di dimensioni sufficientemente piccole per essere inserite in un singolo datagramma.
Solo i processi che usano messaggi di dimensioni inferiori a 65507 byte possono utilizzare UDP, questo perché abbiamo:
- 65535 - 8 byte di intestazione UDP e -20 byte di intestazione IP
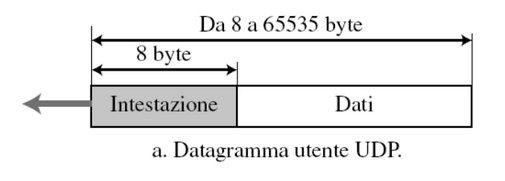
Come sono strutturati i datagrammi UDP?
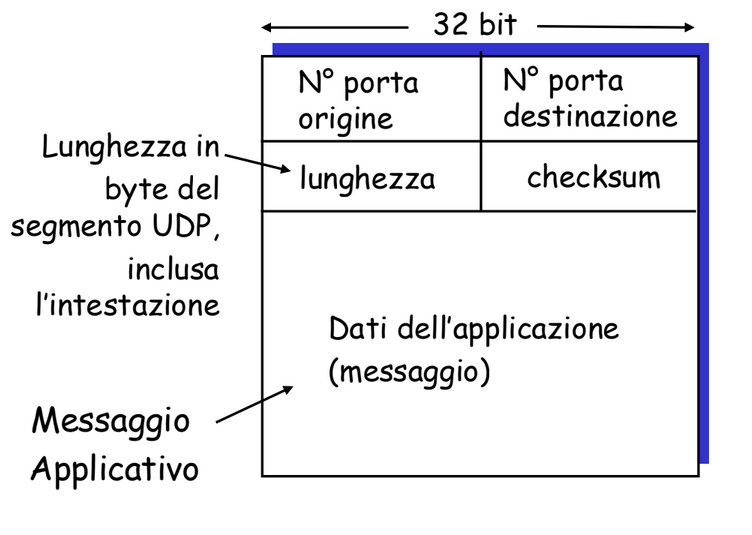
Cosa indica il campo checksum?
Checksum UDP
Serve a rilevare errori nel datagramma trasmesso, cosa devono fare mittente e destinatario?
Mittente
- Divide il messaggio in “parole” da 16 bit
- Il checksum viene inizialmente impostato a 0
- Tutte le parole incluso il checksum vengono sommate usando l’addizione complemento a 1
- Viene fatto il complemento a 1 della somma e quello che otteniamo è il checksum
- Viene inviato il messaggio
Destinatario
- Viene ricevuto il messaggio
- Viene diviso in parole da 16 bit
- Tutte le parole vengono sommate con complemento a 1
- Viene fatto il complemento a 1 della somma ed il risultato è il nuovo checksum
- Se il checksum vale 0 allora il messaggio viene accettato altrimenti si scarta
Esempio di checksum
Dobbiamo inviare la seguente stringa da 32 bit:
11100110011001101101010101010101
La dividiamo quindi in parole da 16 e le sommiamo

Altre info su UDP
UDP viene utilizzato anche da DNS, le applicazioni DNS inviano una query e aspettano una risposta dal server, se questa non arriva semplicemente fanno una query ad altri server.
Quindi la semplicità delle richieste DNS giustifica l’utilizzo di UDP che è anche più veloce.
In generale viene spesso utilizzato per applicazioni di streaming multimediale dato che tollera una limitata perdita di pacchetti:
Intro a TCP
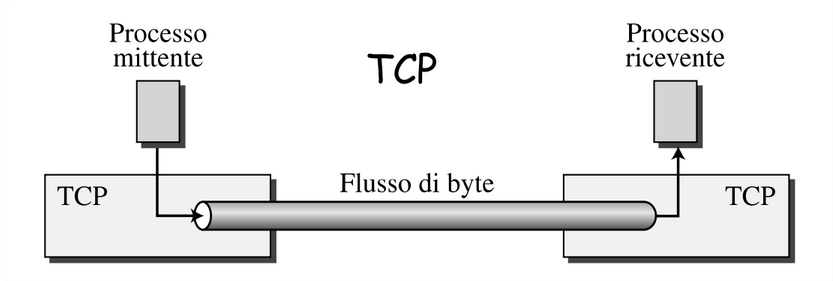
A differenza di UDP possiamo vederlo come un flusso di byte che passa in tubo:
Il TCP a differenza di UDP ci offre anche:
- Un trasporto orientato alla connessione dove serve quindi un setup fra i client
- Controllo del flusso
- Controllo degli errori
- Controllo della congestione
Demultiplexing orientato alla connessione
La socket TCP è identificata da 4 parametri:
- Indirizzo IP e porta di origine
- Indirizzo IP e porta di destinazione
Un host server può supportare più socket TCP contemporanee dato che ogni socket è identificata dai 4 parametri. Si avrà una socket differente anche per lo stesso client, ogni richiesta viene trasmessa su una diversa socket.
Essenzialmente il server accetta tutte le connessioni sulla stessa socket e poi le sposta su una porta differente.
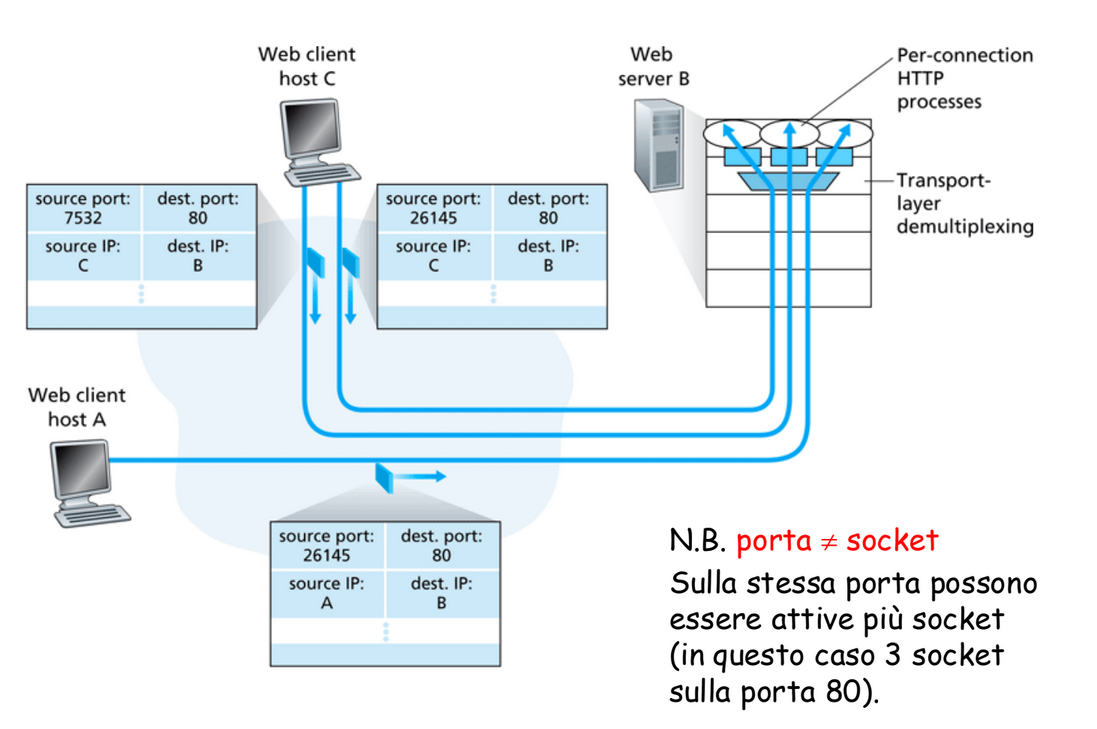
Inoltre essendo appunto un servizio orientato alla connessione non si verifica più l’evento che i messaggi arrivano in ordine diverso dall’invio, anche nel caso in cui in messaggio arrivi prima questo viene memorizzato a livello di trasporto e trasmesso solo dopo l’arrivo del suo predecessore.
Rappresentazione tramite FSM
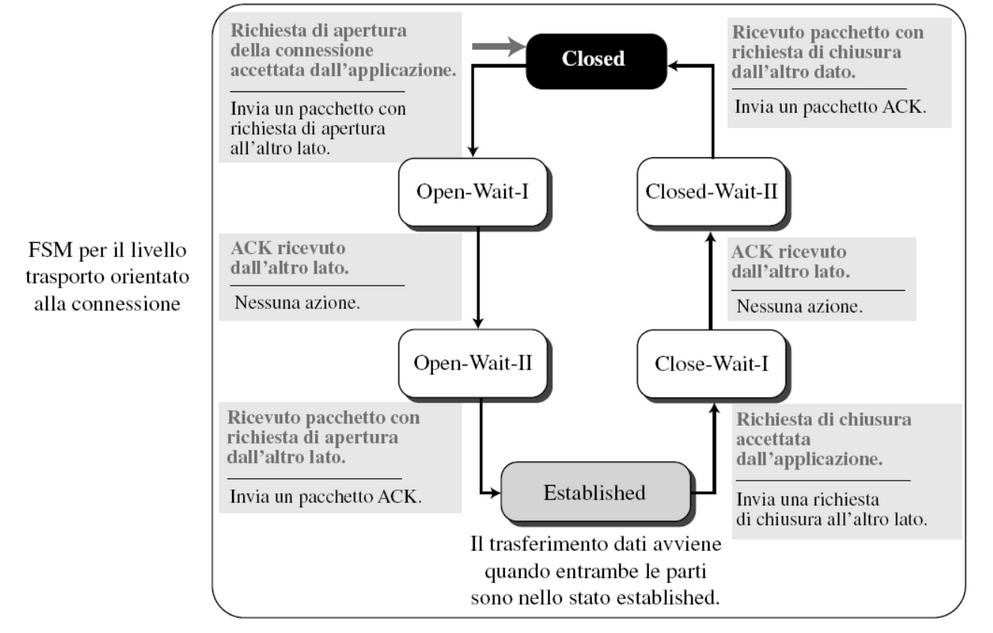
Quindi l’apertura della connessione inizia dallo stato closed dove i due host si inviano dei pacchetti per stabilire la connessione. Una volta stabilita possono scambiarsi i dati e quando hanno terminato si inviano un messaggio per chiudere la connessione.
Controllo di Flusso
Abbiamo detto che TCP ci offre il controllo del flusso, cosa significa?
Quando un host produce dati che un altro host deve consumare deve esserci equilibrio fra velocità di produzione e di consumo:
- Se produzione > consumo: il consumatore potrebbe sovraccaricarsi e potrebbe eliminare alcuni dati
- Se consumo > produzione: Il consumatore rimane in attesa di dati riducendo l’efficienza del sistema.
Il controllo del flusso però si occupa principalmente della prima problematica ovvero la perdita di dati.
Ci occupiamo del controllo del flusso a livello di trasporto, individuiamo 4 entità:
- Processo e trasporto mittente
- Processo e trasporto destinatario
Ci sono 2 casi di controllo di flusso:
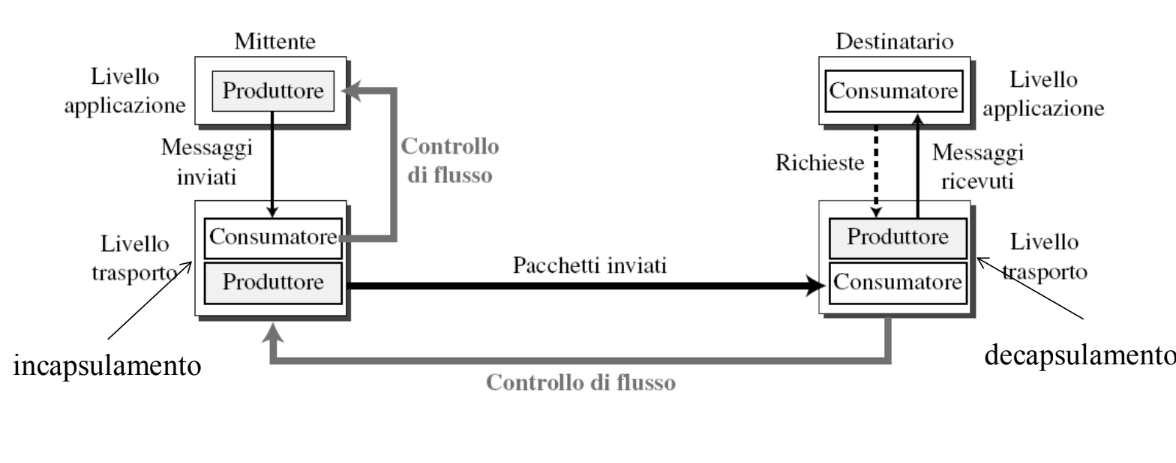
Come possiamo realizzare il controllo del flusso?
- Implementiamo dei buffer ovvero delle zone di memoria che memorizzano i pacchetti
- Il consumatore invia dei segnali al produttore:
- Il livello trasporto del mittente segnala al livello applicazione di sospendere l’invio dei messaggi quando il buffer è saturo, quando si svuota si può riprendere l’invio.
- Il livello trasporto del destinatario segnala al trasporto del mittente di sospendere l’invio dei messaggi quando il buffer è saturo, quando si svuota si può riprendere.
Controllo degli Errori
Dato che il livello di rete è inaffidabile, l’affidabilità va implementata a livello di trasporto e per farlo abbiamo bisogno di implementare un controllo degli errori che agisce sui pacchetti:
- Rilevare e scartare pacchetti corrotti
- Tracciare i pacchetti persi e il loro rinvio
- Riconoscere pacchetti duplicati
- Bufferizzare i pacchetti fuori sequenza finché non arrivano quelli mancanti
È il livello trasporto del destinatario a gestire il controllo errori e segnalarli al livello trasporto mittente.
Come si realizza?
- Numeriamo i pacchetti con un campo nell’header, questa sarà una numerazione sequenziale
Poiché il numero di sequenza va inserito nell’intestazione, va specificata la dimensione massima:
- Se l’intestazione prevede bit per il numero di sequenza questi possono assumere valori da a
- I numeri di sequenza sono quindi considerati in modulo (ciclici)
Questo numero di sequenza serve al destinatario per:
- Capire la sequenza dei pacchetti in arrivo
- Se ci sono pacchetti persi
- Se ci sono pacchetti duplicati
Ma il mittente come fa a capire che un pacchetto è andato perso?
- Il destinatario ad un ogni pacchetto ricevuto invia un ACK (acknowledgment) con il numero del pacchetto che ha ricevuto che funziona da notifica di ricezione.
commenti funny di instagram
Integrazione del controllo degli errori e del flusso
Abbiamo visto che:
- Il controllo del flusso richiede 2 buffer uno per il mittente e uno per il destinatario
- Il controllo degli errori richiede un numero di sequenza e dei messaggi ACK
Possiamo combinare i due meccanismi tramite dei buffer numerati nel mittente e nel destinatario. Come funzionano?
Mittente
- Quando prepara un pacchetto usa come come numero di sequenza il numero della prima locazione libera nel buffer
- Quando invia il pacchetto ne memorizza una copia nella locazione del buffer
- Quando riceve il segnale ACK di un pacchetto libera la posizione di memoria occupata da quel pacchetto
Destinatario
- Quando riceve un pacchetto con numero lo memorizza nella locazione fino a quando il livello applicazione non è pronto a riceverlo
- Quando passa il pacchetto al livello applicazione invia ACK al mittente
Dato che i numeri di sequenza sono calcolati in modulo e quindi ciclici possiamo rappresentarli tramite un cerchio. Il buffer viene rappresentato con un insieme di settori chiamati sliding windows che occupano una parte del cerchio.
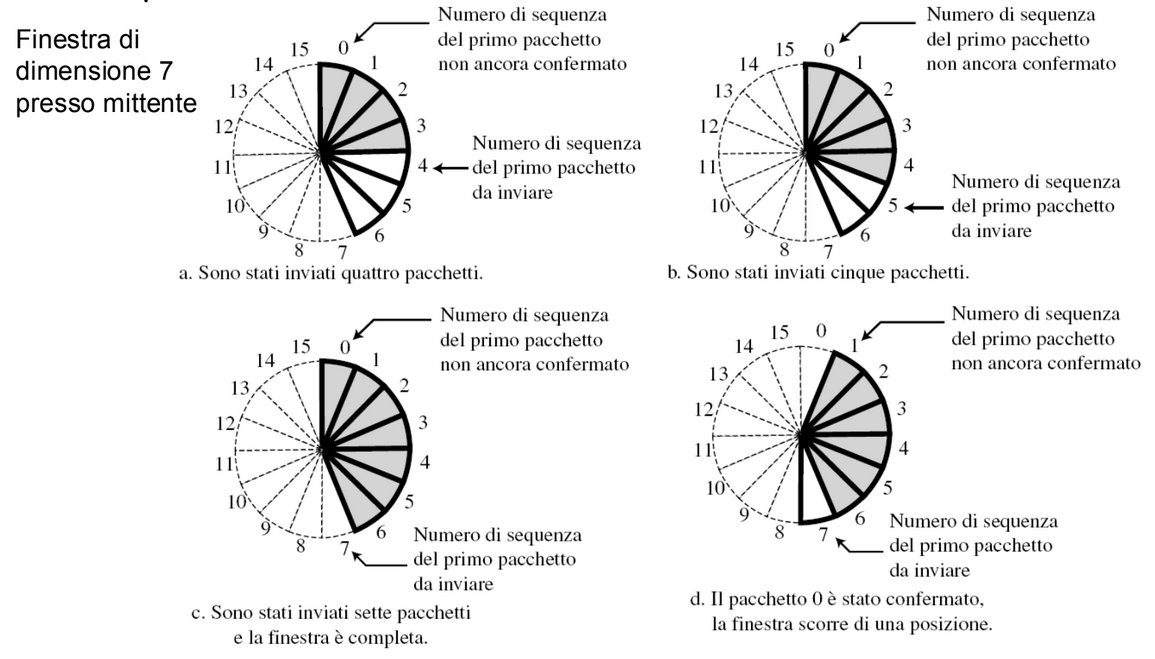
Quindi finché il destinatario non svuota il suo buffer non vengono inviati nuovi pacchetti in modo da non sovraccaricare la rete.
Nella realtà per memorizzare i numeri di sequenza del prossimo pacchetto da inviare e dell’ultimo inviato si usano delle variabili e le sliding windows vengono rappresentate in modo lineare:

Controllo della Congestione
Nella commutazione a pacchetto la congestione avviene se il carico della rete ovvero il numero di pacchetti su di essa è superiore alla sua capacità, con il controllo della congestione usiamo delle tecniche per fare in modo che questa situazione non si verifichi mai.
Si parla di congestione perché arrivano più pacchetti di quelli che router e switch riescono a gestire e quindi si riempiono le loro code portando alla perdita di pacchetti e rallentamenti.