Ci troviamo nel livello applicazione, la prima che troviamo andando a vedere la storia è il Worl Wide Web ovvero un’applicazione nata per scambiare informazioni tra ricercatori di varie università in diverse nazioni.
Inizialmente si basava su documenti di testo collegati fra loro tramite dei collegamenti ipertestuali (link), successivamente è stato creato il primo browser grafico ed è stata creata la W3C (World Wide Web Consortium) ovvero un’organizzazione incentrata sullo sviluppo del Web e la standardizzazione dei protocolli.
Il WWW è formato da varie componenti:
- Web Client - ovvero i browser che utilizza l’utente
- Web Server - Dove sono memorizzate le applicazioni vere e proprie (ad ese. Apache)
- HTML: Linguaggio per scrivere pagine web
- HTTP: Protocollo per la comunicazione tra client e server
Quindi la rete si basa su un funzionamento on demand ovvero un client invia una richiesta per una pagina web e il server gliela invia.
Architettura Generale di un Browser
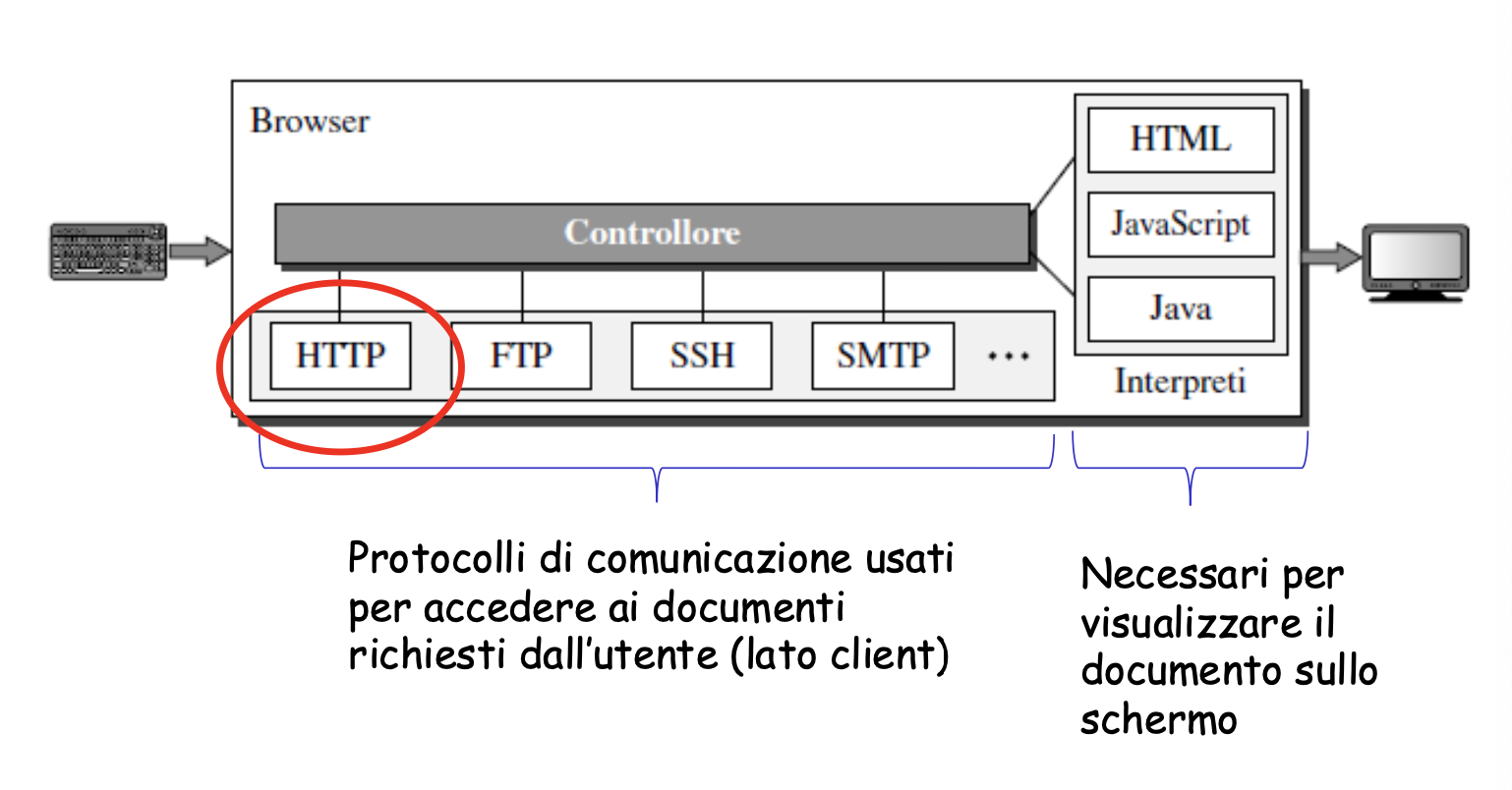
Elementi Fondamentali
Una pagina Web è costituita da oggetti che possono essere:
- Un file HTML, un’immagine JPEG, un’applet Java ecc…
- Ogni pagina però di base è un file HTML che include diversi oggetti referenziati
- Gli oggetti sono referenziati tramite degli URL (Uniform Resource Locator)
- es.
www.someschool.edu/someDept/pic.gif
- es.
Come funzionano gli URL? - Il problema al principio era quello di riuscire a localizzare una pagina, era possibile farlo tramite un identificatore univoco? No perché sapremmo si come si chiama ma non di preciso dove andarla a cercare.
Gli URL sono infatti composti da 3 parti:
- Il protocollo da usare per richiedere quella pagina
- Nome della macchina dove è situata la pagina
- Percorso del file all’interno di quella macchina
Quindi:

Per comunicare con una macchina questa “apre delle porte” ognuna per un tipo di protocollo o servizio, i protocolli hanno delle porte standard che vengono utilizzate se non le specifichiamo dopo il nome della macchina, quindi ad esempio:
protocol://host/pathuserà la porta standard del protocolloprotocol://host:porta/pathutilizzerà la porta specificata
Arriviamo ai documenti veri e proprio, esistono vari tipi di documenti web:
- Statici - Contenuto predeterminato e già memorizzato sul server
- Dinamico - Il contenuto viene creato dal server nel momento della ricezione di una richiesta
- Attivo - Contiene degli script che vengono eseguiti sulla macchina del client
Come vengono richiesti e ricevuti questi documenti nello specifico?
HTTP (RFC 2616)
Come detto prima HTTP si basa sul modello Client - Server, il protocollo definisce in che modo i client devono richiedere le pagine e come i server devono trasferirle ai client. Nello specifico:
- Lato Client
- Il browser determina dall’URL host e nome del file
- Esegue la connessione TCP alla porta 80 (standard)
- Invia una richiesta per il file
- Riceve il file
- Chiude la connessione
- Visualizza il file
- Lato Server
- Accetta la connessione TCP dal client
- Riceve il nome del file richiesto
- Recupera il file dal disco
- Invia il file al client
- Rilascia la connessione
Non tutte le risorse che il client richiede si troveranno sullo stesso server, in modo trasparente all’utente il client richiederà le informazioni anche da altri server:
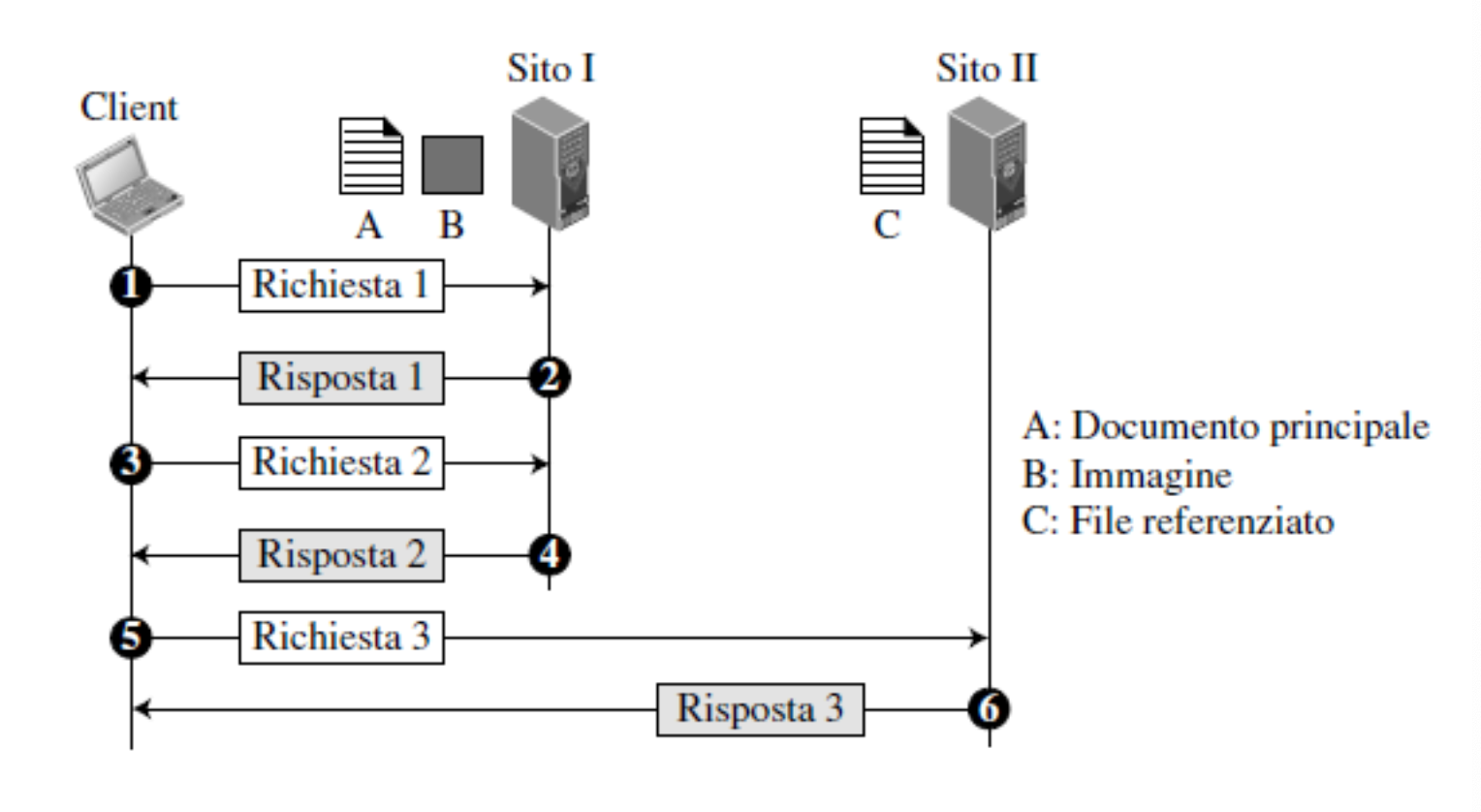
Connessioni HTTP
Ne esistono di due tipi
- Connessioni non persistenti - Per ogni oggetto che richiediamo va aperta una nuova connessione TCP e chiusa a fine trasferimento.
- Connessioni persistenti - È la modalità usata di default, tramite una singola connessione possono essere trasmessi più oggetti. La connessione non viene più chiusa a fine trasferimento ma quando rimane inattiva per molto tempo.
Connessioni non Persistenti
Supponiamo che l’utente immetta come URL www.someSchool.edu/someDepartment/home.index e che questo documento contenga riferimenti a 10 immagini jpeg.
| Client | Server |
|---|---|
| 1a - Inizializza una connessione TCP | 1b - Il server accetta la connessione |
2 - Il client trasmette una richiesta dove indica che vuole il file someDepartment/home.index | 3 - Il server crea il messaggio di risposta che contiene l’oggetto richiesto e lo spedisce |
| 4 - Il server chiude la connessione TCP | |
| 5 - Il client riceve il messaggio e visualizza il documento html che contiene i 10 riferimenti | |
| 6 - Vengono ripetuti i precedenti passaggi per ogni documento |
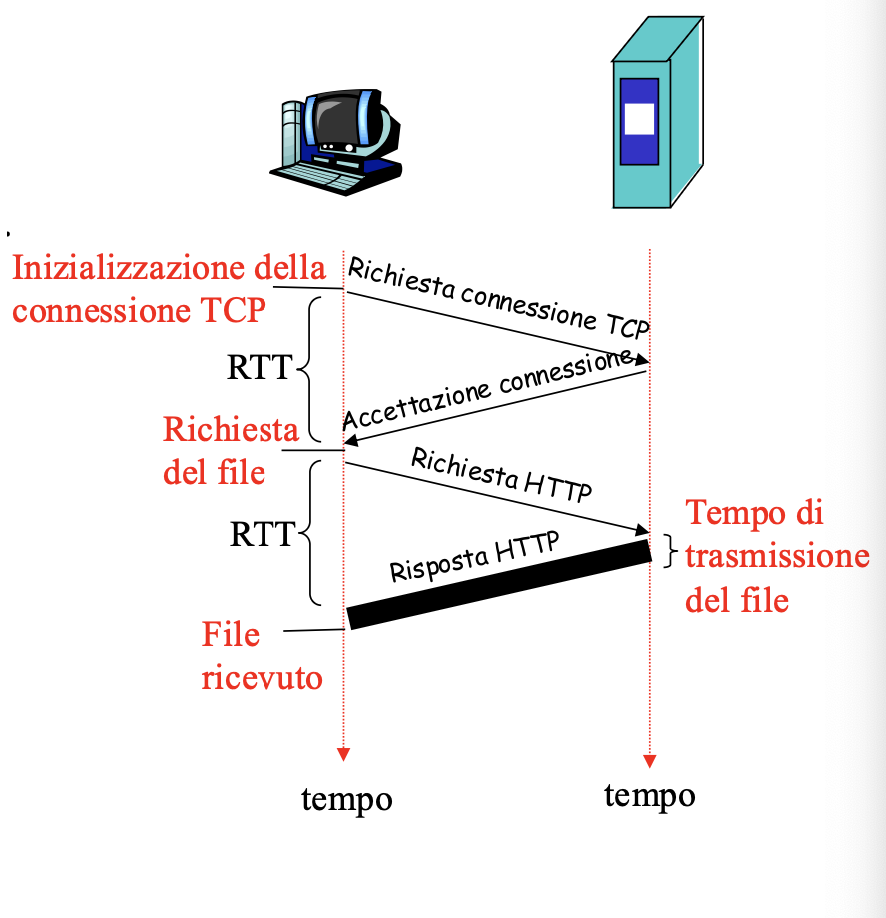
Per calcolare il tempo di risposta in queste connessione definiamo il concetto di RTT.
RTT - Round Trip Time
È il tempo impiegato da un piccolo pacchetto per andare dal client al server e tornare indietro. Questo include i ritardi di propagazione, accodamento e di elaborazione del pacchetto.
Il tempo di risposta è dato da:
- Un RTT per inizializzare la connessione TCP
- Un RTT per la richiesta HTTP e i primi byte della risposta
- Tempo di trasmissione del file
- Quindi in totale:
Connessioni Persistenti
Gli svantaggi delle connessioni non persistenti sono:
- Richiedono 2RTT per oggetto
- Overhead nel sistema dato che per ogni oggetto va creata una connessione
- I browser spesso aprono connessioni parallele per caricare oggetti referenziati
Con le connessioni persistenti andiamo a risolvere alcuni dei problemi delle non persistenti, infatti:
- Il server lascia aperta la connessione dopo l’invio di una risposta
- In questo modo i successivi invii tra client / server usano la stessa connessione
- Non abbiamo quindi bisogno di un RTT per ogni oggetto ma di uno soltanto per la connessione e uno per ogni oggetto ricevuto.
Formato dei messaggi in una richiesta HTTP
Vediamo come sono strutturati i messaggi che inviamo
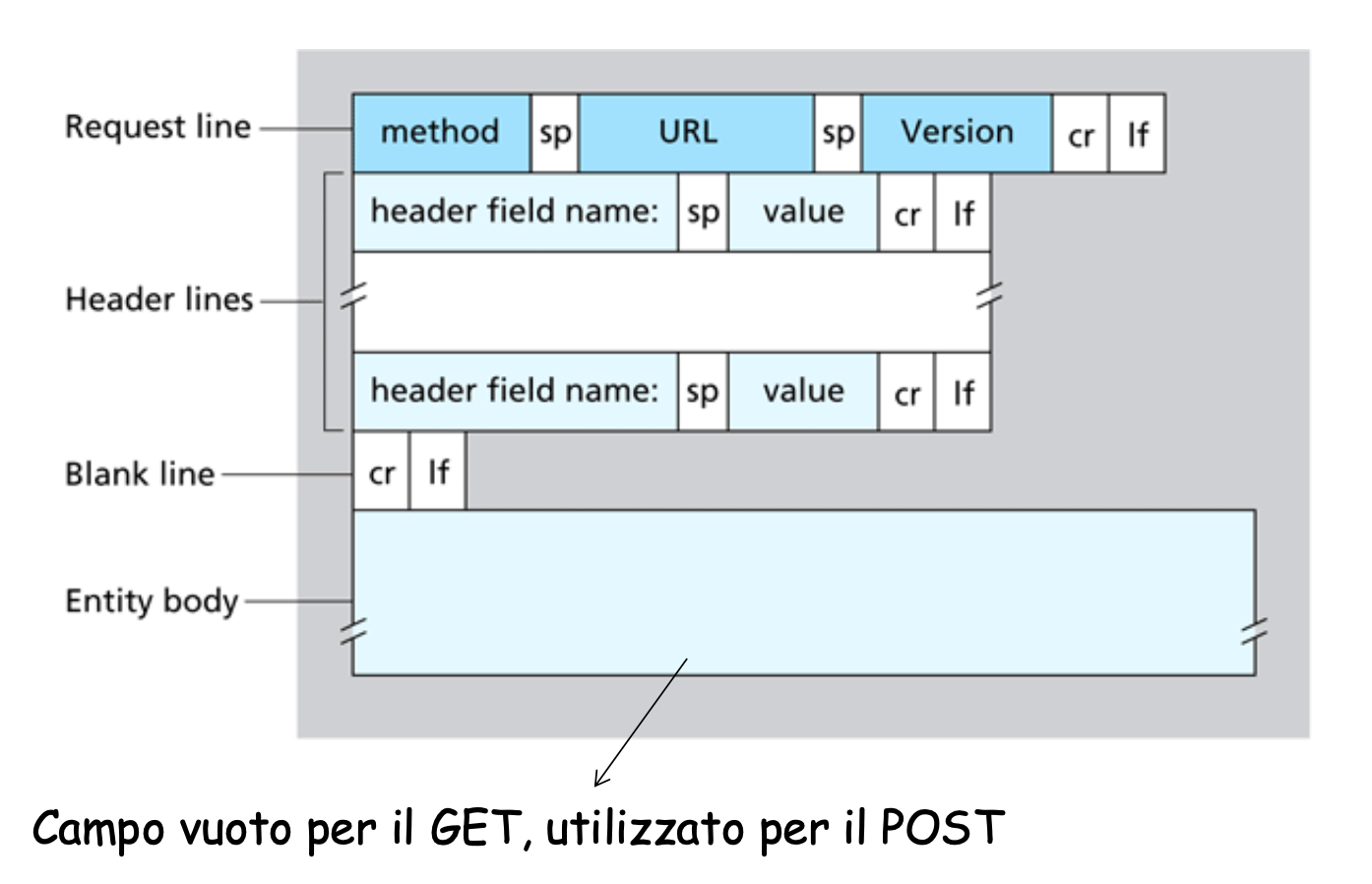
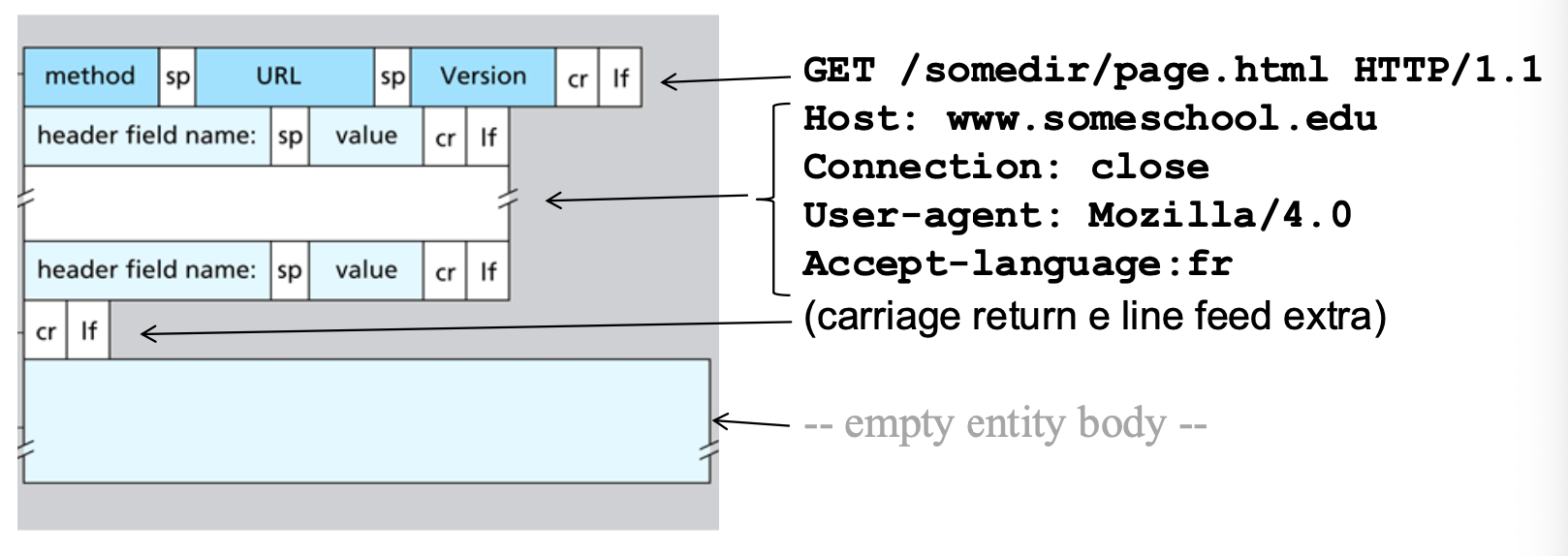
Vediamo un esempio:
GET /somedir/page.html HTTP/1.1
Host: www.someschool.edu
Connection: close
User-agent: Mozilla/4.0
Accept-language:fr- La prima riga è riga di richiesta dove vengono inseriti i comandi GET - POST - HEAD.
- Le successive sono righe di intestazione.
- A fine messaggio troviamo carriage return e un life feed.
A confronto:
Upload dell’input di un form
Quando compiliamo un form ad esempio per iscrizione a qualche pagina o altro abbiamo diversi metodi per caricarlo:
Metodo POST - La pagina web include un form per l’input dell’utente e questo input arriva al server nel body dell’entità.
Metodo GET - Alternativamente al metodo POST, possiamo usare il GET inserendo i dati del form nell’URL richiesto: www.sito.com/animalsearch?moneys&banana.
Tipi di Metodi - HTTP/1.1
- GET - Viene usato quando il client vuole scaricare un documento dal server. Il documento viene specificato all’interno dell’URL.
- HEAD - Utilizzato quando il client non vuole scaricare l’intero documento ma solo alcune informazioni di esso. Il server quindi in risposta non invia l’intero documento ma soltanto gli header richiesti.
- POST - Utilizzato per fornire input al server, questi vengono inseriti dall’utente in dei campi di un form. L’input arriva nel corpo del messaggio. Come detto prima è possibile utilizzare anche il GET inserendo i dati nell’URL.
- PUT - È utilizzato per memorizzare un documento nel server. Il documento viene fornito nel corpo del messaggio e la posizione di memorizzazione nell’URL.
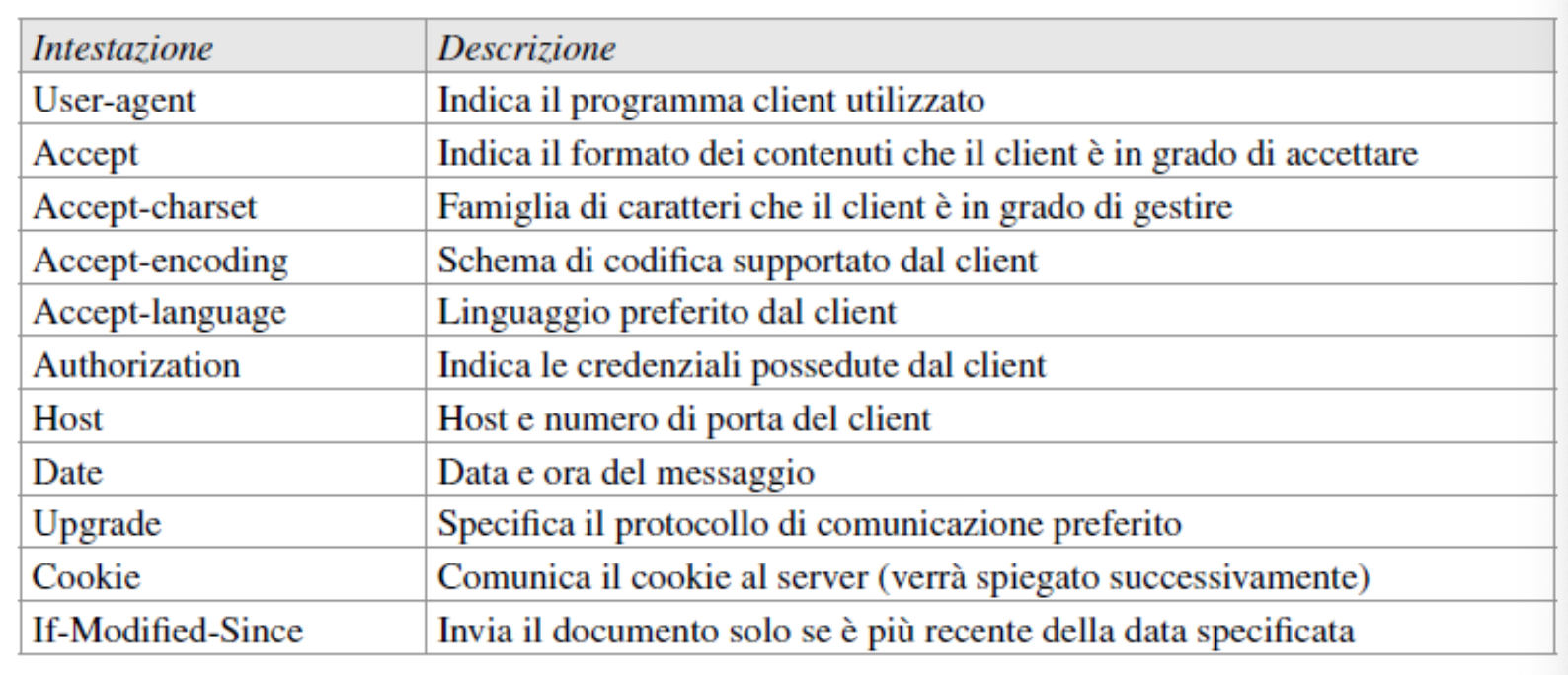
Intestazioni nella Richiesta
Alcune intestazioni che possiamo trovare:
Formato dei messaggi di Risposta
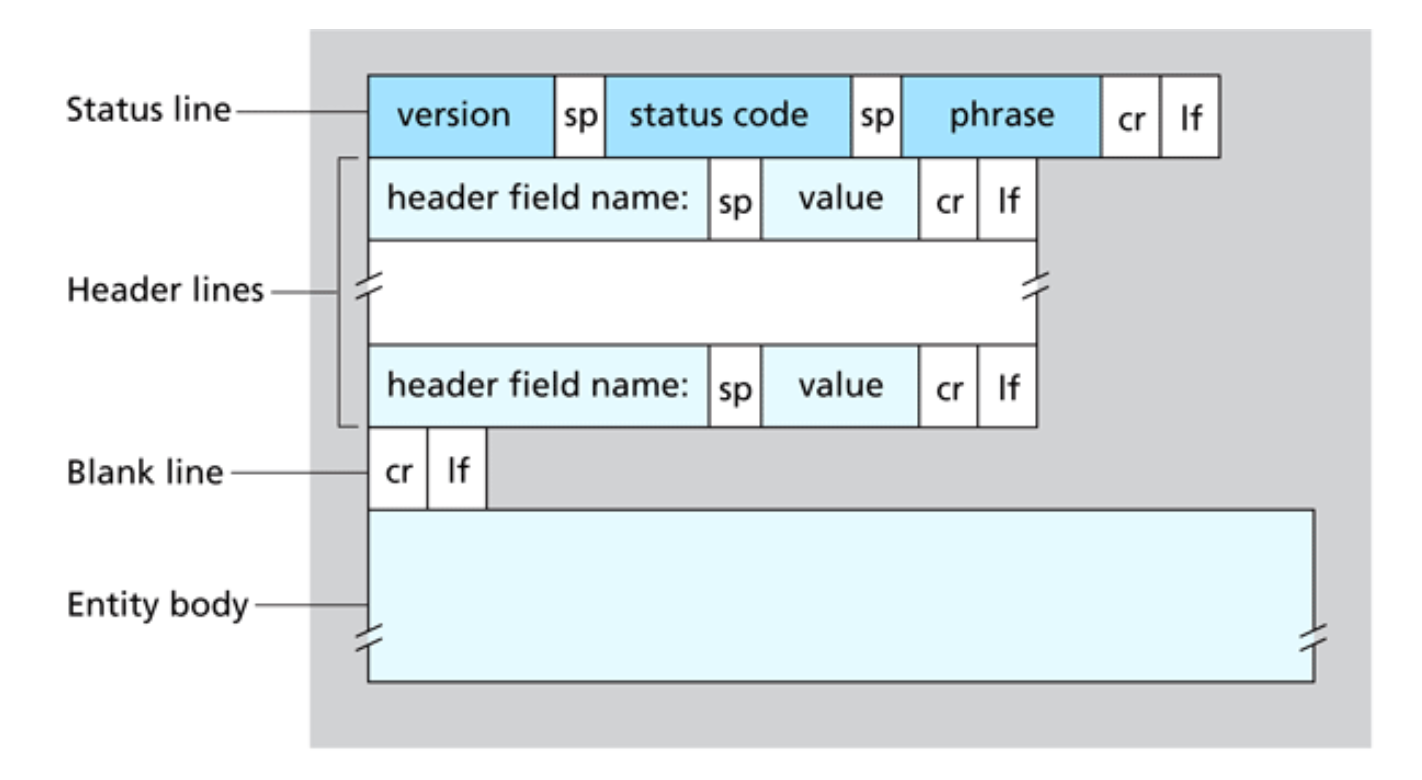
In questo caso i nomi diventano:
- La prima riga prende il nome di riga di stato
- Troviamo sempre le righe di intestazione
- Possiamo trovare altri dati come ad esempio gli oggetti richiesti
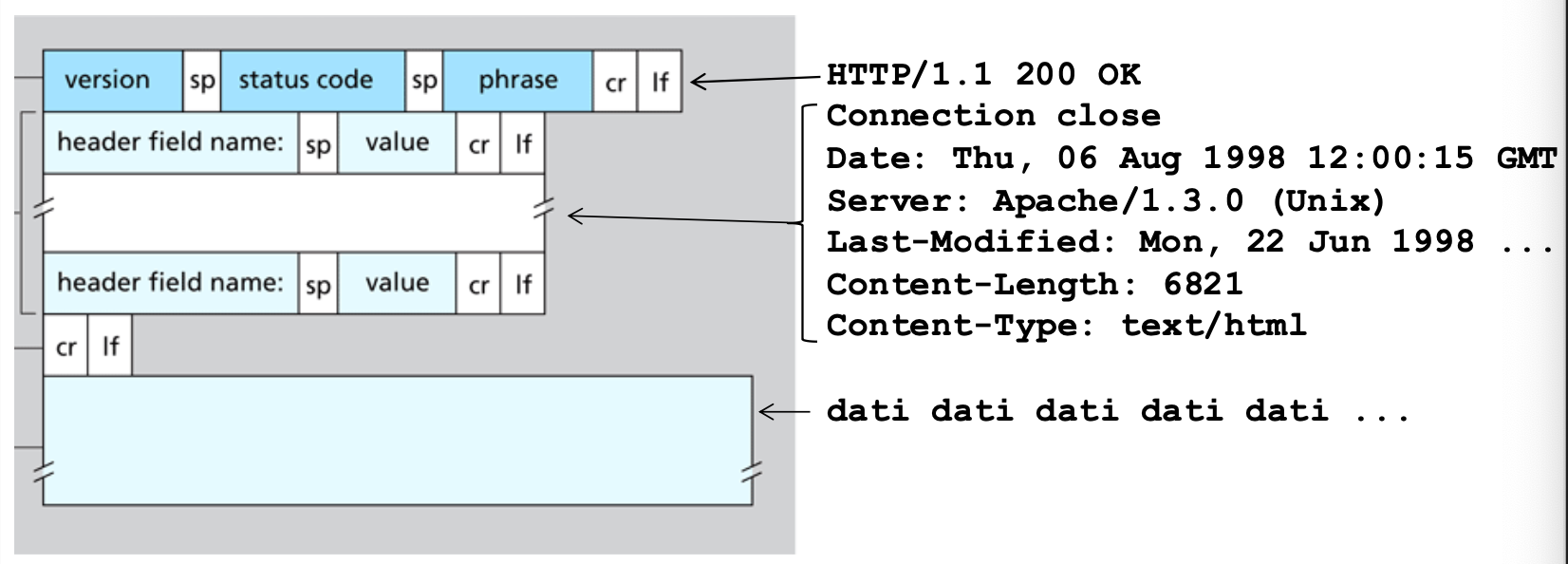
Esempio
HTTP/1.1 200 OK
Connection close
Date: Thu, 06 Aug 1998 12:00:15 GMT
Server: Apache/1.3.0 (Unix)
Last-Modified: Mon, 22 Jun 1998 ...
Content-Lenght: 6821
Content-Type: text/html
---
(altri dati)Vediamo anche qui un confronto:
Codici di Stato nella Risposta
Nella riga di stato troviamo i codici di stato che ci indicano lo stato della risposta ricevuta, alcuni esempi:
- 200 OK - La richiesta ha avuto successo
- 301 Moved Permanently - L’oggetto richiesto è stato trasferito e la nuova locazione viene specificata nell’intestazione
Locationdella risposta - 400 Bad Request - Il messaggio di richiesta non è stato compreso dal server
- 404 Not Found - Il documento richiesto non si trova sul server
- 505 HTTP Version Not Supported - Il server non ha la versione di protocollo HTTP
In generale la prima cifra del numero ci dice di che tipo è il codice:
- 1xx - Messaggi di Informazione
- 2xx - Successo
- 3xx - Reindirizzamento
- 4xx - Client Error
- 5xx - Server Error
Infine, le intestazioni della risposta sono:
Esempio GET
In questo esempio il client preleva un documento: viene usato il metodo GET per ottenere l’immagine individuata dal percorso. /usr/bin/image1
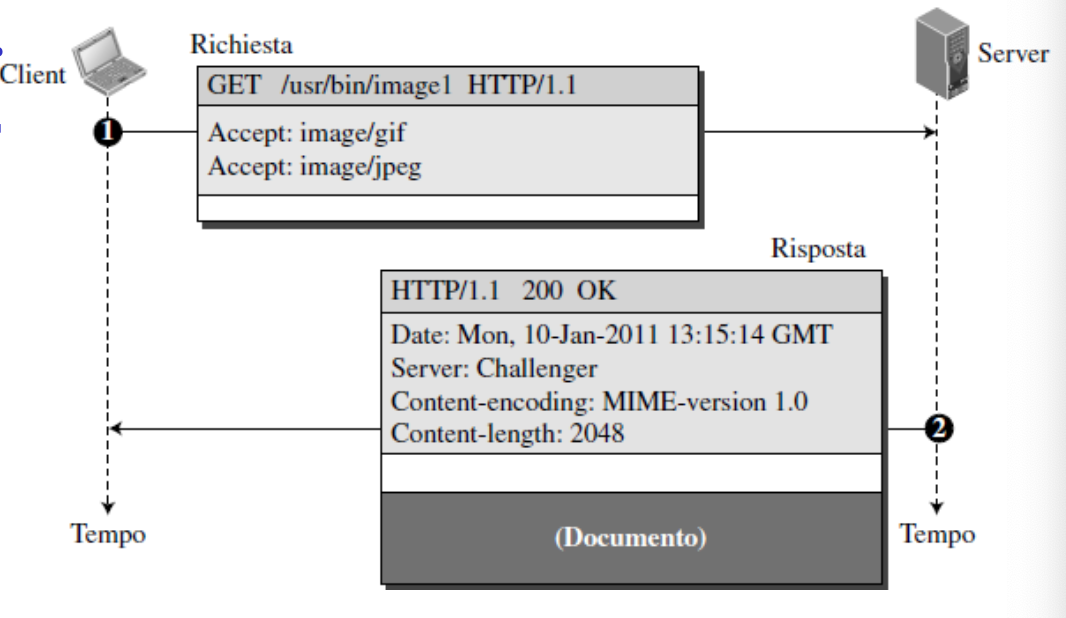
In questo caso notiamo che la riga di richiesta contiene il metodo GET, l’URL e la versione 1.1 del protocollo HTTP. L’intestazione specifica che il client accetta immagini nei formati GIF e JPEG. Il messaggio non ha un body.
La risposta contiene la riga di stato e quattro righe di intestazione:
- Data
- Server
- Metodo di codifica
- Lunghezza del documento
- Il corpo del messaggio segue l’intestazione
Esempio PUT
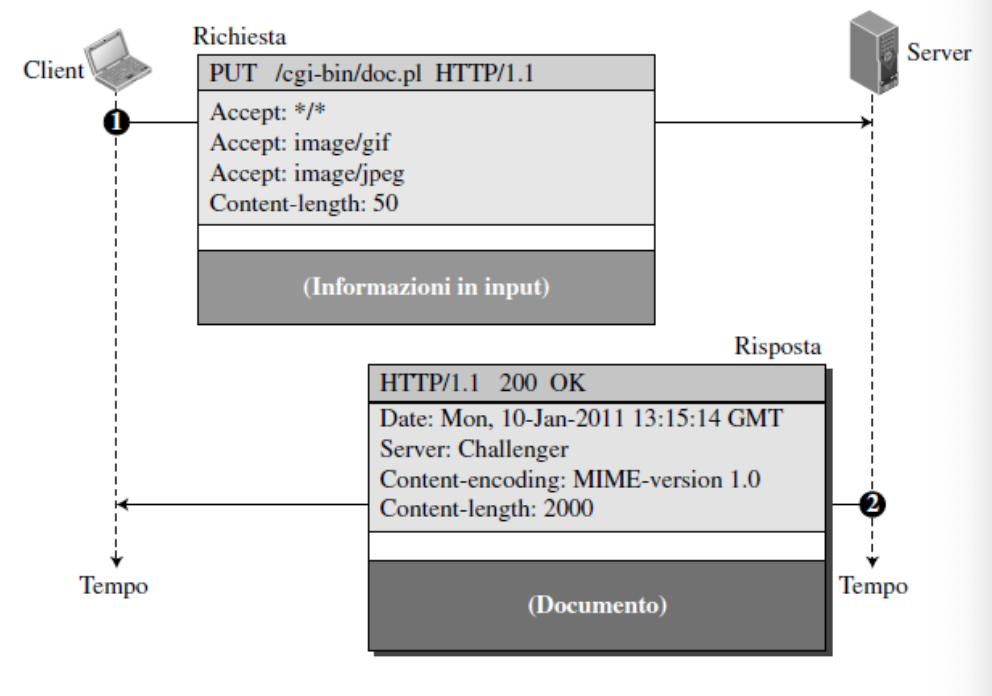
Il client spedisce al server una pagina web da pubblicare utilizzando il metodo PUT.
La riga di richiesta contiene il metodo PUT, l’URL e la versione 1.1 di HTTP. L’intestazione è composta da 4 righe e il corpo contiene la pagina web inviata
La risposta contiene la riga di stato e quattro righe di intestazione, il documento è incluso nel body della risposta.
Cookie
HTTP è un protocollo stateless ovvero, il server dopo aver servito il client se ne dimentica, quindi non mantiene informazioni su di esso. I protocolli che mantengono lo stato sono complessi dato che va memorizzato tutto quello che fa il client e se si verifica qualche errore le viste sullo stato di client e server potrebbero essere contrastanti.
In molti casi è necessario che il server si ricordi degli utenti ad esempio per:
- Offrire contenuti personalizzati in base alle preferenze di ogni utente
- Mantenere il carrello degli utenti nei siti di e-commerce
Per fare questo però gli indirizzi IP non sono adatti dato che gli utenti possono lavorare su dispositivi diversi e molti ISP assegnano lo stesso IP ai pacchetti in uscita provenienti da tutti gli utenti (tramite il NAT).
La soluzione è utilizzare i Cookie (RFC 6265).
Tramite i cookie possiamo creare una sessione di richieste e risposte HTTP con stato. La sessione rappresenta un concetto più esteso rispetto alle semplici richieste e risposte.
Ci possono essere diversi tipi di sessione in base al tipo di informazioni scambiate e la natura del sito, in generale però troviamo delle caratteristiche comuni:
- Inizio e fine
- Tempo di vita relativamente corto
- Client e server possono terminare la sessione
- La sessione è implicita nello scambio di informazioni di stato
Una sessione quindi non va vista come una connessione persistente ma come una connessione logica creata da richieste e risposte, possiamo quindi crearne una sia su connessioni persistenti che non.
Interazione utente-server con i cookie
Abbiamo bisogno di 4 componenti:
- Una riga di intestazione nel messaggio di risposta HTTP
- Una riga di intestazione nel messaggio di richiesta HTTP
- Un file cookie mantenuto sul terminale del client e gestito dal browser
- Un database sul server
Esempio - L’utente A accede sempre a Internet dallo stesso PC e non necessariamente con lo stesso IP. Quando visita per la prima volta un sito di e-commerce e la prima richiesta HTTP giunge al sito questo crea un identificativo unico e una entry nel database per quel ID. L’utente da quel momento in poi invierà tutte le sue richieste con all’interno quell’ID.
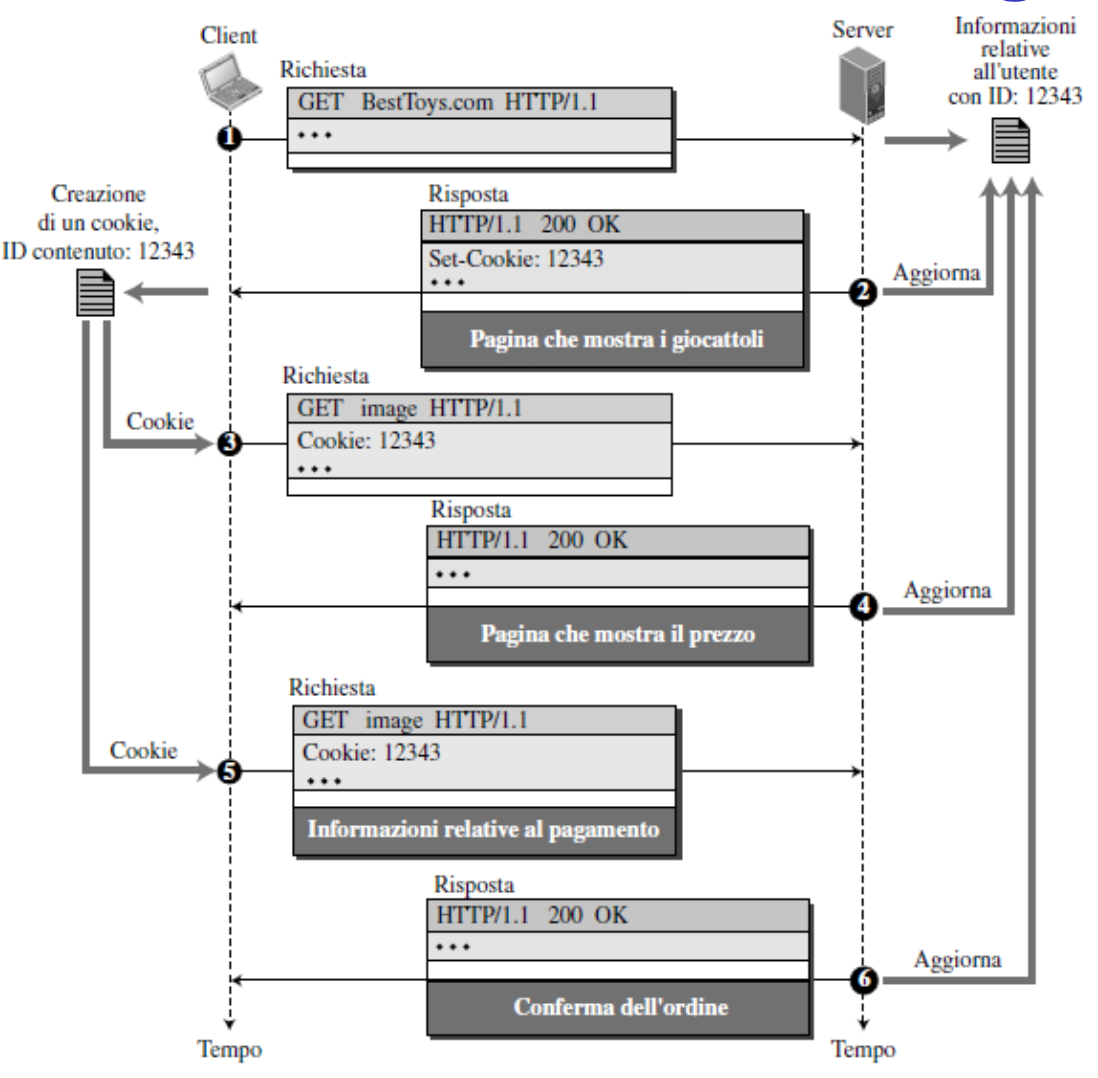
Il server mantiene tutte le informazioni riguardanti il client su un file e gli assegna un cookie ovvero un identificatore che verrà assegnato al client.
Questo identificatore, per evitare che vada in mano ad utenti maligni, è composto da una stringa complessa di numeri.
Ad ogni richiesta il browser consulta il file del cookie, estrae quello che necessario per quel sito web e lo inserisce in ogni richiesta HTTP, a questo punto il server può riconoscerlo e può mostrargli dei contenuti personalizzati.
Quindi a seconda del sito il browser sceglie il cookie con il giusto identificativo.
- Ma quanto dura un cookie?
Quando il server chiude una sessione invia al client un’intestazione Set-Cookie nel messaggio dove all’interno troviamo Max-Age=delta-seconds dove al posto di delta-seconds troviamo i secondi dopo i quali il client dovrebbe rimuovere il cookie. Se troviamo 0 allora il cookie dovrebbe essere rimosso subito.
- Cosa possiamo fare con i cookie?
- Memorizzare carte per acquisti
- Preferenze dell’utente
- Autorizzazioni di accesso
- Mantengono lo stato del mittente e del ricevente per più transazioni
- Ovviamente va tenuta sotto controllo la privacy, il sito chiede sempre se l’utente vuole che vengano creati dei cookie per memorizzare queste informazioni oppure no.
Un’altra soluzione potrebbe essere quella di non usare i cookie e ad ogni richiesta inviare i dati che sarebbero stati nei cookie.
- Questo è sicuramente più semplice da implementare ma:
- Può generare grandi scambi di dati
- Il server deve re-inizializzare le risorse ad ogni richiesta.
Web Caching
Vogliamo fare caching per migliorare le prestazioni dell’applicazione web. Per fare caching intendiamo caricare pagine in anticipo.
- Un modo potrebbe essere quello di salvare le pagine richieste per riutilizzarle in seguito
- Porterà sicuramente a dei vantaggi per quanto riguarda pagine caricate molto spesso
- Il caching può essere eseguito dal Browser o da dei server Proxy.
Browser Caching
Con questo metodo è il browser a mantenere una cache delle pagine visitate, possiamo gestirla in diversi modi:
- L’utente può impostarla in modo tale che dopo alcuni giorni i contenuti vengano cancellati
- La pagina può essere mantenuta in base alla sua ultima modifica
- Si possono utilizzare informazioni nei campi intestazione dei messaggi per gestire la cache
Server Proxy
Il server proxy è un intermediario fra i vari client e i server, il proxy ha una memoria che serve a mantenere a gestire le richieste e mantenere le pagine in cache. Essenzialmente se ad esempio 3 client richiedono una pagina, il proxy riceve le 3 richieste ma il server vero e proprio ne riceve soltanto una dal proxy.
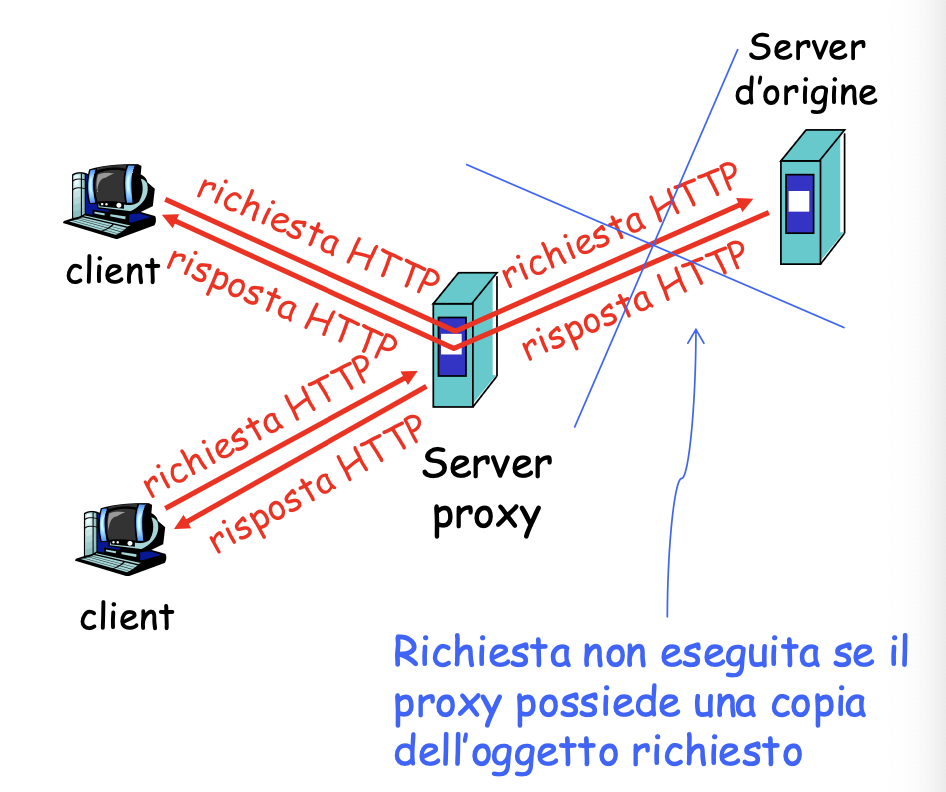
Il server proxy possiamo trovarlo anche all’interno di una LAN o anche nelle reti degli ISP per velocizzare i loro servizi.
La cache serve quindi a ridurre i tempi di risposta per i client, ridurre il traffico sul collegamento ad Internet e permettere ad ISP meno efficienti di fornire i dati in maniera veloce.
Esempio con assenza di cache
- Abbiamo come dimensione media degli oggetti 1Mb
- I browser della rete effettuano 15 richieste al secondo
- Per recuperare un file sulla internet ci vogliono 2 secondi - Internet delay
- Il tempo totale di risposta è quindi LAN Delay + Access delay + Internet delay
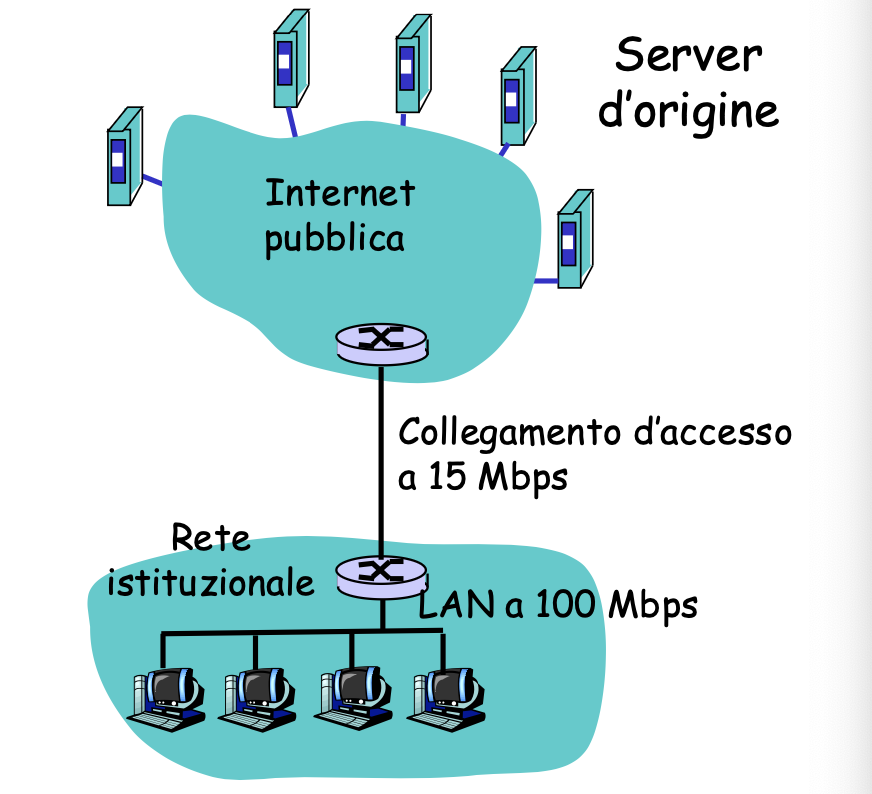
Facciamo una stima del ritardo calcolando :
- Utilizzo sulla LAN:
- Utilizzo sul collegamento d’accesso
- L’intensità tende quindi a 1 e il ritardo diventa importante
- Come ritardo totale otteniamo .
Come soluzione potremmo aumentare l’ampiezza di banda del collegamento a 100Mbps e raggiungere quindi un utilizzo sul collegamento del e avere un ritardo notevolmente ridotto. Ma fare questo non è sempre possibile dato che è molto costoso aggiornare l’intero collegamento.
Oppure possiamo inserire una cache nella rete:
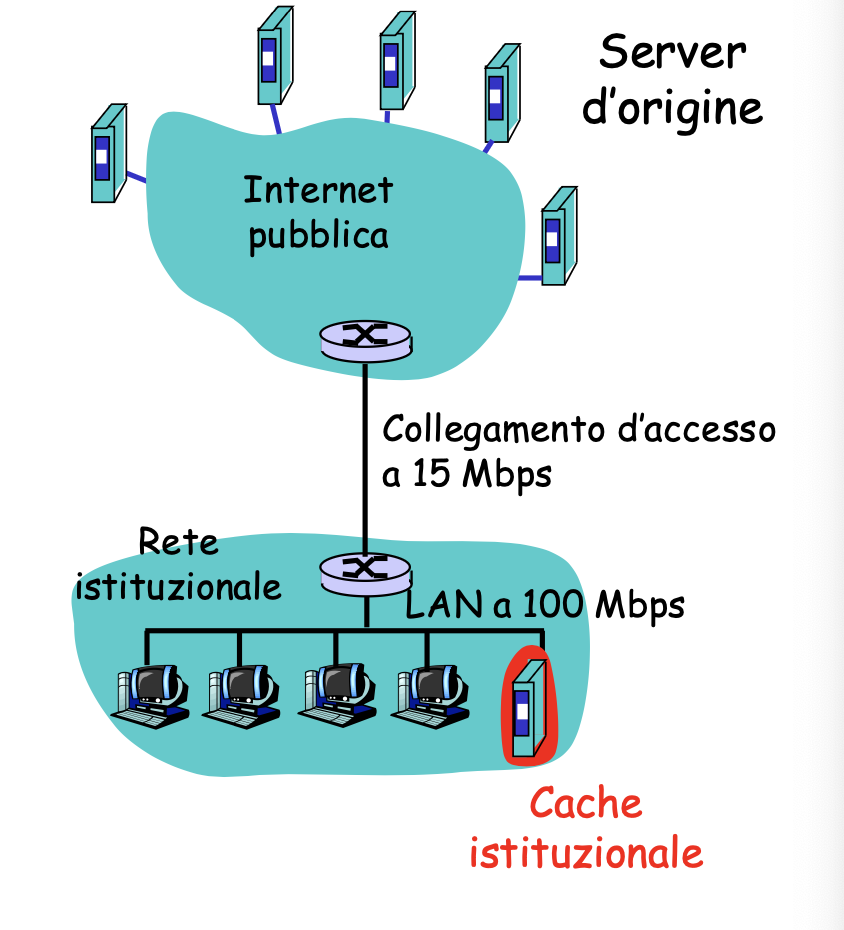
Supponiamo di avere una probabilità di successo pari a 0.4, ovvero una hit nella cache.
Otteniamo quindi che:
- Il 40% delle richieste sarà soddisfatto immediatamente, nell’ordine dei ms
- Il 60% delle richieste sarà soddisfatto dal server d’origine
- L’utilizzo del collegamento si è ridotto dal 100% al 60% portandoci ad avere dei ritardi trascurabili di circa 10ms
Inserimento di un oggetto in Cache
Il client invia un messaggio di richiesta HTTP alla cache:
GET /page/figure.gif
Host: www.sito.comLa cache non ha l’oggetto e invia quindi una richiesta HTTP al server il quale risponde con l’oggetto richiesto. La cache memorizza la pagina per richieste future e spedisce la risposta al client.
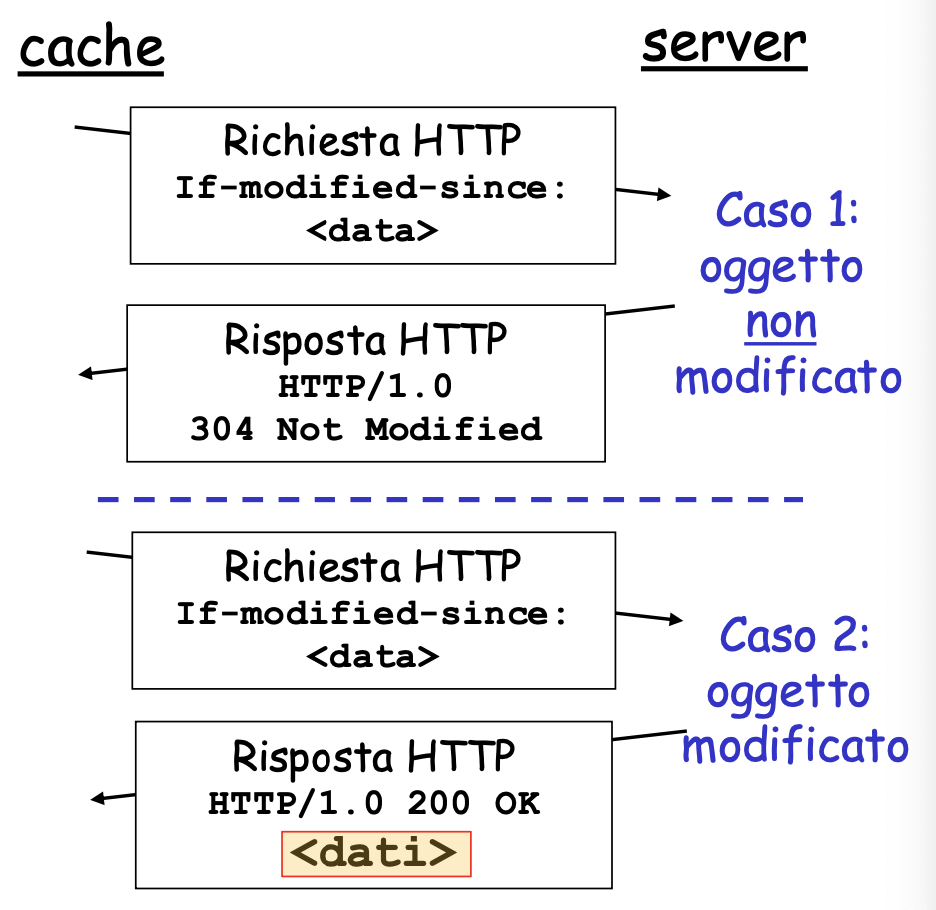
Se invece la cache ha l’oggetto in memoria allora può inviarlo al client, ma prima deve validarlo per verificare che non sia stato modificato dal server. Per fare questo tipo di verifica viene utilizzato il GET condizionale che utilizza degli if.
Questo serve per fare in modo che se la cache ha una copia aggiornata allora l’oggetto non viene rinviato altrimenti si.