Come accennato precedentemente, la multiprogrammazione può causare problemi, vediamo quali con la gestione della concorrenza.
Per i moderni sistemi operativi é fondamentale l’esecuzione di più processi contemporaneamente e qualsiasi tecnica si usi bisogna affrontare il problema della concorrenza ovvero la gestione del modo in cui questi processi interagiscono fra di loro.
Multiprogramming
Quando si ha un solo processore e i processi si alternano nel suo utilizzo (interleaving)
Multiprocessing
C’è più di un processore e i processi si alternano nell’uso di un processore (interleaving) ma possono anche sovrapporsi nell’uso di vari processori (overlapping), quindi più processi possono trovarsi in esecuzione nello stesso momento.
La concorrenza si manifesta in diverse occasioni:
- Più applicazioni aperte nello stesso momento
- Applicazioni strutturate in modo parallelo, quindi organizzate in thread oppure perché danno vita ad altri processi.
- Struttura del sistema operativo, infatti il SO stesso ha diversi thread e processi in esecuzione parallela.
Terminologia:
- Sezione Critica: Parte del codice di un processo dove viene eseguito l’accesso ad una certa risorsa condivisa, questa è la parte di codice che può portare ad una Race Condition.
- Mutua Esclusione: Due o più processi vogliono accedere ad una risorsa (si trovano in una sezione critica che li fa accedere alla stessa risorsa condivisa) ma questa risorsa può essere usata da un solo processo alla volta, quindi o la usa un processo o l’altro. I due processi si escludono a vicenda
- Race Condition (Corsa Critica): Situazione in cui viene violata la sezione critica
- Operazione Atomica: Sequenza indivisibile di comandi, abbiamo visto che il dispatcher può interrompere un processo quando vuole ma in realtà non è sempre così, ci sono alcune operazioni che non possono essere interrotte in qualsiasi momento.
- Deadlock (Stallo): Situazione dove due o più processi sono bloccati perché si stanno “aspettando” a vicenda.
- Livelock (stallo attivo): Situazione dove due o più processi cambiano continuamente il proprio stato, l’uno per rispondere all’altro ma senza concludere nulla di utile.
- Starvation: Un processo, anche se ready, non viene mai scelto dallo scheduler.
Difficoltà Principali
-
La principale é che non possiamo fare nessuna assunzione sul comportamento dei processi e su quello dello scheduler, quindi in ogni problema di concorrenza che vedremo dovremo scrivere una soluzione che funzioni sempre, indipendentemente dal comportamento dello scheduler o del processo.
-
Condivisione di Risorse
-
Gestione dell’allocazione delle risorse condivise
- Il sistema operativo deve decidere se assegnare una certa risorsa ad un processo che ne fa richiesta. La concorrenza rende impossibile una gestione ottima, ad esempio se ad un processo viene assegnato un I/O e poi il processo viene messo in pausa dal dispatcher come consideriamo quell’I/O, in uso o no?
-
Difficile tracciare gli errori di programmazione
- Questo perché in alcuni casi gli errori dipendono dalle scelte fatte dal dispatcher, quindi se abbiamo ottenuto un errore e vogliamo indagare ripetendo le stesse azioni per riprodurlo potremmo non ottenere lo stesso errore di prima o magari non ottenerne nessuno.
Esempio - Race Condition
void echo()
{
chin = getchar(); /* Globale */
chout = chin; /* Globale */
putchar(chout);
}Facciamo eseguire questo codice a due processi su uno stesso processore:

Notiamo che per il processo P2 tutto é andato come previsto mentre per P1 no, infatti ha ricevuto un carattere me ha stampato quello ricevuto da P2, questo per via delle decisione del dispatcher, infatti se avesse mandato in esecuzione prima tutto P1 e poi tutto P2 il problema non si sarebbe verificato. Vediamo un altro caso con più processori:

Anche in questo caso P1 stampa il dato ottenuto da P2.
Entrambi i casi sono una race condition quindi una violazione della mutua esclusione più nello specifico questa si ha quando:
- Più processi o thread leggono e scrivono su una stessa risorsa condivisa e lo fanno in modo tale che lo stato finale della risorsa dipende dall’ordine di esecuzione di processi e thread. Negli esempi di prima, il valore all’interno di
chindipende da l’ultimo processo che esegue l’assegnamento - Quindi il risultato dipende dal processo o thread che finisce per ultimo
Come Risolviamo il problema?
Restrizione all’Accesso Singolo
Facciamo in modo che la funzione echo possa essere chiamata da un solo processo per volta, quindi diventa atomica.
In questo modo P1 ci entra per primo e P2 viene bloccato fino al termine di P1.
Per fare questo ci serve un meccanismo per identificare la funzione come atomica.
Il sistema operativo
Per quanto riguarda il sistema operativo e la concorrenza, questo deve:
- Tenere traccia di diversi processi
- Allocare e deallocare risorse
- Proteggere dati e risorse dall’interferenza non autorizzata di altri processi
- Assicurarsi che processi ed output siano indipendenti dalla velocità di computazione ovvero dallo scheduling (esempio visto sopra.)
Interazioni tra Processi
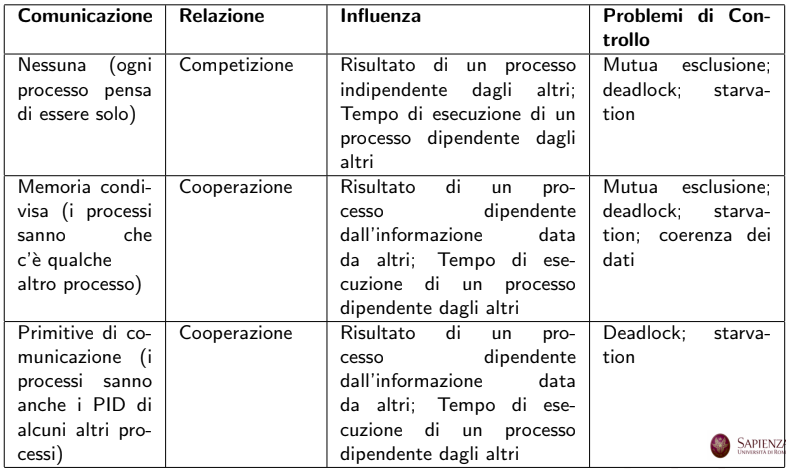
- Competizione: I processi pensano di essere soli e non si vedono l’un l’altro, competono quindi per l’utilizzo delle risorse.
- Cooperazione: Processi nati per cooperare, alcuni hanno una memoria condivisa (un processo scrive in una zona di memoria e qualcun altro legge) mentre altri comunicano con delle primitive apposite (più preciso della memoria).
Problemi principali con la competizione
- Ogni processo pensa solo per sé:
- Se però ha bisogno di risorse deve chiedere al sistema operativo
Quindi si hanno tre problemi di controllo principali:
- Mutua Esclusione
- Deadlock
- Starvation
Mutua Esclusione per Processi in Competizione
Prendiamo come competizione l’accesso alla tastiera o al monitor o altri I/O.
La soluzione ottimale é chiamare una syscall che si occupa di tutto, quindi entra nella sezione critica, fa l’operazione ed esce. Ma questo non é sempre possibile, infatti se si vuole accedere ad una risorsa condivisa con altri processi occorre fare una richiesta di bloccaggio della risorsa e si ricade nel caso di processi cooperanti.
Cosa accade quindi?

La syscall si occuperebbe delle zone entercritical, critical section e exitcritical, più nello specifico nella zona entercritical si decide se assegnare la risorsa o rimanere in attesa.
Tutti i processi sono visti come dei cicli che chiedono continuamente accesso a risorse, inoltre come visto prima non deve importare l’ordine di scelta del dispatcher perché un solo processo deve trovarsi in zona critica.
Mutua Esclusione per Processi Cooperanti
In questo caso é lo sviluppatore di questi processi che deve occuparsi della creazione delle syscall, questo però deve appoggiarsi a degli strumenti forniti dal sistema operativo. (Ad esempio i semafori)
Requisiti per la Mutua Esclusione
Ricordiamo:
Deadlock
Sono due processi che si aspettano a vicenda senza sbloccarsi mai, ad esempio A chiede stampante e poi monitor mentre B il contrario, se lo scheduler manda B in mezzo alle operazioni di A, succede che B blocca il monitor quindi A non può proseguire ma non può proseguire nemmeno B dato che la stampante è bloccata da A.
Starvation
Un processo attende una risorsa senza mai riceverla, in generale non viene mai mandato in esecuzione.
- Solo un processo alla volta può trovarsi nella sezione critica per una risorsa
- Non devono verificarsi deadlock e starvation
- Nessuna assunzione su scheduling dei processi e nemmeno sul loro numero
- Un processo deve entrare subito nella sezione critica se non ci sono altri processi che usano quella risorsa
- Un processo che si trova nella sezione non critica non deve subire interferenze da altri processi, quindi non può essere bloccato
- Un processo che si trova nella sezione critica deve prima o poi uscirci
Esempi
int bolt = 0;
void P ( in t i )
{
while ( true ) {
bolt = 1;
while ( bolt == 1) {
/* do nothing */
}
/* critical section */;
bolt = 0;
/* remainder */;
}
}Immaginiamo che ci siano processi che eseguono questa funzione , tutti i processi possono quindi leggere e scrivere sulla stessa variabile bolt condivisa fra tutti.
Vediamo subito che questa soluzione di impostare una variabile prima della sezione critica non funziona nemmeno con un solo processo, infatti una volta entrato nel secondo for il processo andrà in loop senza più sbloccarsi.
Proviamo a invertire la riga del while e la precedente:
int bolt = 0;
void P ( int i )
{
while ( true ) {
while ( bolt == 1) {
/* do nothing */
}
bolt = 1;
/* critical section */;
bolt = 0;
/* remainder */;
}
}In questo caso sembra funzionare anche con più processi, infatti se bolt vale 1 nessun altro processo può entrare nella sezione critica dato che finché non torna a 0 significa che il precedente processo ancora non ha finito.
Però se lo scheduler fa eseguire i 2 processi in interleaving e violiamo la mutua esclusione, se ad esempio un processo supera il controllo del while ma non imposta bolt = 1 e viene mandato in esecuzione un altro processo allora anche questo troverà bolt = 0 e quindi supererà il controllo mandando entrambi i processi nella critical section.
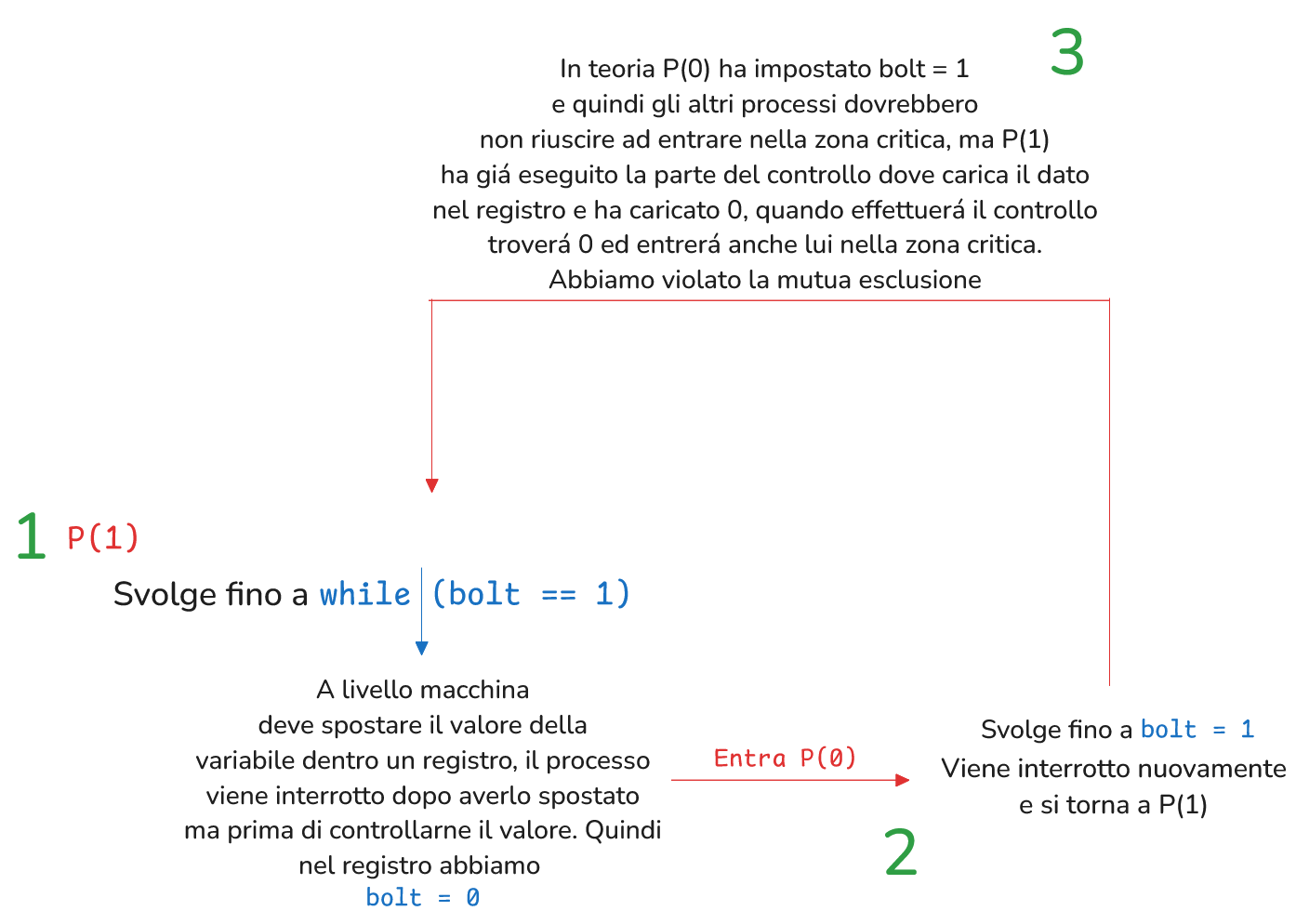
Scheduler e Livello Macchina
Lo scheduler può interrompere i processi anche in mezzo alle singole istruzioni, quindi a livello macchina.
Prendendo l’esempio precedente, vediamo una possibile violazione che può accadere a livello macchina:
Mutua Esclusione: Supporto Hardware
Iniziamo a vedere qualche soluzione funzionante che garantisce la mutua esclusione.
Disabilitazione delle Interruzioni
Ci troviamo sempre nel loop dove si cerca di accedere ad una sezione critica, prima di entrarci disabilitiamo gli interrupt e prima di uscire li riabilitiamo. In questo modo togliamo al dispatcher la possibilità di alternare i processi sul processore.
Quindi:
while (true) {
/* prima della sezione critica */;
disabilita_interrupt();
/* sezione critica */;
riabilita_interrupt();
/* rimanente */;
}E otteniamo una situazione come questa:
Quindi se disabilitiamo gli interrupt niente interrompe l’esecuzione del processo, ma questo ha dei problemi:
- Se un processo abusa di questa funzione, farà calare il livello di multiprogrammazione.
- Inoltre questo funziona solo in sistemi con un solo processore, infatti non disabilitiamo gli interrupt su tutti i processori quindi magari un processore é bloccato mentre un altro no e quindi processi in esecuzione su questo possono entrare nella sezione critica.
- Di solito quindi si può fare solo in kernel_mode
Istruzioni Macchina Speciali
Questo é un altro tipo di soluzione, possiamo semplificarle in due:
- Istruzione
exchange
void exchange(int register, int memory)
{
int temp;
temp = memory;
memory = register;
register = temp;
}Ovviamente va fatta a livello macchina quindi questa é una soluzione in pseudocodice. Questa prende un registro e un indirizzo di memoria e scambia questi elementi.
Queste sono speciali perché sono atomiche, quindi non verranno mai interrotte da altri processi, questo é garantito dall’hardware.
Come risolviamo il problema della mutua esclusione con questa funzione?
/* program mutualexclusion */
const int n = /* number of processes */
int bolt;
void P(int i)
{
while (true) {
int keyi = 1;
do exchange(keyi, bolt) while (keyi != 0)
/* critical section */
bolt = 0;
/* remainder */
}
}
void main()
{
bolt = 0;
parbegin (P(1), P(2), ..., P(n));
}Quindi c’è uno scambio di valori fra keyi, bolt fintanto keyi non diventa 0 a quel punto si va nella sezione critica.
Da notare che l’assegnamento di keyi = 1 va fatto dentro al while altrimenti se abbiamo un solo processo questo rimarrà bloccato
- Istruzione
compare_and_swap
int compare_and_swap(int word, int testval, int newval)
{
int oldval;
oldval = word;
if (word == testval) word = newval;
return oldval;
}Se il valore presente in word é uguale a quello presente in testval allora cambiamo il valore presente in word con quello presente in newval. In ogni caso la funzione ritorna il valore oldval.
Come risolviamo la mutua esclusione con questa funzione?
/* program mutualexclusion */
const int n = /* number of processes */
int bolt;
void P(int i)
{
while (true) {
while (compare_and_swap(bolt, 0, 1) == 1)
{
/* do nothing */
}
/* critical section */
bolt = 0;
/* remainder */
}
}
void main()
{
bolt = 0;
parbegin (P(1), P(2), ..., P(n));
}La funzione prende la variabile bolt, se vale 0 gli assegna 1 ma ritorna il vecchio valore quindi ritorna 0 ed entra nella sezione critica. Adesso se il dispatcher manda in esecuzione un altro processo, per lui bolt adesso vale 1 quindi la funzione non ne cambia il valore e ritorna 1 quindi entra nel while e non va nella sezione critica.
Quando il primo processo eseguirà bolt = 0 allora il secondo processo potrà uscire dal loop ed entrare nella sezione critica.
Vantaggi
Queste funzioni sono applicabili ad un qualsiasi numero di processi e sia su sistemi multiprocessore che con un solo. Sono molto semplici da verificare e inoltre possono essere usate per gestire più di una sezione critica.
Svantaggi
Si basano sul concetto di busy-waiting ovvero uno spreco del tempo di computazione, ad esempio i cicli while con i quali blocchiamo i processi. Il problema è che il ciclo di busy-waiting non viene distinto dal sistema operativo, non riesce quindi a distinguere chi sta aspettando di entrare nella sezione critica e chi sta facendo cose utili, per lui sono tutti ready.
Un altro svantaggio é che é possibile sia la starvation che il deadlock, questo solo se a questi meccanismi viene abbinata la priorità fissa, ovvero se un processo con bassa priorità viene interrotto nella sezione critica ed entra uno ad alta priorità rimarrà bloccato perché il primo processo deve sbloccare la zona critica.
Semafori
Una soluzione tipica per evitare i busy waiting sono i semafori, questi sono essenzialmente delle strutture dati che permettono 3 operazioni:
- Inizializzazione -
initialize decrement o semWait: diminuisce il valore di un intero presente nel semaforo che mette in stato di blocket il processo, quindi non si spreca CPU come con il busy waitingincrement o semSignal, aumenta il valore dell’intero e mette in stato di ready il processo
Queste operazioni sono delle syscall e vengono quindi eseguite in kernel mode e agiscono direttamente sui processi.
Pseudocodice per semaforo:
struct semaphore {
int count;
queueType queue;
};
void semWait(semaphore s)
{
s.count--;
if (s.count < 0) {
/* place this process in s.queue */
/* block this process */
}
}
void semSignal(semaphore s)
{
s.count++;
if (s.count <= 0) {
/* remove a process P from s.queue */
/* place process P on ready list */
}
}Notiamo quindi che hanno, oltre ad un intero, una coda di processi.
Se chiamiamo una wait su un semaforo allora decrementiamo l’intero e se questo ha valore negativo allora il processo che ha fatto la chiamata va messo in blocked e aggiunto alla coda del semaforo.
Se viene invece chiamata una signal viene incrementato il contatore e se il valore é negativo o 0 allora c’è da sbloccare qualcosa, si sceglie un processo dalla coda si toglie da questa e si dichiara ready.
Esistono anche semafori binari dove al posto dell’intero count abbiamo una variabile che assume soltanto 0 ed 1, count infatti ci dà informazioni aggiuntive ad calcolandone il valore assoluto possiamo capire quanti processi ci sono in coda.
I semafori non sono istruzioni macchina come exchange o compare_and_swap ma sono syscall offerte dal sistema operativo. Inoltre per evitare che vengano bloccate possono far uso delle istruzioni macchina exchange o compare_and_swap.
Quando c’è una signal e dobbiamo quindi decidere quale processo sbloccare, in che modo lo decidiamo?
Semafori Deboli e Forti
Se la politica che utilizziamo è quella “ovvia” cioè la FIFO allora si parla di strong semaphore, se invece la politica non viene specificata allora si parla di weak semaphore.
Quindi con quelli forti, se usati bene, possiamo evitare la starvation mentre con i deboli no.
Esempio di Semaforo Forte
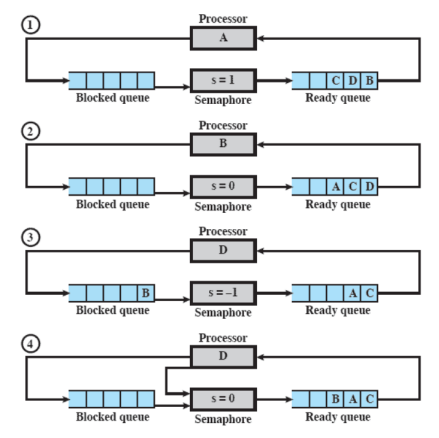
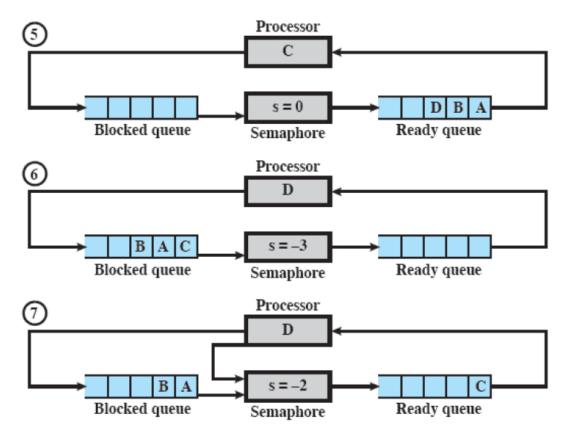
1-2) Abbiamo A in esecuzione e chiama una wait sul semaforo, quindi questo scende a 0 ma non essendo sceso sotto a 0 non sposta il processo in blocked, A viene quindi rimandato in ready.
2-3) B va in esecuzione e chiama una wait, il count del semaforo scende a -1 e quindi B viene messo in blocked.
3-4) Va in esecuzione D che chiama una signal infatti s passa a 0 e il processo B viene rimesso in ready.
4-5-6) Viene messo in esecuzione C e, saltando dei passaggi nelle foto, vengono chiamate 3 wait una per ogni processo, quindi abbiamo D in esecuzione e tutti gli altri in blocked
6-7) A questo punto D chiama una signal che sblocca C e lo manda in ready.
La differenza con un semaforo debole sta nel punto 6-7, il debole avrebbe sbloccato un processo a caso mentre il forte sblocca sempre quello in testa alla coda.
Mutua Esclusione con Semafori
coinst int n = /* number of processes */
semaphore s = 1;
void P(int i)
{
while (true) {
semWait(s);
/* critical section */;
semSignal(s);
/* remainder */;
}
}
void main()
{
parbegin (P(1), P(2), ..., P(n));
}È importante impostare s = 1 prima di iniziare.
Grafico del funzionamento:
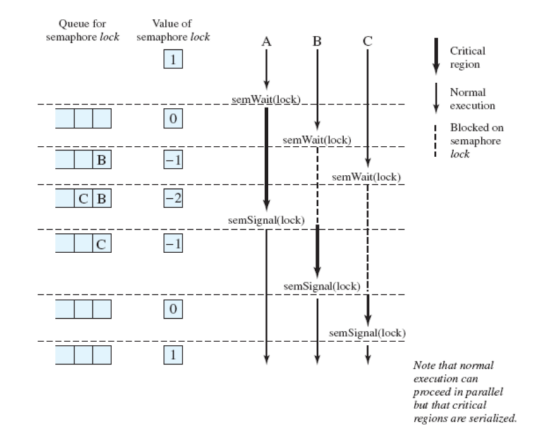
Problema del Produttore / Consumatore
Situazione generale:
- Uno o più processi creano dati (produttori) e li mettono in un buffer
- Un consumatore prende dati dal buffer uno alla volta
- Al buffer può accedere un solo processo sia produttore o consumatore
Dobbiamo quindi garantire la mutua esclusione per l’accesso al buffer, ma questa é solo una parte del problema.
Infatti, oltre alla mutua esclusione:
- Ci si deve assicurare che i produttori non inseriscano dati quando il buffer è pieno
- Assicurarsi che i consumatori non prendano dati quando il buffer è vuoto
Si potrebbe permettere l’accesso in contemporanea di produttori e consumatori ma per semplicità non consideriamo questo caso.
Pseudocodici
Per ora facciamo finta che il buffer abbia spazio infinito, eliminiamo quindi il primo punto, il produttore non ha mai motivo di fermarsi.
/* Produttore */
while (true) {
/* produce item v */
b[in] = v;
in++;
}
/* Consumatore */
while (true) {
while (in <= out)
/* do nothing */
w = b[out];
out++;
/* consume item w */
}Quindi solo il consumatore deve preoccuparsi di non consumare quando il buffer è vuoto.
Soluzione con semafori binari:

Se vogliamo usare con semafori generali:

Entrambe risolvono il problema dove il consumatore legge da un buffer vuoto.
Nella seconda soluzione essenzialmente ad ogni elemento prodotto incrementiamo il semaforo e ad ogni elemento consumato lo riduciamo.
Produttori e Consumatori con Buffer Circolare
Adesso eliminiamo l’ipotesi del buffer infinito, questo adesso é gestito in maniera circolare.
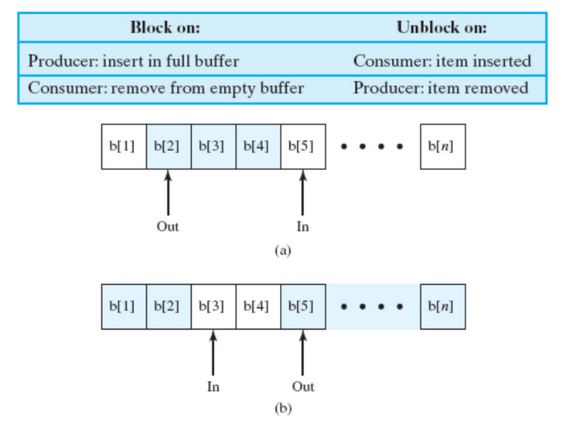
Come prima abbiamo in dove il produttore può inserire e out dove il consumatore può recuperare oggetti, inoltre in questo caso se le due variabili sono uguali il buffer non è sempre vuoto potrebbe anche essere pieno. Per risolvere questo il nostro buffer in realtà sarà grande n - 1 e non n.
In questo modo se in == out allora il buffer è vuoto. Sarà pieno quando in + 1 % n == out.
Adesso le implementazioni diventano:
- Produttori
while (true) {
/* produce item v */
while ((in + 1) % n == out)
{
/* do nothing */
}
b[in] = v;
in = (in + 1) % n
}- Consumatori
while (true) {
while (in == out)
{
/* do nothing */
}
w = b[out];
out = (out + 1) % n
/* Consume item w */
}Ricordiamo che vogliamo:
- Mutua esclusione sul buffer
- Consumatore non deve mai consumare se buffer vuoto
- Produttore mai produrre se buffer pieno
Possiamo modificare la soluzione di prima con poche righe:

Aggiungiamo un terzo semaforo e grande quanto il buffer. Nel produttore facciamo subito una wait su e, in questo modo se facciamo un numero di operazioni pari alla grandezza del buffer veniamo bloccati.
Ovviamente se un elemento viene consumato allora chiamiamo una signal su e.
Slide 62 - 70 ci sono degli esempi con i semafori
Mutua Esclusione: Soluzioni Software
Abbiamo visto la soluzione tramite semafori, vediamo un altro tipo di soluzione. Queste non useranno istruzioni macchina o altro, non si appoggiano su niente.
Facciamo quindi affidamento soltanto a variabili o altri strumenti software.
Algoritmo di Dekker

I due processi impostano la variabile wants_to_enter a true dichiarando quindi di voler entrare nella sezione critica.
Con if turn = (0,1) a seconda del processo, controlliamo se è il suo turno di entrare nella sezione critica, se non tocca a lui impostiamo a falso il wants_to_enter e facciamo un’attesa attiva finché l’altro processo non ha finito e quindi turn cambia valore.
Questa soluzione vale soltanto per 2 processi, l’estensione a più processi è possibile ma non banale.
- Garantisce la non starvation grazie a
turn - Garantisce il non deadlock ma è busy-waiting, quindi se ci sono le priorità fisse può accadere.
- Non richiede nessun supporto dal SO, anche se in alcune architetture ci sono delle ottimizzazioni che riordinano le istruzioni e gli accessi in memoria, è necessario disabilitarle
Algoritmo di Peterson
Questo algoritmo risolve il problema in maniera più semplice.

Anche qui il processo che vuole entrare nella sezione critica lo segnala impostando flag a true.
Ognuno dei due processi imposta turn per l’altro, come se gli cedesse il posto, poi se l’altro è interessato allora loro aspettano.
- Anche questo vale soltanto per 2 processi e l’estensione a più processi è più semplice ma comunque non banale.
- Per starvation e deadlock è come il Dekker
- Bounded-Waiting: Un processo può aspettare l’altro al più una volta.
- Stesso discorso per ottimizzazioni che riordinano gli accessi.
Passaggio di Messaggi
Per ora abbiamo visto lo scambio di informazioni fra processi tramite variabili globali, adesso vediamo come un processo può mandare un messaggio direttamente ad un altro processo.
Questo scambio funziona con due primitive:
send(destination, message)receive(source, message)- Spesso abbiamo anche dei test di ricezione
- Da notare che
messagein send è un input mentre in receive è un output
Lo scambio di messaggi richiede la sincronizzazione, infatti il mittente deve inviare prima che il ricevente riceva. Cosa succede ai processi quando usano queste syscall? Queste operazioni possono essere sia bloccanti che non, da notare che il test di ricezione non è mai bloccante.
Send e Receive Bloccanti
In questo caso sia mittente che destinatario sono bloccati finché il messaggio non è completamente ricevuto, tipicamente si chiama rendezvous e richiede una sincronizzazione molto stretta.
Quello che succede, molto banalmente, è che chi chiama una send rimane bloccato finché qualcuno non riceve, stessa cosa se qualcuno chiama una receive rimane bloccato finché non riceve qualcosa.
Send / Receive non Bloccante
Spesso si utilizza una send non bloccante e una receive bloccante.
Terminologia
Se scriviamo
send o receivele indichiamo bloccanti, se invece inseriamonbdavanti sono non bloccanti quindinbsend o nbreceive.
Con una send non bloccante accade che:
- Il mittente manda il messaggio e non si preoccupa se questo arriva o no, non viene bloccato
- Il destinatario se parte prima dell’arrivo del messaggio rimane bloccato finché questo non arriva, se invece é partito dopo non viene bloccato dato che il messaggio viene ricevuto subito.
Quindi se mittente parte prima non si blocca nessuno, altrimenti si blocca il destinatario.
C’è anche una versione con receive non bloccante, anche se molto rara, in questo caso la syscall può essere utilizzata anche per capire se è avvenuta o meno la ricezione.
Queste sono sempre atomiche, un solo processo per volta le esegue.
Indirizzamento
Il mittente deve poter dire a quale processo o processi vuole mandare il messaggio, lo stesso vale per il destinatario anche se non sempre.
Per fare questo si utilizza:
- Indirizzamento Diretto
- Indirizzamento Indiretto
Indirizzamento Diretto
Nella primitiva send abbiamo come parametro l’identificatore per il destinatario o un gruppo di destinatari.
Per la receive questo può accadere oppure no per ricevere messaggi solo da determinati mittenti oppure per ricevere da chiunque.
Ogni processo ha una sua coda di messaggi, una volta piena solitamente il messaggio si perde o viene ritrasmesso.
Indirizzamento Indiretto
I messaggi sono inviati in una mailbox ovvero una zona di memoria dove altri processi vanno a prendere questi messaggi.
Ovviamente possono esserci più di una mailbox e serve anche un processo che la inizializza.
Inoltre se più processi hanno fatto una receive su quella mailbox e vengono tutti bloccati perché vuota, nel momento in cui questa riceve un messaggio verrà sbloccato un solo processo e non tutti quelli in attesa. Notiamo che se la mailbox è piena allora anche i processi che inviano a lei si bloccano.
Vari casi d’uso
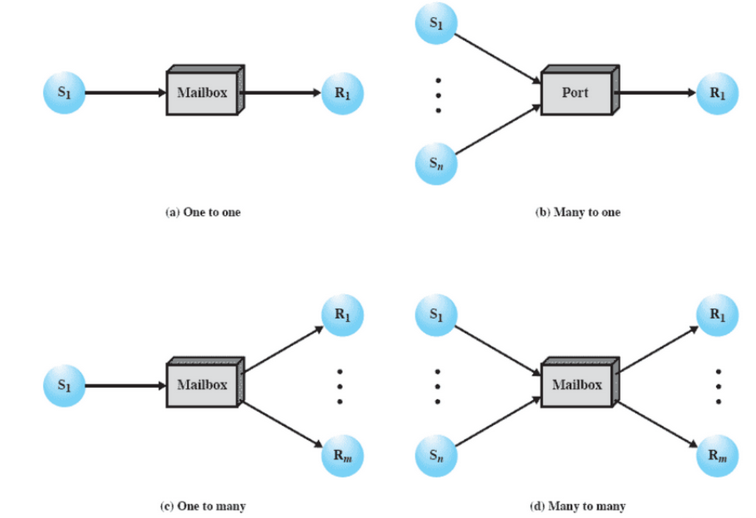
Formato dei Messaggi
Quando inviamo un messaggio, non si manda soltanto il corpo ma anche dei metadati:
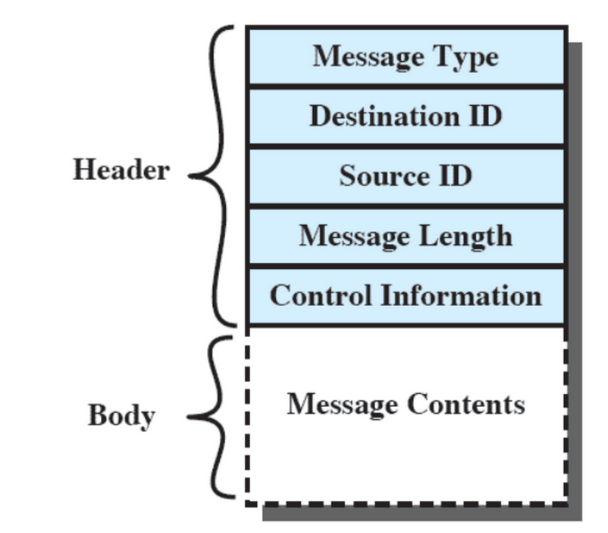
- Message Type: Dipende dall’applicazione
- Destination / Source ID: ID del destinatario e mittente
- Message Length: Grandezza della zona Message Contents
- Control Information: Se il messaggio è troppo grande, questa zona contiene informazioni sulle parti, ad esempio se è la prima parte o un’altra.
Mutua Esclusione con i Messaggi
const message null = /* null message */;
mailbox box ;
void P ( int i ) {
message msg\;
while ( true ) {
receive ( box , msg ) ;
/* critical section */;
nbsend ( box , msg ) ;
/* remainder */;
}
}
void main () {
box = create_mailbox () ;
nbsend ( box , null ) ;
parbegin ( P (1) , P (2) , . . . , P ( n ) ) ;
}Inizializziamo la mailbox e mandiamo subito un messaggio in modo non bloccante, in questo modo anche se abbiamo più processi soltanto il primo che lo riceve entra nella zona critica e una volta finito manda un messaggio alla mailbox andando a sbloccare un altro processo.
Produttore / Consumatore con Messaggi
Ricordiamo la situazione generale:
- Uno o più processi produttori inseriscono dati in un buffer
- Un consumatore prende i dati uno alla volta
- Al buffer può accedere un solo processo sia produttore che consumatore.
Dobbiamo fare in modo che:
- I produttori non inseriscano i dati quando il buffer è pieno
- I consumatori non prendano dati quando il buffer è vuoto
- Mutua esclusione sul buffer.
const in t capacity = /* buffering capacity */ ;
mailbox mayproduce , mayconsume ;
const message null = /* null message */;
void main ()
{
mayproduce = create_mailbox () ;
mayconsume = create_mailbox () ;
for ( in t i = 1; i <= capacity ; i ++)
nbsend ( mayproduce , null ) ;
parbegin ( producer , consumer ) ;
}Abbiamo due mailbox.
Ricordiamo con i semafori, inizializzavamo il valore alla grandezza del buffer, qui facciamo la stessa cosa, inviamo nella mailbox mayproduce tanti messaggi quanti la grandezza del buffer.
In questo modo possiamo:
void producer () {
message pmsg ;
while ( true ) {
receive ( mayproduce , pmsg ) ;
pmsg = produce () ;
nbsend ( mayconsume , pmsg ) ;
}
}
void consumer () {
message cmsg ;
while ( true ) {
receive ( mayconsume , cmsg ) ;
consume ( cmsg ) ;
nbsend ( mayproduce , null ) ;
}
}Il produttore prima di inviare qualcosa a mayconsume riceve da mayproduce. Il consumatore fa l’opposto quindi riceve da mayconsume e poi invia a mayproduce.
Quando inviamo null è perché non ci interessa del messaggio ma lo usiamo solo a scopo di misurare quanto possiamo produrre.
Da notare inoltre che si usano send bloccanti e receive non bloccanti.
Con questa soluzione abbiamo:
- Risolto Mutua Esclusione
- Niente deadlock
- Niente starvation ma solo se le code di processi bloccati su una receive sono gestite in modo forte ovvero usando FIFO.
- Funziona anche con più di 1 produttore e più di 1 consumatore.
Problema dei Lettori / Scrittori
Qui abbiamo un’area dati condivisa fra molti processi, alcuni leggono da questa e altri scrivono.
Cosa vogliamo:
- Più lettori possono leggere contemporaneamente
- Può scrivere un solo scrittore alla volta
- Se uno scrittore sta scrivendo, nessun lettore può leggere.
A differenza del caso produttori / consumatori l’area condivisa si accede per intero quindi non ci sono i problemi del buffer pieno o vuoto. Come detto prima però è importante permettere l’accesso a più lettori contemporaneamente.
Soluzione con Precedenza ai Lettori

Questo significa che se abbiamo un lettore che sta leggendo ed arriva uno scrittore, poi arrivano altri lettori allora quei lettori vanno avanti per primi.
Lo scrittore ha un semaforo wsem e molto semplicemente prima di scrivere fa una wait e dopo aver scritto una signal. In questo modo un solo scrittore alla volta riesce a scrivere.
Il lettore usa una variabile condivisa readCount per capire quanti stanno leggendo, per modificarla in sicurezza usiamo un altro semaforo x. Se il lettore entra chiama una wait anche sul semaforo degli scrittori per bloccarli dato che lui sta leggendo.
Dopo che ha letto decrementa il valore dei lettori e se era l’ultimo riabilita gli scrittori.
Quindi per questo è precedenza ai lettori, se ci sono lettori continuano a leggere avendo la precedenza sugli scrittori, questo significa che potrebbe esserci starvation per gli scrittori.
Soluzione con Precedenza agli Scrittori

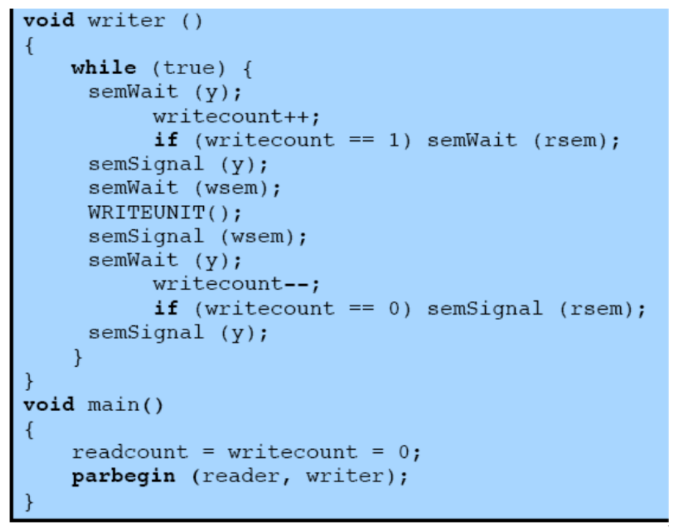
Con questa soluzione, anche se abbiamo una sequenza di lettori che vogliono leggere e arriva uno scrittore possono al massimo finire quelli già in lista per leggere, gli altri dovranno aspettare lo scrittore.
Soluzione con Messaggi
Utilizziamo sia comunicazione diretta che indiretta.
void reader ( int i )
{
while ( true ) {
nbsend ( readrequest , null ) ;
receive ( controller_pid , null ) ;
READUNIT () ;
nbsend ( finished , null ) ;
}
}
void writer ( int j )
{
while ( true ) {
nbsend ( writerequest , null ) ;
receive ( controller_pid , null ) ;
WRITEUNIT () ;
nbsend ( finished , null ) ;
}
}Le mailbox sono readrequest, writerequest, finished.
Nel caso dei messaggi non abbiamo soltanto i processi reader e writer ma anche un terzo processo controller, questo decide quando uno scrittore può scrivere e quando un lettore può leggere:
void controller () {
int count = MAX_READERS ;
while ( true ) {
if ( count > 0) {
if (! empty ( finished ) ) { /* da reader ! */
receive ( finished , msg ) ;
count ++;
}
else if (! empty ( writerequest ) ) {
receive ( writerequest , msg ) ;
writer_id = msg.sender ;
count = count - MAX_READERS ;
}
else if (! empty ( readrequest ) ) {
receive ( readrequest , msg ) ;
count--;
nbsend ( msg.sender , " OK " ) ;
}
}
if ( count == 0) {
nbsend ( writer_id , " OK " ) ;
receive ( finished , msg ) ; /* da writer ! */
count = MAX_READERS ;
}
while ( count < 0) {
receive ( finished , msg ) ; /* da reader ! */
count ++;
} /* while ( count < 0) */
} /* while ( true ) */
} /* controller */Sia reader che writer “chiedono” il permesso con invii non bloccanti e receive bloccanti al controller. Una volta finito segnalano anche questo.
Cosa deve fare il controller?
La variabile locale count conta il numero di lettore attualmente in lettura. Vedremo che può anche essere negativo e in quel caso indica altro.
Supponiamo sia positivo, quindi siamo nel primo if, lui prova a vedere se c’è qualcosa da ricevere da finished, se così lo riceve e aumenta il count.
Fa la stessa cosa con tutte le altre mailbox e notiamo che nella mailbox readrequest mandiamo un lettore a leggere quindi decrementiamo count e inoltre inviamo una conferma di lettura a chi ha mandato questo messaggio.
Quindi finché ci sono lettori che leggono continuiamo a stare nel primo if.
Se arriva uno scrittore, prendiamo la sua richiesta e il suo PID, sottraiamo da count MAX_READERS. Questo significa che se ci sono lettori andiamo sotto zero, se non ci sono andiamo a 0.
Se andiamo a 0 non ci sono lettori e quindi lo scrittore può andare e reimpostiamo il numero di lettori una volta che lui ha terminato, se invece siamo sotto a 0 aspettiamo che tutti i lettori finiscano.
Equivalenze
La condivisione di risorse può quindi essere implementata con questi 3 metodi:
- Istruzioni Hardware
- Semafori
- Messaggi
Se si può implementare un’applicazione con uno qualsiasi dei 3 metodi allora lo si può fare anche con gli altri 2, ovviamente un meccanismo sarà più conveniente degli altri in termini di sviluppo, prestazioni e gestione.