SLIDE DI INTRODUZIONE
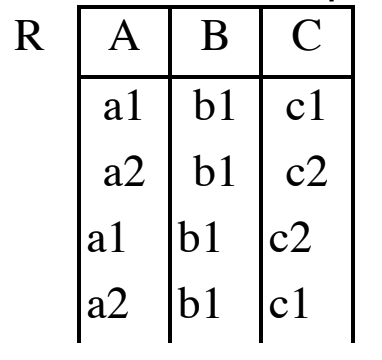
Prima per immagazzinare i dati si utilizzavano sistemi informativi dove ogni applicazione aveva il suo file privato, quali erano li svantaggi?
- Ridondanza: Se due applicazioni usavano gli stessi dati questi venivano salvati due volte.
- Inconsistenza: Se abbiamo due copie, l’aggiornamento di un dato poteva riguardare soltanto una di queste.
- Dipendenza dei Dati: Ogni applicazione organizzava i dati in modo diverso, in base all’utilizzo che ne faceva.
Adesso si utilizzano le Basi di Dati (Database) ovvero un insieme di file mutuamente connessi, questi sono organizzati in strutture dati che ne facilitano la creazione e l’accesso, inoltre ottimizzano la gestione delle risorse fisiche.
Si utilizzano i Sistemi di Gestione di Basi di Dati (DBMS) per la gestione di grandi masse di dati residenti su memorie secondarie.
Quando un’informazione viene registrata in formato elettronico ci sono due possibilità:
- Dati Strutturati: I dati sono rappresentanti da stringhe di simboli e da numeri.
- Dati non strutturati: Rappresentati in linguaggio naturale.
La struttura di un dato dipende dal suo utilizzo e può essere modificate nel tempo, ad esempio se dobbiamo salvare i dati relativi ad una persona ci servirà: nome, cognome, codice fiscale ecc…
L’obiettivo è quello di facilitare l’elaborazione dei dati sulla base delle loro relazioni, infatti possiamo accedere singolarmente agli elementi della struttura tramite “interrogazioni” per recuperare informazioni o effettuare calcoli.
In una base di dati ogni componente è interessata ad una porzione del Sistema Informativo, queste porzioni possono sovrapporsi ma la base di dati ci permette di ridurre le ridondanze e conseguenti inconsistenze.
La condivisione non è mai completa, vanno regolamentati gli accessi e questa comporta il controllo della concorrenza ovvero l’accesso simultaneo allo stesso dato.
Sistema Informativo
Un sistema informativo è un complesso di dati organizzati fisicamente in una memoria secondaria e gestiti in maniera tale da consentirne la creazione, l’aggiornamento e l’interrogazione.
I dati sono organizzati in aggregati di informazioni omogenee che costituiscono le componenti del sistema informativo, ogni operazione ha per oggetto un singolo aggregato mentre un’interrogazione può coinvolgerne più di uno.
Nelle basi di dati:
- Aggregati di informazioni omogenee: file
- Indici: File che permettono di recuperare velocemente delle informazioni.
L’informazione è rappresentata sotto forma di dati ovvero dei valori che devono essere interpretati e correlati per fornire un’informazione.
Ad esempio “Alessio Marini” e ‘1234567890’ sono una stringa e un numero ovvero due dati, ma se li vediamo come risposta alla domanda “Di chi sono gli appunti e quel è il suo numero di telefono?” allora costituiscono informazione.
Modello dei dati
Sono strutture da utilizzare per organizzare i dati e le loro relazioni, un componente fondamentale sono i costruttori di tipo, ad esempio nel modello relazionale abbiamo il costruttore di relazione che organizza i dati come insieme di record.
Ci sono due tipi di modelli:
- Modelli Logici: Sono indipendenti dalle strutture fisiche ma sono disponibili nei DBMS.
- Modelli Concettuali: Sono indipendenti dalle modalità di realizzazione e hanno lo scopo di rappresentare le entità del mondo reale e le loro relazione nella prima fase della progettazione.
Modello Relazionale
Nel 1970 IBM introduce il Modello Relazionale, i dati e le relazioni vengono rappresentati come valori e non ci sono riferimenti espliciti come puntatori, garantendo quindi una rappresentazione di alto livello.
- Oggetto: record
- Campi: Informazioni di interesse
Ad esempio:
- Oggetto: “Membro dello Staff”
- Campi: Codice, Cognome, Nome, Ruolo, Anno di Assunzione
- Tabella: Insieme di record di tipo omogeneo, creiamo ad esempio la Tabella STAFF ovvero l’insieme di record di tipo “Membro dello Staff”:
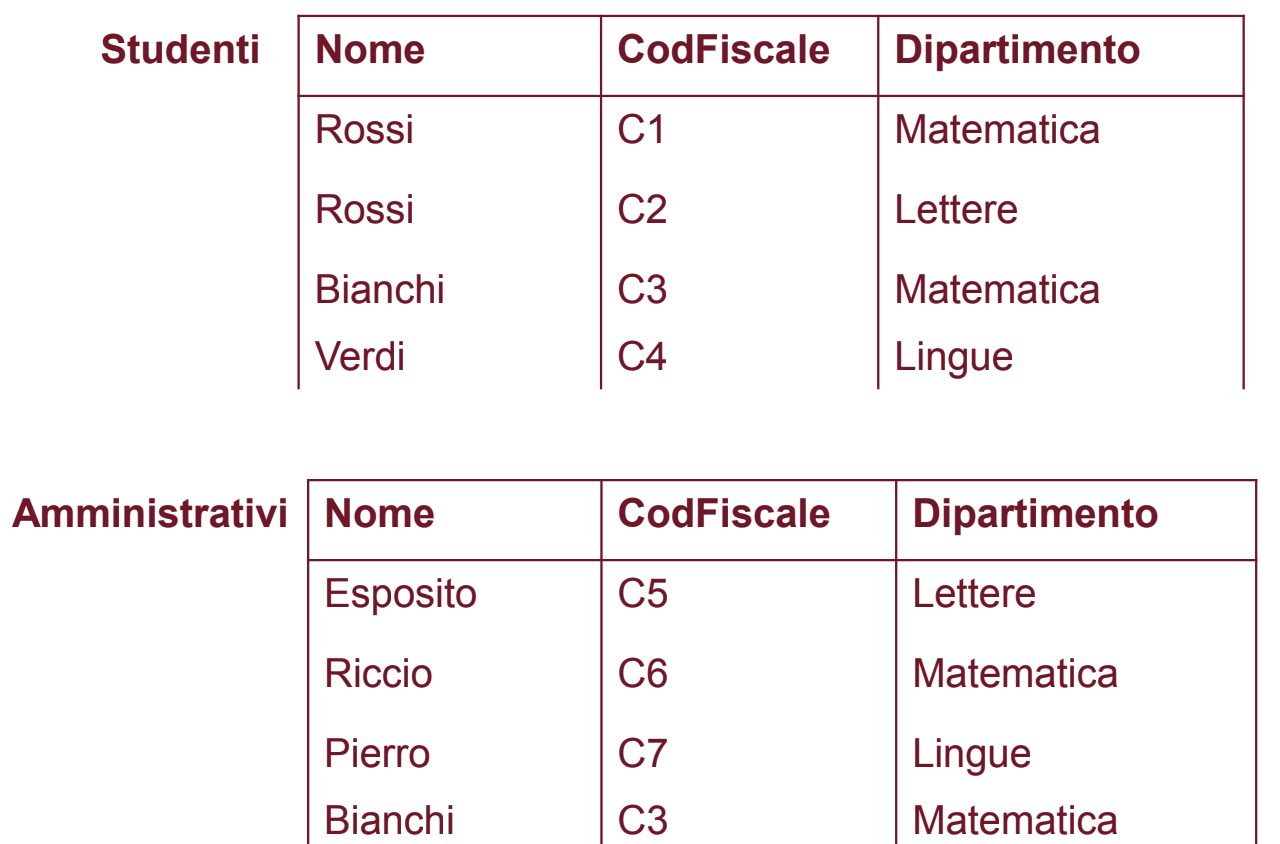
Esempio più completo di DB Relazionale
Studenti:
Corsi:
Esami:
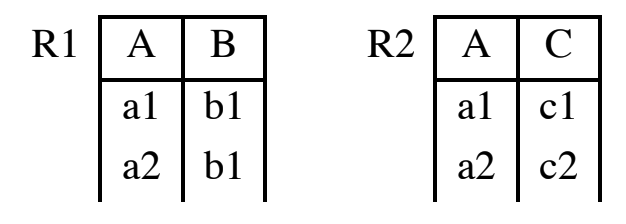
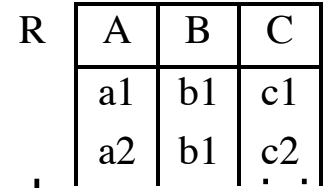
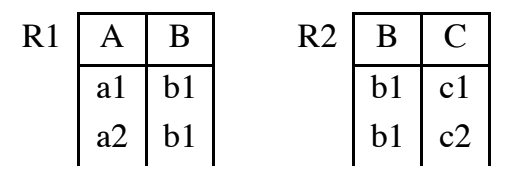
Abbiamo la tabella Esami che mette collega i corsi e gli studenti.
DB e DBMS
- Il Database è la collezione di dati logicamente correlati di interesse per il Sistema Informativo
- Il DBMS è un software che interagisce con il DB da una parte e con i programmi applicativi dall’altra
- Oggetti nella base di Dati: Memorizzano proprietà di “Oggetti” e relazioni tra oggetti nel dominio di interesse.
Le componenti di un Sistema Informativo Informatizzato sono quindi:
- La base di dati BD
- Un DBMS
- Applicativo software che utilizza il DB
- Hardware del computer, ovvero i dispositivi di memorizzazione.
- Personale che gestisce il sistema.
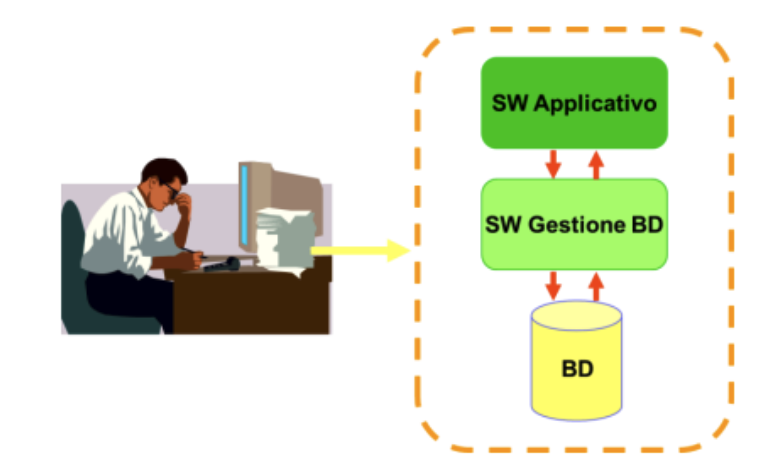
La memorizzazione avviene in maniera astratta, ovvero, i sistemi di basi di dati utilizzano dei formati proprietari per salvare i dati, ma offrono all’utente una vista “normale” dell’oggetto memorizzato, in modo da rendere trasparenti i dettagli di memorizzazione e manipolazione.
Livelli di Astrazione di un DB
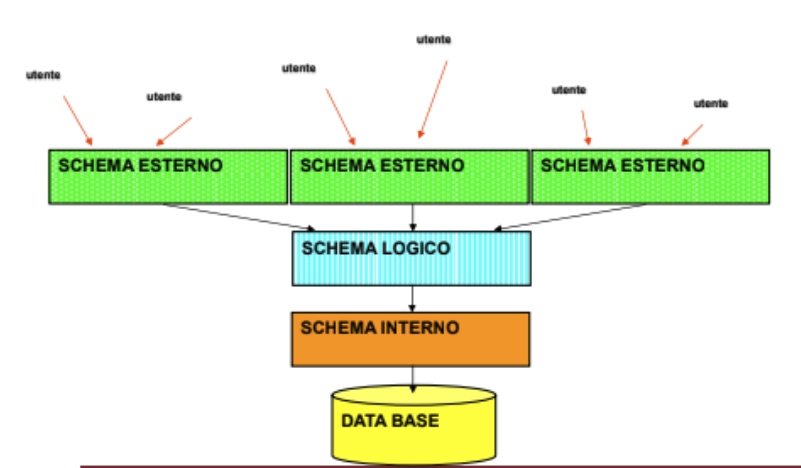
- Schema Esterno:Descrizione di una porzione della base di dati in un modello logico attraverso delle viste parziali che possono prevedere organizzazioni dei dati diverse rispetto a quelle utilizzate nello schema logico, queste riflettono esigenze e privilegi dell’utente. Ad uno schema logico si possono associare più schemi esterni. (In poche parole non tutti gli utenti devono accedere a tutti i dati, chi ha più privilegi può vedere più cose)
- Schema Logico: Descrizione dell’intera base di dati nel modello logico principale del DBMS, come ad esempio la struttura delle tabelle.
- Schema Fisico: Rappresentazione dello schema logico per mezzo di strutture fisiche di memorizzazione, i file.
Esempio
Dato lo schema logico:

Una possibile vista CorsiSedi può essere:
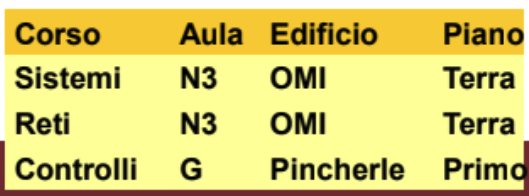
Gli accessi alla base avvengono solamente attraverso lo schema esterno che può coincidere o meno con quello logico.
Indipendenza dei Dati
- Indipendenza Fisica: Il livello logico e quello esterno sono indipendenti da quello fisico, questo comporta che una relazione è utilizzata nello stesso modo qualunque sia la sua realizzazione fisica ovvero l’organizzazione dei file sulla memoria. Inoltre la realizzazione fisica può cambiare senza causa problemi nei programmi che utilizzano la base di dati.
- Indipendenza Logica: Il livello esterno è indipendente da quello logico, infatti aggiunte o modifiche alle viste non richiedono modifiche al livello logico mentre modifiche che allo schema logico che lasciano inalterato lo schema esterno sono trasparenti.
Schemi e Istanze
In ogni base di dati esistono:
- Schema: Non cambia nel tempo e ne descrive la struttura, sono le intestazioni delle tabelle.
- Istanza: I valori attuali che possono cambiare, sono gli elementi di ogni tabella.
Linguaggi per le Basi di Dati
- Data Definition Language (DDL): Per la definizione degli schemi
- Data Manipulation Language (DML): Per l’interrogazione e l’aggiornamento delle istanze della base di dati.
- SQL (Structured Query Language): Linguaggio standardizzato per database basati sul modello relazionale. In SQL le due funzionalità sono integrate in un unico linguaggio.
Ricapitolando
Le basi di dati sono:
- Multiuso
- Integrazione
- Indipendenza dei dati
- Controllo centralizzato (DBA: Database Administrator).
I vantaggi sono:
- Minima ridondanza
- Indipendenza dei dati
- Integrità
- Sicurezza
Integrità
I dati devo soddisfare i vincoli imposti dalla realtà di interesse, ad esempio:
- Uno studente vive in una sola città, Dipendenze Funzionale.
- La matricola identifica univocamente uno studente, Vincoli di Chiave.
- Un voto è un intero positivo compreso tra 18 e 30, Vincoli di Dominio.
- Lo straordinario di un impiegato è dato dal prodotto del numero di ore per la paga oraria, lo stipendio non può diminuire, Vincoli Dinamici.
Sicurezza
I dati devono essere protetti da accessi non autorizzati, il DBA deve considerare chi può accedere a quali dati e in quale modalità e decidere il regolamento di accesso e gli effetti di una violazione, inoltre i dati devono essere protetti da malfunzionamenti hardware, software e dall’accesso concorrente alla base di dati.
Ad esempio una transazione deve essere eseguita completamente, committed oppure non deve essere eseguita affatto rolled back.
Per ripristinare un valore corretto si usa il transaction log che contiene i dettagli delle operazioni, si esegue il dump ovvero la copia dei dati.
Concorrenza
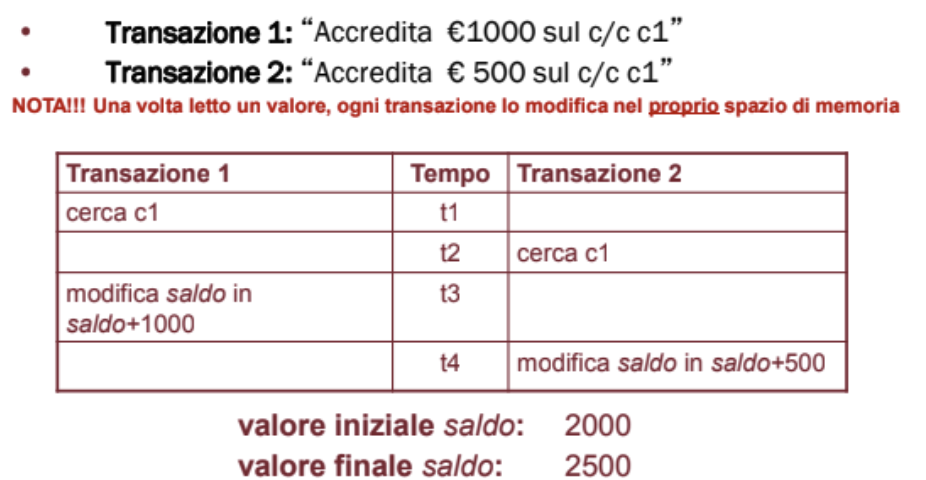
La transazione 1 ha impostato il saldo a 2000 + 1000 mentre la due avendo letto il dato prima della fine della 1 lo ha impostato a 2000 + 500 e terminando per ultima lo ha impostato come valore finale. Per questo è importante gestire la concorrenza.
Il compito di un DBA è quindi:
- Definizione e descrizione di:
- Schema Logico
- Schema Fisico
- Viste
- Mantenimento:
- Modifiche per nuove esigenze o efficienza
- Routine (analisi, ripristino ecc…)
Modello Relazionale
Si basa sul concetto matematico di relazione, queste sono come delle tabelle e d’ora in poi le chiameremo appunto relazioni.
- Relazione matematica.
- Relazione secondo il modello relazionale dei dati.
- Relazione che rappresenta un’associazione nel modello Entità - Relazioni, rappresenta un collegamento concettuale tra entità diverse.
Definizioni
- Dominio: un insieme, anche infinito, di valori. Siano D1, D2,…,Dk domini, il prodotto cartesiano di tali domini è dato da:
- Una relazione matematica è un sottoinsieme del prodotto cartesiano di uno o più domini.
- Una relazione che è sottoinsieme del prodotto cartesiano di domini si dice di grado k. (grado = numero di domini)
- Gli elementi di una relazione sono detti tuple, il numero di tuple di una relazione indica la cardinalità di quest’ultima. (cardinalità = numero di coppie ordinate, ovvero tuple).
- Ogni tupla di una relazione di grado ha componenti ordinate (attributi) ma non c’è ordinamento tra le tuple.
- Le tuple di una relazione sono tutte distinte almeno per un valore dai vincoli sugli insiemi. (Almeno un elemento deve cambiare fra ciascuna).
Esempio
Supponiamo che e i due domini sono e , il prodotto cartesiano è dato da .
Come relazioni possiamo prendere:
- : Ha come cardinalità 3 e come grado 2.
- : Ha come cardinalità 2 e come grado 2.
Spesso si usano come domini comuni ai linguaggi di programmazione come String, Integer, Boolean.
Notazioni
- Se è una relazione di grado
- Se è una tupla di
- Se è un numero intero nell’insieme
Allora indica la i-esima componente di
Esempio
- Se
Relazioni e Tabelle
Per interpretare le tabelle dobbiamo assegnare dei nomi a queste e alle loro colonne:
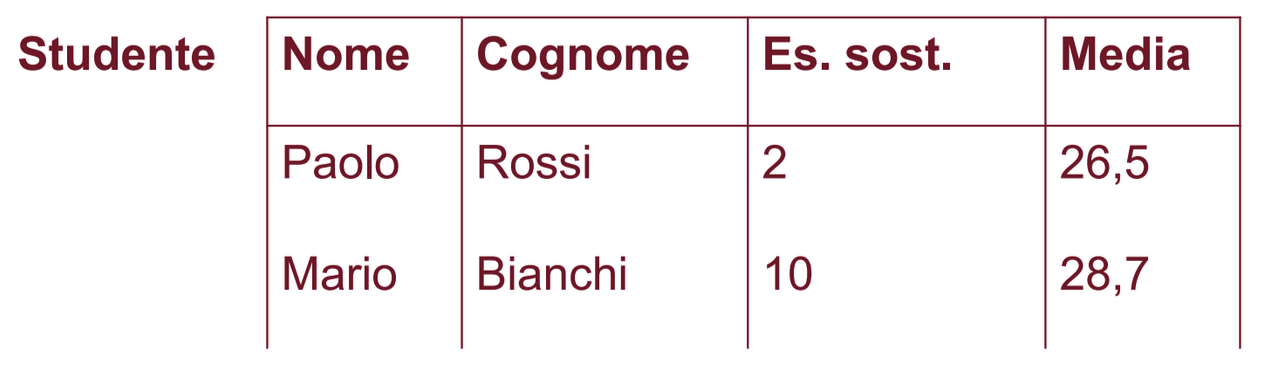
- Un attributo è definito da un nome A e dal dominio dell’attributo A che indichiamo con dom(A).
- Sia un insieme di attributi, un’ennupla su è una funzione definita su che associa ad ogni attributo in un elemento di dom(A).
- Se è un’ennupla su ed è un attributo in , allora con indicheremo il valore assunto dalla funzione in corrispondenza dell’attributo A.
Vediamo gli elementi graficamente:
Quindi:
-
Una relazione possiamo implementarla come una tabella dove ogni riga è una tupla della relazione e ogni colonna è un attributo.
-
Le colonne corrispondono ai domini e hanno associati dei nomi univoci, detti nomi degli attributi.
-
L’insieme degli attributi di una relazione è detto schema
-
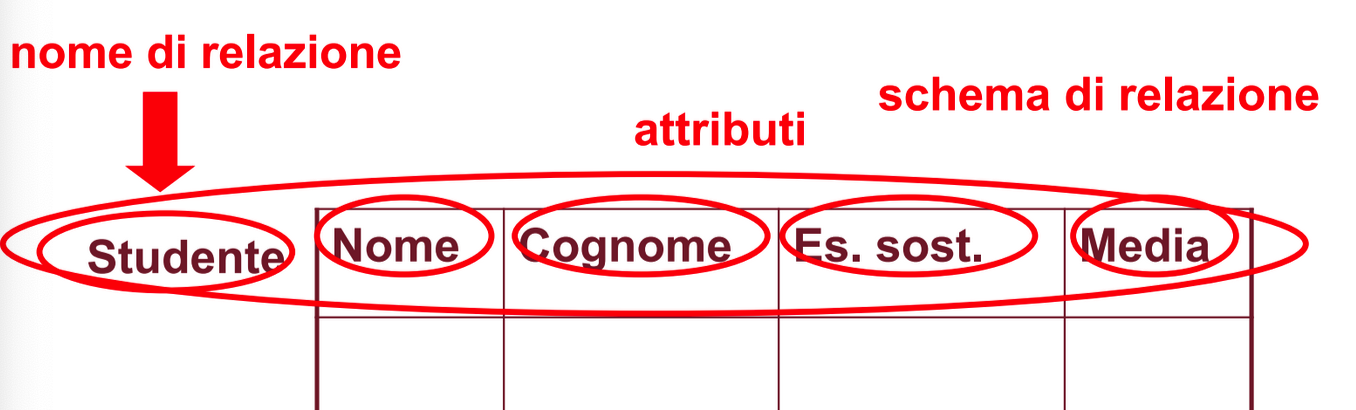
Se una relazione è denominata da e i suoi attributi hanno nomi A1, A2, …, Ak lo schema è indicato da , questo è lo schema di relazione.
-
Lo schema spesso è invariante nel tempo e descrive la struttura della relazione.
-
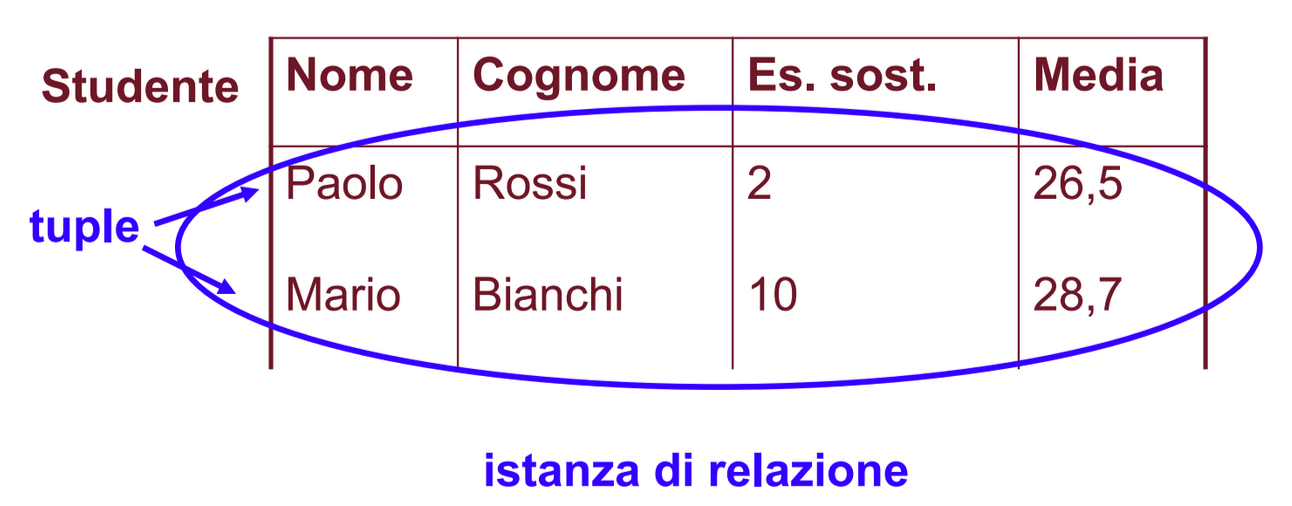
L’istanza di una relazione è un’insieme di tuple. (i valori presenti nella tabella)
-
L’istanza contiene i valori attuali e possono anche cambiare molto spesso.
-
Schema di base di dati: Un insieme di schemi di relazione con nomi differenti (un insieme di tabelle).
-
Schema di base di dati relazionale: Insieme di schemi di relazione
-
Base di dati relazionale con schema : un insieme dove è un’istanza di relazione con schema . Quindi lo schema della base sono l’insieme delle strutture delle tabelle mentre la base di dati sono i valori presenti nelle rispettive tabelle (istanze).
Esempio
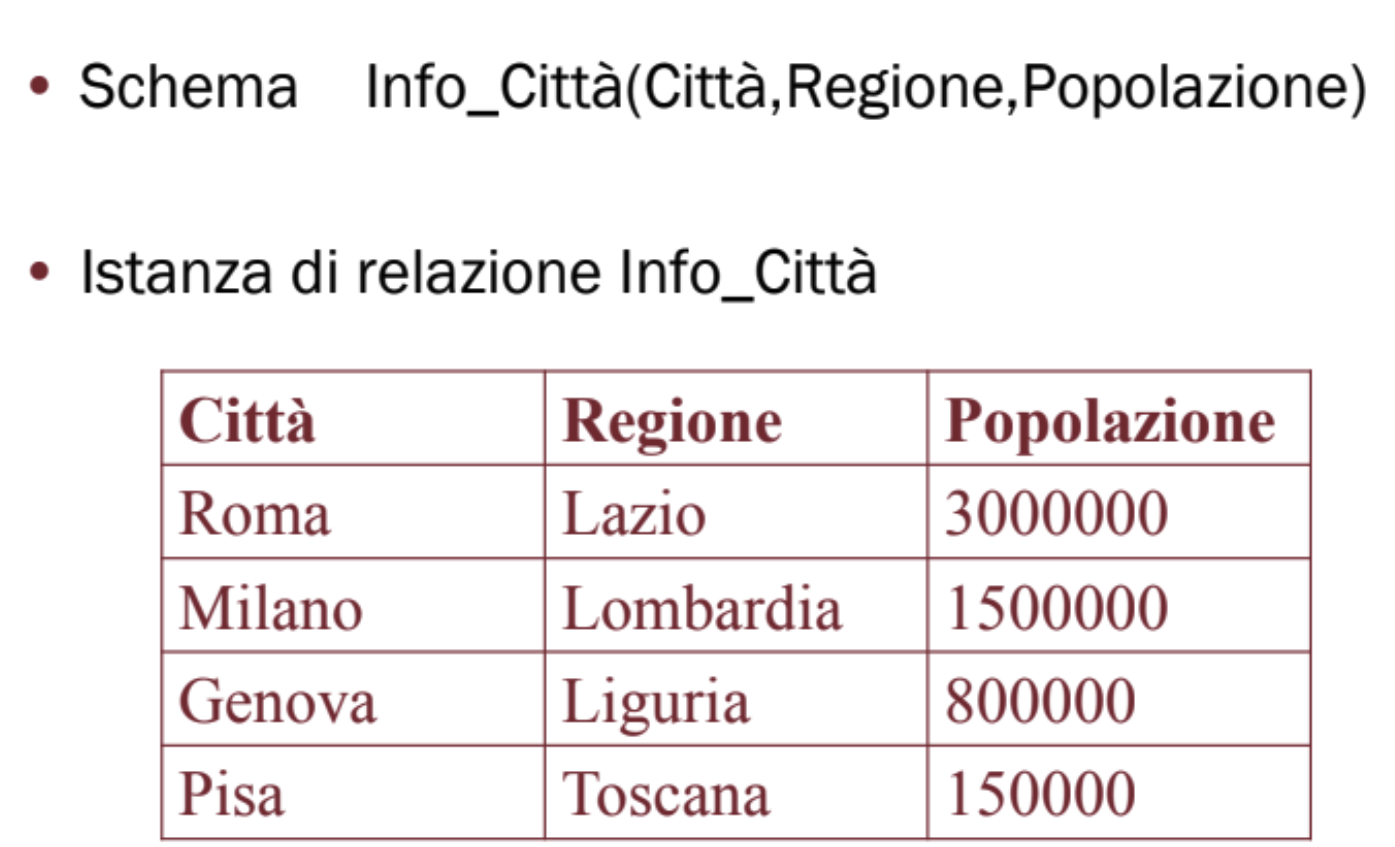
Prima abbiamo utilizzato la notazione per indicare il valore ad un determinato attributo di una tupla con intero, adesso si utilizza con nome dell’attributo, ad esempio se prendiamo seconda tupla dell’esempio sopra .
Se è un sottoinsieme di attributi dello schema di una relazione allora è il sottoinsieme dei valori nella tupla che corrispondono ad attributi contenuti in , detto restizione di .
Valori
Nel modello relazionale i riferimenti fra dati in relazioni diverse sono rappresentati per mezzo di valori dei domini che compaiono nelle ennuple.
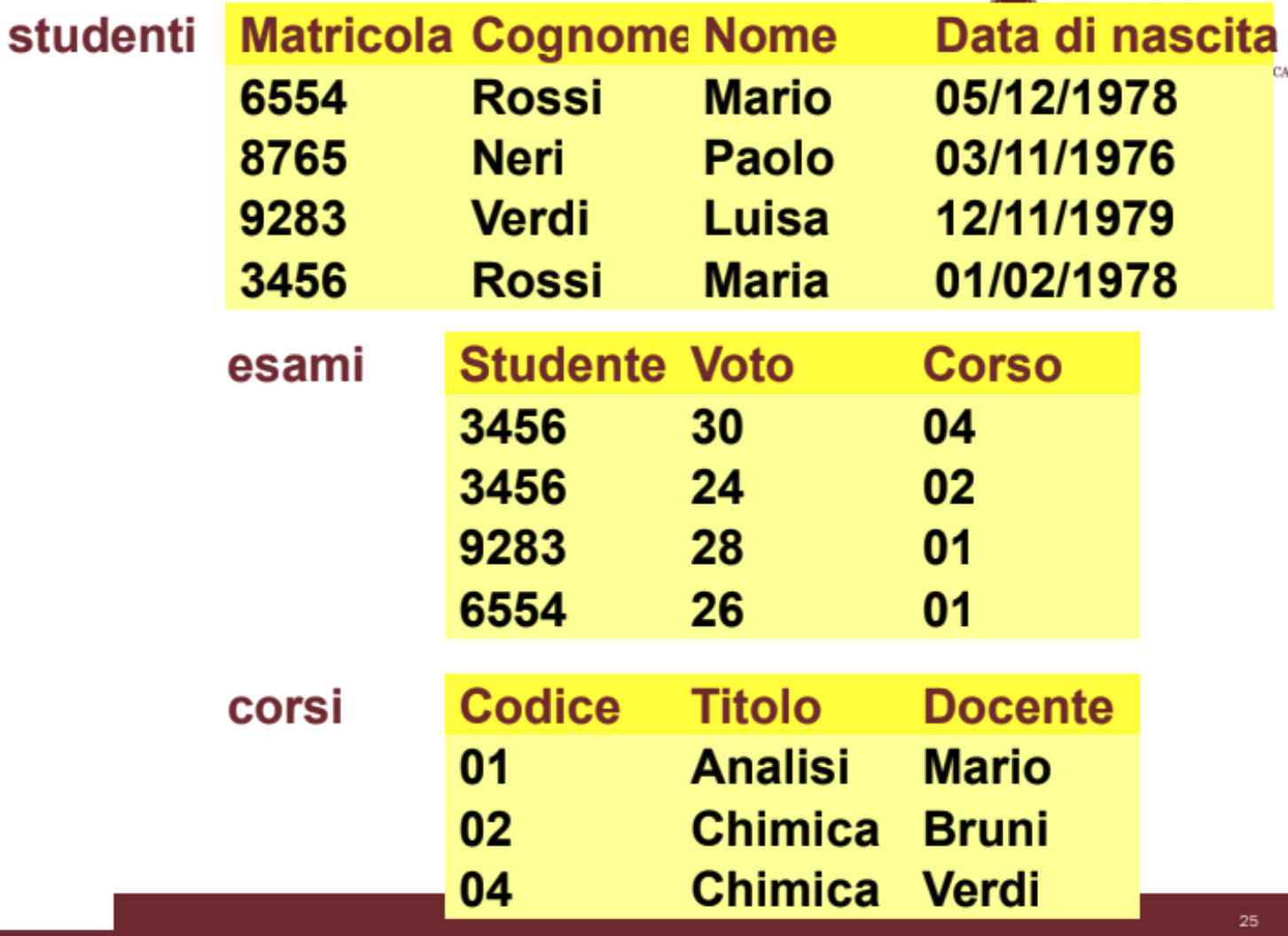
Qui ad esempio la tabella Esami mette in relazione gli Studenti e i Corsi rispettivamente tramite la Matricola e il Codice. Se una tabella contiene un elemento univoco di un’altra questa si chiama slave mentre l’altra master, in questo caso abbiamo quindi due master ovvero Studenti e Corsi mentre lo slave è Esami.
Il master quindi deve esistere prima dello slave altrimenti non è possibile creare il secondo.
All’interno di una tupla è possibile inserire anche dei valori nulli ma non possiamo omettere completamente un campo, le tuple devono seguire tutte lo stesso schema. Se vogliamo “omettere” dei campi possiamo stabilire un valore di default.
Valore Speciale NULL
Il valore null non appartiene a nessun dominio ma può essere assegnato a un dominio qualsiasi (qualsiasi attributo). Se prendiamo confrontiamo due valori null, anche sullo stesso dominio di attributo, questi risulteranno sempre diversi. Non è possibile assegnare NULL ai valori usati come identificativi delle tuple.
Vincoli

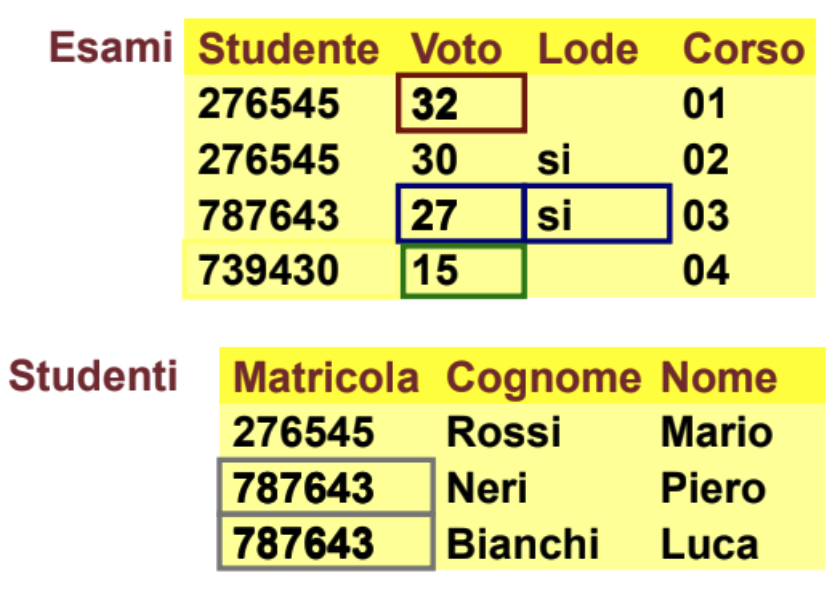
Entrambe questi basi di dati presentano degli errori, nella prima abbiamo una data di assunzione impossibile, un codice impiegato ripetuto ma che è un valore univoco e un codice DIP non esistente.
Nella seconda altri tipi di errori ad esempio 32 un voto che non esiste, una lode con un 27 un valore sotto al 18, mentre sugli studenti una matricola duplicata.
I Vincoli di Integrità sono delle regole che devono essere soddisfatte da ogni istanza della base di dati.
Quindi nel primo caso possiamo stabilire che:
- Assunzione deve essere > 1980
- Codice impiegato deve essere UNIQUE
- Il campo DIP è collegato al campo Dipartimento.Numero. Nella seconda base:
- Voto >= 18 AND Voto ⇐ 30
- Voto = 30 OR NOT Lode = “si”
- Il campo Esami.Studente è collegato a Studenti.Matricola
- Matricola deve essere UNIQUE
Possiamo dividerli in due categorie: Vincoli Intra-Relazionali e Vincoli Inter-Relazionali
Vincoli Intra-Relazionali
Sono definiti su valori di singoli attributi oppure tra valori di una stessa tupla o ancora tra tuple della stessa relazione.
- Vincoli di chiave Primaria: unica e mai nulla
- Vincoli di Dominio: ad esempio Assunzione > 1980
- Vincoli di Unicità: li indichiamo con UNIQUE
- Vincoli di Tupla: Voto = 30 OR NOT Lode = “si”
- Vincoli di esistenza del valore per un certo attributo: NOT NULL
- Espressioni sul valore di attributi della stessa tupla: ad esempio orario_partenza < orario_arrivo, con gli orari di un treno.
Vincoli Inter-Relazionali
Sono vincoli definiti tra più relazioni ad esempio:
- Impiegato.DIP references dipartimento.numero
- Esami.studente references Studenti.Matricola
Chiavi
In un’istanza di relazione dobbiamo identificare univocamente le tuple di una relazione e per fare questo utilizziamo le chiavi, la chiave può essere un attributo o un insieme di attributo.
Un insieme di attributi di una relazione è una chiave se soddisfa le seguenti condizioni:
- Per ogni istanza di , non esistono due tuple e che hanno gli stessi valori per tutti gli attributi in , ovvero che . Quindi i valori in questi attributi devono essere tutti diversi fra le tuple, unici.
- Nessun sottoinsieme proprio di X soddisfa la condizione 1. Questo significa che la chiave può essere semplicemente quel sottoinsieme, ovviamente dovremo ricontrollare la seconda condizione anche all’interno di quest’ultimo.
Nel caso in cui un sottoinsieme proprio di non soddisfi la seconda condizione, prende il nome di superchiave. Una chiave è anche superchiave dato che è unsieme che contiene se stessa.
Una relazione potrebbe avere più chiavi alternative e si sceglie quella più usata o quella composta da un numero minore di attributi, questa prende il nome di chiave primaria. Questa non ammette valori nulli, deve esserci sempre una chiave dato che le tuple non possono essere uguali e inoltre consentono di mettere in relazione diverse tabelle fra loro.
Vincolo di Integrità Referenziale
Delle informazioni presenti in relazioni diverse possono essere messe in relazione fra loro tramite le foreign key:
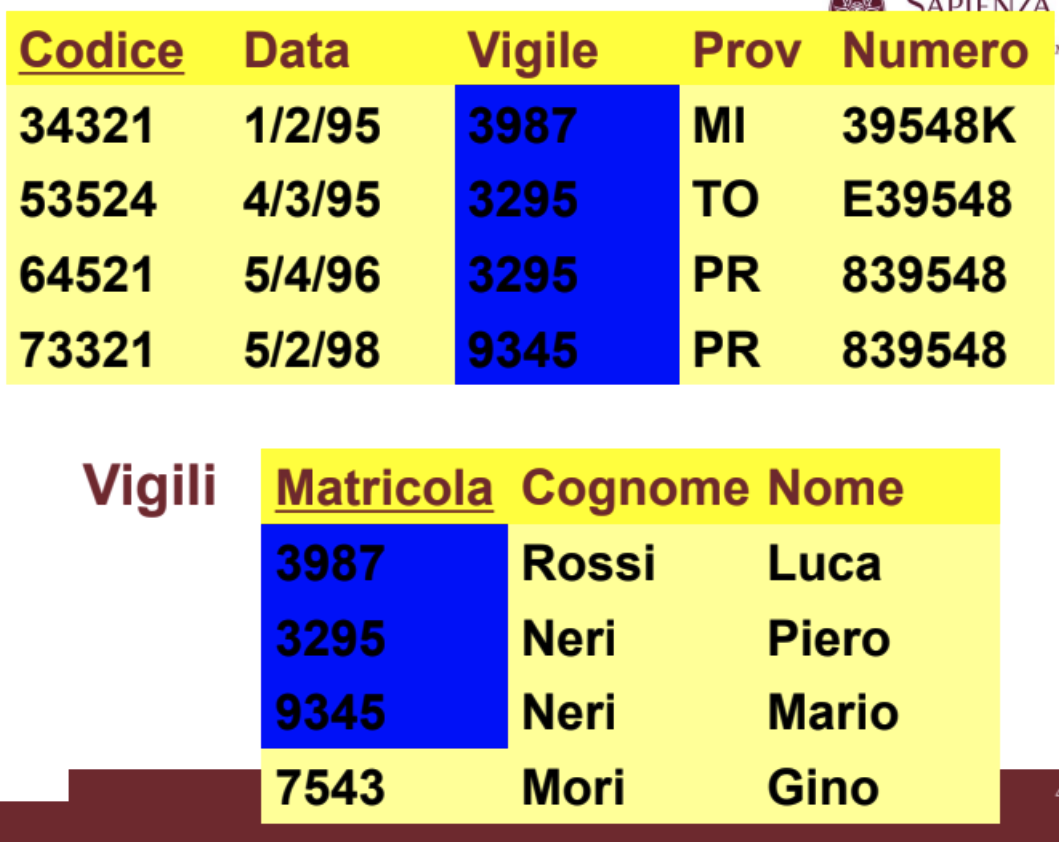
Nella tebella Infrazioni l’attributo Vigile è una foreign key che la mette in relazione con la tabella Vigili.
Come detto prima la chiave può essere composta da più attributi:
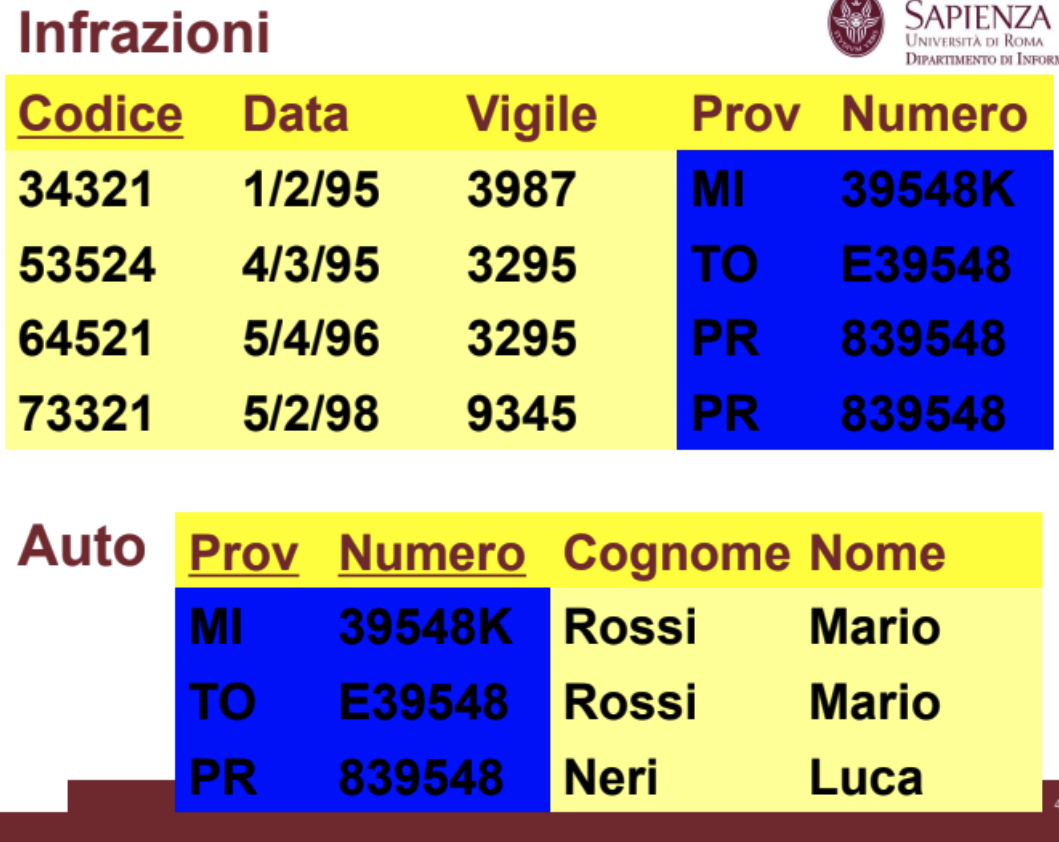
In questo caso la chiave primaria della Relazione Auto è formata da Prov e Numero e quindi in Infrazioni sono presenti entrambe le informazioni come foreign key.
Le Chiavi si stabiliscono in base alle Dipendenze Funzionali.
Dipendenze Funzionali
Una dipendenza funzionale stabilisce un legame semantico tra due insiemi non vuoti di attributi appartenenti ad uno schema .
Il vincolo si scrive e si legge determina .
Esempio
Il nostro schema è: VOLI(CodiceVolo, Giorno, Pilota, Ora).
Stabiliamo dei vincoli:
- Un volo con un certo codice parte sempre alla stessa ora
- Esiste un solo volo con un dato pilota, in un dato giorno ad una data ora
- C’è un solo pilota di un dato volo in un dato giorno. Otteniamo le seguenti dipendenze funzionali:
- CodiceVolo → Ora (Dato che un volo con lo stesso codice parte sempre alla stessa ora)
- {Giorno, Pilota, Ora} → CodiceVolo (Dato che c’è un solo volo con un determinato pilota, giorno e ora)
- {CodiceVolo, Giorno} → Pilota (Dato che c’è un solo pilota dato un volo in un dato giorno)
Questo significa che come chiave posso usare l’insieme {CodiceVolo, Giorno} dato che CodiceVolo mi determina l’ora e con CodiceVolo e Giorno posso determinare il Pilota.
Non posso usare ad esempio soltanto il CodiceVolo dato che in quel caso saprei soltanto a che ora parte l’aereo ma non saprei chi sarà il pilota e che giorno partirà.
Diremo che una relazione soddisfa la dipendenza funzionale se:
- La dipendenza funzionale è applicabile a , ovvero che sono sottoinsiemi di .
- Le ennuple in che concordano su concordano anche su , ovvero per ogni coppia di ennuple e in abbiamo che . Prendendo l’esempio di prima quindi, se due tuple concordano sul CodiceVolo (X) devono concordare anche sull’ora (Y).
- Nel caso in cui allora ci basta verificare che prese due tuple qualsiasi per stabilire che la dipendenza non è rispettata.
X prende il nome di Determinante e Y di Dipendente, inoltre un’istanza si dice legale quando soddisfa tutte le dipendenze funzionali.
Algebra Relazionale
Linguaggio Formale per interrogare una base di dati relazionale: Consiste in un insieme di operatori che possono essere applicati ad una o due relazioni e forniscono come risultato una nuova istanza di relazione.
Inoltre è un Linguaggio Procedurale: L’interrogazione consiste in un’espressione in cui compaiono operatori dell’algebra e istanze di relazioni della base di dati, in una sequenza che stabilisce l’ordine delle operazioni e i loro operandi.
Proiezione
Consiste nell’effettuare un taglio verticale su una relazione, ovvero selezionare soltanto alcuni attributi di essa.
Si denota con il simbolo ad esempio , in questo modo stiamo selezionando le colonne di che corrispondono agli attributi .
Esempio
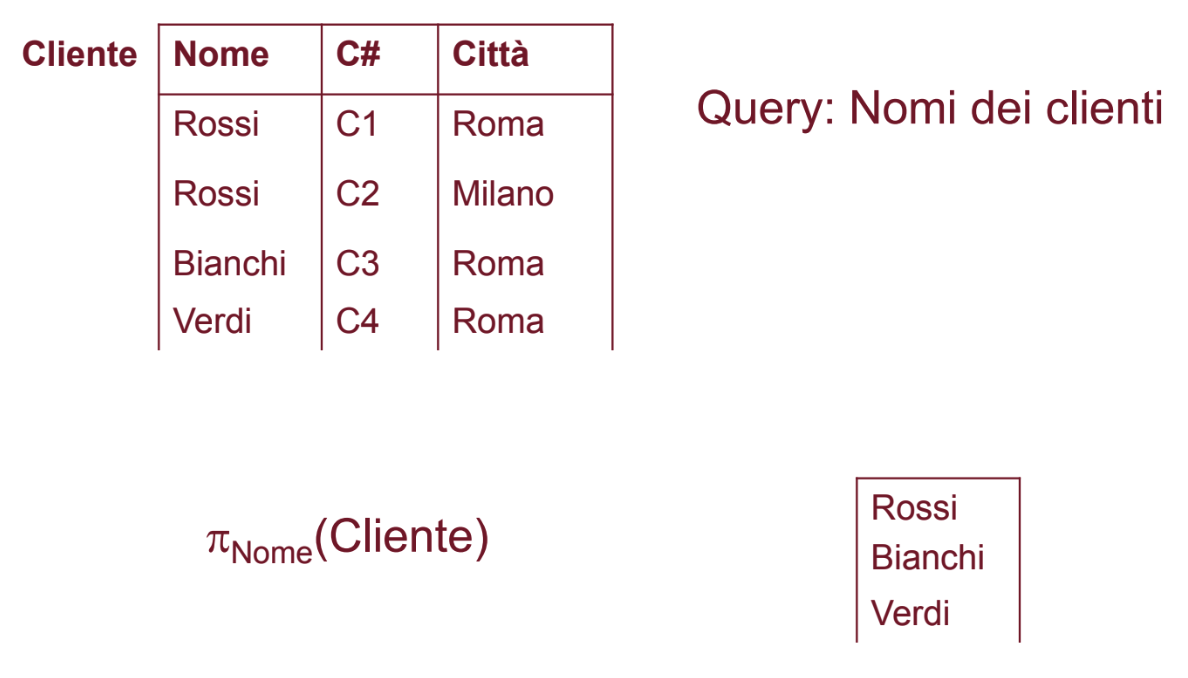
NOTA: Si seguono le regole insiemistiche e quindi nella relazione risultato non ci sono duplicati, notiamo però che abbiamo cancellato delle ennuple significative, ovvero delle ennuple che sono in realtà diverse se consideriamo tutti gli attributi.
Dobbiamo considerare nella proiezione anche un attributo in più, in questo caso la chiave ovvero C#:
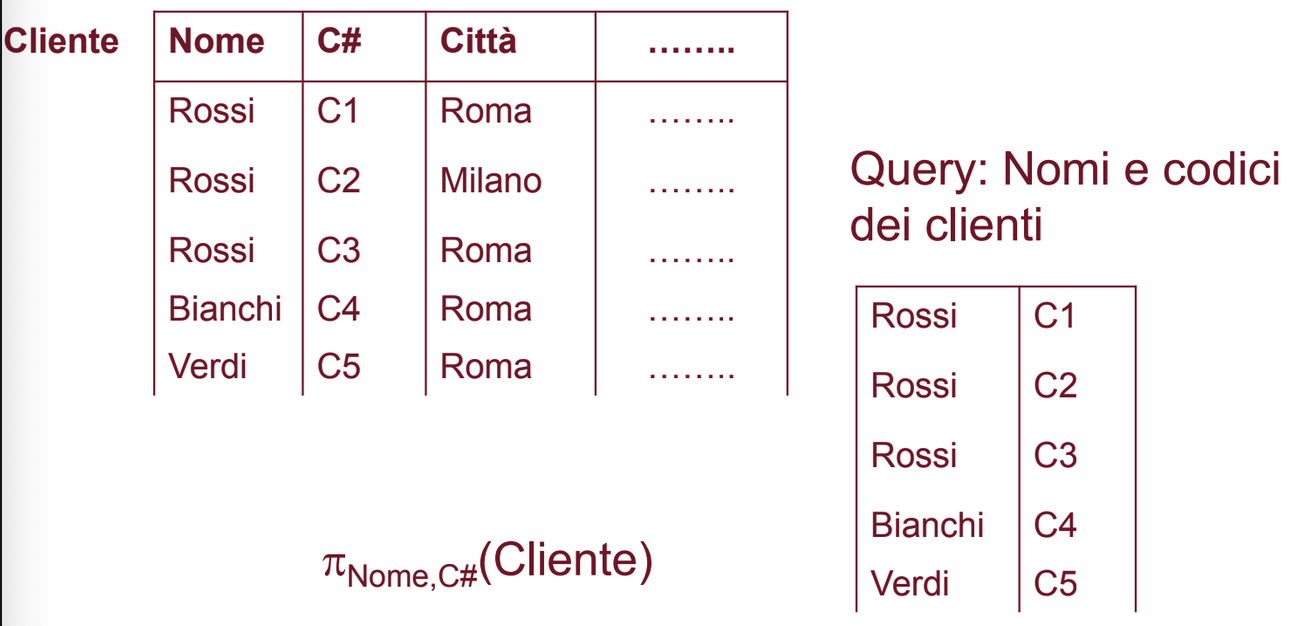
Selezione
Consente di effettuare soltanto alcune tuple di una relazione.
Si denota con il simbolo , in questo caso seleziona le tuple della relazione che soddisfano la condizione .
La selezione è un’espressione booleana composta in cui i termini semplici sono del tipo:
- oppure
Dove:
- è un operatore di confronto,
- A e B sono due attributi con lo stesso dominio
- a è un elemento di dom(A)
Esempio
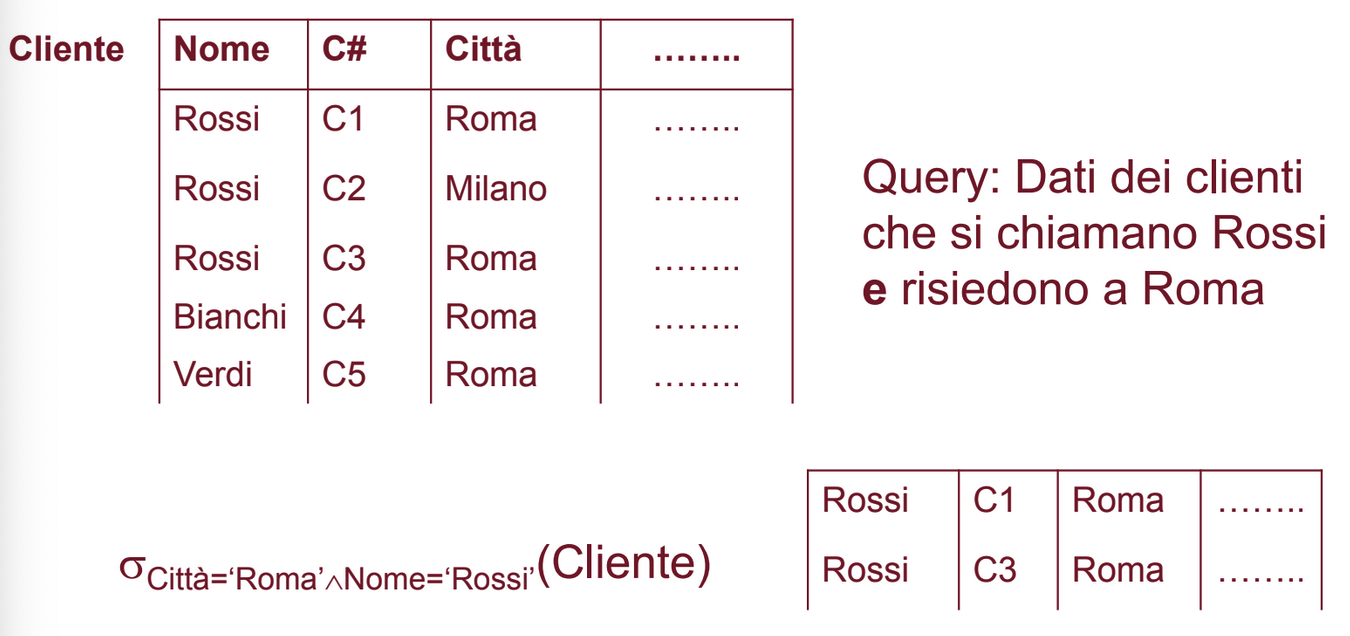
Da notare che al contrario della proiezione, con la selezione non rischiamo di perdere dati significativi.
Unione
Costruisce una relazione contenente tutte le ennuple che appartengono ad almeno uno dei due operandi, si denota con
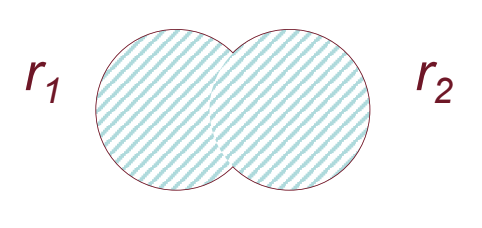
L’unione può essere applicata soltanto ad operandi compatibili ovvero:
- Hanno lo stesso numero di attributi
- Gli attributi corrispondenti nell’ordine devono avere lo stesso dominio
Gli schemi in questo caso sono detti union compatibili.
Inoltre:
-
Non è necessario che gli attributi abbiano lo stesso nome ma l’unione ha senso se hanno un significato omogeneo.
Ad esempio Numero di esami ed Età sono definiti sullo stesso dominio ma non avrebbe senso unire due relazioni che hanno questi attributi in colonne corrispondenti.
-
Uno o entrambi gli operandi possono essere il risultato di operazioni precedenti, ad esempio eliminare gli attributi incompatibili.
Esempio 1
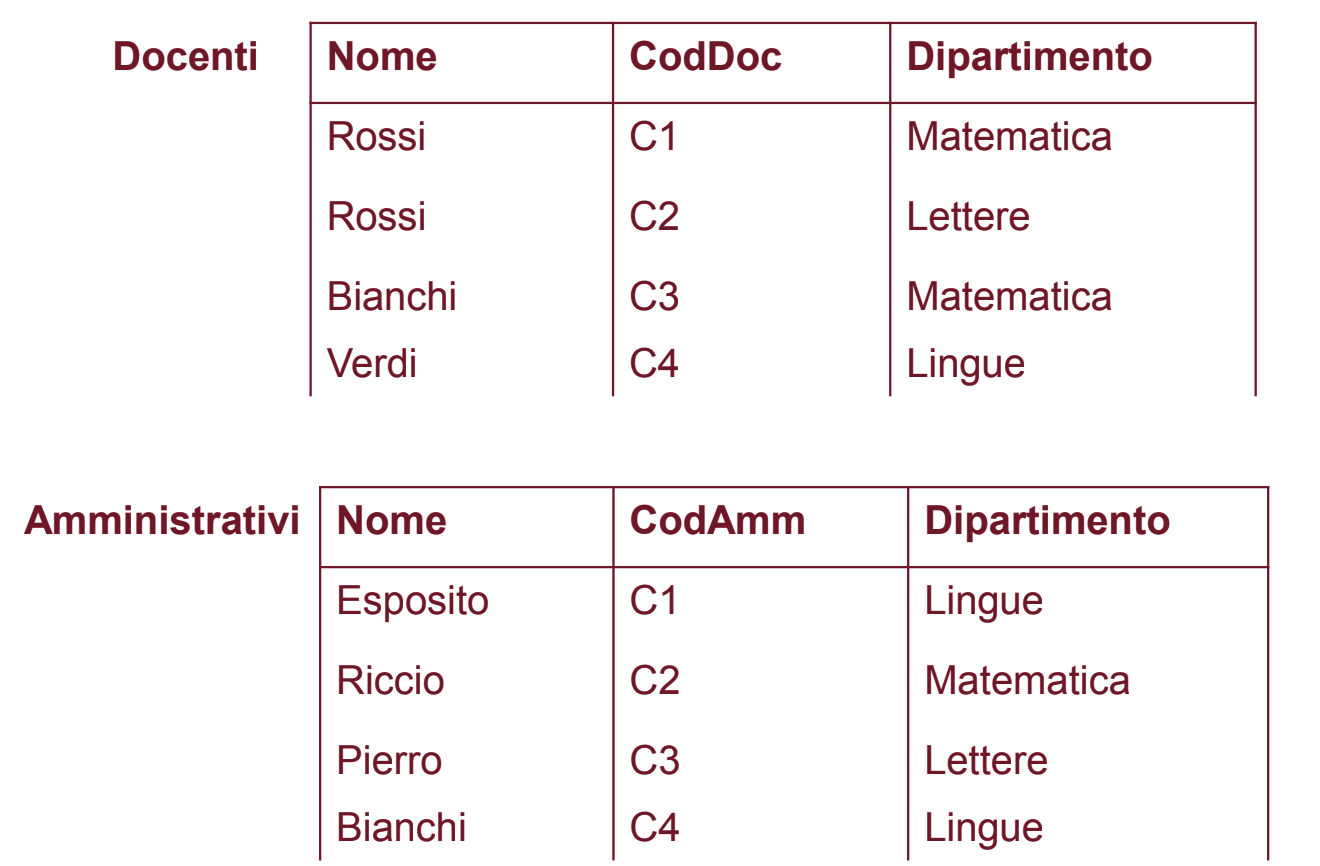
In questo caso l’unione è fattibile, dato che le istanze sono compatibili, otteniamo quindi:
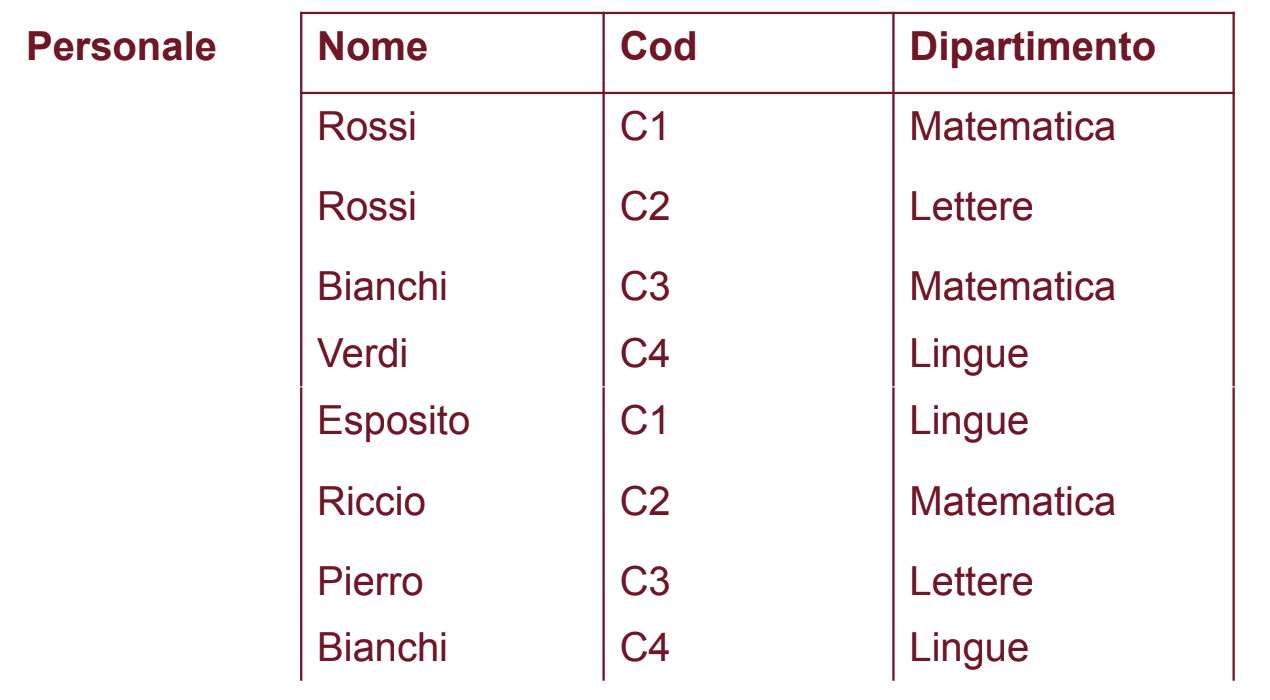
Abbiamo un problema adesso, non riusciamo più a distinguere i Docenti dagli Amministrativi, inoltre dovremmo avere 9 membri del personale ma ne abbiamo solo 8, questo perché una tupla era presente in entrambe le relazioni e quindi è stata riportata una sola volta (Bianchi, C4, Lingue).
Questo è un problema di progettazione, possiamo risolverlo cambiando la notazione per i COD:
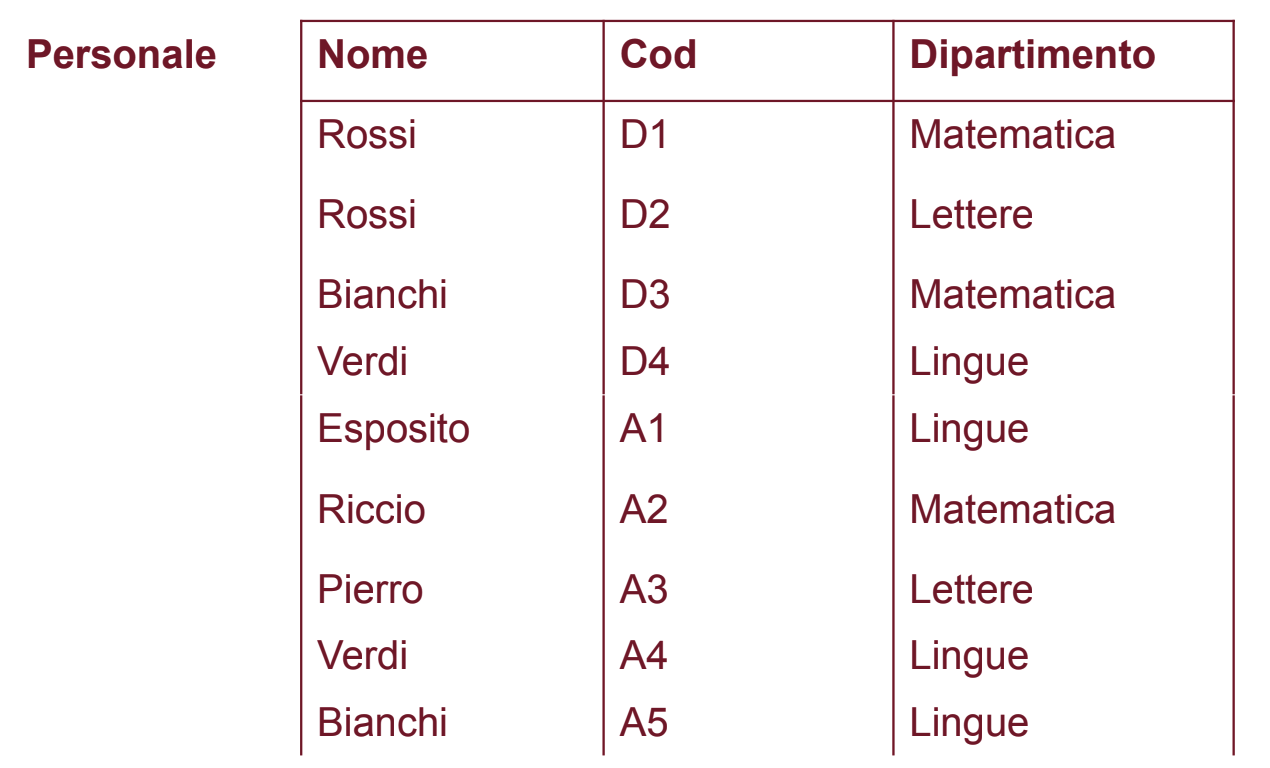
In questo modo vediamo tutto il personale e riusciamo anche a ditinguerli.
Esempio 2
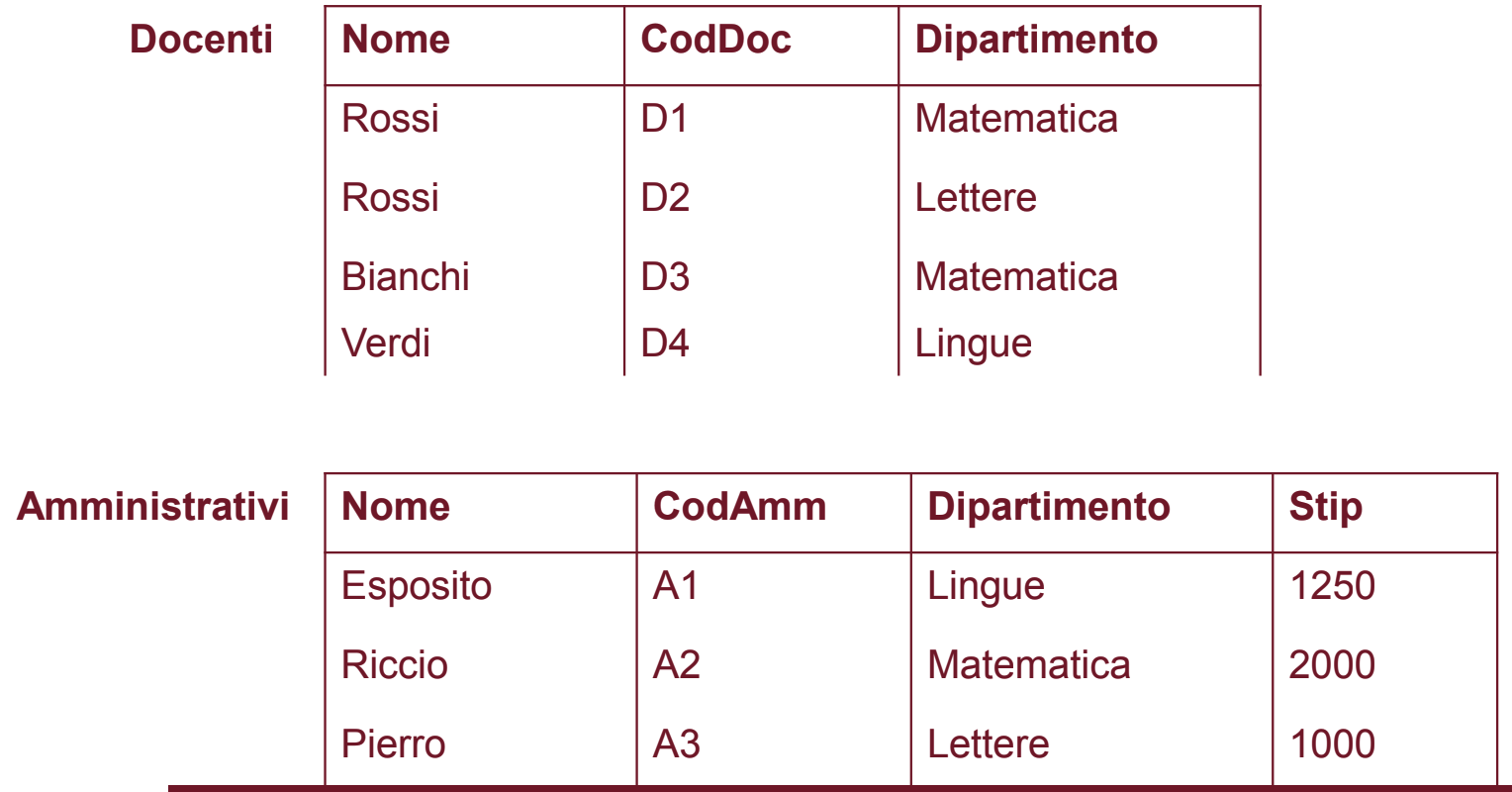
In questo caso non possiamo effettuare l’unione, le due istanze non hanno lo stesso numero di attributi. Come possiamo proseguire?
Possiamo proiettare su un sottoinsieme di attributi comuni (con significato compatibile):

Quindi Amministrativi non ha più l’attributi Stip e quindi le relazioni diventano compatibili.
Esempio 3
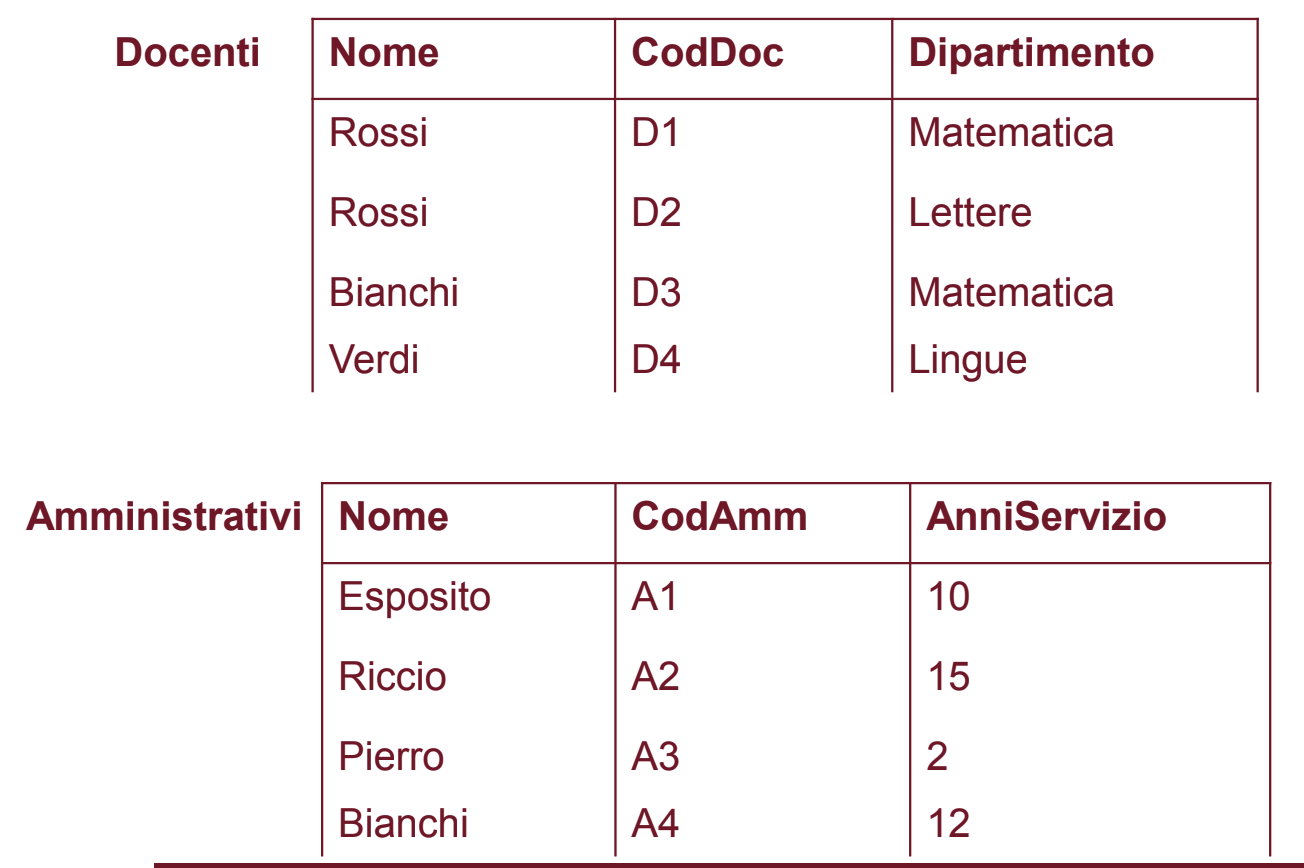
In questo caso non dobbiamo proiettare entrambe le relazioni dato che abbiamo si lo stesso numero di attributi ma Dipartimento e AnniServizio non sono compatibili, dobbiamo quindi rimuoverli entrambi.

Esempio 4
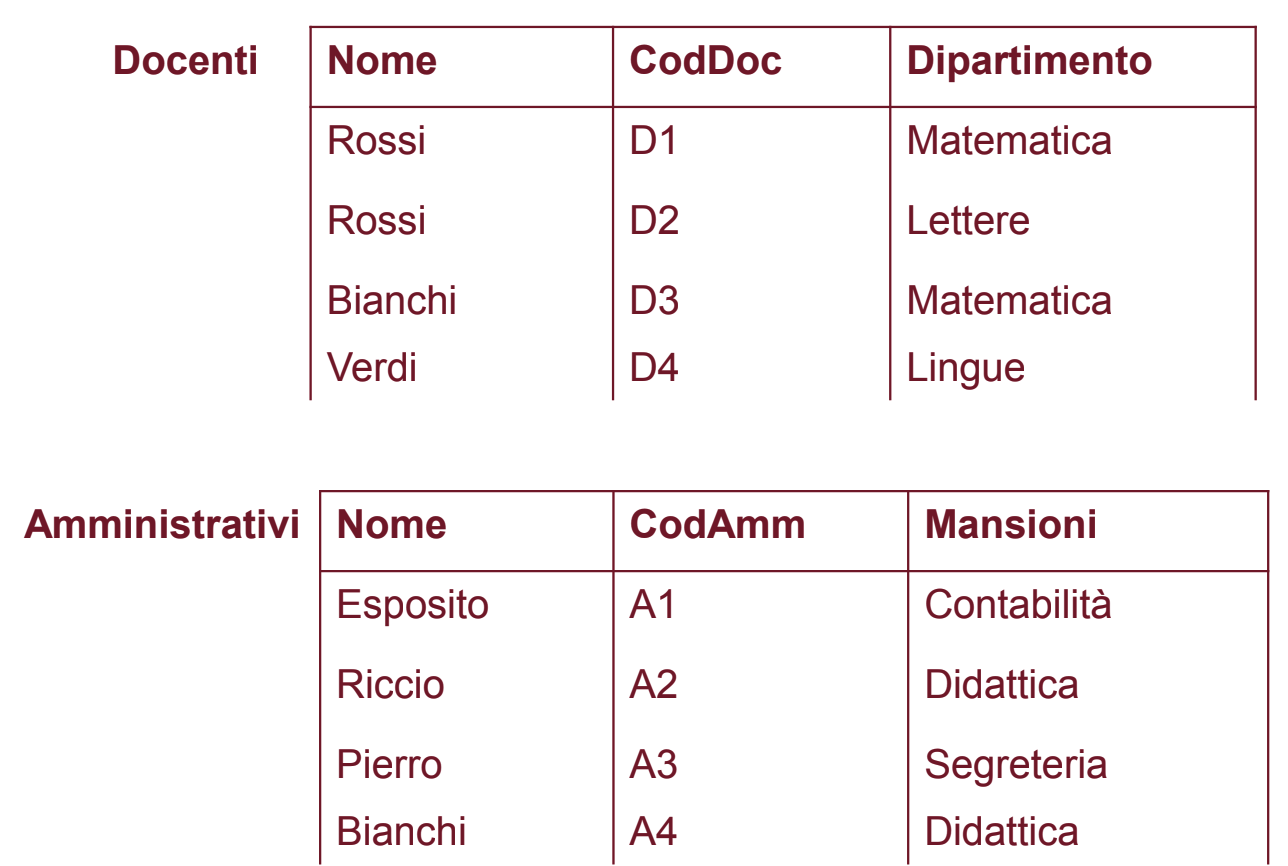
In questo caso Dipartimento e Mansioni hanno lo stesso dominio ma significato diverso, in questo caso possiamo proiettare togliendo i due attributi, come visto prima.

Differenza
Anche la differenza si applica a operandi union compatibili, quindi le condizioni sono uguali a quelle dell’unione.
La differenza consente di costruire una relazione contenente tutte le tuple che appartengono al primo operando e non appartengono al secondo operando.
Si denota con il simbolo .
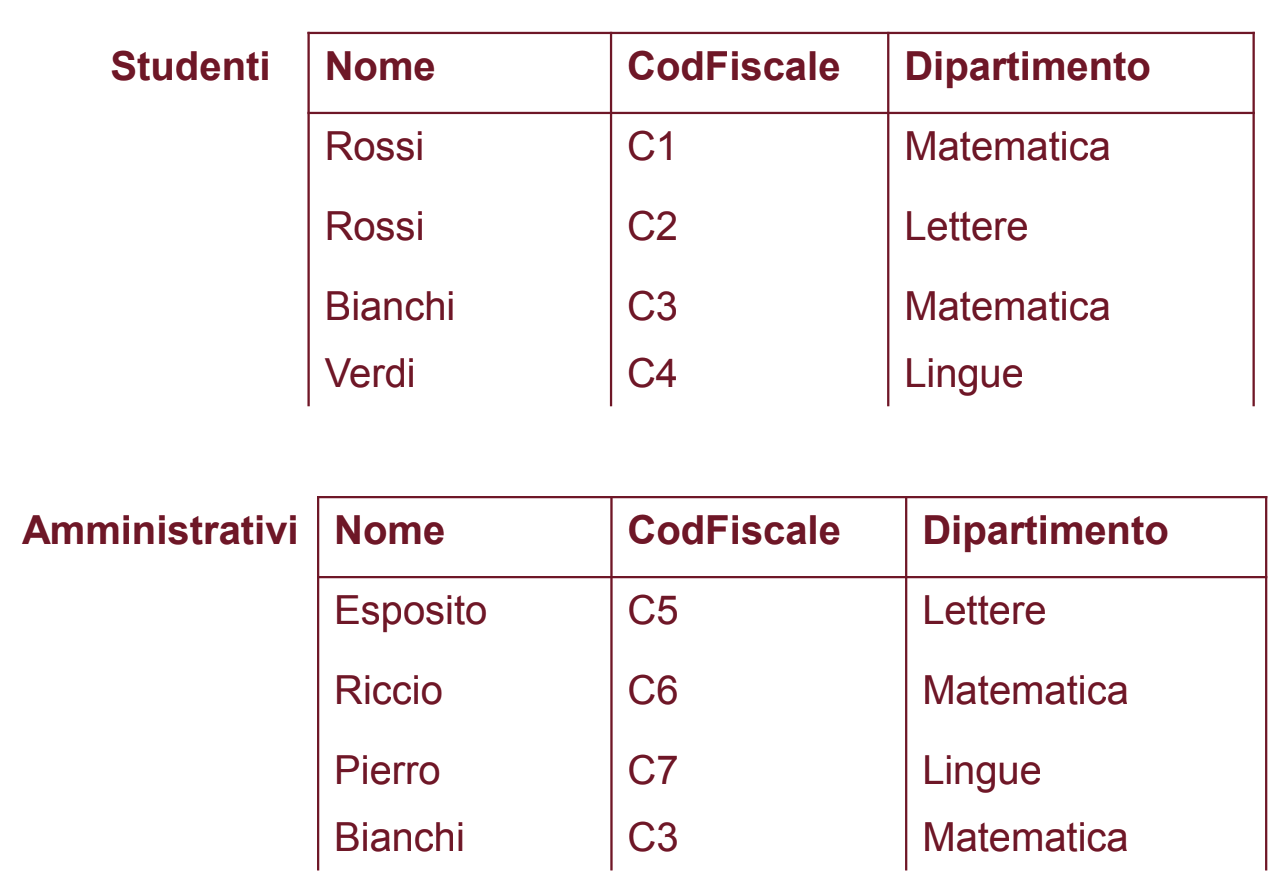
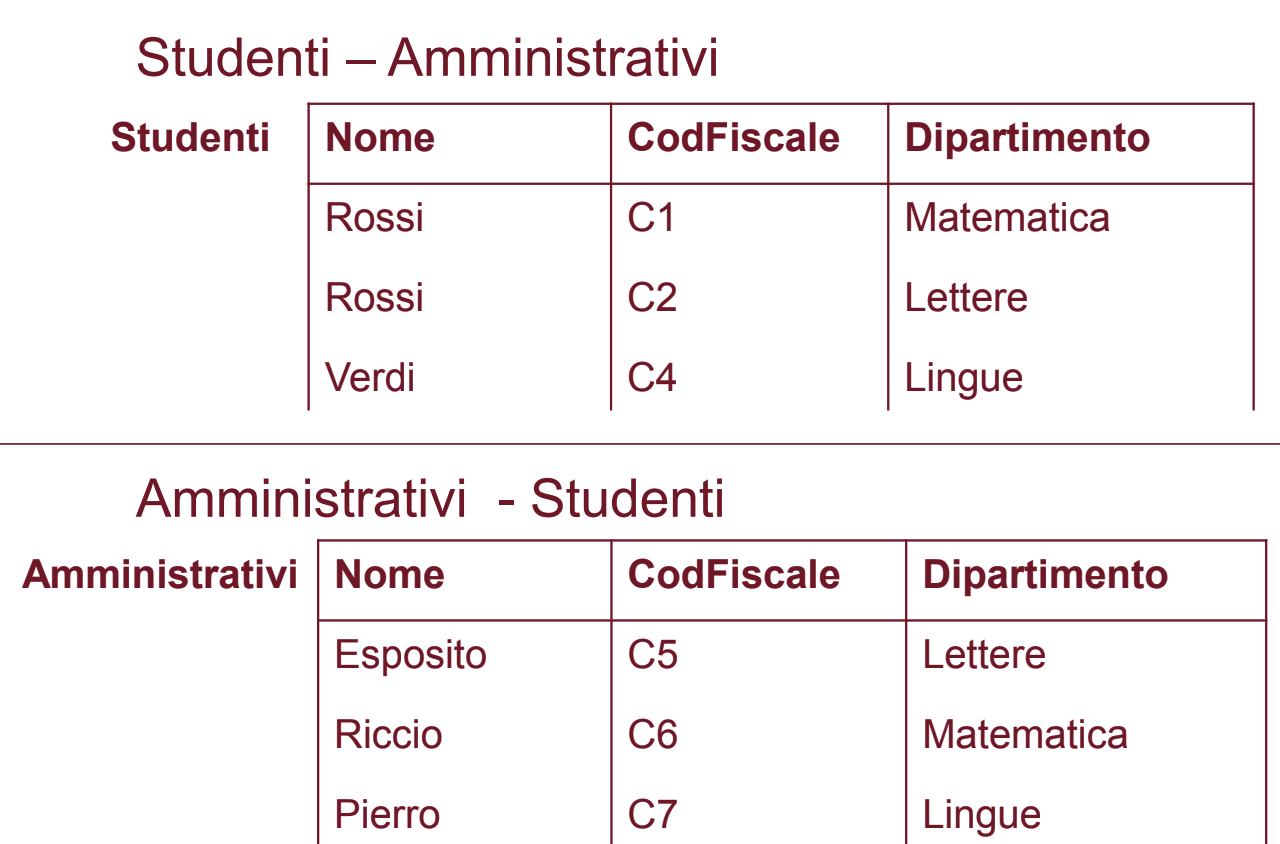
Attenzione, la differenza non è commutativa:
- Studenti - Amministrativi: Sono gli studenti che non sono anche amministrativi
- Amministrativi - Studenti: Sono gli amministrativi che non sono anche studenti.
Risultati:
Intersezione
Si applica sempre ad operandi union-compatibili, consente di costruire una relazione contenente tutte le tuple che appartengono ad entrambi gli operandi.
Si denota con
Esempio
- L’operazione intersezione è commutativa.

Come tutte le operazioni, se non rispetto la union-compatibili posso effettuare delle proiezioni.
Algebra Relazionale II
Per garantire un’ottima qualità di una relazione occorre rappresentare in relazioni diverse più concetti. Infatti capita spesso che le informazioni che interessano un’interrogazione sono distribuite in più relazioni dato che coinvolgono più oggetti associati fra loro.
Dobbiamo individuare le relazioni in cui si trovano le informazioni che ci interessano e combinare queste informazioni in modo opportuno.
Prodotto Cartesiano
Consente di costruire una relazione contenente tutte le ennuple che si ottengono concatenando ogni ennupla del primo operando con ogni ennupla del secondo.
Si denota con il simbolo e si utilizza quando le informazioni che occorrono per rispondere ad una query si trovano i relazioni diverse.
In questa operazione non dobbiamo rispettare la union-compatibile e per questo non tutti i risultati che otteniamo hanno un senso.
Esempio

Query: Dati dei clienti e degli ordini ().
Per poter distinguere gli attributi con lo stesso nome nello schema risultante possiamo usare l’operazione di ridenominazione per utilizzare una copia della relazione Ordine in cui l’attributo C# diventa CC#. Altrimenti avremmo anche potuto scrivere Ordine.C#.
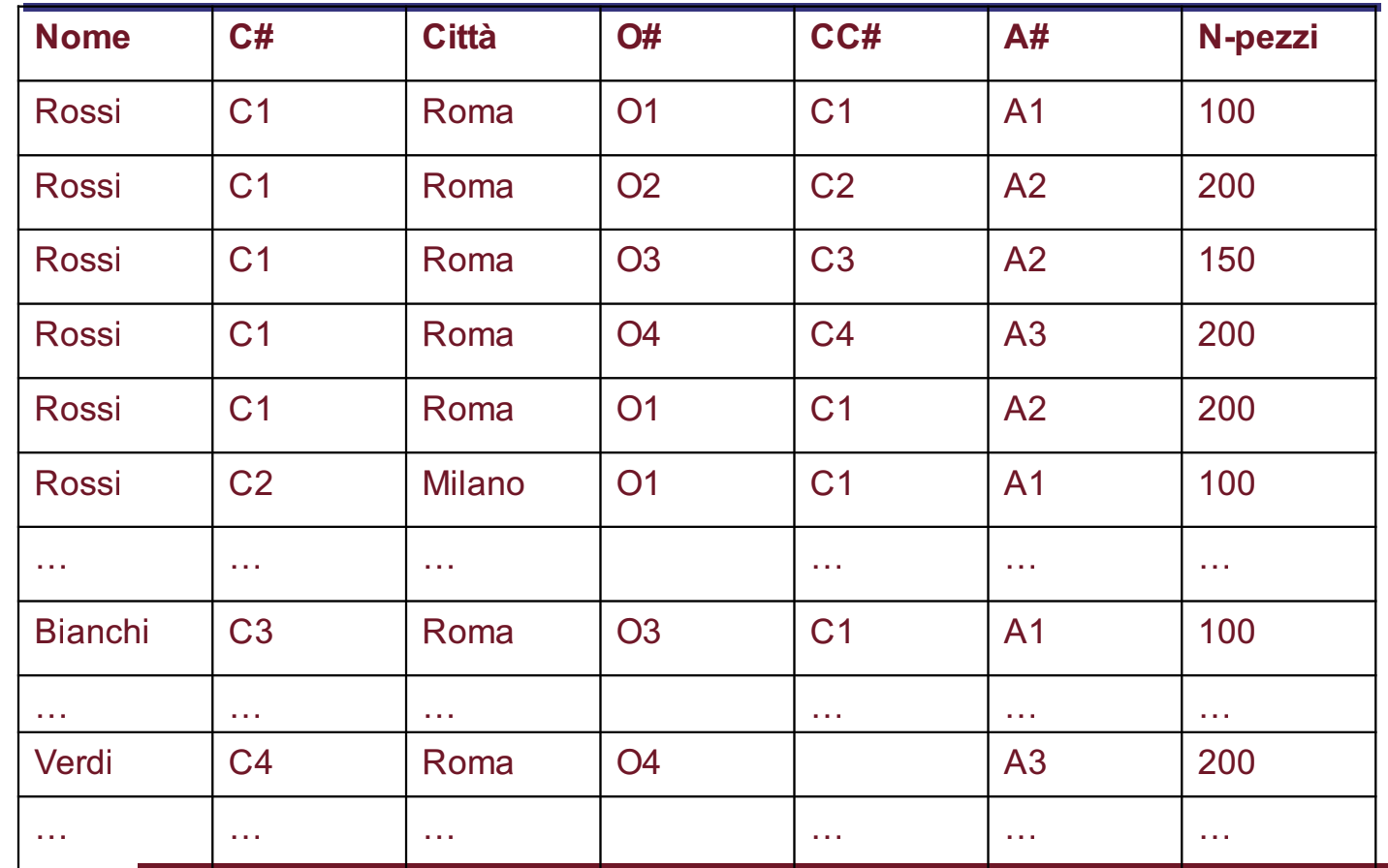
Adesso però abbiamo delle ennuple “inutili” dato che C# e CC# non corrispondono.
Per risolvere questo problema possiamo fare una selezione dove C# e C## sono uguali ottenendo:
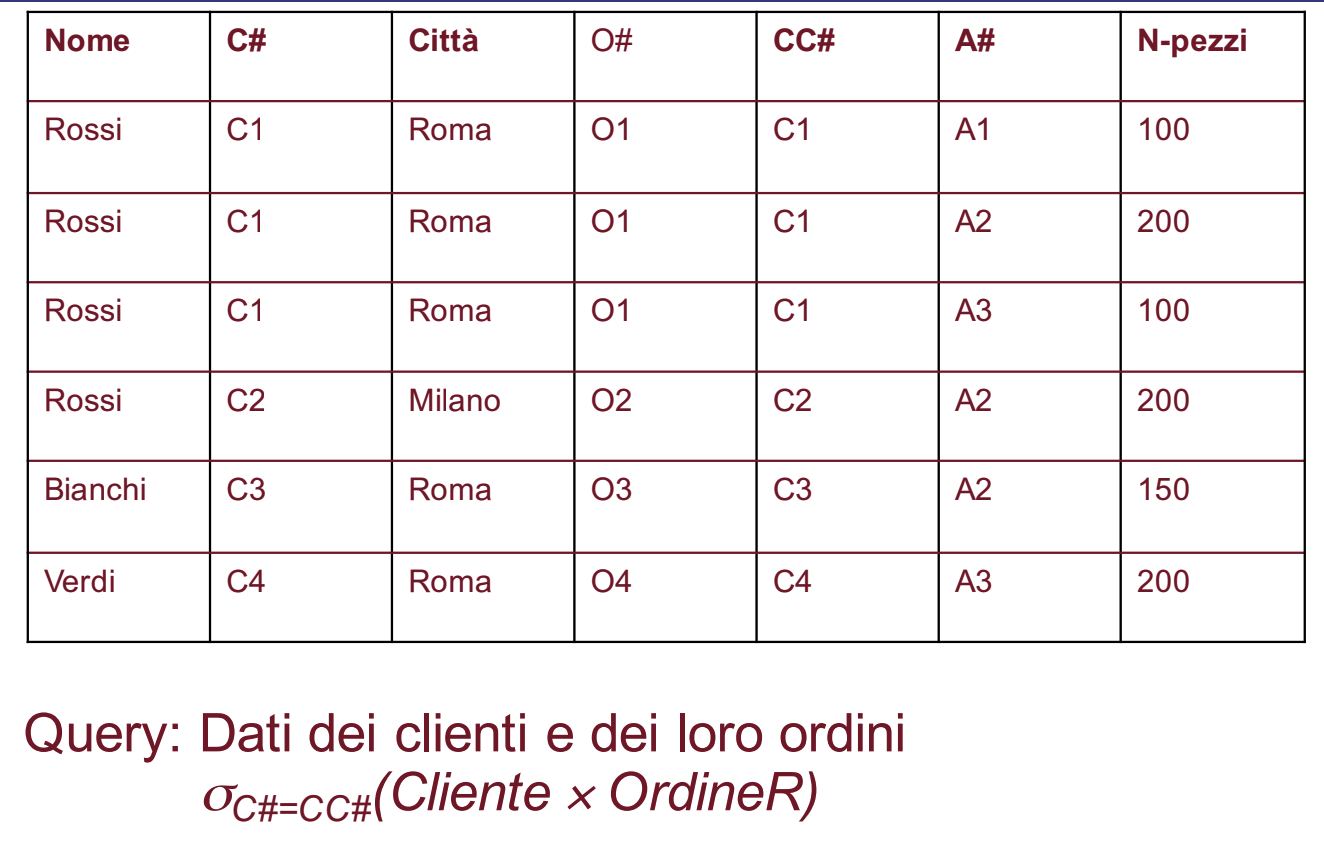
Notiamo anche che adesso le colonne C# e C## sono uguali, quindi se vogliamo fare una soluzione più elegante possiamo anche effettuare una proiezione sugli altri attributi e lasciare solo la colonna C#.
Join Naturale
Consente di selezionare le tuple del prodotto cartesiano dei due operandi che soddisfano la condizione:
Dove ed sono i nomi delle relazioni operando e sono gli attrinuti comuni, cioè con lo stesso nome, delle relazioni operando, eliminando le ripetizioni degli attributi.
Si scrive con

NOTA:
- Nel join naturale gli attributi della condizione che consente di unire solo le ennuple giuste hanno lo stesso nome.
- Vengono unite le ennuple in cui questi attributi hanno lo stesso valore
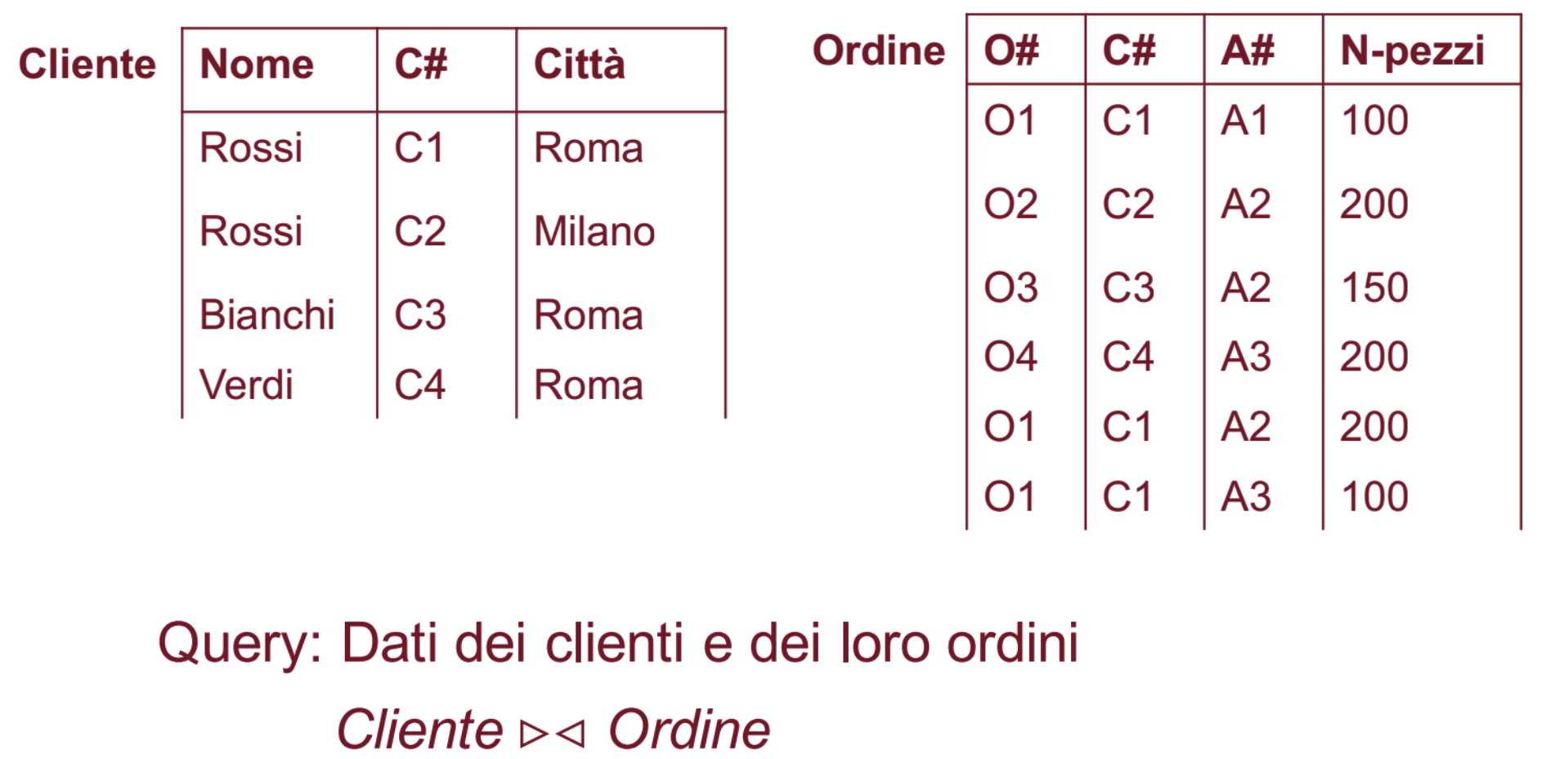
Quindi il Join naturale fa tutte le operazioni che abbiamo visto prima con il prodotto cartesiano.
Risultato Join:
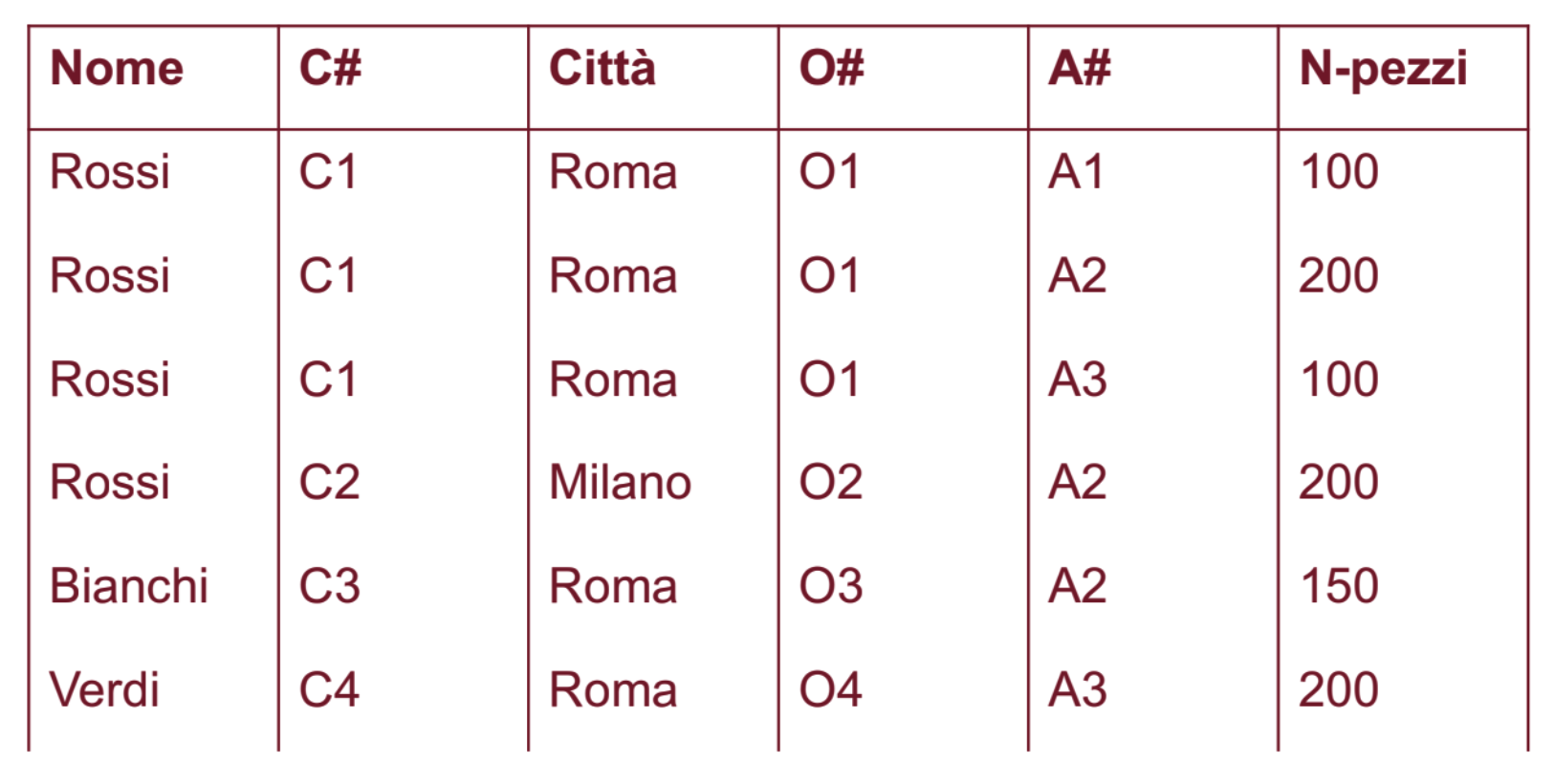
Spesso quando facciamo un join non vogliamo farlo su tutti gli attributi in comune ma solo su alcuni specificati, si vede successivamente con altri tipi di join.
Anche nel caso in cui gli attributi non hanno lo stesso nome, o come prima facciamo una ridenominazione oppure usiamo altri join, altrimenti in alcuni casi il join potrebbe restituire un prodotto cartesiano.
Casi Limite Join Naturale
- Attributi con lo stesso nome ma nessuna tupla della prima relazione ha valori uguali con la seconda relazione in corrispondenza degli attributi uguali, risultato vuoto.
- Se non abbiamo attributi con lo stesso nome, il risultato diventa un prodotto cartesiano.
Un possibile errore quindi può essere che gli attributi hanno lo stesso nome ma non lo stesso significato.

Quindi C# in Artista è il codice artista mentre in Quadro indica il codice quadro, il join per avere senso quindi deve essere effettuato tra Artista.C# e Quadro.Artista, non possiamo utilizzare un join naturale.
Possiamo o fare una ridenominazione o usare un join.
Join
Consente di selezionare le tuple del prodotto cartesiano di due operandi che soddisfano una condizione: .
Ci permette di effettuare un join sugli attributi che vogliamo noi.
Dove:
- è un operatore di confronto
- A è un attributo della prima relazione
- B è un attributo della seconda relazione
Ad es.
Condizione Negative
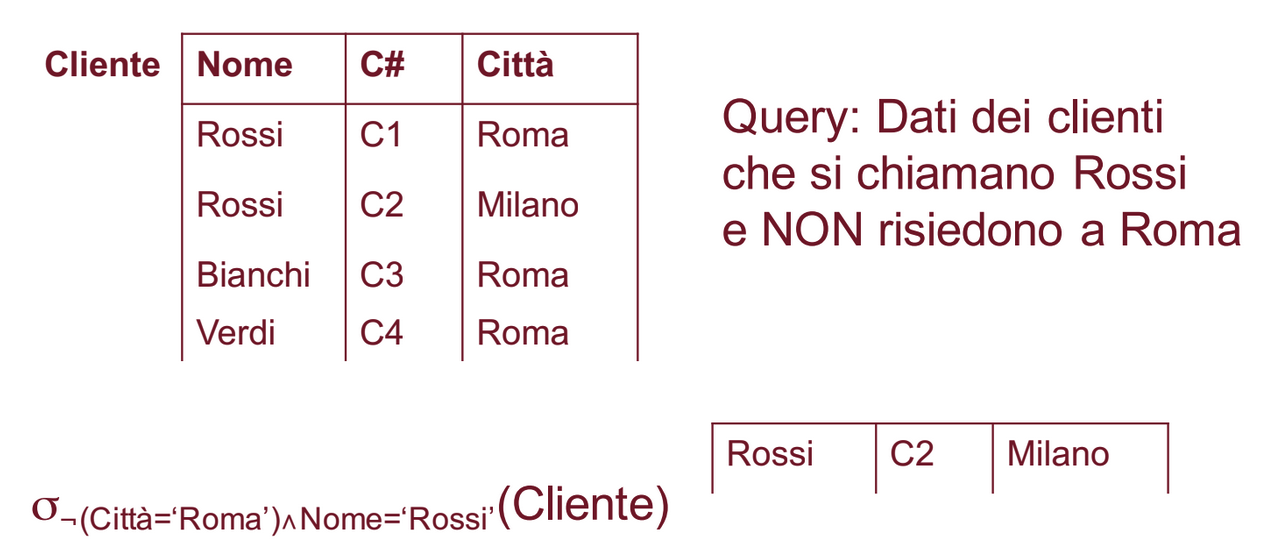
Quindi quando le informazioni che vogliamo non sono nella stessa relazione:
- Troviamo tutte le relazioni che contengono le informazioni
- Selezioniamo soltanto dei sottoinsiemi rilevanti per le interrogazioni
- Combiniamo le informazioni attraverso i valori che in delle tuple fanno riferimento ad altre tuple
Quantificatore Universale
Fino ad ora abbiamo visto query che implicano condizioni equivalenti al quantificatore esistenziale ovvero “esiste almeno un”.
Era possibile rispondere a queste query dato che la valutazione delle tuple avviene in modo sequenziale quando si incontra una tupla che soddisfa la condizione si aggiunge al risultato.
La condizione però potrebbe richiedere la valutazione di gruppi interi di tuple prima di decidere se inserirerle o meno nel risultato, e le tuple una volta inserite non possono essere rimosse, in questo caso la query corrisponde al quantificatore universale oppure .
Esempio


Notiamo che ad esempio la seconda tupla soddisfa la condizione di aver comprato più di 100 pezzi ma non possiamo inserirla, in qualche modo dovremmo memorizzare che “Rossi” compariva in una tupla precedente e non soddisfaceva la condizione.
Anche scambiando l’ordine delle tuple non risolviamo il problema, infatti lo inseriremo ma successivamente dovremmo toglierlo dal risultato.
Negazione del quantificatore universale
La negazione di “per ogni” non è “per nessuno” ma “esiste almeno un elemento per cui la condizione è falsa”.
Grazie a questo possiamo risolvere il problema con una doppia negazione:
- Eseguiamo la query con la condizione negata
- In questo modo abbiamo trovato gli oggetti che almeno una volta soddisfano la condizione contraria e quindi non soddisfano sempre quella che ci interessa.
- Eliminiamo questi oggetti ottenuti dal totale tramite la differenza
Quindi in questo caso eseguiamo:
In questo modo ci sono rimasti soltanto chi non ha mai ordinato meno di 100.
Nota
Se sappiamo di inserire un cliente nel struttura dati soltanto quando effettua un ordine allora nel primo operando della differenza potremmo scrivere semplicemente ovvero i clienti totali.
Ma se questo non è vero allora nel risultato finale avremo anche clienti che non hanno mai effettuato ordine, per questo abbiamo effettuato un join cliente, in modo da avere soltanto chi avesse almeno un ordine.
Inoltre è importante anche valutare le proiezioni, nell’esempio precedente ci interessavano i nomi ma abbiamo proiettato anche su Città, questo perché altrimenti nella sottrazione sarebbe sparito anche il Rossi di Milano.
Esempio

Seguendo lo stesso ragionamento di prima, prendiamo prima chi non ci interessa:
E poi eseguiamo una differenza:
La query in questo caso restituisce un risultato vuoto.
Condizioni che richiedono il prodotto di una relazione con se stessa
Ci sono anche casi in cui sono associati oggetti della stessa relazione.
Esempio
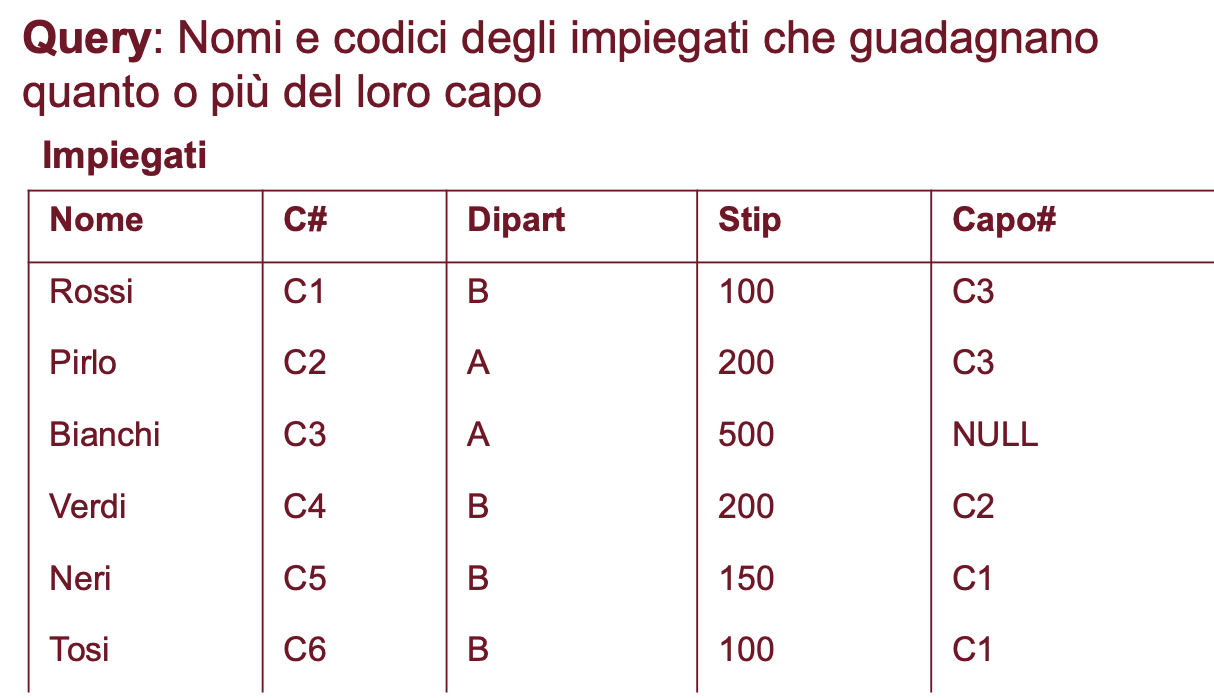
Le informazioni che ci servono sono tutte nella stessa relazione ma si trovano su tuple diverse e per poter confrontare valori, questi devono trovarsi sulla stessa tupla, come procediamo?
Creiamo una copia della relazione ed effettuiamo un prodotto in modo da combinare le informazioni di un impiegato con quelle del suo capo, quindi creiamo una relazione ImpiegatiC che con un join sarà collegata ad Impiegati combinando le tuple che hanno il valore C# uguale a Capo#. Utilizziamo anche la ridenominazione per aiutarci.
Poi eseguiamo:
Ridenominazione
Se non avessimo usato la ridenominazione il join naturale ci avrebbe fatto combinare anche ogni impiegato con se stesso, inoltre C3 non ha capo quindi non entra nel join dal lato impiegato.
A questo punto ci basta confrontare gli stipendi e infine proiettare:
Esempio
Abbiamo come query: “Nomi e codici dei capi che guadagnano più di tutti i loro impiegati”.
Possiamo prendere la query dell’esempio precedente che trova gli impiegati che guadagnano quanto o più del loro capo, i capi che compaiono anche una sola volta in questo risultato non ci interessano.
Note

Progettazione basi di dati - Problemi e Vincoli
Vogliamo creare una base di dati per studenti universitari che contiene:
Dati Anagrafici e identificativa:
- Nome e cognome
- Data, comune e provincia di nascita
- matricola
- codice Fiscale
Dati curriculari, per ogni esame:
- Voto
- data
- codice, titolo e docente del corso
Ipotesi 1
Creiamo una sola relazione con schema:
Che problemi si presentano?

Ridondanza:
I dati di uno studente vengono memorizzati ogni volta che questo sostiene un esame mentre i dati di un corso sono memorizzati per ogni esame sostenuto in quel corso, questo porta a spreco di memoria ed errori durante aggiornamento, inserimento e cancellazione.
Anomalia di Aggiornamento:
Se cambia il docente di un corso, dobbiamo cambiarlo per ogni esame sostenuto in quel corso, stessa cosa per ogni altro dato.
Anomalia di Inserimento:
Non posso inserire i dati di uno studente finché non ha sostenuto almeno uno esame, a meno che non inserisco molti valori NULL. Non posso comunque farlo dato che questi attributi fanno parte della chiave.
Anomalia di Cancellazione:
Se elimino i dati di uno studente sto cancellando anche i dati di un corso, se ad esempio lo studente è l’unico ad aver sostenuto l’esame di quel corso.
Tutti questi problemi accadono perché ho messo insieme 3 informazioni di oggetti diversi, corsi, esami e studenti.
Ipotesi 2
Possiamo passare quindi a tre schemi di relazione:
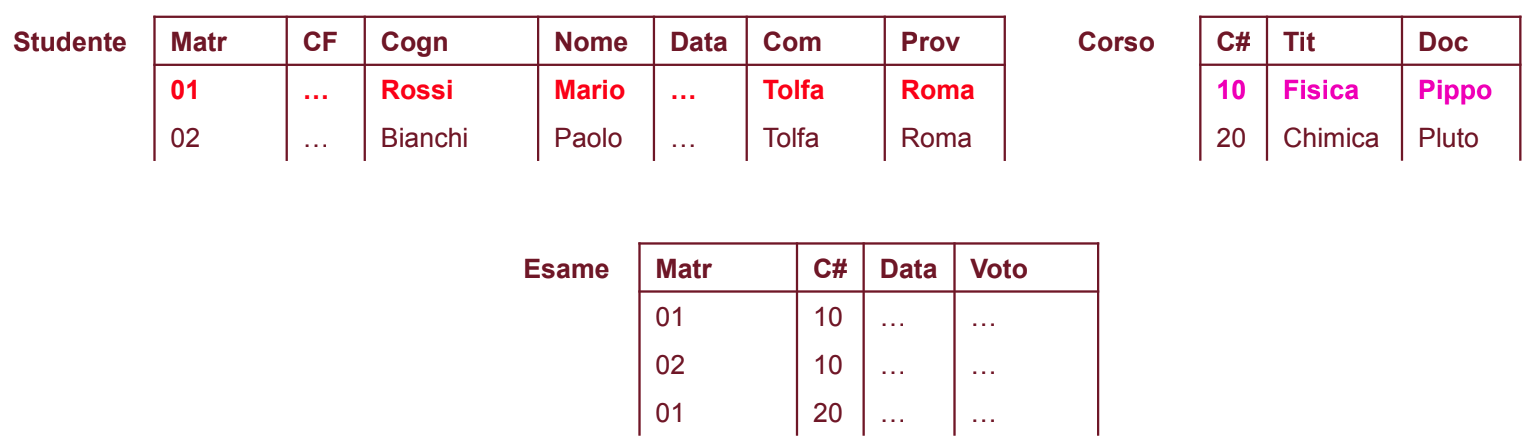
Non abbiamo i problemi di prima però se ne presenta un atro con Comune e Provincia dato che il Comune determina la Provincia
Ridondanza:
Il fatto che un comune si trova in una provincia è ripetuto molte volte
Anomalia di aggiornamento:
Se un comune cambia provincia devono essere modificate più tuple
Anomalia di Inserimento:
Non è possibile memorizzare il fatto che un comune si trova in una provincia se non abbiamo almeno uno studente di quel comune
Anomalia di Cancellazione:
Cancellando studenti potremmo perdere informazioni relative ai comuni
La base di dati adesso è formata da:
In questo modo non abbiamo più ridondanze e anomalie
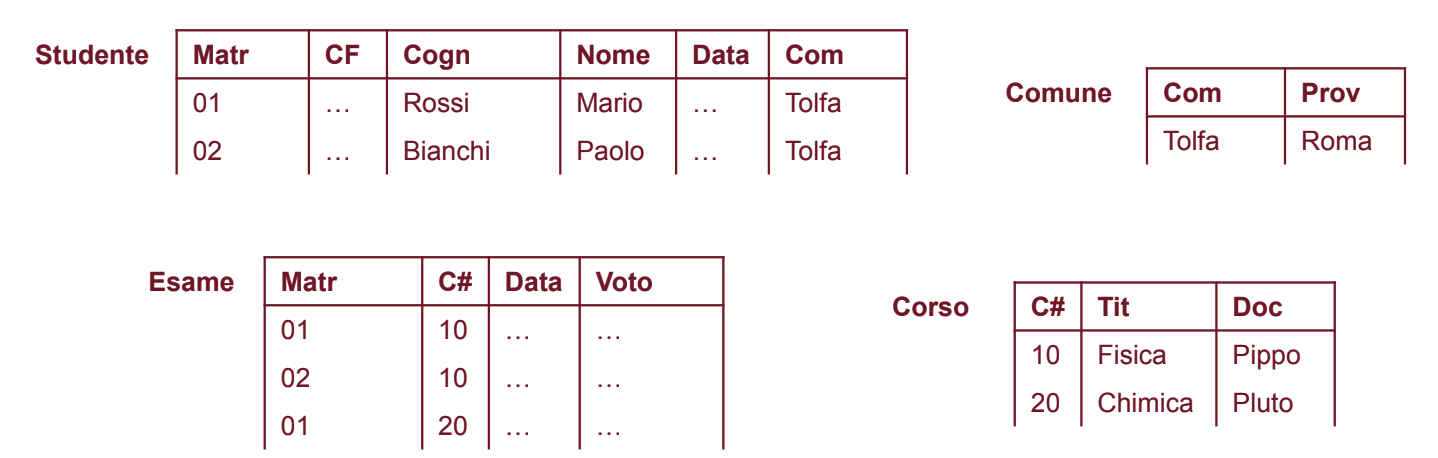
Schema "buono"
Uno schema è buono se non presenta ridondanza e anomalie di aggiornamento, inserimento e cancellazione, come si progetta? Occorre rappresentare ogni concetto in una relazione distinta
Rappresentazione dei concetti
Tutti i problemi di prima derivano dal fatto che abbiamo rappresentanto in un’unica relazione tre concetti diversi, 4 considerando anche i comuni e le province.
Vincoli
I vincoli sono delle condizioni sulla realtà che stiamo progettando, ad esempio:
- Un voto va da 18 a 30
- La matricola deve essere univoca
- ecc..
Quando rappresentiamo una realtà deve essere possibili rappresentare anche tutti i suoi vincoli, un’istanza è legale se soddisfa tutti i vincoli imposti. Più avanti vedremo che per questa definizione ci interessano soltanto le dipendenze funzionali e non ad esempio i vincoli di dominio.
Un DBMS permette di:
- Definire insieme allo schema della base anche i suoi vincoli
- Verificare che un’istanza sia legale
- Impedire l’inserimento di tuple che violerebbero tali vincoli
Le dipendenze funzionali di uno schema esprimono dei vincoli di dipendenza tra sottoinsiemi di attributi dello schema stesso, questi devono essere soddisfatti da ogni istanza dello schema. Se io ad esempio ho Matricola e CF nel caso di matricola uguale dovrà essere uguale anche CF.
Dipendenze Funzionali
Schema di relazione
Uno schema di relazione è un insieme di attributi
Notazione:
- Le prime lettere dell’alfabeto denotano singoli attributi
- Le ultime lettere denotano insiemi di attributi
- Se ed sono insiemi di attributi denota
Tupla
Dato uno schema di relazione una tupla su è una funzione che associa ad ogni attributo in un valore nel corrispondente .
Se è un sottoinsieme di e sono due tuple su , coincidono su se .
Istanza di Relazione
Dato uno schema di relazione una istanza di è un insieme di tuple su
Dipendenze Funzionali
Dato uno schema di relazione , una dipendenza funzionale su è una coppia ordinata di sottoinsiemi non vuoti di .
Notazione:
- determina funzionalmente oppure dipende funzionalmente da
- = Determinante
- = Dipendente
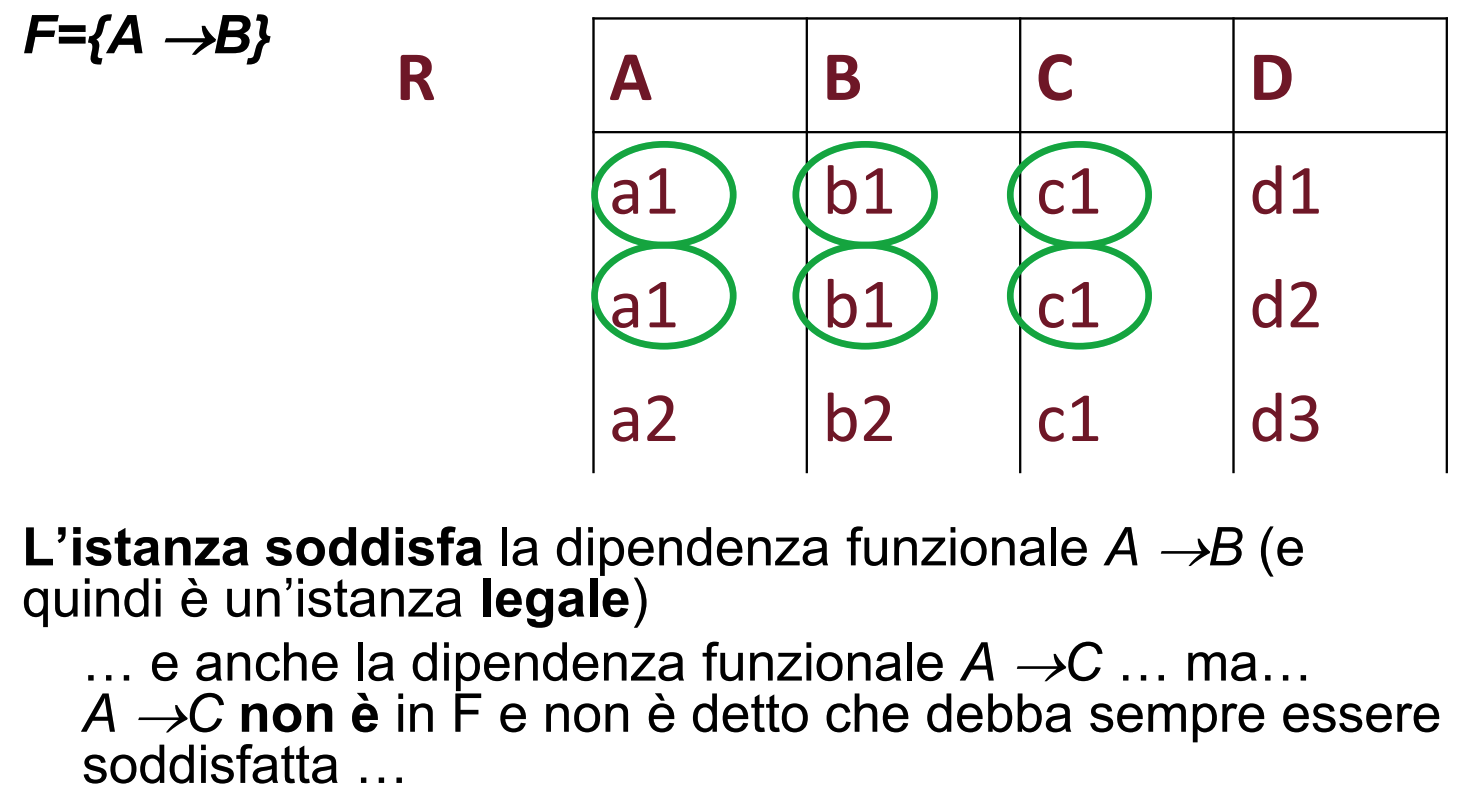
Dati uno schema e una dipendenza funzionale su , un’istanza di soddisfa la dipendenza funzionale se:
Se allora la dipendenza è comunque soddisfatta qualsiasi siano i valori di .
Quindi notiamo che il minimo numero per violare una dipendenza è 2, infatti istanze da 1 o 0 elementi è impossibile che violino una qualsiasi dipendenza.
Istanza Legale
Dati uno schema di relazione e un insieme di dipendenze funzionali, un’istanza di è legale se soddisfa tutte le dipendenze in .
Osservazione
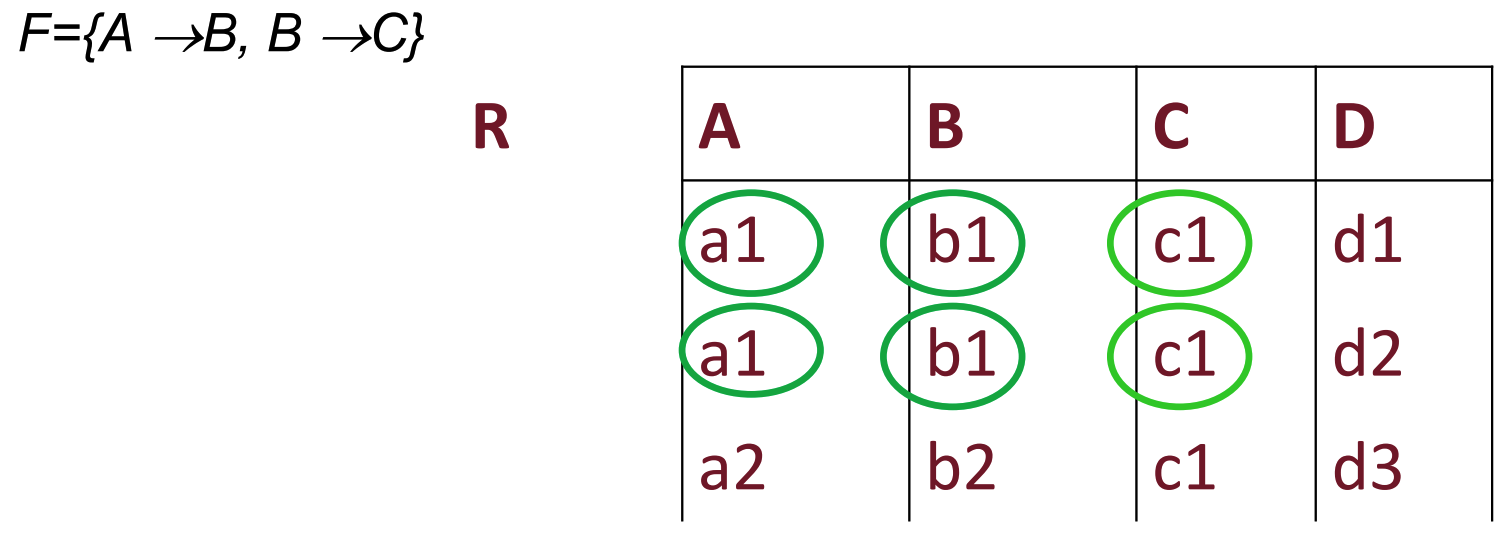
Notiamo che ogni istanza legale che quindi soddisfa soddisfa sempre anche la dipendenza , possiamo quindi considerarla come se fosse in ?
Dato uno schema di relazione e un insieme di dipendenza funzionali su ci sono delle dipendenze funzionali che non sono in ma che sono comunque soddisfatte da tutte le istanze legali di .
Chiusura di un insieme di Dipendenze Funzionali
Dato uno schema di relazione e un insieme di dipendenze funzionali su la chiusura di è l’insieme delle dipendenze funzionali che sono soddisfatte da ogni istanza legale di .
Lo scriviamo .
Otteniamo quindi che .
Chiave
Dati uno schema di relazione e un insieme di dipendenze funzionali , un sottoinsieme di uno schema di relazione è una chiave se:
- Non esiste un sottoinsieme proprio di tale che
Se rispettiamo soltanto la prima condizione allora è detta superchiave. Se soddisfa la seconda e quindi non ha altri sottoinsiemi che soddisfano la prima condizione allora è detta chiave. Possiamo anche diri quindi che una chiave è sempre superchiave dato che contiene se stessa ma una superchiave non è detto che sia sempre chiave, ma ne contiene sempre una.
significa che se due tuple sono uguali su allora le tuple devono essere uguali e dato che non possiamo avere due tuple uguali significa che non possiamo avere due chiavi uguali.
Esempio
Consideriamo lo schema . Il numero di matricola viene assegnato allo studente per identificarlo e quindi non ci possono essere 2 studenti con la stessa matricola e un’istanza di Studente non può contenere due tuple con lo stesso numero di matricola.
Otteniamo quindi che deve essere soddisfatta da ogni istanza legale. Matr è chiave per lo schema Studente.
Chiave Primaria
Dati uno schema e un insieme di dipendenze funzionali, possono esistere più chiavi, in SQL una di esse verrà scelta come chiave primaria (non può avere valore nullo).
Di solito si sceglie quella con meno attributi (non minimale, minimale significa che non ha altri sottoinsiemi chiave, superchiave) questo perché migliora la velocità di ricerca nella base di dati. Quindi una volta scelta chiave primaria le altre chiavi devo impostarle come attributi unique per rispettare il fatto che non si deve ripetere.
Dipendenze Funzionali Banali
Dati uno schema di relazione e due sottoinsiemi non vuoti di tali che si ha che ogni istanza di soddisfa la dipendenza funzionali .
Queste dipendenze sono soddisfatte da ogni tupla anche da quelle non legali.
Quindi ad esempio se io ho due tuple uguali su allora saranno uguali anche su e quindi è soddisfatta.
Quindi se , , questa è detta dipendenza banale.
Proprietà delle dipendenze funzionali
Dati uno schema di relazione e un insieme di dipendenze funzionali si ha:
Quindi se allora anche e .
Per la terza forma normale l’insieme è molto importante, è l’insieme di tutte le dipendenze soddisfatte da tutte le istanze legali. Ma come si calcola questo insieme ?
Dato che calcolare è molto “pesante” ci limiteremo a capire se una dipendenza ne fa parte o meno.
Assiomi di Armstrong
Introduciamo , con gli Assiomi di Armstrong
Denotiamo come l’insieme di dipendenze funzionali definito:
- Se allora
- Se allora Assioma della Riflessività
- Se allora , per ogni , Assioma dell’aumento
- Se e allora , Assioma della transitività
Dimostreremo che , ma prima alcune osservazioni su questi assiomi:
Riflessività: Se allora
Ad esempio e quindi se due tuple hanno uguale la coppia (Nome, Cognome) allora avranno uguale l’attributo Nome e stesso ragionamento per Cognome. Questo significa che è sempre soddisfatta.
Aumento: Se allora , per ogni
Ad esempio è soddisfatta quando tutte le tuple che hanno lo stesso CodiceFiscale hanno anche lo stesso Cognome.
Se aggiungiamo un altro attributo Indirizzo avremo che se due tuple sono uguali su (CodFiscale, Indirizzo) lo saranno anche su (Cognome, Indirizzo), quindi se viene soddisfatta viene soddisfatta anche .
Transitività: Se e allora
Ad esempio è soddisfatta quando tutte le tuple con la stessa Matricola hanno anche lo stesso CodFiscale.
è soddisfatta quando tutte le tuple con stesso CodFiscale hanno anche lo stesso Cognome.
Se entrambe le dipendenze sono soddisfatte quindi possiamo dire che ogni volta che le tuple hanno la stessa Matricola avranno hanno lo stesso Cognome, è soddisfatta quindi anche la dipendenza .
Vediamo altre regole che ci permettono di derivare altre dipendenze in :
- Se e allora , Regola dell’unione
- Se e allora , Regola della decomposizione
- Se e allora , Regola della pseudotransitività
Teorema: Sia un insieme di dipendenze funzionali dove valgono le implicazioni viste sopra.
Dimostrazione 1)
Se per l’assioma dell’aumento si ha (aggiungiamo X da entrambe le parti quindi XX=X). Analogamente diventa e quindi per transitività si ha che .
Dimostrazione 2)
Se allora per riflessività si ha . Quindi poiché e per transitività
Dimostrazione 3)
Se per aumento si ha , quindi dato che e allora per transitività abbiamo .
Osservazione
Da riscrivere

Chiusura di un insieme di attributi
Siano uno schema di relazione, un insieme di dipendenze funzionali su e un sottoinsieme di .
La chiusura di rispetto ad denotata con o anche è definito da:
Fanno parte della chiusura, gli attributi che vengono determinati direttamente da (da dipendenze che sono in ), oppure indirettamente (da dipendenze che sono in ). Quindi otteniamo che:
Quindi in ogni istanza legale se due tuple sono uguali su allora sono uguali su tutti gli attributi della chiusura di , ovviamente se .
Chiusure
La chiusura di non è mai vuota dato che abbiamo sempre almeno le dipendenze banali stessa cosa per la chiusura di , infatti determina sicuramente se stesso.
Lemma:
Siano uno schema di relazione ed un insieme di dipendenze funzionali su si ha che: se e solo se
Dimostrazione
Sia
PARTE SE:
Poiché per ogni si ha che , pertanto per la regola dell’unione
PARTE SE E SOLO SE
Poiché per la regola della decomposizione si ha che per ogni cioè per ogni e quindi .
Teorema
Siano uno schema di relazione ed un insieme di dipendenze funzionali su si ha .
Dimostrazione, dobbiamo dimostrare che . La parte a sinistra ci indica che tutte le dipendenze calcolate con Armstrong sono soddisfatte dalle istanze, mentre a sinistra che tutte le dipendenza soddisfatte dalle istanze sono calcolabili con Armstrong.
Iniziamo dimostrando , Sia una dipendenza funzionale in , dimostriamo che per induzione sul numero di applicazioni degli assiomi di Armstrong.
Base dell’induzione: , in questo caso è in e quindi , questo perché appunto non abbiamo applicato nessun assioma e . Inoltre questo significa che significa che è rispettata da ogni istanza legale.
Ipotesi Induttiva: , Prendiamo applicazioni e per ipotesi induttiva abbiamo
Passo Induttivo: Ci troviamo a e per ipotesi ogni dipendenza ottenuta da applicando gli assiomi fino a si trova in dobbiamo dimostrarlo anche per e si possono presentare 3 casi, ovvero l’applicazioni di ognuno dei 3 assiomi:
-
Riflessività
All’i-esimo passo decidiamo di applicare la riflessività, quindi se è stata ottenuta per riflessività allora implica che .
-
Aumento
Se è stata ottenuta per aumento, quindi in passi avevamo al quale possiamo applicare l’aumento con ottenendo e possiamo chiamare e .
Essendo quindi soddisfatta da ogni istanza legale abbiamo che la nuova dipendenza è in .
-
Transitività
è stata ottenuta per transitività quindi a . E per ipotesi induttiva si trovano in quindi:
Quindi qualunque sia il numero di applicazioni di Armstrong, ogni dipendenza di si troverà anche in .
Adesso dobbiamo dimostrare che se una dipendenza si trova in allora si trova in . ovvero:
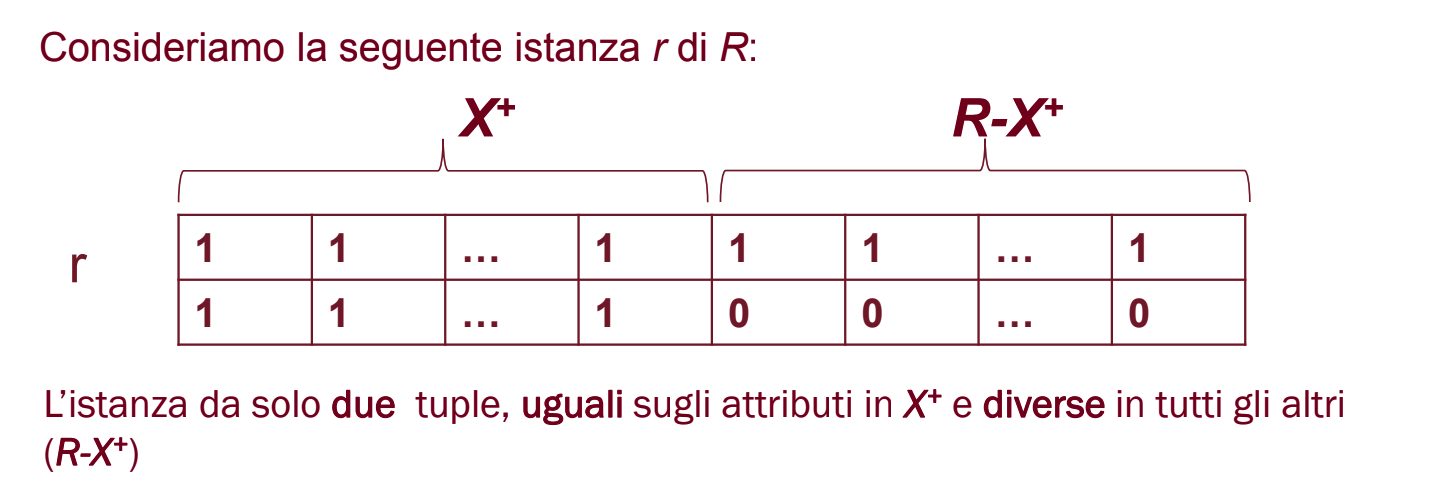
Prendiamo una qualunque dipendenza e mostriamo per prima cosa che è un’istanza legale perché la soddisfa:
Se ovvero se allora è soddisfatta.
Se (sappiamo che sono uguali sicuramente solo in ). Per il lemma 1 sappiamo che e per transitività insieme a . Quindi le due tuple sono uguali sia sui valori di che su quelli di . L’istanza è legale.
Adesso mostriamo che se allora .
Dato che è un’istanza legale significa che , quindi se , noi sappiamo che le tuple sono uguali per gli attributi di e per riflessività , quindi le tuple sono sicuramente uguali sui valori di e quindi l’implicazione ci dice che lo sono anche sui valori di .
Se sono uguali sui valori di significa che anche e per il lemma che .
Adesso abbiamo un modo per conoscere tutte le dipendenze in , queste sono le stesse che si possono inserire in partendo da e applicando gli assiomi di Armstrong e le regole derivate, notiamo però che abbiamo una complessità esponenziale e quindi calcolare questi insiemi richiede molto tempo.
Vedremo la terza forma normale che si basa come già detto sul fatto di decomporre il nostro schema e non rappresentare più concetti in un’unica tabella, ovviamente tutte le dipendenza soddisfatte nei vecchi schemi devono essere soddisfatte anche nei nuovi, in poche parole devono essere preservate tutte le dipendenze in .
Prendiamo lo schema visto un po’ sopra degli studenti, la base consiste in quattro schemi:
Dato che una matricola identifica univocamente uno studente, significa che ogni istanza per essere legale deve rispettare:
E allo stesso modo anche un identifica univocamente uno studente pertanto sia Matr che CF sono chiavi di Studente.
Possiamo anche osservare che ci possono essere studenti che con lo stesso cognome hanno nome diverso, quindi alcune istanze di studente non soddisfano . Possiamo dire che le uniche dipendenze funzionali non banali che devono essere soddisfatte da un’istanza legale sono del tipo:
Dove contiene una chiave, in questo caso Matr o CF.
Guardando gli altri schemi notiamo che un esame viene registrato una sola volta e quindi ogni istanza di esame per essere legale deve rispettare:
Notiamo però che uno studente può sostenere esami in date differenti e avere anche voti diversi in vari esami. Quindi abbiamo delle dipendenze che non vengono soddisfatte sempre:
Possiamo osservare anche che l’esame relativo ad un corso viene superato da diversi studenti in diverse date e con voti diversi, per cui alcune istanze non soddisfano:
La chiave dello schema Esame è quindi Matr C#.
Completiamo la definizione di terza forma normale, per ora sappiamo solo che tutte le dipendenze non banali che devono essere soddisfatte devono essere del tipo dove contiene una chiave oppure è contenuto in una chiave.
Terza Forma Normale
Dati uno schema di relazione R e un insieme di dipendenze funzionali su , è in 3NF se:
(Con escludiamo le dipendenze banali)
- appartiene ad una chiave (si dice che è primo) Oppure
- contiene una chiave (è una superchiave)
È sbagliato scrivere perché poi non sapremmo come valutare dipendenze del tipo ovvero con 2 o più attributi a destra, infatti in una dipendenza del tipo possiamo scomporla in e .
E se cambio la condizione in non so come comportarmi, infatti in potremmo avere sia attributi primi che non, dovremmo cambiare la condizione in modo tale che tutti gli elementi di siano primi.
Esempio
,
Abbiamo come chiavi
ha come determinante un attributo che non è superchiave però se scomponiamo otteniamo e e notiamo che appartengono a delle chiave, sono quindi primi, rispettiamo la 3NF.
Esempio 2
La chiave è , infatti per ogni istanza legale:
- allora ma allora se implica che
- Quindi se allora e quindi
- Per la regola dell’unione e sappiamo che e quindi , inoltre è un singleton e quindi è una chiave.
- è l’unica chiave perché non determina e nè nè determinato attributi.
Vediamo se siamo in 3NF:
- va bene dato che è chiave.
- dobbiamo studiare le dipendenze con singleton, quindi passando ad possiamo studiare e , notiamo che non è superchiave e inoltre e non sono primi, non rispettiamo la 3NF.
Esempio 3
La chiave è per ogni istanza legale.
- Se allora
- Se allora
- Quindi
- e quindi sapendo che possiamo scrivere , è chiave dato che e da soli non determinano altri attributi.
- è un’altra chiave e quindi infatti applicando l’aumento a otteniamo .
- Anche è una chiave, o meglio una superchiave dato che contiene e che sono chiavi.
3NF?
- è ok dato che è superchiave.
- scomponiamola in e abbiamo che non è superchiave in entrambi i casi però appartiene ad una chiave e quindi ok ma non appartiene a chiavi e quindi violiamo la 3NF.
Questo caso è utile con la “scappatoia” vista prima di scrivere per la definizione, infatti in questo caso come valutiamo ? abbiamo primo ma no, dovremmo dare definizioni più complesse per valutare ogni attributo a destra. Dato che possiamo applicare la decomposizione, è più semplice fare così.
Violare 3NF
Per violare la 3NF è sufficiente trovare anche una sola dipendenza che viola la condizione.
Dipendenze Parziali e Transitive
Dipendenze Parziali
Prendiamo come esempio , dove le chiavi sono Matr e C# notiamo che ad un numero di matricola corrisponde un solo cognome otteniamo quindi che e questa dipendenza è una conseguenza di quella vista prima .
La dipendenza viene detta dipendenza parziale, vediamo la loro definizione formale:
Siano uno schema di relazione e un insieme di dipendenze funzionali su .
è una dipendenza parziale su se non è primo ed è contenuto propriamente in una chiave di .
Per capirlo meglio abbiamo che l’attributo Cognome dipende parzialmente dalla chiave Matr C# ovvero non mi serve la chiave intera per determinarlo ma soltanto una parte della chiave, infatti Matr appartiene alla chiave.
Dipendenze Transitive
Prendiamo come esempio lo schema che ha come chiave Matr e CF. Notiamo che ad un numero di matricola corrisponde un solo comune di nascita e che un comune si trova in una sola provincia , in conclusione possiamo dire che ovvero che ad una matricola corrisponde una sola provincia.
Possiamo dire quindi che è una conseguenza delle altre due dipendenze e è detta dipendenza transitiva, vediamo le definizione formale:
Siano uno schema di relazione e un insieme di dipendenze funzionali su :
è una dipendenza transitiva su se non è primo e per ogni chiave di abbiamo che non è contenuto propriamente in e .
In questo caso abbiamo che l’attributo provincia non dipende direttamente da una chiave, ma dipende transitivamente infatti è una conseguenza di e , inoltre è importante ricordare che la dipendenza transitiva è quella che “causa” la transitività e quindi in questo caso .
Definizione Alternativa 3NF
Dato uno schema un insieme di dipendenze funzionali , è in 3NF se e solo se non ci sono attributi che dipendono parzialmente o transitivamente da una chiave, o meglio se non ci sono né dipendenze parziali né transitive
Definizioni a Confronto
Le due definizioni sono equivalenti, dimostriamolo.
Teorema: Siano uno schema di relazione e un insieme di dipendenze funzionali su . Uno schema è in 3NF se e solo se non esistono né dipendenze parziali né transitive in .
Dimostriamo partendo dal fatto che lo schema è in 3NF
- Siamo in 3NF quindi , appartiene ad una chiave oppure contiene una chiave.
Se è parte di una chiave allora già è impossibile che ci siano dipendenze parziali o transitive, infatti questa è la prima condizione che devono rispettare entrambe. Se non è primo allora sappiamo che è superchiave, in quanto tale può contenere una chiave ma non essere contenuto propriamente in una chiave quindi non possiamo avere dipendenze parziali. Inoltre sapendo che è superchiave non può verificarsi che per ogni chiave di non è contenuto propriamente in e infatti ne contiene almeno una completamente e quindi facendo la differenza otteniamo il vuoto.
Dimostriamo partendo dal fatto che non esistono dipendenze parziali e transitive
Quindi sappiamo che non esistono dipendenze parziali e transitive, supponiamo per assurdo che non sia 3NF allora in questo caso esiste una dipendenza funzionale tale che non è primo e non è una superchiave, dato che non è una superchiave abbiamo due casi:
- Per ogni chiave di abbiamo che non è contenuto propriamente in (infatti X non ha chiavi) e (non faremo mai la differenza con una chiave). In questo caso abbiamo che è transitiva, otteniamo una contraddizione.
- Esiste una chiave di tale che e quindi è contenuto in una chiave, significa quindi che è una dipendenza parziale, otteniamo una contraddizione.
Uno schema 3NF come abbiamo visto è quindi preferibile ad uno non, quando ne progettiamo uno è bene quindi mantenere questa struttura. Quando si progetta uno schema ovvero nella fase di individuazione dei concetti da rappresentare, se questa progettazione viene fatta bene lo schema derivato sarà 3NF, altrimenti dovremmo procedere ad una fase di decomposizione per portarcelo, come abbiamo visto con l’esempio dell’università.
Uno schema che non è in 3NF infatti può essere decomposto in più modi in un insieme di schemi che invece rispettano la 3NF.
Vediamo un esempio semplice con lo schema con l’insieme questo non è in 3NF per via della dipendenza transitiva dato che la chiave è . Possiamo però decomporre in:
- e con
- e Oppure
- e con
- e
Entrambi gli schemi sono in 3NF, tuttavia la seconda soluzione non va bene, perché?
Consideriamo due istanze legali degli schemi ottenuti:
Ricostruiamo lo schema originale tramite un join naturale:
Notiamo che non è un’istanza legale di infatti non rispettiamo la dipendenza , dobbiamo preservare tutte le dipendenze presenti in .
Vediamo un altro esempio.
Consideriamo lo schema con l’insieme di dipendenze funzionali , lo schema non è 3NF dato che entrambe le dipendenze sono parziali, la chiave infatti è AC e possiamo decomporre lo schema in:
- con
- con
Questo schema preserva tutte le dipendenze di ma non va comunque bene.
Prendiamo un’istanza legale di
Adesso decomponiamola in base ai due schemi visti prima:
In teria facendo un join dovremmo ricostruire l’istanza originale ma non è così:
Le ultime due tuple sono estranee all’istanza originale, c’è stata quindi perdita di informazione.
Ci sono altri esempi nelle slide ma i casi sono uguali a questi due.
Per concludere quindi quando si decompone uno schema per ottenere una 3NF dobbiamo ricordare che:
- Dobbiamo preservare le dipendenze funzionali che valgono sullo schema originario.
- Dobbiamo permettere di ricostruire tramite join lo schema originario, senza aggiunta di informazioni estranee.
Formale Normale di Boyce-Codd
La 3NF non è la più restrittiva che possiamo ottenere, ne esistono altre come la forma normale di Boyce-Codd.
Definizione
Una relazione è in formale normale di Boyce-Codd (BCNF) quando ogni determinante è una superchiave.
Una relazione che rispetta BCNF è anche in terza formale normale, ma non è vero l’opposto.
Inoltre non è sempre possibile decomporre uno schema non BCNF e ottenere sottoschemi BCNF preservando allo stesso tempo tutte le dipendenze ma è sempre possibile per 3NF che va comunque bene.
Ci sono esempi su slide ma non so se sono utili, dato che prenderemo in considerazione solo 3NF da adesso
Chiusura di un Insieme di Attributi
Abbiamo detto che quando si decompone uno schema su cui è definito un insieme di dipendenze funzionali per ottenere altri schemi in 3NF, vogliamo preservare tutte le dipendenze e poter ricostruire tramite join tutta l’informazione originaria.
Si vogliono preservare tutte le dipendenze in quindi tutte quelle soddisfatte da ogni istanza legale, siamo quindi interessati a calcolare ma sappiamo che richiede tempo esponenziale in .
A noi basterà avere un metodo per decidere se una dipendenza funzionale appartiene ad , e possiamo farlo calcolando e verificando che , infatti per il lemma: e poi il teorema dimostra che .
Il calcolo di può tornare utile a verificare che un insieme di attributi sia chiave di uno schema oppure verificare se una decomposizione preserva le dipendenze originarie. Vediamo come si calcola.
Calcolo di
Per il calcolo della chiusura di un insieme di attributi denotata con possiamo utilizzare un algoritmo.
Come input abbiamo bisogno di uno schema di relazione , un insieme di dipendenze funzionali su e un sottoinsieme di .
Come output riceviamo la chiusura di rispetto ad restituita nella variabile .
Quindi abbiamo che è stesso, poi in inseriamo i singoli attributi che compongono le parti a destra delle dipendenze funzionali la cui parte sinistra è in , quindi inizialmente in avremo gli attributi determinati da . Poi aggiungiamo questi elementi a e continuiamo a iterare sui nuovi insieme .
Ci fermiamo quando non ha elementi “nuovi” rispetto a .
Esempio di applicazione

Notiamo che per ogni passaggio dobbiamo sempre far partire la catena di operazioni da .
È quindi più semplice vedere cosa abbiamo in e “combinando” i pezzi vedere cosa possiamo ottenere.
Adesso dobbiamo dimostrare che l’algoritmo è corretto, ovvero che calcola correttamente la chiusura di un insieme di attributi rispetto ad un insieme di dipendenze funzionali
Dimostrazione
Con indichiamo il valore iniziale di e con e i valori di ed dopo la i-esima iterazione Ad ogni iterazione aggiungiamo elementi in , alla fine otteniamo , dobbiamo provare che, siccome ad ogni iterazione non cancelliamo mai elementi ma al massimo ne aggiungiamo di nuovi, è facile notare che per ogni .
Quindi sia tale che , con indichiamo l’iterazione finale, proveremo che:
- Iniziamo mostrando che , per induzione.
Base Induzione: , sappiamo che questo è uguale ad ma e quindi .
Ipotesi Induttiva:
Passo Induttivo: Prendiamo un attributo ovvero un attributo che abbiamo appena aggiunto. Se abbiamo aggiunto , significa che:
Notiamo che quindi possiamo scrivere che e sempre per il lemma 1 .
Adesso siccome abbiamo e , per transitività abbiamo che e per il lemma .
- Adesso mostriamo che
Dato che abbiamo un per il lemma sappiamo che quindi significa che questa dipendenza deve essere soddisfatta da ogni istanza legale.
Prendiamo come esempio la seguente istanza di :
Mostriamo che è un’istanza legale.
Prendiamo una qualsiasi dipendenza e supponiamo per assurdo che non sia soddisfatta, questo significa che:
Ovvero che:
Ma questo significa che questo elemento che si trova ancora in potrei raccoglierlo con l’algoritmo e portarlo dentro a in una nuova iterazione, ma questo significa che non abbiamo preso il “vero” ovvero l’ultima iterazione e andiamo in contraddizione con la costruzione della nostra istanza.
Quindi la dipendenza è soddisfatta anche quando le tuple hanno valori uguali su , l’istanza è legale.
Dato che è legale soddisfa la nostra dipendenza , e dato che significa che le due tuple sono uguali su e quindi, siccome è legale, lo sono anche su ma questo significa che (per come abbiamo costruito l’istanza).
Insieme Vuoto
Ricordiamo che è diverso da , infatti il primo è un insieme che contiene l’insieme vuoto mentre il secondo è l’insieme vuoto stesso. Proprietà:
- L’insieme vuoto è un sottoinsieme di ogni insieme
- L’unione di un qualunque insieme con l’insieme vuoto è
- L’intersezione di un qualunque insieme con l’insieme vuoto è l’insieme vuoto
- L’unico sottoinsieme dell’insieme vuoto, è l’insieme vuoto stesso
- L’insieme vuoto è finito ed ha 0 elementi
Identificare le chiavi di uno Schema
Per determinarle possiamo utilizzare il calcolo della chiusura di un insieme di attributi.
Esempio
Prendiamo lo schema e lo schema di relazioni:
Calcoliamo la chiusura di , abbiamo che:
Ma è chiave? Ricordando la definizione abbiamo che un sottoinsieme di e un insieme di dipendenze funzionali è chiave se:
- Non esiste un sottoinsieme proprio di che soddisfa la prima condizione
Quindi dobbiamo verificare che non ci siano sottoinsiemi di che siano chiave. Quindi utilizziamo ancora l’algoritmo delle chiusure sui sottoinsiemi di , facendo però alcune osservazioni:
- Conviene partire da quelli con cardinalità maggiore, infatti se la loro chiusura non contiene è inutile proseguire con loro sottoinsiemi.
- Gli attributi che non compaiono mai come dipendenti (a destra) faranno sicuramente parte della chiave, se invece compaiono sempre come dipendenti allora sicuramente non fanno parte della chiave.
Infatti prendendo l’esempio di prima, per vedere i sottoinsiemi di che sono chiavi possiamo dire per prima cosa che va sicuramente nella chiave dato che non viene mai determinato e quindi dobbiamo controllare i sottoinsiemi che sono quelli di cardinalità più grande.
Entrambi i sottoinsiemi non determinano altri attributi quindi possiamo fermarci qui, è inutile controllare sottoinsiemi di cardinalità inferiore, quindi è chiave.
In uno schema possiamo avere più chiavi
Abbiamo detto che deve essere sicuramente parte della chiave e abbiamo già verificato che non sono chiavi, proviamo a controllare .
Quindi non è chiave.
Non è chiave
Non è chiave.
Quindi dovremmo provare con altri sottoinsiemi di 3 elementi, incluso , notiamo che da soli non determinano nulla e inoltre non dipendono da altri attributi quindi vanno per forza nella chiave. Questo significa che è l’unica chiave.
Per decidere da dove cominciare per cercare una chiave possiamo partire dalla osservazioni di prima, oppure si può cominciare dagli insiemi individuati dalle dipendenze funzionali: data una dipendenza calcoliamo la chiusura dell’insieme di attributi . Se la chiusura di questo insieme contiene allora è superchiave però dobbiamo verificare che sia chiave e quindi controllare i suoi sottoinsiemi.
Esempio
Abbiamo e:
Quindi in base a quanto detto prima calcoliamo le superchiavi:
Adesso però dobbiamo verificare che siano chiavi:
- Notiamo che vanno sicuramente nella chiave
- da solo non determina nulla quindi va sicuramente insieme a o
Proviamo a vedere quindi e .
Quindi e non sono chiavi dato che contengono mentre non è chiave dato che contiene .
Per le osservazioni di prima è inutile controllare sottoinsiemi, non esistono. Dobbiamo avere sicuramente e non può stare da solo.
Test di unicità della chiave
Calcoliamo la chiusura dell’intersezione degli insiemi ottenuti con la formula di prima, nell’esempio precedente, se la loro chiusura determina tutto allora questa intersezione è l’unica chiave:
Quindi avremmo potuto capire che esiste più di una chiave, infatti ce ne sono 2.
Una volta determinate le chiavi possiamo passare alla verifica di per ognuna di queste, e quindi verificare che:
- è primo (fa parte di una chiave) Oppure
- contiene una chiave
Decomposizione di Uno Schema
Se non siamo in gli schemi vanno decomposti:
- I sottoschemi devono essere in 3NF
- Dobbiamo preservare le dipendenze in
- Il join dei sottoschemi devi farci ottenere istanze valide dello schema di partenza
Inoltre non sempre li decomponiamo per ottenere una 3NF ma anche per motivi di efficienza degli accessi.
- Definizione Decomposizione Schema
Iniziamo a dare delle definizioni: Sia uno schema di relazione. Una Decomposizione di è una famiglia di di sottoinsiemi di che ricopre (), i sottoinsiemi possono avere intersezioni non vuota.
Quindi decomporre uno schema significa definire dei sottoschemi che contengono ognuno un insieme degli attributi di , questi possono avere attributi in comune e la loro unione deve necessariamente contenere tutti gli attributi di .
” è un insieme di attributi e una decomposizione di è una famiglia di insiemi di attributi”.
Quindi possiamo avere anche più decomposizioni ma poi dobbiamo verificare se sono “buone” ovvero se i sottoschemi preservano la 3NF, le dipendenze funzionali e facendo un join non abbiamo perdite.
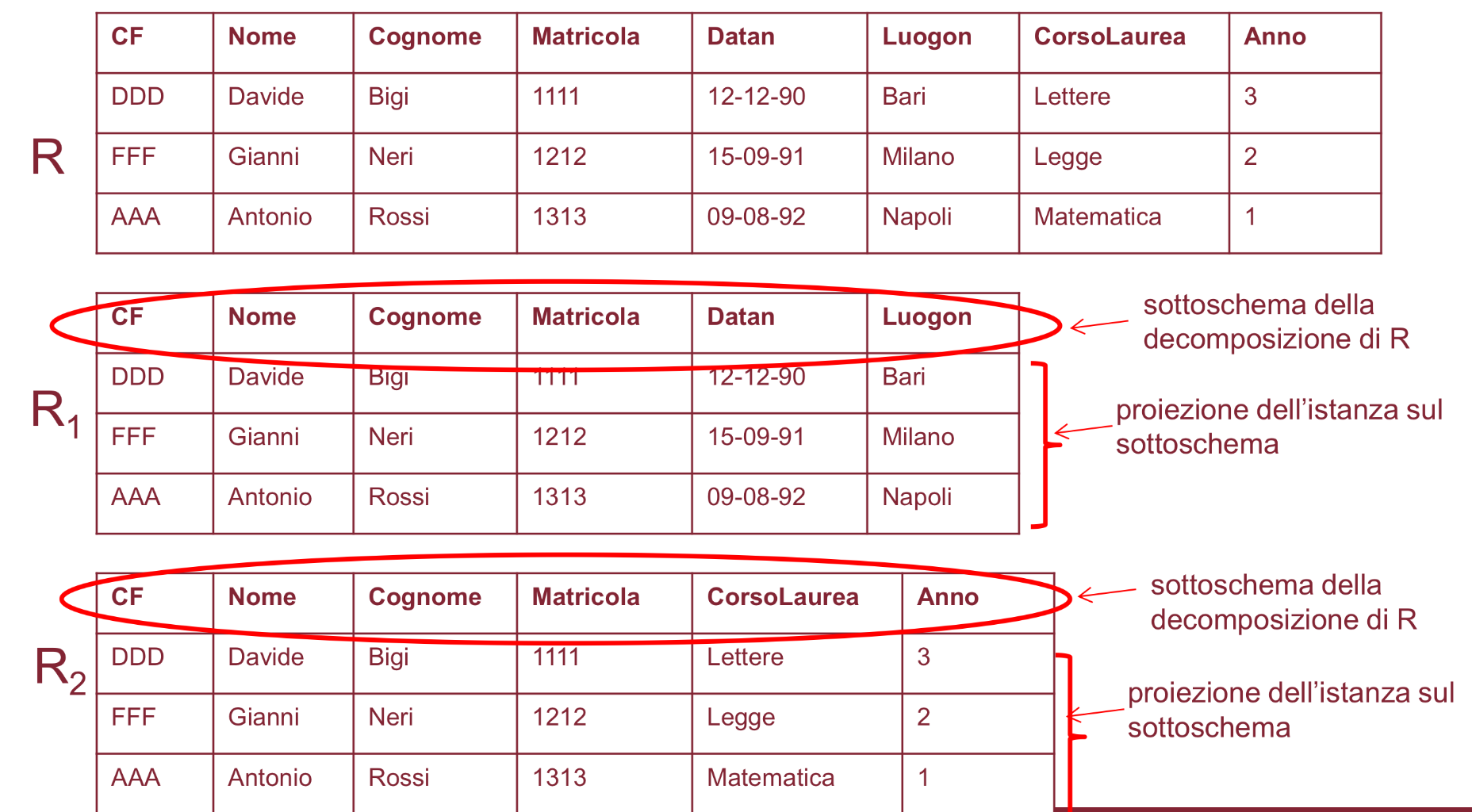
- Definizione Decomposizione Istanza
Decomporre un’istanza significa invece fare una proiezione dello schema originale con gli attributi del sottoschema, eliminando eventuali duplicati generati dal fatto che nello schema originale magari due tuple sono distinte ma considerando solo una parte degli attributi, ovvero il sottoschema, risultano uguali.
Esempio
- Definizione Equivalenza tra due insiemi di dipendenze funzionali
Siano e due insiemi di dipendenze funzionali, sono equivalenti se , quindi , e non contengono le stesse dipendenze ma le loro chiusure si.
Verificare Equivalenza di due insiemi di Dipendenze Funzionali
Quindi per verificare l’equivalenza dobbiamo verificare l’uguaglianza tra le loro chiusure, ovvero e che .
Come visto prima calcolare la chiusura di un insieme di dipendenze richiede tempo esponenziale, ma questo lemma ci viene in aiuto.
Lemma 2
Siano e due insiemi di dipendenze funzionali, se allora
Dimostrazione
-
Sia , quindi è una dipendenza che sta in ma non in .
-
Ogni dipendenza che si trova in è derivabile da per gli assiomi di Armstrong, infatti per la nostra ipotesi e per il teorema . Infatti se significa che fa parte della chiusura di ed è quindi derivabile da mediante gli assiomi di Armstrong
- Dato che abbiamo è derivata da tramite Armstrong.
- E quindi è derivabile da mediante gli assiomi di Armstrong, infatti dato che sta in significa che abbiamo applicato Armstrong a tutto e quindi anche sta in .
Adesso possiamo dare la definizione.
Sia uno schema di relazione, un insieme di dipendenze funzionali su e una decomposizione di diciamo che preserva se:
Dove con indichiamo quindi è l’insieme delle dipendenze funzionali che appartengono ad e sono “compatibili” con il sottoschema ovvero che gli attributi che compaiono nella relazione sono contenuti nel sottoschema.
In modo formale quindi è un insieme di dipendenze funzionali dato dalla proiezione dell’insieme di dipendenze funzionali sul sottoschema e proiettare un insieme di dipendenze su un sottoschema significa prendere tutte e sole le dipendenze in che hanno tutti gli attributi in .
Adesso supponiamo di avere già una decomposizione e di voler verificare se preserva le dipendenze funzionali.
Verificare se una decomposizione preserva un insieme di dipendenze richiede che venga verificata l’equivalenza dei due insiemi di dipendenze funzionali e . Quindi dobbiamo verificare che e che .
Per come abbiamo definito sappiamo che i suoi elementi sono proiezioni di dipendenze di , inoltre sappiamo che contiene queste proiezioni (condizione dell’and) e quindi contiene , scritto più formalmente abbiamo che che per il lemma 2 implica che .
Quindi adesso ci manca da verificare che che poi con il lemma ci porta a dire che .
Questa verifica può essere fatta tramite un algoritmo. Algoritmo contenimento di F in
- Input: Due insiemi e di dipendenze funzionali su
- Output: Una variabile che indica true se , altrimenti false
Infatti se per il lemma abbiamo che e quindi neanche in per il teorema. Basta quindi trovare una sola dipendenza che non rispetta la condizione per poter affermare che non c’è equivalenza.
Ma come calcoliamo ? Infatti non possiamo utilizzare l’algoritmo che conosciamo dato che non sappiamo come è fatta , inoltre per la definizione di dobbiamo prima calcolare ma richiede tempo esponenziale.
Vediamo quindi un algoritmo che ci permette di calcolare a partire da .
- Input: uno schema , un insieme di dipendenze funzionali su , una decomposizione di e un sottoinsieme di .
- Output: La chiusura di rispetto a , in questo caso lo inseriamo nella variabile .
Nel primo for stiamo raccogliendo gli attributi determinati da ovvero il nostro , e grazie all’intersezione ci assicuriamo che sia dipendenti che dipendente si trovino nel sottoschema, tutti questi li raccogliamo in .
Poi con il while quello che andiamo a fare è essenzialmente raccogliere in tutti gli attributi che sono determinati da anche se non si trova nel sottoschema, questo perché magari sono determinati da attributi presenti in altri schemi dove in questi sono determinati da .
Per fare questo utilizziamo le dipendenze nella chiusura di dato che sappiamo che le dipendenze che formano sono incluse in .
Ricordiamo che l’algoritmo per definizione termina sempre, ci fornisce la chiusura di un insieme di attributi rispetto ad un insieme di dipendenze funzionali che non conosciamo, ma sappiamo essere incluso in un altro, questo risultato dobbiamo quindi utilizzarlo insieme all’algoritmo visto precedentemente per l’equivalenza di due insiemi di dipendenze.
Teorema Dimostrazione Algoritmo
Sia uno schema di relazione, un insieme di dipendenze funzionali su e una decomposizione di . Prendiamo un sottoinsieme di . L’algoritmo calcola correttamente dove .
Dimostrazione
Dato che l’algoritmo aggiunge sempre qualcosa alla chiusura senza mai togliere nulla, possiamo procedere per induzione.
Indichiamo con il valore iniziale di e con il valore di dopo l’i-esima esecuzione dell’assegnazione , è facile vedere che per ogni i.
Sia il valore di quando l’algoritmo termina, proveremo che:
Parte solo se
Mostriamo che per ogni , in particolare per
-
Base dell’induzione , poiché e si ha che .
-
Induzione: , per ipotesi induttiva abbiamo che , con indichiamo le iterazione del while
Sia un attributo in ovvero che lo abbiamo aggiunto nell’iterazione appena fatta, significa che quindi esiste un indice della decomposizione tale che .
Poiché possiamo dire che .
Quindi sappiamo che:
- (appartiene all’intersezione fra la chiusura e vista prima)
Adesso per la definizione di si ha che , infatti in abbiamo le proiezione delle dipendenze sui sottoschemi e siccome abbiamo l’intersezione con sappiamo che si trova in un sottoschema.
Per ipotesi induttiva sappiamo che ovvero che e per la regola della decomposizione possiamo dire che .
Possiamo quindi usare l’assioma della transitività, dato che e che possiamo dire che e quindi che . Quindi .
Abbiamo mostrato che vengono inseriti anche gli elementi della i-esima iterazione mentre quelli delle precedenti ci sono per ipotesi.
Parte Se non ci interessa
Join Senza Perdita
Quando uno schema viene decomposto abbiamo visto che non basta mantenere la 3NF sui sottoschemi, dobbiamo anche mantenere tutte le dipendenze e tutti i dati dell’istanza originale quando effettuiamo un join sui sottoschemi, per perdita di dati intendiamo in realtà un’aggiunta di informazioni estranee allo schema originale. (Fatti esempi più sopra).
Quindi quando decomponiamo uno schema abbiamo come obiettivo: permettere la ricostruzione di ogni istanza legale dello schema originale mediante join naturale.
Definizione
Sia uno schema di relazione, una decomposizione di ha un join senza perdita se per ogni istanza legale di si ha che:
Infatti facendo la proiezione di un’istanza su ogni sottoschema otteniamo “una parte” di quell’istanza, facendo il join dobbiamo ricomporla tutta.
Partiamo da una decomposizione data e cerchiamo un modo per verificare che soddisfi la proprietà data.
Teorema
Sia uno schema di relazione e una decomposizione di . Per ogni istanza legale di , indicato con si ha che:
Abbiamo uno schema e un insieme di dipendenze funzionali e una decomposizione , come verifichiamo che la decomposizione ha un join senza perdita? Possiamo farlo tramite un algoritmo di verifica che agisce in tempo polinomiale ovvero per una qualche costante .
- Input: uno schema di relazione , un insieme di dipendenze funzionali su e una decomposizione di .
- Output: un booleano che ci dice se ha un join senza perdita.
Costruiamo una tabella in modo tale da avere un numero di colonne pari al numero degli attributi di e un numero di righe pari al numero di sottoschemi presenti nella decomposizione .
Nelle celle che si incontrano all’indice per le righe e per le colonne inseriamo il simbolo se l’attributo ovvero se l’attributo della colonna appartiene al sottoschema della riga . Altrimenti inseriamo .
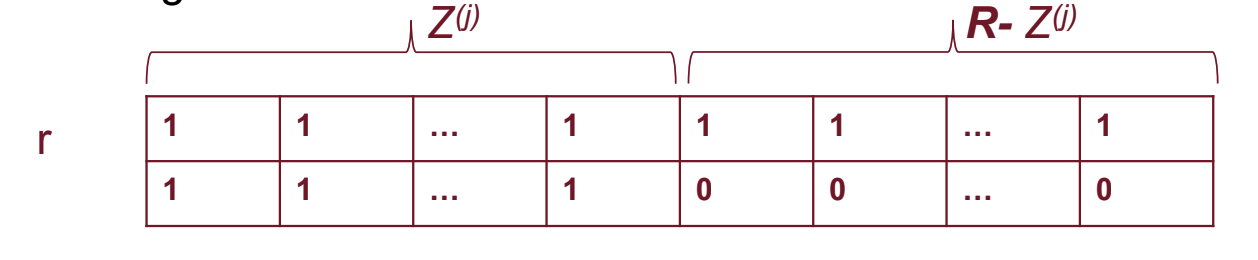
Adesso per ogni dipendenza controlliamo se nella tabella ci sono tuple che non rispettano la dipendenza ovvero tali che e , e a questo punto le facciamo diventare “legali”, se in una tupla è presente una nell’attributo allora propaghiamo questa a tutte le altre, altrimenti scegliamo un a piacere e la propaghiamo su tutte le altre.
Se abbiamo apportato modifiche continuiamo ad applicare l’algoritmo altrimenti ci fermiamo. Ci fermiamo anche se in una riga ci sono tutte .
Se quando ci fermiamo è presente una riga con tutte allora la decomposizione ha join senza perdita.
Osservazione
- Possiamo considerare gli come valori particolari appartenenti al dominio dell’attributi .
- Possiamo considerare i come valori particolari appartenenti al dominio dell’attributo
- Possiamo considerare tutti i valori uguali tra di loro
- Il valore è diverso da e da un altro valore anche se appartengono tutti allo stesso dominio dell’attributo
- Quindi la nostra iniziale è una particolare istanza dello schema che trasformiamo in un’istanza legale e per fare questo dobbiamo fare in modo che tutte le dipendenze in siano soddisfatte.
- Infatti quando troviamo tuple uguali sugli attributi di sinistra (determinanti) allora facciamo in modo che siano uguali anche sui dipendenti, dando precedenza alle .
- Quando ci fermiamo significa che abbiamo costruito un’istanza legale di

Esempio
Dato lo schema e , dire se la decomposizione ha un join senza perdita.
Costruiamo la tabella
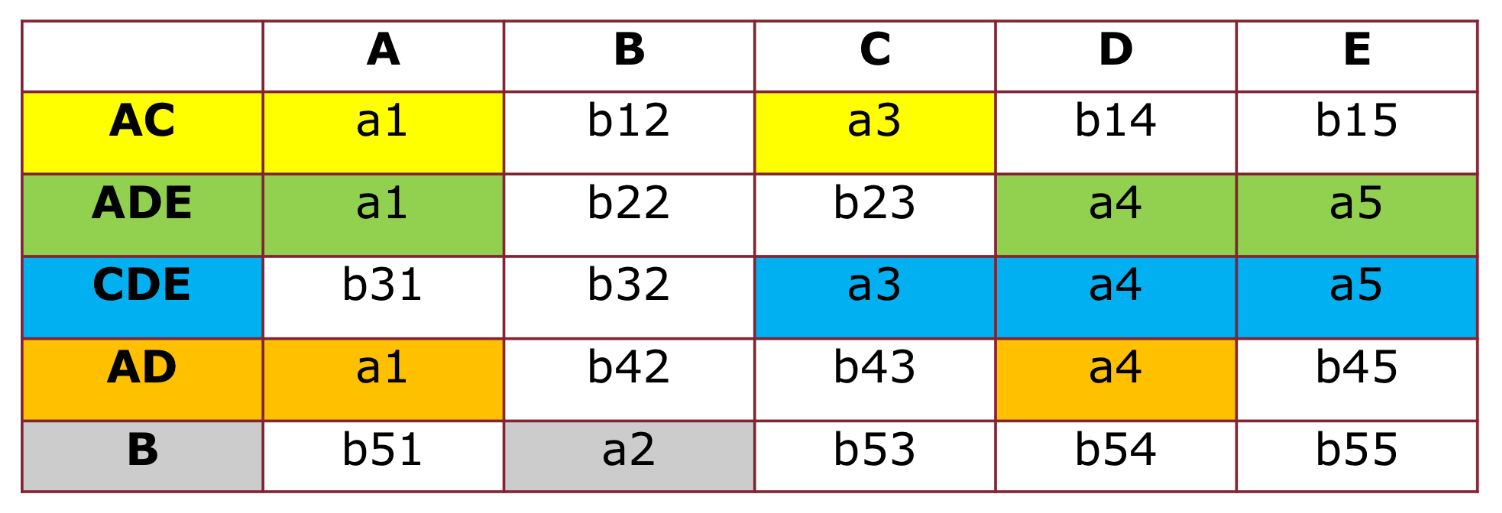
Adesso iniziamo a verificare le dipendenze:
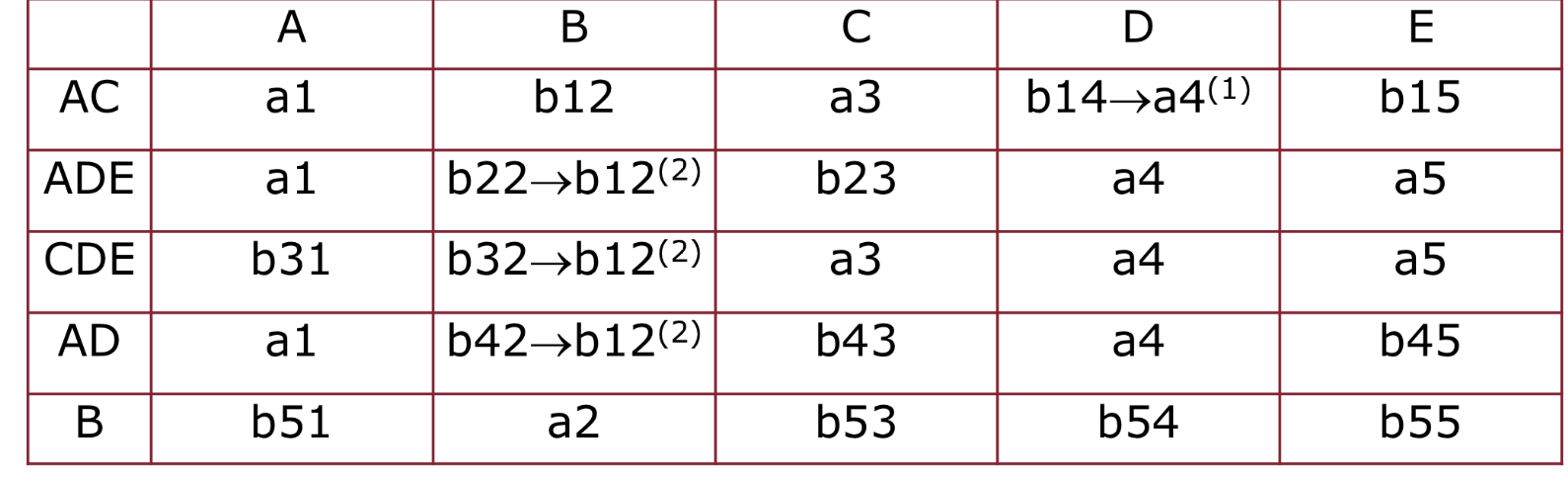
- , prima e terza riga sono uguali su C ma diverse su D, sulla riga 3 abbiamo quindi la portiamo anche alla prima riga
- è già soddisfatta
- , abbiamo 3 tuple uguali su D e diverse su B, non abbiamo nessuna quindi scegliamo una e la portiamo su tutte le righe
Scriviamo la tabella e siccome abbiamo effettuato modifiche e non abbiamo su un’intera riga, continuiamo ad applicare l’algoritmo.
- è già soddisfatta
- abbiamo 3 tuple uguali su AB e diverse su E, sulla E abbiamo quindi portiamo su tutte le tuple
- già soddisfatta
Scriviamo la tabella e continuiamo con le iterazioni
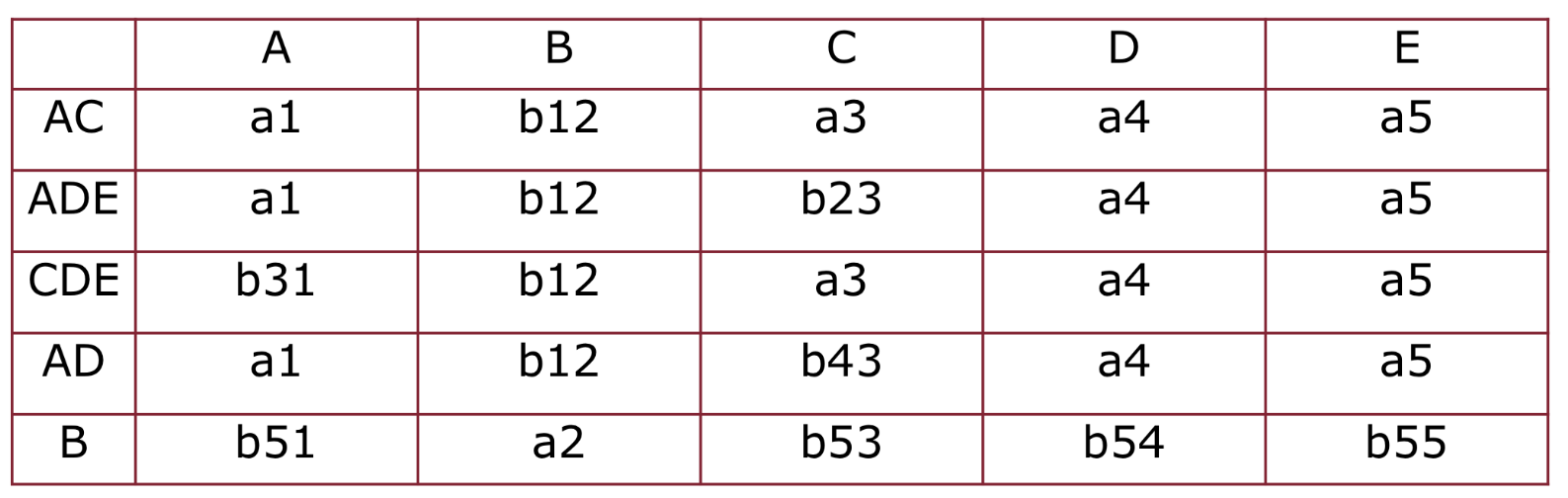
Adesso notiamo che tutte e 3 le dipendenze sono soddisfatte e quindi non facciamo cambiamenti in questa iterazione, l’algoritmo si ferma.
Abbiamo una riga con tutte ? No quindi la decomposizione non ha join senza perdita.
Non so se serve la dimostrazione di questo algoritmo di verifica (spoiler serviva)
Ottenere una decomposizione con Join senza perdita
Abbiamo visto sempre come verificare che una decomposizione non abbia perdita nel join, ma è sempre possibile ottenere una decomposizione con questa proprietà? Si, è possibile tramite un algoritmo.
Ci sono alcune osservazioni da fare, la decomposizione che si ottiene da questo algoritmo non è l’unica possibile, quindi se ci viene fornito uno schema e una decomposizione ma con l’algoritmo non ci viene restituita la stessa non significa che una delle due è sbagliata, potrebbero essere entrambe corrette. È importante quindi utilizzare i due algoritmo nel momento giusto, uno per la verifica e uno per ottenere decomposizioni.
Per usare questo algoritmo ci serve il concetto di copertura minimale di un insieme di dipendenze. Questa copertura è l’input dell’algoritmo e ce dato un insieme di dipendenze ci possono essere più coperture minimali, proprio per questo l’algoritmo può fornire diverse decomposizioni.
Copertura Minimale
Sia un insieme di dipendenze funzionali, una copertura minimale di è un insieme equivalente ad tale che:
-
Ogni dipendenza funzionale di ha la parte destra che è un singleton.
-
Per nessuna dipendenza funzionale esiste tale che ovvero gli attributi nella parte sinistra non sono ridondanti. Ad esempio se abbiamo non dobbiamo avere e .
Non deve essere quindi possibile determinare tramite un sottoinsieme di .
-
Per nessuna dipendenza funzionale deve accadere , ovvero ogni dipendenza è non ridondante. Ad esempio se abbiamo e possiamo eliminare dato che possiamo ricostruirla per transitività.
Non deve essere possibile determinare tramite altre dipendenze.
Vediamo come calcolare questa copertura minimale.
Per ogni insieme di dipendenze funzionali esiste una copertura minimale equivalente ottenibile in tempo polinomiale.
Passaggi:
- Usando la regola della decomposizione riduciamo i dipendenti in singleton
- Per ogni dipendenza funzionale tale che questa viene sostituita appunto da ovvero la dipendenza che ha come determinante il sottoinsieme del precedente determinante. Se invece questa dipendenza è già presente allora eliminiamo semplicemente quella più grande. Applichiamo ricorsivamente il passo finché non è più possibile ridurre dipendenze.
- Ogni dipendenza tale che viene eliminata dato che è ridondante.
I passi 2 e 3 ovviamente richiedono una verifica dell’equivalenza, ma ci troviamo in dei casi particolari.
Per il passo 2 assumiamo che sia l’insieme che contiene la dipendenza originaria e con l’insieme che contiene quella “ridotta”. Notiamo che i due insieme differiscono soltanto di una dipendenza, quindi tutte le altre sono uguali e appartengono quindi alle loro chiusure. Per verificare quindi l’equivalenza dobbiamo solo verificare che la dipendenza originale si trova in e quella ridotta si trova in .

Per calcolare le chiusure degli insiemi usiamo l’algoritmo, che a sua volta calcola le chiusure degli insiemi di attributi. Andare a verificare se la dipendenza originale si trova in è superfluo dato che in abbiamo quella con un dipendente in meno, e quindi se aggiungiamo qualcosa non cambia nulla.
Banalmente, se abbiamo sarà vero anche .
Esempio
Abbiamo , per verificare se possiamo eliminare la in dobbiamo verificare se e se . Per la prima ci basta applicare l’algoritmo e notiamo che mentre per la seconda è banale dato che infatti compare .
Adesso ci manca da verificare che e per farlo usiamo l’algoritmo per verificare se , dobbiamo quindi calcolarlo. Se questo accade possiamo ridurre la dipendenza o rimuoverla in alcuni casi.
Passo 3
Assumiamo di chiamare l’insieme che contiene e con l’insieme dove è stata eliminata. Anche in questo caso i due insiemi differiscono di una sola dipendenza e inoltre si verifica che e quindi già sappiamo . Ci manca quindi da verificare che che sarà vero se .
In particolare ci basta verificare che ovvero .
Riassumendo
Indichiamo con l’insieme che contiene la dipendenza e con quello che contiene al suo posto dove . Per il passo 2:
- Dobbiamo verificare che , se accade riduciamo la dipendenza, o se presenti entrambe in eliminiamo .
- Se e tale che allora eliminiamo .
- Se ma non esiste con allora è inutile provare ad eliminare attributi a sinistra della dipendenza.
- È inutile ricalcolare chiusure transitive di attributi o di gruppi di attributi.
Per il passo 3, assumiamo che contiene l’originale e che non la contiene. Dobbiamo verificare e per farlo ci basta verificare ovvero se :
- Se ma non esiste con allora è inutile provare ad eliminare .
- Vanno ricalcolate le chiusure di attributi e gruppi di attributi.
Esempio

Algoritmo di Decomposizione
Dato uno schema di relazione e un insieme di dipendenze funzionali su esiste sempre una decomposizione di tale che:
- Per ogni abbiamo in 3NF
- preserva
- ha un join senza perdita
Inoltre tale decomposizione può essere calcolata in tempo polinomiale.
L’algoritmo prende come una copertura minimale, ci va bene una qualsiasi.
Algoritmo
Dimostrazione Algoritmo
Abbiamo detto che l’algoritmo permette di calcolare una decomposizione che in tempo polinomiale ha ogni sottoschema in 3NF e preserva le dipendenze.
Dimostriamo le due proprietà.
- preserva .
Sia . Poiché per ogni dipendenza funzionale si ha che (dato che è un sottoschema, li aggiungiamo in un passo dell’algoritmo) e quindi questa dipendenza di sarà sicuramente in , quindi dato che allora , l’inclusione inversa è verificata dato che per definizione abbiamo che .
- Ogni schema di relazione in è in 3NF
Si possono verificare diversi casi:
- Se ogni attributo in fa parte della chiave e quindi banalmente è in 3NF (infatti in S abbiamo gli attributi che non compaiono nelle dipendenze, questo significa che non vengono mai determinati e quindi si trovano sicuramente nella chiave)
- Se esiste una dipendenza funzionale che coinvolge tutti gli attributi, siccome è una copertura minimale, avrà forma inoltre non ci possono essere dipendenze in tali che e quindi è chiave in (coinvolge tutti gli attributi). Inoltre sia una qualsiasi dipendenza in , se allora, siccome minimale, ovvero superchiave e quindi mantiene la 3NF. Se invece allora che è chiave e quindi è primo, rispetta ancora la 3NF.
- Se , dato che è una copertura minimale, non ci può essere dipendenza funzionale tale che e quindi è chiave in . Inoltre sia una qualsiasi dipendenza in tale che se allora poiché è una copertura minimale ovvero superchiave e quindi rispettiamo la 3NF, se invece allora deve essere in che è chiave e quindi è primo, rispettiamo ancora la 3NF.
- Come facciamo ad ottenere un join senza perdita?
Ci basta aggiungere un sottoschema contenente una chiave al risultato dell’algoritmo di decomposizione. Adesso però dobbiamo dimostare che questa aggiunta non ci fa perdere gli obiettivi ottenuti prima.
Teorema
Sia uno schema di relazione e un insieme di dipendenze funzionali su , che è una copertura minimale, inoltre sia la decomposizione di prodotta dall’algoritmo di decomposizione. La decomposizione dove è una chiave per , è tale che:
- Ogni schema di è 3NF
- preserva
- ha un join senza perdita
IN TEORIA NON LE CHIEDE
Dimostrazione
- preserva , infatti dato che preserva , lo farà anche .
Infatti stiamo aggiungendo un nuovo sottoschema, una nuova proiezione di . Chiamiamo il nuovo , e lo definiamo come quindi e quindi . L’inclusione inversa è banalmente verificata per lo stesso motivo del teorema precedente.
- Ogni schema di relazione in è in 3NF
Poiché , è sufficiente verificare che anche lo schema sia in 3NF, dobbiamo mostrare che è chiave anche per lo schema .
Supponiamo per assurdo che non lo sia, allora esiste un sottoinsieme proprio di che determina tutto lo schema ovvero tale che o più precisamente appartiene alla chiusura ma questa è sottoinsieme di . Poiché è chiave per lo schema , ovvero , per transitività si ha che che contraddice il fatto che è chiave per lo schema . Quindi è chiave per lo schema e per ogni dipendenza funzionale con , primo.
- ha un join senza perdita
Continuare dimostrazione, slide 19 con aggiunte pag. 13
Supponiamo che l’ordine in cui gli attributi in vengono aggiunti a dell’algoritmo che calcola la chiusura di un insieme di attributi (qui ) sia e supponiamo che per ogni l’attributo venga aggiunto a a causa della presenza
SPERO NON LE CHIEDA VERAMENTE 🥶
Quindi presa un qualsiasi schema di DB possiamo farlo diventare “buono” effettuando decomposizioni per portarlo in 3NF.