Learning Algorithms
Un algoritmo di machine learning è in grado di imparare dai dati. Ma cosa intendiamo con imparare?
Mitchell (1997)
A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E.
The Task, T
Il Machine Learning ci permette di affrontare tasks che sarebbero troppo difficili con dei semplici programmi. Cercando di dare la definizione di tasks è importante notare che il processo di apprendimento non è la task ma il mezzo con il quale otteniamo le capacità di svolgere il task.
Gli algoritmi di machine learning di solito vengono descritti in base a come dovrebbero processare un example. Un example è una collezione di features che sono state misurate da un oggetto o evento che vogliamo far processare all’algoritmo. Rappresentiamo l’example come un vettore dove ogni valore è una feature. Ad esempio, le features di un’immagine sono i pixel che la compongono.
Con algoritmi di machine learning possiamo risolvere tantissimi tipi di tasks, tra i più importanti:
-
Classification: Viene chiesto all’algoritmo di specificare a quali categorie appartiene l’input. In generale viene chiesto all’algoritmo di produrre una funzione , quando il modello assegna all’input descritto da la categoria identificata da . Un esempio di classification è il riconoscimento di oggetti, quindi come input abbiamo un’immagine e come output un codice numerico che identifica l’oggetto nell’immagine.
-
Classification with missing inputs: La classification diventa più difficile se l’algoritmo non è sicuro di trovare tutti i dati nel suo vettore di input. Ad esempio in campo medico non sempre abbiamo a disposizione tutte le visite possibili magari perché sono troppo invasive o costose. L’algoritmo deve quindi essere in grado di lavorare anche quando manca qualche dato, per fare questo l’algoritmo non deve più definire una singola funzione ma un set di funzioni, ogni funzione corrisponde a mappare l’input se manca un sottoinsieme di dati. Quindi se abbiamo variabili in ingresso l’algoritmo dovrà mappare funzioni ma spesso è inefficiente e su alcuni sistemi impossibile, per risolvere il problema l’algoritmo dovrà imparare la distribuzione di probabilità congiunta di tutte le variabili. In pratica deve creare una mappa che mette in relazione fra loro tutte le variabili (ad es. malattie, visite e sintomi) le loro dipendenze e quanto spesso si verificano insieme, quando un dato manca il modello marginalizza il dato ovvero “elimina” l’impatto della variabile mancante calcolando una media ponderata di tutti i possibili valori che l’esame avrebbe potuto avere basandosi sulle altre variabili presenti.
-
Regression: Viene chiesto all’algoritmo di predire un valore numerico dato un input. In questo caso viene chiesto all’algoritmo di fornire una funzione . Ad esempio nelle compagnie di assicurazioni o in algorithmic trading.
-
Transcription: Qui viene chiesto all’algoritmo di osservare la rappresentazione, non strutturata, di alcuni dati e trasformarla in testo. Ad esempio viene fornita una foto con del testo e vogliamo che ci venga fornito il testo in output come caratteri, oppure il riconoscimento vocale delle parole.
-
Machine Translation: In questo caso l’input è già in forma di testo, semplicemente viene fornito in una lingua e l’algoritmo deve convertirlo in un’altra.
-
Structured Output: Comprendono ogni tasks dove l’output è un vettore e dove le relazioni tra gli elementi sono molto importanti. Qui non ci basta una semplice risposta tipo “La mail è spam o no?” ma vogliamo delle risposte strutturata e complesse. Alcuni esempi sono parsing ovvero una sorta di analisi grammaticale dove l’algoritmo deve classificare ogni parola (verbo, aggettivo, avverbio…), la segmentazione delle immagini ovvero indicare ogni pixel a cosa appartiene (strada, prato, macchina…) oppure le didascalie per immagini (image captioning) ovvero forniamo all’algoritmo un’immagine e lui ci fornisce un testo che la descrive. In sintesi in questi problemi gli algoritmi non devono soltanto indovinare dei valori ma produrre valori che hanno senso relazionati fra loro.
-
Anomaly Detection: L’algoritmo riceve una serie di eventi od oggetti e identifica quali fra quelli sono diversi dal solito. Un esempio di utilizzo è per rilevare i furti di carte di credito o simili.
-
Synthesis and sampling: In questi problemi viene chiesto all’algoritmo di generare esempi simili a quelli che ha utilizzato in fase di allenamento. Questo può essere utile quando potrebbe essere molto noioso o costoso recuperare tanti dati per il modello.
-
Imputation of missing values: Viene dato all’algoritmo un nuovo esempio ma con alcuni valori mancanti, l’algoritmo deve essere in grado di indovinare questi valori.
-
Denoising: Viene dato all’algoritmo un esempio corrotto ottenuto tramite un processo corrotto da un esempio pulito . L’algoritmo deve indovinare l’esempio pulito dalla sua versione corrotto o, in generale, indovinare la distribuzione di probabilità condizionata .
-
Density estimation or probability mass function estimation: Viene chiesto all’algoritmo di imparare una funzione dove può essere interpretata come funzione di densità di probabilità se è continua oppure come funzione di probabilità se discreta. Stiamo chiedendo all’algoritmo di comprendere la “mappa” o le regole dell’universo di dati che sta osservando. Imparare quella funzione per l’algoritmo significa capire dove i dati si raggruppano e dove invece sono rari o impossibili. In realtà quasi tutti gli algoritmi di ML fanno questo implicitamente ma se riusciamo a calcolarla in modo esplicito per l’universo dei nostri dati possiamo risolvere tutti gli altri problemi, ad esempio per l’imputation se abbiamo già calcolato la mappa di come si comportano i pazienti e arriva un paziente a cui manca un esame non abbiamo bisogno di un nuovo algoritmo, usiamo le regole della probabilità condizionata calcolando .
Ovviamente calcolare questa mappa completa dei nostri dati è spesso computazionalmente intrattabile per problemi reali.
The Performance Measure, P
Per valutare le performance di un algoritmo di ML dobbiamo creare una misura quantitativa, di solito una misura P è specifica per una task T. Per task come classification, classification with missing inputs e transcription, spesso si misura l’accuracy del modello ovvero la proporzione di esempi per i quali il modello produce output corretto. Otteniamo le stesse informazioni se ad esempio misuriamo l’error rate ovvero per quanti esempi fornisce output errato.
Per task come density estimation non ha senso misurare l’accuracy o l’error rate ma va usata una metrica che fornisca un “punteggio continuo”, vogliamo valutare quanto il modello sia coerente con la realtà:
- Se diamo al modello dati reali e lui aveva predetto che questi avevano un’alta probabilità di esistere → voto alto.
- Se diamo dati reali e aveva stimato una bassa probabilità → voto basso.
La soluzione è utilizzare la average log-probability:
- Si prende un insieme di test.
- Si chiede al modello, per ogni test, quale era la probabilità secondo la sua mappa.
- Queste probabilità sono numeri molto piccoli e per non andare incontro a problemi di underflow si utilizza il logaritmo.
- Si sommano tutte queste log-probabilità e si fa la media.
Un altro fattore importante è il come decidiamo di valutare l’algoritmo, ad esempio:
- Se deve fare trascrizioni e scrive “il ratto è sul tavolo” invece di “il gatto è sul tavolo” gli diamo un voto di 0 oppure un 80% dato che ha comunque indovinato 4 parole su 5?
- È meglio un algoritmo che sbaglia sempre di pochissimo oppure un algoritmo sempre preciso ma che quando sbaglia, anche se raramente, di valori enormi?
Tutto dipende a cosa servirà il sistema ma anche al budget o altre scelte di design.
The Experience, E
Possiamo dividere gli algoritmi di ML in due categorie in base al tipo di experience che fanno durante il processo di apprendimento:
- Unsupervised
- Supervised
Molti algoritmi che vedremo hanno imparato da interi dataset, una collezione di examples (data points). Uno dei dataset più vecchi è il Iris dataset, una collezione di misurazioni di diverse parti di 150 piante, ogni pianta corrisponde ad una example mentre le features di ogni example sono le misurazioni di ogni parte della pianta.
Unsupervised learning algorithms - Prendono il dataset ed imparano proprietà della struttura di quel dataset, in deep learning vogliamo imparare l’intera distribuzione della probabilità che ha generato il dataset.
Supervised learning algorithms - In questo caso ogni esempio del dataset viene affiancato con una label o target, ad esempio l’Iris dataset è annotato con la specie di ogni pianta.
In generale, unsupervised learning significa osservare diversi examples di un vettore casuale e provare ad imparare, in modo implicito o esplicito, la distribuzione di probabilità o alcune sue proprietà. Il supervised learning invece significa osservare gli examples di un vettore e un altro vettore associato e imparare a predire da , quindi con . Il termine supervised deriva dal fatto che di solito il vettore viene fornito da un insegnante (rispetto al modello) che appunto insegna all’algoritmo come pensare. Nell’unsupervised learning ovviamente manca questa figura.
La linea che separa queste due metodologie è molto vaga e spesso molte tecnologie di ML possono essere usate per entrambe, di solito le persone si riferiscono a problemi di regression, classification e strctured output come supervised learning mentre density estimation in supporto ad altra task viene considerata unsupervised learning.
Esistono però anche altri tipi di algoritmi di ML che non utilizzano dei dataset fissi, ad esempio gli algoritmi di reinforcement learning che interagiscono con un ambiente tramite un feedback loop tra il learning systems e le esperienze su di questo, è praticamente un trials and errors dove l’algoritmo va appunto a tentativi.
In generale però la maggior parte degli algoritmi di ML imparano da dei dataset, un dataset può essere descritto in molti modi ma in tutti i casi è semplicemente una collezione di examples che a loro volta sono collezione di features. Uno dei modi più utilizzati per descrivere i dataset sono le design matrix, queste contengono un examples su ogni riga mentre ogni colonna corrisponde ad una diversa feature. Prendiamo come esempio l’Iris dataset, contiene 150 examples con 4 features ciascuno, questo significa che possiamo rappresentarlo con una design matrix .
Ovviamente per descrivere un dataset in questo modo è necessario che ogni example sia rappresentabile con un vettore e che tutti questi vettori abbiano la stessa dimensione. Non sempre è possibile, ad esempio se abbiamo diverse foto come examples non è detto che abbiano tutte la stessa dimensione. In casi come questo invece che descrivere il dataset come una matrice con righe, lo descriviamo come un set che contiene elementi: , questa notazione non implica che due vettori e abbiano la stessa dimensione. In casi come il supervised learning avremo bisogno anche di strutture aggiuntive per le label di ogni example, dato che non ci sono definizioni formali non ci sono nemmeno regole precise su queste strutture, è sempre possibile quindi realizzarne di nuove più adatte alle nostre esigenze.
Esempio: Linear Regression
L’obiettivo è quello di costruire un sistema che prende in input un vettore e predice il valore di uno scalare come output. Nel caso della linear regression, l’output è una funzione lineare dell’input. Diciamo che è il valore che il nostro modello predice e lo definiamo come:
dove è un vettore di parametri. I parametri sono valori che controllano il comportamento del sistema, in questo caso il coefficiente verrà moltiplicato con la feature prima di sommare i contributi di tutte le feature. Possiamo pensare a come un insieme di pesi (weights) che determinano come ogni feature modifica la predizione. Se una feature riceve un peso positivo allora incrementare il valore di quella feature incrementerà il valore della predizione . Al contrario, se una feature riceve un peso negativo, incrementare il valore di quella feature abbasserà il valore della predizione.
Abbiamo quindi una definizione per la nostra task T: predire il valore dall’input dando in output il valore . Adesso abbiamo bisogno della definizione della misura della performance P.
Supponiamo di avere una design matrix di examples in input che non è stata utilizzata per la fase di training, la utilizzeremo solo per la valutazione. Abbiamo anche un vettore che per ogni example ci dice qual è il valore corretto di che vogliamo ottenere. Chiamiamo questo dataset test set e ci riferiamo alla sua design matrix con e al vettore dei target con .
Un modo per misurare le performance del modello è quello di calcolare il mean squared error sul test set. Se sono le predizioni fatte dal modello sul test set allora il mean squared error è dato da:
Mean Squared Error
- Si calcola la differenza tra il valore giusto e quello ottenuto
- Si eleva al quadrato in modo da eliminare i valori negativi ma anche per aumentare di molto il peso di errori grandi, un errore di 2 diventa 4 ma un errore di 10 diventa 100.
- Si calcola la media di tutti questi errori.
Per creare un algoritmo di ML dobbiamo fare in modo che questo migliori i pesi in modo da ridurre l’errore quando l’algoritmo impara osservando il training set. Un modo per farlo è quello di minimizzare il MSE nel training set, per farlo ci basta risolvere per quando il gradient è 0:
Il sistema di equazioni le cui soluzioni sono date dall’equazione sopra le chiamiamo normal equations, risolvere quell’equazione corrisponde ad un semplice algoritmo di ML.
Esempio
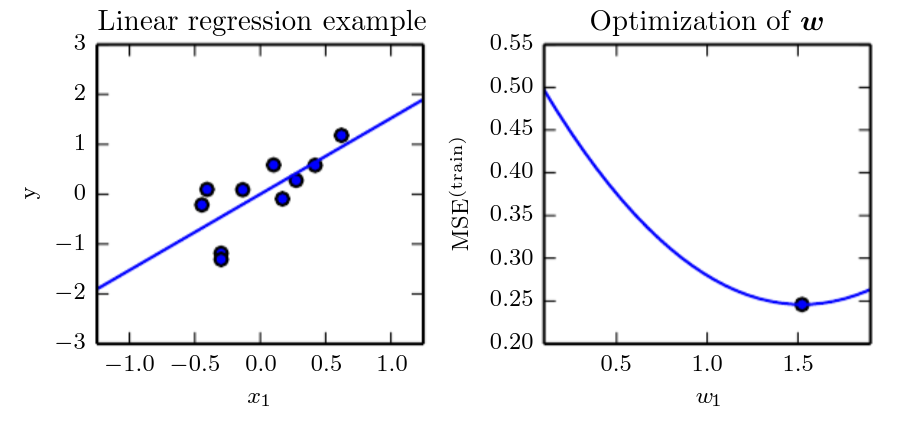
Il training set è formato da solo 10 punti, ciascuno composto da una sola feature, dato che c’è una sola feature il vettore contiene un solo parametro da imparare, . Nella figura a sinistra vediamo come l’algoritmo ha imparato a impostare in modo che la linea passi il più vicino possibile a tutti i punti. A destra invece vediamo come il valore di trovato dalla normal equations minimizza il MSE nel training set.
Significato del MSE
Il MSE è una generalizzazione della derivata di una funzione. Immaginiamo l’errore come una funzione a forma di “U”, più alti ci troviamo più alto sarà l’errore e le nostre coordinate sono i pesi , l’obiettivo è raggiungere il punto più basso. Il gradiente ci indica la “pendenza”, quindi se raggiungiamo pendenza 0 significa che siamo nel punto più basso dato che il “terreno” è piatto. Non possiamo fare normali derivate dato che non abbiamo una sola variabile ma avendo più pesi facciamo un vettore composto da “derivate parziali”, una per ogni peso, questo vettore prende il nome di gradiente.
Da notare che di solito con il termine linear regression ci si riferisce a dei modelli leggermente più complessi con un parametro aggiuntivo , usando sempre questo modello avremo:
Il termine viene spesso chiamato bias, questo deriva dal fatto che la predizione del modello viene trasformata anche in assenza di input.
Capacity, Overfitting e Underfitting
La sfida principale nel machine learning è che il modello deve performare bene su dati nuovi e mai visti prima e non soltanto su quelli usati in addestramento. L’abilità di un modello di saper gestire inputs mai visti prima si chiama generalization. Quando alleniamo un modello abbiamo accesso ad un training set sul quale possiamo misurare degli errori che chiamiamo training error, dobbiamo ridurre questi errori. Quello che separa il Machine Learning dall’Optimization è che noi vogliamo il generalization error o test error basso allo stesso modo del training error. Il generalization error è definito come il valore di errore che ci aspettiamo da un nuovo input, questo nuovo input deve comunque essere coerente con gli altri e quindi non “assurdo”.
Di solito stimiamo il generalization error di un modello misurando le sue performance su un test set di examples che abbiamo raccolto separatamente dal training set. Ma come possiamo modificare le performance sul test set se possiamo osservare e imparare soltanto dal training set? La statistical learning theory ci fornisce delle risposte. Se i due set sono raccolti in modo arbitrario c’è poco che possiamo fare ma se invece possiamo fare delle assunzioni sul come sono stati raccolti allora otteniamo dei progressi. I dati dei due set sono generati da una distribuzione di probabilità chiamata data generating process. Facciamo inoltre un set di assunzioni chiamate i.i.d. assumptions che ci dicono che gli examples in ogni dataset sono indipendenti fra loro e che i due set sono identicamente distribuiti e provengono dalla stessa distribuzione di probabilità. Chiamiamo questa distribuzione data generating distribution denotata da , questi dati ci permettono di studiare matematicamente la relazione tra training e test error.
Una relazione immediata che possiamo notare è che l’expected training error di un modello scelto casualmente è uguale all’expected test error del modello. Supponiamo di avere una distribuzione di probabilità da cui generiamo train e test set. Per qualche valore fissato l’expected training set error è esattamente lo stesso dell’expected test set error perché entrambe le expectations sono formate utilizzando lo stesso processo di creazione. Quindi finché il modello non impara dal training set avremo lo stesso livello di errore.
Infatti, quando utilizziamo modelli di ML non fissiamo , creiamo il training set con il quale l’algoritmo sceglie il più appropriato e poi gli mandiamo in input il test set. In questo modo otteniamo che l’expected test error sarà maggiore o uguale all’expected training error. Per capire quanto un modello performa bene dobbiamo vedere le sue abilità nel:
- Rendere piccolo il training error.
- Rendere piccola la differenza fra training e test error.
Questi due concetti sono collegati alle due sfide principali del ML:
- Underfitting: accade quando il modello non è in grado di ottenere un valore sufficientemente basso nel training set. (detto in modo semplice, il modello è stupido)
- Overfitting: accade quando la differenza tra training error e test error è troppo alta. (il modello “sa troppo” e usa male queste conoscenze, oppure non gli servono proprio)
Possiamo controllare il comportamento del modello alterando la sua capacity, informalmente la capacity è l’abilità del modello di saper utilizzare una vasta quantità di funzioni. Modelli con capacity bassa avranno difficoltà nel lavorare con il training set mentre modelli con capacity alta andranno in overfit memorizzando proprietà del training set che non serviranno nel test set. La capacity possiamo dire che è data dal numero di parametri che utilizziamo, ad esempio se il modello sa disegnare solo rette o se aggiungiamo esponenti sarà in grado di disegnare più curve.
Un modo che abbiamo per controllare la capacity di un algoritmo è scegliendo il suo hypothesis space, ovvero il set di funzioni che l’algoritmo può scegliere come soluzione. Ad esempio, l’algoritmo per la linear regression ha l’intero set di funzioni lineari del suo input come hypothesis space. Possiamo generalizzare la linear regression includendo polinomi nello spazio, facendolo incrementiamo la capacity.
Un polinomio di grado 1 ci fornisce il modello di linear regression che già conosciamo:
Se introduciamo come feature aggiuntiva al modello otteniamo:
Nonostante il modello utilizzi una funzione quadratica dell’input, l’output è comunque una funzione lineare dei parametri, possiamo quindi utilizzare le normal equations per allenare il modello. Possiamo continuare ad aggiungere feature, potenze di e ottenere polinomi di grado 9:
Gli algoritmi di ML generalmente performano meglio quando la loro capacity è appropriata per la complessità del task che devono compiere e per la quantità di dati sui quali vengono allenati. Modelli con poca capacity non sono in grado di risolvere task complesse, ma modelli con alta capacity potrebbero andare in overfit.
Esempi
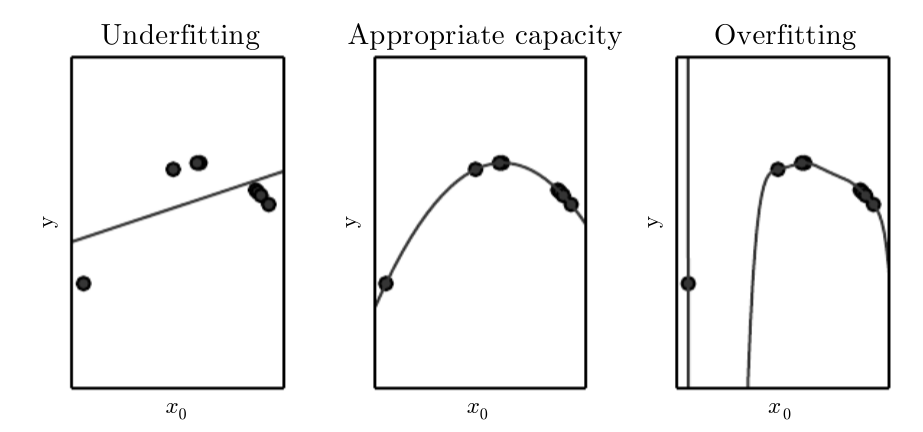
La curva richiesta è una curva quadratica.
- Il primo modello che conosce solo funzioni lineari va in underfit.
- Il secondo, conosce fino alle funzioni quadratiche e predice correttamente la curva.
- Il terzo conosce polinomi di grado 9, quindi infinite altre funzioni.
Per ora abbiamo visto solo un modo per modificare la capacity di un modello: cambiare il numero di features in input e aggiungendo anche nuovi parametri associati a queste features. Esistono però diversi altri modi per cambiare la capacity di un modello, questa non è determinata soltanto dalle scelte del modello, questo infatti specifica quale famiglia di funzioni il learning algorithm può scegliere quando cambia i suoi parametri durante l’allenamento. Questa è chiamate representational capacity del modello e indica appunto quello che può “raggiungere” il modello modificando i suoi pesi. Trovare la funzione migliore fra queste però è un grande problema di ottimizzazione quindi il nostro algoritmo non troverà mai la combinazione di pesi perfetta del modello ma una configurazione abbastanza buona. Dunque la vera capacity che riusciamo a sfruttare si chiama effective capacity e sarà sempre inferiore a quella representational.
Quindi non importa la capacity del modello perché quella che riusciremo effettivamente a sfruttare è data dal learning algorithm.
Nel Statistical Learning esistono diverse teorie per quantificare la capacity di un modello, fra queste la più conosciuta è la Vapnik-Chervonenkis dimension o VC dimension. La VC dimension misura la capacity di un binary classifier, questa è definita come il valore più grande possibile di per cui esiste un training set di diversi punti che il classifier può etichettare arbitrariamente (in due categorie).