Git serve a gestire meglio il problema del versioning, questo fenomeno di solito accade quando più persone lavorano allo stesso progetto. Esempio
Version Control Systems
I Version Control System (VCS) diventano necessari all’interno di un team, o anche da uno sviluppatore singolo, questo perché i progetti iniziano a crescere a livello di complessità e dimensione, vengono fatte diverse modifiche da più sviluppatori e quindi tenere traccia di tutti questi cambiamenti diventa necessario all’interno del progetto. Altre volte i progetti potrebbero avere più versioni che vengono sviluppate nello stesso momento, ad esempio se si vogliono testare diversi approcci ad un problema. Oppure possono tornare utili dopo svariato tempo per avere un modo di controllare quando un determinato blocco di codice è stato inserito nel progetto e quindi tenere traccia di bug, soluzioni ecc…
Questi sistemi quindi sono diventati praticamente essenziali nei progetti di oggi, questi garantiscono:
- Etichettatura (labeling) delle versioni: Più versioni di un file vengono etichettate con un metodo standard.
- Cronologia dei cambiamenti: Ogni differenza tra due versioni viene tracciata e può essere riutilizzata in futuro.
- Metadata: Ad esempio chi ha effettuato una modifica e quando.
- Branches: Un progetto può avere più versioni parallele sviluppate nello stesso momento (branch)
- Merges: Diversi branch possono essere uniti (merged) unendo le loro modifiche.
- Sincronizzazione tra diversi PC e utenti.
Diverse applicazioni sono utilizzate per questo motivo, ma la più utilizzata è git.
Git
Git è un VCS creato nel 2005 da Linus Torvalds per gestire il codice del Kernel di Linux. Nel tempo è diventato uno standard ovunque per il version control.
Repository
Una repository è un insieme di commits, branches e tags di solito dello stesso progetto. Vedremo ogni termine più avanti, per ora vediamo una repository come un contenitore per tutte le informazioni relative a un progetto. Un progetto potrebbe anche essere diviso in più repository per motivi di organizzazione.
Working Copy
La working copy o working directory è una copia in locale del progetto. È l’insieme dei file che vengono “tracciati” da git, quando aggiungiamo, modifichiamo o eliminiamo un file dobbiamo farlo sapere a Git. Git infatti gestisce i file nella working directory e quando decidiamo di cambiare versione, lui cambierà tutti i file per farli combaciare con quelli che avevamo al tempo della versione scelta.
Esempio
Abbiamo un file chiamato travels.txt e la sua prima versione contiene:
2022 RomeSuccessivamente il file viene modificato in:
2022 Rome; 2023 ParisSe torniamo indietro alla prima versione git cambierà il contenuto del file a:
2022 Rome
Commit
Un commit è come una “foto” della working directory, questa può includere tutti o solo alcuni file del progetto, quando si deve fare un commit siamo noi a decidere quali file includere. Normalmente un commit ha un padre ma ci sono diversi casi, ad esempio se c’è stato un merge tra branches allora il commit ha più padri oppure se abbiamo fatto il primo commit questo non avrà padre e viene detto “orfano”. In git ogni commit viene identificato in una repository da una stringa alfanumerica, questa è l’hash SHA1 dei contenuti del commit.
SHA1
SHA1 è una funzione di hash, quindi mappa i dati di una qualsiasi dimensione in una dimensione fissa, in alcuni casi la funzione può creare collisioni, ovvero due input hanno lo stesso valore hash. Una proprietà delle funzioni di hash infatti deve essere la resistenza alle collisioni, ovvero deve essere difficile trovare due input che restituiscono lo stesso valore hash.
Un commit ha bisogno di un messaggio esplicativo che descrive cosa è stato fatto, il commit comprende anche il nome e l’email di chi ha fatto la modifica insieme anche alla data. I commits contengono anche una copia della working directory di quel momento, questo campo viene chiamato tree.
Recap sui commits
I commits contengono:
- Commit messages
- Autore e data
- Tree (hash di tutti i file nel commit)
- Padri del commit
Viene identificato da un ID alfanumerico che è il codice hash SHA1 dei campi scritti sopra.
Staging Area
Come detto prima un commit può contenere anche solo una parte dei file modificati nella working directory, per riuscire a fare questo git utilizza la staging area. La staging area contiene tutti i cambiamenti che andranno a far parte del nuovo commit, scelti da noi. Quindi prima di effettuare un commit dobbiamo andare ad aggiungere i file nuovi, modificati o cancellati alla staging area. La staging area ci permette anche di aggiungere soltanto alcune parti di un file e non sempre il file per intero.
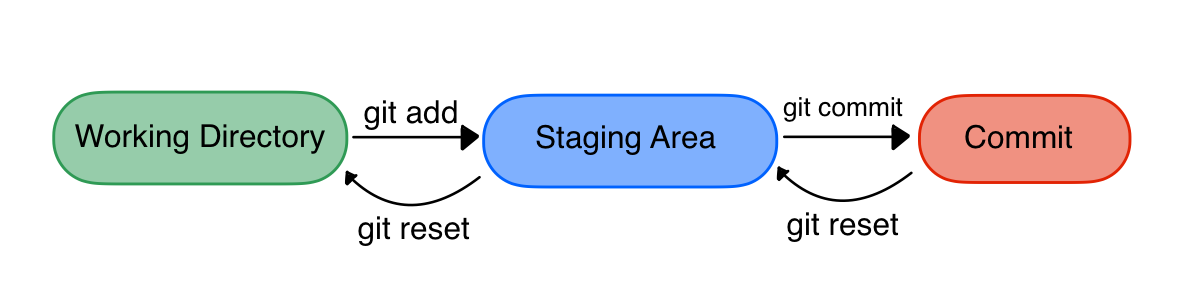
Branch
Un branch è come una linea temporale dello sviluppo di un progetto, è un insieme ordinato dei commits fatti tutti collegati fra loro in un Direct Acyclic Graph (DAG) tramite relazioni padre-figlio. Ogni branch ha un nome ed inizia con un commit, il branch punta sempre all’ultimo commit che è stato fatto su quel branch, la sua cronologia delle modifiche inizia quindi dal primo orfano ovvero il primo commit.
Esempio DAG
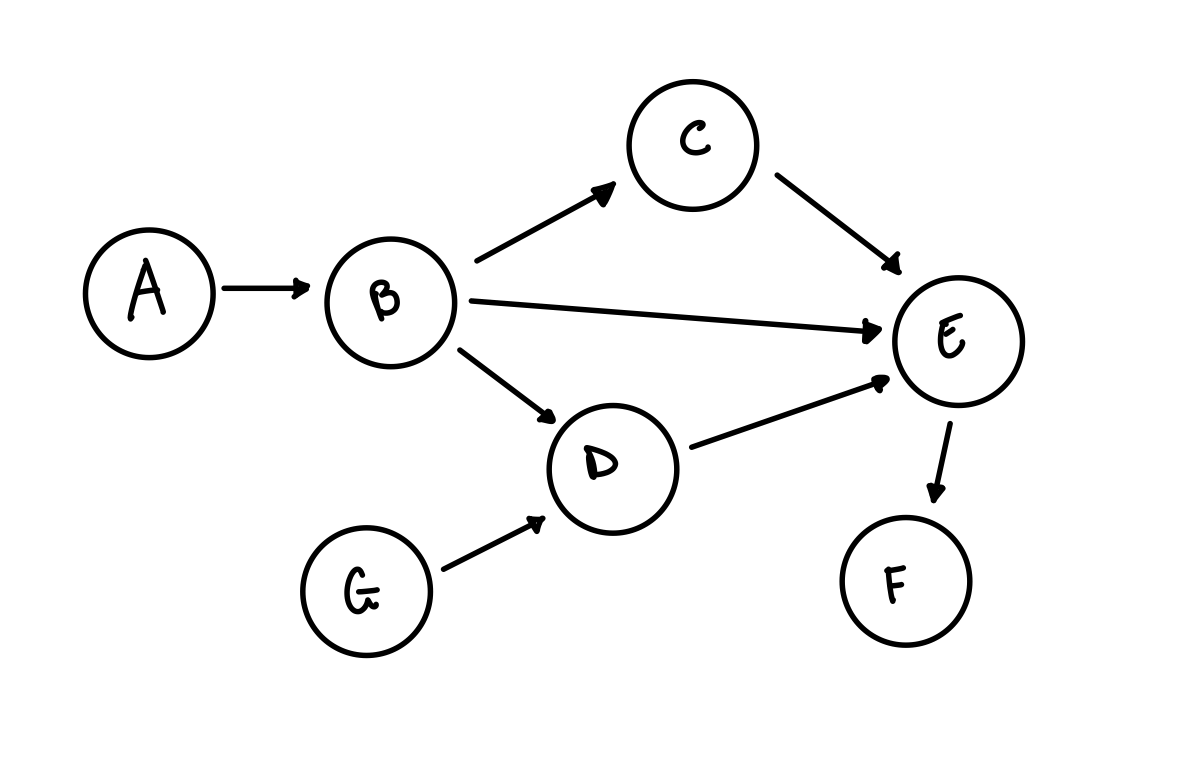
Quando creiamo una nuova repository, questa non conterrà nè commits nè branches, al nostro primo commit git creerà automaticamente il primo branch chiamato master, ogni commit successivo sarà figlio dell’ultimo commit.
Commit senza branch
È possibile creare anche dei commit senza un branch associato ma non è consigliato dato che è difficile da recuperare e il garbage collector potrebbe eliminarlo, questa è un’operazione periodica che svolge git per eliminare file inutili e ottimizzare la repository.
Esempio 1
Abbiamo una repository con il primo commit A, poi un secondo commit B e un terzo commit C, le frecce rappresentano le relazioni padre-figlio, queste puntano sempre al padre, il nome del branch master punta all’ultimo commit:
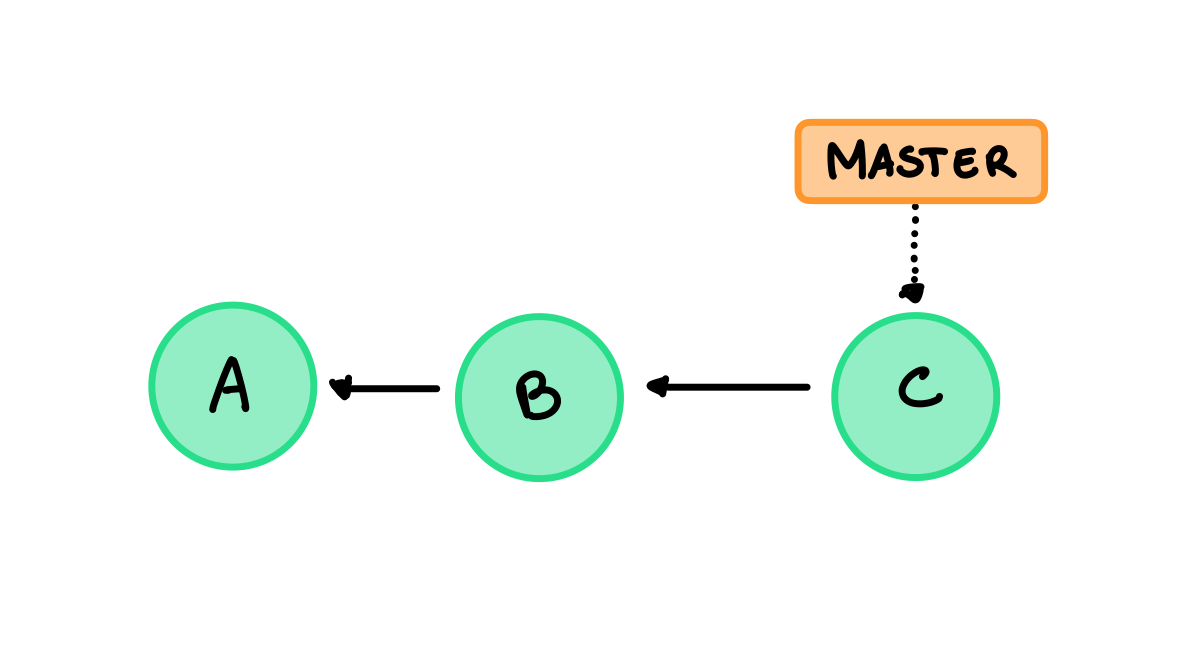
Esempio 2
In questo esempio abbiamo due branches, master e nuovo-algoritmo, questi condividono i commits A e B ma cambiano dopo quest’ultimo. Il commit C effettua modifiche al master mentre il D modifica il branch nuovo-algoritmo.
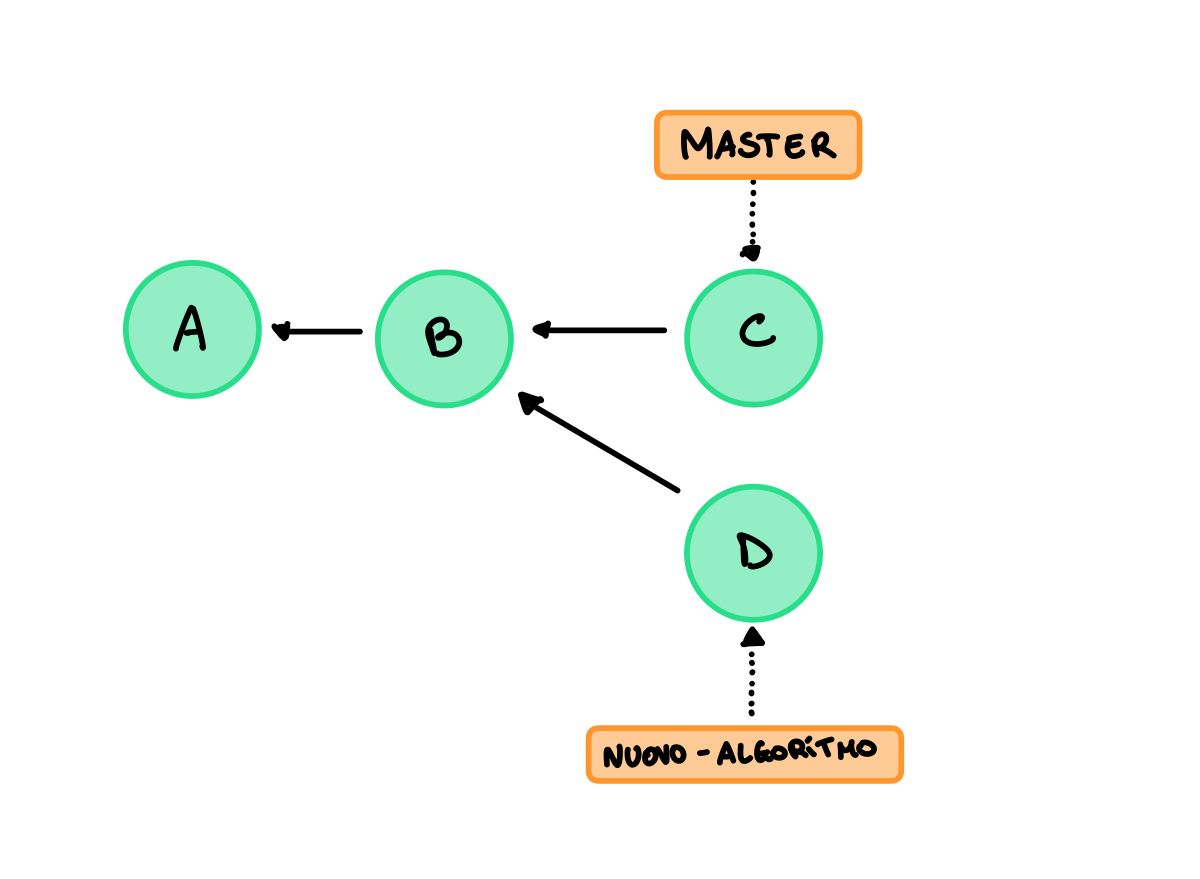
Il branching è quindi molto utile per sviluppare diverse implementazioni nello stesso momento e successivamente decidere se abbandonare alcuni branch oppure unirli. Di solito lo sviluppo principale del progetto è portato avanti sul branch master.
HEAD
In git l’HEAD è il puntatore alla posizione corrente nella git history, questa determina lo stato della working directory. In poche parole i file nella working directory corrispondono a quelli del commit puntato dall’HEAD. L’HEAD può puntare un commit, un branch o un tag (che vedremo successivamente), git ci permette di muovere l’HEAD con un comanda chiamato checkout che aggiorna la nostra working directory per combaciare con il cambiamento di HEAD. Quando l’HEAD non sta puntando ad un branch ci troviamo in un caso speciale chiamato detached HEAD, in questo stato non possiamo creare nuovi commit, dobbiamo prima spostare l’HEAD su un branch. (L’unico modo per creare commit in questo stato è crearli fuori dai branch).
Tags
Ci potrebbe tornare utile etichettare alcuni commit per tornarci in futuro, magari quel commit corrisponde ad una vecchia versione del progetto e vogliamo quindi aggiungere un tag per identificarlo più velocemente. Questi potrebbero anche essere rimossi ma non è consigliato perché sono considerati immutabili e quindi rimuoverli potrebbe causare problemi in alcuni sistemi se la repository è condivisa.
Merge
Quando i cambiamenti in un merge sono pronti per essere mossi in un altro branch possiamo eseguire il merge fra questi due, di solito il più recente conterrà le modifiche di entrambi mentre il meno recente rimane invariato. Esistono diversi modi per effettuare il merge chiamati strategies:
- fast-forward
- non-fast-forward (merge commit)
- rebase In base alla situazione in cui ci troviamo sceglieremo il metodo più adatto.
Fast-Forward Strategy
Questa è la più semplice da applicare e può essere applicata soltanto quando il nuovo branch contiene anche il precedente, in questo modo il merge sposterà semplicemente il master sul nuovo branch.
Immaginiamo di trovarci in questa situazione:
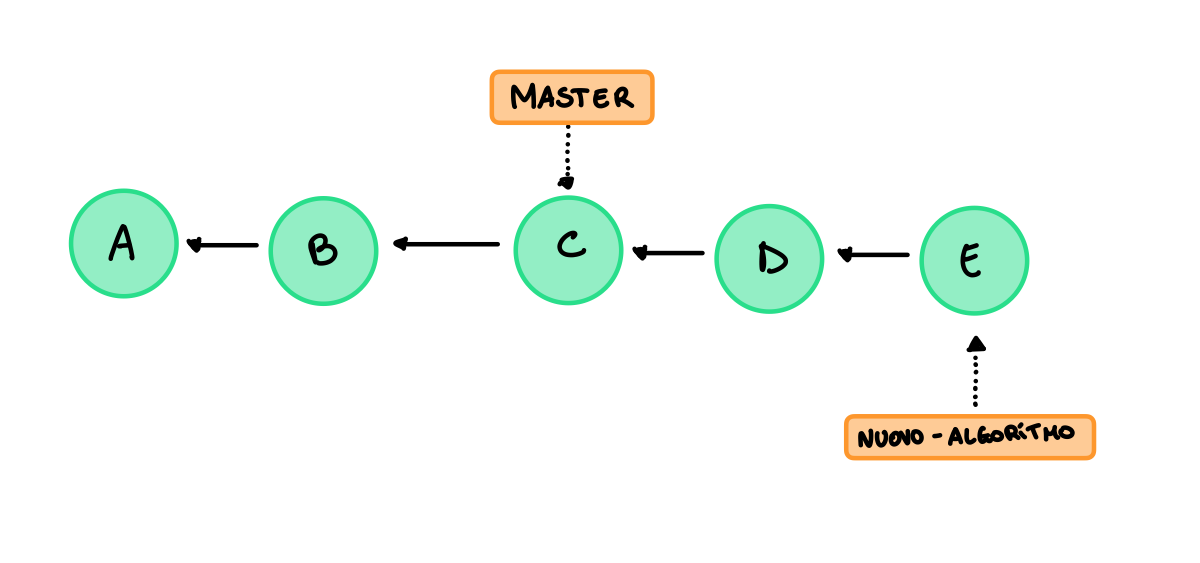
Effettuando un merge otteniamo questo:
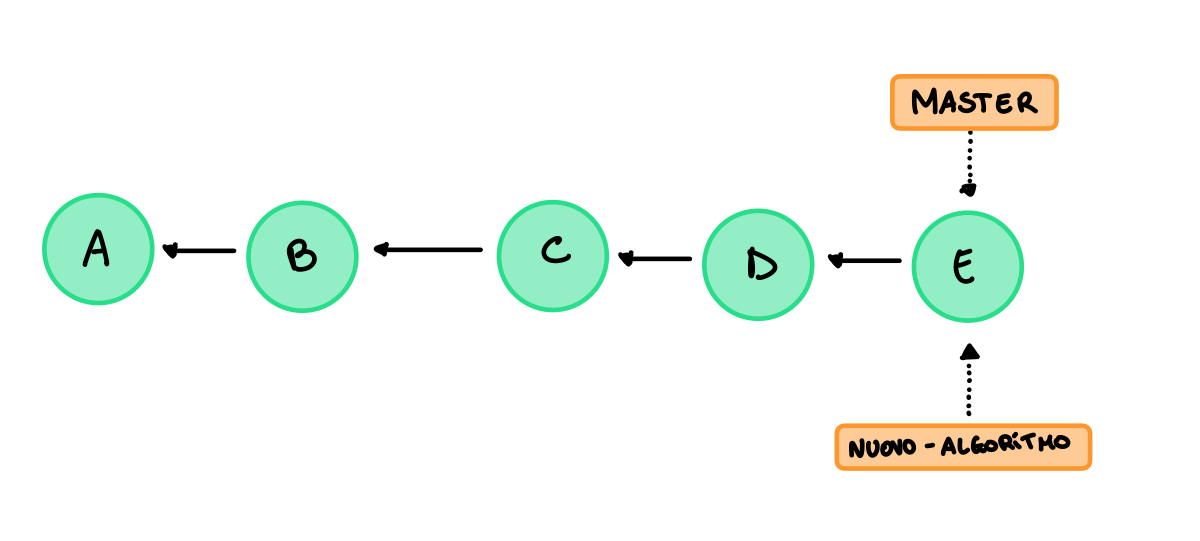
Abbiamo quindi effettuato il merge e possiamo anche rimuovere il branch nuovo-algoritmo dato che combacia con il master.
Non-Fast-Forward Strategy
Questa può essere applicata anche quando non abbiamo uno sviluppo lineare, questa richiede la creazione di un nuovo commit nel master che contiene i cambiamenti del branch con il quale vogliamo effettuare il merge. Per fare questo quindi il nuovo commit dovrà avere 2 padri: l’ultimo commit del master e l’ultimo commit del secondo branch, successivamente sposteremo il master su questo commit.
Se siamo in questa situazione e vogliamo effettuare il merge:
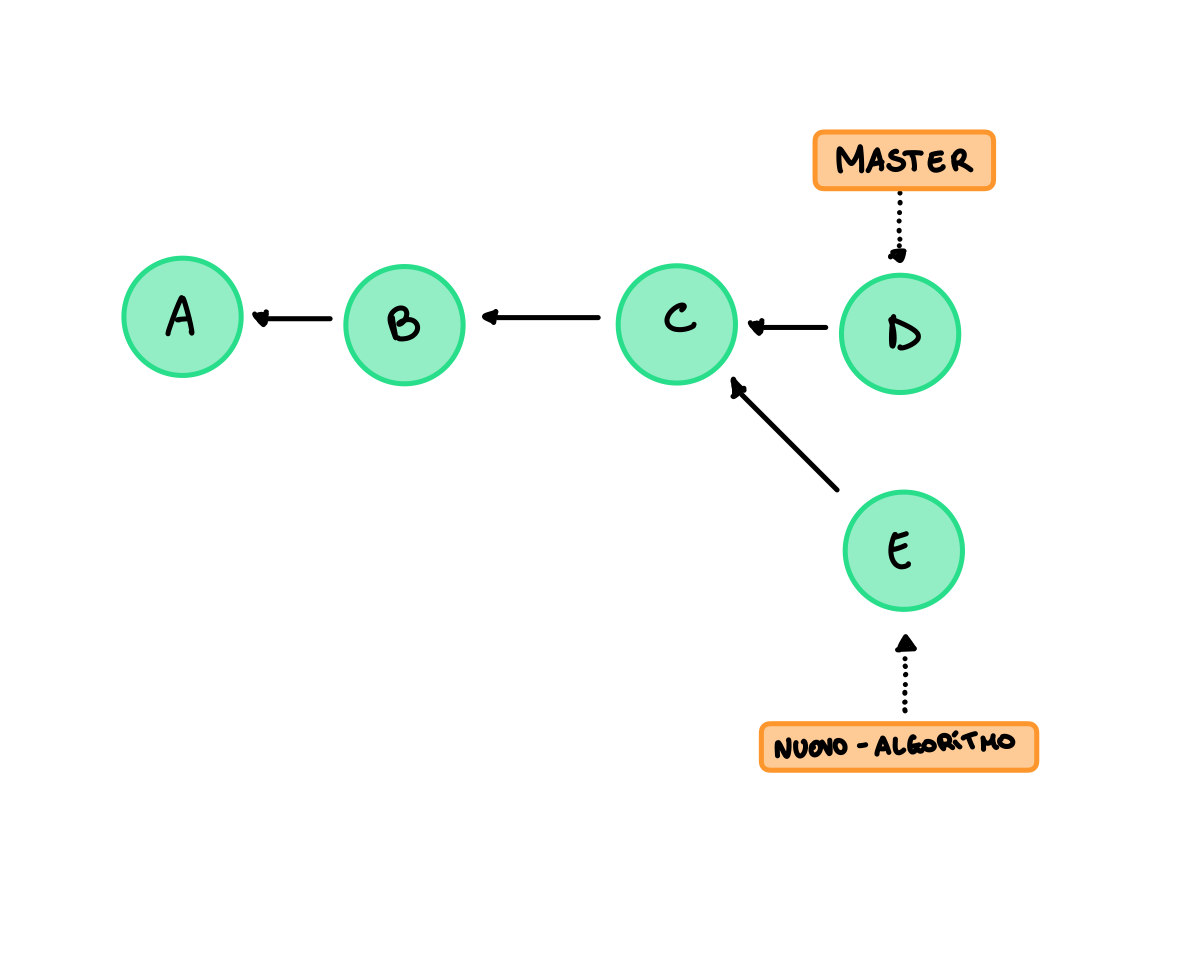
Dobbiamo creare un nuovo commit con i due padri e poi muovere il master:
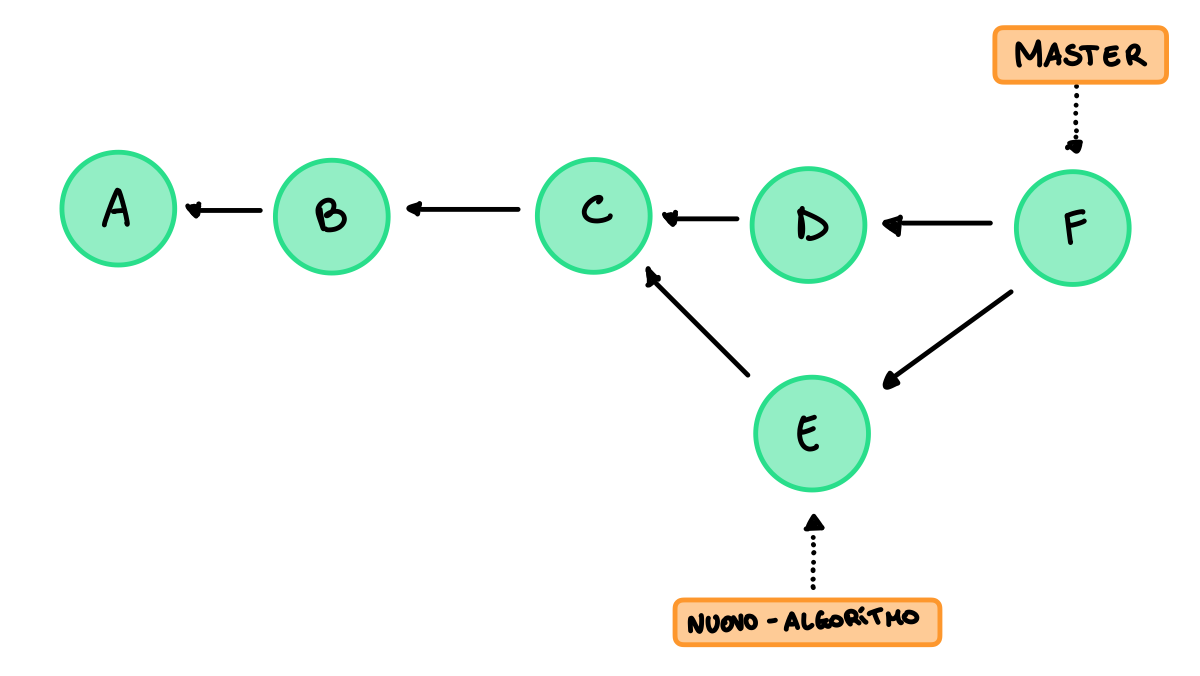
Una difficoltà che possiamo incontrare in questo tipo di merge sono i conflitti, vedremo più avanti come gestirli.
Rebase Strategy
L’idea per questo metodo è quella di modificare l’history della repository prima del merge in modo da renderla lineare per poi applicare la fast-forward. Per effettuare queste modifiche dobbiamo creare una copia di tutti i commits del nuovo branch che non sono in comune con il master, il primo commit copiato che non è in comune deve avere come padre l’ultimo commit del master, tutti i successivi lo seguiranno normalmente. Per visualizzare il rebase più seplicemente, è come se stessimo creando un nuovo branch a partire dall’ultimo commit del master e a questo stiamo aggiungendo tutti i commit contenuti nuovo branch.
Esempio, situazione iniziale:
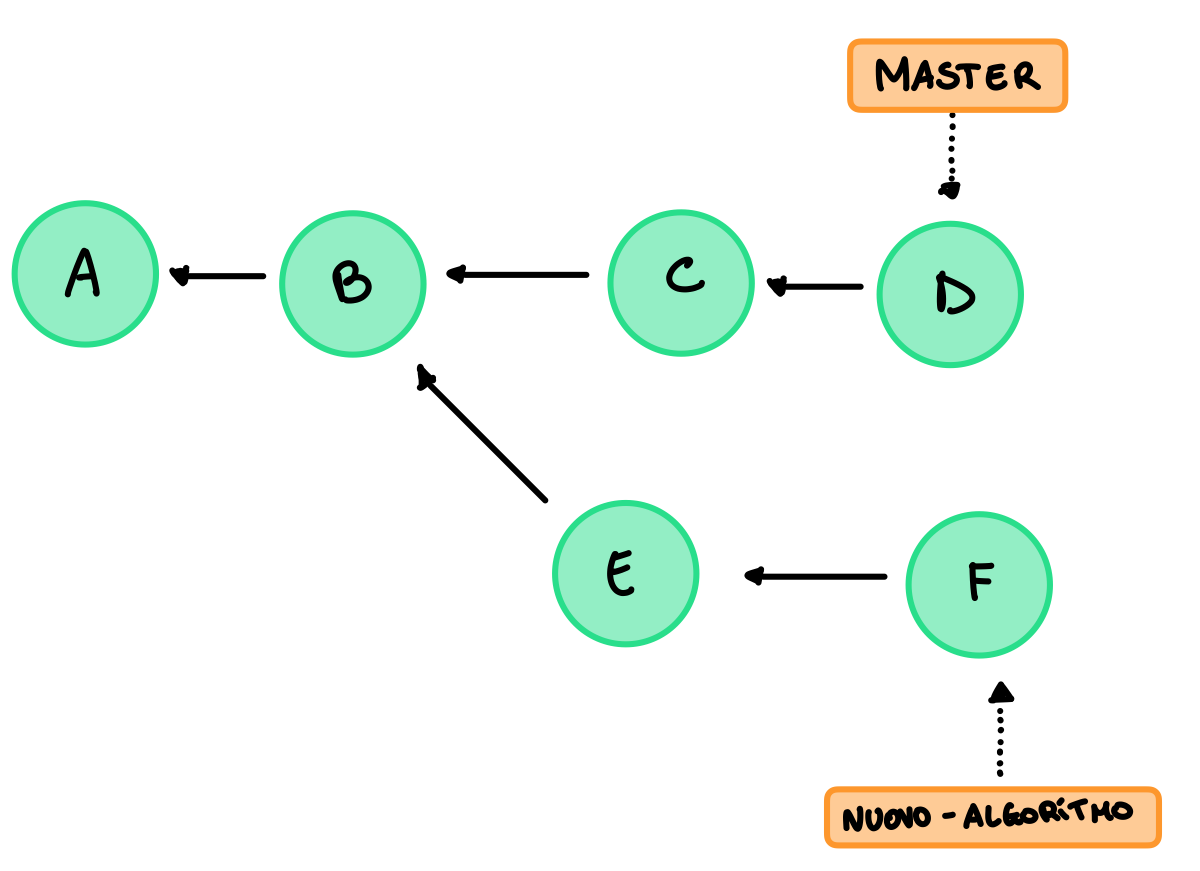
Per prima cosa quindi creiamo le copie dei commit non in comune con il master, quindi E ed F, ma a differenza degli originali E avrà come padre D, poi spostiamo il branch nuovo-algoritmo sulla copia di F e a questo punto possiamo applicare la fast-forward spostanto il master.
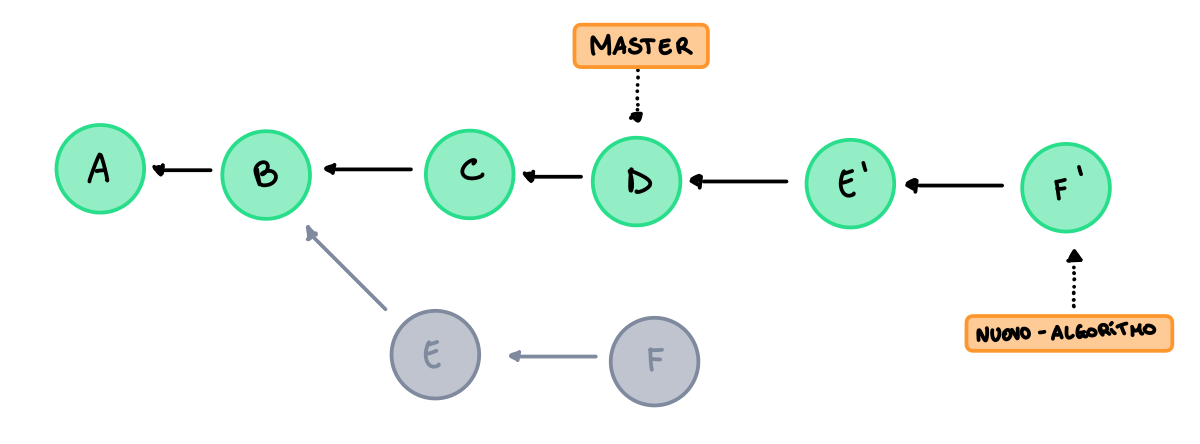
Anche questa strategia può causare conflitti.
Copie dei commits e Dangling commits
- Per i motivi detti prima, ovvero che ogni commit ha un proprio hash code, le due copie che abbiamo creato contengono si le stesse modifiche ma sono a tutti gli effetti due commit diversi dagli originali
- E ed F in questo caso non saranno più collegati a nessun branch dopo il merge (dangling commits) questo significa che verranno rimossi al prossimo garbage collection
Merge Conflicts
Come detto prima quando effettuiamo un merge di tipo non-forward o rebase, possono verificarsi situazioni dove lo stesso file viene modificato in entrambi i branches, in questo caso git prova ad effettuare il merge unendo le modifiche di entrambi i file, questo avviene senza problemi se le modifiche nel file sono distanti fra loro ma se ad esempio queste avvengono sulla stessa linea git non riesce ad effettuare il merge, otteniamo quindi un merge conflict. (un conflict può avvenire anche quando un file cambia in un branch ma viene eliminato in un altro).
Vediamo una situazione più reale come esempio, immaginiamo di avere questo file example.go
package main
import "fmt"
func main() {
fmt.Println("")
}La situazione della nostra repository è questa:
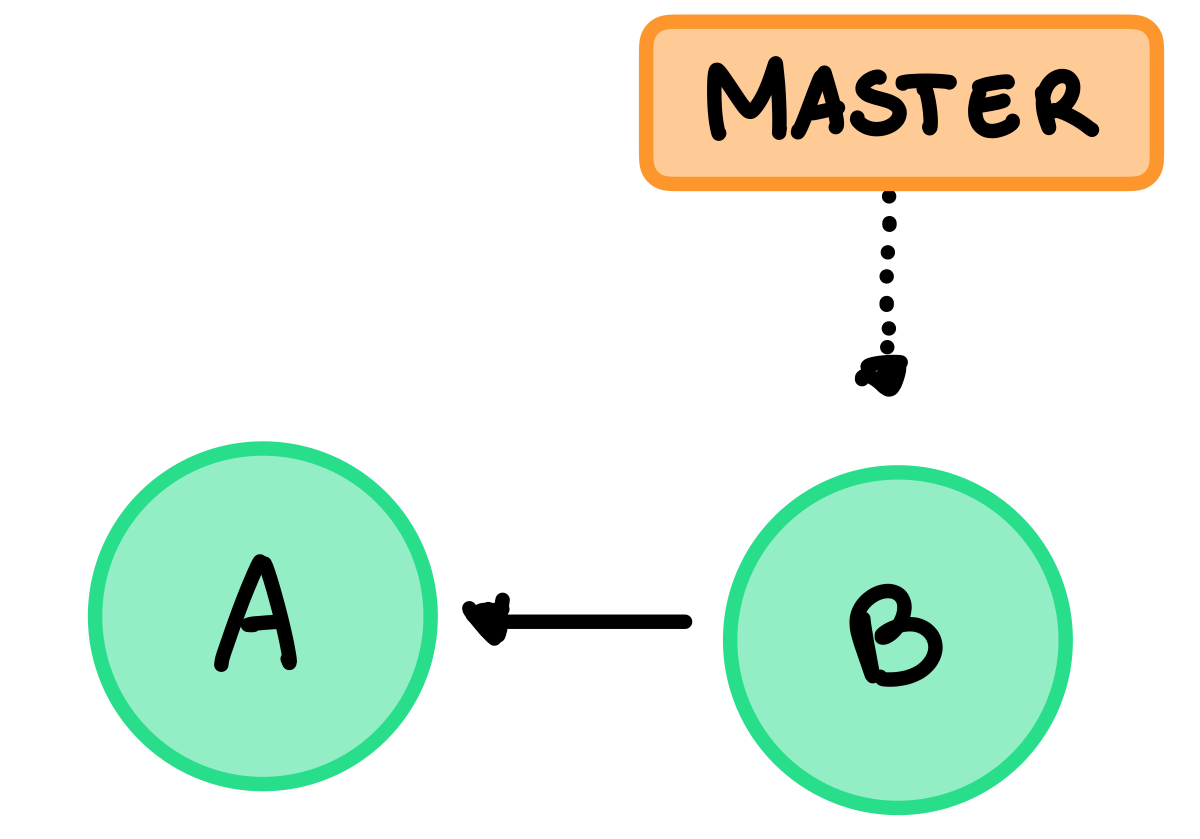
Adesso due diversi collaboratori, dev1 e dev2, effettuano delle modifiche in parallelo sulla stessa linea cambiano il messaggio da stampare.
Dev1 crea un nuovo commit in un nuovo branch dev1-add-text e rimpiazza fmt.Println("") con fmt.Println("hello!"), otteniamo quindi:
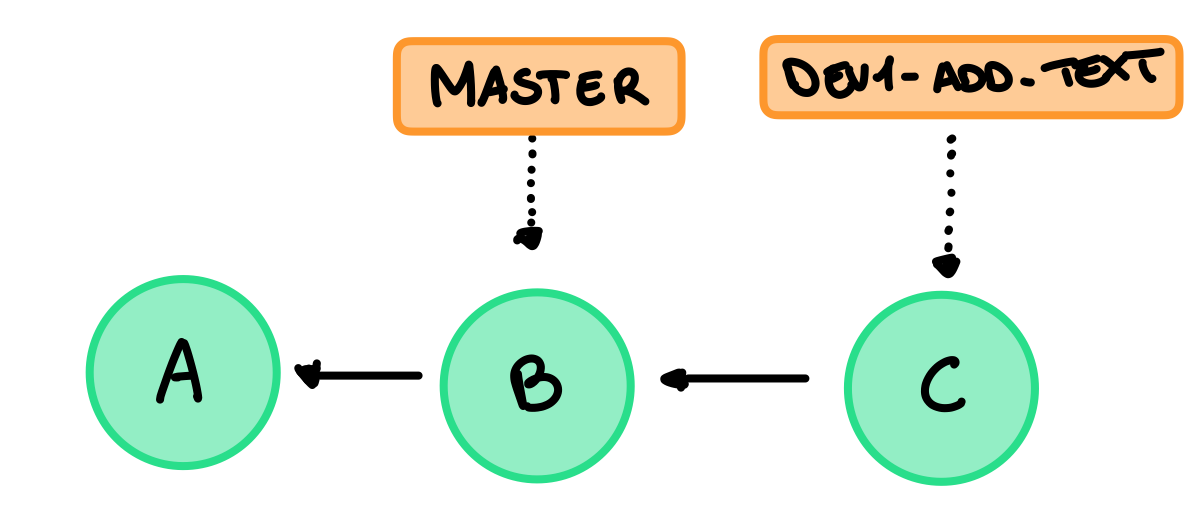
A questo punto possiamo facilmente effettuare un merge e spostare il master su C.
Nello stesso momento però dev2 modifica il file creando un nuovo commit in un nuovo branch cambiando la riga di codice in fmt.Println("world"), adesso siamo in questa situazione:
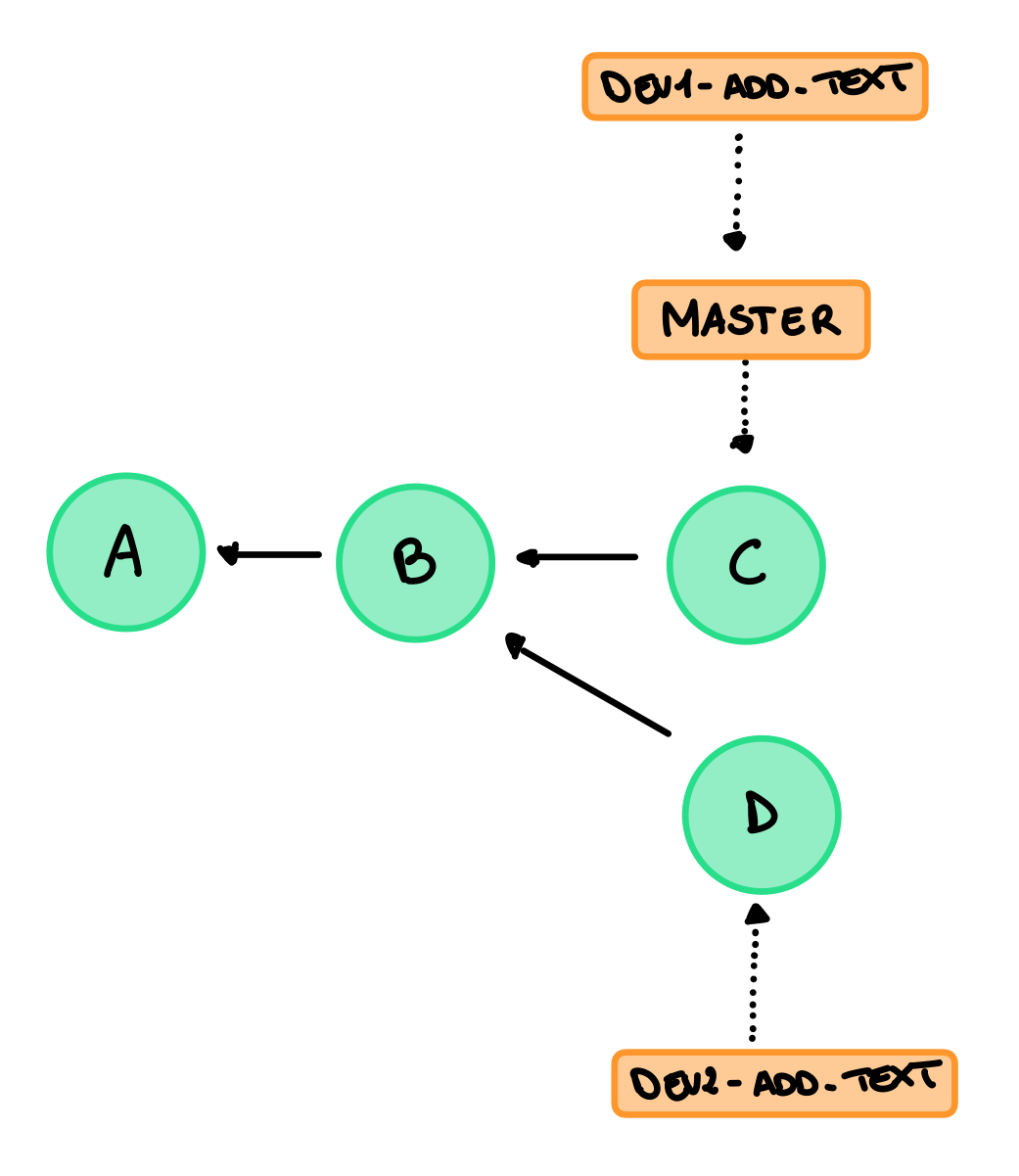
Adesso abbiamo un conflitto, possiamo applicare la non-fast-forward ma git non riuscirebbe ad effettuare il merge. Dobbiamo intervenire noi. Quando avviene un conflict git ce lo farà notare e ci darà una descrizione dello stato corrente e del conflitto, infatti se andiamo ad aprire il file interessato vedremo qualcosa di simile:
package main
import "fmt"
func main() {
<<<<<< HEAD
fmt.Println("")
======
fmt.Println("world")
>>>>>> dev2-add-text
}Dato che il file è stato modificato git aggiunge entrambe le linee all’interno del blocco. Nella prima parte abbiamo la linea che si trova nell’HEAD, che nell’esempio precedente corrisponde a C ovvero il master; mentre nella seconda parte abbiamo la linea presente nel branch dev2-add-text.
Abbiamo 3 modi per risolvere un conflict:
- Possiamo mantenere il file di cui è già stato effettuato il merge dal dev1, in questo caso dobbiamo dire a git di accettare la versione ours.
- Possiamo usare il nuovo file dal dev2 dicendo a git di accettare la versione theirs.
- Editiamo il file manualmente. Le prime due opzioni sono implementate in git tramite dei comandi mentre per la terza dobbiamo aprire noi il file e modificarlo. Se vogliamo seguire la terza strada ci basta entrare nel file, rimuovere il blocco di git e scrivere la giusta linea che desideriamo.
package main
import "fmt"
func main() {
fmt.Println("hello world!")
}A questo punto possiamo aggiungere il file alla staging area e continuare con il merge.
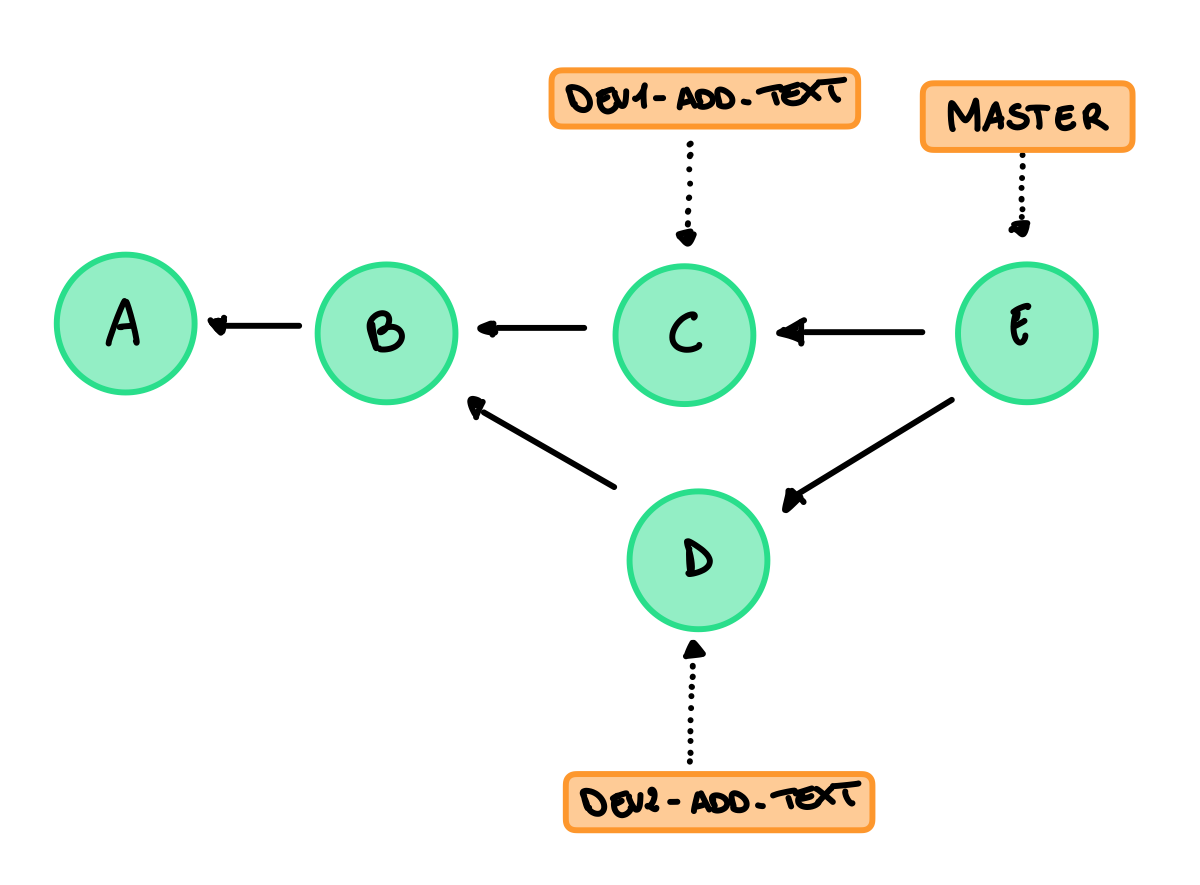
Pausa del merge
Il commit E è stato creato durante il merge indipendentemente dal conflict, git una volta rilevato il conflitto si ferma per sapere come risolvere il conflitto e continuare. Quindi nel nostro esempio è stato creato E, poi git si è fermato, abbiamo scelto di modificare manualmente il file che è stato aggiunto ad E e successivamente è stato ripreso il merge portando il master su E.
Remote Git Repositories
Git può inviare e ricevere commits, tags o branches da host non locali come server esterni, questi vengono identificati da un URL e un nome e prendono il nome di remotes. Il remote di default si chiama origin, ma possiamo chiamarlo anche in altri modi. Quando git scarica i file dai remotes, li copia nella nostra repository locale, l’unica cosa che cambia è il nome dei branches che adesso contiene un prefisso che ci indica il remote dal quale proviene, ad esempio il master del remote origin si chiama origin/master. Questi prefissi servono a git per tenere traccia dello stato dei remotes, infatti non possiamo creare dei commit in un branch collegato ad un remote dato che servono soltanto per “tenere traccia”. Per farlo dobbiamo creare un branch locale collegato al branch del remote.
Vedremo successivamente questi collegamenti, adesso vediamo i comandi principali di git per la sincronizzazione fra diversi computer.
Clone
Con clone indichiamo il download di una repository da un remote, questo crea appunto una copia locale della repository nel nostro PC, lURL sarà il nostro origin remote e di default l’HEAD sarà uguale a quello del remote. Vediamo meglio con un esempio, questa è la repository presente nel remote:
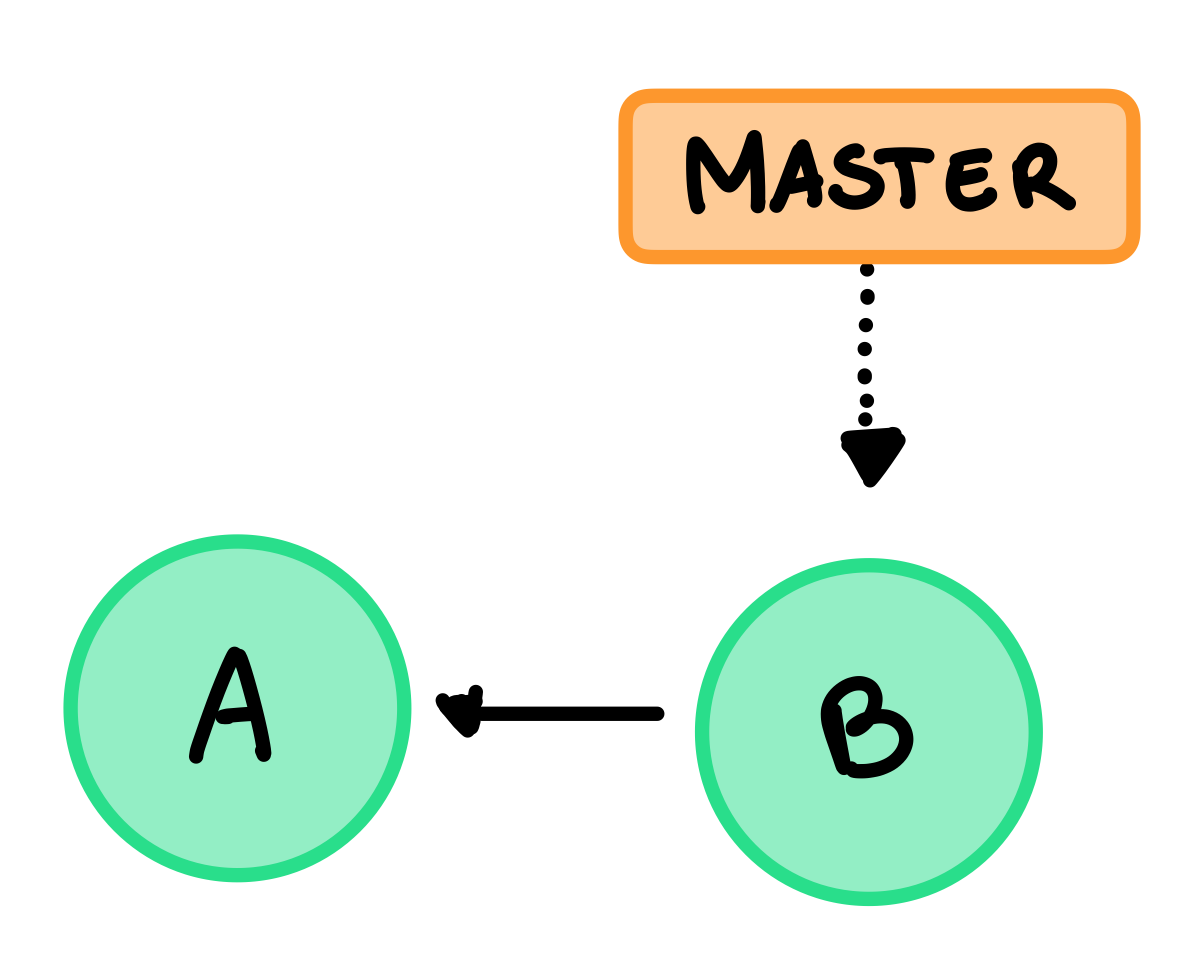
Eseguendo un clone scarichiamo tutti i commits e i branches e git creerà un master locale che corrisponde a quello del remote e imposterà l’HEAD locale uguale a quello remote. Otteniamo quindi:
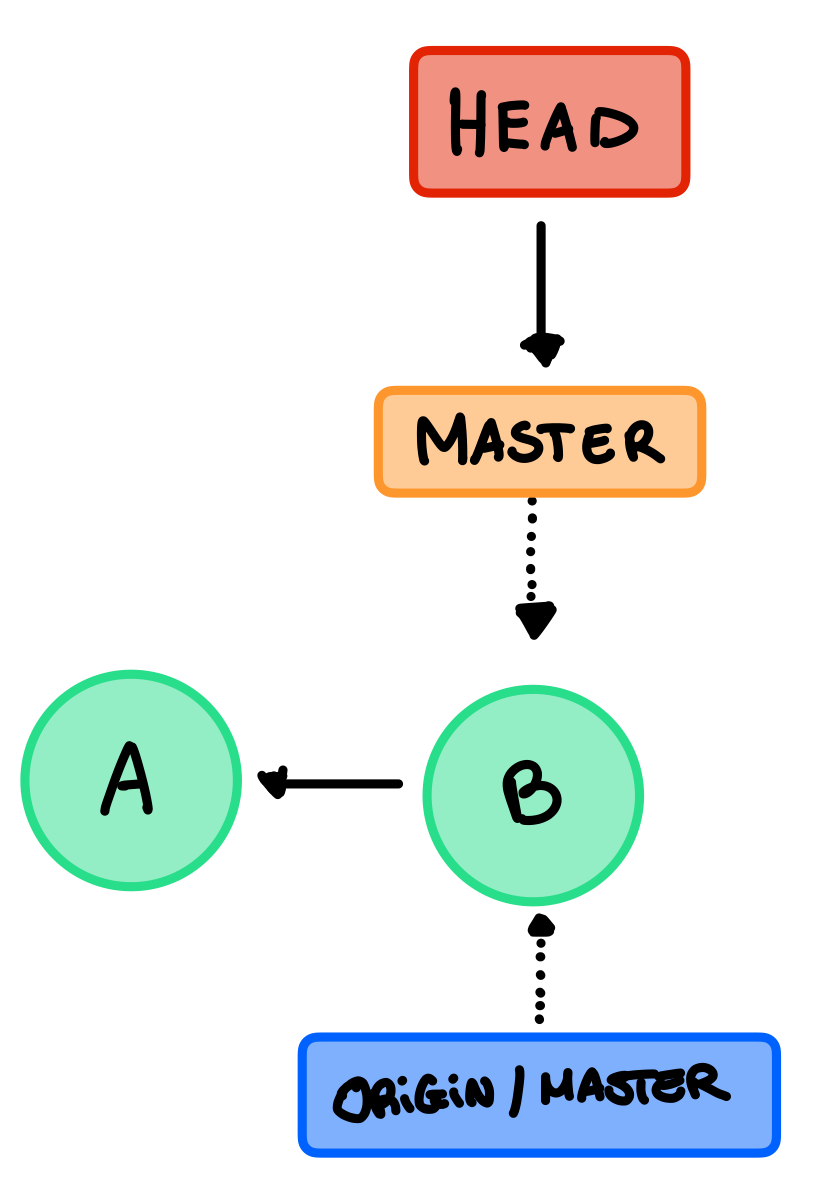
Push
Utilizziamo push per aggiornare i branches remoti, inviamo quindi il nostro branch al remote. Se il nostro branch proviene dal branch remoto allora quello remoto viene aggiornato alla stessa posizione del locale, se il branch remoto non esiste allora viene creato. I nuovi commits che non erano presenti sul remote vengono inviati automaticamente.
Immaginiamo di avere questa repository in origin:
E in locale dopo aver clonato la precedente abbiamo ottenuto questa:
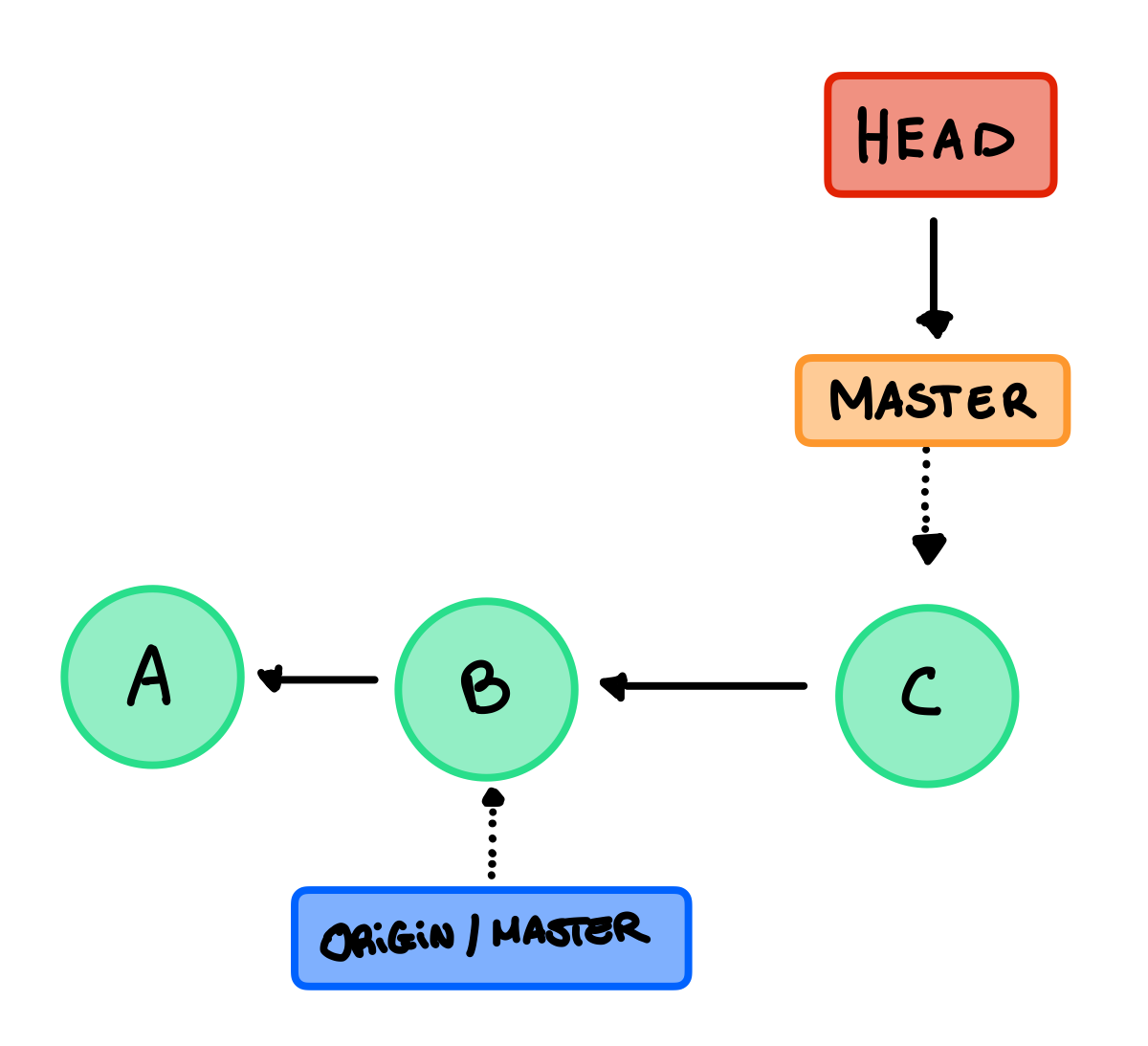
Dopo aver creato C abbiamo spostato il master e l’HEAD ma soltanto in locale, quelli del remote sono rimasti allo stato precedente, quindi se inviamo un push otteniamo sia in locale che nel remote questa situazione:
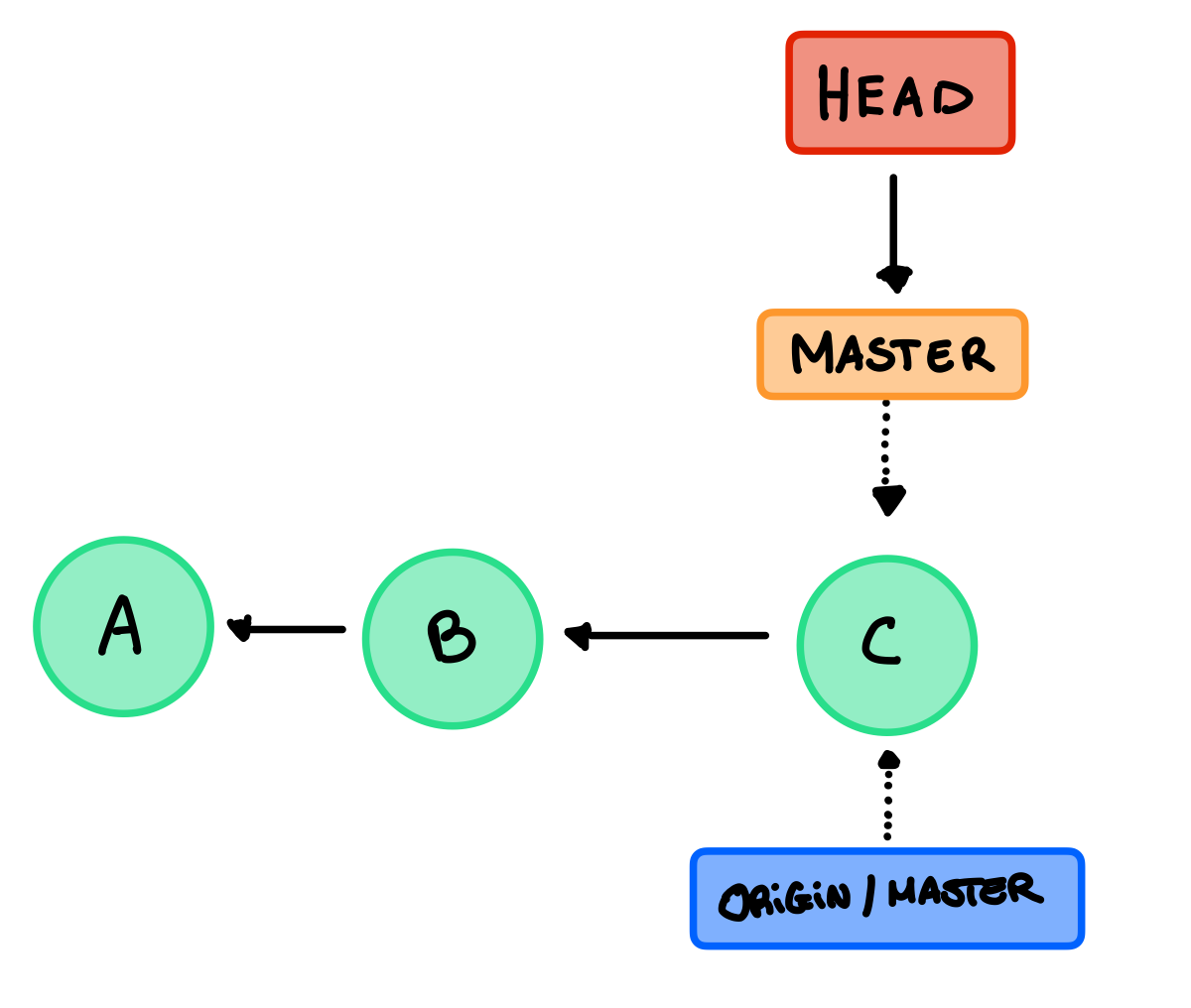
Fetch
Il fetch sincronizza branches e tag remoti nella repository locale, questo aggiorna soltanto quelli provenienti dal remote, gli altri rimangono uguali, infatti se nella nostra repository abbiamo un master locale e un origin/master verrà aggiornato soltanto il origin/master. Verrano quindi scaricati anche tutti i commits.
Vediamo un esempio, nel remote origin abbiamo questo:
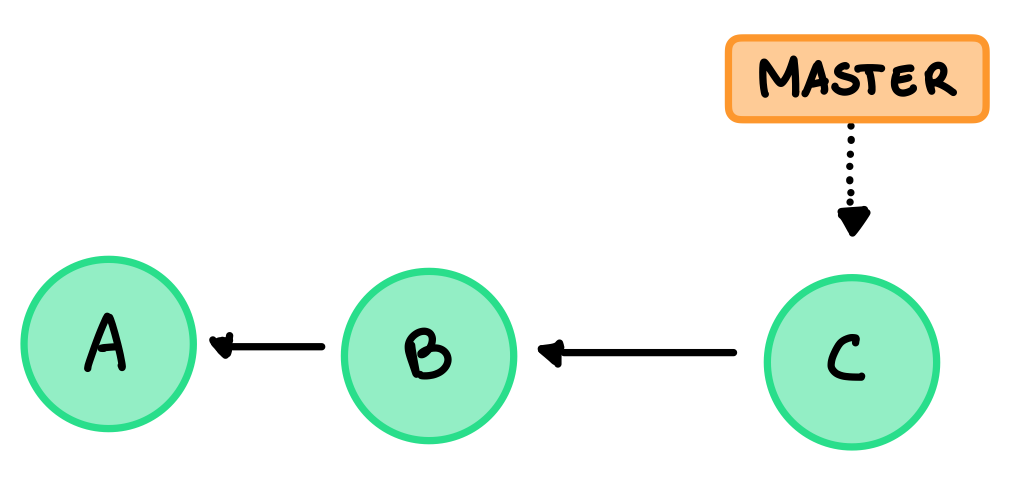
La nostra repository locale è meno aggiornata, non abbiamo il commit C e il master sta puntando a B, nella locale anche il origin/master sta ancora puntando a C dato che non sa che la remote è cambiata. Quindi nella locale abbiamo questa situazione:
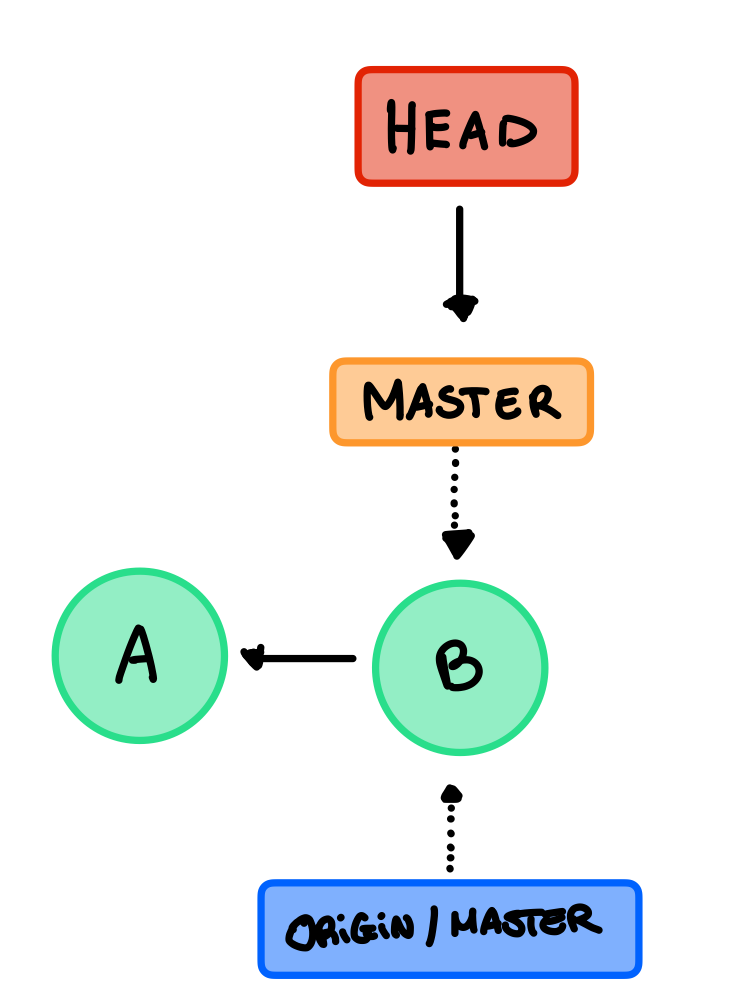
Se eseguiamo un fetch otteniamo questo:
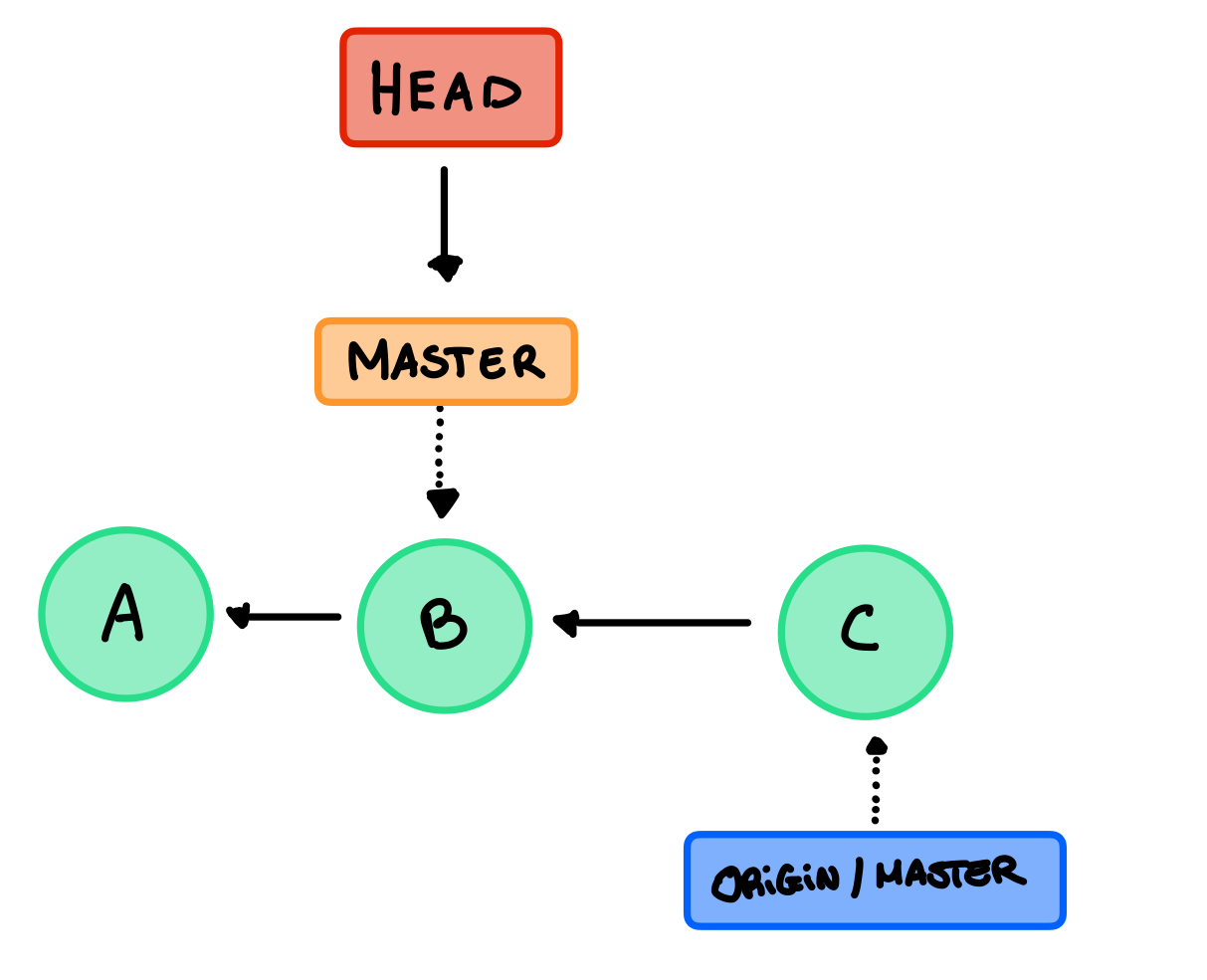
Possiamo controllare questo nuovo commit dato che adesso si trova nella nostra repository locale ma il nostro master rimane ancora su B. Notiamo subito però che possiamo eseguire un merge fast-forward per spostare il master su C, dato che questa operazione è molto comune git ci fornisce un comando specifico, il pull.
Sincronizzazione
Per effettuare questo merge ovviamente possiamo utilizzare anche altre strategie soprattutto quando il remote e il locale non proseguono in modo lineare, questo può accadere quando creiamo un nuovo commit prima di sincronizzare la repository con il remote ottenendo molto probabilmente dei conflitti. È suggerito infatti di eseguire spesso fetch e pull soprattutto prima di iniziare a modificare i file, un altro consiglio è anche quello di non lavorare insieme a più persone sullo stesso branch.
Pull
Di solito si eseguono fetch e pull insieme dato che vogliamo aggiornare la nostra copia locale prima di metterci a lavoro, per questo il pull esegue automaticamente fetch e merge.
Esempio più complesso di una repository
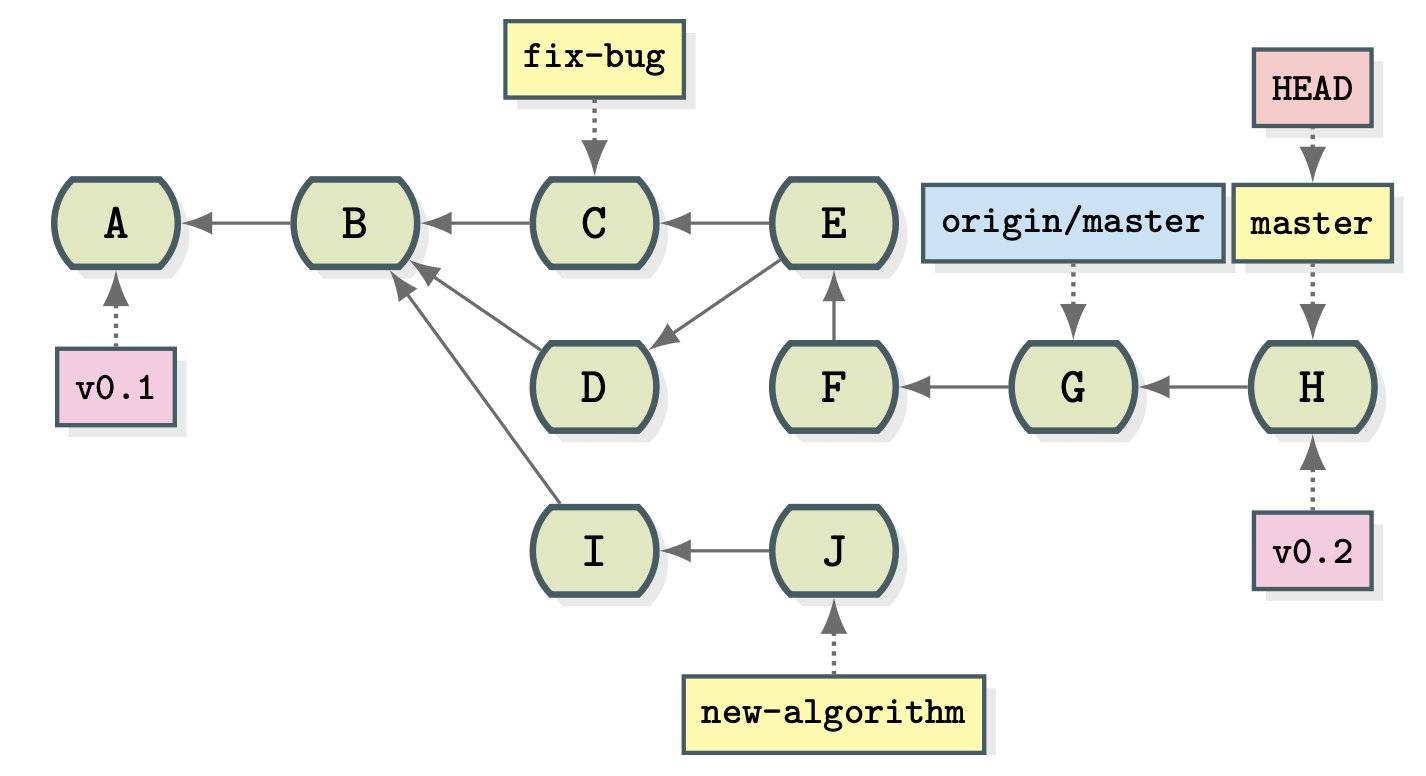
In questo caso abbiamo:
- A è la root della nostra repository, il primo commit ed ha il tag come versione 0.1
- A e B sono condivisi da tutti i Branches.
- C è condiviso da fix-bug e master ma il master contiene anche D, E, F, G, H che è anche la versione 0.2 e l’HEAD corrente
- new-algorithm contiene A, B, I, J
- Il master presente sul remote origin è fermo al commit G precedente al master locale.
Git repository Hosting
Per “hostare” le nostre repository possiamo utilizzare app esterne che ci offrono anche strumenti aggiuntivi, queste vengono chiamate forges, alcuni esempi possono essere GitLab, GitHub, BitBucket e Gitea.
Issues
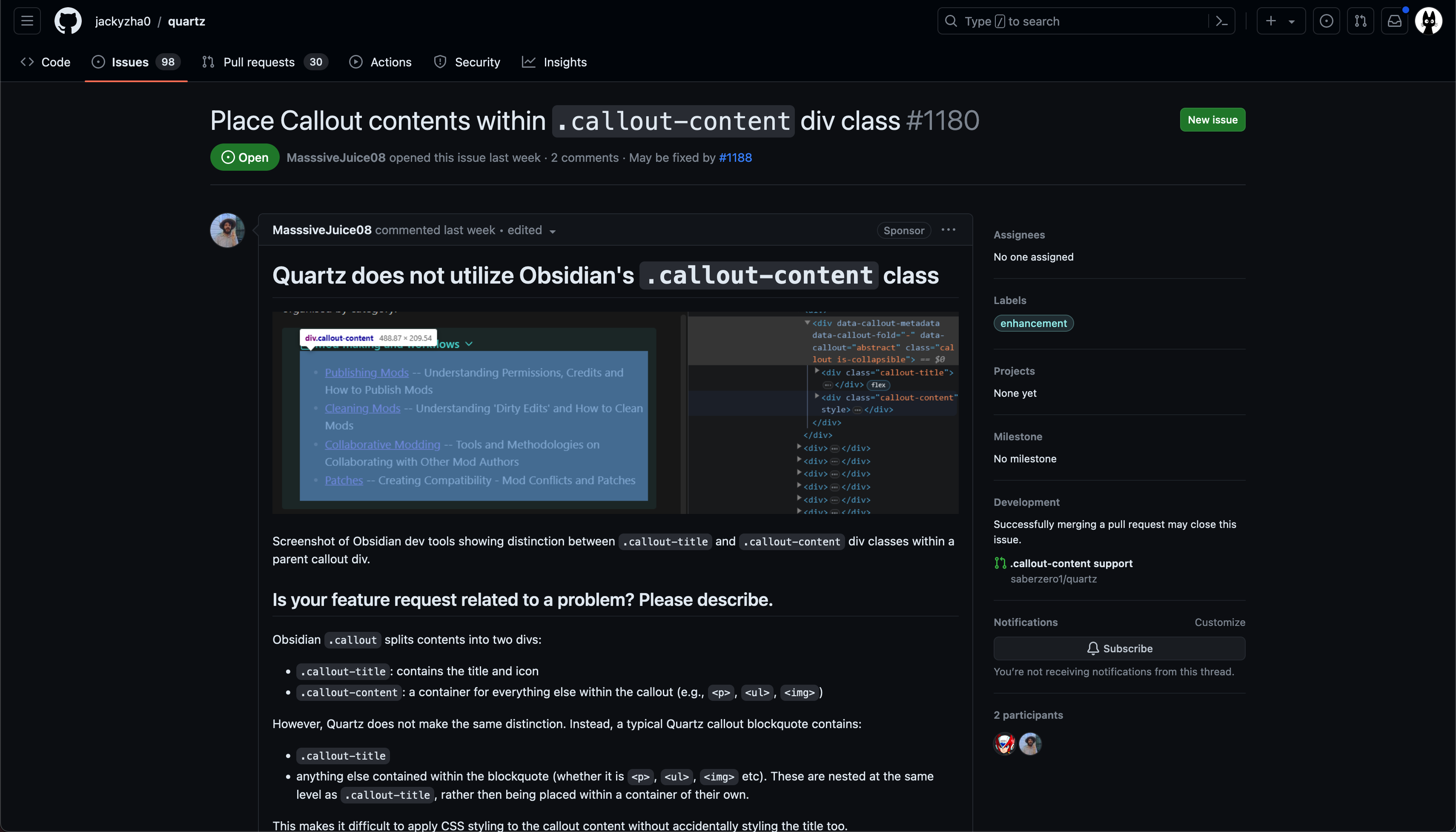
Queste applicazioni possono aiutarci a tenere traccia dei bug o problemi nel nostro progetto creando degli issues, questi possono essere creati anche da utenti esterni per richiedere ad esempio l’aggiunta di funzionalità. Quando ne viene creato uno dobbiamo fornire un titolo e una descrizione del problema, una volta fatto gli verrà assegnato lo stato open. Successivamente, quando il problema verrà risolto o la feature è stata aggiunta gli verrà assegnato lo stato closed; molte applicazioni forniscono anche stati aggiuntivi per descrivere al meglio lo stato. Gli issues hanno anche delle labels per organizzarli ma anche deadline e milestone (una versione futura dell’app).
Esempio di issue su GitHub
Forks
Non possiamo inviare commits o branches a repository non nostre, ma i proprietari possono accettare pull o merge request (che vedremo avanti). Oppure è possibile creare la nostra versione del codice per applicare alcune modifiche non accettate dagli autori, quindi basandoci sull’originale possiamo creare la nostra versione modificata, questa viene chiamata fork.
Prima di effettuare un fork o modificare il codice in generale è meglio controllare la licenza del codice, in alcuni casi anche se il codice è pubblico è vietato effettuare alcune azioni su di esso.
Quindi quando creiamo un fork, il forge che stiamo utilizzando creerà sul nostro account una repository copia dell’originale nella quale potremmo effettuare tutte le modifiche che vogliamo.
Pull / Merge requests
Se abbiamo un fork o un branch per il quale dobbiamo effettuare il merge in una repository ma non abbiamo il permesso per farlo possiamo effettuare una pull request o chiamata anche merge request. Questa quindi è una nostra richiesta di effettuare il merge del nostro codice nella repository originale, questa hanno le stesse caratteristiche degli issues quindi nome, descrizione, labels, e altro. Ci mostrano anche le differenze con il codice originale e possiamo commentarlo o fare domande (o ci possono fare domande). Se questa viene accettata viene effettuato il merge e viene chiusa, ma può anche essere chiusa senza aver effettuato il merge.
Practical Git
Configurazione Iniziale di git
Chiameremo il primo branch master anche se fatto di default (quindi non serve farlo):
git config --global init.defaultBranch masterPoi dobbiamo impostare un nome utente e una mail per il nostro profilo, questi verranno mostrati quando effettuiamo azioni.
git config --global user.name "Nome"
git config --global user.email "il@tuo.indirizzo"Creare repository locale
Ci posizioniamo nella cartella in cui vogliamo creare la repository ed eseguiamo:
git initGit creerà la sua cartella .git per salvare i file che gli servono, per ora lasciamola così.
La nostra repository ora è vuota, per vedere lo stato corrente possiamo eseguire
git statusQuesto ci fornirà come output:
On branch master
No commits yet
nothing to commit (create / copy files and use "git add" to track)Il primo commit
Per creare il commit dobbiamo prima avere qualcosa su cui effettuarlo, possiamo creare un file, inquesto caso english.txt che contiene Hello world.
Una volta creato questo non farà parte della stagin area e quindi git non ne terrà traccia, infatti eseguendo di nuovo git status avremo la lista degli elementi non tracciati.
Per aggiungere il file eseguiamo:
git add english.txtSuccessivamente eseguiamo il commit cont con:
git commit -m "Aggiunto file di testo"Ci verranno fornite alcune informazioni come il branch in cui lo abbiamo effettuato e il suo ID, in questo caso abbiamo creato un root-commit o commit orfano, infatti è il primo della repository.
Il flag -m per il messaggio serve appunto per spiegare cosa è stato fatto, questo è richiesto da git, se lo omettiamo ci verrà aperto un editor di testo per modificare il messaggio predefinito.
Se adesso eseguiamo un log possiamo vedere alcune informazioni sul nostro commit, come autore, data, branch ecc…
git log
commit 0a35df923534dbafa5bfaa225b2731e04e2ce3f8 (HEAD -> master)
Author: alem <email@email.email>
Date: Tue Jun 11 12:00:29 2024 +0200
Aggiunto file di testoSpostarsi tra i commits
Per spostarsi fra i commits prima abbiamo bisogno di più commits, quindi creiamone altri.
In questo caso aggiungiamo in due commit separati, i file italian.txt e german.txt.
Controlliamo quindi i log:
git log
commit 8d5e099663ba92acffd33bc98647ebcc81bb5385 (HEAD -> master)
Author: Alessio Marini <marini.alessio1105@gmail.com>
Date: Tue Jun 11 13:23:11 2024 +0200
Aggiunto file tedesco
commit 1d4e38db82c8db1563e0157bd98746c669bc3d1f
Author: Alessio Marini <marini.alessio1105@gmail.com>
Date: Tue Jun 11 13:22:02 2024 +0200
Aggiunto file italiano
commit 0a35df923534dbafa5bfaa225b2731e04e2ce3f8
Author: Alessio Marini <marini.alessio1105@gmail.com>
Date: Tue Jun 11 12:00:29 2024 +0200
Aggiunto file di testoQuindi abbiamo 3 commits, l’ultimo del master è anche il nostro HEAD. Se volessimo tornare indietro al commit “Aggiunto file italiano” dobbiamo usare checkout.
git checkout 1d4e38d
Nota: eseguo il checkout di '1d4e38d'.
Sei nello stato 'HEAD scollegato'. Puoi dare un'occhiata, apportare modifiche
sperimentali ed eseguirne il commit, e puoi scartare qualunque commit eseguito
in questo stato senza che ciò abbia alcuna influenza sugli altri branch tornando
su un branch.
Se vuoi creare un nuovo branch per mantenere i commit creati, puoi farlo
(ora o in seguito) usando l'opzione -c con il comando switch. Ad esempio:
git switch -c <nome nuovo branch>
Oppure puoi annullare quest'operazione con:
git switch -
Disattiva questo consiglio impostando la variabile di configurazione
advice.detachedHead a false
HEAD si trova ora a 1d4e38d Aggiunto file italianoAdesso ci troviamo nello stato detached HEAD e git ci suggerisce di creare un branch se vogliamo mantenere i commits. Inolte git ci suggerisce di usare switch che è una nuova versione di checkout, per ora continuiamo con checkout.
Anche eseguendo status ci verrà notificano che siamo in HEAD scollegato:
git status
HEAD scollegato su 1d4e38d
non c'è nulla di cui eseguire il commit, l'albero di lavoro è pulitoEd eseguendo log:
git log
commit 1d4e38db82c8db1563e0157bd98746c669bc3d1f (HEAD)
Author: Alessio Marini <marini.alessio1105@gmail.com>
Date: Tue Jun 11 13:22:02 2024 +0200
Aggiunto file italiano
commit 0a35df923534dbafa5bfaa225b2731e04e2ce3f8
Author: Alessio Marini <marini.alessio1105@gmail.com>
Date: Tue Jun 11 12:00:29 2024 +0200
Aggiunto file di testoNotiamo che abbiamo soltanto 2 commits e che il nostro HEAD non corrisponde a nessun branch, se vogliamo vedere anche il branch eseguiamo git log master.
Inoltre dato che l’HEAD non si trova sull’ultimo commit è come se ci trovassimo alla versione precedente del codice, infatti se guardiamo la cartella il file german.txt non sarà presente.
Possiamo vedere le differenze tra due commit con il comando git diff <primoCommit> <secondoCommit>:
git diff 0a35df9 1d4e38d
diff --git a/italian.txt b/italian.txt
new file mode 100644
index 0000000..abb27dc
--- /dev/null
+++ b/italian.txt
@@ -0,0 +1 @@
+Ciao mondoStiamo vedendo quindi le differenze fra il primo e il secondo commit, come leggiamo questo output?
- L’ordine degli ID è importante, il primo che inseriamo è la situazione precedente, quindi ad esempio una linea aggiunta significa che non era presente nel primo ma nel secondo si.
- La riga
diff --git....ci indica in che file è presente la differenza New file modeindica che il file ha un nuovo set di permessi.Indexci indica i due indici per il file, tutti 0 indica che il file non esisteva mentre la stringa successiva è il suo nuovo indice.---Indica che sono state rimosse linee ai file seguenti, in questo caso /dev/null indica un file non esistente.+++b/italian.txt indica che tutte le linee seguenti che iniziano con + sono all’interno del file italian.txt.@@ -0,0 +1 @@è il “contesto” per le differenze (linea 0 per il file precedente e linea 0 per il futuro, 1 linea è stata aggiunta).- Infine ci viene mostrato il file, quindi linee con + sono state aggiunte e linee con - sono quelle rimosse da commit futuri.
Spostarsi fra i branches
Adesso che che ci troviamo in una situazione di HEAD scollegato, torniamo al master con git checkout master. Per spostarsi, come nel caso dei commits, abbiamo bisogno di più branches quindi creiamo il branch experiment.
git branch experimentQuindi adesso guardando il log (prendiamo solo ultima riga):
git log
commit 8d5e099663ba92acffd33bc98647ebcc81bb5385 (HEAD -> master, experiment)
Author: Alessio Marini <marini.alessio1105@gmail.com>
Date: Tue Jun 11 13:23:11 2024 +0200
Aggiunto file tedescoAdesso abbiamo due branch ma il nostro HEAD sta puntando al master quindi qualsiasi commit faremo verrà aggiunto a questo. Spostiamoci quindi su experiment con il comando checkout
git checkout experimentAggiungiamo quindi un commit ad experiment, ad esempio il file spanish.txt, guardando le ultime righe del log:
git log
commit b28fc045d0253be7dba8117f0b602c832f3c72d0 (HEAD -> experiment)
Author: Alessio Marini <marini.alessio1105@gmail.com>
Date: Tue Jun 11 14:32:42 2024 +0200
Aggiunto file spagnolo
commit 8d5e099663ba92acffd33bc98647ebcc81bb5385 (master)
Author: Alessio Marini <marini.alessio1105@gmail.com>
Date: Tue Jun 11 13:23:11 2024 +0200
Aggiunto file tedescoAbbiamo l’HEAD un commit più avanti del master e sta puntando al branch experiment. Possiamo tornare indietro al master con checkout. Per vedere tutti i commit nel log e non solo quelli fino all’HEAD dobbiamo aggiungere il flag —all.
Merge di experiment (FAST FORWARD)
Adesso vogliamo effettuare il merge di experiment nel master, per fare questo assicuriamoci di avere l’HEAD che punta al master. A questo punto possiamo effettuare un merge:
git merge --ff experiment
Aggiornamento di 8d5e099..b28fc04
Fast-forward
spanish.txt | 1 +
1 file changed, 1 insertion(+)
create mode 100644 spanish.txtCon il flag —ff abbiamo “forzato” Git ad utilizzare il fast-forward e abbiamo quindi spostato l’HEAD sul branch experiment insieme anche al branch master. A questo punto possiamo anche eliminare il branch experiment con:
git branch -d experimentSe cancelliamo un branch con il quale non abbiamo effettuato un merge, Git ci avviserà che perderemo tutti i commit presenti in quel singolo branch.
Non fast-forward merge
Adesso creiamo due branch paralleli e proviamo ad effettuare un merge con la strategy non-fast-forward.
git branch dev1
git checkout dev1
rm spanish.txt
git add spanish.txt
git commit -m "Rimosso file spagnolo"
[dev1 6569f20] Rimosso file spagnolo
1 file changed, 1 deletion(-)
delete mode 100644 spanish.txtAdesso torniamo sul master e creiamo un altro branch con un commit chiamato dev2 dove togliamo il file german.txt. Adesso ci troviamo in una situazione simile:
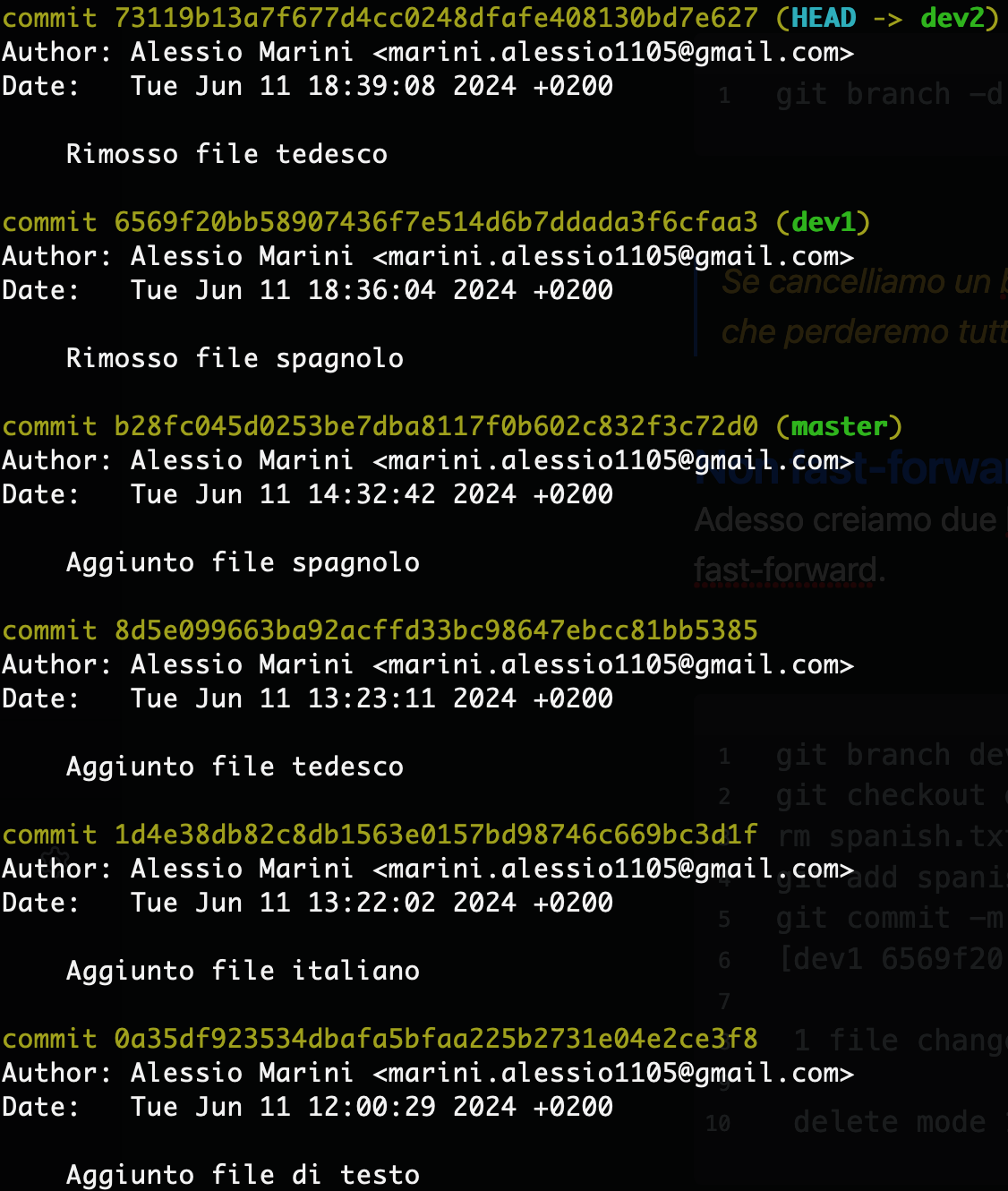
Adesso possiamo effettuare una fast-forward sul dev1, in questo modo git ci avviserà che è stato rimosso il file spanish.txt. Adesso procediamo con una non-fast-forward per il dev2.
git merge --no-ff dev2 -m "Merge branch dev2"Dobbiamo aggiungere anche un messaggio dato che abbiamo bisogno di un commit per effettuarla. Questa è la situazione di adesso, abbiamo un nuovo commit come master:
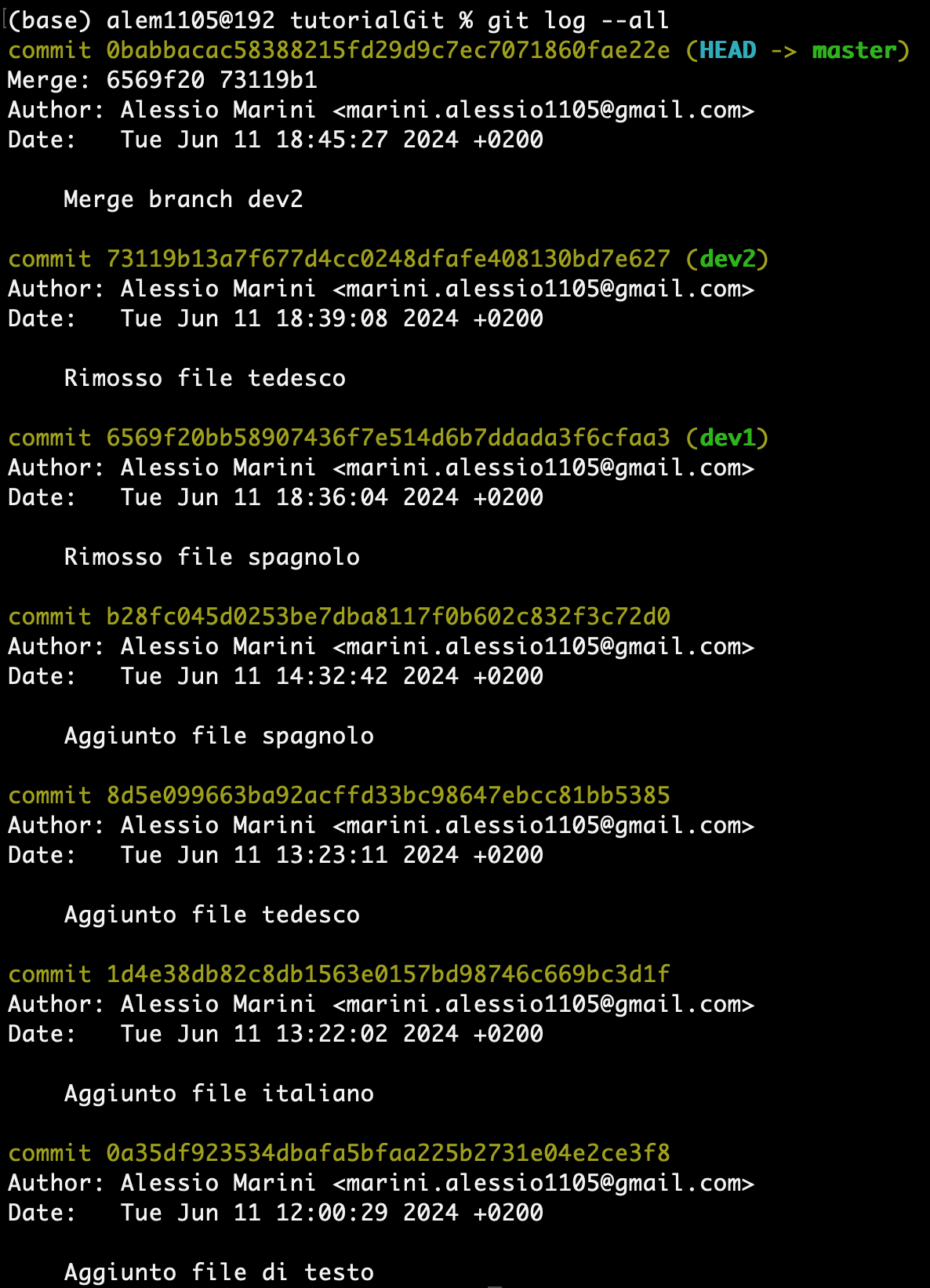
Conflicts
Codice presente in diversi branches potrebbe causare conflitti, creiamo due branches con dei conflitti e vediamo cosa succede.
Siamo in una situazione come questa:
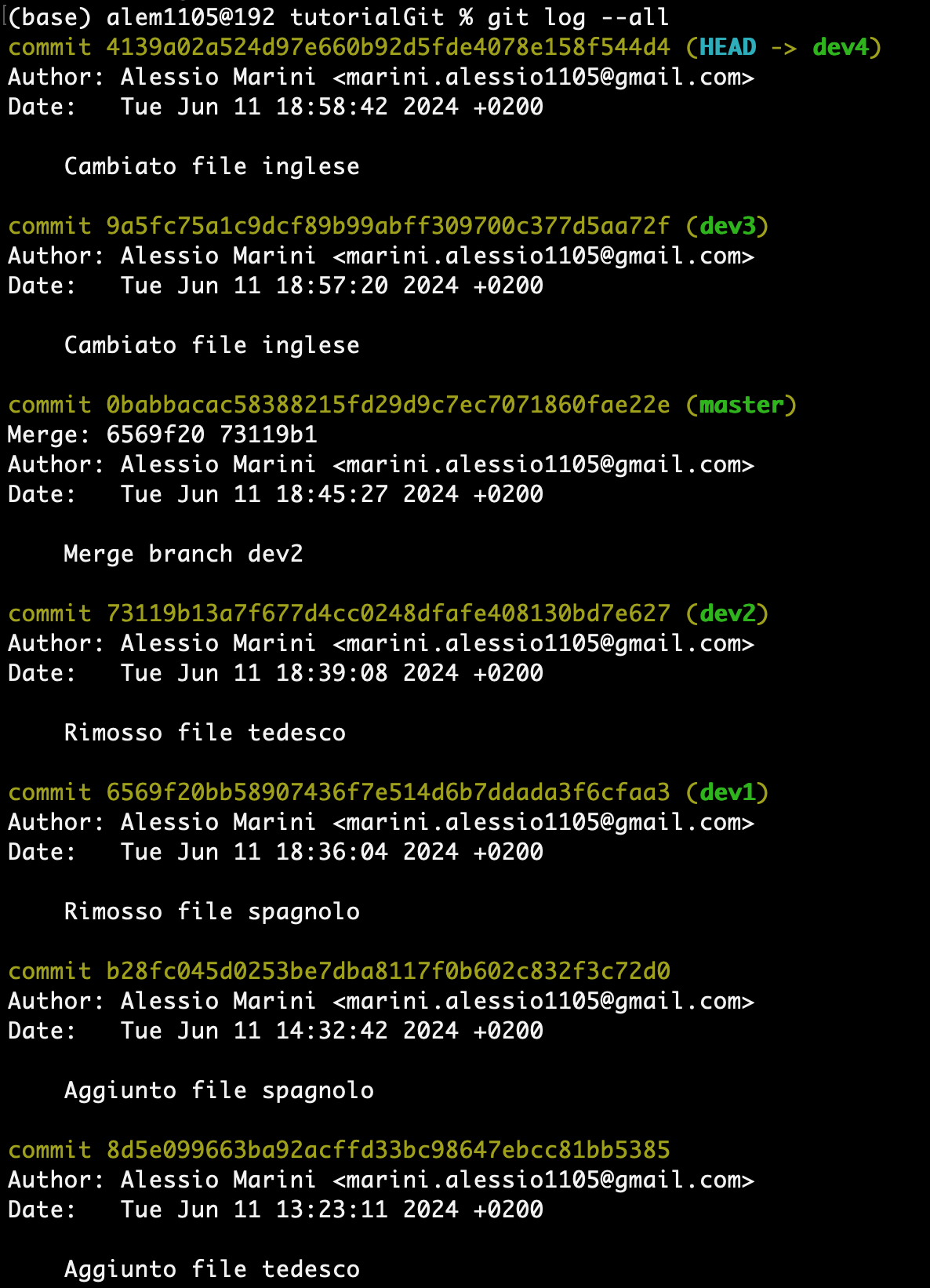
dev3 e dev4 sono dei branches creati dal master ed entrambi modificano il file english.txt nella stessa riga, hanno quindi un conflitto. Adesso eseguiamo una fast-forward di dev3 nel master e poi una non-fast-forward di dev4.
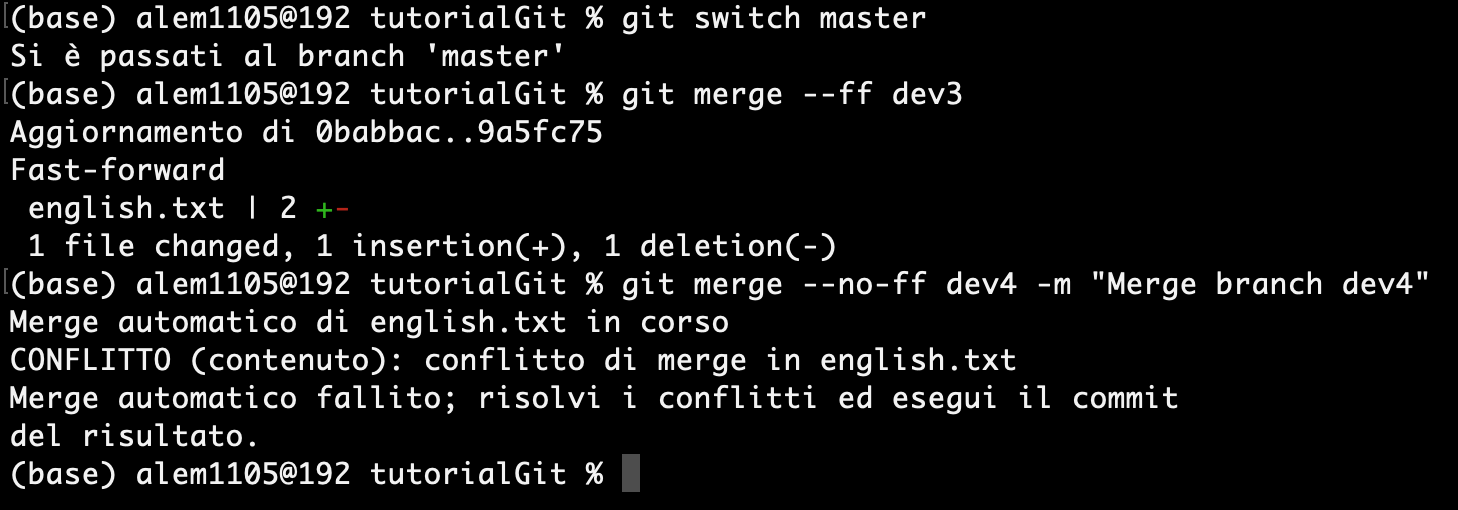
Git ha rilevato il conflitto e non può risolverlo automaticamente.
Se controlliamo lo stato di git e anche il contenuto del file otteniamo questo:
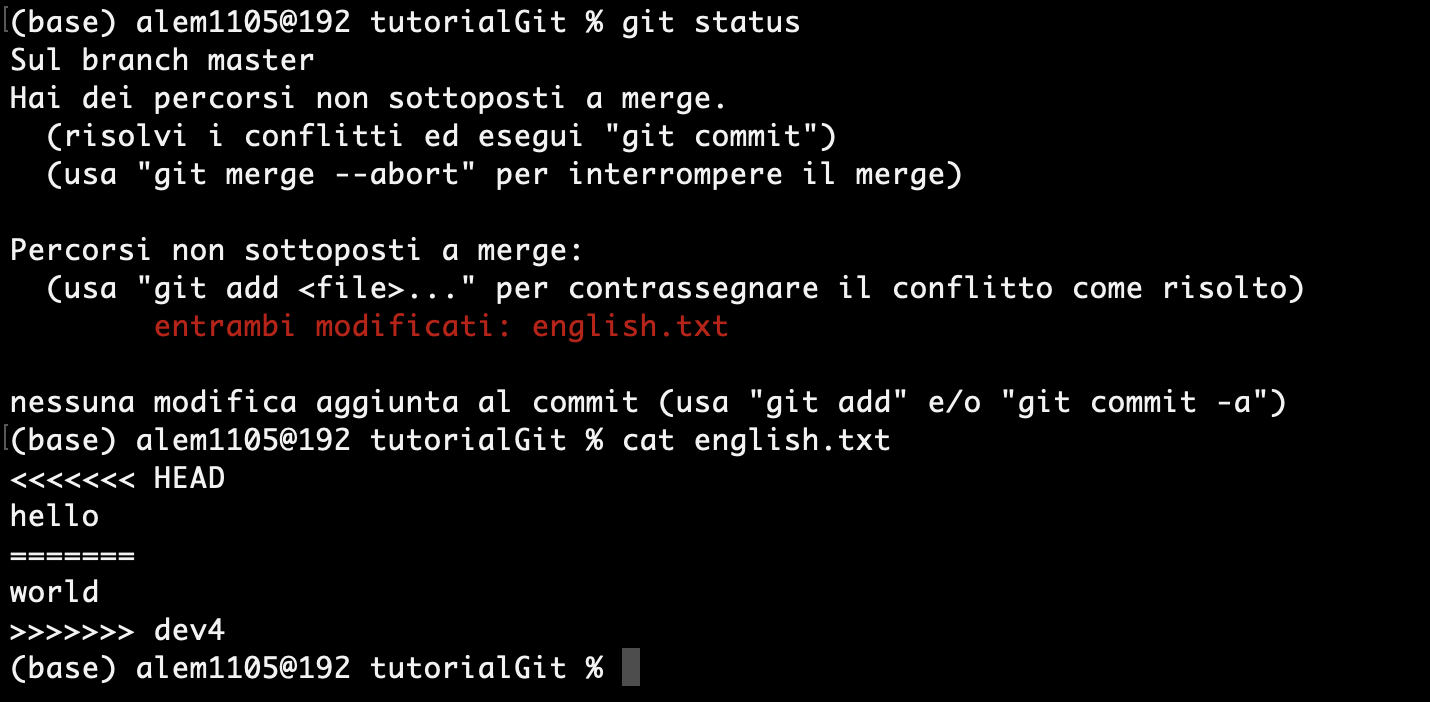
Possiamo quindi entrare nel file modificarlo come vogliamo e poi eseguire il commit. Una volta eseguito anche il commit:
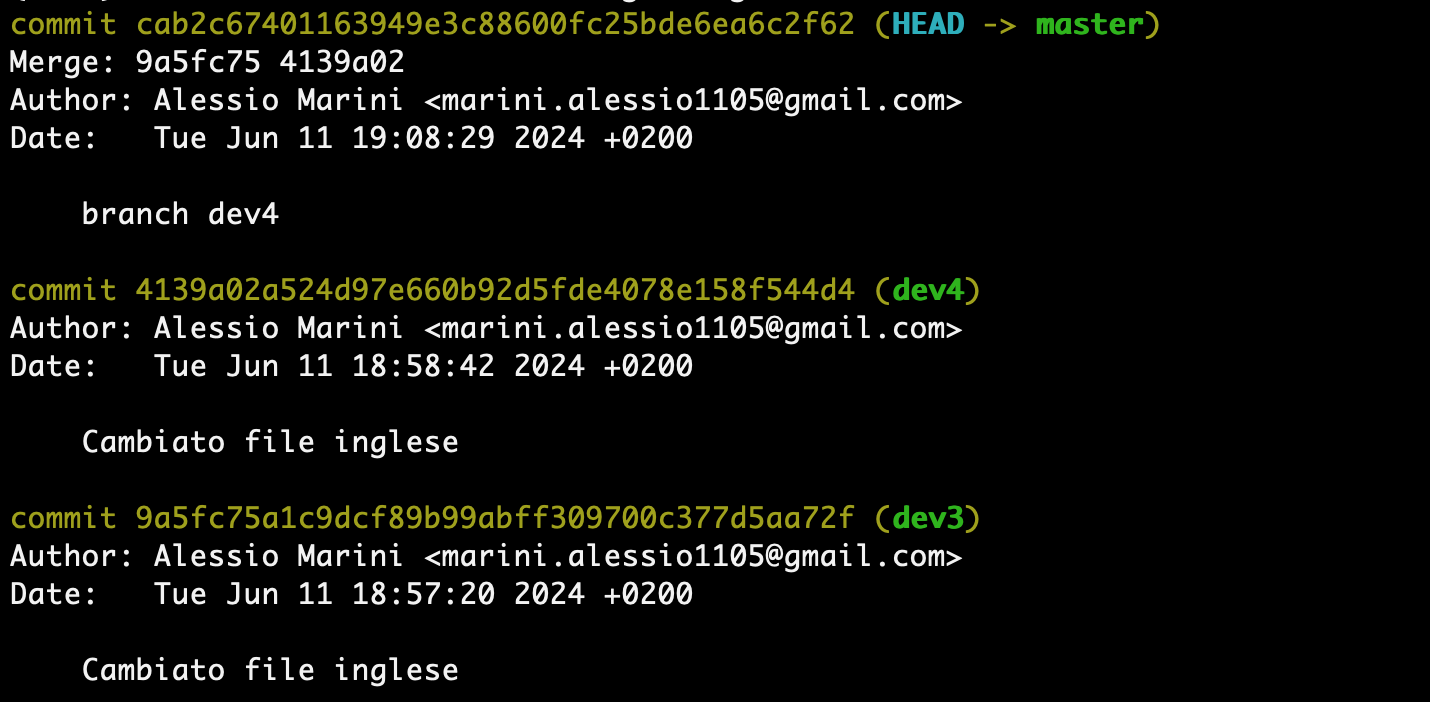
Abbiamo eseguito correttamente il merge risolvendo i conflitti.
Tagging
Per taggare il commit in cui ci troviamo ci basta utilizzare il comando tag.
git tag v1Come visto prima possiamo muoverci anche nei tag ma se non sono presenti branch ci ritroveremo nello stato di HEAD detached.
Clone a remote repository
Per clonare una repository utilizziamo il comando git clone seguito dall’URL della repository, in questo modo avremo la nostra copia in locale. Dopo aver effettuato delle modifiche dobbiamo inviare i nostri commits / branches e tags al remote.
Send commits / branches / tags to the remote
Dopo aver eseguito un commit in locale per inviarlo ci basta eseguire il comando git push
Fetch commits / branches / tags from remote
Molto simile a prima con il comando git fetch otteniamo le informazioni dal remote e poi dobbiamo eseguire un git pull per aggiornare la nostra repository locale. Se eseguiamo git pull verrà eseguito in automatico anche il fetch.
Issues, pull / merge request
Queste cambiano per ogni forge che utilizziamo ma di norma il funzionamento è simile, comunque è tutto indicato tramite interfaccia grafica.